
最新刊期
2024 年 第 29 卷 第 12 期
-
 摘要:图像去模糊是计算机视觉的基础任务,对医学影像、监控摄像及卫星图像等领域具有重要意义。对于真实场景去模糊任务,由于场景内可能存在多个目标以及复杂的运动,成像过程容易受到许多外界因素的干扰,例如噪声、光照等,使图像去模糊问题更复杂。早期的研究主要针对仿真降质,但由于仿真模型受到多种假设限制,例如高斯噪声和全局一致运动等,难以在真实场景下展现出良好的复原效果。因此,越来越多的学者着手研究真实场景去模糊问题,以提升去模糊方法在现实生活中的使用价值。当前对真实场景下去模糊问题的综述性研究尚处于空白阶段,为此本文对真实场景去模糊任务进行了系统调研,分析其中存在的挑战,从降质模型的角度出发,由浅入深,由易到难,将真实场景下的去模糊问题拆解开,归纳为单一模糊去除方法、复合模糊去除方法以及真实场景下未知模糊去除方法,全方位描述了当前学术界在该问题上的研究内容和方法,总结和对比了各类方法的优缺点,阐述了阻碍复原性能进一步提升的难点问题,并对常用的一些数据集和评价指标进行了整理总结。最后,对真实场景去模糊任务的未来发展前景和研究热点进行了展望,并给出了可能的解决方法。关键词:图像去模糊;真实场景;非均匀模糊;复合模糊;未知降质表征982|669|0更新时间:2024-12-16
摘要:图像去模糊是计算机视觉的基础任务,对医学影像、监控摄像及卫星图像等领域具有重要意义。对于真实场景去模糊任务,由于场景内可能存在多个目标以及复杂的运动,成像过程容易受到许多外界因素的干扰,例如噪声、光照等,使图像去模糊问题更复杂。早期的研究主要针对仿真降质,但由于仿真模型受到多种假设限制,例如高斯噪声和全局一致运动等,难以在真实场景下展现出良好的复原效果。因此,越来越多的学者着手研究真实场景去模糊问题,以提升去模糊方法在现实生活中的使用价值。当前对真实场景下去模糊问题的综述性研究尚处于空白阶段,为此本文对真实场景去模糊任务进行了系统调研,分析其中存在的挑战,从降质模型的角度出发,由浅入深,由易到难,将真实场景下的去模糊问题拆解开,归纳为单一模糊去除方法、复合模糊去除方法以及真实场景下未知模糊去除方法,全方位描述了当前学术界在该问题上的研究内容和方法,总结和对比了各类方法的优缺点,阐述了阻碍复原性能进一步提升的难点问题,并对常用的一些数据集和评价指标进行了整理总结。最后,对真实场景去模糊任务的未来发展前景和研究热点进行了展望,并给出了可能的解决方法。关键词:图像去模糊;真实场景;非均匀模糊;复合模糊;未知降质表征982|669|0更新时间:2024-12-16 -
 摘要:人体姿态估计(human pose estimation,HPE)是计算机视觉中的一项基本任务,旨在从给定的图像中获取人体关节的空间坐标,在动作识别、语义分割、人机交互和人员重新识别等方面得到了广泛应用。随着深度卷积神经网络(deep convolutional neural network,DCNN)的兴起,人体姿态估计取得了显著进展。然而,尽管取得了不错的成果,人体姿态估计仍然是一项具有挑战性的任务,特别是在面对复杂姿态、关键点尺度的变化和遮挡等因素时。为了总结关于遮挡的人体姿态估计技术的发展,本文系统地概述了自2018年以来的代表性方法,根据神经网络包含的训练数据、模型结构以及输出结果,将方法细分为基于数据增广(data augmentation)的预处理、基于特征区分的结构设计和基于人体先验的结果优化3类。基于数据增广方法通过生成遮挡的数据来增加训练样本;基于特征区分的方法通过利用注意力机制等方式来减少干扰特征;基于人体结构先验的方法通过利用人体结构先验来优化遮挡姿态。同时,为了更好地评测遮挡方法的性能,重新标注了MSCOCO (Microsoft common objects in context)val2017数据集。最后,对各种方法进行了对比和总结,阐明了它们在面对遮挡时性能的优劣。此外,在此基础上总结和讨论了遮挡情况下人体姿态估计困难的原因以及该领域未来的发展趋势。关键词:人体姿态估计(HPE);遮挡;数据增广;人体结构先验;遮挡标注数据不足1012|568|0更新时间:2024-12-16
摘要:人体姿态估计(human pose estimation,HPE)是计算机视觉中的一项基本任务,旨在从给定的图像中获取人体关节的空间坐标,在动作识别、语义分割、人机交互和人员重新识别等方面得到了广泛应用。随着深度卷积神经网络(deep convolutional neural network,DCNN)的兴起,人体姿态估计取得了显著进展。然而,尽管取得了不错的成果,人体姿态估计仍然是一项具有挑战性的任务,特别是在面对复杂姿态、关键点尺度的变化和遮挡等因素时。为了总结关于遮挡的人体姿态估计技术的发展,本文系统地概述了自2018年以来的代表性方法,根据神经网络包含的训练数据、模型结构以及输出结果,将方法细分为基于数据增广(data augmentation)的预处理、基于特征区分的结构设计和基于人体先验的结果优化3类。基于数据增广方法通过生成遮挡的数据来增加训练样本;基于特征区分的方法通过利用注意力机制等方式来减少干扰特征;基于人体结构先验的方法通过利用人体结构先验来优化遮挡姿态。同时,为了更好地评测遮挡方法的性能,重新标注了MSCOCO (Microsoft common objects in context)val2017数据集。最后,对各种方法进行了对比和总结,阐明了它们在面对遮挡时性能的优劣。此外,在此基础上总结和讨论了遮挡情况下人体姿态估计困难的原因以及该领域未来的发展趋势。关键词:人体姿态估计(HPE);遮挡;数据增广;人体结构先验;遮挡标注数据不足1012|568|0更新时间:2024-12-16 -
 摘要:跨视角地理定位技术是计算机视觉领域中的重要问题之一,因其可在缺乏卫星定位环境中实现实时定位,一直受到图像配准、导航定位和图像检索等诸多领域的关注。传统的跨视角地理定位方法采用手工特征进行特征抽取,导致定位精度受限。随着深度学习技术的发展,深度学习的跨视角地理定位方法成为当前的主流技术。但由于跨视角地理定位任务涉及多个步骤、迁移知识广泛,因此本领域仍缺少相关综述。本文首次从跨视角地理定位任务框架的视角,对当前深度学习的跨视角地理定位方法进行全面综述。在问题概述的基础上,对数据预处理、深度学习网络、特征注意力模块和损失函数等技术的发展进行了归纳总结。通过对近百篇高影响力文献的梳理,本文总结出跨视角地理定位任务的特性和改进思路,有助于启发研究者设计新方法。此外,还在两个具有代表性的数据集上分别测试了10种不同深度学习的跨视角地理定位方法。从实验精度、模型的参数量和推理速度3个方面综合评估了现有方法的性能。最后,基于对上述跨视角地理定位方法的归纳分析,本文结合实际应用指出该领域存在的一些问题,并对未来发展趋势进行讨论,希望为该领域感兴趣的学者提供参考。关键词:跨视角;地理定位;图像检索;深度学习;注意力;无人机7188|2296|0更新时间:2024-12-16
摘要:跨视角地理定位技术是计算机视觉领域中的重要问题之一,因其可在缺乏卫星定位环境中实现实时定位,一直受到图像配准、导航定位和图像检索等诸多领域的关注。传统的跨视角地理定位方法采用手工特征进行特征抽取,导致定位精度受限。随着深度学习技术的发展,深度学习的跨视角地理定位方法成为当前的主流技术。但由于跨视角地理定位任务涉及多个步骤、迁移知识广泛,因此本领域仍缺少相关综述。本文首次从跨视角地理定位任务框架的视角,对当前深度学习的跨视角地理定位方法进行全面综述。在问题概述的基础上,对数据预处理、深度学习网络、特征注意力模块和损失函数等技术的发展进行了归纳总结。通过对近百篇高影响力文献的梳理,本文总结出跨视角地理定位任务的特性和改进思路,有助于启发研究者设计新方法。此外,还在两个具有代表性的数据集上分别测试了10种不同深度学习的跨视角地理定位方法。从实验精度、模型的参数量和推理速度3个方面综合评估了现有方法的性能。最后,基于对上述跨视角地理定位方法的归纳分析,本文结合实际应用指出该领域存在的一些问题,并对未来发展趋势进行讨论,希望为该领域感兴趣的学者提供参考。关键词:跨视角;地理定位;图像检索;深度学习;注意力;无人机7188|2296|0更新时间:2024-12-16
综述

-
 摘要:目的细粒度军事目标数据集是实现现代战争目标自动分类的重要支撑数据之一。当前缺乏高质量的细粒度军事目标遥感图像数据集,制约了军事目标自动精准检测的研究。为此,本文收集并标注了一个新的军用车辆细粒度检测遥感图像数据集MVRSD(military vehicle remote sensing dataset),并基于此设计了一种基于YOLOv5s(you only look once)的改进模型来提高军用车辆目标检测性能。方法该数据集来源于谷歌地球数据,收集了亚洲、北美洲和欧洲范围内40多个军事场景下的3 000幅遥感图像,包含多个国家和地区的军用车辆目标。经高质量人工水平边界框标注,最终形成包含5个类别共计32 626个实例的军用车辆细粒度检测遥感图像数据集。针对遥感图像中军用车辆识别难题,本文提出的基准模型考虑了遥感军用车辆目标较小、形状和外观较为模糊以及类间相似性、类内差异性大的特点,设计了基于目标尺寸的跨尺度检测头和上下文聚合模块,提升细粒度军用车辆目标的检测性能。结果提出的基准模型在军用车辆细粒度检测遥感图像数据集上的实验表明,对比经典的目标检测模型,新基准模型在平均精度均值(mean average precision,mAP)指标上提高了1.1%。结论本文构建的军用车辆细粒度检测遥感图像数据集为军事目标自动分类算法的研究提供了参考与支持,有助于更为全面地研究遥感图像中军用车辆目标的特性。数据集及检测基准模型地址为:https://github.com/baidongls/MVRSD。关键词:目标检测;军用车辆数据集;高分辨率遥感;细粒度;深度学习1187|1922|0更新时间:2024-12-16
摘要:目的细粒度军事目标数据集是实现现代战争目标自动分类的重要支撑数据之一。当前缺乏高质量的细粒度军事目标遥感图像数据集,制约了军事目标自动精准检测的研究。为此,本文收集并标注了一个新的军用车辆细粒度检测遥感图像数据集MVRSD(military vehicle remote sensing dataset),并基于此设计了一种基于YOLOv5s(you only look once)的改进模型来提高军用车辆目标检测性能。方法该数据集来源于谷歌地球数据,收集了亚洲、北美洲和欧洲范围内40多个军事场景下的3 000幅遥感图像,包含多个国家和地区的军用车辆目标。经高质量人工水平边界框标注,最终形成包含5个类别共计32 626个实例的军用车辆细粒度检测遥感图像数据集。针对遥感图像中军用车辆识别难题,本文提出的基准模型考虑了遥感军用车辆目标较小、形状和外观较为模糊以及类间相似性、类内差异性大的特点,设计了基于目标尺寸的跨尺度检测头和上下文聚合模块,提升细粒度军用车辆目标的检测性能。结果提出的基准模型在军用车辆细粒度检测遥感图像数据集上的实验表明,对比经典的目标检测模型,新基准模型在平均精度均值(mean average precision,mAP)指标上提高了1.1%。结论本文构建的军用车辆细粒度检测遥感图像数据集为军事目标自动分类算法的研究提供了参考与支持,有助于更为全面地研究遥感图像中军用车辆目标的特性。数据集及检测基准模型地址为:https://github.com/baidongls/MVRSD。关键词:目标检测;军用车辆数据集;高分辨率遥感;细粒度;深度学习1187|1922|0更新时间:2024-12-16
数据集
-
 摘要:目的针对目前已有的纹理结构滤波方法存在无法有效保证在滤除纹理的同时保持结构稳定的问题,提出一种正则化权值自适应的相对全变分图像平滑算法。方法首先,提出一种具有纹理抑制和结构保持的多尺度区间圆形梯度算子,其中引入了定向各向异性结构度量框架,提高了纹理—结构间的区分度。随后,利用高斯混合模型和EM(expectation maximization)算法实现纹理层和结构层的分离。最后,根据纹理和结构之间的差异性,对相对全变分模型中的正则化项进行自适应设置,使之可以在纹理区域利用大权重的正则化权值进行纹理抑制;在结构区域利用小权重的正则化权值进行结构保持。结果在视觉层面上,通过测试油画、十字绣、涂鸦、壁画和自然场景类型图像,并与已有的主流纹理结构滤波方法进行比较,本文算法不仅可以有效地抑制强梯度纹理,还可以保持弱梯度结构边缘的稳定;在定量度量方面,通过JPG格式图像压缩痕迹去除和高斯噪声图像平滑,并与相对全变分、滚动引导图像滤波、双边纹理滤波、尺度感知纹理滤波和
摘要:目的针对目前已有的纹理结构滤波方法存在无法有效保证在滤除纹理的同时保持结构稳定的问题,提出一种正则化权值自适应的相对全变分图像平滑算法。方法首先,提出一种具有纹理抑制和结构保持的多尺度区间圆形梯度算子,其中引入了定向各向异性结构度量框架,提高了纹理—结构间的区分度。随后,利用高斯混合模型和EM(expectation maximization)算法实现纹理层和结构层的分离。最后,根据纹理和结构之间的差异性,对相对全变分模型中的正则化项进行自适应设置,使之可以在纹理区域利用大权重的正则化权值进行纹理抑制;在结构区域利用小权重的正则化权值进行结构保持。结果在视觉层面上,通过测试油画、十字绣、涂鸦、壁画和自然场景类型图像,并与已有的主流纹理结构滤波方法进行比较,本文算法不仅可以有效地抑制强梯度纹理,还可以保持弱梯度结构边缘的稳定;在定量度量方面,通过JPG格式图像压缩痕迹去除和高斯噪声图像平滑,并与相对全变分、滚动引导图像滤波、双边纹理滤波、尺度感知纹理滤波和 -
 摘要:目的图像篡改检测主要分为图像区域复制篡改、图像拼接和对象移除3个方向,其中图像复制粘贴篡改是图像篡改检测的重要研究方向之一。针对目前大多数复制粘贴篡改检测方法难以检测平滑和小的篡改区域,且虚警率较高等问题,提出了一种基于匹配对的密度聚类MP-DBSCAN(matched pairs——density based spatial clustering of applications with noise)和点密度过滤策略的图像复制粘贴篡改检测方法。方法首先,在图像中提取大量关键点,根据关键点的灰度值分组后进行匹配。其次,提出了一种改进的密度聚类算法MP-DBSCAN,聚类对象为匹配对的一侧,并利用匹配对的另一侧约束聚类过程,即使篡改区域在空间上距离较近,或者篡改区域存在多个的情况,也能把不同的篡改区域较好地区分开来。此外,本文还提出了一种点密度过滤策略,通过删除低密度簇,降低了检测结果的虚警率。最后,通过估计仿射矩阵并使用ZNCC (zero-mean normalized cross-correlation)算法定位篡改区域。结果消融实验表明了MP-DBSCAN算法和点密度过滤策略的有效性。在FAU、MICC-F600、GRIP和CASIA v2.0这4个数据集上与几个经典的和新颖的检测方法进行了对比实验,本文方法的F1在4个数据集上像素层的实验结果分别是0.914 3、0.890 6、0.939 1和0.856 8。结论本文提出的MP-DBSCAN聚类算法和点密度过滤策略能有效提高检测算法的性能,即使篡改区域经过旋转、缩放、压缩和添加噪声等处理,本文方法依然能够检测出大部分的篡改区域,性能优于当前的检测算法。关键词:多媒体取证;图像取证;图像篡改检测;复制粘贴篡改;基于密度的带噪声空间聚类(DBSCAN)236|392|0更新时间:2024-12-16
摘要:目的图像篡改检测主要分为图像区域复制篡改、图像拼接和对象移除3个方向,其中图像复制粘贴篡改是图像篡改检测的重要研究方向之一。针对目前大多数复制粘贴篡改检测方法难以检测平滑和小的篡改区域,且虚警率较高等问题,提出了一种基于匹配对的密度聚类MP-DBSCAN(matched pairs——density based spatial clustering of applications with noise)和点密度过滤策略的图像复制粘贴篡改检测方法。方法首先,在图像中提取大量关键点,根据关键点的灰度值分组后进行匹配。其次,提出了一种改进的密度聚类算法MP-DBSCAN,聚类对象为匹配对的一侧,并利用匹配对的另一侧约束聚类过程,即使篡改区域在空间上距离较近,或者篡改区域存在多个的情况,也能把不同的篡改区域较好地区分开来。此外,本文还提出了一种点密度过滤策略,通过删除低密度簇,降低了检测结果的虚警率。最后,通过估计仿射矩阵并使用ZNCC (zero-mean normalized cross-correlation)算法定位篡改区域。结果消融实验表明了MP-DBSCAN算法和点密度过滤策略的有效性。在FAU、MICC-F600、GRIP和CASIA v2.0这4个数据集上与几个经典的和新颖的检测方法进行了对比实验,本文方法的F1在4个数据集上像素层的实验结果分别是0.914 3、0.890 6、0.939 1和0.856 8。结论本文提出的MP-DBSCAN聚类算法和点密度过滤策略能有效提高检测算法的性能,即使篡改区域经过旋转、缩放、压缩和添加噪声等处理,本文方法依然能够检测出大部分的篡改区域,性能优于当前的检测算法。关键词:多媒体取证;图像取证;图像篡改检测;复制粘贴篡改;基于密度的带噪声空间聚类(DBSCAN)236|392|0更新时间:2024-12-16 -
 摘要:目的现有点云几何压缩算法通常将点云转换为八叉树或带潜在特征的稀疏点,从而提高数据结构的存储效率。这些方法将点云量化至三维网格点,导致点云所在表面的精度受限于量化分辨率。针对这一问题,本文将点云转化为连续的隐式表征,提出一种基于隐式表征的点云几何压缩算法框架,以克服量化分辨率对压缩质量的不利影响。方法该框架由基于符号对数距离场的隐式表征与带乘性分支结构的神经网络组成。具体来说,本文在编码阶段利用神经网络拟合隐式表征,并对该网络进行模型压缩,然后在解码阶段结合改进的 Marching Cube(MC)算法重建点云所在表面,采样恢复点云数据。结果本文在ABC(a big CAD model dataset)、Famous与 MPEG PCC(MPEG point cloud compression dataset) 数据集上进行了点云表面压缩实验。与基准算法INR(implicit neural representations for image compression)相比,本文算法的L1倒角损失平均下降了12.4%,Normal Consistency与F-score指标平均提升了1.5%与13.6%,压缩效率随模型参数量增大而提升,平均增幅为12.9%。与几何压缩标准算法G-PCC(geometry-based point cloud compression)相比,本文算法在存储大小为10 KB下依然保持55 dB以上的D1-PSNR重建性能,有效压缩上限高于G-PCC。此外,消融实验分别验证了本文提出的隐式表征和神经网络结构的有效性。结论实验结果表明,本文提出的点云压缩算法克服了现有算法的分辨率限制,不仅提升了表面重建精度,而且提升了点云表面的压缩效率与有效压缩上限。关键词:点云几何压缩;隐式表征;三维重建;模型压缩;表面提取算法239|455|0更新时间:2024-12-16
摘要:目的现有点云几何压缩算法通常将点云转换为八叉树或带潜在特征的稀疏点,从而提高数据结构的存储效率。这些方法将点云量化至三维网格点,导致点云所在表面的精度受限于量化分辨率。针对这一问题,本文将点云转化为连续的隐式表征,提出一种基于隐式表征的点云几何压缩算法框架,以克服量化分辨率对压缩质量的不利影响。方法该框架由基于符号对数距离场的隐式表征与带乘性分支结构的神经网络组成。具体来说,本文在编码阶段利用神经网络拟合隐式表征,并对该网络进行模型压缩,然后在解码阶段结合改进的 Marching Cube(MC)算法重建点云所在表面,采样恢复点云数据。结果本文在ABC(a big CAD model dataset)、Famous与 MPEG PCC(MPEG point cloud compression dataset) 数据集上进行了点云表面压缩实验。与基准算法INR(implicit neural representations for image compression)相比,本文算法的L1倒角损失平均下降了12.4%,Normal Consistency与F-score指标平均提升了1.5%与13.6%,压缩效率随模型参数量增大而提升,平均增幅为12.9%。与几何压缩标准算法G-PCC(geometry-based point cloud compression)相比,本文算法在存储大小为10 KB下依然保持55 dB以上的D1-PSNR重建性能,有效压缩上限高于G-PCC。此外,消融实验分别验证了本文提出的隐式表征和神经网络结构的有效性。结论实验结果表明,本文提出的点云压缩算法克服了现有算法的分辨率限制,不仅提升了表面重建精度,而且提升了点云表面的压缩效率与有效压缩上限。关键词:点云几何压缩;隐式表征;三维重建;模型压缩;表面提取算法239|455|0更新时间:2024-12-16 -
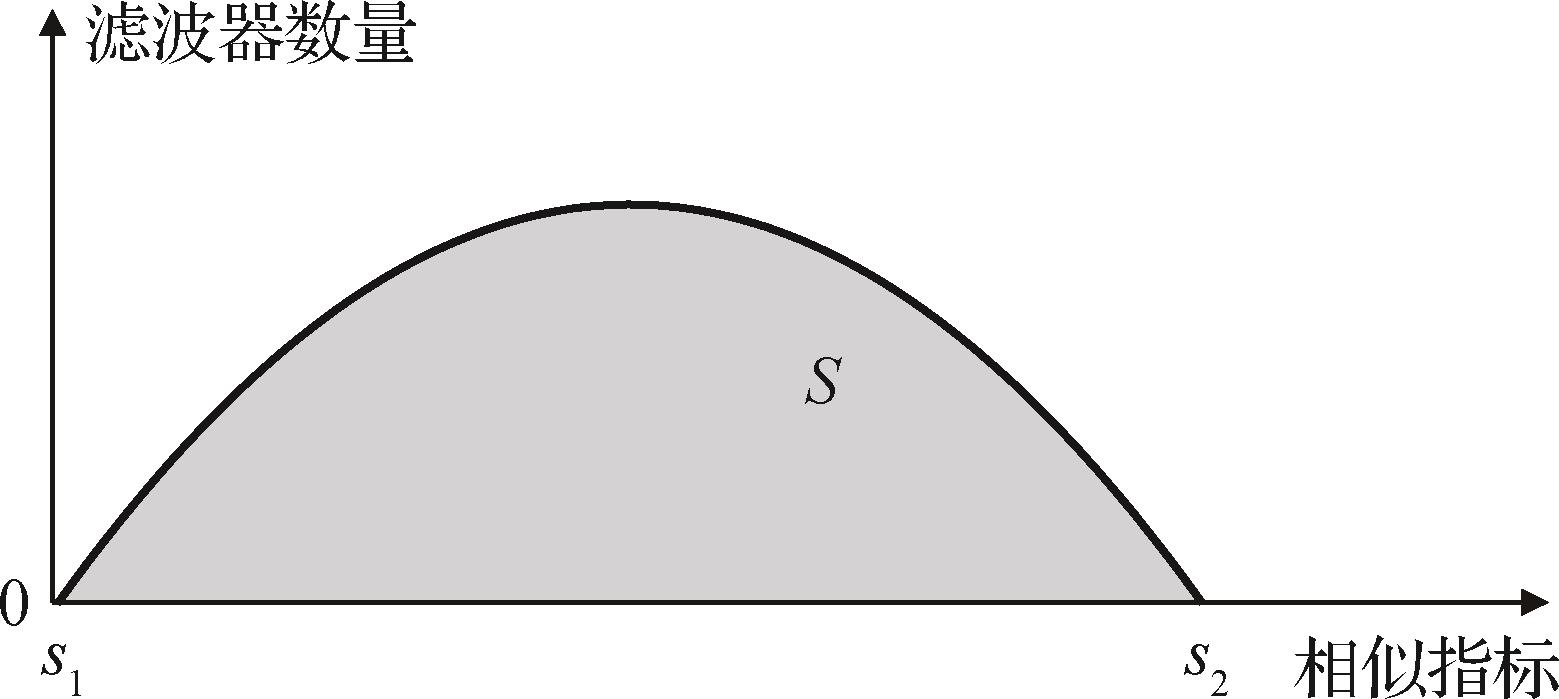 摘要:目的深度神经网络在图形图像、计算机视觉等众多应用领域取得了令人瞩目的效果,但是一直以来深度学习网络模型由于其庞大的计算量以及存储资源而无法部署在资源受限的嵌入式设备端。为了解决模型所需的计算资源和嵌入式设备资源受限之间的矛盾,提出了一种引入余弦空间相关的两阶段滤波器剪枝方法,旨在利用滤波器间的空间相关性实现更优的剪枝方式。方法在预剪枝阶段引入L范数记录下范数值最高的滤波器,本文称为关键滤波器;在剪枝阶段引入余弦距离保留和关键滤波器空间相关性高的滤波器。结果本文提出的剪枝方法在CIFAR(Canadian Institute for Advanced Research)数据集上取得了优于其他对比方法的效果,在CIFAR10数据集上将VGG(Visual Geometry Group)16的参数量和浮点运算量分别压缩了72.9%和73.5%,同时模型精度提升了0.1%。对于高效的残差网络ResNet(residual neural network)56和深度可分离网络MobileNet V1也可以有效地压缩,该方法在CIFAR100数据集上对ResNet56网络在更高的压缩率下实现了更小的精度损失(精度提升0.48%)。对于MobileNet V1网络,压缩了46.89%的参数量和46.23%的浮点运算量,而模型精度提升了0.11%。结论引入余弦空间相关性的两阶段滤波器剪枝策略避免了网络剪枝中“衡量指标小,则衡量对象不重要”和“相似即冗余”两种假设不成立而导致模型陷入次优结果,从滤波器空间的角度挖掘相关性,在保证模型准确率的前提下能够压缩更多的参数量和浮点运算量。关键词:深度学习;神经网络;模型压缩;余弦距离;滤波器剪枝197|476|0更新时间:2024-12-16
摘要:目的深度神经网络在图形图像、计算机视觉等众多应用领域取得了令人瞩目的效果,但是一直以来深度学习网络模型由于其庞大的计算量以及存储资源而无法部署在资源受限的嵌入式设备端。为了解决模型所需的计算资源和嵌入式设备资源受限之间的矛盾,提出了一种引入余弦空间相关的两阶段滤波器剪枝方法,旨在利用滤波器间的空间相关性实现更优的剪枝方式。方法在预剪枝阶段引入L范数记录下范数值最高的滤波器,本文称为关键滤波器;在剪枝阶段引入余弦距离保留和关键滤波器空间相关性高的滤波器。结果本文提出的剪枝方法在CIFAR(Canadian Institute for Advanced Research)数据集上取得了优于其他对比方法的效果,在CIFAR10数据集上将VGG(Visual Geometry Group)16的参数量和浮点运算量分别压缩了72.9%和73.5%,同时模型精度提升了0.1%。对于高效的残差网络ResNet(residual neural network)56和深度可分离网络MobileNet V1也可以有效地压缩,该方法在CIFAR100数据集上对ResNet56网络在更高的压缩率下实现了更小的精度损失(精度提升0.48%)。对于MobileNet V1网络,压缩了46.89%的参数量和46.23%的浮点运算量,而模型精度提升了0.11%。结论引入余弦空间相关性的两阶段滤波器剪枝策略避免了网络剪枝中“衡量指标小,则衡量对象不重要”和“相似即冗余”两种假设不成立而导致模型陷入次优结果,从滤波器空间的角度挖掘相关性,在保证模型准确率的前提下能够压缩更多的参数量和浮点运算量。关键词:深度学习;神经网络;模型压缩;余弦距离;滤波器剪枝197|476|0更新时间:2024-12-16
图像处理和编码
-
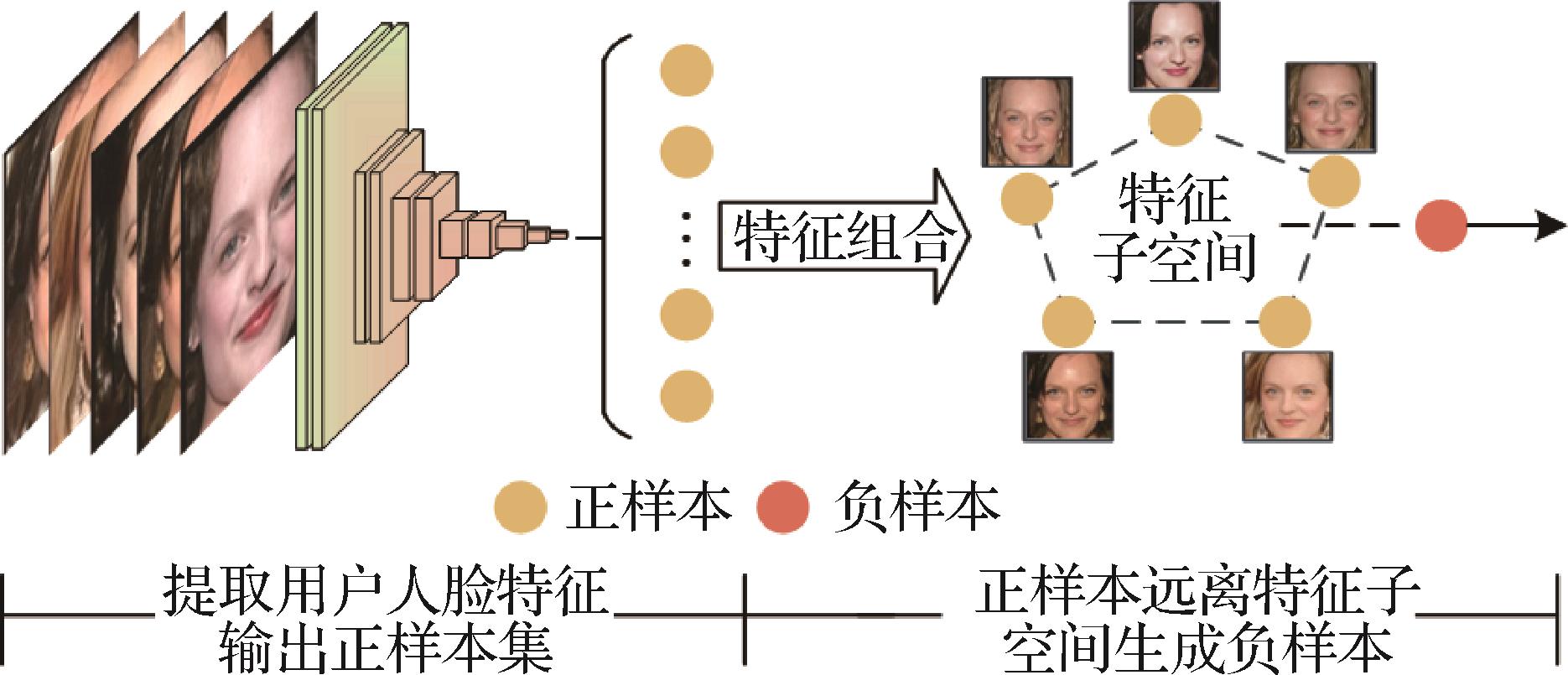 摘要:目的人脸图像去识别是保护人脸隐私的一种手段,类通用扰动作为人脸图像去识别的一种方法,为每个用户生成专属扰动来抵御深度人脸识别系统的恶意分析行为。针对现有类通用扰动方法存在用户训练数据不足的问题以及进一步提升扰动保护效果的需要,提出基于三元组损失约束的类通用扰动生成方法,同时引入一种基于特征子空间方法扩充训练数据构建三元组所需的负样本。方法首先将深度神经网络提取的用户人脸图像特征作为正样本,然后对单个用户所有正样本进行仿射组合构建特征子空间,再结合凸优化方法训练样本远离特征子空间,生成负样本扩充训练数据。之后对原始图像叠加随机扰动,提取特征得到待训样本。利用三元组函数约束扰动训练过程,使待训样本远离正样本的同时靠近负样本,并以余弦距离作为指标计算损失值。对训练生成的扰动施加一个缩放变换,得到用户的类通用扰动。结果针对具有不同损失函数(ArcFace、SFace和CosFace)和网络架构(SENet、MobileNet和IResNet)的6个人脸识别模型在2个数据集上进行实验,与相关的4种方法进行比较均取得了最优效果。在Privacy-Commons和Privacy-Celebrities数据集上,相比已知最优的方法,扰动训练效率平均提升了66.5%,保护成功率平均提升了5.76%。结论本文提出的三元组约束扰动生成方法,在兼顾扰动生成效率的同时,既缓解了训练样本不足的问题,又使类通用扰动综合了梯度攻击信息和特征攻击信息,提升了人脸隐私保护效果。关键词:类通用扰动;三元组约束;人脸图像去识别;数据扩充;人脸隐私保护142|381|0更新时间:2024-12-16
摘要:目的人脸图像去识别是保护人脸隐私的一种手段,类通用扰动作为人脸图像去识别的一种方法,为每个用户生成专属扰动来抵御深度人脸识别系统的恶意分析行为。针对现有类通用扰动方法存在用户训练数据不足的问题以及进一步提升扰动保护效果的需要,提出基于三元组损失约束的类通用扰动生成方法,同时引入一种基于特征子空间方法扩充训练数据构建三元组所需的负样本。方法首先将深度神经网络提取的用户人脸图像特征作为正样本,然后对单个用户所有正样本进行仿射组合构建特征子空间,再结合凸优化方法训练样本远离特征子空间,生成负样本扩充训练数据。之后对原始图像叠加随机扰动,提取特征得到待训样本。利用三元组函数约束扰动训练过程,使待训样本远离正样本的同时靠近负样本,并以余弦距离作为指标计算损失值。对训练生成的扰动施加一个缩放变换,得到用户的类通用扰动。结果针对具有不同损失函数(ArcFace、SFace和CosFace)和网络架构(SENet、MobileNet和IResNet)的6个人脸识别模型在2个数据集上进行实验,与相关的4种方法进行比较均取得了最优效果。在Privacy-Commons和Privacy-Celebrities数据集上,相比已知最优的方法,扰动训练效率平均提升了66.5%,保护成功率平均提升了5.76%。结论本文提出的三元组约束扰动生成方法,在兼顾扰动生成效率的同时,既缓解了训练样本不足的问题,又使类通用扰动综合了梯度攻击信息和特征攻击信息,提升了人脸隐私保护效果。关键词:类通用扰动;三元组约束;人脸图像去识别;数据扩充;人脸隐私保护142|381|0更新时间:2024-12-16 -
 摘要:目的考虑到图像信息在视觉通路中的表征是多尺度的,为了实现自然场景下多对比度分布图像的轮廓检测任务,提出了一种基于双视通路尺度信息融合的轮廓检测新方法。方法首先构建对亮度信息敏感和对颜色信息敏感的大细胞(M)、小细胞(P)并行通路,构建不同尺度的感受野模拟神经节细胞对刺激的模糊和精细感知,使用亮度对比度和色差信息指导不同尺度感受野响应的自适应融合,使其能够充分提取亮度轮廓和颜色轮廓。其次结合外膝体(lateral geniculate nucleus,LGN)多尺度方向差异编码与多尺度朝向选择性抑制方法,构建显著轮廓提取模型,实现轮廓区域的增强以及背景纹理的抑制。最后将加工后的亮度轮廓和颜色轮廓前馈至初级视皮层(V1)区,构建双通道响应权重调节模型整合M、P通路所得信息,进一步丰富轮廓。结果本文使用BSDS500(berkeley segmentation data set)图像库和NYUD(New York University-depth)图像库对提出的算法进行验证,其中在BSDS500图像库的最优平均准确率(average precision,AP)指标为0.74,相对于SCSI(subfield-based center-surround inhibition)、BAR(bilateral asymmetric receptive)和SED(surround-modulated edge detection)等基于生物视觉机制的检测方法有4%~13%的提升,所得结果轮廓图也更为连续、准确。结论本文利用M、P双通路机制以及亮度信息和颜色信息在前端视觉通路中的编码过程实现轮廓信息的加工与提取,可以有效实现自然图像的轮廓检测,尤其是对于图像中的细微轮廓边缘的检测,也为研究更高级皮层中视觉信息机制提供新的思路。关键词:轮廓检测;双视通路;多尺度;自适应融合;方向差异246|733|0更新时间:2024-12-16
摘要:目的考虑到图像信息在视觉通路中的表征是多尺度的,为了实现自然场景下多对比度分布图像的轮廓检测任务,提出了一种基于双视通路尺度信息融合的轮廓检测新方法。方法首先构建对亮度信息敏感和对颜色信息敏感的大细胞(M)、小细胞(P)并行通路,构建不同尺度的感受野模拟神经节细胞对刺激的模糊和精细感知,使用亮度对比度和色差信息指导不同尺度感受野响应的自适应融合,使其能够充分提取亮度轮廓和颜色轮廓。其次结合外膝体(lateral geniculate nucleus,LGN)多尺度方向差异编码与多尺度朝向选择性抑制方法,构建显著轮廓提取模型,实现轮廓区域的增强以及背景纹理的抑制。最后将加工后的亮度轮廓和颜色轮廓前馈至初级视皮层(V1)区,构建双通道响应权重调节模型整合M、P通路所得信息,进一步丰富轮廓。结果本文使用BSDS500(berkeley segmentation data set)图像库和NYUD(New York University-depth)图像库对提出的算法进行验证,其中在BSDS500图像库的最优平均准确率(average precision,AP)指标为0.74,相对于SCSI(subfield-based center-surround inhibition)、BAR(bilateral asymmetric receptive)和SED(surround-modulated edge detection)等基于生物视觉机制的检测方法有4%~13%的提升,所得结果轮廓图也更为连续、准确。结论本文利用M、P双通路机制以及亮度信息和颜色信息在前端视觉通路中的编码过程实现轮廓信息的加工与提取,可以有效实现自然图像的轮廓检测,尤其是对于图像中的细微轮廓边缘的检测,也为研究更高级皮层中视觉信息机制提供新的思路。关键词:轮廓检测;双视通路;多尺度;自适应融合;方向差异246|733|0更新时间:2024-12-16 -
 摘要:目的对抗样本对深度神经网络(deep neural network,DNN)的安全性构成了重大威胁,此现象引起了广泛的关注。当前许多黑盒对抗攻击方法普遍存在一个问题:它们仅在空间域或频率域单一域中进行对抗攻击,生成的对抗样本无法充分利用目标模型在其他域中的潜在脆弱性,导致对抗样本的迁移性不佳。为此,提出一种多域特征混合增强对抗样本迁移性方法(multiple domain feature mixup,MDFM),以提高对抗样本在黑盒场景下的攻击成功率。方法使用离散余弦变换将图像从空间域变换到频率域,存储原始图像的清洁频率域特征。然后利用逆离散余弦变换将图像转换回空间域。之后利用替代模型提取图像的清洁空间域特征。在生成对抗样本的过程中,通过在频率域和空间域中进行特征混合,最终生成迁移性更好的对抗样本。结果在CIFAR-10和ImageNet数据集上进行了广泛实验,并对比了多种不同的攻击方法。在CIFAR-10数据集上,对不同模型的平均攻击成功率达到了89.8%。在ImageNet数据集上,分别使用ResNet-50和Inception-v3作为替代模型时,在不同的DNN模型上的平均攻击成功率达到75.9%和40.6%;当分别使用ResNet-50和adv-ResNet-50作为替代模型并在基于Transformer的模型上进行测试时,平均攻击成功率为32.3%和59.4%,超越了目前先进的黑盒对抗攻击方法。结论多域特征混合增强对抗样本迁移性方法通过在空间域和频率域上进行特征混合,促使对抗样本利用多域中广泛的特征来克服清洁特征带来的干扰,从而提高对抗样本的迁移性。本文的代码可以在https://github.com/linghuchong111da/MDFM获取。关键词:对抗样本;频率域;特征混合;黑盒对抗攻击;深度神经网络(DNN)342|486|0更新时间:2024-12-16
摘要:目的对抗样本对深度神经网络(deep neural network,DNN)的安全性构成了重大威胁,此现象引起了广泛的关注。当前许多黑盒对抗攻击方法普遍存在一个问题:它们仅在空间域或频率域单一域中进行对抗攻击,生成的对抗样本无法充分利用目标模型在其他域中的潜在脆弱性,导致对抗样本的迁移性不佳。为此,提出一种多域特征混合增强对抗样本迁移性方法(multiple domain feature mixup,MDFM),以提高对抗样本在黑盒场景下的攻击成功率。方法使用离散余弦变换将图像从空间域变换到频率域,存储原始图像的清洁频率域特征。然后利用逆离散余弦变换将图像转换回空间域。之后利用替代模型提取图像的清洁空间域特征。在生成对抗样本的过程中,通过在频率域和空间域中进行特征混合,最终生成迁移性更好的对抗样本。结果在CIFAR-10和ImageNet数据集上进行了广泛实验,并对比了多种不同的攻击方法。在CIFAR-10数据集上,对不同模型的平均攻击成功率达到了89.8%。在ImageNet数据集上,分别使用ResNet-50和Inception-v3作为替代模型时,在不同的DNN模型上的平均攻击成功率达到75.9%和40.6%;当分别使用ResNet-50和adv-ResNet-50作为替代模型并在基于Transformer的模型上进行测试时,平均攻击成功率为32.3%和59.4%,超越了目前先进的黑盒对抗攻击方法。结论多域特征混合增强对抗样本迁移性方法通过在空间域和频率域上进行特征混合,促使对抗样本利用多域中广泛的特征来克服清洁特征带来的干扰,从而提高对抗样本的迁移性。本文的代码可以在https://github.com/linghuchong111da/MDFM获取。关键词:对抗样本;频率域;特征混合;黑盒对抗攻击;深度神经网络(DNN)342|486|0更新时间:2024-12-16
图像分析和识别
-
 摘要:目的深度神经网络在计算机视觉分类任务上表现出优秀的性能,然而,在标签噪声环境下,深度学习模型面临着严峻的考验。基于协同学习(co-teaching)的学习算法能够有效缓解神经网络对噪声标签数据的学习问题,但仍然存在许多不足之处。为此,提出了一种协同学习中考虑历史信息的标签噪声鲁棒学习方法(Co-history)。方法首先,针对在噪声标签环境下使用交叉熵损失函数(cross entropy,CE)存在的过拟合问题,通过分析样本损失的历史规律,提出了修正损失函数,在模型训练时减弱CE损失带来的过拟合带来的影响。其次,针对co-teaching算法中两个网络存在过早收敛的问题,提出差异损失函数,在训练过程中保持两个网络的差异性。最后,遵循小损失选择策略,通过结合样本历史损失,提出了新的样本选择方法,可以更加精准地选择干净样本。结果在4个模拟噪声数据集F-MNIST(Fashion-mixed National Institute of Standards and Technology)、SVHN(street view house number)、CIFAR-10(Canadian Institute for Advanced Research-10)和CIFAR-100和一个真实数据集Clothing1M上进行对比实验。其中,在F-MNIST、SVHN、CIFAR-10、CIFAR-100,对称噪声(symmetric)40%噪声率下,对比co-teaching算法,本文方法分别提高了3.52%、4.77%、6.16%和6.96%;在真实数据集Clothing1M下,对比co-teaching算法,本文方法的最佳准确率和最后准确率分别提高了0.94%和1.2%。结论本文提出的协同学习下考虑历史损失的带噪声标签鲁棒分类算法,经过大量实验论证,可以有效降低噪声标签带来的影响,提高模型分类准确率。关键词:深度神经网络(DNN);分类;噪声标签;协同学习;历史损失211|435|0更新时间:2024-12-16
摘要:目的深度神经网络在计算机视觉分类任务上表现出优秀的性能,然而,在标签噪声环境下,深度学习模型面临着严峻的考验。基于协同学习(co-teaching)的学习算法能够有效缓解神经网络对噪声标签数据的学习问题,但仍然存在许多不足之处。为此,提出了一种协同学习中考虑历史信息的标签噪声鲁棒学习方法(Co-history)。方法首先,针对在噪声标签环境下使用交叉熵损失函数(cross entropy,CE)存在的过拟合问题,通过分析样本损失的历史规律,提出了修正损失函数,在模型训练时减弱CE损失带来的过拟合带来的影响。其次,针对co-teaching算法中两个网络存在过早收敛的问题,提出差异损失函数,在训练过程中保持两个网络的差异性。最后,遵循小损失选择策略,通过结合样本历史损失,提出了新的样本选择方法,可以更加精准地选择干净样本。结果在4个模拟噪声数据集F-MNIST(Fashion-mixed National Institute of Standards and Technology)、SVHN(street view house number)、CIFAR-10(Canadian Institute for Advanced Research-10)和CIFAR-100和一个真实数据集Clothing1M上进行对比实验。其中,在F-MNIST、SVHN、CIFAR-10、CIFAR-100,对称噪声(symmetric)40%噪声率下,对比co-teaching算法,本文方法分别提高了3.52%、4.77%、6.16%和6.96%;在真实数据集Clothing1M下,对比co-teaching算法,本文方法的最佳准确率和最后准确率分别提高了0.94%和1.2%。结论本文提出的协同学习下考虑历史损失的带噪声标签鲁棒分类算法,经过大量实验论证,可以有效降低噪声标签带来的影响,提高模型分类准确率。关键词:深度神经网络(DNN);分类;噪声标签;协同学习;历史损失211|435|0更新时间:2024-12-16 -
 摘要:目的全景图像质量评价(omnidirectional image quality assessment,OIQA)旨在定量描述全景图像降质情况,对于算法提升和系统优化起着重要的作用。早期的OIQA方法设计思想主要是结合全景图像的几何特性(如两级畸变和语义分布不均匀)和2D-IQA方法,这类方法并未考虑用户的观看行为,因而性能一般;现有的OIQA方法主要通过模拟用户的观看行为,提取观看视口序列;进一步,计算视口序列失真情况,然后融合视口失真得到全景图像的全局质量。然而,观看视口序列预测较为困难,且预测模型的实时性和鲁棒性难以保证。为了解决上述问题,提出一种非视口依赖的抗畸变无参考(no reference,NR)OIQA(NR-OIQA)模型。针对全景图像等距柱状投影(equirectangular projection,ERP)所带来的规律性几何畸变问题,提出一种可同时处理不规则语义和规律性畸变的新型卷积方法,称为等矩形可变形卷积方法,并基于该卷积方法构建NR-OIQA模型。方法该模型主要由先验指导的图像块采样(prior-guided patch sampling,PPS)模块、抗畸变特征提取(deformation-unaware feature extraction,DUFE)模块和块内—块间注意力聚集(intra-inter patch attention aggregation,A-EPAA)模块3个部件组成。其中,PPS模块根据先验概率分布从高分辨率的全景图像采样提取相同分辨率的图像块;DUFE模块通过等矩形可变形卷积渐进式地提取输入图像块质量相关特征;A-EPAA模块旨在调整单个图像块内部特征以及各图像块对整体质量评价的影响程度,以提升模型对全景图像质量的评价准确度。结果在3个公开数据集上将本文模型与其他IQA和OIQA模型进行性能比较,与性能第1的Assessor360相比,参数量减少了93.7%,计算量减少了95.4%;与模型规模近似的MC360IQA相比,在CVIQ、OIQA和JUFE数据集上的斯皮尔曼相关系数分别提升了1.9%、1.7%和4.3%。结论本文所提出的NR-OIQA模型,充分考虑了全景图像的特点,能够以不依赖视口的方式高效提取具有失真特性的质量特征,对全景图像进行准确质量评价,并具有计算量低的优点。关键词:图像质量评价(IQA);全景图像;可变形卷积;注意力机制;无参考;视口281|513|0更新时间:2024-12-16
摘要:目的全景图像质量评价(omnidirectional image quality assessment,OIQA)旨在定量描述全景图像降质情况,对于算法提升和系统优化起着重要的作用。早期的OIQA方法设计思想主要是结合全景图像的几何特性(如两级畸变和语义分布不均匀)和2D-IQA方法,这类方法并未考虑用户的观看行为,因而性能一般;现有的OIQA方法主要通过模拟用户的观看行为,提取观看视口序列;进一步,计算视口序列失真情况,然后融合视口失真得到全景图像的全局质量。然而,观看视口序列预测较为困难,且预测模型的实时性和鲁棒性难以保证。为了解决上述问题,提出一种非视口依赖的抗畸变无参考(no reference,NR)OIQA(NR-OIQA)模型。针对全景图像等距柱状投影(equirectangular projection,ERP)所带来的规律性几何畸变问题,提出一种可同时处理不规则语义和规律性畸变的新型卷积方法,称为等矩形可变形卷积方法,并基于该卷积方法构建NR-OIQA模型。方法该模型主要由先验指导的图像块采样(prior-guided patch sampling,PPS)模块、抗畸变特征提取(deformation-unaware feature extraction,DUFE)模块和块内—块间注意力聚集(intra-inter patch attention aggregation,A-EPAA)模块3个部件组成。其中,PPS模块根据先验概率分布从高分辨率的全景图像采样提取相同分辨率的图像块;DUFE模块通过等矩形可变形卷积渐进式地提取输入图像块质量相关特征;A-EPAA模块旨在调整单个图像块内部特征以及各图像块对整体质量评价的影响程度,以提升模型对全景图像质量的评价准确度。结果在3个公开数据集上将本文模型与其他IQA和OIQA模型进行性能比较,与性能第1的Assessor360相比,参数量减少了93.7%,计算量减少了95.4%;与模型规模近似的MC360IQA相比,在CVIQ、OIQA和JUFE数据集上的斯皮尔曼相关系数分别提升了1.9%、1.7%和4.3%。结论本文所提出的NR-OIQA模型,充分考虑了全景图像的特点,能够以不依赖视口的方式高效提取具有失真特性的质量特征,对全景图像进行准确质量评价,并具有计算量低的优点。关键词:图像质量评价(IQA);全景图像;可变形卷积;注意力机制;无参考;视口281|513|0更新时间:2024-12-16 -
 摘要:目的骨骼运动重定向是指将源角色的骨骼运动数据,修改后运用到另一个具有不同骨架结构的目标角色上,使得目标角色和源角色做出相同的动作。由于骨骼运动数据与骨架结构之间具有高耦合性,重定向算法需要从运动数据中分离出与骨架结构无关、只表示动作类型的特征。当源角色与目标角色骨架结构不同,且两者运动模式(如关节角变化范围)存在较大差异时,特征分离难度加大,重定向网络训练难度变大。针对该问题,提出了特征分离的方法和高阶骨骼卷积算子。方法在数据处理阶段,首先从运动数据中分离出一部分与骨架结构无关的特征,从而降低重定向网络训练难度,得到更好的重定向结果。另外,结合图卷积网络,本文针对人体骨架结构提出了高阶骨骼卷积算子。使用该算子,本文网络模型可以捕获更多有关骨架结构的信息,提高重定向结果的精度和视觉效果。结果在异构重定向任务中,本文方法在合成动画数据集Mixamo上与最新方法对比,重定向结果精度提升了38.6%。另外,本文方法也同样适用于同构重定向,结果精度比最新方法提升了74.8%。在从真人采集的运动数据到虚拟动画角色的异构重定向任务中,相比最新方法,本文方法能够明显减少重定向错误,重定向结果有更高的视觉质量。结论相比较于目前最新的方法,本文方法降低了特征分离的难度且更加充分挖掘了骨架的结构信息,使得重定向结果误差更低且动作更自然合理。关键词:深度学习;运动重定向;图卷积;自编码器;Human3.6M运动数据193|541|0更新时间:2024-12-16
摘要:目的骨骼运动重定向是指将源角色的骨骼运动数据,修改后运用到另一个具有不同骨架结构的目标角色上,使得目标角色和源角色做出相同的动作。由于骨骼运动数据与骨架结构之间具有高耦合性,重定向算法需要从运动数据中分离出与骨架结构无关、只表示动作类型的特征。当源角色与目标角色骨架结构不同,且两者运动模式(如关节角变化范围)存在较大差异时,特征分离难度加大,重定向网络训练难度变大。针对该问题,提出了特征分离的方法和高阶骨骼卷积算子。方法在数据处理阶段,首先从运动数据中分离出一部分与骨架结构无关的特征,从而降低重定向网络训练难度,得到更好的重定向结果。另外,结合图卷积网络,本文针对人体骨架结构提出了高阶骨骼卷积算子。使用该算子,本文网络模型可以捕获更多有关骨架结构的信息,提高重定向结果的精度和视觉效果。结果在异构重定向任务中,本文方法在合成动画数据集Mixamo上与最新方法对比,重定向结果精度提升了38.6%。另外,本文方法也同样适用于同构重定向,结果精度比最新方法提升了74.8%。在从真人采集的运动数据到虚拟动画角色的异构重定向任务中,相比最新方法,本文方法能够明显减少重定向错误,重定向结果有更高的视觉质量。结论相比较于目前最新的方法,本文方法降低了特征分离的难度且更加充分挖掘了骨架的结构信息,使得重定向结果误差更低且动作更自然合理。关键词:深度学习;运动重定向;图卷积;自编码器;Human3.6M运动数据193|541|0更新时间:2024-12-16 -
 摘要:目的在联邦学习场景中,由于各客户端数据分布的不一致,会导致各客户端的局部目标之间偏差较大,以及全局平均模型偏离全局最优,影响模型训练的收敛速度和模型精度。针对非独立同分布数据导致的全局模型收敛缓慢以及模型准确率较低的问题,提出一种联合动态校正的联邦学习算法(federated learning algorithm for joint dynamic correction, FedJDC),分别从客户端和服务器端进行优化。方法为了降低局部模型更新偏移的影响,定义累积偏移度来衡量各参与客户端的数据非独立同分布程度,并在本地损失函数中引入动态约束项,根据累积偏移度动态调整约束项大小,可自动适应不同程度的非独立同分布数据,减小局部模型的更新方向不一致性,从而提高模型准确率及通信效率;其次,针对全局模型聚合偏移,将参与客户端上传的累积偏移度作为全局模型聚合权重,从而动态更新全局模型,大幅减少通信轮数。结果本文在3个真实数据集上的实验结果表明,与4种不同的联邦学习算法相比,在多种不同非独立同分布程度的情况下,FedJDC可以平均减少62.29%、20.90%、24.93%和20.47%的通信轮次,平均提高5.48%、1.62%、2.10%和2.28%的模型准确率。结论本文提出的联邦学习中局部和全局偏移的联合动态校正算法从局部模型更新和全局模型聚合两方面进行改进,降低了通信轮次,提高了准确率,取得了良好的收敛效果。关键词:联邦学习(FL);非独立同分布(non-IID);损失函数;模型聚合;收敛性235|445|0更新时间:2024-12-16
摘要:目的在联邦学习场景中,由于各客户端数据分布的不一致,会导致各客户端的局部目标之间偏差较大,以及全局平均模型偏离全局最优,影响模型训练的收敛速度和模型精度。针对非独立同分布数据导致的全局模型收敛缓慢以及模型准确率较低的问题,提出一种联合动态校正的联邦学习算法(federated learning algorithm for joint dynamic correction, FedJDC),分别从客户端和服务器端进行优化。方法为了降低局部模型更新偏移的影响,定义累积偏移度来衡量各参与客户端的数据非独立同分布程度,并在本地损失函数中引入动态约束项,根据累积偏移度动态调整约束项大小,可自动适应不同程度的非独立同分布数据,减小局部模型的更新方向不一致性,从而提高模型准确率及通信效率;其次,针对全局模型聚合偏移,将参与客户端上传的累积偏移度作为全局模型聚合权重,从而动态更新全局模型,大幅减少通信轮数。结果本文在3个真实数据集上的实验结果表明,与4种不同的联邦学习算法相比,在多种不同非独立同分布程度的情况下,FedJDC可以平均减少62.29%、20.90%、24.93%和20.47%的通信轮次,平均提高5.48%、1.62%、2.10%和2.28%的模型准确率。结论本文提出的联邦学习中局部和全局偏移的联合动态校正算法从局部模型更新和全局模型聚合两方面进行改进,降低了通信轮次,提高了准确率,取得了良好的收敛效果。关键词:联邦学习(FL);非独立同分布(non-IID);损失函数;模型聚合;收敛性235|445|0更新时间:2024-12-16 -
 摘要:目的针对目前基于深度学习的低重叠度点云配准方法在学习全局点云场景后进行特征匹配时,忽略局部特征间作用的问题,提出了一种结合边缘特征增强的层次注意力点云配准方法。方法首先,利用边缘自适应核点卷积(edge adaptive kernel point convolution, EAKPConv)模块提取源点云、目标点云特征,增强边缘特征识别能力。然后,利用局部空间差异注意模块(local spatial contrast attention module, LSCAM)聚合局部空间差异捕捉点云的几何细节,利用序列相似度关联模块(sequential similarity association module, SSAM)计算量化两点云间的相似分数,并利用相似分数引导局部匹配。最后,通过LSCAM模块与SSAM模块结合的层次化注意力融合模块(hierarchical attention fusion module, HAFM)整合局部、全局特征,实现全局匹配。结果在室内场景点云配准数据集3DMatch和三维模型数据集ModelNet-40上进行了对比实验,本算法在3DMatch和3DLoMatch上的配准召回率分别达到93.2%和67.3%;在ModelNet-40和ModelLoNet-40上取得了最低的旋转误差(分别为1.417和3.141)以及平移误差(分别为0.013 91和0.072)。此外,本文算法在推理效率上比REGTR算法减少了10 ms左右。结论本文算法通过自底向上的层次化处理方式显著提升了有限重叠场景点云的配准精度,同时降低了推理时间。关键词:三维点云配准;低重叠度点云;边缘特征;层次注意力;局部相似匹配193|505|0更新时间:2024-12-16
摘要:目的针对目前基于深度学习的低重叠度点云配准方法在学习全局点云场景后进行特征匹配时,忽略局部特征间作用的问题,提出了一种结合边缘特征增强的层次注意力点云配准方法。方法首先,利用边缘自适应核点卷积(edge adaptive kernel point convolution, EAKPConv)模块提取源点云、目标点云特征,增强边缘特征识别能力。然后,利用局部空间差异注意模块(local spatial contrast attention module, LSCAM)聚合局部空间差异捕捉点云的几何细节,利用序列相似度关联模块(sequential similarity association module, SSAM)计算量化两点云间的相似分数,并利用相似分数引导局部匹配。最后,通过LSCAM模块与SSAM模块结合的层次化注意力融合模块(hierarchical attention fusion module, HAFM)整合局部、全局特征,实现全局匹配。结果在室内场景点云配准数据集3DMatch和三维模型数据集ModelNet-40上进行了对比实验,本算法在3DMatch和3DLoMatch上的配准召回率分别达到93.2%和67.3%;在ModelNet-40和ModelLoNet-40上取得了最低的旋转误差(分别为1.417和3.141)以及平移误差(分别为0.013 91和0.072)。此外,本文算法在推理效率上比REGTR算法减少了10 ms左右。结论本文算法通过自底向上的层次化处理方式显著提升了有限重叠场景点云的配准精度,同时降低了推理时间。关键词:三维点云配准;低重叠度点云;边缘特征;层次注意力;局部相似匹配193|505|0更新时间:2024-12-16 -
 摘要:目的在无教师模型指导的条件下,自知识蒸馏方法可以让模型从自身学习知识来提升性能,但该类方法在解决细粒度图像分类任务时,因缺乏对图像判别性区域特征的有效提取导致蒸馏效果不理想。为了解决该问题,提出了一种融合高效通道注意力的细粒度图像分类自知识蒸馏学习方法。方法首先,引入高效通道注意力(efficient channel attention, ECA)模块,设计了ECA残差模块并构建ECA-ResNet18(residual network)轻量级骨干网,用以更好地提取图像判别性区域的多尺度特征;其次,构建了高效通道注意力加权双向特征金字塔ECA-BiFPN(bidirectional feature pyramid network)模块,用以融合不同尺度的特征,构建更加鲁棒的跨尺度特征;最后,提出了一种多级特征知识蒸馏损失,用以跨尺度特征对多尺度特征的蒸馏学习。结果在Caltech-UCSD Birds 200、Stanford Cars和FGVC-Aircraft 3个公开数据集上,所提方法分别取得了76.04%、91.11%和87.64%的分类精度,与已有15种自知识蒸馏方法中最佳方法的分类精度相比,分别提高了2.63%、1.56%和3.66%。结论所提方法具有高效提取图像判别性区域特征的能力,能获得更好的细粒度图像分类精度,其轻量化的网络模型适合于面向嵌入式设备的边缘计算应用。关键词:细粒度图像分类;通道注意力;知识蒸馏(KD);自知识蒸馏(SKD);特征融合;卷积神经网络(CNN);轻量级模型339|725|0更新时间:2024-12-16
摘要:目的在无教师模型指导的条件下,自知识蒸馏方法可以让模型从自身学习知识来提升性能,但该类方法在解决细粒度图像分类任务时,因缺乏对图像判别性区域特征的有效提取导致蒸馏效果不理想。为了解决该问题,提出了一种融合高效通道注意力的细粒度图像分类自知识蒸馏学习方法。方法首先,引入高效通道注意力(efficient channel attention, ECA)模块,设计了ECA残差模块并构建ECA-ResNet18(residual network)轻量级骨干网,用以更好地提取图像判别性区域的多尺度特征;其次,构建了高效通道注意力加权双向特征金字塔ECA-BiFPN(bidirectional feature pyramid network)模块,用以融合不同尺度的特征,构建更加鲁棒的跨尺度特征;最后,提出了一种多级特征知识蒸馏损失,用以跨尺度特征对多尺度特征的蒸馏学习。结果在Caltech-UCSD Birds 200、Stanford Cars和FGVC-Aircraft 3个公开数据集上,所提方法分别取得了76.04%、91.11%和87.64%的分类精度,与已有15种自知识蒸馏方法中最佳方法的分类精度相比,分别提高了2.63%、1.56%和3.66%。结论所提方法具有高效提取图像判别性区域特征的能力,能获得更好的细粒度图像分类精度,其轻量化的网络模型适合于面向嵌入式设备的边缘计算应用。关键词:细粒度图像分类;通道注意力;知识蒸馏(KD);自知识蒸馏(SKD);特征融合;卷积神经网络(CNN);轻量级模型339|725|0更新时间:2024-12-16 -
 摘要:目的知识蒸馏旨在不影响原始模型性能的前提下,将一个性能强大且参数量也较大的教师模型的知识迁移到一个轻量级的学生模型上。在图像分类领域,以往的蒸馏方法大多聚焦于全局信息的提取而忽略了局部信息的重要性。并且这些方法多是围绕单教师架构蒸馏,忽视了学生可以同时向多名教师学习的潜力。因此,提出了一种融合全局和局部特征的双教师协作知识蒸馏框架。方法首先随机初始化一个教师(临时教师)与学生处理全局信息进行同步训练,利用其临时的全局输出逐步帮助学生以最优路径接近教师的最终预测。同时又引入了一个预训练的教师(专家教师)处理局部信息。专家教师将局部特征输出分离为源类别知识和其他类别知识并分别转移给学生以提供较为全面的监督信息。结果在CIFAR-100(Canadian Institute for Advanced Research)和Tiny-ImageNet数据集上进行实验并与其他蒸馏方法进行了比较。在CIFAR-100数据集中,与最近的NKD(normalized knowledge distillation)相比,在师生相同架构与不同架构下,平均分类准确率分别提高了0.63%和1.00%。在Tiny-ImageNet数据集中,ResNet34(residual network)和MobileNetV1的师生组合下,分类准确率相较于SRRL(knowledge distillation via softmax regression representation learning)提高了1.09%,相较于NKD提高了1.06%。同时也在CIFAR-100数据集中进行了消融实验和可视化分析以验证所提方法的有效性。结论本文所提出的双教师协作知识蒸馏框架,融合了全局和局部特征,并将模型的输出响应分离为源类别知识和其他类别知识并分别转移给学生,使得学生模型的图像分类结果具有更高的准确率。关键词:知识蒸馏(KD);图像分类;轻量级模型;协作蒸馏;特征融合680|1011|0更新时间:2024-12-16
摘要:目的知识蒸馏旨在不影响原始模型性能的前提下,将一个性能强大且参数量也较大的教师模型的知识迁移到一个轻量级的学生模型上。在图像分类领域,以往的蒸馏方法大多聚焦于全局信息的提取而忽略了局部信息的重要性。并且这些方法多是围绕单教师架构蒸馏,忽视了学生可以同时向多名教师学习的潜力。因此,提出了一种融合全局和局部特征的双教师协作知识蒸馏框架。方法首先随机初始化一个教师(临时教师)与学生处理全局信息进行同步训练,利用其临时的全局输出逐步帮助学生以最优路径接近教师的最终预测。同时又引入了一个预训练的教师(专家教师)处理局部信息。专家教师将局部特征输出分离为源类别知识和其他类别知识并分别转移给学生以提供较为全面的监督信息。结果在CIFAR-100(Canadian Institute for Advanced Research)和Tiny-ImageNet数据集上进行实验并与其他蒸馏方法进行了比较。在CIFAR-100数据集中,与最近的NKD(normalized knowledge distillation)相比,在师生相同架构与不同架构下,平均分类准确率分别提高了0.63%和1.00%。在Tiny-ImageNet数据集中,ResNet34(residual network)和MobileNetV1的师生组合下,分类准确率相较于SRRL(knowledge distillation via softmax regression representation learning)提高了1.09%,相较于NKD提高了1.06%。同时也在CIFAR-100数据集中进行了消融实验和可视化分析以验证所提方法的有效性。结论本文所提出的双教师协作知识蒸馏框架,融合了全局和局部特征,并将模型的输出响应分离为源类别知识和其他类别知识并分别转移给学生,使得学生模型的图像分类结果具有更高的准确率。关键词:知识蒸馏(KD);图像分类;轻量级模型;协作蒸馏;特征融合680|1011|0更新时间:2024-12-16
图像理解和计算机视觉
-
 摘要:目的从口内扫描点云模型上精确分割牙齿是计算机辅助牙科治疗中重要的任务,但存在手动执行耗时且烦琐的问题。近年来,计算机视觉领域涌现出一些端到端的方法实现三维形状分割。然而,大多数方法没有注意到口腔分割需要网络具有更加细粒度的感受野,因此分割精度仍然受到限制。为了解决该问题,设计了一个端到端的具有细粒度感受野的全自动牙齿分割网络——TRNet,用于在未加工的口内扫描点云模型上自动分割牙齿。方法首先, TRNet使用了具有细粒度感受野的编码器,其基于多尺度融合从不同的尺度提取到更全面的口腔模型特征,并通过更适合口腔模型分割的细粒度分组查询半径以及具有相对坐标归一化的特征提取层来提升分割性能。其次,TRNet采用了基于层级连接的特征嵌入方式,网络学习到口腔模型中由各个局部区域到覆盖更大范围空间的关键特征,特征提取更全面,提升了网络的分割精度。同时,TRNet使用了基于软性注意力机制的特征融合方式,使网络更好地从融合特征中关注到口腔模型的关键信息。结果使用由口内扫描仪获取的患者口内扫描点云模型数据集评估了TRNet。经过5折交叉验证的实验结果中,TRNet的总体准确率(overall accuracy,OA)达到了97.015
摘要:目的从口内扫描点云模型上精确分割牙齿是计算机辅助牙科治疗中重要的任务,但存在手动执行耗时且烦琐的问题。近年来,计算机视觉领域涌现出一些端到端的方法实现三维形状分割。然而,大多数方法没有注意到口腔分割需要网络具有更加细粒度的感受野,因此分割精度仍然受到限制。为了解决该问题,设计了一个端到端的具有细粒度感受野的全自动牙齿分割网络——TRNet,用于在未加工的口内扫描点云模型上自动分割牙齿。方法首先, TRNet使用了具有细粒度感受野的编码器,其基于多尺度融合从不同的尺度提取到更全面的口腔模型特征,并通过更适合口腔模型分割的细粒度分组查询半径以及具有相对坐标归一化的特征提取层来提升分割性能。其次,TRNet采用了基于层级连接的特征嵌入方式,网络学习到口腔模型中由各个局部区域到覆盖更大范围空间的关键特征,特征提取更全面,提升了网络的分割精度。同时,TRNet使用了基于软性注意力机制的特征融合方式,使网络更好地从融合特征中关注到口腔模型的关键信息。结果使用由口内扫描仪获取的患者口内扫描点云模型数据集评估了TRNet。经过5折交叉验证的实验结果中,TRNet的总体准确率(overall accuracy,OA)达到了97.015 -
 摘要:目的糖尿病视网膜病变(糖网病)(diabetic retinopathy, DR)是人类致盲的首要杀手,自动准确的糖网病病灶分割对于糖网病分级和诊疗至关重要。然而,不同类型的糖网病病灶结构复杂,大小尺度不一致且存在类间相似性和类内差异性,导致同时准确分割多种病灶充满挑战。针对上述问题,提出一种基于多重注意力和级联上下文融合的糖网病多类型病灶分割方法。方法首先,三重注意力模块提取病灶的通道注意力、空间注意力和像素点注意力特征并进行加法融合以保证病灶特征的一致性。另外,级联上下文特征融合模块采用自适应平均池化和非局部操作提取不同层网络的全局上下文信息以扩大病灶的感受野。最后,平衡注意力模块计算病灶前景、背景和边界注意力图,并利用挤压激励模块在特征通道之间加权以重新平衡3个区域的注意力,令网络更多关注病灶的边缘细节,实现精细化分割。结果在国际公开的糖网病图像数据集DDR(dataset for diabetic retinopathy)、IDRiD(Indian diabetic retinopathy image dataset)和E-Ophtha进行充分的对比实验和消融实验,4种病灶分割的平均AUC(area under curve)分别达到0.679 0、0.750 3和0.660 1。结论基于多重注意力和级联上下文融合的糖网病分割方法(multi-attention and cascaded context fusion network,MCFNet)能够克服其他眼底组织和病灶噪声的不良干扰,同时实现糖网病4种病灶的精准分割,具有较好的准确性和鲁棒性,为临床医生进行糖网病诊疗提供有力支持。关键词:糖尿病视网膜病变(DR);多病灶分割;三重注意力;级联上下文融合;平衡注意力246|317|0更新时间:2024-12-16
摘要:目的糖尿病视网膜病变(糖网病)(diabetic retinopathy, DR)是人类致盲的首要杀手,自动准确的糖网病病灶分割对于糖网病分级和诊疗至关重要。然而,不同类型的糖网病病灶结构复杂,大小尺度不一致且存在类间相似性和类内差异性,导致同时准确分割多种病灶充满挑战。针对上述问题,提出一种基于多重注意力和级联上下文融合的糖网病多类型病灶分割方法。方法首先,三重注意力模块提取病灶的通道注意力、空间注意力和像素点注意力特征并进行加法融合以保证病灶特征的一致性。另外,级联上下文特征融合模块采用自适应平均池化和非局部操作提取不同层网络的全局上下文信息以扩大病灶的感受野。最后,平衡注意力模块计算病灶前景、背景和边界注意力图,并利用挤压激励模块在特征通道之间加权以重新平衡3个区域的注意力,令网络更多关注病灶的边缘细节,实现精细化分割。结果在国际公开的糖网病图像数据集DDR(dataset for diabetic retinopathy)、IDRiD(Indian diabetic retinopathy image dataset)和E-Ophtha进行充分的对比实验和消融实验,4种病灶分割的平均AUC(area under curve)分别达到0.679 0、0.750 3和0.660 1。结论基于多重注意力和级联上下文融合的糖网病分割方法(multi-attention and cascaded context fusion network,MCFNet)能够克服其他眼底组织和病灶噪声的不良干扰,同时实现糖网病4种病灶的精准分割,具有较好的准确性和鲁棒性,为临床医生进行糖网病诊疗提供有力支持。关键词:糖尿病视网膜病变(DR);多病灶分割;三重注意力;级联上下文融合;平衡注意力246|317|0更新时间:2024-12-16 -
 摘要:目的病理切片的显微高光谱图像包含生物组织反射的光谱信息,为胆管癌组织细胞的分类诊断提供基础。目前病理高光谱图像分类算法的性能大多依赖于高质量标注数据集,然而数据标注过程耗时、费力。基于自监督的特征提取算法可以缓解数据标注难题。因此,本文提出了自监督提取光谱序列和语义信息的胆管癌显微高光谱图像分类方法,提升自监督方法的特征提取能力及分类精度。方法首先,从自然语言处理中借鉴了具有序列信息建模能力的Transformer架构,将高光谱图像每个像素反射的光谱曲线看做一个光谱序列,设计Transformer自编码器,通过位置嵌入和注意力模块有效关注光谱序列间的差异,从而更好地学习到光谱序列信息。其次,图像经Transformer编码器结构图像增强得到正样本后,设计卷积自编码器作为另一组图像增强,获取对比学习需要的负样本。随后通过新颖的原型对比学习网络捕获图像中的高级语义信息,网络提取特征的过程使用未标记数据。最后,通过少量标记数据微调下游分类任务网络得到分类结果。结果在多维胆管癌病理高光谱数据集的8个场景上进行实验,结果表明,与现有7种有监督的特征提取方法和5种无监督的特征提取算法相比,本文方法提取的特征在下游分类任务中能达到更高的分类精度,平均总体分类精度达到96.63%。结论本文方法能从未标记的胆管癌显微高光谱图像中提取有效特征,特征应用于分类任务中达到较高的分类精度,缓解了病理高光谱图像数据标注难题,对胆管癌的医学诊断具有一定的研究价值和现实意义。关键词:癌症分类;高光谱图像;深度学习;自监督学习;图像增强154|504|0更新时间:2024-12-16
摘要:目的病理切片的显微高光谱图像包含生物组织反射的光谱信息,为胆管癌组织细胞的分类诊断提供基础。目前病理高光谱图像分类算法的性能大多依赖于高质量标注数据集,然而数据标注过程耗时、费力。基于自监督的特征提取算法可以缓解数据标注难题。因此,本文提出了自监督提取光谱序列和语义信息的胆管癌显微高光谱图像分类方法,提升自监督方法的特征提取能力及分类精度。方法首先,从自然语言处理中借鉴了具有序列信息建模能力的Transformer架构,将高光谱图像每个像素反射的光谱曲线看做一个光谱序列,设计Transformer自编码器,通过位置嵌入和注意力模块有效关注光谱序列间的差异,从而更好地学习到光谱序列信息。其次,图像经Transformer编码器结构图像增强得到正样本后,设计卷积自编码器作为另一组图像增强,获取对比学习需要的负样本。随后通过新颖的原型对比学习网络捕获图像中的高级语义信息,网络提取特征的过程使用未标记数据。最后,通过少量标记数据微调下游分类任务网络得到分类结果。结果在多维胆管癌病理高光谱数据集的8个场景上进行实验,结果表明,与现有7种有监督的特征提取方法和5种无监督的特征提取算法相比,本文方法提取的特征在下游分类任务中能达到更高的分类精度,平均总体分类精度达到96.63%。结论本文方法能从未标记的胆管癌显微高光谱图像中提取有效特征,特征应用于分类任务中达到较高的分类精度,缓解了病理高光谱图像数据标注难题,对胆管癌的医学诊断具有一定的研究价值和现实意义。关键词:癌症分类;高光谱图像;深度学习;自监督学习;图像增强154|504|0更新时间:2024-12-16
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0