
最新刊期
2024 年 第 29 卷 第 5 期
-
-
 摘要:语义分割是计算机视觉领域的一项像素级别的感知任务,目的是为图像中的每个像素分配相应类别标签,具有广泛应用。许多语义分割网络结构复杂,计算量和参数量较大,在对高分辨率图像进行像素层次的理解时具有较大的延迟,这极大限制了其在资源受限环境下的应用,如自动驾驶、辅助医疗和移动设备等。因此,实时推理的语义分割网络得到了广泛关注。本文对深度学习中实时语义分割算法进行了全面论述和分析。1)介绍了语义分割和实时语义分割任务的基本概念、应用场景和面临问题;2)详细介绍了实时语义分割算法中常用的技术和设计,包括模型压缩技术、高效卷积神经网络(convolutional neural network,CNN)模块和高效Transformer模块;3)全面整理和归纳了现阶段的实时语义分割算法,包括单分支网络、双分支网络、多分支网络、U型网络和神经架构搜索网络5种类别的实时语义分割方法,涵盖基于CNN、基于Transformer和基于混合框架的分割网络,并分析了各类实时语义分割算法的特点和局限性;4)提供了完整的实时语义分割评价体系,包括相关数据集和评价指标、现有方法性能汇总以及领域主流方法的同设备比较,为后续研究者提供统一的比较标准;5)给出结论并分析了实时语义分割领域仍存在的挑战,对实时语义分割领域未来可能的研究方向提出了相应见解。本文提及的算法、数据集和评估指标已汇总至https://github.com/xzz777/Awesome-Real-time-Semantic-Segmentation,以便后续研究者使用。关键词:实时语义分割;模型轻量化;高效模块设计;计算机视觉;深度学习1524|1270|4更新时间:2024-05-15
摘要:语义分割是计算机视觉领域的一项像素级别的感知任务,目的是为图像中的每个像素分配相应类别标签,具有广泛应用。许多语义分割网络结构复杂,计算量和参数量较大,在对高分辨率图像进行像素层次的理解时具有较大的延迟,这极大限制了其在资源受限环境下的应用,如自动驾驶、辅助医疗和移动设备等。因此,实时推理的语义分割网络得到了广泛关注。本文对深度学习中实时语义分割算法进行了全面论述和分析。1)介绍了语义分割和实时语义分割任务的基本概念、应用场景和面临问题;2)详细介绍了实时语义分割算法中常用的技术和设计,包括模型压缩技术、高效卷积神经网络(convolutional neural network,CNN)模块和高效Transformer模块;3)全面整理和归纳了现阶段的实时语义分割算法,包括单分支网络、双分支网络、多分支网络、U型网络和神经架构搜索网络5种类别的实时语义分割方法,涵盖基于CNN、基于Transformer和基于混合框架的分割网络,并分析了各类实时语义分割算法的特点和局限性;4)提供了完整的实时语义分割评价体系,包括相关数据集和评价指标、现有方法性能汇总以及领域主流方法的同设备比较,为后续研究者提供统一的比较标准;5)给出结论并分析了实时语义分割领域仍存在的挑战,对实时语义分割领域未来可能的研究方向提出了相应见解。本文提及的算法、数据集和评估指标已汇总至https://github.com/xzz777/Awesome-Real-time-Semantic-Segmentation,以便后续研究者使用。关键词:实时语义分割;模型轻量化;高效模块设计;计算机视觉;深度学习1524|1270|4更新时间:2024-05-15 -
 摘要:语义分割是计算机视觉领域的基本任务,旨在为每个像素分配语义类别标签,实现对图像的像素级理解。得益于深度学习的发展,基于深度学习的全监督语义分割方法取得了巨大进展。然而,这些方法往往需要大量带有像素级标注的训练数据,标注成本巨大,限制了其在诸如自动驾驶、医学图像分析以及工业控制等实际场景中的应用。为了降低数据的标注成本并进一步拓宽语义分割的应用场景,研究者们越来越关注基于深度学习的弱监督语义分割方法,希望通过诸如图像级标注、最小包围盒标注、线标注和点标注等弱标注信息实现图像的像素级分割预测。首先对语义分割任务进行了简要介绍,并分析了全监督语义分割所面临的困境,从而引出弱监督语义分割。然后,介绍了相关数据集和评估指标。接着,根据弱标注的类型和受关注程度,从图像级标注、其他弱标注以及大模型辅助这3个方面回顾和讨论了弱监督语义分割的研究进展。其中,第2类弱监督语义分割方法包括基于最小包围盒、线和点标注的弱监督语义分割。最后,分析了弱监督语义分割领域存在的问题与挑战,并就其未来可能的研究方向提出建议,旨在进一步推动弱监督语义分割领域研究的发展。关键词:语义分割;深度学习;弱监督语义分割(WSSS);图像级标注;最小包围盒标注;线标注;点标注;大模型827|1915|1更新时间:2024-05-15
摘要:语义分割是计算机视觉领域的基本任务,旨在为每个像素分配语义类别标签,实现对图像的像素级理解。得益于深度学习的发展,基于深度学习的全监督语义分割方法取得了巨大进展。然而,这些方法往往需要大量带有像素级标注的训练数据,标注成本巨大,限制了其在诸如自动驾驶、医学图像分析以及工业控制等实际场景中的应用。为了降低数据的标注成本并进一步拓宽语义分割的应用场景,研究者们越来越关注基于深度学习的弱监督语义分割方法,希望通过诸如图像级标注、最小包围盒标注、线标注和点标注等弱标注信息实现图像的像素级分割预测。首先对语义分割任务进行了简要介绍,并分析了全监督语义分割所面临的困境,从而引出弱监督语义分割。然后,介绍了相关数据集和评估指标。接着,根据弱标注的类型和受关注程度,从图像级标注、其他弱标注以及大模型辅助这3个方面回顾和讨论了弱监督语义分割的研究进展。其中,第2类弱监督语义分割方法包括基于最小包围盒、线和点标注的弱监督语义分割。最后,分析了弱监督语义分割领域存在的问题与挑战,并就其未来可能的研究方向提出建议,旨在进一步推动弱监督语义分割领域研究的发展。关键词:语义分割;深度学习;弱监督语义分割(WSSS);图像级标注;最小包围盒标注;线标注;点标注;大模型827|1915|1更新时间:2024-05-15 -
 摘要:纯视觉鸟瞰图(bird’s-eye-view,BEV)感知是国内外自动驾驶领域的前沿方向与研究热点,旨在通过相机2D图像信息,生成3D空间中周围道路环境俯视视角下的特征表示。该领域在单车智能方向上迅速发展,并实现大量落地部署。但由于车端相机的安装高度受限,不可避免地面临着远距离感知不稳定、存在驾驶盲区等实际问题,单车智能仍存在着一定的安全性风险。路端摄像头部署在红绿灯杆等高处基础设施上,能够有效扩展智能车辆的感知范围,补充盲区视野。因此,车路协同逐渐成为当前自动驾驶的发展趋势。据此,本文从相机部署端和相机视角出发,将纯视觉BEV感知技术划分为车端单视角感知、车端环视视角感知和路端固定视角感知三大方向。在每一方向中,从通用处理流程入手梳理其技术发展脉络,针对主流数据集、BEV映射模型和任务推理输出三大模块展开综述。此外,本文还介绍了相机成像系统的基本原理,并对现有方法从骨干网络使用统计、GPU(graphics processing unit)类型使用统计和模型性能统计等角度进行了定量分析,从可视化对比角度进行了定性分析。最后,从场景多元、尺度多样分布等技术挑战和相机几何参数迁移能力差、计算资源受限等部署挑战两方面揭示了当前纯视觉BEV感知技术亟待解决的问题。并从车路协同、车车协同、虚拟现实交互和统一多任务基座大模型4个方向对本领域的发展进行了全面展望。希望通过对纯视觉BEV感知现有研究以及未来趋势的总结为相关领域研究人员提供一个全面的参考以及探索的方向。关键词:自动驾驶感知;纯视觉BEV感知;路端固定视角感知;车端移动视角感知;多视角图像融合431|2475|0更新时间:2024-05-15
摘要:纯视觉鸟瞰图(bird’s-eye-view,BEV)感知是国内外自动驾驶领域的前沿方向与研究热点,旨在通过相机2D图像信息,生成3D空间中周围道路环境俯视视角下的特征表示。该领域在单车智能方向上迅速发展,并实现大量落地部署。但由于车端相机的安装高度受限,不可避免地面临着远距离感知不稳定、存在驾驶盲区等实际问题,单车智能仍存在着一定的安全性风险。路端摄像头部署在红绿灯杆等高处基础设施上,能够有效扩展智能车辆的感知范围,补充盲区视野。因此,车路协同逐渐成为当前自动驾驶的发展趋势。据此,本文从相机部署端和相机视角出发,将纯视觉BEV感知技术划分为车端单视角感知、车端环视视角感知和路端固定视角感知三大方向。在每一方向中,从通用处理流程入手梳理其技术发展脉络,针对主流数据集、BEV映射模型和任务推理输出三大模块展开综述。此外,本文还介绍了相机成像系统的基本原理,并对现有方法从骨干网络使用统计、GPU(graphics processing unit)类型使用统计和模型性能统计等角度进行了定量分析,从可视化对比角度进行了定性分析。最后,从场景多元、尺度多样分布等技术挑战和相机几何参数迁移能力差、计算资源受限等部署挑战两方面揭示了当前纯视觉BEV感知技术亟待解决的问题。并从车路协同、车车协同、虚拟现实交互和统一多任务基座大模型4个方向对本领域的发展进行了全面展望。希望通过对纯视觉BEV感知现有研究以及未来趋势的总结为相关领域研究人员提供一个全面的参考以及探索的方向。关键词:自动驾驶感知;纯视觉BEV感知;路端固定视角感知;车端移动视角感知;多视角图像融合431|2475|0更新时间:2024-05-15 -
 摘要:语义分割作为计算机视觉领域的重要研究方向之一,应用十分广泛。其目的是根据预先定义好的类别对输入图像进行像素级别的分类。实时语义分割则在一般语义分割的基础上又增加了对速度的要求,广泛应用于如无人驾驶、医学图像分析、视频监控与航拍图像等领域。其要求分割方法不仅要取得较高的分割精度,且分割速度也要快。随着深度学习和神经网络的快速发展,实时语义分割也取得了一定的研究成果。本文在前人已有工作的基础上对基于深度学习的实时语义分割算法进行系统的归纳总结,包括基于Transformer和剪枝的方法等,全面介绍实时语义分割方法在各领域中的应用。首先介绍实时语义分割的概念,再根据标签的数量和质量,将现有的基于深度学习的实时语义分割方法分为强监督学习、弱监督学习和无监督学习3个类别。在分类的基础上,结合各个类别中最具有代表性的方法,对其优缺点展开分析,并从多个角度进行比较。随后介绍目前实时语义分割常用的数据集和评价指标,并对比分析各算法在各数据集上的实验效果,阐述现阶段实时语义分割的应用场景。最后,讨论了基于深度学习的实时语义分割存在的挑战,并对实时语义分割未来值得研究的方向进行展望,为研究者们解决存在的问题提供便利。关键词:语义分割(SS);实时语义分割;深度学习;注意力;卷积353|746|0更新时间:2024-05-15
摘要:语义分割作为计算机视觉领域的重要研究方向之一,应用十分广泛。其目的是根据预先定义好的类别对输入图像进行像素级别的分类。实时语义分割则在一般语义分割的基础上又增加了对速度的要求,广泛应用于如无人驾驶、医学图像分析、视频监控与航拍图像等领域。其要求分割方法不仅要取得较高的分割精度,且分割速度也要快。随着深度学习和神经网络的快速发展,实时语义分割也取得了一定的研究成果。本文在前人已有工作的基础上对基于深度学习的实时语义分割算法进行系统的归纳总结,包括基于Transformer和剪枝的方法等,全面介绍实时语义分割方法在各领域中的应用。首先介绍实时语义分割的概念,再根据标签的数量和质量,将现有的基于深度学习的实时语义分割方法分为强监督学习、弱监督学习和无监督学习3个类别。在分类的基础上,结合各个类别中最具有代表性的方法,对其优缺点展开分析,并从多个角度进行比较。随后介绍目前实时语义分割常用的数据集和评价指标,并对比分析各算法在各数据集上的实验效果,阐述现阶段实时语义分割的应用场景。最后,讨论了基于深度学习的实时语义分割存在的挑战,并对实时语义分割未来值得研究的方向进行展望,为研究者们解决存在的问题提供便利。关键词:语义分割(SS);实时语义分割;深度学习;注意力;卷积353|746|0更新时间:2024-05-15 -
 摘要:目的遮挡物体实例分割效果的好坏与物体轮廓的预测结果息息相关,但目前算法预测的物体轮廓并不够细化,使得分割掩膜粗糙,物体边界分割效果不佳。为此,以BCNet(bilayer convolutional network)网络为基础,提出一种针对遮挡物体的轮廓细化实例分割算法,预测的物体轮廓更加精细,分割掩膜更加完整。方法1)提出一种均衡池化注意力模块来提取特征,在传统一维平均池化的基础上,增加一维最大池化操作以突出细节特征,并将最大池化和平均池化结果进行加权融合来提取特征,使提取的特征能更好地兼顾物体的整体和边缘细节;2)将BCNet掩膜头中轮廓预测与掩膜预测分成两个支路来进行,从特征金字塔最高分辨率特征中提取感兴趣区域(region of interest, RoI)特征用于轮廓预测,并提出一种自适应特征融合模块,将轮廓预测支路中的特征与掩膜预测支路的特征进行融合,在轮廓预测支路中,融合掩膜预测支路的特征可以更好地判定轮廓所属物体类别,在掩膜预测支路,融合轮廓预测支路的特征能够更好地辅助掩膜定位。结果在COCO 2017(common objects in context 2017)数据集上,本文相较于目前同类网络中性能最优的 BCNet 网络,在骨干网络为ResNet-50/101(deep residual network)时平均精度(average precision, AP)分别提高了1.7%和2.1%。结合可视化结果,本文分割算法对遮挡物体的轮廓分割更加精细,能有效分割出更加完整、精细的掩码。结论提出的针对遮挡物体的轮廓细化实例分割算法,明显提升了遮挡物体实例分割的效果。关键词:遮挡物体实例分割;均衡池化注意力模块(BPAM);自适应特征融合模块(AFFM);BCNet;轮廓预测支路;掩膜预测支路175|590|0更新时间:2024-05-15
摘要:目的遮挡物体实例分割效果的好坏与物体轮廓的预测结果息息相关,但目前算法预测的物体轮廓并不够细化,使得分割掩膜粗糙,物体边界分割效果不佳。为此,以BCNet(bilayer convolutional network)网络为基础,提出一种针对遮挡物体的轮廓细化实例分割算法,预测的物体轮廓更加精细,分割掩膜更加完整。方法1)提出一种均衡池化注意力模块来提取特征,在传统一维平均池化的基础上,增加一维最大池化操作以突出细节特征,并将最大池化和平均池化结果进行加权融合来提取特征,使提取的特征能更好地兼顾物体的整体和边缘细节;2)将BCNet掩膜头中轮廓预测与掩膜预测分成两个支路来进行,从特征金字塔最高分辨率特征中提取感兴趣区域(region of interest, RoI)特征用于轮廓预测,并提出一种自适应特征融合模块,将轮廓预测支路中的特征与掩膜预测支路的特征进行融合,在轮廓预测支路中,融合掩膜预测支路的特征可以更好地判定轮廓所属物体类别,在掩膜预测支路,融合轮廓预测支路的特征能够更好地辅助掩膜定位。结果在COCO 2017(common objects in context 2017)数据集上,本文相较于目前同类网络中性能最优的 BCNet 网络,在骨干网络为ResNet-50/101(deep residual network)时平均精度(average precision, AP)分别提高了1.7%和2.1%。结合可视化结果,本文分割算法对遮挡物体的轮廓分割更加精细,能有效分割出更加完整、精细的掩码。结论提出的针对遮挡物体的轮廓细化实例分割算法,明显提升了遮挡物体实例分割的效果。关键词:遮挡物体实例分割;均衡池化注意力模块(BPAM);自适应特征融合模块(AFFM);BCNet;轮廓预测支路;掩膜预测支路175|590|0更新时间:2024-05-15 -
 摘要:目的传统的半监督视频分割多是基于光流的方法建模关键帧与当前帧之间的特征关联。而光流法在使用过程中容易因遮挡、特殊纹理等情况产生错误,从而导致多帧融合存在问题。为了更好地融合多帧特征,本文提取第1帧的外观特征信息与邻近关键帧的位置信息,通过Transformer和改进的PAN(path aggregation network)模块进行特征融合,从而基于多帧时空注意力学习并融合多帧的特征。方法多帧时空注意力引导的半监督视频分割方法由视频预处理(即外观特征提取网络和当前帧特征提取网络)以及基于Transformer和改进的PAN模块的特征融合两部分构成。具体包括以下步骤:构建一个外观信息特征提取网络,用于提取第1帧图像的外观信息;构建一个当前帧特征提取网络,通过Transformer模块对当前帧与第1帧的特征进行融合,使用第1帧的外观信息指导当前帧特征信息的提取;借助邻近数帧掩码图与当前帧特征图进行局部特征匹配,决策出与当前帧位置信息相关性较大的数帧作为邻近关键帧,用来指导当前帧位置信息的提取;借助改进的PAN特征聚合模块,将深层语义信息与浅层语义信息进行融合。结果本文算法在DAVIS(densely annotated video segmentation)-2016数据集上的
摘要:目的传统的半监督视频分割多是基于光流的方法建模关键帧与当前帧之间的特征关联。而光流法在使用过程中容易因遮挡、特殊纹理等情况产生错误,从而导致多帧融合存在问题。为了更好地融合多帧特征,本文提取第1帧的外观特征信息与邻近关键帧的位置信息,通过Transformer和改进的PAN(path aggregation network)模块进行特征融合,从而基于多帧时空注意力学习并融合多帧的特征。方法多帧时空注意力引导的半监督视频分割方法由视频预处理(即外观特征提取网络和当前帧特征提取网络)以及基于Transformer和改进的PAN模块的特征融合两部分构成。具体包括以下步骤:构建一个外观信息特征提取网络,用于提取第1帧图像的外观信息;构建一个当前帧特征提取网络,通过Transformer模块对当前帧与第1帧的特征进行融合,使用第1帧的外观信息指导当前帧特征信息的提取;借助邻近数帧掩码图与当前帧特征图进行局部特征匹配,决策出与当前帧位置信息相关性较大的数帧作为邻近关键帧,用来指导当前帧位置信息的提取;借助改进的PAN特征聚合模块,将深层语义信息与浅层语义信息进行融合。结果本文算法在DAVIS(densely annotated video segmentation)-2016数据集上的 -
 摘要:目的通过融合颜色、深度和空间信息,利用RGB_D这两种模态数据的显著目标检测方案通常能比单一模态数据取得更加准确的预测结果。深度学习进一步推动RGB_D显著目标检测领域的发展。然而,现有RGB_D显著目标检测深度网络模型容易忽略模态的特异性,通常仅通过简单的元素相加、相乘或特征串联来融合多模态特征,如何实现RGB图像和深度图像之间的信息交互则缺乏合理性解释。为了探求两种模态数据中的互补信息重要性及更有效的交互方式,在分析了传统卷积网络中修正线性单元(rectified linear unit,ReLU)选通特性的基础上,设计了一种新的RGB和深度特征互补信息交互机制,并首次应用于RGB_D显著目标检测中。方法首先,根据该机制提出了互补信息交互模块将模态各自的“冗余”特征用于辅助对方。然后,将其阶段式插入两个轻量级主干网络分别用于提取RGB和深度特征并实施两者的交互。该模块核心功能基于修改的ReLU,具有结构简单的特点。在网络的顶层还设计了跨模态特征融合模块用于提取融合后特征的全局语义信息。该特征被馈送至主干网络每个尺度,并通过邻域尺度特征增强模块与多个尺度特征进行聚合。最后,采用了深度恢复监督、边缘监督和深度监督3种监督策略以有效监督提出模型的优化过程。结果在4个广泛使用的公开数据集NJU2K(Nanjing University 2K)、NLPR(national laboratory of pattern recognition)、STERE(stereo dataset)和SIP(salient person)上的定量和定性的实验结果表明,以Max F-measure、MAE(mean absolute error)以及Max E-measure 共3种主流测度评估,本文提出的显著目标检测模型相比较其他方法取得了更优秀的性能和显著的推理速度优势(373.8 帧/s)。结论本文论证了在RGB_D显著目标检测中两种模态数据具有信息互补特点,提出的模型具有较好的性能和高效率推理能力,有较好的实际应用价值。关键词:显著目标检测(SOD);RGB_D;深度卷积网络;互补信息交互;跨模态特征融合292|770|0更新时间:2024-05-15
摘要:目的通过融合颜色、深度和空间信息,利用RGB_D这两种模态数据的显著目标检测方案通常能比单一模态数据取得更加准确的预测结果。深度学习进一步推动RGB_D显著目标检测领域的发展。然而,现有RGB_D显著目标检测深度网络模型容易忽略模态的特异性,通常仅通过简单的元素相加、相乘或特征串联来融合多模态特征,如何实现RGB图像和深度图像之间的信息交互则缺乏合理性解释。为了探求两种模态数据中的互补信息重要性及更有效的交互方式,在分析了传统卷积网络中修正线性单元(rectified linear unit,ReLU)选通特性的基础上,设计了一种新的RGB和深度特征互补信息交互机制,并首次应用于RGB_D显著目标检测中。方法首先,根据该机制提出了互补信息交互模块将模态各自的“冗余”特征用于辅助对方。然后,将其阶段式插入两个轻量级主干网络分别用于提取RGB和深度特征并实施两者的交互。该模块核心功能基于修改的ReLU,具有结构简单的特点。在网络的顶层还设计了跨模态特征融合模块用于提取融合后特征的全局语义信息。该特征被馈送至主干网络每个尺度,并通过邻域尺度特征增强模块与多个尺度特征进行聚合。最后,采用了深度恢复监督、边缘监督和深度监督3种监督策略以有效监督提出模型的优化过程。结果在4个广泛使用的公开数据集NJU2K(Nanjing University 2K)、NLPR(national laboratory of pattern recognition)、STERE(stereo dataset)和SIP(salient person)上的定量和定性的实验结果表明,以Max F-measure、MAE(mean absolute error)以及Max E-measure 共3种主流测度评估,本文提出的显著目标检测模型相比较其他方法取得了更优秀的性能和显著的推理速度优势(373.8 帧/s)。结论本文论证了在RGB_D显著目标检测中两种模态数据具有信息互补特点,提出的模型具有较好的性能和高效率推理能力,有较好的实际应用价值。关键词:显著目标检测(SOD);RGB_D;深度卷积网络;互补信息交互;跨模态特征融合292|770|0更新时间:2024-05-15 -
 摘要:目的构建支持分支和查询分支间的信息交互对于提升小样本语义分割的性能具有重要作用,提出一种多尺度特征融合与交叉指导的小样本语义分割算法。方法利用一组共享权重的主干网络将双分支输入图像映射到深度特征空间,并将输出的低层、中间层和高层特征进行尺度融合,构造多尺度特征;借助支持分支的掩码将支持特征分解成目标前景和背景特征图;设计了一种特征交互模块,在支持分支的目标前景和整个查询分支的特征图上建立信息交互,增强任务相关特征的表达能力,并利用掩码平均池化策略生成目标前景和背景区域的原型集;利用无参数的度量方法分别计算支持特征和原型集、查询特征与原型集之间的余弦相似度值,并根据相似度值给出对应图像的掩码。结果通过在PASCAL-5i(pattern analysis, statistical modeling and computational learning)和COCO-20i(common objects in context)开源数据集上进行实验,结果表明,利用VGG-16(Visual Geometry Group)、ResNet-50(residual neural network)和ResNet-101作为主干网络时,所提模型在1-way 1-shot任务中,分别获得50.2%、53.2%、57.1%和23.9%、35.1%、36.4%的平均交并比(mean intersection over union,mIoU),68.3%、69.4%、72.3%/和60.1%、62.4%、64.1%的前景背景二分类交并比(foreground and background intersection over union,FB-IoU);在1-way 5-shot任务上,分别获得52.9%、55.7%、59.7%和32.5%、37.3%、38.3%的mIoU,69.7%、72.5%、74.6%和64.2%、66.2%、66.7%的FB-IoU。结论相比当前主流的小样本语义分割模型,所提模型在1-way 1-shot和1-way 5-shot任务中可以获得更高的mIoU和FB-IoU,综合性能提升效果显著。关键词:小样本语义分割;多尺度特征融合;跨分支交叉指导;特征交互;掩码平均池化329|536|1更新时间:2024-05-15
摘要:目的构建支持分支和查询分支间的信息交互对于提升小样本语义分割的性能具有重要作用,提出一种多尺度特征融合与交叉指导的小样本语义分割算法。方法利用一组共享权重的主干网络将双分支输入图像映射到深度特征空间,并将输出的低层、中间层和高层特征进行尺度融合,构造多尺度特征;借助支持分支的掩码将支持特征分解成目标前景和背景特征图;设计了一种特征交互模块,在支持分支的目标前景和整个查询分支的特征图上建立信息交互,增强任务相关特征的表达能力,并利用掩码平均池化策略生成目标前景和背景区域的原型集;利用无参数的度量方法分别计算支持特征和原型集、查询特征与原型集之间的余弦相似度值,并根据相似度值给出对应图像的掩码。结果通过在PASCAL-5i(pattern analysis, statistical modeling and computational learning)和COCO-20i(common objects in context)开源数据集上进行实验,结果表明,利用VGG-16(Visual Geometry Group)、ResNet-50(residual neural network)和ResNet-101作为主干网络时,所提模型在1-way 1-shot任务中,分别获得50.2%、53.2%、57.1%和23.9%、35.1%、36.4%的平均交并比(mean intersection over union,mIoU),68.3%、69.4%、72.3%/和60.1%、62.4%、64.1%的前景背景二分类交并比(foreground and background intersection over union,FB-IoU);在1-way 5-shot任务上,分别获得52.9%、55.7%、59.7%和32.5%、37.3%、38.3%的mIoU,69.7%、72.5%、74.6%和64.2%、66.2%、66.7%的FB-IoU。结论相比当前主流的小样本语义分割模型,所提模型在1-way 1-shot和1-way 5-shot任务中可以获得更高的mIoU和FB-IoU,综合性能提升效果显著。关键词:小样本语义分割;多尺度特征融合;跨分支交叉指导;特征交互;掩码平均池化329|536|1更新时间:2024-05-15 -
 摘要:目的语义分割是遥感图像智能解译的关键任务之一,遥感图像覆盖面广,背景交叉复杂,且地物尺寸差异性大。现有方法在复杂背景下的多尺度地物上分割效果较差,且分割区域破碎边界不连续。 针对上述问题,提出了一种跨层细节感知和分组注意力引导的语义分割模型用于高分辨率遥感图像解析。方法首先采用结构新颖的ConvNeXt骨干网络,编码输入图像的各层次特征。其次,设计了分组协同注意力模块,分组并行建模通道和空间维度的特征依赖性,通道注意力和空间注意力协同强化重要通道和区域的特征信息。接着,引入了自注意力机制,构建了跨层细节感知模块,利用低层特征中丰富的细节信息,指导高层特征层学习空间细节,保证分割结果的区域完整性和边界连续性。最后,以山西省太原市为研究区域,自制高分辨率遥感太原市城区土地覆盖数据集(Taiyuan urban land cover dataset,TULCD),所提方法实现了太原市城区土地覆盖精细分类任务。结果实验在自制数据集TULCD和公开数据集Vaihingen上与最新的5种算法进行了比较,所提方法在两个数据集上平均像素准确率(mean pixel accuracy,mPA)为74.23%、87.26%,平均交并比(mean intersection over union,mIoU)为58.91%、77.02%,平均得分mF1 为72.24%、86.35%,均优于对比算法。结论本文提出的高分辨率遥感图像语义分割模型具有较强的空间和细节感知能力,对类间差异小的相邻地物也有较强的鉴别能力,模型的整体分割精度较高。关键词:遥感图像;语义分割;全卷积网络(FCN);注意力机制;分组卷积411|1332|0更新时间:2024-05-15
摘要:目的语义分割是遥感图像智能解译的关键任务之一,遥感图像覆盖面广,背景交叉复杂,且地物尺寸差异性大。现有方法在复杂背景下的多尺度地物上分割效果较差,且分割区域破碎边界不连续。 针对上述问题,提出了一种跨层细节感知和分组注意力引导的语义分割模型用于高分辨率遥感图像解析。方法首先采用结构新颖的ConvNeXt骨干网络,编码输入图像的各层次特征。其次,设计了分组协同注意力模块,分组并行建模通道和空间维度的特征依赖性,通道注意力和空间注意力协同强化重要通道和区域的特征信息。接着,引入了自注意力机制,构建了跨层细节感知模块,利用低层特征中丰富的细节信息,指导高层特征层学习空间细节,保证分割结果的区域完整性和边界连续性。最后,以山西省太原市为研究区域,自制高分辨率遥感太原市城区土地覆盖数据集(Taiyuan urban land cover dataset,TULCD),所提方法实现了太原市城区土地覆盖精细分类任务。结果实验在自制数据集TULCD和公开数据集Vaihingen上与最新的5种算法进行了比较,所提方法在两个数据集上平均像素准确率(mean pixel accuracy,mPA)为74.23%、87.26%,平均交并比(mean intersection over union,mIoU)为58.91%、77.02%,平均得分mF1 为72.24%、86.35%,均优于对比算法。结论本文提出的高分辨率遥感图像语义分割模型具有较强的空间和细节感知能力,对类间差异小的相邻地物也有较强的鉴别能力,模型的整体分割精度较高。关键词:遥感图像;语义分割;全卷积网络(FCN);注意力机制;分组卷积411|1332|0更新时间:2024-05-15 -
 摘要:目的由于数据采集限制和隐私保护造成高强度聚焦超声(high intensity focused ultrasound, HIFU)治疗超声监控图像数据量过少,导致现有的强监督分割方法提取治疗目标区域不佳。因此,提出了一种结合潜在扩散模型(latent diffusion)和U型网络的HIFU治疗目标区域提取方法。方法生成阶段利用潜在扩散模型和自动筛选模块,实现超声监控图像数据的扩充。目标区域提取阶段提出新型U型分割网络(novel U-shaped segmentation network, NUNet),在编码器端结合空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP),扩大网络的感受野;设计双注意力跳跃连接模块(dual attention skip connection,DAttention-SK),降低边缘纹理信息丢失的风险;引入多交叉熵损失提高网络的分割性能。结果实验结果表明,与其他生成模型相比,本文使用潜在扩散模型生成的超声监控图像在FID(Fréchet inception distance)和LPIPS(learned perceptual image patch similarity)上获得更优的指标(分别为0.172和0.072);相较于先进的PDF-UNet(U-shaped pyramid-dilated network),在HIFU临床治疗子宫肌瘤超声监控数据集中,本文分割算法的MIoU(mean intersection over union)和DSC(Dice similarity coefficient)分别提高了2.67%和1.39%。为进一步探讨所提算法的泛化性,在乳腺超声公共数据集(breast ultrasound images dataset,BUSI)上进行了验证。相较于M2SNet(multi-scale in multi-scale subtraction network),本文算法MIoU和DSC分别提升了2.11%和1.36%。结论本文算法在一定程度上解决了超声监控图像中数据量过少的问题,实现对监控超声图像中目标区域的精确提取。代码开源地址为https://github.com/425877/based-on-latent-diffusion-model-for-HIFU-treatment-target-region-extraction。关键词:高强度聚焦超声(HIFU);图像分割;图像生成;损失函数;潜在扩散模型269|578|0更新时间:2024-05-15
摘要:目的由于数据采集限制和隐私保护造成高强度聚焦超声(high intensity focused ultrasound, HIFU)治疗超声监控图像数据量过少,导致现有的强监督分割方法提取治疗目标区域不佳。因此,提出了一种结合潜在扩散模型(latent diffusion)和U型网络的HIFU治疗目标区域提取方法。方法生成阶段利用潜在扩散模型和自动筛选模块,实现超声监控图像数据的扩充。目标区域提取阶段提出新型U型分割网络(novel U-shaped segmentation network, NUNet),在编码器端结合空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP),扩大网络的感受野;设计双注意力跳跃连接模块(dual attention skip connection,DAttention-SK),降低边缘纹理信息丢失的风险;引入多交叉熵损失提高网络的分割性能。结果实验结果表明,与其他生成模型相比,本文使用潜在扩散模型生成的超声监控图像在FID(Fréchet inception distance)和LPIPS(learned perceptual image patch similarity)上获得更优的指标(分别为0.172和0.072);相较于先进的PDF-UNet(U-shaped pyramid-dilated network),在HIFU临床治疗子宫肌瘤超声监控数据集中,本文分割算法的MIoU(mean intersection over union)和DSC(Dice similarity coefficient)分别提高了2.67%和1.39%。为进一步探讨所提算法的泛化性,在乳腺超声公共数据集(breast ultrasound images dataset,BUSI)上进行了验证。相较于M2SNet(multi-scale in multi-scale subtraction network),本文算法MIoU和DSC分别提升了2.11%和1.36%。结论本文算法在一定程度上解决了超声监控图像中数据量过少的问题,实现对监控超声图像中目标区域的精确提取。代码开源地址为https://github.com/425877/based-on-latent-diffusion-model-for-HIFU-treatment-target-region-extraction。关键词:高强度聚焦超声(HIFU);图像分割;图像生成;损失函数;潜在扩散模型269|578|0更新时间:2024-05-15
图像/视频语义分割

-
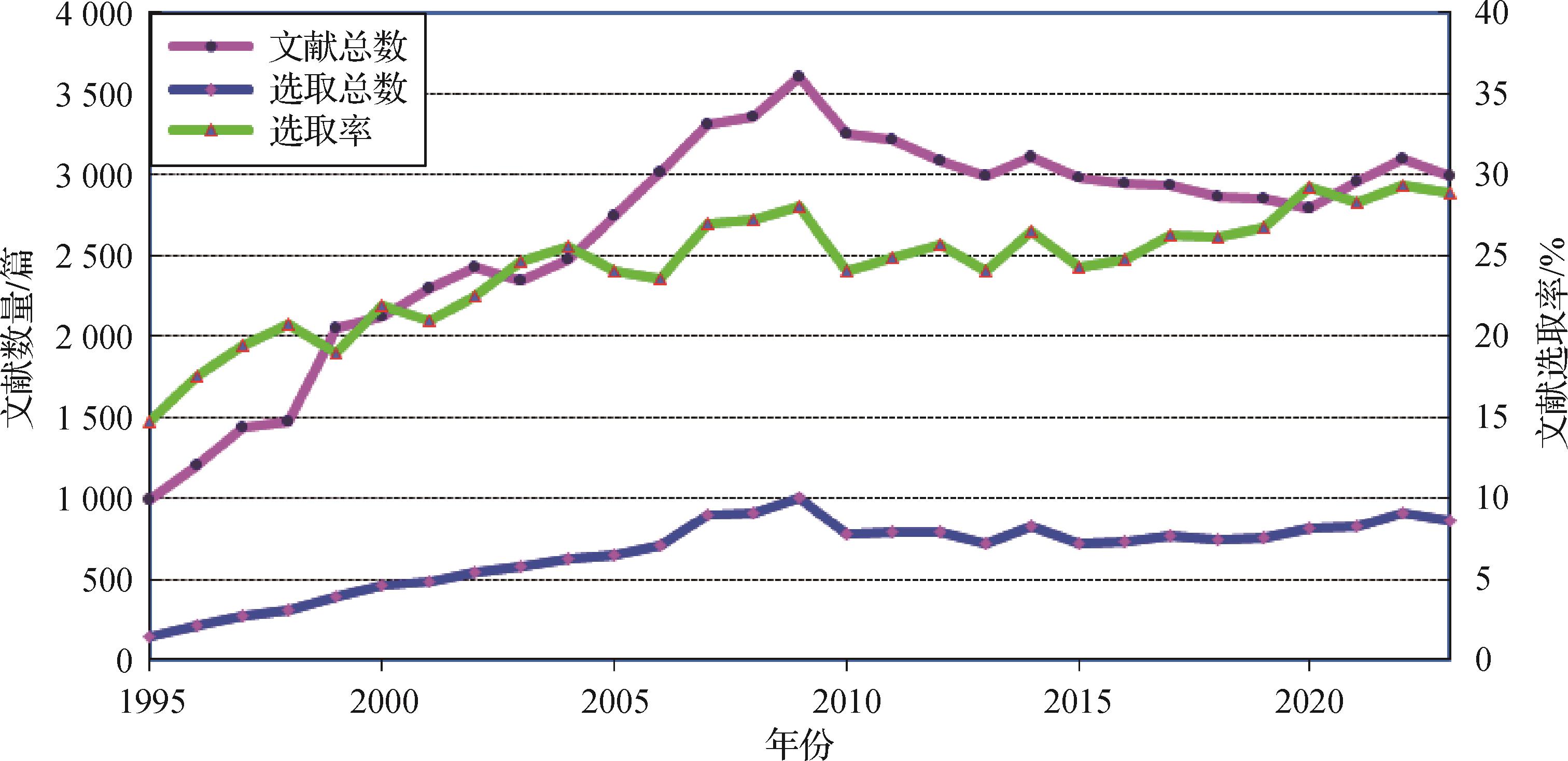 摘要:本文是关于中国图像工程的年度文献综述系列之二十九。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,本文对2023年度发表的图像工程相关文献进行了统计和分析。具体从国内15种有关图像工程重要中文期刊在2023年发行的所有154期上发表的学术研究和技术应用文献(共2 989篇)中,选取出所有属于图像工程领域的文献(共865篇),并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前18年相同),并在此基础上分别进行了各个期刊及各类文献的统计和分析。根据对2023年统计数据的分析可以看出:从研究角度看,图像分析方向当前得到了最多的关注,其中图像分割和基元检测、目标检测和识别以及人体生物特征提取和验证等都是研究的焦点;从应用角度看,遥感、雷达、声呐、测绘等领域最为活跃,而且新的图像技术开发和应用领域拓展很快。总的来说,中国图像工程在2023年的研究深度和广度还在继续提高和扩大,仍保持了快速发展的势头。综合29年的统计数据还为读者提供了更全面和更可信的各个研究方向发展趋势的信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学218|851|0更新时间:2024-05-15
摘要:本文是关于中国图像工程的年度文献综述系列之二十九。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,本文对2023年度发表的图像工程相关文献进行了统计和分析。具体从国内15种有关图像工程重要中文期刊在2023年发行的所有154期上发表的学术研究和技术应用文献(共2 989篇)中,选取出所有属于图像工程领域的文献(共865篇),并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前18年相同),并在此基础上分别进行了各个期刊及各类文献的统计和分析。根据对2023年统计数据的分析可以看出:从研究角度看,图像分析方向当前得到了最多的关注,其中图像分割和基元检测、目标检测和识别以及人体生物特征提取和验证等都是研究的焦点;从应用角度看,遥感、雷达、声呐、测绘等领域最为活跃,而且新的图像技术开发和应用领域拓展很快。总的来说,中国图像工程在2023年的研究深度和广度还在继续提高和扩大,仍保持了快速发展的势头。综合29年的统计数据还为读者提供了更全面和更可信的各个研究方向发展趋势的信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学218|851|0更新时间:2024-05-15 -
 摘要:液晶屏(liquid crystal display, LCD)和有机发光半导体(organic light-emitting diode, OLED)屏的制造工艺复杂,其生产过程的每个阶段会不可避免地引入各种缺陷,影响产品的视觉效果及用户体验,甚至出现严重的质量问题。实现快速且精确的缺陷检测是提高产品质量和生产效率的重要手段。本文综述了近20年来基于机器视觉的液晶屏/OLED屏缺陷检测方法。首先给出了液晶屏/OLED屏表面缺陷的定义、分类及其产生的原因和缺陷的量化指标;指出了基于视觉的液晶屏/OLED屏表面缺陷检测的难点。然后重点阐述了基于图像处理的缺陷检测方法,包括介绍图像去噪和图像亮度矫正的图像预处理过程;考虑到所采集的液晶屏/OLED屏图像存在纹理背景干扰,对重复性纹理背景消除和背景抑制法进行分析;针对Mura缺陷边缘模糊等特点,总结改进的缺陷分割方法;阐述提取图像特征并使用支持向量机、支持向量数据描述和随机森林算法等基于特征识别的缺陷检测方法。接着综述了基于深度学习的缺陷检测方法,根据产线不同时期的样本数量分别总结了无监督学习、缺陷样本生成、迁移学习和监督学习的方法,其中无监督学习从基于生成对抗网络和自编码器两个方面进行阐述。随后梳理了通用纹理表面缺陷数据集和模型性能的评价指标。最后针对目前液晶屏/OLED屏缺陷检测方法存在的问题,对未来进一步的研究方向进行了展望。关键词:缺陷检测;液晶屏(LCD);OLED屏;机器视觉;深度学习;纹理背景消除;无监督学习542|3094|2更新时间:2024-05-15
摘要:液晶屏(liquid crystal display, LCD)和有机发光半导体(organic light-emitting diode, OLED)屏的制造工艺复杂,其生产过程的每个阶段会不可避免地引入各种缺陷,影响产品的视觉效果及用户体验,甚至出现严重的质量问题。实现快速且精确的缺陷检测是提高产品质量和生产效率的重要手段。本文综述了近20年来基于机器视觉的液晶屏/OLED屏缺陷检测方法。首先给出了液晶屏/OLED屏表面缺陷的定义、分类及其产生的原因和缺陷的量化指标;指出了基于视觉的液晶屏/OLED屏表面缺陷检测的难点。然后重点阐述了基于图像处理的缺陷检测方法,包括介绍图像去噪和图像亮度矫正的图像预处理过程;考虑到所采集的液晶屏/OLED屏图像存在纹理背景干扰,对重复性纹理背景消除和背景抑制法进行分析;针对Mura缺陷边缘模糊等特点,总结改进的缺陷分割方法;阐述提取图像特征并使用支持向量机、支持向量数据描述和随机森林算法等基于特征识别的缺陷检测方法。接着综述了基于深度学习的缺陷检测方法,根据产线不同时期的样本数量分别总结了无监督学习、缺陷样本生成、迁移学习和监督学习的方法,其中无监督学习从基于生成对抗网络和自编码器两个方面进行阐述。随后梳理了通用纹理表面缺陷数据集和模型性能的评价指标。最后针对目前液晶屏/OLED屏缺陷检测方法存在的问题,对未来进一步的研究方向进行了展望。关键词:缺陷检测;液晶屏(LCD);OLED屏;机器视觉;深度学习;纹理背景消除;无监督学习542|3094|2更新时间:2024-05-15 -
 摘要:RGB-D图像包含丰富的多层特征,如底层的线特征、平面特征,高层的语义特征,面向RGB-D图像的多层特征提取结果可以作为先验知识提升室内场景重建、SLAM(simultaneous localization and mapping)等多种任务的输出质量,是计算机图形学领域的热点研究内容之一。传统的多层特征提取算法一般利用RGB图像中丰富的颜色、纹理信息以及深度图像中的几何信息提取多层特征,此类提取算法依赖输入RGB-D图像的质量,而受采集过程中环境和人为因素的影响,很难得到高质量的RGB-D图像。随着深度学习技术的快速发展,基于深度学习的多层特征提取算法突破了这一限制,涌现出一批高质量的研究成果。本文对面向RGB-D图像的多层特征提取算法进行综述。首先,汇总了现有的常用于多层特征提取任务的RGB-D数据集和相关算法的质量评价指标。然后,按照特征所处的不同层次,依次对线、平面和语义特征相关算法进行了总结。此外,本文还对各算法的优缺点进行比较并结合常用算法质量评价标准进行了定量分析。最后,讨论了当前多层特征提取算法亟待解决的问题并展望了未来发展的趋势。关键词:RGB-D图像;多层特征;线特征;平面特征;语义特征;特征提取313|726|0更新时间:2024-05-15
摘要:RGB-D图像包含丰富的多层特征,如底层的线特征、平面特征,高层的语义特征,面向RGB-D图像的多层特征提取结果可以作为先验知识提升室内场景重建、SLAM(simultaneous localization and mapping)等多种任务的输出质量,是计算机图形学领域的热点研究内容之一。传统的多层特征提取算法一般利用RGB图像中丰富的颜色、纹理信息以及深度图像中的几何信息提取多层特征,此类提取算法依赖输入RGB-D图像的质量,而受采集过程中环境和人为因素的影响,很难得到高质量的RGB-D图像。随着深度学习技术的快速发展,基于深度学习的多层特征提取算法突破了这一限制,涌现出一批高质量的研究成果。本文对面向RGB-D图像的多层特征提取算法进行综述。首先,汇总了现有的常用于多层特征提取任务的RGB-D数据集和相关算法的质量评价指标。然后,按照特征所处的不同层次,依次对线、平面和语义特征相关算法进行了总结。此外,本文还对各算法的优缺点进行比较并结合常用算法质量评价标准进行了定量分析。最后,讨论了当前多层特征提取算法亟待解决的问题并展望了未来发展的趋势。关键词:RGB-D图像;多层特征;线特征;平面特征;语义特征;特征提取313|726|0更新时间:2024-05-15
综述
-
 摘要:目的现有的跨域重识别任务普遍存在源域与目标域之间的域偏差大和聚类质量差的问题,同时跨域模型过度关注在目标域上的泛化能力将导致对源域知识的永久性遗忘。为了克服以上挑战,提出了一个基于跨域联合学习与共享子空间度量的车辆重识别方法。方法在跨域联合学习中设计了一种交叉置信软聚类来建立源域与目标域之间的域间相关性,并利用软聚类结果产生的监督信息来保留旧知识与泛化新知识。提出了一种显著性感知注意力机制来获取车辆的显著性特征,将原始特征与显著性特征映射到一个共享子空间中并通过它们各自全局与局部之间的杰卡德距离来获取共享度量因子,根据共享度量因子来平滑全局与局部的伪标签,进而促使模型能够学习到更具鉴别力的特征。结果在3个公共车辆重识别数据集VeRi-776(vehicle re-identification-776 dataset)、VehicleID(large-scale vehicle re-identification dataset)和VeRi-Wild(vehicle re-identification dataset in the wild)上与较新方法进行实验对比,以首位命中率(rank-1 accuracy,Rank-1)和平均精度均值(mean average precision,mAP)作为性能评价指标,本文方法在VeRi-776→VeRi-Wild,VeRi-Wild→VeRi-776,VeRi-776→VehicleID,VehicleID→VeRi-776的跨域任务中,分别在目标域中取得了42.40%,41.70%,56.40%,61.90%的Rank-1准确率以及22.50%,23.10%,41.50%,49.10%的mAP准确率。在积累源域的旧知识表现中分别取得了84.60%,84.00%,77.10%,67.00%的Rank-1准确率以及55.80%,44.80%,46.50%,30.70%的mAP准确率。结论相较于无监督域自适应和无监督混合域方法,本文方法能够在积累跨域知识的同时有效缓解域偏差大的问题,进而提升车辆重识别的性能。关键词:车辆重识别;跨域联合学习(CJL);交叉置信软聚类;共享子空间度量(SSM);显著性感知注意力机制;伪标签平滑235|522|0更新时间:2024-05-15
摘要:目的现有的跨域重识别任务普遍存在源域与目标域之间的域偏差大和聚类质量差的问题,同时跨域模型过度关注在目标域上的泛化能力将导致对源域知识的永久性遗忘。为了克服以上挑战,提出了一个基于跨域联合学习与共享子空间度量的车辆重识别方法。方法在跨域联合学习中设计了一种交叉置信软聚类来建立源域与目标域之间的域间相关性,并利用软聚类结果产生的监督信息来保留旧知识与泛化新知识。提出了一种显著性感知注意力机制来获取车辆的显著性特征,将原始特征与显著性特征映射到一个共享子空间中并通过它们各自全局与局部之间的杰卡德距离来获取共享度量因子,根据共享度量因子来平滑全局与局部的伪标签,进而促使模型能够学习到更具鉴别力的特征。结果在3个公共车辆重识别数据集VeRi-776(vehicle re-identification-776 dataset)、VehicleID(large-scale vehicle re-identification dataset)和VeRi-Wild(vehicle re-identification dataset in the wild)上与较新方法进行实验对比,以首位命中率(rank-1 accuracy,Rank-1)和平均精度均值(mean average precision,mAP)作为性能评价指标,本文方法在VeRi-776→VeRi-Wild,VeRi-Wild→VeRi-776,VeRi-776→VehicleID,VehicleID→VeRi-776的跨域任务中,分别在目标域中取得了42.40%,41.70%,56.40%,61.90%的Rank-1准确率以及22.50%,23.10%,41.50%,49.10%的mAP准确率。在积累源域的旧知识表现中分别取得了84.60%,84.00%,77.10%,67.00%的Rank-1准确率以及55.80%,44.80%,46.50%,30.70%的mAP准确率。结论相较于无监督域自适应和无监督混合域方法,本文方法能够在积累跨域知识的同时有效缓解域偏差大的问题,进而提升车辆重识别的性能。关键词:车辆重识别;跨域联合学习(CJL);交叉置信软聚类;共享子空间度量(SSM);显著性感知注意力机制;伪标签平滑235|522|0更新时间:2024-05-15 -
 摘要:目的基于深度学习的端到端场景文本识别任务已经取得了很大的进展。然而受限于多尺度、任意形状以及背景干扰等问题,大多数端到端文本识别器依然会面临掩码提议不完整的问题,进而影响模型的文本识别结果。为了提高掩码预测的准确率,提出了一种基于软注意力的掩码嵌入模块(soft attention mask embedding,SAME),方法利用Transformer更好的全局感受野,将高层特征进行编码并计算软注意力,然后将编码特征与预测掩码层级嵌入,生成更贴近文本边界的掩码来抑制背景噪声。基于SAME强大的文本掩码优化及细粒度文本特征提取能力,进一步提出了一个健壮的文本识别框架SAME-Net,开展无需字符级注释的端到端精准文本识别。具体来说,由于软注意力是可微的,所提出的SAME-Net可以将识别损失传播回检测分支,以通过学习注意力的权重来指导文本检测,使检测分支可以由检测和识别目标联合优化。结果在多个文本识别公开数据集上的实验表明了所提方法的有效性。其中,SAME-Net在任意形状文本数据集Total-Text上实现了84.02%的H-mean,相比于2022年的GLASS(global to local attention for scene-text spotting),在不增加额外训练数据的情况下,全词典的识别准确率提升1.02%。所提方法在多向数据集ICDAR 2015(International Conference on Document Analysis and Recognition)也获得了与同期工作相当的性能,取得83.4%的强词典识别结果。结论提出了一种基于SAME的端到端文本识别方法。该方法利用Transformer的全局感受野生成靠近文本边界的掩码来抑制背景噪声,提出的SAME模块可以将识别损失反向传输到检测模块,并且不需要额外的文本校正模块。通过检测和识别模块的联合优化,可以在没有字符级标注的情况下实现出色的文本定位性能。关键词:自然场景文本检测;自然场景文本识别;软注意力嵌入;深度学习;端到端自然场景文本检测与识别166|670|0更新时间:2024-05-15
摘要:目的基于深度学习的端到端场景文本识别任务已经取得了很大的进展。然而受限于多尺度、任意形状以及背景干扰等问题,大多数端到端文本识别器依然会面临掩码提议不完整的问题,进而影响模型的文本识别结果。为了提高掩码预测的准确率,提出了一种基于软注意力的掩码嵌入模块(soft attention mask embedding,SAME),方法利用Transformer更好的全局感受野,将高层特征进行编码并计算软注意力,然后将编码特征与预测掩码层级嵌入,生成更贴近文本边界的掩码来抑制背景噪声。基于SAME强大的文本掩码优化及细粒度文本特征提取能力,进一步提出了一个健壮的文本识别框架SAME-Net,开展无需字符级注释的端到端精准文本识别。具体来说,由于软注意力是可微的,所提出的SAME-Net可以将识别损失传播回检测分支,以通过学习注意力的权重来指导文本检测,使检测分支可以由检测和识别目标联合优化。结果在多个文本识别公开数据集上的实验表明了所提方法的有效性。其中,SAME-Net在任意形状文本数据集Total-Text上实现了84.02%的H-mean,相比于2022年的GLASS(global to local attention for scene-text spotting),在不增加额外训练数据的情况下,全词典的识别准确率提升1.02%。所提方法在多向数据集ICDAR 2015(International Conference on Document Analysis and Recognition)也获得了与同期工作相当的性能,取得83.4%的强词典识别结果。结论提出了一种基于SAME的端到端文本识别方法。该方法利用Transformer的全局感受野生成靠近文本边界的掩码来抑制背景噪声,提出的SAME模块可以将识别损失反向传输到检测模块,并且不需要额外的文本校正模块。通过检测和识别模块的联合优化,可以在没有字符级标注的情况下实现出色的文本定位性能。关键词:自然场景文本检测;自然场景文本识别;软注意力嵌入;深度学习;端到端自然场景文本检测与识别166|670|0更新时间:2024-05-15 -
 摘要:目的动作识别在工业生产制造中变得越来越重要。但在复杂的生产车间内,动作识别技术会受到环境遮挡、视角变化以及相似动作识别等干扰。基于此,提出一种结合双视图骨架多流网络的装箱行为识别方法。方法将堆叠的差分图像(residual frames, RF)作为模型的输入,结合多视图模块解决人体被遮挡的问题。在视角转换模块中,将差分人体骨架旋转到最佳的虚拟观察角度,并将转换后的骨架数据传入3层堆叠的长短时记忆网络(long short-term memory, LSTM)中,将不同视角下的分类分数进行融合,得到识别结果。为了解决细微动作的识别问题,采用结合注意力机制的局部定位图像卷积网络,传入到卷积神经网络中进行识别。融合骨架和局部图像识别的结果,预测工人的行为动作。结果在实际生产环境下的装箱场景中进行了实验,得到装箱行为识别准确率为92.31%,较大幅度领先于现有的主流行为识别方式。此外,该方法在公共数据集NTU(Nanyang Technological University) RGB+D上进行了评估,结果显示在CS(cross-subject)协议和CV(cross-view)协议中的性能分别达到了85.52%和93.64%,优于其他网络,进一步验证了本文方法的有效性和准确性。结论本文提出了一种人体行为识别方法,能够充分利用多个视图中的人体行为信息,采用骨架网络和卷积神经网络模型相结合的方式,有效提高了行为识别的准确率。关键词:动作识别;长短时记忆网络(LSTM);双视图;自适应视图转换;注意力机制207|355|0更新时间:2024-05-15
摘要:目的动作识别在工业生产制造中变得越来越重要。但在复杂的生产车间内,动作识别技术会受到环境遮挡、视角变化以及相似动作识别等干扰。基于此,提出一种结合双视图骨架多流网络的装箱行为识别方法。方法将堆叠的差分图像(residual frames, RF)作为模型的输入,结合多视图模块解决人体被遮挡的问题。在视角转换模块中,将差分人体骨架旋转到最佳的虚拟观察角度,并将转换后的骨架数据传入3层堆叠的长短时记忆网络(long short-term memory, LSTM)中,将不同视角下的分类分数进行融合,得到识别结果。为了解决细微动作的识别问题,采用结合注意力机制的局部定位图像卷积网络,传入到卷积神经网络中进行识别。融合骨架和局部图像识别的结果,预测工人的行为动作。结果在实际生产环境下的装箱场景中进行了实验,得到装箱行为识别准确率为92.31%,较大幅度领先于现有的主流行为识别方式。此外,该方法在公共数据集NTU(Nanyang Technological University) RGB+D上进行了评估,结果显示在CS(cross-subject)协议和CV(cross-view)协议中的性能分别达到了85.52%和93.64%,优于其他网络,进一步验证了本文方法的有效性和准确性。结论本文提出了一种人体行为识别方法,能够充分利用多个视图中的人体行为信息,采用骨架网络和卷积神经网络模型相结合的方式,有效提高了行为识别的准确率。关键词:动作识别;长短时记忆网络(LSTM);双视图;自适应视图转换;注意力机制207|355|0更新时间:2024-05-15 -
 摘要:目的为了更好地实现轻量化的人体姿态估计,在轻量级模型极为有限的资源下实现更高的检测性能。基于高分辨率网络(high resolution network,HRNet)提出了结合密集连接网络的轻量级高分辨率人体姿态估计网络(lightweight high-resolution human estimation combined with densely connected network,LDHNet)。方法通过重新设计HRNet中的阶段分支结构以及提出新的轻量级特征提取模块,构建了轻量高效的特征提取单元,同时对多分支之间特征融合部分进行了轻量化改进,进一步降低模型的复杂度,最终大幅降低了模型的参数量与计算量,实现了轻量化的设计目标,并且保证了模型的性能。结果实验表明,在MPII(Max Planck Institute for Informatics)测试集上相比于自顶向下的轻量级人体姿态估计模型LiteHRNet,LDHNet仅通过增加少量参数量与计算量,平均预测准确度即提升了1.5%,与LiteHRNet的改进型DiteHRNet相比也提升了0.9%,在COCO(common objects in context)验证集上的结果表明,与LiteHRNet相比,LDHNet的平均检测准确度提升了3.4%,与DiteHRNet相比也提升了2.3%,与融合Transformer的HRFormer相比,LDHNet在参数量和计算量都更低的条件下有近似的检测性能,在面对实际场景时LDHNet也有着稳定的表现,在同样的环境下LDHNet的推理速度要高于基线HRNet以及LiteHRNet等。结论该模型有效实现了轻量化并保证了预测性能。关键词:人体姿态估计;轻量级网络;密集连接网络;高分辨率网络;多分支结构247|564|0更新时间:2024-05-15
摘要:目的为了更好地实现轻量化的人体姿态估计,在轻量级模型极为有限的资源下实现更高的检测性能。基于高分辨率网络(high resolution network,HRNet)提出了结合密集连接网络的轻量级高分辨率人体姿态估计网络(lightweight high-resolution human estimation combined with densely connected network,LDHNet)。方法通过重新设计HRNet中的阶段分支结构以及提出新的轻量级特征提取模块,构建了轻量高效的特征提取单元,同时对多分支之间特征融合部分进行了轻量化改进,进一步降低模型的复杂度,最终大幅降低了模型的参数量与计算量,实现了轻量化的设计目标,并且保证了模型的性能。结果实验表明,在MPII(Max Planck Institute for Informatics)测试集上相比于自顶向下的轻量级人体姿态估计模型LiteHRNet,LDHNet仅通过增加少量参数量与计算量,平均预测准确度即提升了1.5%,与LiteHRNet的改进型DiteHRNet相比也提升了0.9%,在COCO(common objects in context)验证集上的结果表明,与LiteHRNet相比,LDHNet的平均检测准确度提升了3.4%,与DiteHRNet相比也提升了2.3%,与融合Transformer的HRFormer相比,LDHNet在参数量和计算量都更低的条件下有近似的检测性能,在面对实际场景时LDHNet也有着稳定的表现,在同样的环境下LDHNet的推理速度要高于基线HRNet以及LiteHRNet等。结论该模型有效实现了轻量化并保证了预测性能。关键词:人体姿态估计;轻量级网络;密集连接网络;高分辨率网络;多分支结构247|564|0更新时间:2024-05-15 -
 摘要:目的在动态手势序列特征提取时,忽略了不同动态手势手指间的相关性,是造成手势识别率不高的重要原因。针对此问题,提出了时空位置编码和掩码的方法进行手势识别,是首次对手部关节点进行空间二维位置编码。方法首先,根据手部关节序列构造时空图,利用关节点平面坐标生成空间二维编码,并与时间轴的一维编码器融合,生成关节点的时空位置编码,可以有效处理空间上的异常姿态同时避免时间上的乱序问题;然后,将时空图按照人体手部生物结构进行分块,通过空间自注意力和空间掩码,获取手指与手指之间的潜在信息。采用时间维度扩张的策略,通过时间自注意力和时间掩码,捕获长时间手指序列动态演变信息。结果在DHG-14/28(dynamic hand gesture 14/28)数据集上,该算法比HPEV(hand posture evolution volume)算法平均识别率高出4.47%,比MS-ISTGCN (multi-stream improved spatio-temporal graph convolutional network)算法平均识别率高出2.71%;在SHREC’17 track数据集上,该算法比HPEV算法平均识别率高出0.47%,利用消融实验证明了本文策略的合理性。结论通过大量实验评估,验证了基于分块和时空位置编码构造出来的模型很好地解决了上述问题,提高了手势识别率。关键词:手势识别;自注意力;空间二维位置编码;时空掩码;手部分块189|523|0更新时间:2024-05-15
摘要:目的在动态手势序列特征提取时,忽略了不同动态手势手指间的相关性,是造成手势识别率不高的重要原因。针对此问题,提出了时空位置编码和掩码的方法进行手势识别,是首次对手部关节点进行空间二维位置编码。方法首先,根据手部关节序列构造时空图,利用关节点平面坐标生成空间二维编码,并与时间轴的一维编码器融合,生成关节点的时空位置编码,可以有效处理空间上的异常姿态同时避免时间上的乱序问题;然后,将时空图按照人体手部生物结构进行分块,通过空间自注意力和空间掩码,获取手指与手指之间的潜在信息。采用时间维度扩张的策略,通过时间自注意力和时间掩码,捕获长时间手指序列动态演变信息。结果在DHG-14/28(dynamic hand gesture 14/28)数据集上,该算法比HPEV(hand posture evolution volume)算法平均识别率高出4.47%,比MS-ISTGCN (multi-stream improved spatio-temporal graph convolutional network)算法平均识别率高出2.71%;在SHREC’17 track数据集上,该算法比HPEV算法平均识别率高出0.47%,利用消融实验证明了本文策略的合理性。结论通过大量实验评估,验证了基于分块和时空位置编码构造出来的模型很好地解决了上述问题,提高了手势识别率。关键词:手势识别;自注意力;空间二维位置编码;时空掩码;手部分块189|523|0更新时间:2024-05-15
图像分析和识别
-
 摘要:目的针对现有动态三维数字人体模型生成时不能改变体型、运动固定单一等问题,提出一种融合变分自编码器(variational auto-encoder, VAE)网络、对比语言—图像预训练(contrastive language-image pretraining,CLIP)网络与门控循环单元(gate recurrent unit,GRU)网络生成运动三维人体模型的方法。该方法可根据文本描述生成相应体型和动作的三维人体模型。方法首先,使用VAE编码网络生成潜在编码,结合CLIP网络零样本生成体型与文本表述相符的人体模型,以解决蒙皮多人线性(skinned multi-person linear, SMPL)模型参数不合理而生成不符合正常体型特征的人体模型问题;其次,采用VAE网络与GRU网络生成与文本表述相符的变长时间三维人体姿势序列,以解决现有运动生成方法仅生成事先指定的姿势序列、无法生成运动时间不同的姿势序列问题;最后,将体型特征与运动特征结合,得到三维运动人体模型。结果在HumanML3D数据集上进行人体生成实验,并与其他3种方法进行比较,相比于现有最好方法,R精度的Top1、Top2和Top3分别提高了0.031、0.034和0.028,弗雷歇初始距离(Fréchet inception distance,FID)提高了0.094,多样性提高了0.065。消融实验验证了模型的有效性,结果表明本文方法对人体模型生成效果有提升。结论本文方法可通过文本描述生成运动三维人体模型,模型的体型和动作更符合输入文本的描述。关键词:人体动作合成;自然语言处理(NLP);深度学习;蒙皮多人线性模型;变分自编码器网络238|534|1更新时间:2024-05-15
摘要:目的针对现有动态三维数字人体模型生成时不能改变体型、运动固定单一等问题,提出一种融合变分自编码器(variational auto-encoder, VAE)网络、对比语言—图像预训练(contrastive language-image pretraining,CLIP)网络与门控循环单元(gate recurrent unit,GRU)网络生成运动三维人体模型的方法。该方法可根据文本描述生成相应体型和动作的三维人体模型。方法首先,使用VAE编码网络生成潜在编码,结合CLIP网络零样本生成体型与文本表述相符的人体模型,以解决蒙皮多人线性(skinned multi-person linear, SMPL)模型参数不合理而生成不符合正常体型特征的人体模型问题;其次,采用VAE网络与GRU网络生成与文本表述相符的变长时间三维人体姿势序列,以解决现有运动生成方法仅生成事先指定的姿势序列、无法生成运动时间不同的姿势序列问题;最后,将体型特征与运动特征结合,得到三维运动人体模型。结果在HumanML3D数据集上进行人体生成实验,并与其他3种方法进行比较,相比于现有最好方法,R精度的Top1、Top2和Top3分别提高了0.031、0.034和0.028,弗雷歇初始距离(Fréchet inception distance,FID)提高了0.094,多样性提高了0.065。消融实验验证了模型的有效性,结果表明本文方法对人体模型生成效果有提升。结论本文方法可通过文本描述生成运动三维人体模型,模型的体型和动作更符合输入文本的描述。关键词:人体动作合成;自然语言处理(NLP);深度学习;蒙皮多人线性模型;变分自编码器网络238|534|1更新时间:2024-05-15 -
 摘要:目的微表情是人在外界信息和刺激下做出的无意识面部动作,是判断受试人情绪和行为的重要佐证,在社会安全、商业谈判和心理辅导等领域都有着广泛的应用。微表情不同于一般的表情,分类与定位较为困难。针对这种情况,提出了一种基于光流窗口的双分支微表情定位网络(dual-branch optical flow spotting network,DFSN)和一种利用峰值帧光流信息的微表情分类网络,以识别视频中的微表情。方法在定位任务中,首先提取面部图像,选择光流窗口大小和位置,计算面部光流并进行预处理;接下来输入双分支网络中进行两次分类,分别针对有无微表情和在有微表情前提下微表情所处阶段分类,并结合两个损失函数抑制过拟合;最后绘制出微表情强度曲线,曲线峰值所处位置即为所求微表情峰值帧。在分类任务中,选取视频起始帧和定位网络取得的峰值帧作为光流窗口,并利用欧拉运动放大算法(Eulerian motion magnification,EMM)放大微表情,最后采用峰值帧光流信息分类微表情视频。结果微表情定位网络分别在CASME II(Chinese Academy of Sciences Micro-expression Database II)数据集和CASME数据集上按照使用留一被试交叉验证法进行了实验,与目前最好的定位方法比较,此网络在CASME II上获得了最低的NMAE(normalized mean absolute error)值0.101 7,比Optical flow + UPC方法提高了9%。在CASME上获得的NMAE值为0.137 8,在此数据集上为次优定位方法。在定位网络得到的峰值基础上,分类网络在CASME II上取得了89.79%的准确率,在CASME上取得了66.06%的准确率。若采用数据集标注的峰值,分类网络在CASME II上取得了91.83%的准确率,在CASME上取得了76.96%的准确率。结论提出的微表情定位网络可以有效定位视频中微表情峰值帧的位置,帮助后续网络进行分类,微表情分类网络可以有效区分不同种类的微表情视频。关键词:微表情定位;情感计算;峰值帧;微表情分类;图像识别;深度学习212|863|1更新时间:2024-05-15
摘要:目的微表情是人在外界信息和刺激下做出的无意识面部动作,是判断受试人情绪和行为的重要佐证,在社会安全、商业谈判和心理辅导等领域都有着广泛的应用。微表情不同于一般的表情,分类与定位较为困难。针对这种情况,提出了一种基于光流窗口的双分支微表情定位网络(dual-branch optical flow spotting network,DFSN)和一种利用峰值帧光流信息的微表情分类网络,以识别视频中的微表情。方法在定位任务中,首先提取面部图像,选择光流窗口大小和位置,计算面部光流并进行预处理;接下来输入双分支网络中进行两次分类,分别针对有无微表情和在有微表情前提下微表情所处阶段分类,并结合两个损失函数抑制过拟合;最后绘制出微表情强度曲线,曲线峰值所处位置即为所求微表情峰值帧。在分类任务中,选取视频起始帧和定位网络取得的峰值帧作为光流窗口,并利用欧拉运动放大算法(Eulerian motion magnification,EMM)放大微表情,最后采用峰值帧光流信息分类微表情视频。结果微表情定位网络分别在CASME II(Chinese Academy of Sciences Micro-expression Database II)数据集和CASME数据集上按照使用留一被试交叉验证法进行了实验,与目前最好的定位方法比较,此网络在CASME II上获得了最低的NMAE(normalized mean absolute error)值0.101 7,比Optical flow + UPC方法提高了9%。在CASME上获得的NMAE值为0.137 8,在此数据集上为次优定位方法。在定位网络得到的峰值基础上,分类网络在CASME II上取得了89.79%的准确率,在CASME上取得了66.06%的准确率。若采用数据集标注的峰值,分类网络在CASME II上取得了91.83%的准确率,在CASME上取得了76.96%的准确率。结论提出的微表情定位网络可以有效定位视频中微表情峰值帧的位置,帮助后续网络进行分类,微表情分类网络可以有效区分不同种类的微表情视频。关键词:微表情定位;情感计算;峰值帧;微表情分类;图像识别;深度学习212|863|1更新时间:2024-05-15
图像理解和计算机视觉
-
 摘要:目的随着遥感观测技术的飞速发展,遥感影像的分辨率越来越高,如何从高分遥感影像中有效提取具有鉴别性的特征进行地物变化检测成为一个具有挑战性的问题。卷积神经网络广泛应用于计算机视觉领域,但面向遥感影像变化检测时仍存在图像语义或位置信息的丢失及网络参数量过大等缺陷,导致检测性能受限。为此,提出一种新型GUNet++(Ghost-UNet++)网络,用于遥感影像的精准变化检测。方法首先,为了提取双时相遥感影像更具判别性的深度特征,设计具有多分支架构的高分辨率网络HRNet替换传统UNet++的主干网;其次,采用UNet++解码结构进行差异判别时,引入鬼影(Ghost)模块代替传统卷积模块以降低网络参量,并设计密集跳跃连接进一步加强信息传输,以减少深层位置信息的丢失;最后,设计一个集成注意力模块,将网络的多个语义层次特征进行聚合和细化,抑制语义和位置信息的丢失,进一步增强特征表征能力用于最终的精准变化检测。结果在LEVIR-CD(LEVIR change detection data set)和Google Data Set两个公开数据集上进行实验,结果表明本文算法变化检测精度高达99.62%和99.16%,且网络参数量仅为1.93 M,与现有主流变化检测方法相比优势明显。结论提出方法综合考虑了遥感图像中语义和位置信息对变化检测性能的影响,具有良好的特征抽取和表征能力,因此变化检测的精度和效率比现有同类方法更高。关键词:高分辨率遥感影像;变化检测;深度学习(DL);鬼影模块;集成注意力277|1002|1更新时间:2024-05-15
摘要:目的随着遥感观测技术的飞速发展,遥感影像的分辨率越来越高,如何从高分遥感影像中有效提取具有鉴别性的特征进行地物变化检测成为一个具有挑战性的问题。卷积神经网络广泛应用于计算机视觉领域,但面向遥感影像变化检测时仍存在图像语义或位置信息的丢失及网络参数量过大等缺陷,导致检测性能受限。为此,提出一种新型GUNet++(Ghost-UNet++)网络,用于遥感影像的精准变化检测。方法首先,为了提取双时相遥感影像更具判别性的深度特征,设计具有多分支架构的高分辨率网络HRNet替换传统UNet++的主干网;其次,采用UNet++解码结构进行差异判别时,引入鬼影(Ghost)模块代替传统卷积模块以降低网络参量,并设计密集跳跃连接进一步加强信息传输,以减少深层位置信息的丢失;最后,设计一个集成注意力模块,将网络的多个语义层次特征进行聚合和细化,抑制语义和位置信息的丢失,进一步增强特征表征能力用于最终的精准变化检测。结果在LEVIR-CD(LEVIR change detection data set)和Google Data Set两个公开数据集上进行实验,结果表明本文算法变化检测精度高达99.62%和99.16%,且网络参数量仅为1.93 M,与现有主流变化检测方法相比优势明显。结论提出方法综合考虑了遥感图像中语义和位置信息对变化检测性能的影响,具有良好的特征抽取和表征能力,因此变化检测的精度和效率比现有同类方法更高。关键词:高分辨率遥感影像;变化检测;深度学习(DL);鬼影模块;集成注意力277|1002|1更新时间:2024-05-15
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0