
最新刊期
2024 年 第 29 卷 第 4 期
-
-
 摘要:图像模糊是指在图像捕捉或传输过程中,由于镜头或相机运动、光照条件等因素导致图像失去清晰度和细节,从而影响图像的质量和可用性。为了消除这种影响,图像去模糊技术应运而生。其目的在于通过构建计算机数学模型来衡量图像的模糊信息,从而自动预测去模糊后的清晰图像。图像去模糊算法的研究发展不仅为计算机视觉领域的其他任务提供了便利,同时也为生活领域提供了便捷和保障,如安全监控等。1)回顾了整个图像去模糊领域的发展历程,对盲图像去模糊和非盲图像去模糊中具有影响力的算法进行论述和分析。2)讨论了图像模糊的常见原因以及去模糊图像的质量评价方法。3)全面阐述了传统方法和基于深度学习方法的基本思想,并针对图像非盲去模糊和图像盲去模糊两方面的一些文献进行了综述。其中,基于深度学习的方法包括基于卷积神经网络、基于循环神经网络、基于生成式对抗网络和基于Transformer的方法等。4)简要介绍了图像去模糊领域的常用数据集并比较分析了一些代表性图像去模糊算法的性能。5)探讨了图像去模糊领域所面临的挑战,并对未来的研究方法进行了展望。关键词:图像去模糊;卷积神经网络(CNN);循环神经网络(RNN);生成式对抗网络(GAN);Transformer;深度学习1057|2038|1更新时间:2024-04-12
摘要:图像模糊是指在图像捕捉或传输过程中,由于镜头或相机运动、光照条件等因素导致图像失去清晰度和细节,从而影响图像的质量和可用性。为了消除这种影响,图像去模糊技术应运而生。其目的在于通过构建计算机数学模型来衡量图像的模糊信息,从而自动预测去模糊后的清晰图像。图像去模糊算法的研究发展不仅为计算机视觉领域的其他任务提供了便利,同时也为生活领域提供了便捷和保障,如安全监控等。1)回顾了整个图像去模糊领域的发展历程,对盲图像去模糊和非盲图像去模糊中具有影响力的算法进行论述和分析。2)讨论了图像模糊的常见原因以及去模糊图像的质量评价方法。3)全面阐述了传统方法和基于深度学习方法的基本思想,并针对图像非盲去模糊和图像盲去模糊两方面的一些文献进行了综述。其中,基于深度学习的方法包括基于卷积神经网络、基于循环神经网络、基于生成式对抗网络和基于Transformer的方法等。4)简要介绍了图像去模糊领域的常用数据集并比较分析了一些代表性图像去模糊算法的性能。5)探讨了图像去模糊领域所面临的挑战,并对未来的研究方法进行了展望。关键词:图像去模糊;卷积神经网络(CNN);循环神经网络(RNN);生成式对抗网络(GAN);Transformer;深度学习1057|2038|1更新时间:2024-04-12 -
 摘要:目的现有的低照度图像增强算法常存在局部区域欠增强、过增强及色彩偏差等情况,且对于极低照度图像增强,伴随着噪声放大及细节信息丢失等问题。对此,提出了一种基于照度与场景纹理注意力图的低光图像增强算法。方法首先,为了降低色彩偏差对注意力图估计模块的影响,对低光照图像进行了色彩均衡处理;其次,试图利用低照度图像最小通道约束图对正常曝光图像的照度和纹理进行注意力图估计,为后续增强模块提供信息引导;然后,设计全局与局部相结合的增强模块,用获取的照度和场景纹理注意力估计图引导图像亮度提升和噪声抑制,并将得到的全局增强结果划分成图像块进行局部优化,提升增强性能,有效避免了局部欠增强和过增强的问题。结果将本文算法与2种传统方法和4种深度学习算法比较,主观视觉和客观指标均表明本文增强结果在亮度、对比度以及噪声抑制等方面取得了优异的性能。在VV(Vasileios Vonikakis)数据集上,本文方法的BTMQI(blind tone-mapped quality index)和NIQMC(no-reference image quality metric for contrast distortion)指标均达到最优值;在178幅普通低照度图像上本文算法的BTMQI和NIQMC均取得次优值,但纹理突出和噪声抑制优势显著。结论大量定性及定量的实验结果表明,本文方法能有效提升图像亮度和对比度,且在突出暗区纹理时,能有效抑制噪声。本文方法用于极低照度图像时,在色彩还原、细节纹理恢复和噪声抑制方面均具有明显优势。代码已共享在Github上:https://github.com/shuanglidu/LLIE_CEIST.git。关键词:低照度图像增强;注意力机制;U-Net网络;照度估计;最小通道约束图509|1883|3更新时间:2024-04-12
摘要:目的现有的低照度图像增强算法常存在局部区域欠增强、过增强及色彩偏差等情况,且对于极低照度图像增强,伴随着噪声放大及细节信息丢失等问题。对此,提出了一种基于照度与场景纹理注意力图的低光图像增强算法。方法首先,为了降低色彩偏差对注意力图估计模块的影响,对低光照图像进行了色彩均衡处理;其次,试图利用低照度图像最小通道约束图对正常曝光图像的照度和纹理进行注意力图估计,为后续增强模块提供信息引导;然后,设计全局与局部相结合的增强模块,用获取的照度和场景纹理注意力估计图引导图像亮度提升和噪声抑制,并将得到的全局增强结果划分成图像块进行局部优化,提升增强性能,有效避免了局部欠增强和过增强的问题。结果将本文算法与2种传统方法和4种深度学习算法比较,主观视觉和客观指标均表明本文增强结果在亮度、对比度以及噪声抑制等方面取得了优异的性能。在VV(Vasileios Vonikakis)数据集上,本文方法的BTMQI(blind tone-mapped quality index)和NIQMC(no-reference image quality metric for contrast distortion)指标均达到最优值;在178幅普通低照度图像上本文算法的BTMQI和NIQMC均取得次优值,但纹理突出和噪声抑制优势显著。结论大量定性及定量的实验结果表明,本文方法能有效提升图像亮度和对比度,且在突出暗区纹理时,能有效抑制噪声。本文方法用于极低照度图像时,在色彩还原、细节纹理恢复和噪声抑制方面均具有明显优势。代码已共享在Github上:https://github.com/shuanglidu/LLIE_CEIST.git。关键词:低照度图像增强;注意力机制;U-Net网络;照度估计;最小通道约束图509|1883|3更新时间:2024-04-12 -
 摘要:目的图像超分辨率重建的目的是将低分辨率图像复原出具有更丰富细节信息的高分辨率图像。近年来,基于Transformer的深度神经网络在图像超分辨率重建领域取得了令人瞩目的性能,然而,这些网络往往参数量巨大、计算成本较高。针对该问题,设计了一种轻量级图像超分辨率重建网络。方法提出了一种轻量级图像超分辨率的蓝图可分离卷积Transformer网络(blueprint separable convolution Transformer network,BSTN)。基于蓝图可分离卷积(blueprint separable convolution,BSConv)设计了蓝图前馈神经网络和蓝图多头自注意力模块。然后设计了移动通道注意力模块(shift channel attention block,SCAB)对通道重点信息进行加强,包括移动卷积、对比度感知通道注意力和蓝图前馈神经网络。最后设计了蓝图多头自注意力模块(blueprint multi-head self-attention block,BMSAB),通过蓝图多头自注意力与蓝图前馈神经网络以较低的计算量实现了自注意力过程。结果本文方法在4个数据集上与10种先进的轻量级超分辨率方法进行比较。客观上,本文方法在不同数据集上取得了不同程度的领先,并且参数量和浮点运算量都处于较低水平。当放大倍数分别为2、3和4时,在Set5数据集上相比SOTA(state-of-the-art)方法,峰值信噪比(peak signal to noise ratio,PSNR)分别提升了0.11 dB、0.16 dB和0.17 dB。主观上,本文方法重建图像清晰,模糊区域小,具有丰富的细节。结论本文所提出的蓝图可分离卷积Transformer网络BSTN以较少的参数量和浮点运算量达到了先进水平,能获得高质量的超分辨率重建结果。关键词:图像超分辨率;轻量级模型;Transformer;深度学习;注意力机制443|680|0更新时间:2024-04-12
摘要:目的图像超分辨率重建的目的是将低分辨率图像复原出具有更丰富细节信息的高分辨率图像。近年来,基于Transformer的深度神经网络在图像超分辨率重建领域取得了令人瞩目的性能,然而,这些网络往往参数量巨大、计算成本较高。针对该问题,设计了一种轻量级图像超分辨率重建网络。方法提出了一种轻量级图像超分辨率的蓝图可分离卷积Transformer网络(blueprint separable convolution Transformer network,BSTN)。基于蓝图可分离卷积(blueprint separable convolution,BSConv)设计了蓝图前馈神经网络和蓝图多头自注意力模块。然后设计了移动通道注意力模块(shift channel attention block,SCAB)对通道重点信息进行加强,包括移动卷积、对比度感知通道注意力和蓝图前馈神经网络。最后设计了蓝图多头自注意力模块(blueprint multi-head self-attention block,BMSAB),通过蓝图多头自注意力与蓝图前馈神经网络以较低的计算量实现了自注意力过程。结果本文方法在4个数据集上与10种先进的轻量级超分辨率方法进行比较。客观上,本文方法在不同数据集上取得了不同程度的领先,并且参数量和浮点运算量都处于较低水平。当放大倍数分别为2、3和4时,在Set5数据集上相比SOTA(state-of-the-art)方法,峰值信噪比(peak signal to noise ratio,PSNR)分别提升了0.11 dB、0.16 dB和0.17 dB。主观上,本文方法重建图像清晰,模糊区域小,具有丰富的细节。结论本文所提出的蓝图可分离卷积Transformer网络BSTN以较少的参数量和浮点运算量达到了先进水平,能获得高质量的超分辨率重建结果。关键词:图像超分辨率;轻量级模型;Transformer;深度学习;注意力机制443|680|0更新时间:2024-04-12 -
 摘要:目的卷积神经网络(convolutional neural network, CNN)和自注意力(self-attention, SA)在多媒体应用领域已经取得了巨大的成功。然而,鲜有研究人员能够在图像修复任务中有效地协调这两种架构。针对这两种架构各自的优缺点,提出了一种关联学习的方式以综合利用两种方法的优点并抑制各自的不足,实现高质高效的图像修复。方法本文结合CNN和SA两种架构的优势,尤其是在特定的局部上下文和全局结构表示中充分利用CNN的局部感知和平移不变性,以及SA的全局聚合能力。此外,图像的降质分布揭示了图像空间中退化的位置和程度。受此启发,本文在背景修复中引入退化先验,并据此提出一种动态关联学习的图像修复方法。核心是一个新的多输入注意力模块,将降质扰动的消除和背景修复关联起来。通过结合深度可分离卷积,利用CNN和SA两种架构的优势实现高效率和高质量图像修复。结果在Test1200数据集中进行了消融实验以验证算法各个部分的有效性,实验结果证明CNN和SA的融合可以有效提升模型的表达能力;同时,降质扰动的消除和背景修复关联学习可以有效提升整体的修复效果。本文方法在3个图像修复任务的合成和真实数据上与其他10余种方法进行了比较,提出的方法取得了显著的提升。在图像去雨任务上,本文提出的ELF(image deeraining meets association learning and Transformer)方法在合成数据集Test1200上,相比于MPRNet(multi-stage progressive image restoration network),PSNR(peak signal-to-noise ratio)值提高了0.9 dB;在水下图像增强任务上,ELF在R90数据集上超过Ucolor方法4.15 dB;在低照度图像增强任务上,相对于LLFlow(flow-based low-light image enhancement)算法,ELF获得了1.09 dB的提升。结论本文方法在效果和性能上具有优势,在常见的图像去雨、低照度图像增强和水下图像修复等任务上优于代表性的方法。关键词:图像修复;关联学习;自注意力(SA);图像去雨;低照度图像增强;水下图像修复302|802|0更新时间:2024-04-12
摘要:目的卷积神经网络(convolutional neural network, CNN)和自注意力(self-attention, SA)在多媒体应用领域已经取得了巨大的成功。然而,鲜有研究人员能够在图像修复任务中有效地协调这两种架构。针对这两种架构各自的优缺点,提出了一种关联学习的方式以综合利用两种方法的优点并抑制各自的不足,实现高质高效的图像修复。方法本文结合CNN和SA两种架构的优势,尤其是在特定的局部上下文和全局结构表示中充分利用CNN的局部感知和平移不变性,以及SA的全局聚合能力。此外,图像的降质分布揭示了图像空间中退化的位置和程度。受此启发,本文在背景修复中引入退化先验,并据此提出一种动态关联学习的图像修复方法。核心是一个新的多输入注意力模块,将降质扰动的消除和背景修复关联起来。通过结合深度可分离卷积,利用CNN和SA两种架构的优势实现高效率和高质量图像修复。结果在Test1200数据集中进行了消融实验以验证算法各个部分的有效性,实验结果证明CNN和SA的融合可以有效提升模型的表达能力;同时,降质扰动的消除和背景修复关联学习可以有效提升整体的修复效果。本文方法在3个图像修复任务的合成和真实数据上与其他10余种方法进行了比较,提出的方法取得了显著的提升。在图像去雨任务上,本文提出的ELF(image deeraining meets association learning and Transformer)方法在合成数据集Test1200上,相比于MPRNet(multi-stage progressive image restoration network),PSNR(peak signal-to-noise ratio)值提高了0.9 dB;在水下图像增强任务上,ELF在R90数据集上超过Ucolor方法4.15 dB;在低照度图像增强任务上,相对于LLFlow(flow-based low-light image enhancement)算法,ELF获得了1.09 dB的提升。结论本文方法在效果和性能上具有优势,在常见的图像去雨、低照度图像增强和水下图像修复等任务上优于代表性的方法。关键词:图像修复;关联学习;自注意力(SA);图像去雨;低照度图像增强;水下图像修复302|802|0更新时间:2024-04-12 -
 摘要:目的超分辨率(super resolution,SR)重建任务通过划分窗口引入自注意力机制进行特征提取,获得了令人瞩目的成绩。针对划分窗口应用自注意力机制时会限制图像信息聚合范围、制约模型对特征信息进行建模的问题,本文基于转置自注意力机制构建全局和局部信息建模网络捕捉图像像素依赖关系。方法首先采用轻量的基线模型对特征进行简单关系建模,然后将空间维度上的自注意力机制转换到通道维度,通过计算交叉协方差矩阵构建各像素点之间的长距离依赖关系,接着通过引入通道注意力块补充图像重建所需的局部信息,最后构建双门控机制控制信息在模型中的流动,提高模型对特征的建模能力及其鲁棒性。结果实验在5个基准数据集Set5、Set14、BSD100、Urban100、Manga109上与主流方法进行了比较,在不同比例因子的SR任务中均获得了最佳或者次佳的结果。与SwinIR(image restoration using swin Transformer)在×2倍SR任务中相比,在以上5个数据集上的峰值信噪比分别提升了0.03 dB、0.21 dB、0.05 dB、0.29 dB和0.10 dB,结构相似度也获得了极大提升,同时视觉感知优化十分明显。结论所提出的网络模型能够更充分地对特征信息全局关系进行建模,同时也不会丢失图像特有的局部相关性。重建图像质量明显提高,细节更加丰富,充分说明了本文方法的有效性与先进性。关键词:图像超分辨率重建;自注意力机制;深度学习;图像复原;门控网络508|403|1更新时间:2024-04-12
摘要:目的超分辨率(super resolution,SR)重建任务通过划分窗口引入自注意力机制进行特征提取,获得了令人瞩目的成绩。针对划分窗口应用自注意力机制时会限制图像信息聚合范围、制约模型对特征信息进行建模的问题,本文基于转置自注意力机制构建全局和局部信息建模网络捕捉图像像素依赖关系。方法首先采用轻量的基线模型对特征进行简单关系建模,然后将空间维度上的自注意力机制转换到通道维度,通过计算交叉协方差矩阵构建各像素点之间的长距离依赖关系,接着通过引入通道注意力块补充图像重建所需的局部信息,最后构建双门控机制控制信息在模型中的流动,提高模型对特征的建模能力及其鲁棒性。结果实验在5个基准数据集Set5、Set14、BSD100、Urban100、Manga109上与主流方法进行了比较,在不同比例因子的SR任务中均获得了最佳或者次佳的结果。与SwinIR(image restoration using swin Transformer)在×2倍SR任务中相比,在以上5个数据集上的峰值信噪比分别提升了0.03 dB、0.21 dB、0.05 dB、0.29 dB和0.10 dB,结构相似度也获得了极大提升,同时视觉感知优化十分明显。结论所提出的网络模型能够更充分地对特征信息全局关系进行建模,同时也不会丢失图像特有的局部相关性。重建图像质量明显提高,细节更加丰富,充分说明了本文方法的有效性与先进性。关键词:图像超分辨率重建;自注意力机制;深度学习;图像复原;门控网络508|403|1更新时间:2024-04-12 -
 摘要:目的各类终端设备获取的大量数据往往由于信息丢失而导致数据不完整,或经常受到降质问题的困扰。为有效恢复缺损或降质数据,低秩张量补全备受关注。张量分解可有效挖掘张量数据的内在特征,但传统分解方法诱导的张量秩函数无法探索张量不同模式之间的相关性;另外,传统张量补全方法通常将全变分约束施加于整体张量数据,无法充分利用张量低维子空间的平滑先验。为解决以上两个问题,提出了基于稀疏先验与多模式张量分解的低秩张量恢复方法。方法在张量秩最小化模型基础上,融入多模式张量分解技术以及分解因子局部稀疏性。首先对原始张量施加核范数约束,以此捕获张量的全局低秩性,然后,利用多模式张量分解将整体张量沿着每个模式分解为一组低维张量和一组因子矩阵,以探索不同模式之间的相关性,对因子矩阵施加因子梯度稀疏正则化约束,探索张量子空间的局部稀疏性,进一步提高张量恢复性能。结果在高光谱图像、多光谱图像、YUV(也称为YCbCr)视频和医学影像数据上,将本文方法与其他8种修复方法在3种丢失率下进行定量及定性比较。在恢复4种类型张量数据方面,本文方法与深度学习GP-WLRR方法(global prior refined weighted low-rank representation)的修复效果基本持平, 本文方法的MPSNR(mean peak signal-to-noise ratio)在所有丢失率及张量数据上的总体平均高0.68 dB,MSSIM(mean structural similarity)总体平均高0.01;与其他6种张量建模方法相比,本文方法的MPSNR及MSSIM均取得最优结果。结论提出的基于稀疏先验与多模式张量分解的低秩张量恢复方法,可同时利用张量的全局低秩性与局部稀疏性,能够对受损的多维视觉数据进行有效修复。关键词:多模式张量分解;稀疏先验;因子梯度稀疏性;低秩张量恢复249|639|0更新时间:2024-04-12
摘要:目的各类终端设备获取的大量数据往往由于信息丢失而导致数据不完整,或经常受到降质问题的困扰。为有效恢复缺损或降质数据,低秩张量补全备受关注。张量分解可有效挖掘张量数据的内在特征,但传统分解方法诱导的张量秩函数无法探索张量不同模式之间的相关性;另外,传统张量补全方法通常将全变分约束施加于整体张量数据,无法充分利用张量低维子空间的平滑先验。为解决以上两个问题,提出了基于稀疏先验与多模式张量分解的低秩张量恢复方法。方法在张量秩最小化模型基础上,融入多模式张量分解技术以及分解因子局部稀疏性。首先对原始张量施加核范数约束,以此捕获张量的全局低秩性,然后,利用多模式张量分解将整体张量沿着每个模式分解为一组低维张量和一组因子矩阵,以探索不同模式之间的相关性,对因子矩阵施加因子梯度稀疏正则化约束,探索张量子空间的局部稀疏性,进一步提高张量恢复性能。结果在高光谱图像、多光谱图像、YUV(也称为YCbCr)视频和医学影像数据上,将本文方法与其他8种修复方法在3种丢失率下进行定量及定性比较。在恢复4种类型张量数据方面,本文方法与深度学习GP-WLRR方法(global prior refined weighted low-rank representation)的修复效果基本持平, 本文方法的MPSNR(mean peak signal-to-noise ratio)在所有丢失率及张量数据上的总体平均高0.68 dB,MSSIM(mean structural similarity)总体平均高0.01;与其他6种张量建模方法相比,本文方法的MPSNR及MSSIM均取得最优结果。结论提出的基于稀疏先验与多模式张量分解的低秩张量恢复方法,可同时利用张量的全局低秩性与局部稀疏性,能够对受损的多维视觉数据进行有效修复。关键词:多模式张量分解;稀疏先验;因子梯度稀疏性;低秩张量恢复249|639|0更新时间:2024-04-12 -
 摘要:目的传统降噪方法通常忽视人眼感知因素,对不同区域的图像块都进行同等处理。当使用传统降噪算法对全景画面滤波处理时,全景画面两极区域容易产生模糊问题,尤其是通过视口观察时,该问题更加明显。针对此问题,提出一种视觉显著性驱动的蒙特卡洛渲染生成全景图非局部均值(visual saliency driven non-local means,VSD-NLM)滤波降噪算法。方法在VSD-NLM算法中首先使用全景图显著区域检测算法获取全景画面的显著区域;然后使用梯度幅值相似性偏差辅助的非局部均值(gradient magnitude similarity deviation assisted non-local means,GMSDA-NLM)滤波算法,降低显著区域的噪声;同时设计并行非局部均值(parallel non-local means,P-NLM)滤波算法,加快降噪处理速度,降低非显著区域噪声;最后利用改进的Canny算法提取梯度特征,同时结合各向异性扩散引导滤波来优化降噪结果。结果采用结构相似度(structural similarity,SSIM)和FLIP作为评价指标,来对比VSD-NLM算法与非局部均值滤波算法、多特征非局部均值滤波算法以及渐进式去噪算法等其他算法的性能。实验结果表明,VSD-NLM算法的降噪结果在客观评价指标上均优于对比算法,SSIM值比其他算法平均提高14.7%,FLIP值比其他算法平均降低15.2%。在视觉效果方面,VSD-NLM算法能够减轻全景画面模糊,提升视觉感知质量。本文对GMSDA-NLM和P-NLM算法的有效性进行了实验验证,相较于非局部均值滤波算法,GMSDA-NLM算法能够有效去除噪声并保持图像细节的完整性。P-NLM算法在运行速度方面相较对比算法平均提高约6倍,与串行算法生成的图像之间的SSIM值可达到0.996。结论本文算法能够更好地用于全景图降噪,滤波效果更佳,对全景电影制作应用有重要的理论和实际意义。关键词:全景图像;非局部均值滤波;梯度幅值相似性偏差(GMSD);引导滤波;图像降噪169|826|0更新时间:2024-04-12
摘要:目的传统降噪方法通常忽视人眼感知因素,对不同区域的图像块都进行同等处理。当使用传统降噪算法对全景画面滤波处理时,全景画面两极区域容易产生模糊问题,尤其是通过视口观察时,该问题更加明显。针对此问题,提出一种视觉显著性驱动的蒙特卡洛渲染生成全景图非局部均值(visual saliency driven non-local means,VSD-NLM)滤波降噪算法。方法在VSD-NLM算法中首先使用全景图显著区域检测算法获取全景画面的显著区域;然后使用梯度幅值相似性偏差辅助的非局部均值(gradient magnitude similarity deviation assisted non-local means,GMSDA-NLM)滤波算法,降低显著区域的噪声;同时设计并行非局部均值(parallel non-local means,P-NLM)滤波算法,加快降噪处理速度,降低非显著区域噪声;最后利用改进的Canny算法提取梯度特征,同时结合各向异性扩散引导滤波来优化降噪结果。结果采用结构相似度(structural similarity,SSIM)和FLIP作为评价指标,来对比VSD-NLM算法与非局部均值滤波算法、多特征非局部均值滤波算法以及渐进式去噪算法等其他算法的性能。实验结果表明,VSD-NLM算法的降噪结果在客观评价指标上均优于对比算法,SSIM值比其他算法平均提高14.7%,FLIP值比其他算法平均降低15.2%。在视觉效果方面,VSD-NLM算法能够减轻全景画面模糊,提升视觉感知质量。本文对GMSDA-NLM和P-NLM算法的有效性进行了实验验证,相较于非局部均值滤波算法,GMSDA-NLM算法能够有效去除噪声并保持图像细节的完整性。P-NLM算法在运行速度方面相较对比算法平均提高约6倍,与串行算法生成的图像之间的SSIM值可达到0.996。结论本文算法能够更好地用于全景图降噪,滤波效果更佳,对全景电影制作应用有重要的理论和实际意义。关键词:全景图像;非局部均值滤波;梯度幅值相似性偏差(GMSD);引导滤波;图像降噪169|826|0更新时间:2024-04-12 -
 摘要:目的图像逆半色调的目的是从二值半色调图像中恢复出连续色调图像。半色调图像丢失了大量原始图像内容信息,因此逆半色调成为一个经典的图像重建病态问题。现有的逆半色调算法重建效果无法满足对图像细节和纹理的需求。此外,已有方法大多忽略了训练策略对模型优化的重要影响,导致模型性能较差。针对上述问题,提出一个逆半色调网络以提高半色调图像重建质量。方法首先提出一个端到端的多尺度渐进式残差学习网络(multiscale progressivoly residual learning network, MSPRL)以恢复出更高质量的连续色调图像。该网络基于UNet架构并以多尺度图像作为输入;为充分利用不同尺度输入图像的信息,设计一个浅层特征提取模块以捕获多尺度图像的注意力信息;同时探讨不同学习策略对模型训练和性能的影响。结果实验在7个数据集上与6种方法进行对比。在Place365和Kodak数据集上,相比性能第2的方法,峰值信噪比(peak signal-to-noise ratio,PSNR)分别提高0.12 dB和0.18 dB;在其他5个常用于图像超分辨率的测试数据集Set5、Set14、BSD100(Berkeley segmentation dataset 100)、Urban100和Manga109上,相比性能第2的方法,PSNR值分别提高0.11 dB、0.25 dB、0.08 dB、0.39 dB和0.35 dB。基于本文的训练策略,重新训练的渐进式残差学习网络相比未优化训练模型在7个数据集上PSNR平均提高1.44 dB。本文方法在图像细节和纹理重建上实现最优效果。实验表明选用合适的学习策略能够优化模型训练,对性能提升具有重要帮助。结论本文提出的逆半色调模型,综合UNet架构和多尺度图像信息的优点,选用合适的训练策略,使得图像重建的细节与纹理更加清晰,视觉效果更加细致。本文算法代码公布在https://github.com/Feiyuli-cs/MSPRL。关键词:图像逆半色调;误差扩散;多尺度渐进式学习;深度学习;图像恢复201|457|0更新时间:2024-04-12
摘要:目的图像逆半色调的目的是从二值半色调图像中恢复出连续色调图像。半色调图像丢失了大量原始图像内容信息,因此逆半色调成为一个经典的图像重建病态问题。现有的逆半色调算法重建效果无法满足对图像细节和纹理的需求。此外,已有方法大多忽略了训练策略对模型优化的重要影响,导致模型性能较差。针对上述问题,提出一个逆半色调网络以提高半色调图像重建质量。方法首先提出一个端到端的多尺度渐进式残差学习网络(multiscale progressivoly residual learning network, MSPRL)以恢复出更高质量的连续色调图像。该网络基于UNet架构并以多尺度图像作为输入;为充分利用不同尺度输入图像的信息,设计一个浅层特征提取模块以捕获多尺度图像的注意力信息;同时探讨不同学习策略对模型训练和性能的影响。结果实验在7个数据集上与6种方法进行对比。在Place365和Kodak数据集上,相比性能第2的方法,峰值信噪比(peak signal-to-noise ratio,PSNR)分别提高0.12 dB和0.18 dB;在其他5个常用于图像超分辨率的测试数据集Set5、Set14、BSD100(Berkeley segmentation dataset 100)、Urban100和Manga109上,相比性能第2的方法,PSNR值分别提高0.11 dB、0.25 dB、0.08 dB、0.39 dB和0.35 dB。基于本文的训练策略,重新训练的渐进式残差学习网络相比未优化训练模型在7个数据集上PSNR平均提高1.44 dB。本文方法在图像细节和纹理重建上实现最优效果。实验表明选用合适的学习策略能够优化模型训练,对性能提升具有重要帮助。结论本文提出的逆半色调模型,综合UNet架构和多尺度图像信息的优点,选用合适的训练策略,使得图像重建的细节与纹理更加清晰,视觉效果更加细致。本文算法代码公布在https://github.com/Feiyuli-cs/MSPRL。关键词:图像逆半色调;误差扩散;多尺度渐进式学习;深度学习;图像恢复201|457|0更新时间:2024-04-12 -
 摘要:目的低光照图像增强是图像处理中的基本任务之一。虽然已经提出了各种方法,但它们往往无法在视觉上产生吸引人的结果,这些图像存在细节不清晰、对比度不高和色彩失真等问题,同时也对后续目标检测、语义分割等任务有不利影响。针对上述问题,提出一种语义分割和HSV(hue, saturation and value)色彩空间引导的低光照图像增强方法。方法首先提出一个迭代图像增强网络,逐步学习低光照图像与增强图像之间像素级的最佳映射,同时为了在增强过程中保留语义信息,引入一个无监督的语义分割网络并计算语义损失,该网络不需要昂贵的分割注释。为了进一步解决色彩失真问题,在训练时利用HSV色彩空间设计HSV损失;为了解决低光照图像增强中出现细节不清晰的问题,设计了空间一致性损失,使增强图像与对应的低光照图像尽可能细节一致。最终,本文的总损失函数由5个损失函数组成。结果将本文方法与LIME(low-light image enhancement)、RetinexNet(deep retinex decomposition)、EnlightenGAN(deep light enhancement using generative adversarial networks)、Zero-DCE (zero-reference deep curve estimation)和SGZ(semantic-guided zero-shot learning)5种方法进行了比较。在峰值信噪比(peak signal-to-noise ratio,PSNR)上,本文方法平均比Zero-DCE (zero-reference deep curve estimation)提高了0.32 dB;在自然图像质量评价(natural image quality evaluation,NIQE)方面,本文方法比EnlightenGAN提高了6%。从主观上看,本文方法具有更好的视觉效果。结论本文所提出的低光照图像增强方法能有效解决细节不清晰、色彩失真等问题,具有一定的应用价值。关键词:图像处理;低光照图像增强;深度学习;语义分割;HSV色彩空间361|643|0更新时间:2024-04-12
摘要:目的低光照图像增强是图像处理中的基本任务之一。虽然已经提出了各种方法,但它们往往无法在视觉上产生吸引人的结果,这些图像存在细节不清晰、对比度不高和色彩失真等问题,同时也对后续目标检测、语义分割等任务有不利影响。针对上述问题,提出一种语义分割和HSV(hue, saturation and value)色彩空间引导的低光照图像增强方法。方法首先提出一个迭代图像增强网络,逐步学习低光照图像与增强图像之间像素级的最佳映射,同时为了在增强过程中保留语义信息,引入一个无监督的语义分割网络并计算语义损失,该网络不需要昂贵的分割注释。为了进一步解决色彩失真问题,在训练时利用HSV色彩空间设计HSV损失;为了解决低光照图像增强中出现细节不清晰的问题,设计了空间一致性损失,使增强图像与对应的低光照图像尽可能细节一致。最终,本文的总损失函数由5个损失函数组成。结果将本文方法与LIME(low-light image enhancement)、RetinexNet(deep retinex decomposition)、EnlightenGAN(deep light enhancement using generative adversarial networks)、Zero-DCE (zero-reference deep curve estimation)和SGZ(semantic-guided zero-shot learning)5种方法进行了比较。在峰值信噪比(peak signal-to-noise ratio,PSNR)上,本文方法平均比Zero-DCE (zero-reference deep curve estimation)提高了0.32 dB;在自然图像质量评价(natural image quality evaluation,NIQE)方面,本文方法比EnlightenGAN提高了6%。从主观上看,本文方法具有更好的视觉效果。结论本文所提出的低光照图像增强方法能有效解决细节不清晰、色彩失真等问题,具有一定的应用价值。关键词:图像处理;低光照图像增强;深度学习;语义分割;HSV色彩空间361|643|0更新时间:2024-04-12
低质图像处理与语义理解

-
 摘要:目的线稿上色是由线条构成的黑白线稿草图涂上颜色变为彩色图像的过程,在卡通动画制作和艺术绘画等领域中是非常关键的步骤。全自动线稿上色方法可以减轻绘制过程中烦琐耗时的手工上色的工作量,然而自动理解线稿中的稀疏线条并选取合适的颜色仍较为困难。方法依据现实场景中特定绘画类型常有固定用色风格偏好这一先验,本文聚焦于有限色彩空间下的线稿自动上色,通过约束色彩空间,不仅可以降低语义理解的难度,还可以避免不合理的用色。具体地,本文提出一种两阶段线稿自动上色方法。在第1阶段,设计一个灰度图生成器,对输入的稀疏线稿补充线条和细节,以生成稠密像素的灰度图像。在第2阶段,首先设计色彩推理模块,从输入的颜色先验中推理得到适合该线稿的色彩子空间,再提出一种多尺度的渐进融合颜色信息的生成网络以逐步生成高质量的彩色图像。结果实验在3个数据集上与4种线稿自动上色方法进行对比,在上色结果的客观质量对比中,所提方法取得了更高的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity index measure,SSIM)值以及更低的均方误差;在上色结果的色彩指标对比中,所提方法取得了最高的色彩丰富度分数;在主观评价和用户调查中,所提方法也取得了与人的主观审美感受更一致的结果。此外,消融实验结果也表明了本文所使用的模型结构及色彩空间限制有益于上色性能的提升。结论实验结果表明,本文提出的有限色彩空间下的线稿自动上色方法可以有效地完成多类线稿的自动上色,并且可以简单地通过调整颜色先验以获得更多样的彩色图像。关键词:线稿上色;有限色彩空间;卡通;绘画;生成对抗网络232|985|0更新时间:2024-04-12
摘要:目的线稿上色是由线条构成的黑白线稿草图涂上颜色变为彩色图像的过程,在卡通动画制作和艺术绘画等领域中是非常关键的步骤。全自动线稿上色方法可以减轻绘制过程中烦琐耗时的手工上色的工作量,然而自动理解线稿中的稀疏线条并选取合适的颜色仍较为困难。方法依据现实场景中特定绘画类型常有固定用色风格偏好这一先验,本文聚焦于有限色彩空间下的线稿自动上色,通过约束色彩空间,不仅可以降低语义理解的难度,还可以避免不合理的用色。具体地,本文提出一种两阶段线稿自动上色方法。在第1阶段,设计一个灰度图生成器,对输入的稀疏线稿补充线条和细节,以生成稠密像素的灰度图像。在第2阶段,首先设计色彩推理模块,从输入的颜色先验中推理得到适合该线稿的色彩子空间,再提出一种多尺度的渐进融合颜色信息的生成网络以逐步生成高质量的彩色图像。结果实验在3个数据集上与4种线稿自动上色方法进行对比,在上色结果的客观质量对比中,所提方法取得了更高的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity index measure,SSIM)值以及更低的均方误差;在上色结果的色彩指标对比中,所提方法取得了最高的色彩丰富度分数;在主观评价和用户调查中,所提方法也取得了与人的主观审美感受更一致的结果。此外,消融实验结果也表明了本文所使用的模型结构及色彩空间限制有益于上色性能的提升。结论实验结果表明,本文提出的有限色彩空间下的线稿自动上色方法可以有效地完成多类线稿的自动上色,并且可以简单地通过调整颜色先验以获得更多样的彩色图像。关键词:线稿上色;有限色彩空间;卡通;绘画;生成对抗网络232|985|0更新时间:2024-04-12 -
 摘要:目的传统构造式图像信息隐藏算法通常直接将图像空域特征与秘密信息关联,对算法的安全性造成威胁。因此,本文将曲线绘制函数与信息隐藏相结合,提出一种以B样条控制点为特征,在图像空域间接隐藏信息的算法。方法算法主要分为信息隐藏及信息提取两阶段。在信息隐藏阶段,发送方首先通过选取初始控制点、仿射变换及B样条曲线绘制生成多条参考曲线,然后利用曲线控制点的位置隐藏信息,最后为图像填充颜色,即完成含密纹理图像的构造。在信息提取阶段,提取方根据纹理曲线和图像颜色获得含密曲线及参考曲线,经对照计算即可提取出秘密信息。结果本算法具有较高的隐藏容量、鲁棒性和安全性。实验结果表明,由本文算法生成的800 × 800像素图像,其最高隐藏容量可达2 870 bits,分别是另两种典型构造式信息隐藏算法的6.7和3.4倍,且在质量因子为10的JPEG(joint photographic experts group)压缩攻击下的提取误码率可低至0,优于鲁棒较强的选择式信息隐藏算法LDA-DCT(robust coverless image steganography based on DCT and LDA topic classification)以及与之类似的构造式信息隐藏算法。同时,抗隐写分析检测实验表明,在隐藏容量小于250 bits时检测误差趋近于0.5。结论本文以B样条曲线控制点为特征,在纹理图像的绘制过程中隐藏信息,有效提高了传统构造式图像信息隐藏算法的安全性、隐藏容量和鲁棒性。关键词:构造式信息隐藏;B样条;纹理图像;隐藏容量;安全性;鲁棒性164|666|0更新时间:2024-04-12
摘要:目的传统构造式图像信息隐藏算法通常直接将图像空域特征与秘密信息关联,对算法的安全性造成威胁。因此,本文将曲线绘制函数与信息隐藏相结合,提出一种以B样条控制点为特征,在图像空域间接隐藏信息的算法。方法算法主要分为信息隐藏及信息提取两阶段。在信息隐藏阶段,发送方首先通过选取初始控制点、仿射变换及B样条曲线绘制生成多条参考曲线,然后利用曲线控制点的位置隐藏信息,最后为图像填充颜色,即完成含密纹理图像的构造。在信息提取阶段,提取方根据纹理曲线和图像颜色获得含密曲线及参考曲线,经对照计算即可提取出秘密信息。结果本算法具有较高的隐藏容量、鲁棒性和安全性。实验结果表明,由本文算法生成的800 × 800像素图像,其最高隐藏容量可达2 870 bits,分别是另两种典型构造式信息隐藏算法的6.7和3.4倍,且在质量因子为10的JPEG(joint photographic experts group)压缩攻击下的提取误码率可低至0,优于鲁棒较强的选择式信息隐藏算法LDA-DCT(robust coverless image steganography based on DCT and LDA topic classification)以及与之类似的构造式信息隐藏算法。同时,抗隐写分析检测实验表明,在隐藏容量小于250 bits时检测误差趋近于0.5。结论本文以B样条曲线控制点为特征,在纹理图像的绘制过程中隐藏信息,有效提高了传统构造式图像信息隐藏算法的安全性、隐藏容量和鲁棒性。关键词:构造式信息隐藏;B样条;纹理图像;隐藏容量;安全性;鲁棒性164|666|0更新时间:2024-04-12
图像处理和编码
-
 摘要:目的纹理样图是指一幅用于描述纹理特征的图像,纹理样图多样性在纹理合成任务中是至关重要的,它可以为合成的纹理带来更丰富、多样和逼真的外观,同时为艺术家和设计师提供了更多的创作灵感和自由度。当前,纹理样图的提取主要通过手工剪裁和算法自动提取,从大量的图像中手工剪裁提取出高质量的纹理样图十分耗费精力和时间,并且该方式易受主观驱动且多样性受限。目前先进的纹理样图自动提取算法基于卷积神经网络的 Trimmed T-CNN(texture convolutional neural network)模型存在推理速度慢的问题。基于此,本文致力于利用互联网上丰富的图像资源,自动快速地从各种图像中裁剪出理想且多样的纹理样图,让用户有更多的选择。方法本文提出一个结合深度学习和宽度学习的从原始图像中自动提取纹理样图的方法。为了获取理想的纹理样图,首先通过残差特征金字塔网络提取特征图,有效地从输入图像中识别样图候选者,然后采用区域候选网络快速自动地获取大量的纹理样图候选区域。接下来,利用宽度学习系统对纹理样图的候选区域进行分类。最后,使用评分准则对宽度学习系统的分类结果进行评分,从而筛选出理想的纹理样图。结果为了验证本文方法的有效性,收集大量理想纹理样图并将它们分成6个类进行实验验证,本文模型的准确度达到了94.66%。与当前先进的方法Trimmed T-CNN相比,本文模型准确度提高了0.22%且速度得到了提升。对于分辨率为512 × 512像素、1 024 × 1 024像素和 2 048 × 2 048像素的图像,算法速度分别提快了1.393 8 s、1.864 3 s和2.368 7 s。结论本文提出的纹理样图自动提取算法,综合了深度学习和宽度学习的优点,使纹理样图的提取结果更加准确且高效。关键词:宽度学习;卷积神经网络(CNN);纹理样图提取;目标检测;区域候选网络;特征金字塔网络(FPN)204|1167|0更新时间:2024-04-12
摘要:目的纹理样图是指一幅用于描述纹理特征的图像,纹理样图多样性在纹理合成任务中是至关重要的,它可以为合成的纹理带来更丰富、多样和逼真的外观,同时为艺术家和设计师提供了更多的创作灵感和自由度。当前,纹理样图的提取主要通过手工剪裁和算法自动提取,从大量的图像中手工剪裁提取出高质量的纹理样图十分耗费精力和时间,并且该方式易受主观驱动且多样性受限。目前先进的纹理样图自动提取算法基于卷积神经网络的 Trimmed T-CNN(texture convolutional neural network)模型存在推理速度慢的问题。基于此,本文致力于利用互联网上丰富的图像资源,自动快速地从各种图像中裁剪出理想且多样的纹理样图,让用户有更多的选择。方法本文提出一个结合深度学习和宽度学习的从原始图像中自动提取纹理样图的方法。为了获取理想的纹理样图,首先通过残差特征金字塔网络提取特征图,有效地从输入图像中识别样图候选者,然后采用区域候选网络快速自动地获取大量的纹理样图候选区域。接下来,利用宽度学习系统对纹理样图的候选区域进行分类。最后,使用评分准则对宽度学习系统的分类结果进行评分,从而筛选出理想的纹理样图。结果为了验证本文方法的有效性,收集大量理想纹理样图并将它们分成6个类进行实验验证,本文模型的准确度达到了94.66%。与当前先进的方法Trimmed T-CNN相比,本文模型准确度提高了0.22%且速度得到了提升。对于分辨率为512 × 512像素、1 024 × 1 024像素和 2 048 × 2 048像素的图像,算法速度分别提快了1.393 8 s、1.864 3 s和2.368 7 s。结论本文提出的纹理样图自动提取算法,综合了深度学习和宽度学习的优点,使纹理样图的提取结果更加准确且高效。关键词:宽度学习;卷积神经网络(CNN);纹理样图提取;目标检测;区域候选网络;特征金字塔网络(FPN)204|1167|0更新时间:2024-04-12 -
 摘要:目的传统视觉场景识别(visual place recognition,VPR)算法的性能依赖光学图像的成像质量,因此高速和高动态范围场景导致的图像质量下降会进一步影响视觉场景识别算法的性能。针对此问题,提出一种融合事件相机的视觉场景识别算法,利用事件相机的低延时和高动态范围的特性,提升视觉场景识别算法在高速和高动态范围等极端场景下的识别性能。方法本文提出的方法首先使用图像特征提取模块提取质量良好的参考图像的特征,然后使用多模态特征融合模块提取查询图像及其曝光区间事件信息的多模态融合特征,最后通过特征匹配查找与查询图像最相似的参考图像。结果在MVSEC(multi-vehicle stereo event camera dataset)和RobotCar两个数据集上的实验表明,本文方法对比现有视觉场景识别算法在高速和高动态范围场景下具有明显优势。在高速高动态范围场景下,本文方法在MVSEC数据集上相较对比算法最优值在召回率与精度上分别提升5.39%和8.55%,在RobotCar数据集上相较对比算法最优值在召回率与精度上分别提升3.36%与4.41%。结论本文提出了融合事件相机的视觉场景识别算法,利用了事件相机在高速和高动态范围场景的成像优势,有效提升了视觉场景识别算法在高速和高动态范围场景下的场景识别性能。关键词:视觉场景识别(VPR);事件相机;多模态;特征融合;特征匹配276|1012|0更新时间:2024-04-12
摘要:目的传统视觉场景识别(visual place recognition,VPR)算法的性能依赖光学图像的成像质量,因此高速和高动态范围场景导致的图像质量下降会进一步影响视觉场景识别算法的性能。针对此问题,提出一种融合事件相机的视觉场景识别算法,利用事件相机的低延时和高动态范围的特性,提升视觉场景识别算法在高速和高动态范围等极端场景下的识别性能。方法本文提出的方法首先使用图像特征提取模块提取质量良好的参考图像的特征,然后使用多模态特征融合模块提取查询图像及其曝光区间事件信息的多模态融合特征,最后通过特征匹配查找与查询图像最相似的参考图像。结果在MVSEC(multi-vehicle stereo event camera dataset)和RobotCar两个数据集上的实验表明,本文方法对比现有视觉场景识别算法在高速和高动态范围场景下具有明显优势。在高速高动态范围场景下,本文方法在MVSEC数据集上相较对比算法最优值在召回率与精度上分别提升5.39%和8.55%,在RobotCar数据集上相较对比算法最优值在召回率与精度上分别提升3.36%与4.41%。结论本文提出了融合事件相机的视觉场景识别算法,利用了事件相机在高速和高动态范围场景的成像优势,有效提升了视觉场景识别算法在高速和高动态范围场景下的场景识别性能。关键词:视觉场景识别(VPR);事件相机;多模态;特征融合;特征匹配276|1012|0更新时间:2024-04-12 -
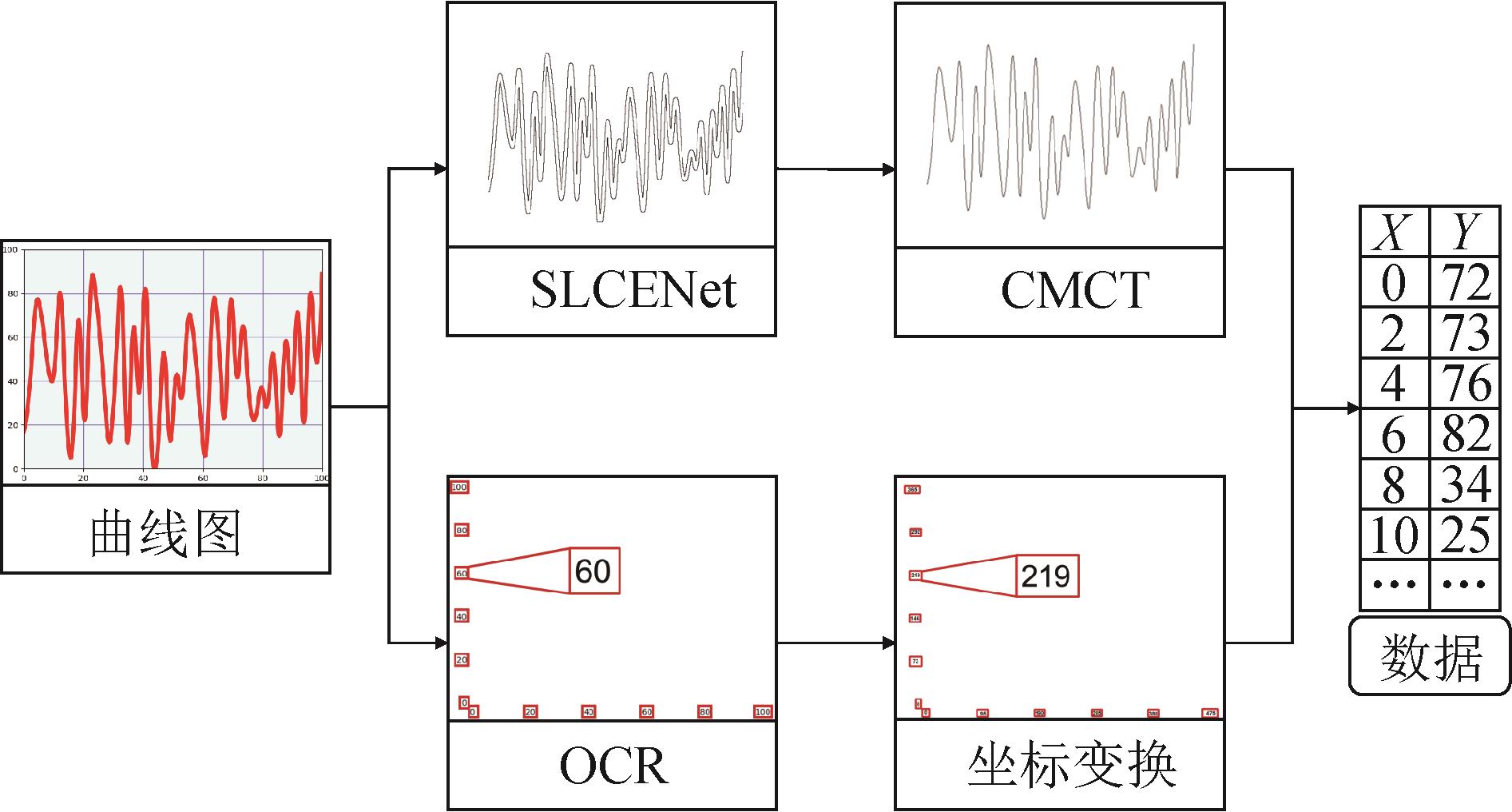 摘要:目的曲线图是数据呈现的重要形式,但在没有原始数据的情况下难以查询其中的具体数值。现有的图数转化算法需要大量的人工辅助操作去除图表中网格线等干扰,具有机械重复性且需大量人力的缺点。另外,图像压缩与缩放等攻击会降低图像质量,导致图数转化的准确度进一步降低。为了解决上述问题,本文提出了一个基于曲线提取与细化神经网络的图数转化算法。方法首先,提出了基于侧结构引导与拉普拉斯卷积的曲线提取神经网络(side structure guidance and Laplace convolution based curve extraction neural network,SLCENet),以轻量化的模型解决了现有曲线提取方法中的池化操作导致的边界模糊问题,提高了曲线提取的准确度。其次,为了减小曲线线宽对图数转化造成的误差,并平衡计算复杂度和准确度,设计了10个能够反映曲线走势的特征,提出了基于曲线走势特征和多层感知机的曲线细化方法(curve trend features and MLP based curve thinning method,CMCT),实现了曲线细化的高精度。最后,利用PaddleOCR(paddle optical character recognition)定位并识别坐标轴上的坐标标签,建立起坐标轴坐标与像素坐标的变换关系,通过坐标变换完成图数转化任务。结果在曲线提取方面,本文方法SLCENet的全局最优阈值指标(optimal dataset scale,ODS)达到了0.985,在分辨率为640 × 480像素的图像上的运行速度达到了0.043 s/幅,在兼顾曲线提取准确度和运行速度的情况下达到了最好的性能。在图数转化方面,本文方法的归一化均值误差(normalized mean error,NME)达到了0.79,运行速度达到了0.83 s/幅。结论提出的方法实现了全自动高精度的图数转化目标。与现有方法相比,在保持较小计算量的情况下兼具准确度高和运行速度快的特点,摆脱了图数转化需要大量人工交互辅助的限制。关键词:曲线图数据转化;曲线提取;曲线细化;拉普拉斯卷积;卷积神经网络(CNN)193|847|0更新时间:2024-04-12
摘要:目的曲线图是数据呈现的重要形式,但在没有原始数据的情况下难以查询其中的具体数值。现有的图数转化算法需要大量的人工辅助操作去除图表中网格线等干扰,具有机械重复性且需大量人力的缺点。另外,图像压缩与缩放等攻击会降低图像质量,导致图数转化的准确度进一步降低。为了解决上述问题,本文提出了一个基于曲线提取与细化神经网络的图数转化算法。方法首先,提出了基于侧结构引导与拉普拉斯卷积的曲线提取神经网络(side structure guidance and Laplace convolution based curve extraction neural network,SLCENet),以轻量化的模型解决了现有曲线提取方法中的池化操作导致的边界模糊问题,提高了曲线提取的准确度。其次,为了减小曲线线宽对图数转化造成的误差,并平衡计算复杂度和准确度,设计了10个能够反映曲线走势的特征,提出了基于曲线走势特征和多层感知机的曲线细化方法(curve trend features and MLP based curve thinning method,CMCT),实现了曲线细化的高精度。最后,利用PaddleOCR(paddle optical character recognition)定位并识别坐标轴上的坐标标签,建立起坐标轴坐标与像素坐标的变换关系,通过坐标变换完成图数转化任务。结果在曲线提取方面,本文方法SLCENet的全局最优阈值指标(optimal dataset scale,ODS)达到了0.985,在分辨率为640 × 480像素的图像上的运行速度达到了0.043 s/幅,在兼顾曲线提取准确度和运行速度的情况下达到了最好的性能。在图数转化方面,本文方法的归一化均值误差(normalized mean error,NME)达到了0.79,运行速度达到了0.83 s/幅。结论提出的方法实现了全自动高精度的图数转化目标。与现有方法相比,在保持较小计算量的情况下兼具准确度高和运行速度快的特点,摆脱了图数转化需要大量人工交互辅助的限制。关键词:曲线图数据转化;曲线提取;曲线细化;拉普拉斯卷积;卷积神经网络(CNN)193|847|0更新时间:2024-04-12
图像分析和识别
-
 摘要:目的图像级弱监督语义分割方法利用类别标签训练分割网络,可显著降低标注成本。现有方法大多采用类激活图定位目标物体,然而传统类激活图只能挖掘出物体中最具辨识性的区域,直接将其作为伪标签训练的分割网络精度较差。本文提出一种显著性引导的弱监督语义分割算法,可在获取更完整类激活图的基础上提高分割模型的性能。方法首先通过显著图对目标进行互补随机隐藏,以获得互补图像对,然后融合互补图像对的类激活图作为监督,提高网络获取完整类激活图的能力。其次引入双重注意力修正模块,利用全局信息修正类激活图并生成伪标签训练分割网络。最后使用标签迭代精调策略,结合分割网络的初始预测、类激活图以及显著图生成更精确的伪标签,迭代训练分割网络。结果在PASCAL VOC 2012(pattern analysis,statistical modeling and computational learning visual object classes 2012)数据集上进行类激活图生成实验与语义分割实验,所生成的类激活图更加完整,平均交并比有10.21%的提升。语义分割结果均优于对比方法,平均交并比提升6.9%。此外在COCO 2014(common object in context 2014)数据集上进行了多目标的语义分割实验,平均交并比提升0.5%。结论该算法可获得更完整的类激活图,缓解了弱监督语义分割中监督信息不足的问题,提升了弱监督语义分割模型的精度。关键词:深度学习;弱监督语义分割;显著性引导;类激活图(CAM);注意力机制211|711|0更新时间:2024-04-12
摘要:目的图像级弱监督语义分割方法利用类别标签训练分割网络,可显著降低标注成本。现有方法大多采用类激活图定位目标物体,然而传统类激活图只能挖掘出物体中最具辨识性的区域,直接将其作为伪标签训练的分割网络精度较差。本文提出一种显著性引导的弱监督语义分割算法,可在获取更完整类激活图的基础上提高分割模型的性能。方法首先通过显著图对目标进行互补随机隐藏,以获得互补图像对,然后融合互补图像对的类激活图作为监督,提高网络获取完整类激活图的能力。其次引入双重注意力修正模块,利用全局信息修正类激活图并生成伪标签训练分割网络。最后使用标签迭代精调策略,结合分割网络的初始预测、类激活图以及显著图生成更精确的伪标签,迭代训练分割网络。结果在PASCAL VOC 2012(pattern analysis,statistical modeling and computational learning visual object classes 2012)数据集上进行类激活图生成实验与语义分割实验,所生成的类激活图更加完整,平均交并比有10.21%的提升。语义分割结果均优于对比方法,平均交并比提升6.9%。此外在COCO 2014(common object in context 2014)数据集上进行了多目标的语义分割实验,平均交并比提升0.5%。结论该算法可获得更完整的类激活图,缓解了弱监督语义分割中监督信息不足的问题,提升了弱监督语义分割模型的精度。关键词:深度学习;弱监督语义分割;显著性引导;类激活图(CAM);注意力机制211|711|0更新时间:2024-04-12 -
 摘要:目的行为识别中广泛使用的深度图序列存在着行为数据时空结构信息体现不足、易受深色物体等因素影响的缺点,点云数据可以提供丰富的空间信息与几何特征,弥补了深度图像的不足,但多数点云数据集规模较小且没有时序信息。为了提高时空结构信息的利用率,本文提出了结合坐标转换和时空信息注入的点云人体行为识别网络。方法通过将深度图序列转换为三维点云序列,弥补了点云数据集规模较小的缺点,并加入帧的时序概念。本文网络由两个模块组成,即特征提取模块和时空信息注入模块。特征提取模块提取点云深层次的外观轮廓特征。时空信息注入模块为轮廓特征注入时序信息,并通过一组随机张量投影继续注入空间结构信息。最后,将不同层次的多个特征进行聚合,输入到分类器中进行分类。结果在3个公共数据集上对本文方法进行了验证,提出的网络结构展现出了良好的性能。其中,在NTU RGB+d60数据集上的精度分别比PSTNet(point spatio-temporal network)和SequentialPointNet提升了1.3%和0.2%,在NTU RGB+d120数据集上的精度比PSTNet提升了1.9%。为了确保网络模型的鲁棒性,在MSR Action3D小数据集上进行实验对比,识别精度比SequentialPointNet提升了1.07%。结论提出的网络在获取静态的点云外观轮廓特征的同时,融入了动态的时空信息,弥补了特征提取时下采样导致的时空损失。关键词:人体行为识别;坐标转换;点云序列;特征提取;时空信息237|383|0更新时间:2024-04-12
摘要:目的行为识别中广泛使用的深度图序列存在着行为数据时空结构信息体现不足、易受深色物体等因素影响的缺点,点云数据可以提供丰富的空间信息与几何特征,弥补了深度图像的不足,但多数点云数据集规模较小且没有时序信息。为了提高时空结构信息的利用率,本文提出了结合坐标转换和时空信息注入的点云人体行为识别网络。方法通过将深度图序列转换为三维点云序列,弥补了点云数据集规模较小的缺点,并加入帧的时序概念。本文网络由两个模块组成,即特征提取模块和时空信息注入模块。特征提取模块提取点云深层次的外观轮廓特征。时空信息注入模块为轮廓特征注入时序信息,并通过一组随机张量投影继续注入空间结构信息。最后,将不同层次的多个特征进行聚合,输入到分类器中进行分类。结果在3个公共数据集上对本文方法进行了验证,提出的网络结构展现出了良好的性能。其中,在NTU RGB+d60数据集上的精度分别比PSTNet(point spatio-temporal network)和SequentialPointNet提升了1.3%和0.2%,在NTU RGB+d120数据集上的精度比PSTNet提升了1.9%。为了确保网络模型的鲁棒性,在MSR Action3D小数据集上进行实验对比,识别精度比SequentialPointNet提升了1.07%。结论提出的网络在获取静态的点云外观轮廓特征的同时,融入了动态的时空信息,弥补了特征提取时下采样导致的时空损失。关键词:人体行为识别;坐标转换;点云序列;特征提取;时空信息237|383|0更新时间:2024-04-12
图像理解和计算机视觉
-
 摘要:目的肺部肿瘤早期症状不典型易导致错过最佳治疗时间,有效准确的肺部肿瘤检测技术在计算机辅助诊断中变得日益重要,但在肺部肿瘤PET/CT(positron emission computed tomography/computed tomography)多模态影像中,肿瘤与周围组织粘连导致边缘模糊和对比度低,且存在病灶区域小、大小分布不均衡等问题。针对上述问题,提出一种跨模态注意力YOLOv5(cross-modal attention you only look once v5, CA-YOLOv5)的肺部肿瘤检测模型。方法首先,在主干网络中设计双分支并行的自学习注意力,利用实例归一化学习比例系数,同时利用特征值与平均值之间差值计算每个特征所包含信息量,增强肿瘤特征和提高对比度;其次,为充分学习多模态影像的多模态优势信息,设计跨模态注意力对多模态特征进行交互式学习,其中Transformer用于建模深浅层特征的远距离相互依赖关系,学习功能和解剖信息以提高肺部肿瘤识别能力;最后,针对病灶区域小、大小分布不均衡的问题,设计动态特征增强模块,利用不同感受野的多分支分组扩张卷积和分组可变形卷积,使网络充分高效挖掘肺部肿瘤特征的多尺度语义信息。结果在肺部肿瘤PET/CT数据集上与其他10种方法进行性能对比,CA-YOLOv5获得了97.37%精度、94.01%召回率、96.36% mAP(mean average precision)和95.67% F1的最佳性能,并且在同设备上训练耗时最短。在LUNA16(lung nodule analysis 16)数据集中本文同样获得了97.52%精度和97.45% mAP的最佳性能。结论本文基于多模态互补特征提出跨模态注意力YOLOv5检测模型,利用注意力机制和多尺度语义信息,实现了肺部肿瘤检测模型在多模态影像上的有效识别,使模型识别更加准确和更具鲁棒性。关键词:YOLOv5检测;自学习注意力;跨模态注意力;动态特征增强模块;PET/CT肺部肿瘤数据集252|691|1更新时间:2024-04-12
摘要:目的肺部肿瘤早期症状不典型易导致错过最佳治疗时间,有效准确的肺部肿瘤检测技术在计算机辅助诊断中变得日益重要,但在肺部肿瘤PET/CT(positron emission computed tomography/computed tomography)多模态影像中,肿瘤与周围组织粘连导致边缘模糊和对比度低,且存在病灶区域小、大小分布不均衡等问题。针对上述问题,提出一种跨模态注意力YOLOv5(cross-modal attention you only look once v5, CA-YOLOv5)的肺部肿瘤检测模型。方法首先,在主干网络中设计双分支并行的自学习注意力,利用实例归一化学习比例系数,同时利用特征值与平均值之间差值计算每个特征所包含信息量,增强肿瘤特征和提高对比度;其次,为充分学习多模态影像的多模态优势信息,设计跨模态注意力对多模态特征进行交互式学习,其中Transformer用于建模深浅层特征的远距离相互依赖关系,学习功能和解剖信息以提高肺部肿瘤识别能力;最后,针对病灶区域小、大小分布不均衡的问题,设计动态特征增强模块,利用不同感受野的多分支分组扩张卷积和分组可变形卷积,使网络充分高效挖掘肺部肿瘤特征的多尺度语义信息。结果在肺部肿瘤PET/CT数据集上与其他10种方法进行性能对比,CA-YOLOv5获得了97.37%精度、94.01%召回率、96.36% mAP(mean average precision)和95.67% F1的最佳性能,并且在同设备上训练耗时最短。在LUNA16(lung nodule analysis 16)数据集中本文同样获得了97.52%精度和97.45% mAP的最佳性能。结论本文基于多模态互补特征提出跨模态注意力YOLOv5检测模型,利用注意力机制和多尺度语义信息,实现了肺部肿瘤检测模型在多模态影像上的有效识别,使模型识别更加准确和更具鲁棒性。关键词:YOLOv5检测;自学习注意力;跨模态注意力;动态特征增强模块;PET/CT肺部肿瘤数据集252|691|1更新时间:2024-04-12 -
 摘要:目的基于深度学习方法进行乳腺癌识别是一项具有挑战的任务,目前较多研究使用单一倍率下的乳腺组织病理图像作为模型的输入,忽略了乳腺组织病理图像固有的多倍率特点,而少数将不同倍率下的图像作为模型输入的研究,存在特征利用率较低以及不同倍率的图像之间缺乏信息交互等问题。方法针对上述问题,提出一种基于多尺度和分组注意力机制的卷积神经网络改进策略。该策略主要包括信息交互模块和特征融合模块。前者通过空间注意力加强不同倍率的图像之间的相关性,然后将加权累加的结果反馈给原始分支进行动态选择实现特征流通;后者则利用一种分组注意力来提升特征的利用率,同时基于特征金字塔来消除图像之间的感受野差异。结果本文将上述策略应用到多种卷积网络中,并与最新的方法进行比较。在Camelyon16公开数据集上进行五折交叉验证实验,并对每一项评价指标计算均值和标准差。相比于单一尺度图像作为输入的卷积网络,本文改进的方法在准确率上提升0.9%~1.1%,F1分数提升1.1%~1.2%;相较于对比方法中性能最好的TransPath网络,本文改进的DenseNet201(dense convolutional network)在准确率上提升0.6%,精确率提升0.8%,F1分数提升0.6%,并且各项指标的标准差低于Transpath,表明加入策略的网络具有更好的稳定性。结论本文所提出的策略能弥补一般多尺度网络的缺陷,并具备一定的通用性,可获得更好的乳腺癌分类性能。关键词:乳腺病理图像分类;密集卷积网络;多尺度;注意力;特征融合228|805|1更新时间:2024-04-12
摘要:目的基于深度学习方法进行乳腺癌识别是一项具有挑战的任务,目前较多研究使用单一倍率下的乳腺组织病理图像作为模型的输入,忽略了乳腺组织病理图像固有的多倍率特点,而少数将不同倍率下的图像作为模型输入的研究,存在特征利用率较低以及不同倍率的图像之间缺乏信息交互等问题。方法针对上述问题,提出一种基于多尺度和分组注意力机制的卷积神经网络改进策略。该策略主要包括信息交互模块和特征融合模块。前者通过空间注意力加强不同倍率的图像之间的相关性,然后将加权累加的结果反馈给原始分支进行动态选择实现特征流通;后者则利用一种分组注意力来提升特征的利用率,同时基于特征金字塔来消除图像之间的感受野差异。结果本文将上述策略应用到多种卷积网络中,并与最新的方法进行比较。在Camelyon16公开数据集上进行五折交叉验证实验,并对每一项评价指标计算均值和标准差。相比于单一尺度图像作为输入的卷积网络,本文改进的方法在准确率上提升0.9%~1.1%,F1分数提升1.1%~1.2%;相较于对比方法中性能最好的TransPath网络,本文改进的DenseNet201(dense convolutional network)在准确率上提升0.6%,精确率提升0.8%,F1分数提升0.6%,并且各项指标的标准差低于Transpath,表明加入策略的网络具有更好的稳定性。结论本文所提出的策略能弥补一般多尺度网络的缺陷,并具备一定的通用性,可获得更好的乳腺癌分类性能。关键词:乳腺病理图像分类;密集卷积网络;多尺度;注意力;特征融合228|805|1更新时间:2024-04-12 -
 摘要:目的随着全球人口老年化趋势日益加剧,阿尔茨海默症(Alzheimer's disease, AD)的及时诊断与病理区域的可视化及其准确定位具有重要的临床意义。目前的研究中,基于块级和区域级的检测,由于采用非线性交互很难解释影响模型决策的病理区域。针对此问题,提出了一种AD病理区域定位及诊断的联合学习框架。方法利用反事实推理的思想,基于前景背景注意力掩码构建注意力引导的循环生成对抗网络(attention-guided cycle generative adversarial network, ACGAN)可视化AD患者的病理区域,并使用生成的病理区域知识指导增强诊断模型。具体来说,通过在ACGAN模型的生成器中设计注意力掩码来引导生成方案,使模型更好地聚焦于疾病的病理区域,有效地捕捉突出的全局特征。并通过ACGAN模型中病理区域生成器实现结构磁共振图像(structural magnetic resonance imaging, sMRI)在源域和目标域之间的转换清晰地划分出细微的病理区域。利用生成的病理区域知识作为指导,并结合三维坐标注意力与全局局部注意力,获取三维图像之间的依赖关系及三维空间的位置信息,优化诊断模型。结果为了验证方法的有效性,在公开的ADNI(Alzheimer’s disease neuroimaging initiative)数据集上对模型进行评估,与传统的卷积神经网络(convolutional neural network,CNN)模型及几种较为先进的AD分类诊断模型相比,本文使用病理区域知识指导增强诊断模型显示出优越的诊断性能,相比于性能较好的方法,ACC(accuracy)、F1-score、AUC(area under curve)分别提高了3.60%、5.02%、1.94%。并对生成的病理区域图像进行定性及定量评估,本文方法得到的病理区域图像归一化互相关分数和峰值信噪比均优于对比方法。结论与现有方法相比,本文模型可以学习sMRI图像在源域和目标域之间的转换,能够准确地捕获全局特征及病理区域。并将学习到的病理区域知识用于AD诊断模型的改进,使分类诊断模型取得了卓越性能。关键词:阿尔茨海默症(AD);病理区域;生成对抗网络(GAN);注意力机制;可视化174|537|0更新时间:2024-04-12
摘要:目的随着全球人口老年化趋势日益加剧,阿尔茨海默症(Alzheimer's disease, AD)的及时诊断与病理区域的可视化及其准确定位具有重要的临床意义。目前的研究中,基于块级和区域级的检测,由于采用非线性交互很难解释影响模型决策的病理区域。针对此问题,提出了一种AD病理区域定位及诊断的联合学习框架。方法利用反事实推理的思想,基于前景背景注意力掩码构建注意力引导的循环生成对抗网络(attention-guided cycle generative adversarial network, ACGAN)可视化AD患者的病理区域,并使用生成的病理区域知识指导增强诊断模型。具体来说,通过在ACGAN模型的生成器中设计注意力掩码来引导生成方案,使模型更好地聚焦于疾病的病理区域,有效地捕捉突出的全局特征。并通过ACGAN模型中病理区域生成器实现结构磁共振图像(structural magnetic resonance imaging, sMRI)在源域和目标域之间的转换清晰地划分出细微的病理区域。利用生成的病理区域知识作为指导,并结合三维坐标注意力与全局局部注意力,获取三维图像之间的依赖关系及三维空间的位置信息,优化诊断模型。结果为了验证方法的有效性,在公开的ADNI(Alzheimer’s disease neuroimaging initiative)数据集上对模型进行评估,与传统的卷积神经网络(convolutional neural network,CNN)模型及几种较为先进的AD分类诊断模型相比,本文使用病理区域知识指导增强诊断模型显示出优越的诊断性能,相比于性能较好的方法,ACC(accuracy)、F1-score、AUC(area under curve)分别提高了3.60%、5.02%、1.94%。并对生成的病理区域图像进行定性及定量评估,本文方法得到的病理区域图像归一化互相关分数和峰值信噪比均优于对比方法。结论与现有方法相比,本文模型可以学习sMRI图像在源域和目标域之间的转换,能够准确地捕获全局特征及病理区域。并将学习到的病理区域知识用于AD诊断模型的改进,使分类诊断模型取得了卓越性能。关键词:阿尔茨海默症(AD);病理区域;生成对抗网络(GAN);注意力机制;可视化174|537|0更新时间:2024-04-12
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0