
最新刊期
2024 年 第 29 卷 第 3 期

-
 摘要:医学影像是产前筛查、诊断、治疗引导和评估的重要工具,能有效避免胎儿脑的发育异常。近年来,磁共振成像在产前诊断中愈加重要,而实现自动、定量、精确地分析胎儿脑磁共振图像依赖于可靠的图像分割。因此,胎儿脑磁共振图像分割具有十分重要的临床意义与研究价值。由于胎儿图像中存在组织器官多、图像质量差及结构变化快等问题,胎儿脑磁共振图像的分割面临着巨大的困难与挑战。目前,尚未有文献对该领域的方法进行系统性的总结和分析,尤其是基于深度学习的方法。本文针对胎儿脑磁共振图像分割方法进行综述,首先,对胎儿脑磁共振图像的主要公开图谱/数据集进行详细说明;接着,对脑实质提取、组织分割和病灶分割方法进行全面的分类与分析;最后,对胎儿脑磁共振图像分割面临的挑战及未来的研究方向进行总结与展望。关键词:胎儿脑;磁共振成像(MRI);数据集;图像分割;深度学习262|1178|0更新时间:2024-03-13
摘要:医学影像是产前筛查、诊断、治疗引导和评估的重要工具,能有效避免胎儿脑的发育异常。近年来,磁共振成像在产前诊断中愈加重要,而实现自动、定量、精确地分析胎儿脑磁共振图像依赖于可靠的图像分割。因此,胎儿脑磁共振图像分割具有十分重要的临床意义与研究价值。由于胎儿图像中存在组织器官多、图像质量差及结构变化快等问题,胎儿脑磁共振图像的分割面临着巨大的困难与挑战。目前,尚未有文献对该领域的方法进行系统性的总结和分析,尤其是基于深度学习的方法。本文针对胎儿脑磁共振图像分割方法进行综述,首先,对胎儿脑磁共振图像的主要公开图谱/数据集进行详细说明;接着,对脑实质提取、组织分割和病灶分割方法进行全面的分类与分析;最后,对胎儿脑磁共振图像分割面临的挑战及未来的研究方向进行总结与展望。关键词:胎儿脑;磁共振成像(MRI);数据集;图像分割;深度学习262|1178|0更新时间:2024-03-13 -
 摘要:口腔医学影像是进行临床口腔疾病检测、筛查、诊断和治疗评估的重要工具,对口腔影像进行准确分析对于后续治疗计划的制定至关重要。常规的口腔医学影像分析依赖于医师的水平和经验,存在阅片效率低、可重复性低以及定量分析欠缺的问题。深度学习可以从大样本数据中自动学习并获取优良的特征表达,提升各类机器学习任务的效率和性能,目前已广泛应用于医学影像分析处理的各类任务之中。基于深度学习的口腔医学影像处理是目前的研究热点,但由于口腔医学领域内在的特殊性和复杂性,以及口腔医学影像数据样本量通常较小的问题,给深度学习方法在相关学习任务和场景的应用带来了新的挑战。本文从口腔医学影像领域常用的二维X射线影像、三维点云/网格影像和锥形束计算机断层扫描影像3种影像出发,介绍深度学习技术在口腔医学影像处理及分析领域应用的思路和现状,分析了各算法的优缺点及该领域所面临的问题和挑战,并对未来的研究方向和可能开展的临床应用进行展望,以助力智慧口腔建设。关键词:深度学习;口腔医学影像;牙齿检测与分割;龋齿检测;计算机辅助诊断(CAD)534|2432|3更新时间:2024-03-13
摘要:口腔医学影像是进行临床口腔疾病检测、筛查、诊断和治疗评估的重要工具,对口腔影像进行准确分析对于后续治疗计划的制定至关重要。常规的口腔医学影像分析依赖于医师的水平和经验,存在阅片效率低、可重复性低以及定量分析欠缺的问题。深度学习可以从大样本数据中自动学习并获取优良的特征表达,提升各类机器学习任务的效率和性能,目前已广泛应用于医学影像分析处理的各类任务之中。基于深度学习的口腔医学影像处理是目前的研究热点,但由于口腔医学领域内在的特殊性和复杂性,以及口腔医学影像数据样本量通常较小的问题,给深度学习方法在相关学习任务和场景的应用带来了新的挑战。本文从口腔医学影像领域常用的二维X射线影像、三维点云/网格影像和锥形束计算机断层扫描影像3种影像出发,介绍深度学习技术在口腔医学影像处理及分析领域应用的思路和现状,分析了各算法的优缺点及该领域所面临的问题和挑战,并对未来的研究方向和可能开展的临床应用进行展望,以助力智慧口腔建设。关键词:深度学习;口腔医学影像;牙齿检测与分割;龋齿检测;计算机辅助诊断(CAD)534|2432|3更新时间:2024-03-13
综述
-
 摘要:目的有丝分裂细胞核计数是乳腺癌诊断和组织学分级的3个重要评分指标之一,基于深度学习的自动检测方法,可以有效辅助医生进行乳腺病理图像有丝分裂细胞核识别和计数。而当前研究中的公开数据集多为竞赛所用,由举办方联合数据提供者挑选而来,与医院临床应用中所使用的数据存在较大的差异,不利于模型性能及泛化能力的测试验证。针对以上问题,本文发布了来自中国赣州市立医院临床环境的数据集GZMH(Ganzhou municipal hospital)。方法整理并公开发布的数据集GZMH包含55幅全视野数字切片(whole slide images, WSIs)临床乳腺癌病理图像,提供了用于有丝分裂细胞核目标检测和语义分割研究的两种标注,并由2名高年资医师对3名初级病理医师的标注进行了复核。5种主流目标检测方法和5种经典分割方法在GZMH数据集上进行了训练和测试,检验它们在临床数据集GZMH上的性能。结果目标检测方法实验结果比较中,SSD(single shot multibox detector)模型取得了最佳的效果,F1分数为0.511;分割方法实验结果比较中,R2U-Net(recurrent rsidual convolutional neural network based on U-Net)性能最佳,F1分数为0.430。所有方法在面对较大规模的临床数据集GZMH时体现的性能都明显低于它们在一些公开数据集上的性能。结论本文所提出的GZMH数据集能够用于有丝分裂目标检测与语义分割研究任务,且此数据集中的图像更加接近实际的应用场景,在推动乳腺病理图像有丝分裂细胞核分割的研究和临床应用方面具有较大的价值。数据集的在线发布地址为:https://doi.org/10.57760/sciencedb.08547。关键词:乳腺癌;病理图像;有丝分裂细胞核;目标检测;语义分割;数据集458|685|0更新时间:2024-03-13
摘要:目的有丝分裂细胞核计数是乳腺癌诊断和组织学分级的3个重要评分指标之一,基于深度学习的自动检测方法,可以有效辅助医生进行乳腺病理图像有丝分裂细胞核识别和计数。而当前研究中的公开数据集多为竞赛所用,由举办方联合数据提供者挑选而来,与医院临床应用中所使用的数据存在较大的差异,不利于模型性能及泛化能力的测试验证。针对以上问题,本文发布了来自中国赣州市立医院临床环境的数据集GZMH(Ganzhou municipal hospital)。方法整理并公开发布的数据集GZMH包含55幅全视野数字切片(whole slide images, WSIs)临床乳腺癌病理图像,提供了用于有丝分裂细胞核目标检测和语义分割研究的两种标注,并由2名高年资医师对3名初级病理医师的标注进行了复核。5种主流目标检测方法和5种经典分割方法在GZMH数据集上进行了训练和测试,检验它们在临床数据集GZMH上的性能。结果目标检测方法实验结果比较中,SSD(single shot multibox detector)模型取得了最佳的效果,F1分数为0.511;分割方法实验结果比较中,R2U-Net(recurrent rsidual convolutional neural network based on U-Net)性能最佳,F1分数为0.430。所有方法在面对较大规模的临床数据集GZMH时体现的性能都明显低于它们在一些公开数据集上的性能。结论本文所提出的GZMH数据集能够用于有丝分裂目标检测与语义分割研究任务,且此数据集中的图像更加接近实际的应用场景,在推动乳腺病理图像有丝分裂细胞核分割的研究和临床应用方面具有较大的价值。数据集的在线发布地址为:https://doi.org/10.57760/sciencedb.08547。关键词:乳腺癌;病理图像;有丝分裂细胞核;目标检测;语义分割;数据集458|685|0更新时间:2024-03-13
数据集
-
 摘要:目的联邦学习允许多个机构在不侵犯数据隐私、安全的前提下协作训练强大的深度模型。现有多数联邦范式在处理多中心不同数据分布时性能通常会下降,且弱监督条件下的联邦范式鲜有研究,特别是各站点数据采用不同形式稀疏标注的情况。针对该问题,提出一种站点分布相似度感知知识蒸馏的统一弱监督个性化联邦学习框架(unified weakly supervised personalized federated image segmentation via similarity-aware distillation,pFedWSD),以应对多中心数据分布和标注上的差异。方法所提出的pFedWSD通过循环知识蒸馏为每个站点训练个性化模型,包含动态循环公共知识积累及个性化两个阶段。第1阶段以不确定度感知方式动态地排序每轮训练中各站点模型性能,并以循环知识蒸馏的形式积累公共知识;第2阶段通过批标准化层的统计信息来度量各站点间相似性并聚合得到各站点教师模型并进行知识蒸馏。在弱监督方面,引入门控条件随机场损失和树能量损失相结合的训练目标,以产生更为精确的伪标注监督信号。结果在眼底视杯视盘分割和视网膜中心凹无血管区分割两项任务中,pFedWSD的Dice系数和HD95(95% Hausdorff distance)指标均优于多种中心式联邦和个性化联邦方法,在两项任务中,Dice系数分别为90.38%和93.12%,相比于较先进的方法FedAP(federated learning with adaptive batchnorm for personalized healthcare)和FedALA(adaptive local aggregation for personalized federated learning)分别提升了1.67%和6.56%,性能接近于全监督集中式训练所得的模型。结论本文提出的弱监督个性化联邦学习框架能有效统一不同形式稀疏标注数据并对不同分布的各站点数据训练得到个性化模型,使各站点分割性能均得到显著提升。关键词:相似度感知;知识蒸馏;弱监督学习;个性化联邦学习;医学图像分割183|516|0更新时间:2024-03-13
摘要:目的联邦学习允许多个机构在不侵犯数据隐私、安全的前提下协作训练强大的深度模型。现有多数联邦范式在处理多中心不同数据分布时性能通常会下降,且弱监督条件下的联邦范式鲜有研究,特别是各站点数据采用不同形式稀疏标注的情况。针对该问题,提出一种站点分布相似度感知知识蒸馏的统一弱监督个性化联邦学习框架(unified weakly supervised personalized federated image segmentation via similarity-aware distillation,pFedWSD),以应对多中心数据分布和标注上的差异。方法所提出的pFedWSD通过循环知识蒸馏为每个站点训练个性化模型,包含动态循环公共知识积累及个性化两个阶段。第1阶段以不确定度感知方式动态地排序每轮训练中各站点模型性能,并以循环知识蒸馏的形式积累公共知识;第2阶段通过批标准化层的统计信息来度量各站点间相似性并聚合得到各站点教师模型并进行知识蒸馏。在弱监督方面,引入门控条件随机场损失和树能量损失相结合的训练目标,以产生更为精确的伪标注监督信号。结果在眼底视杯视盘分割和视网膜中心凹无血管区分割两项任务中,pFedWSD的Dice系数和HD95(95% Hausdorff distance)指标均优于多种中心式联邦和个性化联邦方法,在两项任务中,Dice系数分别为90.38%和93.12%,相比于较先进的方法FedAP(federated learning with adaptive batchnorm for personalized healthcare)和FedALA(adaptive local aggregation for personalized federated learning)分别提升了1.67%和6.56%,性能接近于全监督集中式训练所得的模型。结论本文提出的弱监督个性化联邦学习框架能有效统一不同形式稀疏标注数据并对不同分布的各站点数据训练得到个性化模型,使各站点分割性能均得到显著提升。关键词:相似度感知;知识蒸馏;弱监督学习;个性化联邦学习;医学图像分割183|516|0更新时间:2024-03-13 -
 摘要:目的从眼底图像中分割视盘和视杯对于眼部疾病智能诊断来说是一项重要工作,U-Net及变体模型已经广泛应用在视杯盘分割任务中。由于连续的卷积与池化操作容易引起空间信息损失,导致视盘和视杯分割精度差且效率低。提出了融合残差上下文编码和路径增强的深度学习网络RCPA-Net,提升了分割结果的准确性与连续性。方法采用限制对比度自适应直方图均衡方法处理输入图像,增强对比度并丰富图像信息。特征编码模块以ResNet34(residual neural network)为骨干网络,通过引入残差递归与注意力机制使模型更关注感兴趣区域,采用残差空洞卷积模块捕获更深层次的语义特征信息,使用路径增强模块在浅层特征中获得精确的定位信息来增强整个特征层次。本文还提出了一种新的多标签损失函数用于提高视盘视杯与背景区域的像素比例并生成最终的分割图。结果在4个数据集上与多种分割方法进行比较,在ORIGA(online retinal fundus image database for glaucoma analysis)数据集中,本文方法对视盘分割的JC(Jaccard)指数为0.939 1,F-measure为0.968 6,视杯分割的JC和F-measure分别为0.794 8和0.885 5;在Drishti-GS1数据集中,视盘分割的JC和F-measure分别为0.951 3和0.975 0,视杯分割的JC和F-measure分别为0.863 3和0.926 6;在Refuge(retinal fundus glaucoma challenge)数据集中,视盘分割的JC和F-measure分别为0.929 8和0.963 6,视杯分割的JC和F-measure分别为0.828 8和0.906 3;在RIM-ONE(retinal image database for optic nerve evaluation)-R1数据集中,视盘分割的JC和F-measure分别为0.929 0和0.962 8。在4个数据集上结果均优于对比算法,性能显著提升。此外,针对网络中提出的模块分别做了消融实验,验证了RCPA-Net中各个模块的有效性。结论实验结果表明,RCPA-Net提升了视盘和视杯分割精度,预测图像更接近真实标签结果,同时跨数据集测试结果证明了RCPA-Net具有良好的泛化能力。关键词:视杯视盘分割;深度学习;注意力机制;残差空洞卷积;路径增强264|396|1更新时间:2024-03-13
摘要:目的从眼底图像中分割视盘和视杯对于眼部疾病智能诊断来说是一项重要工作,U-Net及变体模型已经广泛应用在视杯盘分割任务中。由于连续的卷积与池化操作容易引起空间信息损失,导致视盘和视杯分割精度差且效率低。提出了融合残差上下文编码和路径增强的深度学习网络RCPA-Net,提升了分割结果的准确性与连续性。方法采用限制对比度自适应直方图均衡方法处理输入图像,增强对比度并丰富图像信息。特征编码模块以ResNet34(residual neural network)为骨干网络,通过引入残差递归与注意力机制使模型更关注感兴趣区域,采用残差空洞卷积模块捕获更深层次的语义特征信息,使用路径增强模块在浅层特征中获得精确的定位信息来增强整个特征层次。本文还提出了一种新的多标签损失函数用于提高视盘视杯与背景区域的像素比例并生成最终的分割图。结果在4个数据集上与多种分割方法进行比较,在ORIGA(online retinal fundus image database for glaucoma analysis)数据集中,本文方法对视盘分割的JC(Jaccard)指数为0.939 1,F-measure为0.968 6,视杯分割的JC和F-measure分别为0.794 8和0.885 5;在Drishti-GS1数据集中,视盘分割的JC和F-measure分别为0.951 3和0.975 0,视杯分割的JC和F-measure分别为0.863 3和0.926 6;在Refuge(retinal fundus glaucoma challenge)数据集中,视盘分割的JC和F-measure分别为0.929 8和0.963 6,视杯分割的JC和F-measure分别为0.828 8和0.906 3;在RIM-ONE(retinal image database for optic nerve evaluation)-R1数据集中,视盘分割的JC和F-measure分别为0.929 0和0.962 8。在4个数据集上结果均优于对比算法,性能显著提升。此外,针对网络中提出的模块分别做了消融实验,验证了RCPA-Net中各个模块的有效性。结论实验结果表明,RCPA-Net提升了视盘和视杯分割精度,预测图像更接近真实标签结果,同时跨数据集测试结果证明了RCPA-Net具有良好的泛化能力。关键词:视杯视盘分割;深度学习;注意力机制;残差空洞卷积;路径增强264|396|1更新时间:2024-03-13 -
 摘要:目的高度适形放射治疗是常用的癌症治疗方法,该方法的有效性依赖于对癌组织和周边多个危及器官(organ at risk,OAR)解剖结构的精确刻画,因此研究三维图像多器官的高精度自动分割具有重要意义。以视觉Transformer(vision Transformer,ViT)和卷积神经网络(convolutional neural network,CNN)结合为代表的三维医学图像分割方法表现出了丰富的应用优势。然而,这类方法往往忽略同一尺度内和不同尺度间的信息交互,使得CNN和ViT特征的提取和融合受限。本文提出一种端到端多器官分割网络LoGoFUNet(local-global-features fusion UNet),旨在应对现有方法的缺陷。方法首先,针对单一器官分割,提出在同一尺度下并行提取并融合CNN和ViT特征的LoGoF(local-global-features fusion)编码器,并构建了一个端到端的三维医学图像分割多尺度网络M0。此外,考虑到器官内部以及器官之间的相互关系,该方法在M0网络的基础上设计并引入了多尺度交互(multi-scale interaction,MSI)模块和注意力指导(attention guidance,AG)结构,最终形成了LoGoFUNet。结果在Synapse数据集和SegTHOR(segmentation of thoracic organs at risk)数据集上,本文方法相比于表现第2的模型, DSC(Dice similarity cofficient)指标分别提高了2.94%和4.93%,而HD95(Hausdorff distance_95)指标则分别降低了8.55和2.45,切实提升了多器官分割任务的性能表现。在ACDC(automatic cardiac diagnosis challenge)数据集上,3D分割方法的适用性大多较差,但LoGoFUNet依然得到了比2D先进方法更好的结果,说明其对数据集的适应能力更强。结论该方法的分割模型综合尺度内和尺度间的信息交互,具有更好的分割结果,且在数据集上的泛化性更好。关键词:多器官分割;深度神经网络(DNN);视觉Transformer(ViT);局部全局特征;多尺度交互(MSI)147|386|0更新时间:2024-03-13
摘要:目的高度适形放射治疗是常用的癌症治疗方法,该方法的有效性依赖于对癌组织和周边多个危及器官(organ at risk,OAR)解剖结构的精确刻画,因此研究三维图像多器官的高精度自动分割具有重要意义。以视觉Transformer(vision Transformer,ViT)和卷积神经网络(convolutional neural network,CNN)结合为代表的三维医学图像分割方法表现出了丰富的应用优势。然而,这类方法往往忽略同一尺度内和不同尺度间的信息交互,使得CNN和ViT特征的提取和融合受限。本文提出一种端到端多器官分割网络LoGoFUNet(local-global-features fusion UNet),旨在应对现有方法的缺陷。方法首先,针对单一器官分割,提出在同一尺度下并行提取并融合CNN和ViT特征的LoGoF(local-global-features fusion)编码器,并构建了一个端到端的三维医学图像分割多尺度网络M0。此外,考虑到器官内部以及器官之间的相互关系,该方法在M0网络的基础上设计并引入了多尺度交互(multi-scale interaction,MSI)模块和注意力指导(attention guidance,AG)结构,最终形成了LoGoFUNet。结果在Synapse数据集和SegTHOR(segmentation of thoracic organs at risk)数据集上,本文方法相比于表现第2的模型, DSC(Dice similarity cofficient)指标分别提高了2.94%和4.93%,而HD95(Hausdorff distance_95)指标则分别降低了8.55和2.45,切实提升了多器官分割任务的性能表现。在ACDC(automatic cardiac diagnosis challenge)数据集上,3D分割方法的适用性大多较差,但LoGoFUNet依然得到了比2D先进方法更好的结果,说明其对数据集的适应能力更强。结论该方法的分割模型综合尺度内和尺度间的信息交互,具有更好的分割结果,且在数据集上的泛化性更好。关键词:多器官分割;深度神经网络(DNN);视觉Transformer(ViT);局部全局特征;多尺度交互(MSI)147|386|0更新时间:2024-03-13 -
 摘要:目的支气管超声弹性成像具有丰富的通道语义信息,精准的分割纵膈淋巴结对诊断肺癌是否转移具有重要意义,也对癌症的分期和治疗有着重要作用。目前,超声弹性图像分割研究较少,没有充分挖掘图像通道特征之间的关系。因此,提出一种结合注意力机制的多尺度融合增强的纵膈淋巴结超声弹性图像分割U-Net(attention-based multi-scale fusion enhanced ultrasound elastic images segmentation network for mediastinal lymph node, AMFE-UNet)。方法首先,考虑到图像可以提供纵膈淋巴结的位置和通道信息,设计密集卷积网络(dense convolutional network, DenseNet)作为模型编码器;其次,结合注意力机制和空洞卷积设计多尺度融合增强解码器,从多尺度和范围对结节的边界和纹理进行建模;最后,用选择性内核网络设计跳跃连接,将编码器的中间特征与解码器的输出特征充分融合。根据解码器特征进行数值或通道融合的方式不同,将AMFE-UNet分为A和B两个子型。结果在超声弹性图像数据集上进行对比实验与验证。结果表明AMFE-UNet平均Dice系数达到86.593%,较U-Net提升了1.986%;相较于对比模型,AMFE-UNet A在Dice、精确度和特异度指标上均达到了最优;AMFE-UNet B在交并比、灵敏度和豪斯多夫距离指标上也达到最优。消融实验和可视化分析表明提出的改进方法具有明显的提升效果。结论本文通过密集卷积网络设计分割模型编码器,并利用通道注意力机制优化模型特征恢复和连接过程,在超声弹性图像中获得了良好的纵膈淋巴结分割效果,具有较高的临床应用价值。代码链接:https://github.com/Philo-github/AMFE-UNet。关键词:超声弹性成像(UE);纵膈淋巴结;实例分割;U-Net;通道注意力机制160|306|0更新时间:2024-03-13
摘要:目的支气管超声弹性成像具有丰富的通道语义信息,精准的分割纵膈淋巴结对诊断肺癌是否转移具有重要意义,也对癌症的分期和治疗有着重要作用。目前,超声弹性图像分割研究较少,没有充分挖掘图像通道特征之间的关系。因此,提出一种结合注意力机制的多尺度融合增强的纵膈淋巴结超声弹性图像分割U-Net(attention-based multi-scale fusion enhanced ultrasound elastic images segmentation network for mediastinal lymph node, AMFE-UNet)。方法首先,考虑到图像可以提供纵膈淋巴结的位置和通道信息,设计密集卷积网络(dense convolutional network, DenseNet)作为模型编码器;其次,结合注意力机制和空洞卷积设计多尺度融合增强解码器,从多尺度和范围对结节的边界和纹理进行建模;最后,用选择性内核网络设计跳跃连接,将编码器的中间特征与解码器的输出特征充分融合。根据解码器特征进行数值或通道融合的方式不同,将AMFE-UNet分为A和B两个子型。结果在超声弹性图像数据集上进行对比实验与验证。结果表明AMFE-UNet平均Dice系数达到86.593%,较U-Net提升了1.986%;相较于对比模型,AMFE-UNet A在Dice、精确度和特异度指标上均达到了最优;AMFE-UNet B在交并比、灵敏度和豪斯多夫距离指标上也达到最优。消融实验和可视化分析表明提出的改进方法具有明显的提升效果。结论本文通过密集卷积网络设计分割模型编码器,并利用通道注意力机制优化模型特征恢复和连接过程,在超声弹性图像中获得了良好的纵膈淋巴结分割效果,具有较高的临床应用价值。代码链接:https://github.com/Philo-github/AMFE-UNet。关键词:超声弹性成像(UE);纵膈淋巴结;实例分割;U-Net;通道注意力机制160|306|0更新时间:2024-03-13 -
 摘要:目的锥形束计算机断层扫描(cone beam computer tomography, CBCT)已成为口腔诊疗领域中最常用的一项医学影像技术。由于CBCT图像本身对比度低且牙齿形状复杂,在进行牙齿分割时容易导致分割边界模糊、牙齿根部错误分割的问题。现有方法往往无法达到预期效果,并且基于深度学习的分割网络在分割精度等性能提升到一定程度后存在生梯度爆炸、过拟合以及无法关注图像全局信息等限制。然而,牙齿分割在医生制定诊断和治疗计划方面至关重要。为了应对这一问题,提出了一种名为MF-CA Net的牙齿分割模型,以提高牙齿分割的准确性和鲁棒性。方法MF-CA Net模型引入了多尺度特征提取模块(multi-scale feature extraction module, MFEM)和CA(coordinate attention)注意力机制,这些模块使网络能够准确地捕捉感兴趣的牙齿区域,并提取丰富而密集的多尺度特征信息,从而有效地指导分割任务。特别是在牙根分割方面,这些模块能够显著提高分割的精度。为了进一步提升分割算法的性能,还引入了联合损失函数,该损失函数综合考虑了像素级、局部级和全局级3个方向的牙齿边缘分割,以提高算法的准确性和稳健性。结果实验在数据集上对MF-CA Net模型与6种主流方法进行了比较。实验结果表明,相较于其他分割方法,MF-CA Net模型在各项评价指标上都取得了显著的提升。尽管在精度(accuracy)指标上稍低于DeeplabV3+,但在Dice评价指标上达到了0.949 5的高分数,相比PyConvU-Net提高了4%,相对于DeeplabV3+提高了约4%,对比U-Net提高了约16%。此外,平均交并比(mean intersection-over-union,mIoU)指标提升了3%~11%,F2值提升了5%。结论本文提出的MF-CA Net网络模型可以实现对牙齿的精确分割。关键词:深度学习;锥形束计算机断层扫描(CBCT);牙齿分割;注意力机制;多尺度信息;损失函数;分割精度186|811|1更新时间:2024-03-13
摘要:目的锥形束计算机断层扫描(cone beam computer tomography, CBCT)已成为口腔诊疗领域中最常用的一项医学影像技术。由于CBCT图像本身对比度低且牙齿形状复杂,在进行牙齿分割时容易导致分割边界模糊、牙齿根部错误分割的问题。现有方法往往无法达到预期效果,并且基于深度学习的分割网络在分割精度等性能提升到一定程度后存在生梯度爆炸、过拟合以及无法关注图像全局信息等限制。然而,牙齿分割在医生制定诊断和治疗计划方面至关重要。为了应对这一问题,提出了一种名为MF-CA Net的牙齿分割模型,以提高牙齿分割的准确性和鲁棒性。方法MF-CA Net模型引入了多尺度特征提取模块(multi-scale feature extraction module, MFEM)和CA(coordinate attention)注意力机制,这些模块使网络能够准确地捕捉感兴趣的牙齿区域,并提取丰富而密集的多尺度特征信息,从而有效地指导分割任务。特别是在牙根分割方面,这些模块能够显著提高分割的精度。为了进一步提升分割算法的性能,还引入了联合损失函数,该损失函数综合考虑了像素级、局部级和全局级3个方向的牙齿边缘分割,以提高算法的准确性和稳健性。结果实验在数据集上对MF-CA Net模型与6种主流方法进行了比较。实验结果表明,相较于其他分割方法,MF-CA Net模型在各项评价指标上都取得了显著的提升。尽管在精度(accuracy)指标上稍低于DeeplabV3+,但在Dice评价指标上达到了0.949 5的高分数,相比PyConvU-Net提高了4%,相对于DeeplabV3+提高了约4%,对比U-Net提高了约16%。此外,平均交并比(mean intersection-over-union,mIoU)指标提升了3%~11%,F2值提升了5%。结论本文提出的MF-CA Net网络模型可以实现对牙齿的精确分割。关键词:深度学习;锥形束计算机断层扫描(CBCT);牙齿分割;注意力机制;多尺度信息;损失函数;分割精度186|811|1更新时间:2024-03-13 -
 摘要:目的计算机辅助技术以及显微病理图像处理技术给病理诊断带来了极大的便利。病理图像分割是常用的技术手段,可用于划分病灶和背景组织。开发高精度的分割算法,需要大量精准标注的数字病理图像,但是标注过程耗时费力,具有精准标注的病理图像稀少。而且,病理图像非常复杂,对病理组织分割算法的鲁棒性和泛化性要求极高。因此,本文提出一种基于图网络的病理图像分割框架。方法该框架有全监督图网络(full supervised graph network,FSGNet)和弱监督图网络(weakly supervised graph network,WSGNet)两种模式,以适应不同标注量的数据集以及多种应用场景的精度需求。通过图网络学习病理组织的不规则形态,FSGNet能达到较高的分割精度;WSGNet采用超像素级推理,仅需要稀疏点标注就能分割病理组织。结果本文在两个公开数据集GlaS(Gland Segmentation Challenge Dataset)(测试集分为A部分和B部分)、CRAG(colorectal adenocarcinoma gland)和一个私有数据集LUSC(lung squamous cell carcinoma)上进行测试。最终,本文所提框架的两种模式在3个数据集中整体像素级分类精度(overall accuracy,OA)和Dice指数(Dice index,DI)均优于对比算法,且FSGNet在GlaS B数据集中效果最明显,分别提升了1.61%和2.26%,WSGNet在CRAG数据集中较先进算法提升效果最明显,分别提升了2.63%和2.54%。结论本文所提框架的两种模式均优于多种目前先进的算法,表现出较好的泛化性和鲁棒性。关键词:病理图像分割;图卷积网络(GCN);全监督学习;弱监督学习;点标签145|775|1更新时间:2024-03-13
摘要:目的计算机辅助技术以及显微病理图像处理技术给病理诊断带来了极大的便利。病理图像分割是常用的技术手段,可用于划分病灶和背景组织。开发高精度的分割算法,需要大量精准标注的数字病理图像,但是标注过程耗时费力,具有精准标注的病理图像稀少。而且,病理图像非常复杂,对病理组织分割算法的鲁棒性和泛化性要求极高。因此,本文提出一种基于图网络的病理图像分割框架。方法该框架有全监督图网络(full supervised graph network,FSGNet)和弱监督图网络(weakly supervised graph network,WSGNet)两种模式,以适应不同标注量的数据集以及多种应用场景的精度需求。通过图网络学习病理组织的不规则形态,FSGNet能达到较高的分割精度;WSGNet采用超像素级推理,仅需要稀疏点标注就能分割病理组织。结果本文在两个公开数据集GlaS(Gland Segmentation Challenge Dataset)(测试集分为A部分和B部分)、CRAG(colorectal adenocarcinoma gland)和一个私有数据集LUSC(lung squamous cell carcinoma)上进行测试。最终,本文所提框架的两种模式在3个数据集中整体像素级分类精度(overall accuracy,OA)和Dice指数(Dice index,DI)均优于对比算法,且FSGNet在GlaS B数据集中效果最明显,分别提升了1.61%和2.26%,WSGNet在CRAG数据集中较先进算法提升效果最明显,分别提升了2.63%和2.54%。结论本文所提框架的两种模式均优于多种目前先进的算法,表现出较好的泛化性和鲁棒性。关键词:病理图像分割;图卷积网络(GCN);全监督学习;弱监督学习;点标签145|775|1更新时间:2024-03-13 -
 摘要:目的腺体医学图像分割是将医学图像中的腺体区域与周围组织分离出来的过程,对分割精度有极高要求。传统模型在对腺体医学图像分割时,因腺体形态多样性和小目标众多的特点,容易出现分割不精细或误分割等问题,对此根据腺体医学图像的特点对U-Net型通道变换网络分割模型进行改进,实现对腺体图像更高精度分割。方法首先在U-Net型通道变换网络的编码器前端加入ASPP_SE(spatial pyramid pooling_squeeze-and-excitation networks)模块与ConvBatchNorm模块的组合,在增强编码器提取小目标特征信息能力的同时,防止模型训练出现过拟合现象。其次在编码器与跳跃连接中嵌入简化后的密集连接,增强编码器相邻模块特征信息融合。最后在通道融合变换器(channel cross fusion with Transformer,CCT)中加入细化器,将自注意力图投射到更高维度,提高自注意机制能力,增强编码器全局模块特征信息融合。简化后的密集连接与CCT结合使用,模型可以达到更好效果。结果改进算法在公开腺体数据集MoNuSeg(multi-organ nuclei segmentation challenge)和Glas(gland segmentation)上进行实验。以Dice系数和IoU(intersection over union)系数为主要指标,在MoNuSeg的结果为80.55%和67.32%,在Glas数据集的结果为92.23%和86.39%,比原U-Net型通道变换网络分别提升了0.88%、1.06%和1.53%、2.43%。结论本文提出的改进算法在腺体医学分割上优于其他现有分割算法,能满足临床医学腺体图像分割要求。关键词:医学图像分割;U-Net型通道变换网络(UCTransNet);密集连接;注意力机制;细化器173|894|0更新时间:2024-03-13
摘要:目的腺体医学图像分割是将医学图像中的腺体区域与周围组织分离出来的过程,对分割精度有极高要求。传统模型在对腺体医学图像分割时,因腺体形态多样性和小目标众多的特点,容易出现分割不精细或误分割等问题,对此根据腺体医学图像的特点对U-Net型通道变换网络分割模型进行改进,实现对腺体图像更高精度分割。方法首先在U-Net型通道变换网络的编码器前端加入ASPP_SE(spatial pyramid pooling_squeeze-and-excitation networks)模块与ConvBatchNorm模块的组合,在增强编码器提取小目标特征信息能力的同时,防止模型训练出现过拟合现象。其次在编码器与跳跃连接中嵌入简化后的密集连接,增强编码器相邻模块特征信息融合。最后在通道融合变换器(channel cross fusion with Transformer,CCT)中加入细化器,将自注意力图投射到更高维度,提高自注意机制能力,增强编码器全局模块特征信息融合。简化后的密集连接与CCT结合使用,模型可以达到更好效果。结果改进算法在公开腺体数据集MoNuSeg(multi-organ nuclei segmentation challenge)和Glas(gland segmentation)上进行实验。以Dice系数和IoU(intersection over union)系数为主要指标,在MoNuSeg的结果为80.55%和67.32%,在Glas数据集的结果为92.23%和86.39%,比原U-Net型通道变换网络分别提升了0.88%、1.06%和1.53%、2.43%。结论本文提出的改进算法在腺体医学分割上优于其他现有分割算法,能满足临床医学腺体图像分割要求。关键词:医学图像分割;U-Net型通道变换网络(UCTransNet);密集连接;注意力机制;细化器173|894|0更新时间:2024-03-13 -
 摘要:目的由于乳腺肿瘤病灶的隐蔽性强且极易转移,目前采用医学辅助诊断(computer-aided diagnosis, CAD)来尽早地发现肿瘤并诊断。然而,医学图像数据量少且标注昂贵,导致全监督场景下的基于深度学习的X-ray乳腺肿瘤检测方法的性能非常有限,且模型泛化能力弱;此外,噪声产生的域偏移(domain shift)也降低了不同环境下肿瘤检测的性能。针对上述挑战,提出一种单域泛化X-ray乳腺肿瘤检测方法。方法提出了一种单域泛化模型(single-domain generalization model, SDGM)进行X-ray乳腺肿瘤检测,采用ResNet-50(residual network-50)作为主干特征提取网络,设计了域特征增强模块(domain feature enhancement module, DFEM)来有效融合上采样与下采样中的全局信息以抑制噪声,然后在检测头处设计了实例泛化模块(instance generalization module,IGM),对每个实例的类别语义信息进行正则化与白化处理来提升模型的泛化性能,通过学习少量的有标注医学图像对不可预见的噪声图像进行迁移学习,缓解因有标记医学图像匮乏而导致的泛化能力弱的问题;同时避免模型的冗余训练,进一步增强模型在不同环境下的鲁棒性。结果为了验证所提模型SDGM的域内泛化性能,将INbreast的单域X-ray图像作为训练集,多种域偏移的图像为测试集,实验结果表明在域内泛化场景下SDGM性能优于FCOS(fully convolutional one-stage object detection)、Cascade-RCNN、FoveaBox、ATSS、TOOD(task-aligned one-stage object detection)、PVTv2-Transformer等方法,泛化性能比baseline方法的mAP(mean average precision)提升了9.7%;在训练数据量更小的前提下,单域泛化性能优于INbreast全监督场景下的baseline方法的性能。此外,为了进一步验证SDGM在不同数据集的域间的泛化性能,将CBIS-DDSM(curated breast imaging subset of DDSM)数据集作为训练集而多种域偏移的INbreast数据集作为测试集进行实验,所提方法SDGM比baseline方法提升了5.8%。结论所提单域泛化模型SDGM能够有效缓解域偏移对模型性能的影响,并能够针对医学数据域未知且数量少的特点进行泛化,能够较灵活地迁移至临床实践中未知域下的噪声场景。关键词:X-ray乳腺肿瘤检测;单域泛化;域偏移;正则化与白化;特征增强155|741|0更新时间:2024-03-13
摘要:目的由于乳腺肿瘤病灶的隐蔽性强且极易转移,目前采用医学辅助诊断(computer-aided diagnosis, CAD)来尽早地发现肿瘤并诊断。然而,医学图像数据量少且标注昂贵,导致全监督场景下的基于深度学习的X-ray乳腺肿瘤检测方法的性能非常有限,且模型泛化能力弱;此外,噪声产生的域偏移(domain shift)也降低了不同环境下肿瘤检测的性能。针对上述挑战,提出一种单域泛化X-ray乳腺肿瘤检测方法。方法提出了一种单域泛化模型(single-domain generalization model, SDGM)进行X-ray乳腺肿瘤检测,采用ResNet-50(residual network-50)作为主干特征提取网络,设计了域特征增强模块(domain feature enhancement module, DFEM)来有效融合上采样与下采样中的全局信息以抑制噪声,然后在检测头处设计了实例泛化模块(instance generalization module,IGM),对每个实例的类别语义信息进行正则化与白化处理来提升模型的泛化性能,通过学习少量的有标注医学图像对不可预见的噪声图像进行迁移学习,缓解因有标记医学图像匮乏而导致的泛化能力弱的问题;同时避免模型的冗余训练,进一步增强模型在不同环境下的鲁棒性。结果为了验证所提模型SDGM的域内泛化性能,将INbreast的单域X-ray图像作为训练集,多种域偏移的图像为测试集,实验结果表明在域内泛化场景下SDGM性能优于FCOS(fully convolutional one-stage object detection)、Cascade-RCNN、FoveaBox、ATSS、TOOD(task-aligned one-stage object detection)、PVTv2-Transformer等方法,泛化性能比baseline方法的mAP(mean average precision)提升了9.7%;在训练数据量更小的前提下,单域泛化性能优于INbreast全监督场景下的baseline方法的性能。此外,为了进一步验证SDGM在不同数据集的域间的泛化性能,将CBIS-DDSM(curated breast imaging subset of DDSM)数据集作为训练集而多种域偏移的INbreast数据集作为测试集进行实验,所提方法SDGM比baseline方法提升了5.8%。结论所提单域泛化模型SDGM能够有效缓解域偏移对模型性能的影响,并能够针对医学数据域未知且数量少的特点进行泛化,能够较灵活地迁移至临床实践中未知域下的噪声场景。关键词:X-ray乳腺肿瘤检测;单域泛化;域偏移;正则化与白化;特征增强155|741|0更新时间:2024-03-13 -
 摘要:目的乳腺癌在女性中是致病严重且发病率较高的疾病,早期乳腺癌症检测是全世界需要解决的重要难题。如今乳腺癌的诊断方法有临床检查、影像学检查和组织病理学检查。在影像学检查中常用的方式是X光、CT(computed tomography)、磁共振等,其中乳房X光片已用于检测早期癌症,然而从本地乳房X线照片中手动分割肿块是一项非常耗时且容易出错的任务。因此,需要一个集成的计算机辅助诊断(computer aided diagnosis,CAD)系统来帮助放射科医生进行自动和精确的乳房肿块识别。方法基于深度学习图像分割框架,对比了不同图像分割模型,同时在UNet结构上采用了Swin架构来代替分割任务中的下采样和上采样过程,实现局部和全局特征的交互。利用Transformer来获取更多的全局信息和不同层次特征来取代短连接,实现多尺度特征融合,从而精准分割。在分割模型阶段也采用了Multi-Attention ResNet分类网络对癌症区域的等级识别,更好地对乳腺癌进行诊断医疗。结果本文模型在乳腺癌X光数据集INbreast上实现肿块的准确分割,IoU(intersection over union)值达到95.58%,Dice系数为93.45%,与其他的分割模型相比提高了4%~6%,将得到的二值化分割图像进行四分类,Accuracy值达到95.24%。结论本文提出的TransAS-UNet图像分割方法具有良好的性能和临床意义,该方法优于对比的二维图像医学分割方法。关键词:乳腺癌;深度学习;医学图像分割;TransAS-UNet;图像分类367|568|0更新时间:2024-03-13
摘要:目的乳腺癌在女性中是致病严重且发病率较高的疾病,早期乳腺癌症检测是全世界需要解决的重要难题。如今乳腺癌的诊断方法有临床检查、影像学检查和组织病理学检查。在影像学检查中常用的方式是X光、CT(computed tomography)、磁共振等,其中乳房X光片已用于检测早期癌症,然而从本地乳房X线照片中手动分割肿块是一项非常耗时且容易出错的任务。因此,需要一个集成的计算机辅助诊断(computer aided diagnosis,CAD)系统来帮助放射科医生进行自动和精确的乳房肿块识别。方法基于深度学习图像分割框架,对比了不同图像分割模型,同时在UNet结构上采用了Swin架构来代替分割任务中的下采样和上采样过程,实现局部和全局特征的交互。利用Transformer来获取更多的全局信息和不同层次特征来取代短连接,实现多尺度特征融合,从而精准分割。在分割模型阶段也采用了Multi-Attention ResNet分类网络对癌症区域的等级识别,更好地对乳腺癌进行诊断医疗。结果本文模型在乳腺癌X光数据集INbreast上实现肿块的准确分割,IoU(intersection over union)值达到95.58%,Dice系数为93.45%,与其他的分割模型相比提高了4%~6%,将得到的二值化分割图像进行四分类,Accuracy值达到95.24%。结论本文提出的TransAS-UNet图像分割方法具有良好的性能和临床意义,该方法优于对比的二维图像医学分割方法。关键词:乳腺癌;深度学习;医学图像分割;TransAS-UNet;图像分类367|568|0更新时间:2024-03-13 -
 摘要:目的前列腺图像精确分割对评估患者健康和制定治疗方案至关重要。然而传统U-Net模型在前列腺MR(magnetic resonance)图像分割上存在过拟合、边缘信息丢失等问题。针对上述问题,提出一种改进的U-Net 2D分割模型,旨在增强边缘信息、降低噪声影响,进而提高前列腺分割效果。方法为缓解过拟合现象,新模型通过对标准U-Net架构进行修改,将普通卷积替换为深度可分离卷积,重新设计编码器和解码器结构,降低模型参数量;为保存分割结果中的边缘信息,新模型通过ECA(efficient channel attention )注意力机制对U-Net解码器特征进行优化,以放大并保存小尺度目标的信息,并提出边缘信息模块和边缘信息金字塔模块,恢复并增强边缘信息,以缓解频繁下采样带来的边缘信息衰退以及编码器和解码器特征之间的语义差距问题;利用空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)模块对特征进行重采样,扩大感受野,以消除特征噪声。结果在PROMISE12(prostate MR image segmentation 2012)数据集上验证模型的有效性,并与6种基于U-Net的图像分割方法进行对比,实验证明其分割结果在Dice系数(Dice coefficient,DC)、HD95(95% Hausdorff distance)、召回率(recall)、Jaccard系数和准确度(accuracy)等指标上均有提高,DC较U-Net提高了8.87%,HD95较U-Net++和Attention U-Net分别降低了12.04 mm和3.03 mm。结论提出一种基于边缘信息增强的前列腺MR图像分割网络(attention mechanism and marginal information fusion U-Net,AIM-U-Net),其生成的分割图像具有丰富的边缘信息和空间信息,其主观效果和客观评价指标均优于其他同类方法,为提高临床诊断的准确度提供帮助。关键词:医学图像分割;前列腺;MR图像;U-Net;边缘信息170|712|0更新时间:2024-03-13
摘要:目的前列腺图像精确分割对评估患者健康和制定治疗方案至关重要。然而传统U-Net模型在前列腺MR(magnetic resonance)图像分割上存在过拟合、边缘信息丢失等问题。针对上述问题,提出一种改进的U-Net 2D分割模型,旨在增强边缘信息、降低噪声影响,进而提高前列腺分割效果。方法为缓解过拟合现象,新模型通过对标准U-Net架构进行修改,将普通卷积替换为深度可分离卷积,重新设计编码器和解码器结构,降低模型参数量;为保存分割结果中的边缘信息,新模型通过ECA(efficient channel attention )注意力机制对U-Net解码器特征进行优化,以放大并保存小尺度目标的信息,并提出边缘信息模块和边缘信息金字塔模块,恢复并增强边缘信息,以缓解频繁下采样带来的边缘信息衰退以及编码器和解码器特征之间的语义差距问题;利用空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)模块对特征进行重采样,扩大感受野,以消除特征噪声。结果在PROMISE12(prostate MR image segmentation 2012)数据集上验证模型的有效性,并与6种基于U-Net的图像分割方法进行对比,实验证明其分割结果在Dice系数(Dice coefficient,DC)、HD95(95% Hausdorff distance)、召回率(recall)、Jaccard系数和准确度(accuracy)等指标上均有提高,DC较U-Net提高了8.87%,HD95较U-Net++和Attention U-Net分别降低了12.04 mm和3.03 mm。结论提出一种基于边缘信息增强的前列腺MR图像分割网络(attention mechanism and marginal information fusion U-Net,AIM-U-Net),其生成的分割图像具有丰富的边缘信息和空间信息,其主观效果和客观评价指标均优于其他同类方法,为提高临床诊断的准确度提供帮助。关键词:医学图像分割;前列腺;MR图像;U-Net;边缘信息170|712|0更新时间:2024-03-13 -
 摘要:目的评估肿瘤的恶性程度是临床诊断中的一项具有挑战性的任务。因脑肿瘤的磁共振成像呈现出不同的形状和大小,肿瘤的边缘模糊不清,导致肿瘤分割具有挑战性。为有效辅助临床医生进行肿瘤评估和诊断,提高脑肿瘤分割精度,提出一种自适应模态融合双编码器分割网络D3D-Net(double3DNet)。方法本文提出的网络使用多个编码器和特定的特征融合的策略,采用双层编码器用于充分提取不同模态组合的图像特征,并在编码部分利用特定的融合策略将来自上下两个子编码器的特征信息充分融合,去除冗余特征。此外,在编码解码部分使用扩张多纤维模块在不增加计算开销的前提下捕获多尺度的图像特征,并引入注意力门控以保留细节信息。结果采用BraTS2018(brain tumor segmentation 2018)、BraTS2019和BraTS2020数据集对D3D-Net网络进行训练和测试,并进行了消融实验。在BraTS2018数据集上,本模型在增强肿瘤、整个肿瘤、肿瘤核心的平均Dice值与3D U-Net相比分别提高了3.6%,1.0%,11.5%,与DMF-Net(dilated multi-fiber network)相比分别提高了2.2%,0.2%,0.1%。在BraTS2019数据集上进行实验,增强肿瘤、整个肿瘤、肿瘤核心的平均Dice值与3D U-Net相比分别提高了2.2%,0.6%,7.1%。在BraTS2020数据集上,增强肿瘤、整个肿瘤、肿瘤核心的平均Dice值与3D U-Net相比分别提高了2.5%,1.9%,2.2%。结论本文提出的双编码器融合网络能够充分融合多模态特征可以有效地分割小肿瘤部位。关键词:脑肿瘤分割;多模态融合;双编码器;MRI;注意力门控245|891|1更新时间:2024-03-13
摘要:目的评估肿瘤的恶性程度是临床诊断中的一项具有挑战性的任务。因脑肿瘤的磁共振成像呈现出不同的形状和大小,肿瘤的边缘模糊不清,导致肿瘤分割具有挑战性。为有效辅助临床医生进行肿瘤评估和诊断,提高脑肿瘤分割精度,提出一种自适应模态融合双编码器分割网络D3D-Net(double3DNet)。方法本文提出的网络使用多个编码器和特定的特征融合的策略,采用双层编码器用于充分提取不同模态组合的图像特征,并在编码部分利用特定的融合策略将来自上下两个子编码器的特征信息充分融合,去除冗余特征。此外,在编码解码部分使用扩张多纤维模块在不增加计算开销的前提下捕获多尺度的图像特征,并引入注意力门控以保留细节信息。结果采用BraTS2018(brain tumor segmentation 2018)、BraTS2019和BraTS2020数据集对D3D-Net网络进行训练和测试,并进行了消融实验。在BraTS2018数据集上,本模型在增强肿瘤、整个肿瘤、肿瘤核心的平均Dice值与3D U-Net相比分别提高了3.6%,1.0%,11.5%,与DMF-Net(dilated multi-fiber network)相比分别提高了2.2%,0.2%,0.1%。在BraTS2019数据集上进行实验,增强肿瘤、整个肿瘤、肿瘤核心的平均Dice值与3D U-Net相比分别提高了2.2%,0.6%,7.1%。在BraTS2020数据集上,增强肿瘤、整个肿瘤、肿瘤核心的平均Dice值与3D U-Net相比分别提高了2.5%,1.9%,2.2%。结论本文提出的双编码器融合网络能够充分融合多模态特征可以有效地分割小肿瘤部位。关键词:脑肿瘤分割;多模态融合;双编码器;MRI;注意力门控245|891|1更新时间:2024-03-13
图像分析和识别
-
 摘要:目的超声医师手动探查与采集胎儿心脏切面图像时,常因频繁的手动暂停与截图操作而错失心脏切面最佳获取时机。而单纯采用深层视觉目标检测或分类网络自动获取切面时,因无法确保网络重点关注切面图像中相对较小的心脏区域的细粒度特征,导致高误检率;另外,不同的心脏解剖部件的最佳成像时刻也常常不同步。针对上述问题,提出一种目标检测与分类网络相结合,同时融合关键帧间时序关系的标准四腔心(four-chamber,4CH)切面图像自动获取算法。方法首先,利用自行构建的胎儿心脏超声切面数据集训练目标检测网络,实现四腔心区域和降主动脉区域的快速准确定位。接着,当检测到在一定时间窗内的视频帧存在降主动脉区域时,将包含四腔心目标的候选区域提取后送入利用自建的标准四腔心区域图像集训练好的分类网络,进一步分类出标准四腔心区域。最后,通过时序关系确定出可靠的降主动脉区域,将可靠降主动脉的检测置信度及同一时间窗内各个切面图像中四腔心区域在分类模型中的输出,加权计算得到标准四腔心切面图像的得分。结果采用本文构建的数据集训练的YOLOv5x(you only look once version 5 extra large)和Darknet53模型,在四腔心区域和降主动脉区域的检测任务上分别达到94.0%的mAP@0.5和61.1%的mAP@[.5∶.95],以及69.5%的recall@0.5-0.95;在四腔心区域标准性分类任务上TOP-1准确率达到92.4%。将检测与分类模块结合后,系统对四腔心区域的误检率降低了29.38%。结论目标检测与分类网络相结合的策略及帧间时序信息的加入能够有效调和错检与漏检间的矛盾,同时大幅降低误检率。另外,所提算法除可自动获取标准的四腔心切面图像外,还可同时给出最佳切面,具有较好的实际应用价值。关键词:深度学习;卷积神经网络(CNN);目标检测;图像分类;帧间时序关系206|485|0更新时间:2024-03-13
摘要:目的超声医师手动探查与采集胎儿心脏切面图像时,常因频繁的手动暂停与截图操作而错失心脏切面最佳获取时机。而单纯采用深层视觉目标检测或分类网络自动获取切面时,因无法确保网络重点关注切面图像中相对较小的心脏区域的细粒度特征,导致高误检率;另外,不同的心脏解剖部件的最佳成像时刻也常常不同步。针对上述问题,提出一种目标检测与分类网络相结合,同时融合关键帧间时序关系的标准四腔心(four-chamber,4CH)切面图像自动获取算法。方法首先,利用自行构建的胎儿心脏超声切面数据集训练目标检测网络,实现四腔心区域和降主动脉区域的快速准确定位。接着,当检测到在一定时间窗内的视频帧存在降主动脉区域时,将包含四腔心目标的候选区域提取后送入利用自建的标准四腔心区域图像集训练好的分类网络,进一步分类出标准四腔心区域。最后,通过时序关系确定出可靠的降主动脉区域,将可靠降主动脉的检测置信度及同一时间窗内各个切面图像中四腔心区域在分类模型中的输出,加权计算得到标准四腔心切面图像的得分。结果采用本文构建的数据集训练的YOLOv5x(you only look once version 5 extra large)和Darknet53模型,在四腔心区域和降主动脉区域的检测任务上分别达到94.0%的mAP@0.5和61.1%的mAP@[.5∶.95],以及69.5%的recall@0.5-0.95;在四腔心区域标准性分类任务上TOP-1准确率达到92.4%。将检测与分类模块结合后,系统对四腔心区域的误检率降低了29.38%。结论目标检测与分类网络相结合的策略及帧间时序信息的加入能够有效调和错检与漏检间的矛盾,同时大幅降低误检率。另外,所提算法除可自动获取标准的四腔心切面图像外,还可同时给出最佳切面,具有较好的实际应用价值。关键词:深度学习;卷积神经网络(CNN);目标检测;图像分类;帧间时序关系206|485|0更新时间:2024-03-13 -
 摘要:目的针对联邦学习中多中心医学数据的异质性特征导致全局模型性能不佳的问题,提出一种基于特征迁移的自适应个性化联邦学习算法(adaptive personalized federated learning via feature transfer, APFFT)。方法首先,为降低全局模型中异质性特征信息影响,提出鲁棒特征选择网络(robust feature selection network, RFS-Net)构建个性化本地模型。RFS-Net通过学习两个迁移权重分别确定全局模型向本地模型迁移时的有效特征以及特征迁移的目的地,并构建基于迁移权重的迁移损失函数以加强本地模型对全局模型中有效特征的注意力,从而构建个性化本地模型。然后,为过滤各本地模型中异质性特征信息,利用自适应聚合网络(adaptive aggregation network, AA-Net)聚合全局模型。AA-Net基于全局模型交叉熵变化更新迁移权重并构建聚合损失,使各本地模型向全局模型迁移鲁棒特征,提高全局模型的特征表达能力。结果在3种医学图像分类任务上与4种现有方法进行比较实验,在肺结核肺腺癌分类任务中,各中心曲线下面积(area under the curve,AUC)分别为0.791 5, 0.798 1, 0.760 0, 0.705 7和0.806 9;在乳腺癌组织学图像分类任务中,各中心准确率分别为0.984 9、0.980 8、0.983 5、0.982 6和0.983 4;在肺结节良恶性分类任务中,各中心AUC分别为 0.809 7, 0.849 8, 0.784 8和0.792 3。结论所提出的联邦学习方法,降低了多中心的异质性特征影响,实现基于鲁棒特征的个性化本地模型自适应构建和全局模型自适应聚合,模型性能有较大提升。关键词:特征迁移;联邦学习;异质性特征;鲁棒特征选择网络;自适应聚合网络;医学图像分类182|367|0更新时间:2024-03-13
摘要:目的针对联邦学习中多中心医学数据的异质性特征导致全局模型性能不佳的问题,提出一种基于特征迁移的自适应个性化联邦学习算法(adaptive personalized federated learning via feature transfer, APFFT)。方法首先,为降低全局模型中异质性特征信息影响,提出鲁棒特征选择网络(robust feature selection network, RFS-Net)构建个性化本地模型。RFS-Net通过学习两个迁移权重分别确定全局模型向本地模型迁移时的有效特征以及特征迁移的目的地,并构建基于迁移权重的迁移损失函数以加强本地模型对全局模型中有效特征的注意力,从而构建个性化本地模型。然后,为过滤各本地模型中异质性特征信息,利用自适应聚合网络(adaptive aggregation network, AA-Net)聚合全局模型。AA-Net基于全局模型交叉熵变化更新迁移权重并构建聚合损失,使各本地模型向全局模型迁移鲁棒特征,提高全局模型的特征表达能力。结果在3种医学图像分类任务上与4种现有方法进行比较实验,在肺结核肺腺癌分类任务中,各中心曲线下面积(area under the curve,AUC)分别为0.791 5, 0.798 1, 0.760 0, 0.705 7和0.806 9;在乳腺癌组织学图像分类任务中,各中心准确率分别为0.984 9、0.980 8、0.983 5、0.982 6和0.983 4;在肺结节良恶性分类任务中,各中心AUC分别为 0.809 7, 0.849 8, 0.784 8和0.792 3。结论所提出的联邦学习方法,降低了多中心的异质性特征影响,实现基于鲁棒特征的个性化本地模型自适应构建和全局模型自适应聚合,模型性能有较大提升。关键词:特征迁移;联邦学习;异质性特征;鲁棒特征选择网络;自适应聚合网络;医学图像分类182|367|0更新时间:2024-03-13 -
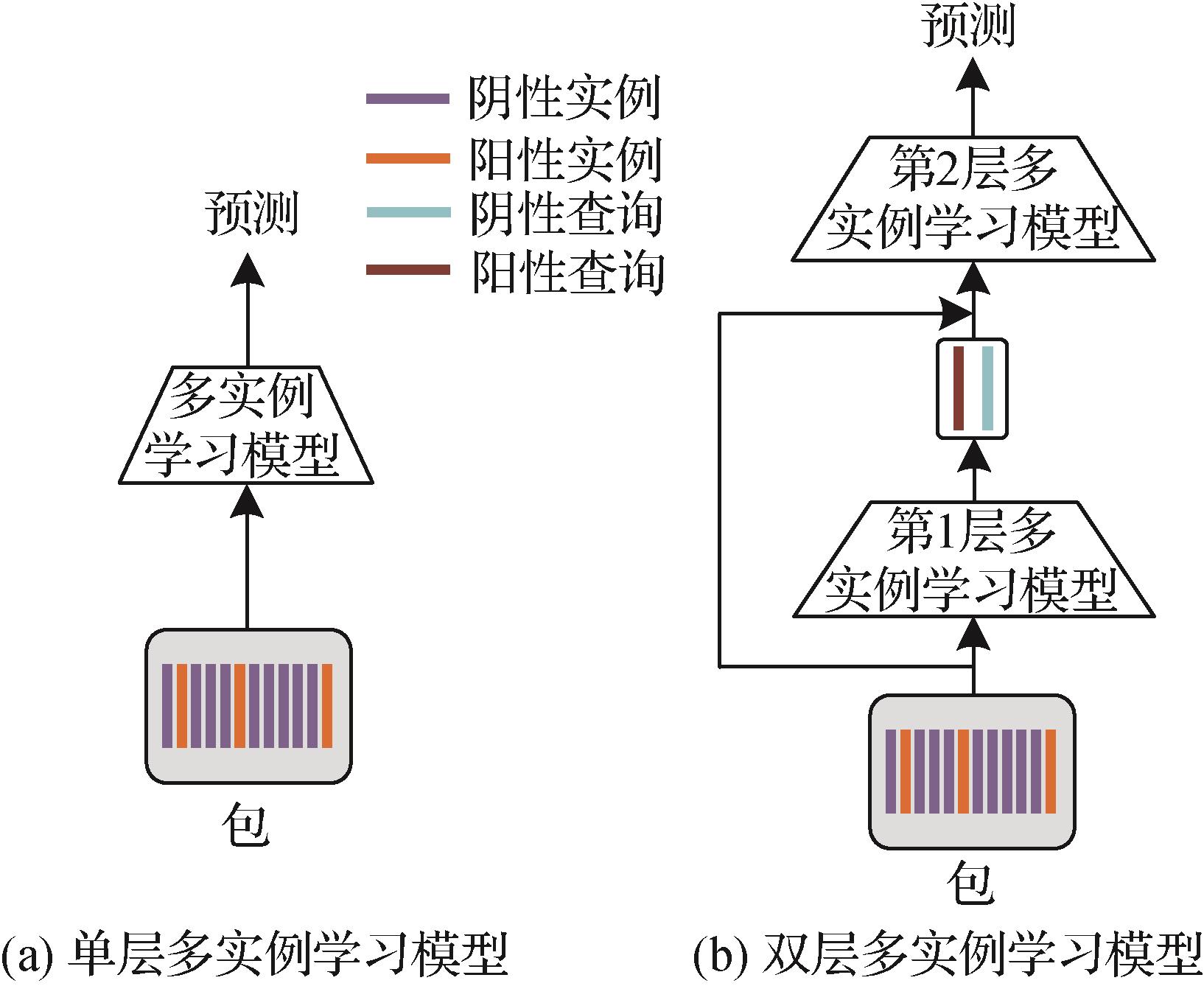 摘要:目的分析组织病理学全玻片图像(whole slide images,WSIs)是病理学诊断的金标准。WSIs具有千兆像素,且通常缺乏像素级标注。弱监督多实例学习是分析WSIs的主流方法,其关键是怎样从大量实例中精确识别出触发类别预测的关键实例。以前的WSIs分析方法主要是在独立同分布假设下设计的,忽略了实例间的相关性和肿瘤的异质性。针对上述问题,提出一种新的双层多实例学习模型。方法具体地,提出的模型由自适应特征挖掘器和双路交叉检测模块级联构成。首先,第1层的自适应特征挖掘器检索包中的区分性特征,为后续的实例特征聚合生成可靠的内部查询;然后,第2层的双路交叉检测模块通过建模内部查询与实例间的相关性,聚合包中所有实例生成最终的包级表示。此外,在特征提取部分中引入了自监督对比学习方法SimCLR以生成高质量的实例特征。结果在两个公共可用的数据集CAMELYON-16和TCGA(the cancer genome atlas)肺癌上评估了提出的模型,对比分析6种经典的多实例学习模型,结果显示本文模型的性能最优。在准确率方面,所提方法在CAMELYON-16和TCGA肺癌两个数据集上分别达到了95.35%和91.87%,较对比方法中最优的分别高出2.33%和0.96%。结论提出的模型可以较好地挖掘组织病理学图像的内部特征信息,显著提升检测精度,表明其在病理学诊断应用中的有效性,并能够准确定位病变区域,在病理辅助诊断场景下有较高的应用价值。关键词:多实例学习(MIL);组织病理学图像;自监督对比学习;弱监督学习;深度学习176|472|1更新时间:2024-03-13
摘要:目的分析组织病理学全玻片图像(whole slide images,WSIs)是病理学诊断的金标准。WSIs具有千兆像素,且通常缺乏像素级标注。弱监督多实例学习是分析WSIs的主流方法,其关键是怎样从大量实例中精确识别出触发类别预测的关键实例。以前的WSIs分析方法主要是在独立同分布假设下设计的,忽略了实例间的相关性和肿瘤的异质性。针对上述问题,提出一种新的双层多实例学习模型。方法具体地,提出的模型由自适应特征挖掘器和双路交叉检测模块级联构成。首先,第1层的自适应特征挖掘器检索包中的区分性特征,为后续的实例特征聚合生成可靠的内部查询;然后,第2层的双路交叉检测模块通过建模内部查询与实例间的相关性,聚合包中所有实例生成最终的包级表示。此外,在特征提取部分中引入了自监督对比学习方法SimCLR以生成高质量的实例特征。结果在两个公共可用的数据集CAMELYON-16和TCGA(the cancer genome atlas)肺癌上评估了提出的模型,对比分析6种经典的多实例学习模型,结果显示本文模型的性能最优。在准确率方面,所提方法在CAMELYON-16和TCGA肺癌两个数据集上分别达到了95.35%和91.87%,较对比方法中最优的分别高出2.33%和0.96%。结论提出的模型可以较好地挖掘组织病理学图像的内部特征信息,显著提升检测精度,表明其在病理学诊断应用中的有效性,并能够准确定位病变区域,在病理辅助诊断场景下有较高的应用价值。关键词:多实例学习(MIL);组织病理学图像;自监督对比学习;弱监督学习;深度学习176|472|1更新时间:2024-03-13 -
 摘要:目的高质量的图像重建是光声层析成像(photoacoustic tomography,PAT)技术的关键,有限角度稀疏测量和组织非均匀的声学特性都会影响重建图像质量。采用迭代重建技术可在一定程度上提高图像质量,但是其结果依赖于有关成像目标的先验假设模型。而且在迭代优化过程中需要反复计算前向成像算子及其伴随算子,因此计算成本较高,需要合理选择正则化方法及其参数。为了解决该问题,提出一种根据不完备光声测量信号联合重建光吸收能量分布图和声速分布图的深度学习方法。方法设计并搭建基于学习迭代策略的联合迭代重建网络(joint iterative reconstruction network,JIR-Net),网络由4个结构单元组成,每个单元包括特征提取、特征融合和重建3个模块。网络的输入是探测器在成像平面中采集的不完备光声信号和预设的常数声速,输出是重建的光吸收能量分布图和声速分布图。分别构建仿真、仿体和在体数据集,用于训练、验证和测试网络。在训练网络的过程中,将光吸收能量密度和声速的梯度下降信息整合到网络训练中,并利用反向传播梯度下降法求解非线性最小二乘问题。结果数值仿真、仿体和在体实验结果表明:与交替优化法、U-Net后处理法和深度梯度下降法相比,JIR-Net重建的光吸收能量分布图的结构相似度可分别提高约39.5%、26.4%和7.6%,峰值信噪比可分别提高约95.6%、71.4%和15.5%。与交替优化法相比,JIR-Net重建的声速分布图的结构相似度和峰值信噪比可分别提高约34.4%和22.6%。结论JIR-Net解决了由于有限角度稀疏测量和组织声速分布不均匀所致的光声图像质量下降问题,实现了从光声信号到高质量光吸收能量分布图和声速分布图的映射。关键词:图像重建技术;光声层析成像(PAT);深度学习;光吸收能量密度;声速(SoS);联合重建;梯度下降103|799|0更新时间:2024-03-13
摘要:目的高质量的图像重建是光声层析成像(photoacoustic tomography,PAT)技术的关键,有限角度稀疏测量和组织非均匀的声学特性都会影响重建图像质量。采用迭代重建技术可在一定程度上提高图像质量,但是其结果依赖于有关成像目标的先验假设模型。而且在迭代优化过程中需要反复计算前向成像算子及其伴随算子,因此计算成本较高,需要合理选择正则化方法及其参数。为了解决该问题,提出一种根据不完备光声测量信号联合重建光吸收能量分布图和声速分布图的深度学习方法。方法设计并搭建基于学习迭代策略的联合迭代重建网络(joint iterative reconstruction network,JIR-Net),网络由4个结构单元组成,每个单元包括特征提取、特征融合和重建3个模块。网络的输入是探测器在成像平面中采集的不完备光声信号和预设的常数声速,输出是重建的光吸收能量分布图和声速分布图。分别构建仿真、仿体和在体数据集,用于训练、验证和测试网络。在训练网络的过程中,将光吸收能量密度和声速的梯度下降信息整合到网络训练中,并利用反向传播梯度下降法求解非线性最小二乘问题。结果数值仿真、仿体和在体实验结果表明:与交替优化法、U-Net后处理法和深度梯度下降法相比,JIR-Net重建的光吸收能量分布图的结构相似度可分别提高约39.5%、26.4%和7.6%,峰值信噪比可分别提高约95.6%、71.4%和15.5%。与交替优化法相比,JIR-Net重建的声速分布图的结构相似度和峰值信噪比可分别提高约34.4%和22.6%。结论JIR-Net解决了由于有限角度稀疏测量和组织声速分布不均匀所致的光声图像质量下降问题,实现了从光声信号到高质量光吸收能量分布图和声速分布图的映射。关键词:图像重建技术;光声层析成像(PAT);深度学习;光吸收能量密度;声速(SoS);联合重建;梯度下降103|799|0更新时间:2024-03-13
图像理解和计算机视觉
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0