
最新刊期
2024 年 第 29 卷 第 2 期

-
 摘要:深度学习作为机器学习的一个具有前景的重要分支,在计算机视觉方面取得了重大突破。深度伪造(Deepfake)通常指的是使用深度学习(deep learning)进行涉及人脸和人声的多媒体伪造技术,如果被恶意滥用会给社会带来灾难。深度伪造不仅限于面部的替换,还有修改面部特征、修改表情、唇形同步、姿势变换、完整脸生成、篡改音频到视频以及文本到视频等方式。人类面部在社会、政治、经济等方面的敏感性,使得深度伪造技术威胁着社会和个人的安全。对深度伪造产物进行检测也成为数字取证领域的一个重要研究课题。为了提供对Deepfake检测研究工作的最新概述,本文描述了各种针对解决Deepfake相关问题的处理方法。本文主要参考了谷歌学术检索2018—2022共5年的深度伪造论文,分为不同类别进行分析比较,并且详细介绍了深度伪造数据集的特点以及伪造方法,简述了深度伪造技术及其基本原理,介绍了检测器在深度伪造技术数据集上的性能效果,分别从输入维度、浅层特征和深层特针对深度伪造检测技术进行分类,并对未来发展前景进行展望。关键词:深度造假;机器学习;人工智能;深度学习;数字取证;数字反取证2286|6649|1更新时间:2024-02-16
摘要:深度学习作为机器学习的一个具有前景的重要分支,在计算机视觉方面取得了重大突破。深度伪造(Deepfake)通常指的是使用深度学习(deep learning)进行涉及人脸和人声的多媒体伪造技术,如果被恶意滥用会给社会带来灾难。深度伪造不仅限于面部的替换,还有修改面部特征、修改表情、唇形同步、姿势变换、完整脸生成、篡改音频到视频以及文本到视频等方式。人类面部在社会、政治、经济等方面的敏感性,使得深度伪造技术威胁着社会和个人的安全。对深度伪造产物进行检测也成为数字取证领域的一个重要研究课题。为了提供对Deepfake检测研究工作的最新概述,本文描述了各种针对解决Deepfake相关问题的处理方法。本文主要参考了谷歌学术检索2018—2022共5年的深度伪造论文,分为不同类别进行分析比较,并且详细介绍了深度伪造数据集的特点以及伪造方法,简述了深度伪造技术及其基本原理,介绍了检测器在深度伪造技术数据集上的性能效果,分别从输入维度、浅层特征和深层特针对深度伪造检测技术进行分类,并对未来发展前景进行展望。关键词:深度造假;机器学习;人工智能;深度学习;数字取证;数字反取证2286|6649|1更新时间:2024-02-16 -
 摘要:深度生成模型的飞速发展推动了人脸深度伪造技术的进步,以Deepfake为代表的深度伪造模型也得到了十分广泛的应用。深度伪造技术可以对人脸图像或视频进行有目的的操纵,一方面,这种技术广泛应用于电影特效、娱乐场景中,丰富了人们的娱乐生活,促进了互联网多媒体的传播;另一方面,深度伪造也应用于一些可能造成不良影响的场景,给公民的名誉权、肖像权造成了危害,同时也给国家安全和社会稳定带来了极大的威胁,因此对深度伪造防御技术的研究日益迫切。现有的防御技术主要分为被动检测和主动防御,而被动检测的方式无法消除伪造人脸在广泛传播中造成的影响,难以做到“事前防御”,因此主动防御的思想得到了研究人员的广泛关注。然而,目前学术界有关深度伪造防御的综述主要关注基于检测的被动式防御方法,几乎没有以深度伪造主动防御技术为重点的综述。基于此,本文对当前学术界提出的人脸深度伪造主动防御技术进行梳理、总结和讨论。首先阐述了深度伪造主动防御的提出背景和主要思想,并对现有的人脸深度伪造主动防御算法进行汇总和归类,然后对各类主动防御算法的技术原理、性能、优缺点等进行了系统性的总结,同时介绍了研究常用的数据集和评估方法,最后对深度伪造主动防御所面临的技术挑战进行了分析,对其未来的发展方向展开了思考和讨论。关键词:人脸深度伪造;人脸深度伪造防御;主动防御;对抗攻击;生成对抗网络(GAN);深度学习1160|2261|0更新时间:2024-02-16
摘要:深度生成模型的飞速发展推动了人脸深度伪造技术的进步,以Deepfake为代表的深度伪造模型也得到了十分广泛的应用。深度伪造技术可以对人脸图像或视频进行有目的的操纵,一方面,这种技术广泛应用于电影特效、娱乐场景中,丰富了人们的娱乐生活,促进了互联网多媒体的传播;另一方面,深度伪造也应用于一些可能造成不良影响的场景,给公民的名誉权、肖像权造成了危害,同时也给国家安全和社会稳定带来了极大的威胁,因此对深度伪造防御技术的研究日益迫切。现有的防御技术主要分为被动检测和主动防御,而被动检测的方式无法消除伪造人脸在广泛传播中造成的影响,难以做到“事前防御”,因此主动防御的思想得到了研究人员的广泛关注。然而,目前学术界有关深度伪造防御的综述主要关注基于检测的被动式防御方法,几乎没有以深度伪造主动防御技术为重点的综述。基于此,本文对当前学术界提出的人脸深度伪造主动防御技术进行梳理、总结和讨论。首先阐述了深度伪造主动防御的提出背景和主要思想,并对现有的人脸深度伪造主动防御算法进行汇总和归类,然后对各类主动防御算法的技术原理、性能、优缺点等进行了系统性的总结,同时介绍了研究常用的数据集和评估方法,最后对深度伪造主动防御所面临的技术挑战进行了分析,对其未来的发展方向展开了思考和讨论。关键词:人脸深度伪造;人脸深度伪造防御;主动防御;对抗攻击;生成对抗网络(GAN);深度学习1160|2261|0更新时间:2024-02-16 -
 摘要:目的感知图像哈希又称图像摘要或是图像指纹,是一种有效的图像认证技术,近年来受到了广泛的关注。该技术通过将图像的感知鲁棒特征转化为固定长度的哈希序列,来实现图像版权认证。然而,该领域始终缺乏一个比较通用的数据集,已有数据集所使用的图像内容保留操作和真实场景差异较大,使得训练得到的神经网络架构在应对复杂的图像编辑操作时效果显著下降。方法针对感知图像哈希任务,面向实际图像内容认证场景构建了一个新的数据集。首先,将现实中常见的图像内容保留操作进行总结和分类,设计了48种单一、复合的图像内容保留操作来生成感知相似图像;然后,根据感知图像哈希的定义,选择与待认证图像语义相似但是感知内容不同的图像作为感知不相似图像,增加了该数据集的辨别难度;最终建立了一个包含116 400幅图像的感知哈希图像数据集。结果由于本文提出的数据集使用的图像内容保留操作更加复杂,不相似图像也更加难以辨别,使得在该数据集上训练得到的深度神经网络具有较好的泛化能力,即这些神经网络即使不进行重新训练或是微调,也可以在其他数据集上取得较好的认证性能。同时,在该数据集上训练得到的神经网络在不同数据集上性能差别较小,体现了本文数据集具有较好的稳定性。结论设计了一个针对感知哈希的图像数据集,大量的对比实验表明了该数据集的有效性,该工作可对感知图像哈希领域的发展起到促进作用。下载链接:https://pan.baidu.com/s/1uVnUVr5HqaSpoNifGElucw?pwd=8xwr关键词:感知图像哈希;图像认证;数据增强;数据集;内容保留操作204|781|0更新时间:2024-02-16
摘要:目的感知图像哈希又称图像摘要或是图像指纹,是一种有效的图像认证技术,近年来受到了广泛的关注。该技术通过将图像的感知鲁棒特征转化为固定长度的哈希序列,来实现图像版权认证。然而,该领域始终缺乏一个比较通用的数据集,已有数据集所使用的图像内容保留操作和真实场景差异较大,使得训练得到的神经网络架构在应对复杂的图像编辑操作时效果显著下降。方法针对感知图像哈希任务,面向实际图像内容认证场景构建了一个新的数据集。首先,将现实中常见的图像内容保留操作进行总结和分类,设计了48种单一、复合的图像内容保留操作来生成感知相似图像;然后,根据感知图像哈希的定义,选择与待认证图像语义相似但是感知内容不同的图像作为感知不相似图像,增加了该数据集的辨别难度;最终建立了一个包含116 400幅图像的感知哈希图像数据集。结果由于本文提出的数据集使用的图像内容保留操作更加复杂,不相似图像也更加难以辨别,使得在该数据集上训练得到的深度神经网络具有较好的泛化能力,即这些神经网络即使不进行重新训练或是微调,也可以在其他数据集上取得较好的认证性能。同时,在该数据集上训练得到的神经网络在不同数据集上性能差别较小,体现了本文数据集具有较好的稳定性。结论设计了一个针对感知哈希的图像数据集,大量的对比实验表明了该数据集的有效性,该工作可对感知图像哈希领域的发展起到促进作用。下载链接:https://pan.baidu.com/s/1uVnUVr5HqaSpoNifGElucw?pwd=8xwr关键词:感知图像哈希;图像认证;数据增强;数据集;内容保留操作204|781|0更新时间:2024-02-16 -
 摘要:目的现有基于对抗图像的隐写算法大多只能针对一种隐写分析器设计对抗图像,且无法抵御隐写分析残差网络(steganalysis residual network,SRNet)、Zhu-Net等最新基于卷积神经网络隐写分析器的检测。针对这一现状,提出了一种联合多重对抗与通道注意力的高安全性图像隐写方法。方法采用基于U-Net结构的生成对抗网络生成对抗样本图像,利用对抗网络的自学习特性实现多重对抗隐写网络参数迭代优化,并通过针对多种隐写分析算法的对抗训练,生成更适合内容隐写的载体图像。同时,通过在生成器中添加多个轻量级通道注意力模块,自适应调整对抗噪声在原始图像中的分布,提高生成对抗图像的抗隐写分析能力。其次,设计基于多重判别损失和均方误差损失相结合的动态加权组合方案,进一步增强对抗图像质量,并保障网络快速稳定收敛。结果实验在BOSS Base 1.01数据集上与当前主流的4种方法进行比较,在使用原始隐写图像训练后,相比于基于 U-Net 结构的生成式多重对抗隐写算法等其他4种方法,使得当前性能优异的5种隐写分析器平均判别准确率降低了1.6%;在使用对抗图像和增强隐写图像再训练后,相比其他4种方法,仍使得当前性能优异的5种隐写分析器平均判别准确率降低了6.8%。同时也对对抗图像质量进行分析,基于测试集生成的2 000幅对抗图像的平均峰值信噪比(peak signal-to-noise ratio,PSNR)可达到39.925 1 dB,实验结果表明本文提出的隐写网络极大提升了隐写算法的安全性。结论本文方法在隐写算法安全性领域取得了较优秀的性能,且生成的对抗图像具有很高的视觉质量。关键词:隐写;隐写分析;对抗图像;通道注意力;生成对抗网络(GAN)204|383|0更新时间:2024-02-16
摘要:目的现有基于对抗图像的隐写算法大多只能针对一种隐写分析器设计对抗图像,且无法抵御隐写分析残差网络(steganalysis residual network,SRNet)、Zhu-Net等最新基于卷积神经网络隐写分析器的检测。针对这一现状,提出了一种联合多重对抗与通道注意力的高安全性图像隐写方法。方法采用基于U-Net结构的生成对抗网络生成对抗样本图像,利用对抗网络的自学习特性实现多重对抗隐写网络参数迭代优化,并通过针对多种隐写分析算法的对抗训练,生成更适合内容隐写的载体图像。同时,通过在生成器中添加多个轻量级通道注意力模块,自适应调整对抗噪声在原始图像中的分布,提高生成对抗图像的抗隐写分析能力。其次,设计基于多重判别损失和均方误差损失相结合的动态加权组合方案,进一步增强对抗图像质量,并保障网络快速稳定收敛。结果实验在BOSS Base 1.01数据集上与当前主流的4种方法进行比较,在使用原始隐写图像训练后,相比于基于 U-Net 结构的生成式多重对抗隐写算法等其他4种方法,使得当前性能优异的5种隐写分析器平均判别准确率降低了1.6%;在使用对抗图像和增强隐写图像再训练后,相比其他4种方法,仍使得当前性能优异的5种隐写分析器平均判别准确率降低了6.8%。同时也对对抗图像质量进行分析,基于测试集生成的2 000幅对抗图像的平均峰值信噪比(peak signal-to-noise ratio,PSNR)可达到39.925 1 dB,实验结果表明本文提出的隐写网络极大提升了隐写算法的安全性。结论本文方法在隐写算法安全性领域取得了较优秀的性能,且生成的对抗图像具有很高的视觉质量。关键词:隐写;隐写分析;对抗图像;通道注意力;生成对抗网络(GAN)204|383|0更新时间:2024-02-16 -
 摘要:目的隐蔽通信是信息安全领域的一个重要研究方向,现有基于多媒体数据流构建隐蔽信道的方法,未考虑网络传输时波动产生的数据包丢失问题。本文提出一种基于跨数据模态信息检索技术的对网络异常具有鲁棒性的隐蔽通信方法,同时可以满足高隐蔽性和高安全性的要求。方法提出了一个名为RoCC(robust covert communication)的通用隐蔽通信框架,它基于跨模态信息检索和可证明安全的隐写技术。所提方法将直接通信和间接通信两种形式相结合。直接通信通过VoIP(voice over internet protocol)网络通话服务进行,传递实时生成的音频流数据,接收方可以通过语音识别将其还原为文本;而间接通信则借助公共网络数据库进行载密数据的传输,接收方通过文本语义相似度匹配的方式来还原完整语义的载密文本数据,这有助于解决网络数据包丢失和语音识别误差导致的文本语义丢失的问题。结果经实验测试,本文方法在协议上具有更好的通用性,相对Saenger方法在丢包率抵抗能力方面提高了5%,所用隐写算法满足可证安全性。同时,RoCC的数据传输率有73~136 bps(bit per second),能够满足实时通信需要。结论RoCC隐蔽通信框架综合可证明安全隐写、生成式机器学习方法和跨模态检索方法的优势,与现有的方法比较,具有更加隐蔽和安全的优势,并且是当前对数据传输丢包异常最鲁棒的模型。关键词:信息隐藏;隐蔽通信;生成式模型;数据跨模态转换;可证明安全隐写;多媒体信息检索;相似度分析232|841|0更新时间:2024-02-16
摘要:目的隐蔽通信是信息安全领域的一个重要研究方向,现有基于多媒体数据流构建隐蔽信道的方法,未考虑网络传输时波动产生的数据包丢失问题。本文提出一种基于跨数据模态信息检索技术的对网络异常具有鲁棒性的隐蔽通信方法,同时可以满足高隐蔽性和高安全性的要求。方法提出了一个名为RoCC(robust covert communication)的通用隐蔽通信框架,它基于跨模态信息检索和可证明安全的隐写技术。所提方法将直接通信和间接通信两种形式相结合。直接通信通过VoIP(voice over internet protocol)网络通话服务进行,传递实时生成的音频流数据,接收方可以通过语音识别将其还原为文本;而间接通信则借助公共网络数据库进行载密数据的传输,接收方通过文本语义相似度匹配的方式来还原完整语义的载密文本数据,这有助于解决网络数据包丢失和语音识别误差导致的文本语义丢失的问题。结果经实验测试,本文方法在协议上具有更好的通用性,相对Saenger方法在丢包率抵抗能力方面提高了5%,所用隐写算法满足可证安全性。同时,RoCC的数据传输率有73~136 bps(bit per second),能够满足实时通信需要。结论RoCC隐蔽通信框架综合可证明安全隐写、生成式机器学习方法和跨模态检索方法的优势,与现有的方法比较,具有更加隐蔽和安全的优势,并且是当前对数据传输丢包异常最鲁棒的模型。关键词:信息隐藏;隐蔽通信;生成式模型;数据跨模态转换;可证明安全隐写;多媒体信息检索;相似度分析232|841|0更新时间:2024-02-16 -
 摘要:目的图像隐藏已成为计算机视觉领域的一个重要课题,其目的是以难以察觉的方式将秘密图像隐藏在载体图像中,同时要求接收端能够恢复秘密图像。尽管该技术发展迅速,但目前的图像隐藏技术大多是从内容层面进行伪装,追求载密图像与载体图像的不可区分性。其实,图像隐藏的本质是对行为安全的追求,因此不仅可以在内容层面进行伪装,还可以在行为层面进行伪装。方法本文从行为安全的角度出发,提出了一种基于超分辨率行为伪装的可逆图像隐藏方法。与传统的图像隐藏技术不同,本文首先将秘密图像可逆地隐藏到载体图像中,生成载密图像,然后通过可逆的超分辨率处理创建与普通超分辨率图像处理操作无法区分的伪装图像。最后,允许接收方从伪装图像中恢复秘密图像和载体图像。结果在图像隐藏和超分辨率两个任务中,本文方法均取得了优异的结果。在相同的数据集下,测试结果显示恢复秘密图像的峰值信噪比(peak signal-to-noise ratio, PSNR)值达到47+ dB,较对比方法提升了2%以上,结构相似度(structure similarity index measure, SSIM)值也达到0.99+,超分辨率图像与Bicubic、SRCNN(super-resolution convolutional neural network)方法的结果相比,峰值信噪比(PSNR)提升了2+ dB, 感知指数(perceptual index, PI)值降低了2.02+。结论本文提出的图像隐藏框架利用可逆超分辨率处理操作实现了行为安全角度的图像隐藏,在容量、安全性和精度上都具有优势。关键词:图像隐藏;可逆神经网络(INN);行为安全;可逆行为伪装;超分辨率;深度学习165|782|0更新时间:2024-02-16
摘要:目的图像隐藏已成为计算机视觉领域的一个重要课题,其目的是以难以察觉的方式将秘密图像隐藏在载体图像中,同时要求接收端能够恢复秘密图像。尽管该技术发展迅速,但目前的图像隐藏技术大多是从内容层面进行伪装,追求载密图像与载体图像的不可区分性。其实,图像隐藏的本质是对行为安全的追求,因此不仅可以在内容层面进行伪装,还可以在行为层面进行伪装。方法本文从行为安全的角度出发,提出了一种基于超分辨率行为伪装的可逆图像隐藏方法。与传统的图像隐藏技术不同,本文首先将秘密图像可逆地隐藏到载体图像中,生成载密图像,然后通过可逆的超分辨率处理创建与普通超分辨率图像处理操作无法区分的伪装图像。最后,允许接收方从伪装图像中恢复秘密图像和载体图像。结果在图像隐藏和超分辨率两个任务中,本文方法均取得了优异的结果。在相同的数据集下,测试结果显示恢复秘密图像的峰值信噪比(peak signal-to-noise ratio, PSNR)值达到47+ dB,较对比方法提升了2%以上,结构相似度(structure similarity index measure, SSIM)值也达到0.99+,超分辨率图像与Bicubic、SRCNN(super-resolution convolutional neural network)方法的结果相比,峰值信噪比(PSNR)提升了2+ dB, 感知指数(perceptual index, PI)值降低了2.02+。结论本文提出的图像隐藏框架利用可逆超分辨率处理操作实现了行为安全角度的图像隐藏,在容量、安全性和精度上都具有优势。关键词:图像隐藏;可逆神经网络(INN);行为安全;可逆行为伪装;超分辨率;深度学习165|782|0更新时间:2024-02-16 -
 摘要:目的密文图像可逆数据隐藏技术既可以保证载体内容不被泄露,又可以传递秘密信息,在军事、医疗等方面发挥着重要的作用。然而,以往的大多数方法存在图像冗余未被充分利用、数据嵌入容量不足等问题。为解决这些问题,提出了一种结合Kd-树和熵编码的高容量密文图像可逆数据隐藏算法。方法该方法在图像加密之前需要对图像应用中值边缘检测(median-edge detector,MED)算法计算预测误差,并把得到的预测误差绝对值图像划分为两个区域:S0区域和S1区域。根据Kd-树标签算法和熵编码生成辅助信息,在对图像使用加密密钥
摘要:目的密文图像可逆数据隐藏技术既可以保证载体内容不被泄露,又可以传递秘密信息,在军事、医疗等方面发挥着重要的作用。然而,以往的大多数方法存在图像冗余未被充分利用、数据嵌入容量不足等问题。为解决这些问题,提出了一种结合Kd-树和熵编码的高容量密文图像可逆数据隐藏算法。方法该方法在图像加密之前需要对图像应用中值边缘检测(median-edge detector,MED)算法计算预测误差,并把得到的预测误差绝对值图像划分为两个区域:S0区域和S1区域。根据Kd-树标签算法和熵编码生成辅助信息,在对图像使用加密密钥 -
 摘要:目的现有屏摄水印方法无法有效平衡计算复杂度、嵌入水印后的图像质量以及水印鲁棒性3项指标,同时广泛使用透视畸变矫正预处理,大大限制了屏摄水印的实际商业使用。本文在重新设计噪声层的基础上,提出了一种最小依赖载体图像隐藏水印信息的屏摄鲁棒水印,将屏摄水印对于载体图像的依赖控制在最小。方法为了保证水印的嵌入效率,极大简化依赖深度隐藏网络框架中的编码网络,达成对载体图像的最小依赖,大大减小计算复杂度;为了平衡网络深度减小所导致的网络提取能力损失,加入Sobel算子,引入载体图像的边缘信息;在噪声层中加入缩放攻击操作,并由此去除了限制屏摄水印应用范围的透视畸变矫正预处理,进一步拓宽了应用范围;为了训练网络的屏摄鲁棒性,重新定义了噪声层,改进原有噪声层的设计结构,对噪声层图像扰动类型和参数进行随机选择,使得解码网络的输入数据具有更高的样本均衡性和多样性。结果在DIV2K(DIVerse 2K)数据集上与其他的3种方法进行了对比实验,本文方法获得了最高的PSNR(peak signal-to-noise ratio)和SSIM(structural similarity index measure)指标,并比排名第2的通用深度隐藏方法提高了12 dB的PSNR值和0.006的SSIM值;在有无攻击两种环境下,本文方法均能保持很高的ACC(accuracy)和F1指标,在攻击环境下比排名第2位的StegaStamp(steganography stamp)方法提高了0.262的F1分数。与同网络框架下的已有噪声层相比,在无攻击环境下,本文算法提高了0.124的ACC和0.284的F1分数;在有攻击环境下,本文算法提高了0.316的ACC和0.524的F1分数,水印提取的准确性更高。结论本文算法在图像质量和水印鲁棒性方面获得了更优的效果,摆脱了透视畸变矫正的限制,拓宽了屏摄水印的应用范围。关键词:数字水印;屏摄信道;全卷积网络;依赖隐藏;噪声层236|905|0更新时间:2024-02-16
摘要:目的现有屏摄水印方法无法有效平衡计算复杂度、嵌入水印后的图像质量以及水印鲁棒性3项指标,同时广泛使用透视畸变矫正预处理,大大限制了屏摄水印的实际商业使用。本文在重新设计噪声层的基础上,提出了一种最小依赖载体图像隐藏水印信息的屏摄鲁棒水印,将屏摄水印对于载体图像的依赖控制在最小。方法为了保证水印的嵌入效率,极大简化依赖深度隐藏网络框架中的编码网络,达成对载体图像的最小依赖,大大减小计算复杂度;为了平衡网络深度减小所导致的网络提取能力损失,加入Sobel算子,引入载体图像的边缘信息;在噪声层中加入缩放攻击操作,并由此去除了限制屏摄水印应用范围的透视畸变矫正预处理,进一步拓宽了应用范围;为了训练网络的屏摄鲁棒性,重新定义了噪声层,改进原有噪声层的设计结构,对噪声层图像扰动类型和参数进行随机选择,使得解码网络的输入数据具有更高的样本均衡性和多样性。结果在DIV2K(DIVerse 2K)数据集上与其他的3种方法进行了对比实验,本文方法获得了最高的PSNR(peak signal-to-noise ratio)和SSIM(structural similarity index measure)指标,并比排名第2的通用深度隐藏方法提高了12 dB的PSNR值和0.006的SSIM值;在有无攻击两种环境下,本文方法均能保持很高的ACC(accuracy)和F1指标,在攻击环境下比排名第2位的StegaStamp(steganography stamp)方法提高了0.262的F1分数。与同网络框架下的已有噪声层相比,在无攻击环境下,本文算法提高了0.124的ACC和0.284的F1分数;在有攻击环境下,本文算法提高了0.316的ACC和0.524的F1分数,水印提取的准确性更高。结论本文算法在图像质量和水印鲁棒性方面获得了更优的效果,摆脱了透视畸变矫正的限制,拓宽了屏摄水印的应用范围。关键词:数字水印;屏摄信道;全卷积网络;依赖隐藏;噪声层236|905|0更新时间:2024-02-16 -
 摘要:目的恶意的图像拼接篡改给名誉、法律、政治等带来一系列的挑战,而现有的图像拼接检测算法通常采用参数固定的高通滤波器提取滤波特征进行预处理,没有考虑图像之间的差异。方法本文设计自适应残差模块(adaptive residuals module, ARM)凸显拼接篡改痕迹,将卷积运算后的残差多次拼接,且每次拼接后再利用注意力机制实现通道间的非线性交互。然后,使用通道注意力SE(squeeze and excitation)模块以减少由ARM提取残差特征产生的通道之间信息冗余,并以在图像分类领域获得卓越性能的EfficientNet(high-efficiency network)为骨干网络,提出一种新的图像拼接检测算法。结果实验结果表明,所提算法在CASIA I(CASIA image tampering detection evaluation database),CASIA II,COLUMBIA COLOR,NIST16(NIST special database 16)和FaceForensic++这5个公开数据集上分别取得98.95%,98.88%,100%,100%,88.20%的检测准确率,获得比现有算法更高的准确率。提出的ARM将骨干网络EfficientNet在CASIA II 数据集的准确率提高了3.94%以上。结论提出的基于自适应残差的图像拼接检测算法充分考虑图像之间的差异,凸显篡改区域与未篡改区域之间的区别,并获得更好的拼接检测结果。关键词:图像取证;深度神经网络;图像拼接检测;自适应残差;EfficientNet250|702|0更新时间:2024-02-16
摘要:目的恶意的图像拼接篡改给名誉、法律、政治等带来一系列的挑战,而现有的图像拼接检测算法通常采用参数固定的高通滤波器提取滤波特征进行预处理,没有考虑图像之间的差异。方法本文设计自适应残差模块(adaptive residuals module, ARM)凸显拼接篡改痕迹,将卷积运算后的残差多次拼接,且每次拼接后再利用注意力机制实现通道间的非线性交互。然后,使用通道注意力SE(squeeze and excitation)模块以减少由ARM提取残差特征产生的通道之间信息冗余,并以在图像分类领域获得卓越性能的EfficientNet(high-efficiency network)为骨干网络,提出一种新的图像拼接检测算法。结果实验结果表明,所提算法在CASIA I(CASIA image tampering detection evaluation database),CASIA II,COLUMBIA COLOR,NIST16(NIST special database 16)和FaceForensic++这5个公开数据集上分别取得98.95%,98.88%,100%,100%,88.20%的检测准确率,获得比现有算法更高的准确率。提出的ARM将骨干网络EfficientNet在CASIA II 数据集的准确率提高了3.94%以上。结论提出的基于自适应残差的图像拼接检测算法充分考虑图像之间的差异,凸显篡改区域与未篡改区域之间的区别,并获得更好的拼接检测结果。关键词:图像取证;深度神经网络;图像拼接检测;自适应残差;EfficientNet250|702|0更新时间:2024-02-16 -
 摘要:目的伪造图像给众多行业埋下了隐患,这会造成大量潜在的经济损失。方法提出一种边缘引导的双注意力图像拼接检测网络(boundary-guided dual attention network,BDA-Net),该网络通过将空间通道依赖和边缘预测集成到网络提取的特征中来得到预测结果。首先,提出一种称为预测分支的编解码模型,该分支作为模型的主干网络,可以提取和融合不同分辨率的特征图。其次,为了捕捉不同维度的依赖关系并增强网络对感兴趣区域的关注能力,设计了一个沿多维度进行特征编码的坐标—空间注意力模块(coordinate-spatial attention module,CSAM)。最后,设计了一条边缘引导分支来捕获篡改区域和非篡改区域之间的微小边缘痕迹,以辅助预测分支进行更好的分割。结果实验使用4个图像拼接数据集与多种方法进行比较,评价指标为F1值。在Columbia数据集中,与排名第1的模型相比,F1值仅相差1.6%。在NIST16 Splicing(National Institute of Standards and Technology 16 Splicing)数据集中,F1值与最好的模型略有差距。而在检测难度更高的CASIA2.0 Splicing(Chinese Academy of Sciences Institute of Automation Dataset 2.0 Splicing)和IMD2020(Image Manipulated Datasets 2020)数据集中,BDA-Net 的F1值相比排名第2的模型分别提高了15.3%和11.9%。为了验证模型的鲁棒性,还对图像施加JPEG压缩、高斯模糊、锐化、高斯噪声和椒盐噪声攻击。实验结果表明,BDA-Net的鲁棒性明显优于其他模型。结论本文方法充分利用深度学习模型的优点和图像拼接检测领域的专业知识,能有效提升模型性能。与现有的检测方法相比,具有更强的检测能力和更好的稳定性。关键词:图像取证;图像篡改检测;卷积神经网络(CNN);注意力机制;融合算法160|1008|1更新时间:2024-02-16
摘要:目的伪造图像给众多行业埋下了隐患,这会造成大量潜在的经济损失。方法提出一种边缘引导的双注意力图像拼接检测网络(boundary-guided dual attention network,BDA-Net),该网络通过将空间通道依赖和边缘预测集成到网络提取的特征中来得到预测结果。首先,提出一种称为预测分支的编解码模型,该分支作为模型的主干网络,可以提取和融合不同分辨率的特征图。其次,为了捕捉不同维度的依赖关系并增强网络对感兴趣区域的关注能力,设计了一个沿多维度进行特征编码的坐标—空间注意力模块(coordinate-spatial attention module,CSAM)。最后,设计了一条边缘引导分支来捕获篡改区域和非篡改区域之间的微小边缘痕迹,以辅助预测分支进行更好的分割。结果实验使用4个图像拼接数据集与多种方法进行比较,评价指标为F1值。在Columbia数据集中,与排名第1的模型相比,F1值仅相差1.6%。在NIST16 Splicing(National Institute of Standards and Technology 16 Splicing)数据集中,F1值与最好的模型略有差距。而在检测难度更高的CASIA2.0 Splicing(Chinese Academy of Sciences Institute of Automation Dataset 2.0 Splicing)和IMD2020(Image Manipulated Datasets 2020)数据集中,BDA-Net 的F1值相比排名第2的模型分别提高了15.3%和11.9%。为了验证模型的鲁棒性,还对图像施加JPEG压缩、高斯模糊、锐化、高斯噪声和椒盐噪声攻击。实验结果表明,BDA-Net的鲁棒性明显优于其他模型。结论本文方法充分利用深度学习模型的优点和图像拼接检测领域的专业知识,能有效提升模型性能。与现有的检测方法相比,具有更强的检测能力和更好的稳定性。关键词:图像取证;图像篡改检测;卷积神经网络(CNN);注意力机制;融合算法160|1008|1更新时间:2024-02-16 -
 摘要:目的变电站图像拼接篡改是电力系统的一大安全隐患,针对篡改图像背景复杂、篡改内容尺度不一造成的误检漏检问题以及相关研究较少,本文提出一种面向变电站的拼接篡改图像的双通道检测模型。方法两通道均采用深度学习方法自适应提取篡改图像和残差图像的特征,其中篡改图像包含丰富的色彩特征和内容信息,残差图像重点凸显了篡改区域的边缘,有效应对了篡改图像多样性导致的篡改特征提取困难问题;将特征金字塔结构Transformer通道作为网络主分支,通过全局交互机制获取图像全局信息,建立关键点之间的联系,使模型具备良好的泛化性和多尺度特征处理能力;引入浅层卷积神经网络(convolutional neural network, CNN)通道作为辅助分支,着重提取篡改区域的边缘特征,使模型在整体轮廓上更容易定位篡改区域。结果实验在自制变电站拼接篡改数据集(self-made substation splicing tampered dataset, SSSTD)、CASIA(Chinese Academy of Sciences Institute of Automation dataset)和NIST16(National Institute of Standards and Technology 16)上与4种同类型方法进行比较。定量上看,在SSSTD数据集中,本文模型相对性能第2的模型在精确率、召回率、F1和平均精度上分别提高了0.12%、2.17%、1.24%和7.71%;在CASIA和NIST16数据集中,本文模型也取得了最好成绩。定性上看,所提模型减少了误检和漏检,同时定位精度更高。结论本文提出的双通道拼接篡改检测模型结合了Transformer和CNN在图像篡改检测方面的优势,提高了模型的检测精度,适用于复杂变电站场景下的篡改目标检测。关键词:变电站图像;拼接篡改检测;Transformer;卷积神经网络(CNN);双通道网络;特征金字塔结构;浅层网络167|599|0更新时间:2024-02-16
摘要:目的变电站图像拼接篡改是电力系统的一大安全隐患,针对篡改图像背景复杂、篡改内容尺度不一造成的误检漏检问题以及相关研究较少,本文提出一种面向变电站的拼接篡改图像的双通道检测模型。方法两通道均采用深度学习方法自适应提取篡改图像和残差图像的特征,其中篡改图像包含丰富的色彩特征和内容信息,残差图像重点凸显了篡改区域的边缘,有效应对了篡改图像多样性导致的篡改特征提取困难问题;将特征金字塔结构Transformer通道作为网络主分支,通过全局交互机制获取图像全局信息,建立关键点之间的联系,使模型具备良好的泛化性和多尺度特征处理能力;引入浅层卷积神经网络(convolutional neural network, CNN)通道作为辅助分支,着重提取篡改区域的边缘特征,使模型在整体轮廓上更容易定位篡改区域。结果实验在自制变电站拼接篡改数据集(self-made substation splicing tampered dataset, SSSTD)、CASIA(Chinese Academy of Sciences Institute of Automation dataset)和NIST16(National Institute of Standards and Technology 16)上与4种同类型方法进行比较。定量上看,在SSSTD数据集中,本文模型相对性能第2的模型在精确率、召回率、F1和平均精度上分别提高了0.12%、2.17%、1.24%和7.71%;在CASIA和NIST16数据集中,本文模型也取得了最好成绩。定性上看,所提模型减少了误检和漏检,同时定位精度更高。结论本文提出的双通道拼接篡改检测模型结合了Transformer和CNN在图像篡改检测方面的优势,提高了模型的检测精度,适用于复杂变电站场景下的篡改目标检测。关键词:变电站图像;拼接篡改检测;Transformer;卷积神经网络(CNN);双通道网络;特征金字塔结构;浅层网络167|599|0更新时间:2024-02-16 -
 摘要:目的由于不同伪造类型样本的数据分布差距较大,现有人脸伪造检测方法的准确度不够高,而且泛化性能差。为此,本文引入“图像块归属纯净性”和“残差图估计可靠性”的概念,提出了基于图像块比较和残差图估计的人脸伪造检测方法。方法除了骨干网络,本文的人脸伪造检测神经网络主要由纯净图像块比较模块和可靠残差图估计模块两部分组成。为了避免在同时包含人脸和背景像素的图像块上提取的混杂特征对于图像块比较的干扰,纯净图像块比较模块中选择只包含人脸像素的纯净人脸图像块和只包含背景像素的纯净背景图像块,通过比较两种图像块纯净特征之间的差异来检测伪造图像,图像块的纯净性保障了特征提取的纯净性,从而提高了特征比较的鲁棒性。考虑到靠近伪造边缘的像素比远离伪造边缘的像素具有较高的残差估计准确度,本文在可靠残差图估计模块中根据像素到伪造边缘的距离设计了一个距离场加权的残差损失来引导网络的训练过程,使网络重点关注输入图像与对应真实图像在伪造边缘附近的差异,对于可靠信息的关注进一步增强了伪造检测的鲁棒性。结果在FF++(FaceForensics++)数据集上的测试结果显示:与对比算法中性能最好的F2Trans-B相比,本文方法的准确率和AUC(area under the ROC curve)指标分别提高了2.49%和3.31%,在FS(FaceSwap)与F2F(Face2Face)两种伪造数据上的准确率指标分别提高了6.01%和3.99%。在泛化性能方面,与11种已有方法在交叉数据集上的测试结果显示:本文方法与其中性能最好的方法相比,在CDF(Celeb-DF)数据集上的视频AUC指标和图像AUC指标分别提高了1.85%和1.03%。结论与对比方法相比,由于提高了特征信息的纯净性和可靠性,本文提出的人脸图像伪造检测模型的泛化能力和准确率优于对比方法。关键词:人脸图像伪造检测;深度伪造;多任务学习;泛化性能;像素级监督;卷积神经网络281|350|0更新时间:2024-02-16
摘要:目的由于不同伪造类型样本的数据分布差距较大,现有人脸伪造检测方法的准确度不够高,而且泛化性能差。为此,本文引入“图像块归属纯净性”和“残差图估计可靠性”的概念,提出了基于图像块比较和残差图估计的人脸伪造检测方法。方法除了骨干网络,本文的人脸伪造检测神经网络主要由纯净图像块比较模块和可靠残差图估计模块两部分组成。为了避免在同时包含人脸和背景像素的图像块上提取的混杂特征对于图像块比较的干扰,纯净图像块比较模块中选择只包含人脸像素的纯净人脸图像块和只包含背景像素的纯净背景图像块,通过比较两种图像块纯净特征之间的差异来检测伪造图像,图像块的纯净性保障了特征提取的纯净性,从而提高了特征比较的鲁棒性。考虑到靠近伪造边缘的像素比远离伪造边缘的像素具有较高的残差估计准确度,本文在可靠残差图估计模块中根据像素到伪造边缘的距离设计了一个距离场加权的残差损失来引导网络的训练过程,使网络重点关注输入图像与对应真实图像在伪造边缘附近的差异,对于可靠信息的关注进一步增强了伪造检测的鲁棒性。结果在FF++(FaceForensics++)数据集上的测试结果显示:与对比算法中性能最好的F2Trans-B相比,本文方法的准确率和AUC(area under the ROC curve)指标分别提高了2.49%和3.31%,在FS(FaceSwap)与F2F(Face2Face)两种伪造数据上的准确率指标分别提高了6.01%和3.99%。在泛化性能方面,与11种已有方法在交叉数据集上的测试结果显示:本文方法与其中性能最好的方法相比,在CDF(Celeb-DF)数据集上的视频AUC指标和图像AUC指标分别提高了1.85%和1.03%。结论与对比方法相比,由于提高了特征信息的纯净性和可靠性,本文提出的人脸图像伪造检测模型的泛化能力和准确率优于对比方法。关键词:人脸图像伪造检测;深度伪造;多任务学习;泛化性能;像素级监督;卷积神经网络281|350|0更新时间:2024-02-16
数字媒体深度伪造与对抗
-
 摘要:目的杂乱场景下的物体抓取姿态检测是智能机器人的一项基本技能。尽管六自由度抓取学习取得了进展,但先前的方法在采样和学习中忽略了物体尺寸差异,导致在小物体上抓取表现较差。方法提出了一种物体掩码辅助采样方法,在所有物体上采样相同的点以平衡抓取分布,解决了采样点分布不均匀问题。此外,学习时采用多尺度学习策略,在物体部分点云上使用多尺度圆柱分组以提升局部几何表示能力,解决了由物体尺度差异导致的学习抓取操作参数困难问题。通过设计一个端到端的抓取网络,嵌入了提出的采样和学习方法,能够有效提升物体抓取检测性能。结果在大型基准数据集GraspNet-1Billion上进行评估,本文方法取得对比方法中的最优性能,其中在小物体上的抓取指标平均提升了7%,大量的真实机器人实验也表明该方法具有抓取未知物体的良好泛化性能。结论本文聚焦于小物体上的抓取,提出了一种掩码辅助采样方法嵌入到提出的端到端学习网络中,并引入了多尺度分组学习策略提高物体的局部几何表示,能够有效提升在小尺寸物体上的抓取质量,并在所有物体上的抓取评估结果都超过了对比方法。关键词:六自由度抓取;采样策略;多尺度学习;点云学习;深度学习332|757|0更新时间:2024-02-16
摘要:目的杂乱场景下的物体抓取姿态检测是智能机器人的一项基本技能。尽管六自由度抓取学习取得了进展,但先前的方法在采样和学习中忽略了物体尺寸差异,导致在小物体上抓取表现较差。方法提出了一种物体掩码辅助采样方法,在所有物体上采样相同的点以平衡抓取分布,解决了采样点分布不均匀问题。此外,学习时采用多尺度学习策略,在物体部分点云上使用多尺度圆柱分组以提升局部几何表示能力,解决了由物体尺度差异导致的学习抓取操作参数困难问题。通过设计一个端到端的抓取网络,嵌入了提出的采样和学习方法,能够有效提升物体抓取检测性能。结果在大型基准数据集GraspNet-1Billion上进行评估,本文方法取得对比方法中的最优性能,其中在小物体上的抓取指标平均提升了7%,大量的真实机器人实验也表明该方法具有抓取未知物体的良好泛化性能。结论本文聚焦于小物体上的抓取,提出了一种掩码辅助采样方法嵌入到提出的端到端学习网络中,并引入了多尺度分组学习策略提高物体的局部几何表示,能够有效提升在小尺寸物体上的抓取质量,并在所有物体上的抓取评估结果都超过了对比方法。关键词:六自由度抓取;采样策略;多尺度学习;点云学习;深度学习332|757|0更新时间:2024-02-16 -
 摘要:目的近年来,采用神经网络完成人像实时抠图已成为计算机视觉领域的研究热点,现有相关网络在处理高分辨率视频时还无法满足实时性要求,为此本文提出一种结合背景图的高分辨率视频人像实时抠图网络。方法给出一种由基准网络和精细化网络构成的双层网络,在基准网络中,视频帧通过编码器模块提取图像的多尺度特征,采用金字塔池化模块融合这些特征作为循环解码器网络的输入;在循环解码器中,通过残差门控循环单元聚合连续视频帧间的时间信息,以此生成蒙版图、前景残差图和隐藏特征图,采用残差结构降低模型参数量并提高网络的实时性。为提高高分辨率图像实时抠图性能,在精细化网络中,设计高分辨率信息指导模块,通过高分辨率图像信息指导低分辨率图像的方式生成高质量人像抠图结果。结果与近年来的相关网络模型进行实验对比,实验结果表明,本文方法在高分辨率数据集Human2K上优于现有相关方法,在评价指标(绝对误差、均方误差、梯度、连通性)上分别提升了18.8%、39.2%、40.7%、20.9%。在NVIDIA GTX 1080Ti GPU上处理4 K分辨率影像运行速率可达26帧/s,处理HD(high definition)分辨率影像运行速率可达43帧/s。结论本文模型能够更好地完成高分辨率人像实时抠图任务,可以为影视、短视频社交以及网络会议等高级应用提供更好的支持。关键词:人像实时抠图;神经网络;多尺度特征;时间信息;高分辨率219|310|1更新时间:2024-02-16
摘要:目的近年来,采用神经网络完成人像实时抠图已成为计算机视觉领域的研究热点,现有相关网络在处理高分辨率视频时还无法满足实时性要求,为此本文提出一种结合背景图的高分辨率视频人像实时抠图网络。方法给出一种由基准网络和精细化网络构成的双层网络,在基准网络中,视频帧通过编码器模块提取图像的多尺度特征,采用金字塔池化模块融合这些特征作为循环解码器网络的输入;在循环解码器中,通过残差门控循环单元聚合连续视频帧间的时间信息,以此生成蒙版图、前景残差图和隐藏特征图,采用残差结构降低模型参数量并提高网络的实时性。为提高高分辨率图像实时抠图性能,在精细化网络中,设计高分辨率信息指导模块,通过高分辨率图像信息指导低分辨率图像的方式生成高质量人像抠图结果。结果与近年来的相关网络模型进行实验对比,实验结果表明,本文方法在高分辨率数据集Human2K上优于现有相关方法,在评价指标(绝对误差、均方误差、梯度、连通性)上分别提升了18.8%、39.2%、40.7%、20.9%。在NVIDIA GTX 1080Ti GPU上处理4 K分辨率影像运行速率可达26帧/s,处理HD(high definition)分辨率影像运行速率可达43帧/s。结论本文模型能够更好地完成高分辨率人像实时抠图任务,可以为影视、短视频社交以及网络会议等高级应用提供更好的支持。关键词:人像实时抠图;神经网络;多尺度特征;时间信息;高分辨率219|310|1更新时间:2024-02-16
图像分析和识别
-
 摘要:目的图像内补与外推可看做根据已知区域绘制未知区域的问题,是计算机视觉领域研究热点。近年来,深度神经网络成为解决内补与外推问题的主流方法。然而,当前解决方法多分别对待内补与外推问题,导致二者难以统一处理; 且模型多采用卷积神经网络(convolutional neural network,CNN)构建,受到视野局部性限制,较难绘制远距离内容。针对这两个问题,本文按照分而治之思想联合CNN与Transformer构建深度神经网络,提出图像内补与外推统一处理框架及模型。方法将内补与外推问题的解决过程分解为“表征、预测、合成”3个部分,表征与合成采用CNN完成,充分利用其局部相关性进行图像到特征映射和特征到图像重建;核心预测由Transformer实现,充分发挥其强大的全局上下文关系建模能力,并提出掩膜自增策略迭代预测特征,降低Transformer同时预测大范围未知区域特征的难度;最后引入对抗学习提升绘制图像逼真度。结果实验给出在多种数据集下内补与外推对比评测,结果显示本文方法各项性能指标均超越对比方法。通过消融实验发现,模型相比采用非分解方式具有更佳表现,说明分而治之思路功效显著。此外,对掩膜自增策略进行详细的实验分析,表明迭代预测方法可有效提升绘制能力。最后,探究了Transformer关键结构参数对模型性能的影响。结论本文提出一种迭代预测统一框架解决图像内补与外推问题,相较对比方法性能更佳,并且各部分设计对性能提升均有贡献,显示了迭代预测统一框架及方法在图像内补与外推问题上的应用价值与潜力。关键词:图像内补;图像外推;分而治之;迭代预测;Transformer;卷积神经网络(CNN)255|396|1更新时间:2024-02-16
摘要:目的图像内补与外推可看做根据已知区域绘制未知区域的问题,是计算机视觉领域研究热点。近年来,深度神经网络成为解决内补与外推问题的主流方法。然而,当前解决方法多分别对待内补与外推问题,导致二者难以统一处理; 且模型多采用卷积神经网络(convolutional neural network,CNN)构建,受到视野局部性限制,较难绘制远距离内容。针对这两个问题,本文按照分而治之思想联合CNN与Transformer构建深度神经网络,提出图像内补与外推统一处理框架及模型。方法将内补与外推问题的解决过程分解为“表征、预测、合成”3个部分,表征与合成采用CNN完成,充分利用其局部相关性进行图像到特征映射和特征到图像重建;核心预测由Transformer实现,充分发挥其强大的全局上下文关系建模能力,并提出掩膜自增策略迭代预测特征,降低Transformer同时预测大范围未知区域特征的难度;最后引入对抗学习提升绘制图像逼真度。结果实验给出在多种数据集下内补与外推对比评测,结果显示本文方法各项性能指标均超越对比方法。通过消融实验发现,模型相比采用非分解方式具有更佳表现,说明分而治之思路功效显著。此外,对掩膜自增策略进行详细的实验分析,表明迭代预测方法可有效提升绘制能力。最后,探究了Transformer关键结构参数对模型性能的影响。结论本文提出一种迭代预测统一框架解决图像内补与外推问题,相较对比方法性能更佳,并且各部分设计对性能提升均有贡献,显示了迭代预测统一框架及方法在图像内补与外推问题上的应用价值与潜力。关键词:图像内补;图像外推;分而治之;迭代预测;Transformer;卷积神经网络(CNN)255|396|1更新时间:2024-02-16 -
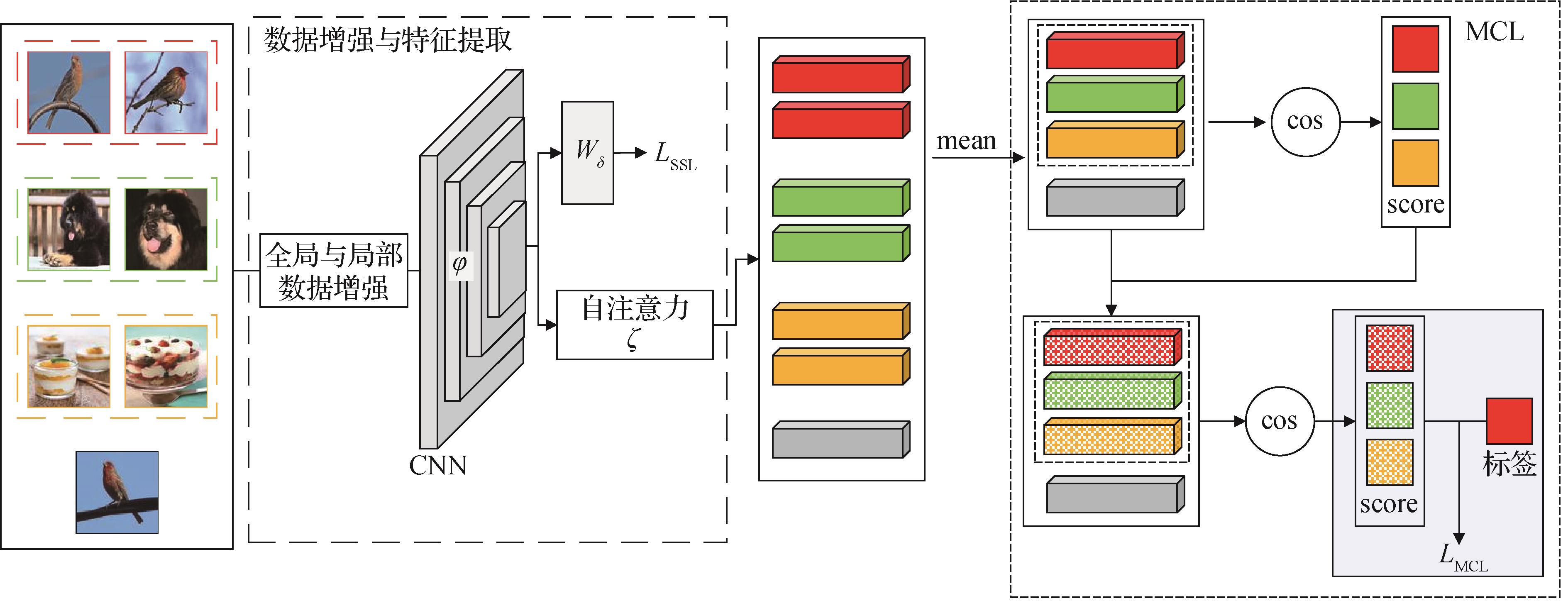 摘要:目的度量学习是少样本学习中一种简单且有效的方法,学习一个丰富、具有判别性和泛化性强的嵌入空间是度量学习方法实现优秀分类效果的关键。本文从样本自身的特征以及特征在嵌入空间中的分布出发,结合全局与局部数据增强实现了一种元余弦损失的少样本图像分类方法(a meta-cosine loss for few-shot image classification,AMCL-FSIC)。方法首先,从数据自身特征出发,将全局与局部的数据增广方法结合起来,利于局部信息提供更具区别性和迁移性的信息,使训练模型更多关注图像的前景信息。同时,利用注意力机制结合全局与局部特征,以得到更丰富更具判别性的特征。其次,从样本特征在嵌入空间中的分布出发,提出一种元余弦损失(meta-cosine loss,MCL)函数,优化少样本图像分类模型。使用样本与类原型间相似性的差调整不同类的原型,扩大类间距,使模型测试新任务时类间距更加明显,提升模型的泛化能力。结果分别在5个少样本经典数据集上进行了实验对比,在FC100(Few-shot Cifar100)和CUB(Caltech-UCSD Birds-200-2011)数据集上,本文方法均达到了目前最优分类效果;在MiniImageNet、TieredImageNet和Cifar100数据集上与对比模型的结果相当。同时,在MiniImageNet,CUB和 Cifar100数据集上进行对比实验以验证MCL的有效性,结果证明提出的MCL提升了余弦分类器的分类效果。结论本文方法能充分提取少样本图像分类任务中的图像特征,有效提升度量学习在少样本图像分类中的准确率。关键词:元学习;少样本学习(FSL);度量学习;元余弦损失(MCL);图像分类174|709|1更新时间:2024-02-16
摘要:目的度量学习是少样本学习中一种简单且有效的方法,学习一个丰富、具有判别性和泛化性强的嵌入空间是度量学习方法实现优秀分类效果的关键。本文从样本自身的特征以及特征在嵌入空间中的分布出发,结合全局与局部数据增强实现了一种元余弦损失的少样本图像分类方法(a meta-cosine loss for few-shot image classification,AMCL-FSIC)。方法首先,从数据自身特征出发,将全局与局部的数据增广方法结合起来,利于局部信息提供更具区别性和迁移性的信息,使训练模型更多关注图像的前景信息。同时,利用注意力机制结合全局与局部特征,以得到更丰富更具判别性的特征。其次,从样本特征在嵌入空间中的分布出发,提出一种元余弦损失(meta-cosine loss,MCL)函数,优化少样本图像分类模型。使用样本与类原型间相似性的差调整不同类的原型,扩大类间距,使模型测试新任务时类间距更加明显,提升模型的泛化能力。结果分别在5个少样本经典数据集上进行了实验对比,在FC100(Few-shot Cifar100)和CUB(Caltech-UCSD Birds-200-2011)数据集上,本文方法均达到了目前最优分类效果;在MiniImageNet、TieredImageNet和Cifar100数据集上与对比模型的结果相当。同时,在MiniImageNet,CUB和 Cifar100数据集上进行对比实验以验证MCL的有效性,结果证明提出的MCL提升了余弦分类器的分类效果。结论本文方法能充分提取少样本图像分类任务中的图像特征,有效提升度量学习在少样本图像分类中的准确率。关键词:元学习;少样本学习(FSL);度量学习;元余弦损失(MCL);图像分类174|709|1更新时间:2024-02-16 -
 摘要:目的三维点云分类作为一项关键任务,在计算机视觉、机器人和自动驾驶等领域有着广泛的应用场景。现有的三维点云分类网络在使用边卷积进行局部特征提取时通常存在输入特征差异性小,空间结构信息提取、融合不充分等问题。针对上述问题,设计了一种结合空间结构卷积和注意力机制的点云分类网络。方法首先,提出一种空间结构卷积,在边卷积的基础上引入邻接点之间的相对位置信息来降低输入特征相似性,而后从结构和位置两个角度分别进行特征编码,实现更具多样性的局部几何结构捕获。其次,设计了全局特征编码模块,从坐标信息中提炼全局特征信息,同时在网络中融合了注意力机制,用于关联局部和全局特征表示,有效保留了全局特征信息,实现全局特征的适应性调整。最后,将局部几何结构信息和全局位置信息进行有效的融合,获得更具代表性和差异性的特征表征。结果设计实验在公开数据集ModelNet40上对提出的网络模型的性能进行评估,点云分类总体准确率和平均准确率分别达到93.0%和89.7%,具备良好的分类性能和预测效率。实验结果表明,空间结构卷积的使用有效增加了输入特征的多样性,位置和结构的单独编码有效提高了局部特征的表达能力。同时,提出的注意力加权方式在保留全局特征前提下实现了局部特征和全局特征的关联。结论提出的网络有较强的细粒度特征提取能力,具有良好的分类性能。关键词:点云;边卷积(EdgeConv);空间结构;注意力机制;分类138|444|1更新时间:2024-02-16
摘要:目的三维点云分类作为一项关键任务,在计算机视觉、机器人和自动驾驶等领域有着广泛的应用场景。现有的三维点云分类网络在使用边卷积进行局部特征提取时通常存在输入特征差异性小,空间结构信息提取、融合不充分等问题。针对上述问题,设计了一种结合空间结构卷积和注意力机制的点云分类网络。方法首先,提出一种空间结构卷积,在边卷积的基础上引入邻接点之间的相对位置信息来降低输入特征相似性,而后从结构和位置两个角度分别进行特征编码,实现更具多样性的局部几何结构捕获。其次,设计了全局特征编码模块,从坐标信息中提炼全局特征信息,同时在网络中融合了注意力机制,用于关联局部和全局特征表示,有效保留了全局特征信息,实现全局特征的适应性调整。最后,将局部几何结构信息和全局位置信息进行有效的融合,获得更具代表性和差异性的特征表征。结果设计实验在公开数据集ModelNet40上对提出的网络模型的性能进行评估,点云分类总体准确率和平均准确率分别达到93.0%和89.7%,具备良好的分类性能和预测效率。实验结果表明,空间结构卷积的使用有效增加了输入特征的多样性,位置和结构的单独编码有效提高了局部特征的表达能力。同时,提出的注意力加权方式在保留全局特征前提下实现了局部特征和全局特征的关联。结论提出的网络有较强的细粒度特征提取能力,具有良好的分类性能。关键词:点云;边卷积(EdgeConv);空间结构;注意力机制;分类138|444|1更新时间:2024-02-16
图像理解和计算机视觉
-
 摘要:目的目标检测是遥感智能解译中重要的研究方向之一,大多数目标检测算法难以实现密集排列的旋转目标的高精度检测。提出了一种基于关键点与引导向量预测的目标检测算法,实现高精度旋转目标检测的同时,还可对目标的朝向进行表征。方法首先提出了一种新的旋转目标建模方式,将目标检测分解成中心点、头部顶点、引导向量以及目标宽度的参数回归以更贴合检测目标;其次设计旋转椭圆高斯核,能够更好地拟合遥感目标的形状,从而提升关键点的预测精度;最后通过预测中心点指向头部顶点的引导向量,完成同一个目标内中心点与头部顶点的匹配,从而生成一个精准的带方向的旋转矩形检测框。结果在大长宽比舰船目标的HRSC(high-resolution ship collections)数据集上的实验结果表明,相比于其他主流的目标检测算法,本文算法获得了更好的检测结果,在VOC 2007(visual object classes)和VOC 2012的平均精度分别达到了90.78%和97.85%。在小长宽比飞机目标UCAS-AOD(UCAS-high resolution aerial object detection dataset)数据集上达到了98.81%的平均精度。实验结果表明了本文算法的可行性与有效性。结论本文算法利用椭圆高斯核计算中心点与头部顶点,并设计引导向量对点匹配关系进行约束,实现了旋转目标的方向检测。关键词:目标检测;深度学习;旋转椭圆高斯核;引导向量;方向检测207|910|0更新时间:2024-02-16
摘要:目的目标检测是遥感智能解译中重要的研究方向之一,大多数目标检测算法难以实现密集排列的旋转目标的高精度检测。提出了一种基于关键点与引导向量预测的目标检测算法,实现高精度旋转目标检测的同时,还可对目标的朝向进行表征。方法首先提出了一种新的旋转目标建模方式,将目标检测分解成中心点、头部顶点、引导向量以及目标宽度的参数回归以更贴合检测目标;其次设计旋转椭圆高斯核,能够更好地拟合遥感目标的形状,从而提升关键点的预测精度;最后通过预测中心点指向头部顶点的引导向量,完成同一个目标内中心点与头部顶点的匹配,从而生成一个精准的带方向的旋转矩形检测框。结果在大长宽比舰船目标的HRSC(high-resolution ship collections)数据集上的实验结果表明,相比于其他主流的目标检测算法,本文算法获得了更好的检测结果,在VOC 2007(visual object classes)和VOC 2012的平均精度分别达到了90.78%和97.85%。在小长宽比飞机目标UCAS-AOD(UCAS-high resolution aerial object detection dataset)数据集上达到了98.81%的平均精度。实验结果表明了本文算法的可行性与有效性。结论本文算法利用椭圆高斯核计算中心点与头部顶点,并设计引导向量对点匹配关系进行约束,实现了旋转目标的方向检测。关键词:目标检测;深度学习;旋转椭圆高斯核;引导向量;方向检测207|910|0更新时间:2024-02-16 -
 摘要:目的针对合成孔径雷达(synthetic aperture radar, SAR)图像噪声大、成像特征不明显, 尤其在复杂场景更容易出现目标误检和漏检的问题,提出了一种融合多重机制的SAR舰船检测方法,用于提高SAR舰船检测的精度。方法在预处理部分,设计了U-Net Denoising模块,通过调整噪声方差参数L的范围来抑制相干斑噪声对图像的干扰。在YOLOv7(you only look once v7)主干网络构建MLAN_SC(maxpooling layer aggregation network that incorporate select kernel and contextual Transformer)结构,加入SK(selective kernel)通道注意力机制至下采样阶段,增强关键信息提取能力和特征表达能力。为解决MP(multiple pooling)结构中上下分支特征不平衡的问题,改善误检情况,融入上下文信息提取模块(contextual Transformer block, COT),利用卷积提取上下文信息,将局部信息和全局信息结合起来,使图像特征能够更有效地提取出来。在头部引入SPD卷积(space-to-depth convolution, SPD-Conv),增强小目标的检测能力。用WIoU(wise intersection over union)损失函数替换CIoU(complete intersection over union)损失函数,运用动态聚焦机制,在复杂图像上加强对目标的定位能力。结果在SSDD(SAR ship detection dataset)数据集和HRSID (high-resolution SAR images dataset)数据集上进行了实验对比,结果表明,改进后的方法相比于YOLOv7,AP(average precision)可达到99.25%和89.73%,分别提升了4.38%和2.57%,准确率和召回率为98.41%,93.24%和94.79%,81.83%,优于对比方法。结论本文通过融合多重机制改进YOLOv7方法,提升了对目标的定位能力,显著改善了SAR舰船检测中复杂舰船的误检和漏检情况,进一步提高了SAR舰船检测精度。关键词:SAR图像;舰船检测;YOLOv7;注意力机制;上下文信息提取;SPD卷积(SPD-Conv);WIoU损失函数295|1109|1更新时间:2024-02-16
摘要:目的针对合成孔径雷达(synthetic aperture radar, SAR)图像噪声大、成像特征不明显, 尤其在复杂场景更容易出现目标误检和漏检的问题,提出了一种融合多重机制的SAR舰船检测方法,用于提高SAR舰船检测的精度。方法在预处理部分,设计了U-Net Denoising模块,通过调整噪声方差参数L的范围来抑制相干斑噪声对图像的干扰。在YOLOv7(you only look once v7)主干网络构建MLAN_SC(maxpooling layer aggregation network that incorporate select kernel and contextual Transformer)结构,加入SK(selective kernel)通道注意力机制至下采样阶段,增强关键信息提取能力和特征表达能力。为解决MP(multiple pooling)结构中上下分支特征不平衡的问题,改善误检情况,融入上下文信息提取模块(contextual Transformer block, COT),利用卷积提取上下文信息,将局部信息和全局信息结合起来,使图像特征能够更有效地提取出来。在头部引入SPD卷积(space-to-depth convolution, SPD-Conv),增强小目标的检测能力。用WIoU(wise intersection over union)损失函数替换CIoU(complete intersection over union)损失函数,运用动态聚焦机制,在复杂图像上加强对目标的定位能力。结果在SSDD(SAR ship detection dataset)数据集和HRSID (high-resolution SAR images dataset)数据集上进行了实验对比,结果表明,改进后的方法相比于YOLOv7,AP(average precision)可达到99.25%和89.73%,分别提升了4.38%和2.57%,准确率和召回率为98.41%,93.24%和94.79%,81.83%,优于对比方法。结论本文通过融合多重机制改进YOLOv7方法,提升了对目标的定位能力,显著改善了SAR舰船检测中复杂舰船的误检和漏检情况,进一步提高了SAR舰船检测精度。关键词:SAR图像;舰船检测;YOLOv7;注意力机制;上下文信息提取;SPD卷积(SPD-Conv);WIoU损失函数295|1109|1更新时间:2024-02-16
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0