
最新刊期
卷 29 , 期 6 , 2024
2024年第6期
-
 摘要:The emergence of foundational large-scale models, such as contrastive language-image pre-training(CLIP), chat generative pre-trained Transformer(ChatGPT), and generative pre-trained Transformer-4(GPT-4), has facilitated the significant growth of the field of artificial general intelligence (AGI). AGI aims to imbue systems with the ability to perform various tasks, which enables them to learn autonomously and evolve. This broad applicability spans various domains and is intended to address diverse problems and accomplish numerous downstream tasks. These models, after being trained on massive datasets, possess the capability to handle a multitude of downstream tasks. In this context, Meta’s segment anything model (SAM) has substantially progressed and introduced the largest image segmentation dataset to date, that is, SA-1B. This dataset includes over 11 million images and more than one billion mask in 2023. One reason is that SA-1B was collected through SAM’s data engine approach in three stages. This approach simultaneously ensures the quality and diversity of these masks, which contributes significantly to breakthroughs in the segmentation domain. This development has profoundly impacted the advancements in the foundational models in the field of computer vision. This study provides a comprehensive understanding of the SAM framework through a detailed review and analysis of relevant research. First, this study delves into three aspects of the background and basic framework of the SAM model. The first aspect involves the tasks of SAM, including traditional image segmentation and prompt-guided interactive image segmentation. The second aspect is the model architecture of SAM, encompassing image encoders, prompt encoders, and mask decoders. The third aspect revolves around the data, including the data engine for collecting datasets and dataset SA-1B. Building upon this foundation, the study then organizes and analyzes methods for improving the SAM model from two perspectives. The first perspective is enhancing inference speed. The reason is that improved inference speed reduces the deployment costs of SAM, which makes it more convenient for application on less powerful devices. The second perspective is enhancing prediction accuracy. Notably, SAM itself lacks specific semantic information, which leads to suboptimal segmentation results in complex scenarios. Thus, considerable research focuses on enhancing the prediction accuracy of SAM. Subsequently, the study thoroughly reviews and analyzes the current applications of the SAM model in various tasks and data types. These applications are divided into three parts: the first part covers applications in image processing-related tasks, including style transfer, object detection, object counting, image editing, complex image segmentation, and medical image segmentation. However, applying SAM directly to medical image segmentation may not yield satisfactory results, which suggests the need for further adjustments in specific scenario tasks. The second part encompasses applications in video-related tasks, including video super-resolution, video object tracking, and audio–visual scene segmentation. The third part explores applications in other directions, such as point cloud segmentation, 3D reconstruction, controllable image caption generation, and data annotation. Through the organization of the applications of SAM in the three parts, the study summarizes the advantages and limitations of applying SAM to various downstream tasks. These analyses can assist researchers in better applying and improving SAM, which enhances its robustness and generalization capabilities. Finally, the study proposes several valuable future research directions for the SAM model. These directions include: 1) modularization: although SAM has already demonstrated excellent performance in certain tasks, its efficiency and flexibility still need to be improved. With the continuous expansion of SAM application domains, many applications have put forward the requirement for SAM to possess new knowledge. Therefore, the model is required to have domain adaptation and continuous learning capabilities. Drawing inspiration from large language models, new modular structures can be added to SAM to enhance its domain adaptation and continuous learning capabilities. 2) Weakly supervised semantic segmentation: in weakly supervised semantic segmentation, retraining model classification and generating pseudo-labels are typically necessary, but they involve time-consuming and intricate steps. Recent studies use SAM as a base model in this domain, which capitalizes on its strong generalization for satisfactory results without fine-tuning. However, although SAM can produce relatively clear results in many explicit scenarios, SAM has difficulty generating accurate segmentation masks in certain semantically ambiguous scenarios because its model does not contain semantic information. We can consider using more diverse weak labels for SAM and incorporating additional post-processing modules to enhance the segmentation accuracy of SAM and improve its performance in weakly supervised semantic segmentation for solving the abovementioned complexity. Exploring the application of SAM as a foundational model in weakly supervised semantic segmentation, which potentially yields promising results. 3) Multimodal fusion for image segmentation: at present, the prompt input of SAM mainly includes four forms: point, target box, split mask, and text prompt. However, the continuous expansion of the application areas of SAM has introduced new requirements for cue input forms. The current focus of SAM is on 2D visual tasks, with potential consideration for future applications in 3D visual tasks. These applications include considering different input modalities for SAM prompts, introducing time-series prompts to address the limitations of SAM in video processing tasks, and further improving the performance of SAM in various video downstream tasks. 4) Efficient fine-tuning of SAM: although SAM has been widely used in various domains, its performance still falls short compared with other state-of-the-art models in the domain in certain specific application scenarios. Studies have shown that its performance is improved by fine-tuning SAM for domain-specific datasets. However, the fine-tuning process is costly due to the large size of the SAM model. Therefore, performing fine-tuning efficiently becomes an important issue. Given the substantial parameter count of SAM, incorporating new modules into the model, freezing its core during training, and only training the newly added modules significantly reduce the training cost. This approach facilitates further research on the application of SAM in various downstream tasks. 5) Leveraging gestalt psychology’s holistic cognitive perspective to enhance SAM’s adversarial robustness: the vulnerability of SAM to attacks may be due to overfitting on local cognitions. Introducing holistic cognition can prevent overfitting on local cognition and resist attacks involving noise. By consolidating and summarizing SAM in this study, SAM can be further developed and applied to drive the advancement of foundational models in the field of computer vision.关键词:artificial general intelligence (AGI);computer vision;image segmentation;visual foundational models;segment anything model (SAM);large language model (LLM)
摘要:The emergence of foundational large-scale models, such as contrastive language-image pre-training(CLIP), chat generative pre-trained Transformer(ChatGPT), and generative pre-trained Transformer-4(GPT-4), has facilitated the significant growth of the field of artificial general intelligence (AGI). AGI aims to imbue systems with the ability to perform various tasks, which enables them to learn autonomously and evolve. This broad applicability spans various domains and is intended to address diverse problems and accomplish numerous downstream tasks. These models, after being trained on massive datasets, possess the capability to handle a multitude of downstream tasks. In this context, Meta’s segment anything model (SAM) has substantially progressed and introduced the largest image segmentation dataset to date, that is, SA-1B. This dataset includes over 11 million images and more than one billion mask in 2023. One reason is that SA-1B was collected through SAM’s data engine approach in three stages. This approach simultaneously ensures the quality and diversity of these masks, which contributes significantly to breakthroughs in the segmentation domain. This development has profoundly impacted the advancements in the foundational models in the field of computer vision. This study provides a comprehensive understanding of the SAM framework through a detailed review and analysis of relevant research. First, this study delves into three aspects of the background and basic framework of the SAM model. The first aspect involves the tasks of SAM, including traditional image segmentation and prompt-guided interactive image segmentation. The second aspect is the model architecture of SAM, encompassing image encoders, prompt encoders, and mask decoders. The third aspect revolves around the data, including the data engine for collecting datasets and dataset SA-1B. Building upon this foundation, the study then organizes and analyzes methods for improving the SAM model from two perspectives. The first perspective is enhancing inference speed. The reason is that improved inference speed reduces the deployment costs of SAM, which makes it more convenient for application on less powerful devices. The second perspective is enhancing prediction accuracy. Notably, SAM itself lacks specific semantic information, which leads to suboptimal segmentation results in complex scenarios. Thus, considerable research focuses on enhancing the prediction accuracy of SAM. Subsequently, the study thoroughly reviews and analyzes the current applications of the SAM model in various tasks and data types. These applications are divided into three parts: the first part covers applications in image processing-related tasks, including style transfer, object detection, object counting, image editing, complex image segmentation, and medical image segmentation. However, applying SAM directly to medical image segmentation may not yield satisfactory results, which suggests the need for further adjustments in specific scenario tasks. The second part encompasses applications in video-related tasks, including video super-resolution, video object tracking, and audio–visual scene segmentation. The third part explores applications in other directions, such as point cloud segmentation, 3D reconstruction, controllable image caption generation, and data annotation. Through the organization of the applications of SAM in the three parts, the study summarizes the advantages and limitations of applying SAM to various downstream tasks. These analyses can assist researchers in better applying and improving SAM, which enhances its robustness and generalization capabilities. Finally, the study proposes several valuable future research directions for the SAM model. These directions include: 1) modularization: although SAM has already demonstrated excellent performance in certain tasks, its efficiency and flexibility still need to be improved. With the continuous expansion of SAM application domains, many applications have put forward the requirement for SAM to possess new knowledge. Therefore, the model is required to have domain adaptation and continuous learning capabilities. Drawing inspiration from large language models, new modular structures can be added to SAM to enhance its domain adaptation and continuous learning capabilities. 2) Weakly supervised semantic segmentation: in weakly supervised semantic segmentation, retraining model classification and generating pseudo-labels are typically necessary, but they involve time-consuming and intricate steps. Recent studies use SAM as a base model in this domain, which capitalizes on its strong generalization for satisfactory results without fine-tuning. However, although SAM can produce relatively clear results in many explicit scenarios, SAM has difficulty generating accurate segmentation masks in certain semantically ambiguous scenarios because its model does not contain semantic information. We can consider using more diverse weak labels for SAM and incorporating additional post-processing modules to enhance the segmentation accuracy of SAM and improve its performance in weakly supervised semantic segmentation for solving the abovementioned complexity. Exploring the application of SAM as a foundational model in weakly supervised semantic segmentation, which potentially yields promising results. 3) Multimodal fusion for image segmentation: at present, the prompt input of SAM mainly includes four forms: point, target box, split mask, and text prompt. However, the continuous expansion of the application areas of SAM has introduced new requirements for cue input forms. The current focus of SAM is on 2D visual tasks, with potential consideration for future applications in 3D visual tasks. These applications include considering different input modalities for SAM prompts, introducing time-series prompts to address the limitations of SAM in video processing tasks, and further improving the performance of SAM in various video downstream tasks. 4) Efficient fine-tuning of SAM: although SAM has been widely used in various domains, its performance still falls short compared with other state-of-the-art models in the domain in certain specific application scenarios. Studies have shown that its performance is improved by fine-tuning SAM for domain-specific datasets. However, the fine-tuning process is costly due to the large size of the SAM model. Therefore, performing fine-tuning efficiently becomes an important issue. Given the substantial parameter count of SAM, incorporating new modules into the model, freezing its core during training, and only training the newly added modules significantly reduce the training cost. This approach facilitates further research on the application of SAM in various downstream tasks. 5) Leveraging gestalt psychology’s holistic cognitive perspective to enhance SAM’s adversarial robustness: the vulnerability of SAM to attacks may be due to overfitting on local cognitions. Introducing holistic cognition can prevent overfitting on local cognition and resist attacks involving noise. By consolidating and summarizing SAM in this study, SAM can be further developed and applied to drive the advancement of foundational models in the field of computer vision.关键词:artificial general intelligence (AGI);computer vision;image segmentation;visual foundational models;segment anything model (SAM);large language model (LLM)- 28
- |
- 6
- |
- 0
发布时间:2024-06-27 -
 摘要:Generative foundation models are facilitating significant transformations in the field of artificial intelligence. They demonstrate general artificial intelligence in diverse research fields, including natural language processing, multimodal content understanding, imagery, and multimodal content synthesis. Generative foundation models often consist of billions or even hundreds of billions of parameters. Thus, they are often deployed on the cloud side to provide powerful and general intelligent services. However, this type of service can be confronted with crucial challenges in practice, such as high latency induced by communications between the cloud and local devices, and insufficient personalization capabilities due to the fact that servers often do not have access to local data considering privacy concerns. By contrast, low-complexity lightweight models are located at the edge side to capture personalized and dynamic scenario data. However, they may suffer from poor generalization. Large and lightweight (or large-small) model collaboration aims to integrate the general intelligence of large foundation models and the personalized intelligence of small lightweight models. This integration empowers downstream vertical domain-specific applications through the interaction and collaboration of both types of intelligent models. Large and small model collaboration has recently attracted increasing attention and becomes the focus of research and development in academia and industry. It has also been predicted to be an important trend in technology. We therefore try to thoroughly investigate this area by highlighting recent progress and bringing potential inspirations for related research. In this study, we first overview representative large language models (LLMs) and large multimodal models. We focus on their mainstream Transformer-based model architectures including encoder-only, decoder-only, and encoder-decoder models. Corresponding pre-training technologies such as next sentence prediction, sequence-to-sequence modeling, contrastive learning, and parameter-efficient fine-tuning methods with representatives including low-rank adaptation and prompt tuning are also explored. We then review the development history and the latest advancement of model compression techniques, including model pruning, model quantization, and knowledge distillation in the era of foundation models. Based on the differences in terms of model collaboration purposes and mechanisms, we propose a new classification method and taxonomies for the large-small model collaboration study, namely, collaborative training, collaborative inference, and collaborative planning. Specifically, we summarize recent and representative methods that consist of dual-directional knowledge distillation between large models at the cloud side and small models deployed at the edge side, modular design of intelligent models that split functional models between the cloud and edge, and generative agents that collaborate to complete more complex tasks in an autonomous and intelligent manner. In collaborative training, a main challenge is dealing with the heterogeneity in data distribution and model architectures between the cloud and client sides. Data privacy may also be a concern during collaborative training, particularly in privacy sensitive cases. Despite much progress in collaborative inference, slicing and completing a complicated task in a collective way automatically remain challenging. Furthermore, the communication costs between computing facilities might be another concern. Collective planning is a new paradigm that gains attention with the increasing study and promising progress of LLM-centric agents (LLM agents). This paradigm often involves multiple LLM agents who compete or cooperate together to complete a challenging task. It often leverages emerging capabilities such as in-context learning and chain-of-thoughts of LLMs to automatically dive a complicated task into several subtasks. By completing and assembling different subtasks, the global task can be conducted in a collaborative manner. This scheme finds diverse applications such as developing games and simulating social societies. However, it may suffer from drawbacks inherent in LLMs, including hallucination and adversarial vulnerabilities. Thus, more robust and reliable collaborative planning schemes remain to be investigated. In summary, this work surveys the large-small model collaboration techniques from the perspectives of generative foundation models, model compression, and heterogeneous model collaboration via LLM agents. This work also compares the advantages and disadvantages between international and domestic technology developments in this research realm. We conclude that, although the gaps are narrowing between domestic and advanced international studies in this area, particularly for newly emerging LLM agents, we may still lack original and major breakthroughs. Certain notable advantages of domestic progress are closely related to industrial applications due to its rich data resources from industries. Therefore, the development of domain specific LLMs is advanced. In addition, this study envisions the applications of large-small model collaboration and discusses certain key challenges and promising directions in this topic. 1) The design of efficient model architectures includes developing new model architectures that can achieve low-complexity inference speed while maintaining efficient long-sequence modeling abilities as Transformers and further improving the scalability of mixture-of-expert-based architectures. 2) Current model compression methods are mainly designed for vision models. Thus, developing techniques specifically for LLMs and large multimodal models is important to preserve their emergent abilities during compression. 3) Existing personalization methods specially focus on discriminative models, and due attention needs to be paid for efficient personalization for generative foundation models. 4) Generative intelligence often suffers from fraudulent contents (e.g., generated fake imagery, deepfake videos, and fake news) and different types of attacks (e.g., adversarial attacks, the jailing breaking attacks, and the Byzantine attacks). Thus, security and trustworthy issues arise in their practical applications. Therefore, this study also advocates a deeper investigation of these emerging security threats. Then, it develops effective defenses accordingly to countermeasure these crucial issues during large-small model collaboration for empowering vertical domains more safely.关键词:generative foundation models;model compression;large-small model collaboration;edge-cloud collaboration;generative agents;generative AI
摘要:Generative foundation models are facilitating significant transformations in the field of artificial intelligence. They demonstrate general artificial intelligence in diverse research fields, including natural language processing, multimodal content understanding, imagery, and multimodal content synthesis. Generative foundation models often consist of billions or even hundreds of billions of parameters. Thus, they are often deployed on the cloud side to provide powerful and general intelligent services. However, this type of service can be confronted with crucial challenges in practice, such as high latency induced by communications between the cloud and local devices, and insufficient personalization capabilities due to the fact that servers often do not have access to local data considering privacy concerns. By contrast, low-complexity lightweight models are located at the edge side to capture personalized and dynamic scenario data. However, they may suffer from poor generalization. Large and lightweight (or large-small) model collaboration aims to integrate the general intelligence of large foundation models and the personalized intelligence of small lightweight models. This integration empowers downstream vertical domain-specific applications through the interaction and collaboration of both types of intelligent models. Large and small model collaboration has recently attracted increasing attention and becomes the focus of research and development in academia and industry. It has also been predicted to be an important trend in technology. We therefore try to thoroughly investigate this area by highlighting recent progress and bringing potential inspirations for related research. In this study, we first overview representative large language models (LLMs) and large multimodal models. We focus on their mainstream Transformer-based model architectures including encoder-only, decoder-only, and encoder-decoder models. Corresponding pre-training technologies such as next sentence prediction, sequence-to-sequence modeling, contrastive learning, and parameter-efficient fine-tuning methods with representatives including low-rank adaptation and prompt tuning are also explored. We then review the development history and the latest advancement of model compression techniques, including model pruning, model quantization, and knowledge distillation in the era of foundation models. Based on the differences in terms of model collaboration purposes and mechanisms, we propose a new classification method and taxonomies for the large-small model collaboration study, namely, collaborative training, collaborative inference, and collaborative planning. Specifically, we summarize recent and representative methods that consist of dual-directional knowledge distillation between large models at the cloud side and small models deployed at the edge side, modular design of intelligent models that split functional models between the cloud and edge, and generative agents that collaborate to complete more complex tasks in an autonomous and intelligent manner. In collaborative training, a main challenge is dealing with the heterogeneity in data distribution and model architectures between the cloud and client sides. Data privacy may also be a concern during collaborative training, particularly in privacy sensitive cases. Despite much progress in collaborative inference, slicing and completing a complicated task in a collective way automatically remain challenging. Furthermore, the communication costs between computing facilities might be another concern. Collective planning is a new paradigm that gains attention with the increasing study and promising progress of LLM-centric agents (LLM agents). This paradigm often involves multiple LLM agents who compete or cooperate together to complete a challenging task. It often leverages emerging capabilities such as in-context learning and chain-of-thoughts of LLMs to automatically dive a complicated task into several subtasks. By completing and assembling different subtasks, the global task can be conducted in a collaborative manner. This scheme finds diverse applications such as developing games and simulating social societies. However, it may suffer from drawbacks inherent in LLMs, including hallucination and adversarial vulnerabilities. Thus, more robust and reliable collaborative planning schemes remain to be investigated. In summary, this work surveys the large-small model collaboration techniques from the perspectives of generative foundation models, model compression, and heterogeneous model collaboration via LLM agents. This work also compares the advantages and disadvantages between international and domestic technology developments in this research realm. We conclude that, although the gaps are narrowing between domestic and advanced international studies in this area, particularly for newly emerging LLM agents, we may still lack original and major breakthroughs. Certain notable advantages of domestic progress are closely related to industrial applications due to its rich data resources from industries. Therefore, the development of domain specific LLMs is advanced. In addition, this study envisions the applications of large-small model collaboration and discusses certain key challenges and promising directions in this topic. 1) The design of efficient model architectures includes developing new model architectures that can achieve low-complexity inference speed while maintaining efficient long-sequence modeling abilities as Transformers and further improving the scalability of mixture-of-expert-based architectures. 2) Current model compression methods are mainly designed for vision models. Thus, developing techniques specifically for LLMs and large multimodal models is important to preserve their emergent abilities during compression. 3) Existing personalization methods specially focus on discriminative models, and due attention needs to be paid for efficient personalization for generative foundation models. 4) Generative intelligence often suffers from fraudulent contents (e.g., generated fake imagery, deepfake videos, and fake news) and different types of attacks (e.g., adversarial attacks, the jailing breaking attacks, and the Byzantine attacks). Thus, security and trustworthy issues arise in their practical applications. Therefore, this study also advocates a deeper investigation of these emerging security threats. Then, it develops effective defenses accordingly to countermeasure these crucial issues during large-small model collaboration for empowering vertical domains more safely.关键词:generative foundation models;model compression;large-small model collaboration;edge-cloud collaboration;generative agents;generative AI- 10
- |
- 6
- |
- 0
发布时间:2024-06-27 -
 摘要:In the contemporary digital era, which is characterized by rapid technological advancements, multimedia content creation, particularly in visual content generation, has become an integral part of modern societal development. The exponential growth of digital media and the creative industry has attracted attention to artificial intelligence generated content (AIGC) technology. The groundbreaking applications of AIGC in visual content generation not only have equipped multimedia creators with novel tools and capabilities but also have delivered substantial benefits across diverse domains, which span from the realms of cinema and gaming to the immersive landscapes of virtual reality. This review comprehensive introduces the profound advancements within AIGC technology. Our particular emphasis is on the domain of visual content generation and its critical facet of traceability. Initially, our discussions trace the evolutionary path of image generation technology, from its inception within generative adversarial networks (GANs) to the latest advancements in Transformer auto-regressive models and diffusion probability models. This progression unveils a remarkable leap in the quality and capability of image generation, which underscores the rapid evolution of this field. This evolution has transitioned from its nascent stages to an era characterized by explosive growth. First, we delve into the development of GANs, encompassing their evolution from text-conditioned methods to sophisticated techniques for style control and the development of large-scale models. This type of technology pioneered the text-to-image generation. GANs can further improve their performance by expanding network parameters and dataset size due to their strong scalability. Furthermore, we explore the emergence of Transformer-based auto-regressive models, such as DALL·E and CogView, which have heralded a new epoch in the domain of image generation. The basic strategy of autoregressive models is to first use the Transformer structure to predict the feature sequence of images based on other conditional feature sequences such as text and sketches. Then, it uses a specially trained decoding network to decode these feature sequences into a complete image. They can generate realistic images based on the large-scale parameters. In addition, our discourse delves into the burgeoning interest surrounding diffusion probability models, which are renowned for their stable training methods and their ability to yield high-quality outputs. The diffusion models first adopt an iterative and random process to simulate the gradual transformation of the observed data into a known noise distribution. Then, they reconstruct the original data in the opposite direction from the noise distribution. This random process based on stochastic approach provides a more stable training process, while it also demonstrates impressive results in terms of generated quality and diversity. As the development of AIGC technology continues to advance, it encounters challenges, such as the enhancement in content quality and the need of precise control to align with specific requisites. Within this context, this review conducts a thorough exploration of controllable image generation technology, which is a pivotal research domain that strives to furnish meticulous control over the generated content. This achievement is facilitated through the integration of supplementary elements, such as intricate layouts, detailed sketches, and precise visual references. This approach empowers creators to preserve their artistic autonomy while upholding exacting standards of quality. One notable facet that has garnered considerable academic attention is the utilization of visual references as a mechanism to enable the generation of diverse styles and personalized outcomes by incorporating user-provided visual elements. This review underscores the profound potential inherent in these methodologies, which illustrates their transformative role across domains such as digital art and interactive media. The development of these technologies introduces new horizons in digital creativity. However, it presents profound challenges, particularly in the domain of image authenticity and the potential for malevolent misuse. These risks are exemplified by the creation of deep fakes or the proliferation of fake news. These challenges extend far beyond mere technical intricacies; they encompass substantial risks pertaining to individual privacy, security, and the broader societal implications of eroding public trust and social stability. In response to these formidable challenges, watermark-related image traceability technology has emerged as an indispensable solution. This technology harnesses the power of watermarking techniques to authenticate and verify AI-generated images, which safeguards their integrity. Within the pages of this review, we meticulously categorize these watermarking techniques into distinct types: watermark-free embedding, watermark pre-embedding, watermark post-embedding, and joint generation methods. First, we introduce the watermark-free embedding methods, which treat the generated traces left during model generation as fingerprints. The inherent fingerprint information is used to achieve model attribution of generated images and achieve traceability purposes. Second, the watermark pre-embedding methods aim to embed the watermark into input training data such as noise and image. Another aim is to use the embedded watermark data to train the generation model, which can also introduce traceability information in the generated image. Third, the watermark post-embedding methods divide the process of generating watermark images into two stages: image generation and watermark embedding. Watermark embedding is performed after image generation. Finally, the joint generation methods aim to achieve adaptive embedding of watermark information during the image generation process, minimize damage to the image generation process when fusing with image features, and ultimately generate images carrying watermarks. Each of these approaches plays a pivotal role in the verification of traceability across diverse scenarios, which offers a robust defense against potential misuses of AI-generated imagery. In conclusion, while AIGC technology offers promising new opportunities in visual content creation, it simultaneously causes significant challenges regarding the security and integrity of generated content. This comprehensive review covers the breadth of AIGC technology, which starts from an overview of existing image generation technologies, such as GANs, auto-regressive models, and diffusion probability models. It then categorizes and analyzes controllable image generation technology from the perspectives of additional conditions and visual examples. In addition, the review focuses on watermark-related image traceability technology, discusses various watermark embedding techniques and the current state of watermark attacks on generated images, and provides an extensive overview and future outlook of generation image traceability technology. The aim is to offer researchers a detailed, systematic, and comprehensive perspective on the advancements in AIGC visual content generation and traceability. This study deepens the understanding of current research trends, challenges, and future directions in this rapidly evolving field.关键词:artificial intelligence generated content (AIGC);visual content generation;controllable image generation;security of generated content;traceability of generated images
摘要:In the contemporary digital era, which is characterized by rapid technological advancements, multimedia content creation, particularly in visual content generation, has become an integral part of modern societal development. The exponential growth of digital media and the creative industry has attracted attention to artificial intelligence generated content (AIGC) technology. The groundbreaking applications of AIGC in visual content generation not only have equipped multimedia creators with novel tools and capabilities but also have delivered substantial benefits across diverse domains, which span from the realms of cinema and gaming to the immersive landscapes of virtual reality. This review comprehensive introduces the profound advancements within AIGC technology. Our particular emphasis is on the domain of visual content generation and its critical facet of traceability. Initially, our discussions trace the evolutionary path of image generation technology, from its inception within generative adversarial networks (GANs) to the latest advancements in Transformer auto-regressive models and diffusion probability models. This progression unveils a remarkable leap in the quality and capability of image generation, which underscores the rapid evolution of this field. This evolution has transitioned from its nascent stages to an era characterized by explosive growth. First, we delve into the development of GANs, encompassing their evolution from text-conditioned methods to sophisticated techniques for style control and the development of large-scale models. This type of technology pioneered the text-to-image generation. GANs can further improve their performance by expanding network parameters and dataset size due to their strong scalability. Furthermore, we explore the emergence of Transformer-based auto-regressive models, such as DALL·E and CogView, which have heralded a new epoch in the domain of image generation. The basic strategy of autoregressive models is to first use the Transformer structure to predict the feature sequence of images based on other conditional feature sequences such as text and sketches. Then, it uses a specially trained decoding network to decode these feature sequences into a complete image. They can generate realistic images based on the large-scale parameters. In addition, our discourse delves into the burgeoning interest surrounding diffusion probability models, which are renowned for their stable training methods and their ability to yield high-quality outputs. The diffusion models first adopt an iterative and random process to simulate the gradual transformation of the observed data into a known noise distribution. Then, they reconstruct the original data in the opposite direction from the noise distribution. This random process based on stochastic approach provides a more stable training process, while it also demonstrates impressive results in terms of generated quality and diversity. As the development of AIGC technology continues to advance, it encounters challenges, such as the enhancement in content quality and the need of precise control to align with specific requisites. Within this context, this review conducts a thorough exploration of controllable image generation technology, which is a pivotal research domain that strives to furnish meticulous control over the generated content. This achievement is facilitated through the integration of supplementary elements, such as intricate layouts, detailed sketches, and precise visual references. This approach empowers creators to preserve their artistic autonomy while upholding exacting standards of quality. One notable facet that has garnered considerable academic attention is the utilization of visual references as a mechanism to enable the generation of diverse styles and personalized outcomes by incorporating user-provided visual elements. This review underscores the profound potential inherent in these methodologies, which illustrates their transformative role across domains such as digital art and interactive media. The development of these technologies introduces new horizons in digital creativity. However, it presents profound challenges, particularly in the domain of image authenticity and the potential for malevolent misuse. These risks are exemplified by the creation of deep fakes or the proliferation of fake news. These challenges extend far beyond mere technical intricacies; they encompass substantial risks pertaining to individual privacy, security, and the broader societal implications of eroding public trust and social stability. In response to these formidable challenges, watermark-related image traceability technology has emerged as an indispensable solution. This technology harnesses the power of watermarking techniques to authenticate and verify AI-generated images, which safeguards their integrity. Within the pages of this review, we meticulously categorize these watermarking techniques into distinct types: watermark-free embedding, watermark pre-embedding, watermark post-embedding, and joint generation methods. First, we introduce the watermark-free embedding methods, which treat the generated traces left during model generation as fingerprints. The inherent fingerprint information is used to achieve model attribution of generated images and achieve traceability purposes. Second, the watermark pre-embedding methods aim to embed the watermark into input training data such as noise and image. Another aim is to use the embedded watermark data to train the generation model, which can also introduce traceability information in the generated image. Third, the watermark post-embedding methods divide the process of generating watermark images into two stages: image generation and watermark embedding. Watermark embedding is performed after image generation. Finally, the joint generation methods aim to achieve adaptive embedding of watermark information during the image generation process, minimize damage to the image generation process when fusing with image features, and ultimately generate images carrying watermarks. Each of these approaches plays a pivotal role in the verification of traceability across diverse scenarios, which offers a robust defense against potential misuses of AI-generated imagery. In conclusion, while AIGC technology offers promising new opportunities in visual content creation, it simultaneously causes significant challenges regarding the security and integrity of generated content. This comprehensive review covers the breadth of AIGC technology, which starts from an overview of existing image generation technologies, such as GANs, auto-regressive models, and diffusion probability models. It then categorizes and analyzes controllable image generation technology from the perspectives of additional conditions and visual examples. In addition, the review focuses on watermark-related image traceability technology, discusses various watermark embedding techniques and the current state of watermark attacks on generated images, and provides an extensive overview and future outlook of generation image traceability technology. The aim is to offer researchers a detailed, systematic, and comprehensive perspective on the advancements in AIGC visual content generation and traceability. This study deepens the understanding of current research trends, challenges, and future directions in this rapidly evolving field.关键词:artificial intelligence generated content (AIGC);visual content generation;controllable image generation;security of generated content;traceability of generated images- 19
- |
- 6
- |
- 0
发布时间:2024-06-27 -
 摘要:The process of brain development in children and adolescents involves various complex, dynamic, and adaptive processes that drive the differentiation and maturation of neural system structures and functions. Changes in brain structures include an increase in white matter volume and integrity in various brain regions, which are accompanied by a decrease in gray matter volume. These structural changes often coincide with alterations in cognitive functions, such as improved intelligence, working memory, problem-solving abilities, and enhanced social cognition. However, the high plasticity of brain structure and function during childhood and adolescence not only facilitates the refinement of brain function but also introduces vulnerabilities to developmental disruptions. Investigating the developing brain is crucial to enhance our understanding of normal developmental processes and allow for targeted early interventions in cases of developmental imbalances. Brain atlas, as an important tool for studying brain structure, function, and diseases, is a powerful tool for researchers to analyze the brain and plays an indispensable role in brain development research. Brain atlases consist of one or multiple brain images with different types of delineated boundaries. In general, these boundaries are partitioned based on existing knowledge of brain anatomy, pathology, or functional characteristics. Their fundamental value lies in providing a priori knowledge about brain anatomy and function. The continuous maturation of brain structure and various cognitive functions during the development stages of children and adolescents leads to differences in the regionalization patterns between children and adults. During early life, some subregions that are clearly delineated in the adult brain remain undifferentiated in the brains of children. These areas await developmental cues from external stimuli to gradually form more distinct boundaries. Clearly, using atlases derived from adults is inappropriate in studies involving children. Inappropriate brain atlases may introduce certain errors in research involving children and adolescents, especially in regions of the brain, such as the frontal lobes, where significant differences exist between children and adults. Building developmental brain atlases for children and adolescents is potentially more challenging than adult brain atlases. Advanced techniques may be required for constructing images of the developing brain, which addresses issues such as higher susceptibility to motion artifacts and lower contrast in scan images. Furthermore, obtaining data from children typically involves additional ethical considerations and requires consent from parents or guardians. These factors collectively pose challenges to the construction of developmental children brain atlases. Notably, the continuous improvement in magnetic resonance imaging (MRI) technology and the growing global attention to the physical and mental health development of children and adolescents in recent years have increased the number of developmental studies. Among these studies, some attempts have made to build developmental atlases for children and adolescents. These studies provide valuable information for educational interventions in children and adolescents, which guides their transition from impulsive and risk-taking psychological states to more mature adulthood. This review focuses on developmental brain atlases and offers an overview of research progress related to brain development and brain atlases of children and adolescents from three key perspectives. First, it introduces the transitions in brain characteristics during childhood and adolescence, which emphasizes the importance of promoting brain-healthy development during these crucial developmental stages. Second, unlike in adults, pediatric brain scan images typically exhibit lower contrast and increased head motion, which necessitates additional technical measures to address the additional noise generated during scans. Summarizing the advantages and disadvantages of current developmental atlas methods, including specialized data preprocessing steps, will promote the development of more data processing tools tailored for research on children and adolescents. Finally, researchers can identify and monitor variations in brain development, which are in typical and atypical cases, by segmenting the brain into regions and creating atlases that represent these divisions. This approach not only aids in understanding the natural course of brain development but also helps in identifying and addressing potential developmental issues. Meanwhile, the structural and functional modules of the brain undergo processes of integration or differentiation during the developmental process. If the same regional divisions are applied to statistically analyze various feature indices, then inaccuracies in localization may lead to deviations between statistical results and actual results. This review describes the progress in research on pediatric and adolescent templates and brain atlases, which helps analyze the contributions and limitations of these studies in understanding pediatric and adolescent development. The segmentation of different regions within the spatial landscape of the brain forms the foundation for decoding the human brain, and the brain atlases derived from these region divisions serve as powerful tools for researchers to analyze the brain. In recent years, the advancement in MRI technology has enabled researchers to observe and explore characteristics of the human brain, such as sulci and gyri, and networks at different developmental stages more effectively. Focusing on developmental brain atlases, conducting research on the developing brain is crucial for enhancing our understanding of normal developmental processes and facilitating targeted early interventions for developmental imbalances. Brain atlases provide researchers with the ability to investigate the significant structural and functional changes in the brain during different stages of life. Research on developing brains contributes to a better understanding of the normal developmental process, which enables targeted early interventions for imbalances in development. Summarizing the advantages and disadvantages of existing technological methods encourages researchers in related fields to develop more data processing tools tailored to the study of children and adolescents. This review of finely segmented brain development atlases based on specific age groups provides a powerful reference for future developmental research. This review, which is grounded in developmental brain atlases, deepens the understanding of brain development and promotes interdisciplinary research by reviewing the general features of development at the child and adolescent stages, the main ways to explore the features, and the developmental mapping as an essential tool for brain developmental research. Thus, it informs the advancement of the field of brain development in children and adolescents and provides a better guide to the study of the education, health, and neurological disorders of adolescents.关键词:child and adolescence;development;brain atlas;brain templates;magnetic resonance imaging(MRI);developmental datasets;Preprocessing
摘要:The process of brain development in children and adolescents involves various complex, dynamic, and adaptive processes that drive the differentiation and maturation of neural system structures and functions. Changes in brain structures include an increase in white matter volume and integrity in various brain regions, which are accompanied by a decrease in gray matter volume. These structural changes often coincide with alterations in cognitive functions, such as improved intelligence, working memory, problem-solving abilities, and enhanced social cognition. However, the high plasticity of brain structure and function during childhood and adolescence not only facilitates the refinement of brain function but also introduces vulnerabilities to developmental disruptions. Investigating the developing brain is crucial to enhance our understanding of normal developmental processes and allow for targeted early interventions in cases of developmental imbalances. Brain atlas, as an important tool for studying brain structure, function, and diseases, is a powerful tool for researchers to analyze the brain and plays an indispensable role in brain development research. Brain atlases consist of one or multiple brain images with different types of delineated boundaries. In general, these boundaries are partitioned based on existing knowledge of brain anatomy, pathology, or functional characteristics. Their fundamental value lies in providing a priori knowledge about brain anatomy and function. The continuous maturation of brain structure and various cognitive functions during the development stages of children and adolescents leads to differences in the regionalization patterns between children and adults. During early life, some subregions that are clearly delineated in the adult brain remain undifferentiated in the brains of children. These areas await developmental cues from external stimuli to gradually form more distinct boundaries. Clearly, using atlases derived from adults is inappropriate in studies involving children. Inappropriate brain atlases may introduce certain errors in research involving children and adolescents, especially in regions of the brain, such as the frontal lobes, where significant differences exist between children and adults. Building developmental brain atlases for children and adolescents is potentially more challenging than adult brain atlases. Advanced techniques may be required for constructing images of the developing brain, which addresses issues such as higher susceptibility to motion artifacts and lower contrast in scan images. Furthermore, obtaining data from children typically involves additional ethical considerations and requires consent from parents or guardians. These factors collectively pose challenges to the construction of developmental children brain atlases. Notably, the continuous improvement in magnetic resonance imaging (MRI) technology and the growing global attention to the physical and mental health development of children and adolescents in recent years have increased the number of developmental studies. Among these studies, some attempts have made to build developmental atlases for children and adolescents. These studies provide valuable information for educational interventions in children and adolescents, which guides their transition from impulsive and risk-taking psychological states to more mature adulthood. This review focuses on developmental brain atlases and offers an overview of research progress related to brain development and brain atlases of children and adolescents from three key perspectives. First, it introduces the transitions in brain characteristics during childhood and adolescence, which emphasizes the importance of promoting brain-healthy development during these crucial developmental stages. Second, unlike in adults, pediatric brain scan images typically exhibit lower contrast and increased head motion, which necessitates additional technical measures to address the additional noise generated during scans. Summarizing the advantages and disadvantages of current developmental atlas methods, including specialized data preprocessing steps, will promote the development of more data processing tools tailored for research on children and adolescents. Finally, researchers can identify and monitor variations in brain development, which are in typical and atypical cases, by segmenting the brain into regions and creating atlases that represent these divisions. This approach not only aids in understanding the natural course of brain development but also helps in identifying and addressing potential developmental issues. Meanwhile, the structural and functional modules of the brain undergo processes of integration or differentiation during the developmental process. If the same regional divisions are applied to statistically analyze various feature indices, then inaccuracies in localization may lead to deviations between statistical results and actual results. This review describes the progress in research on pediatric and adolescent templates and brain atlases, which helps analyze the contributions and limitations of these studies in understanding pediatric and adolescent development. The segmentation of different regions within the spatial landscape of the brain forms the foundation for decoding the human brain, and the brain atlases derived from these region divisions serve as powerful tools for researchers to analyze the brain. In recent years, the advancement in MRI technology has enabled researchers to observe and explore characteristics of the human brain, such as sulci and gyri, and networks at different developmental stages more effectively. Focusing on developmental brain atlases, conducting research on the developing brain is crucial for enhancing our understanding of normal developmental processes and facilitating targeted early interventions for developmental imbalances. Brain atlases provide researchers with the ability to investigate the significant structural and functional changes in the brain during different stages of life. Research on developing brains contributes to a better understanding of the normal developmental process, which enables targeted early interventions for imbalances in development. Summarizing the advantages and disadvantages of existing technological methods encourages researchers in related fields to develop more data processing tools tailored to the study of children and adolescents. This review of finely segmented brain development atlases based on specific age groups provides a powerful reference for future developmental research. This review, which is grounded in developmental brain atlases, deepens the understanding of brain development and promotes interdisciplinary research by reviewing the general features of development at the child and adolescent stages, the main ways to explore the features, and the developmental mapping as an essential tool for brain developmental research. Thus, it informs the advancement of the field of brain development in children and adolescents and provides a better guide to the study of the education, health, and neurological disorders of adolescents.关键词:child and adolescence;development;brain atlas;brain templates;magnetic resonance imaging(MRI);developmental datasets;Preprocessing- 6
- |
- 0
- |
- 0
发布时间:2024-06-27 -
 摘要:Human intelligence evolves through interactions with the environment, which makes autonomous interaction between intelligent agents and the environment a key factor in advancing intelligence. Autonomous interaction with the environment is a research topic that involves multiple disciplines, such as computer graphics, computer vision, and robotics, and has attracted significant attention and exploration in recent years. In this study, we focus on human-like interaction in indoor environment and comprehensively review the research progress in the fundamental components including simulation interaction platforms, scene interaction data, and interaction generation algorithms for digital humans and robots. Regarding simulation interaction platforms, we comprehensively review representative simulation methods for virtual humans, objects, and human-object interaction. Specifically, we cover critical algorithms for articulated rigid-body simulation, deformable-body and cloth simulation, fluid simulation, contact and collision, and multi-body multi-physics coupling. In addition, we introduce several popular simulation platforms that are readily available for practitioners in the graphics, robotics, and machine learning communities. We classify these popular simulation platforms into two main categories: simulators focusing on single-physics systems and those supporting multi-physics systems. We review typical simulation platforms in both categories and discuss their advantages in human-like indoor-scene interaction. Finally, we briefly discuss several emerging trends in the physical simulation community that inspire promising future directions: developing a full-featured simulator for multi-physics multi-body physical systems, equipping modern simulation platforms with differentiability, and combining physics principles with insights from learning techniques. Regarding scene interaction data, we provide an in-depth review of the latest developments and trends in datasets that support the understanding and generation of human-scene interactions. We focus on the need for agents to perceive scenes with a focus on interaction, assimilate interactive information, and recognize human interaction patterns to improve simulation and movement generation. Our review spans three areas: perception datasets for human-scene interaction, datasets for interaction motion, and methods for scaling data efficiently. Perception datasets facilitate a deeper understanding of 3D scenes, which highlights geometry, structure, functionality, and motion. They offer resources for interaction affordances, grasping poses, interactive components, and object positioning. Motion datasets, which are essential for crafting interactions, delve into interaction movement analysis, including motion segmentation, tracking, dynamic reconstruction, action recognition, and prediction. The fidelity and breadth of these datasets are vital for creating lifelike interactions. We also discuss scaling challenges, with the limitations of manual annotation and specialized hardware, and explore current solutions like cost-effective capture systems, dataset integration, and data augmentation to enable the generation of extensive interactive models for advancing human-scene interaction research. For robot-scene interaction, this study emphasizes the importance of affordance, that is, the potential action possibilities that objects or environments can provide to users. It discusses approaches for detecting and analyzing affordance at different granularities, as well as affordance modeling techniques that combine multi-source and multimodal data. In the aspect of digital human-scene interaction, this study provides a detailed introduction to the simulation and generation methods of human motion, especially focusing on technologies based on deep learning and generative models in recent years. Building on this foundation, the study reviews ways to represent a scene and recent successful approaches that achieve high-quality human-scene interaction simulation. Finally, we discuss the challenges and future development trends in this field.关键词:environment interaction;interaction simulation;interaction data;interaction perception;interaction generation
摘要:Human intelligence evolves through interactions with the environment, which makes autonomous interaction between intelligent agents and the environment a key factor in advancing intelligence. Autonomous interaction with the environment is a research topic that involves multiple disciplines, such as computer graphics, computer vision, and robotics, and has attracted significant attention and exploration in recent years. In this study, we focus on human-like interaction in indoor environment and comprehensively review the research progress in the fundamental components including simulation interaction platforms, scene interaction data, and interaction generation algorithms for digital humans and robots. Regarding simulation interaction platforms, we comprehensively review representative simulation methods for virtual humans, objects, and human-object interaction. Specifically, we cover critical algorithms for articulated rigid-body simulation, deformable-body and cloth simulation, fluid simulation, contact and collision, and multi-body multi-physics coupling. In addition, we introduce several popular simulation platforms that are readily available for practitioners in the graphics, robotics, and machine learning communities. We classify these popular simulation platforms into two main categories: simulators focusing on single-physics systems and those supporting multi-physics systems. We review typical simulation platforms in both categories and discuss their advantages in human-like indoor-scene interaction. Finally, we briefly discuss several emerging trends in the physical simulation community that inspire promising future directions: developing a full-featured simulator for multi-physics multi-body physical systems, equipping modern simulation platforms with differentiability, and combining physics principles with insights from learning techniques. Regarding scene interaction data, we provide an in-depth review of the latest developments and trends in datasets that support the understanding and generation of human-scene interactions. We focus on the need for agents to perceive scenes with a focus on interaction, assimilate interactive information, and recognize human interaction patterns to improve simulation and movement generation. Our review spans three areas: perception datasets for human-scene interaction, datasets for interaction motion, and methods for scaling data efficiently. Perception datasets facilitate a deeper understanding of 3D scenes, which highlights geometry, structure, functionality, and motion. They offer resources for interaction affordances, grasping poses, interactive components, and object positioning. Motion datasets, which are essential for crafting interactions, delve into interaction movement analysis, including motion segmentation, tracking, dynamic reconstruction, action recognition, and prediction. The fidelity and breadth of these datasets are vital for creating lifelike interactions. We also discuss scaling challenges, with the limitations of manual annotation and specialized hardware, and explore current solutions like cost-effective capture systems, dataset integration, and data augmentation to enable the generation of extensive interactive models for advancing human-scene interaction research. For robot-scene interaction, this study emphasizes the importance of affordance, that is, the potential action possibilities that objects or environments can provide to users. It discusses approaches for detecting and analyzing affordance at different granularities, as well as affordance modeling techniques that combine multi-source and multimodal data. In the aspect of digital human-scene interaction, this study provides a detailed introduction to the simulation and generation methods of human motion, especially focusing on technologies based on deep learning and generative models in recent years. Building on this foundation, the study reviews ways to represent a scene and recent successful approaches that achieve high-quality human-scene interaction simulation. Finally, we discuss the challenges and future development trends in this field.关键词:environment interaction;interaction simulation;interaction data;interaction perception;interaction generation- 11
- |
- 1
- |
- 0
发布时间:2024-06-27 -
 摘要:Affective computing is an important branch in the field of artificial intelligence (AI). It aims to build a computational system that can automatically perceive, recognize, understand, and provide feedback on human emotions. It involves the intersection of multiple disciplines such as computer science, neuroscience, psychology, and social science. Deep emotional understanding and interaction can enable computers to better understand and respond to human emotional needs. It can also provide personalized interactions and feedback based on emotional states, which enhances the human-computer interaction experience. It has various applications in areas such as intelligent assistants, virtual reality, and smart healthcare. Relying solely on single-modal information, such as speech signal or video, does not align with the way humans perceive emotions. The accuracy of recognition rapidly decreases when faced with interference. Multimodal emotion understanding and interaction technologies aim to fully model multidimensional information from audio, video, and physiological signals to achieve more accurate emotion understanding. This technology is fundamental and an important prerequisite for achieving natural, human-like, and personalized human-computer interaction. It holds significant value for ushering in the era of intelligence and digitalization. Multimodal fusion for sentiment recognition receives increasing attention from researchers in fully exploiting the complementary nature of different modalities. This study introduces the current research status of multimodal sentiment computation from three dimensions: an overview of multimodal sentiment recognition, multimodal sentiment understanding, and detection and assessment of emotional disorders such as depression. The overview of emotion recognition is elaborated from the aspects of academic definition, mainstream datasets, and international competitions. In recent years, large language models (LLMs) have demonstrated excellent modeling capabilities and achieved great success in the field of natural language processing with their outstanding language understanding and reasoning abilities. LLMs have garnered widespread attention because of their ability to handle various complex tasks by understanding prompts with minimal or zero-shot learning. Through methods such as self-supervised learning or contrastive learning, LLMs can learn more expressive multimodal representations, which can capture the correlations between different modalities and emotional information. Multimodal sentiment recognition and understanding are discussed in terms of emotion feature extraction, multimodal fusion, and the representation and models involved in sentiment recognition under the background of pre-trained large models. With the rapid development of society, people are facing increasing pressure, which can lead to feelings of depression, anxiety, and other negative emotions. Those who are in a prolonged state of depression and anxiety are more likely to develop mental illnesses. Depression is a common and serious condition, with symptoms including low mood, poor sleep quality, loss of appetite, fatigue, and difficulty concentrating. Depression not only harms individuals and families but also causes significant economic losses to society. The detection of emotional disorders starts from specific applications, which selects depression as the most common emotional disorder. We analyze its latest developments and trends from the perspectives of assessment and intervention. In addition, this study provides a detailed comparison of the research status of affective computation domestically, and prospects for future development trends are offered. We believe that scalable emotion feature design and large-scale model transfer learning based methods will be the future directions of development. The main challenge in multimodal emotion recognition lies in data scarcity, which means that data available to build and explore complex models are insufficient. This insufficiency causes difficulty in creating robust models based on deep neural network methods. The above mentioned issues can be addressed by constructing large-scale multimodal emotion databases and exploring transfer learning methods based on large models. By transferring knowledge learned from unsupervised tasks or other tasks to emotion recognition tasks, the problem of limited data resources can be alleviated. The use of explicit discrete and dimensional labels to represent ambiguous emotional states has limitations due to the inherent fuzziness of emotions. Enhancing the interpretability of prediction results to improve the reliability of recognition results is also an important research direction for the future. The role of multimodal emotion computing in addressing emotional disorders such as depression and anxiety is increasingly prominent. Future research can be conducted in the following three areas. First, research and construction of multimodal emotion disorder datasets can provide a solid foundation for the automatic recognition of emotional disorders. However, this field still needs to address challenges such as data privacy and ethics. In addition, considerations such as designing targeted interview questions, ensuring patient safety during data collection, and sample augmentation through algorithms are still worth exploring. Second, more effective algorithms should be developed. Emotional disorders fall within the psychological domain, and they can also affect the physiological features of patients, such as voice and body movements. This psychological-physiological correlation is worthy of comprehensive exploration. Therefore, improving the accuracy of algorithms for multimodal emotion disorder recognition is a pressing research issue. Finally, intelligent psychological intervention systems should be designed and implemented. The following issues can be further studied: effectively simulating the counseling process of a psychologist, promptly receiving user emotional feedback, and generating empathetic conversations.关键词:sentiment recognition;multimodel fusion;human-computer interaction;depression detection;emotion disorder intervention;cognitive behavior therapy
摘要:Affective computing is an important branch in the field of artificial intelligence (AI). It aims to build a computational system that can automatically perceive, recognize, understand, and provide feedback on human emotions. It involves the intersection of multiple disciplines such as computer science, neuroscience, psychology, and social science. Deep emotional understanding and interaction can enable computers to better understand and respond to human emotional needs. It can also provide personalized interactions and feedback based on emotional states, which enhances the human-computer interaction experience. It has various applications in areas such as intelligent assistants, virtual reality, and smart healthcare. Relying solely on single-modal information, such as speech signal or video, does not align with the way humans perceive emotions. The accuracy of recognition rapidly decreases when faced with interference. Multimodal emotion understanding and interaction technologies aim to fully model multidimensional information from audio, video, and physiological signals to achieve more accurate emotion understanding. This technology is fundamental and an important prerequisite for achieving natural, human-like, and personalized human-computer interaction. It holds significant value for ushering in the era of intelligence and digitalization. Multimodal fusion for sentiment recognition receives increasing attention from researchers in fully exploiting the complementary nature of different modalities. This study introduces the current research status of multimodal sentiment computation from three dimensions: an overview of multimodal sentiment recognition, multimodal sentiment understanding, and detection and assessment of emotional disorders such as depression. The overview of emotion recognition is elaborated from the aspects of academic definition, mainstream datasets, and international competitions. In recent years, large language models (LLMs) have demonstrated excellent modeling capabilities and achieved great success in the field of natural language processing with their outstanding language understanding and reasoning abilities. LLMs have garnered widespread attention because of their ability to handle various complex tasks by understanding prompts with minimal or zero-shot learning. Through methods such as self-supervised learning or contrastive learning, LLMs can learn more expressive multimodal representations, which can capture the correlations between different modalities and emotional information. Multimodal sentiment recognition and understanding are discussed in terms of emotion feature extraction, multimodal fusion, and the representation and models involved in sentiment recognition under the background of pre-trained large models. With the rapid development of society, people are facing increasing pressure, which can lead to feelings of depression, anxiety, and other negative emotions. Those who are in a prolonged state of depression and anxiety are more likely to develop mental illnesses. Depression is a common and serious condition, with symptoms including low mood, poor sleep quality, loss of appetite, fatigue, and difficulty concentrating. Depression not only harms individuals and families but also causes significant economic losses to society. The detection of emotional disorders starts from specific applications, which selects depression as the most common emotional disorder. We analyze its latest developments and trends from the perspectives of assessment and intervention. In addition, this study provides a detailed comparison of the research status of affective computation domestically, and prospects for future development trends are offered. We believe that scalable emotion feature design and large-scale model transfer learning based methods will be the future directions of development. The main challenge in multimodal emotion recognition lies in data scarcity, which means that data available to build and explore complex models are insufficient. This insufficiency causes difficulty in creating robust models based on deep neural network methods. The above mentioned issues can be addressed by constructing large-scale multimodal emotion databases and exploring transfer learning methods based on large models. By transferring knowledge learned from unsupervised tasks or other tasks to emotion recognition tasks, the problem of limited data resources can be alleviated. The use of explicit discrete and dimensional labels to represent ambiguous emotional states has limitations due to the inherent fuzziness of emotions. Enhancing the interpretability of prediction results to improve the reliability of recognition results is also an important research direction for the future. The role of multimodal emotion computing in addressing emotional disorders such as depression and anxiety is increasingly prominent. Future research can be conducted in the following three areas. First, research and construction of multimodal emotion disorder datasets can provide a solid foundation for the automatic recognition of emotional disorders. However, this field still needs to address challenges such as data privacy and ethics. In addition, considerations such as designing targeted interview questions, ensuring patient safety during data collection, and sample augmentation through algorithms are still worth exploring. Second, more effective algorithms should be developed. Emotional disorders fall within the psychological domain, and they can also affect the physiological features of patients, such as voice and body movements. This psychological-physiological correlation is worthy of comprehensive exploration. Therefore, improving the accuracy of algorithms for multimodal emotion disorder recognition is a pressing research issue. Finally, intelligent psychological intervention systems should be designed and implemented. The following issues can be further studied: effectively simulating the counseling process of a psychologist, promptly receiving user emotional feedback, and generating empathetic conversations.关键词:sentiment recognition;multimodel fusion;human-computer interaction;depression detection;emotion disorder intervention;cognitive behavior therapy- 3
- |
- 0
- |
- 0
发布时间:2024-06-27
Generative Large Model and Human-computer Interaction

-
 摘要:Medical ultrasound, as a noninvasive, radiation-free, real-time medical imaging modality, plays a crucial role in the early and clinical diagnoses and treatment. Image resolution stands as a core indicator of ultrasound instruments, which significantly influences precise diagnosis. In recent years, ultrasound imaging devices have undergone a diversified development to meet various clinical application scenarios, including ultra-fast and hand-held imaging devices. However, most advancement comes at the expense of reducing imaging quality to achieve high imaging frame rate or portable hardware system, which impacts their clinical applicability. Thus, obtaining high-quality ultrasound images is a pivotal issue. This study reviews extensive recent work on the high-quality ultrasound imaging by delving into beamforming algorithms and high-quality ultrasound reconstruction methods. In the aspect of beamforming algorithms, we introduce traditional non-adaptive methods represented by Delay and Sum techniques, as well as four types of adaptive beamforming methods with superior imaging quality but higher computational complexity. In addition, a brief introduction to learning-based models for beamforming is provided. Adaptive beamforming algorithms are currently a major research topic with the advantages of high imaging quality and the substantial development prospects. The study focuses on four main kinds of adaptive algorithms: minimum variance (MV) methods, coherence factor (CF) methods, short-lag spatial coherence (SLSC) methods, and filtered delay multiply and sum (F-DMAS) methods. Detailed analyses of modified algorithms based on the classic adaptive algorithms and corresponding applications are presented. For each type of adaptive algorithm, a brief theoretical introduction is provided. Subsequently, the study lists the most influential related literature in recent years, along with a short summary to the methodology and final results. The primary challenge for MV-based methods is improving the accuracy of covariance matrix estimation and reducing computational complexity. To address this problem, the study introduces several approaches, such as reducing beamforming dimensionality, designing covariance matrix based on Toeplitz structure, and learning adaptive weights using neural networks. For CF-based methods, improved coherence factor methods and other related methods are introduced. Compared with the traditional CF-based methods, the former can greatly improve the lateral resolution and signal-to-noise ratio of images, while the latter can suppress the dark region artifacts and alleviate the excessive suppression of coherence factor. For SLSC-based methods, techniques like adaptive synthesis of dual pore diameter, robust principal component analysis, and linear attenuation weighting are explored to address the issue of poor resolution. For F-DMAS-based methods, approaches to further enhance imaging quality and decrease computational cost are discussed. For instance, combining multi-line acquisition with the lower-complexity F-DMAS algorithm increases the frame rates while maintaining the high quality of images. F-DMAS can also be combined with a pixel-based beamformer to improve the contrast of the generated images and suppress the clutter. Finally, the study provides an analysis of the advantages and disadvantages of each method in terms of resolution, contrast, noise suppression, and robustness. For high-quality ultrasound reconstruction algorithms, the discussion primarily focuses on two aspects: conventional and deep learning-based methods. Conventional methods, including interpolation, sparse representation-based methods, and example-based methods, aim to enhance the spatiotemporal resolution and reduce noise of images. By contrast, deep learning methods, which are capable of fully utilizing prior knowledge to automatically learn gray distribution mapping between images from different domains (centers), present broader application prospects in high-quality ultrasound reconstruction algorithms. For convolutional neural network (CNN)-based methods, the study enumerates several approaches, such as learning the nonlinear mapping between low-quality image subspaces reconstructed from a single plane wave and high-quality image subspaces reconstructed from synthetic aperture measurements through CNN. This approach can accurately preserve complete speckle patterns while improving lateral resolution. The image reconstruction method based on a two-stage CNN can produce high-quality images from ultra-fast ultrasound imaging while ensuring high frame rates. Regarding generative adversarial network (GAN)-based methods, the study introduces several improved algorithms that achieve higher-quality acquisition of images, stronger robustness of algorithms, and higher image frame coherence to better satisfy the specific demand for clinical applications. Finally, the study conducts an overall comparative analysis of research progress at home and abroad and discusses future development trends. Concerning beamforming algorithms, domestic and foreign scholars focus on adaptive beamforming methods. Moreover, the future development and research trends of beamforming algorithms can be primarily summarized as follows: 1) reducing the computational complexity of adaptive beamforming methods to improve their real-time performance; 2) deepening research on learning-based beamforming algorithms; 3) synchronously increasing the imaging frame rate and image quality in ultrafast ultrasound imaging; and 4) integrating different beamforming methods to fully leverage the advantages of various approaches. In terms of high-quality ultrasound image reconstruction, studies predominantly focus on deep learning technology. Relatively few studies are available on using traditional methods for super-resolution reconstruction. The research on deep learning methods has shifted from CNNs to GANs or their fusion. Finally, future prospects for high-quality ultrasound image reconstruction are proposed: 1) combining traditional methods with deep learning techniques, and 2) introducing diffusion models and foundation models into the field of high-resolution ultrasound image reconstruction to further enhance the quality of generated images. The synergy of traditional and deep learning-based methods, coupled with the introduction of innovative and advanced technology, holds great promise for propelling high-resolution ultrasound image reconstruction into new frontiers and contributes significantly to the advancement of healthcare services.关键词:ultrasonic imaging;beamforming;adaptive imaging;image reconstruction;super-resolution
摘要:Medical ultrasound, as a noninvasive, radiation-free, real-time medical imaging modality, plays a crucial role in the early and clinical diagnoses and treatment. Image resolution stands as a core indicator of ultrasound instruments, which significantly influences precise diagnosis. In recent years, ultrasound imaging devices have undergone a diversified development to meet various clinical application scenarios, including ultra-fast and hand-held imaging devices. However, most advancement comes at the expense of reducing imaging quality to achieve high imaging frame rate or portable hardware system, which impacts their clinical applicability. Thus, obtaining high-quality ultrasound images is a pivotal issue. This study reviews extensive recent work on the high-quality ultrasound imaging by delving into beamforming algorithms and high-quality ultrasound reconstruction methods. In the aspect of beamforming algorithms, we introduce traditional non-adaptive methods represented by Delay and Sum techniques, as well as four types of adaptive beamforming methods with superior imaging quality but higher computational complexity. In addition, a brief introduction to learning-based models for beamforming is provided. Adaptive beamforming algorithms are currently a major research topic with the advantages of high imaging quality and the substantial development prospects. The study focuses on four main kinds of adaptive algorithms: minimum variance (MV) methods, coherence factor (CF) methods, short-lag spatial coherence (SLSC) methods, and filtered delay multiply and sum (F-DMAS) methods. Detailed analyses of modified algorithms based on the classic adaptive algorithms and corresponding applications are presented. For each type of adaptive algorithm, a brief theoretical introduction is provided. Subsequently, the study lists the most influential related literature in recent years, along with a short summary to the methodology and final results. The primary challenge for MV-based methods is improving the accuracy of covariance matrix estimation and reducing computational complexity. To address this problem, the study introduces several approaches, such as reducing beamforming dimensionality, designing covariance matrix based on Toeplitz structure, and learning adaptive weights using neural networks. For CF-based methods, improved coherence factor methods and other related methods are introduced. Compared with the traditional CF-based methods, the former can greatly improve the lateral resolution and signal-to-noise ratio of images, while the latter can suppress the dark region artifacts and alleviate the excessive suppression of coherence factor. For SLSC-based methods, techniques like adaptive synthesis of dual pore diameter, robust principal component analysis, and linear attenuation weighting are explored to address the issue of poor resolution. For F-DMAS-based methods, approaches to further enhance imaging quality and decrease computational cost are discussed. For instance, combining multi-line acquisition with the lower-complexity F-DMAS algorithm increases the frame rates while maintaining the high quality of images. F-DMAS can also be combined with a pixel-based beamformer to improve the contrast of the generated images and suppress the clutter. Finally, the study provides an analysis of the advantages and disadvantages of each method in terms of resolution, contrast, noise suppression, and robustness. For high-quality ultrasound reconstruction algorithms, the discussion primarily focuses on two aspects: conventional and deep learning-based methods. Conventional methods, including interpolation, sparse representation-based methods, and example-based methods, aim to enhance the spatiotemporal resolution and reduce noise of images. By contrast, deep learning methods, which are capable of fully utilizing prior knowledge to automatically learn gray distribution mapping between images from different domains (centers), present broader application prospects in high-quality ultrasound reconstruction algorithms. For convolutional neural network (CNN)-based methods, the study enumerates several approaches, such as learning the nonlinear mapping between low-quality image subspaces reconstructed from a single plane wave and high-quality image subspaces reconstructed from synthetic aperture measurements through CNN. This approach can accurately preserve complete speckle patterns while improving lateral resolution. The image reconstruction method based on a two-stage CNN can produce high-quality images from ultra-fast ultrasound imaging while ensuring high frame rates. Regarding generative adversarial network (GAN)-based methods, the study introduces several improved algorithms that achieve higher-quality acquisition of images, stronger robustness of algorithms, and higher image frame coherence to better satisfy the specific demand for clinical applications. Finally, the study conducts an overall comparative analysis of research progress at home and abroad and discusses future development trends. Concerning beamforming algorithms, domestic and foreign scholars focus on adaptive beamforming methods. Moreover, the future development and research trends of beamforming algorithms can be primarily summarized as follows: 1) reducing the computational complexity of adaptive beamforming methods to improve their real-time performance; 2) deepening research on learning-based beamforming algorithms; 3) synchronously increasing the imaging frame rate and image quality in ultrafast ultrasound imaging; and 4) integrating different beamforming methods to fully leverage the advantages of various approaches. In terms of high-quality ultrasound image reconstruction, studies predominantly focus on deep learning technology. Relatively few studies are available on using traditional methods for super-resolution reconstruction. The research on deep learning methods has shifted from CNNs to GANs or their fusion. Finally, future prospects for high-quality ultrasound image reconstruction are proposed: 1) combining traditional methods with deep learning techniques, and 2) introducing diffusion models and foundation models into the field of high-resolution ultrasound image reconstruction to further enhance the quality of generated images. The synergy of traditional and deep learning-based methods, coupled with the introduction of innovative and advanced technology, holds great promise for propelling high-resolution ultrasound image reconstruction into new frontiers and contributes significantly to the advancement of healthcare services.关键词:ultrasonic imaging;beamforming;adaptive imaging;image reconstruction;super-resolution- 3
- |
- 0
- |
- 0
发布时间:2024-06-27 -
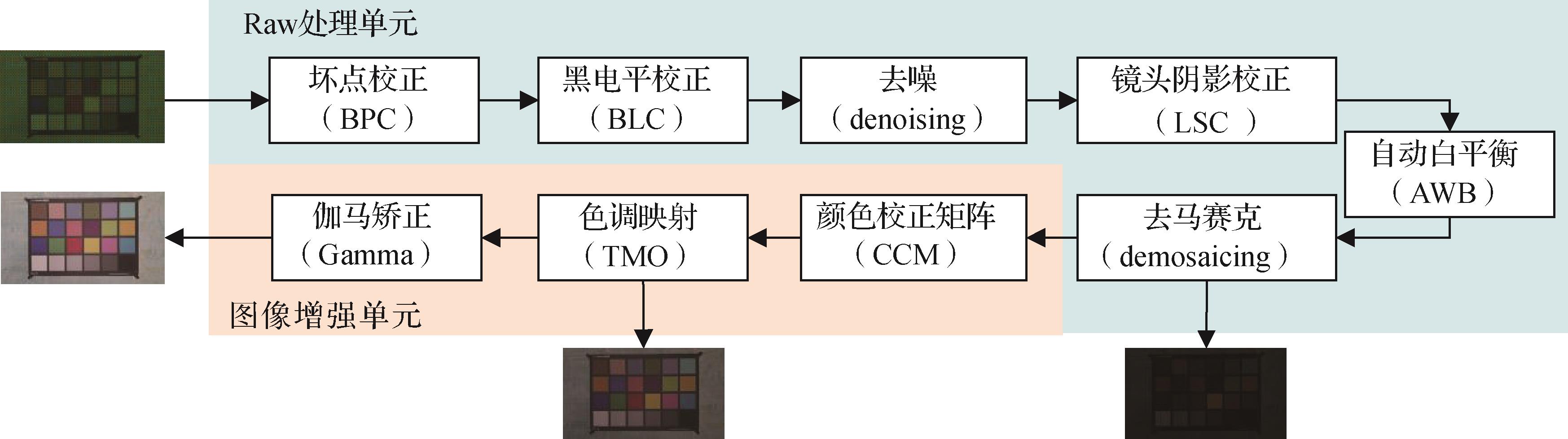 摘要:The low-level vision reconstruction technology aims to reconstruct high-quality images and videos under limited imaging conditions, which is important for subsequent visual analysis. The images (videos) in the raw domain have two advantageous features: wider bit depth (10, 12, 14 bits) and intensity linear to the irradiance. As a result, raw images contain the most original information and the noise statistics are also simpler than those in standard RGB (sRGB) domain. Therefore, low-level vision reconstruction with raw inputs has achieved an increasing attention from academic and industrial communities in recent years. This review focuses on the low-level vision reconstruction technology in the raw domain and mainly investigates the progress of deep learning-based vision reconstruction. Six representative vision reconstruction tasks in raw domain are selected, namely, low-light enhancement and denoising, super-resolution, high dynamic range (HDR) reconstruction, moiré removal, multi-task joint reconstruction, and raw image generation, for a comprehensive review. Representative methods in the six fields are systematically summarized, the advantages and problems of various methods are outlined, and the advantages and unique attributes of raw images (videos) compared with sRGB images (videos) are highlighted in different tasks. Thereafter, the currently open-source low-level vision reconstruction datasets in raw domain in various fields are summarized, including image, burst image, and video datasets. The dataset construction methods for each task are introduced. Different strategies to solve the key problems in dataset construction, namely, spatial alignment and temporal alignment, are also introduced. We hope these summarization and comparisons can provide references for the followers who construct their own datasets. This review would like to point out that the six tasks not only have unique problems but also have common issues. For example, for denoising and enhancement of videos captured in low light, constructing a supervised dataset with realistic motions and fine-scale textures is still difficult. For multi-frame super-resolution, the key problem is constructing the accurate alignment module. For HDR reconstruction, the deghosting performance still needs to be improved in dark and over-exposed areas. For demoiréing, balancing the performance between color recovery and moiré removal needs to be explored. For multi-task joint reconstruction, improving the adjustability and interpretability of the model is a key problem. Meanwhile, all the six tasks need to recover the correct colors while completing their own tasks. However, they have different optimization directions. Introducing special modules to ensure their similar optimization directions may be a good solution. In addition, achieving accurate alignment between degraded and ground truth images is difficult, and many datasets exhibit misalignment. Then, we review representative industrial applications of raw domain reconstruction, including intelligent image signal processing and night imaging in smartphones, low-light and HDR imaging in security monitoring cameras, and raw domain detection in driverless cars. Finally, based on the existing problems and challenges of raw domain vision reconstruction, we identify four possible development trends for raw domain vision reconstruction. First is exploiting the specific properties of raw images (videos) for a specific task. Current methods usually utilize the advantages of raw data in terms of wider bit depth and linearity to intensity. Only a few works utilize the specialized structures of raw data. For example, the moiré distribution in different channels differs, and the green channel usually has higher intensities than other channels. We expect more works exploring the special properties of raw data in popular denoising and super-resolution tasks. Second is improving the availability of large-scale raw data. Many cameras do not provide the raw outputs due to the large memory cost. Therefore, the current constructed raw domain datasets are usually smaller than those in sRGB domain. A feasible solution is to design the raw image compression method with sRGB image guidance for enabling raw domain decoding with a few meta data. Third is alleviating the data-bias problem. The model trained with the raw data captured with one camera may not work well when dealing with raw images captured with other cameras. Alleviating the data-bias is important for real applications. One feasible solution is to jointly utilize physics- and data-driven models. Fourth is further improving raw reconstruction performance with large models. The scale of data is important to improve the reconstruction quality. One solution is to first train a large model with a large-scale dataset and then distill the large model to a small one. Then, the small model can be deployed in various edge devices. In summary, we expect more works exploring low-level vision reconstruction in raw domain to improve the imaging quality of various vision systems.关键词:raw-domain vision reconstruction;low light image (video) enhancement in raw domain;raw image (video) denoising;raw image (video) super-resolution;raw image (video) high dynamic range (HDR) reconstruction;raw image (video) demoriéing
摘要:The low-level vision reconstruction technology aims to reconstruct high-quality images and videos under limited imaging conditions, which is important for subsequent visual analysis. The images (videos) in the raw domain have two advantageous features: wider bit depth (10, 12, 14 bits) and intensity linear to the irradiance. As a result, raw images contain the most original information and the noise statistics are also simpler than those in standard RGB (sRGB) domain. Therefore, low-level vision reconstruction with raw inputs has achieved an increasing attention from academic and industrial communities in recent years. This review focuses on the low-level vision reconstruction technology in the raw domain and mainly investigates the progress of deep learning-based vision reconstruction. Six representative vision reconstruction tasks in raw domain are selected, namely, low-light enhancement and denoising, super-resolution, high dynamic range (HDR) reconstruction, moiré removal, multi-task joint reconstruction, and raw image generation, for a comprehensive review. Representative methods in the six fields are systematically summarized, the advantages and problems of various methods are outlined, and the advantages and unique attributes of raw images (videos) compared with sRGB images (videos) are highlighted in different tasks. Thereafter, the currently open-source low-level vision reconstruction datasets in raw domain in various fields are summarized, including image, burst image, and video datasets. The dataset construction methods for each task are introduced. Different strategies to solve the key problems in dataset construction, namely, spatial alignment and temporal alignment, are also introduced. We hope these summarization and comparisons can provide references for the followers who construct their own datasets. This review would like to point out that the six tasks not only have unique problems but also have common issues. For example, for denoising and enhancement of videos captured in low light, constructing a supervised dataset with realistic motions and fine-scale textures is still difficult. For multi-frame super-resolution, the key problem is constructing the accurate alignment module. For HDR reconstruction, the deghosting performance still needs to be improved in dark and over-exposed areas. For demoiréing, balancing the performance between color recovery and moiré removal needs to be explored. For multi-task joint reconstruction, improving the adjustability and interpretability of the model is a key problem. Meanwhile, all the six tasks need to recover the correct colors while completing their own tasks. However, they have different optimization directions. Introducing special modules to ensure their similar optimization directions may be a good solution. In addition, achieving accurate alignment between degraded and ground truth images is difficult, and many datasets exhibit misalignment. Then, we review representative industrial applications of raw domain reconstruction, including intelligent image signal processing and night imaging in smartphones, low-light and HDR imaging in security monitoring cameras, and raw domain detection in driverless cars. Finally, based on the existing problems and challenges of raw domain vision reconstruction, we identify four possible development trends for raw domain vision reconstruction. First is exploiting the specific properties of raw images (videos) for a specific task. Current methods usually utilize the advantages of raw data in terms of wider bit depth and linearity to intensity. Only a few works utilize the specialized structures of raw data. For example, the moiré distribution in different channels differs, and the green channel usually has higher intensities than other channels. We expect more works exploring the special properties of raw data in popular denoising and super-resolution tasks. Second is improving the availability of large-scale raw data. Many cameras do not provide the raw outputs due to the large memory cost. Therefore, the current constructed raw domain datasets are usually smaller than those in sRGB domain. A feasible solution is to design the raw image compression method with sRGB image guidance for enabling raw domain decoding with a few meta data. Third is alleviating the data-bias problem. The model trained with the raw data captured with one camera may not work well when dealing with raw images captured with other cameras. Alleviating the data-bias is important for real applications. One feasible solution is to jointly utilize physics- and data-driven models. Fourth is further improving raw reconstruction performance with large models. The scale of data is important to improve the reconstruction quality. One solution is to first train a large model with a large-scale dataset and then distill the large model to a small one. Then, the small model can be deployed in various edge devices. In summary, we expect more works exploring low-level vision reconstruction in raw domain to improve the imaging quality of various vision systems.关键词:raw-domain vision reconstruction;low light image (video) enhancement in raw domain;raw image (video) denoising;raw image (video) super-resolution;raw image (video) high dynamic range (HDR) reconstruction;raw image (video) demoriéing- 4
- |
- 1
- |
- 0
发布时间:2024-06-27 -
 摘要:Visual media such as images and videos are crucial means for humans to acquire, express, and convey information. The widespread application of foundational technologies like artificial intelligence and big data has facilitated the gradual integration of systems for the perception and understanding of images and videos into all aspects of production and daily life. However, the emergence of massive applications also brings challenges. Specifically, in open environments, various applications generate vast amounts of heterogeneous data, which leads to complex visual degradation in images and videos. For instance, adverse weather conditions like heavy fog can reduce visibility, which results in the loss of details. Data captured in rainy or snowy weather can exhibit deformations in objects or individuals due to raindrops, which result in structured noise. Low-light conditions can cause severe loss of details and structured information in images. Visual degradation not only diminishes the visual presentation and perceptual experience of images and videos but also significantly affects the usability and effectiveness of existing visual analysis and understanding systems. In today’s era of intelligence and information technology, with explosive growth in visual media data, especially in challenging scenarios, visual perception and understanding technologies hold significant scientific significance and practical value. Traditional visual enhancement techniques can be divided into two methods: spatial domain-based and frequency domain-based. Spatial domain methods directly process 2D spatial data, including grayscale transformation, histogram transformation, and spatial domain filtering. Frequency domain methods transform data into the frequency domain through models, like Fourier transform, for processing and then restore it to the spatial domain. The development of computer vision technology has facilitated the emergence of more well-designed and robust visual enhancement algorithms, such as dehazing algorithms based on dark channel priors. Since 2010s, the rapid advancement in artificial intelligence technology has enabled the development of many visual enhancement methods based on deep learning models. These methods not only can reconstruct damaged visual information but also can further improve the visual presentation, which comprehensively enhances the visual perceptual experience of images and videos captured in challenging scenarios. As computer vision technology becomes more widespread, intelligent visual analysis and understanding are penetrating various aspects of society, such as face recognition and autonomous driving. However, visual enhancement in traditional digital image processing frameworks mainly focuses on improving visual effects, which ignores the impact on high-level analysis tasks. This oversight severely reduces the usability and effectiveness of existing visual understanding systems. In recent years, several visual understanding datasets for challenging scenarios have been established, which leads to the development of numerous visual analysis and understanding algorithms for these scenarios. Domain transfer methods from ordinary scenes to challenging scenes are gaining attention in further reducing reliance on datasets. Coordinating and optimizing the relationship between visual perception and visual presentation, which are two different task objectives, are also important research problems in the field of visual computing. To address the development needs of the visual computing field in challenging scenarios, this study extensively reviews the challenges of the aforementioned research, outlines the developmental trends, and explores the cutting-edge dynamics. Specifically, this study reviews the technologies related to visual degradation modeling, visual enhancement, and visual analysis and understanding in challenging scenarios. In the section on visual data and degradation modeling, various methods for modeling image and video degradation processes in different degradation scenarios are discussed. These methods include noise modeling, downsampling modeling, illumination modeling, and rain and fog modeling. For noise modeling, Poissonian-Gaussian noise modeling is the most commonly used. For downsampling modeling, classical methods include bicubic interpolation and blurring kernel. Noise including JPEG compression is also considered. A recent comprehensive model jointly uses blurring, downsampling, and noise. For illumination modeling, the Retinex theory is one of the most widely used. It decomposes images into illumination and reflectance. For rain and fog modeling, images are generally decomposed into rain and background layers. In the traditional visual enhancement section, numerous visual enhancement algorithms have been developed to address the degradation of image and video information in adverse scenarios. Early algorithms often employed simple strategies, such as super-resolution methods primarily based on interpolation techniques. However, these methods are constrained by linear models and struggle to restore high-frequency details. Researchers have proposed more sophisticated algorithms to address the complex degradation issues in adverse scenarios. These algorithms include techniques such as histogram equalization, Retinex theory, and filtering methods. Deep neural networks have shown remarkable performance in various fields such as image classification, object detection, and facial recognition. Simultaneously, in low-level computer vision tasks such as super-resolution, style transfer, color conversion, and texture transfer, they also demonstrate excellent performance. With the continuous evolution of deep neural network frameworks, researchers have proposed diverse visual enhancement methods. The section on visual enhancement based on deep learning models takes an innovative approach to model architecture. It discusses architectures like convolutional neural networks, Transformer models, and diffusion models. Unlike traditional visual enhancement, which aims to comprehensively improve human visual perception of images and videos, the new generation of visual enhancement and analysis methods considers the interpretive performance of machine vision in degraded scenarios. The section on visual understanding technology in challenging scenarios discusses visual understanding and its corresponding datasets in challenging scenarios based on deep learning models. It also explores the collaborative computation of visual enhancement and understanding in challenging scenarios. Finally, based on the analysis, it provides prospects for the future development of visual perception and understanding in adverse scenarios. When facing complex degradation scenarios, real-world images may be simultaneously influenced by various factors such as heavy rain and fog, dynamic changes in lighting, low-light environments, and image corruption. This condition requires models to handle unknown and diverse image features. The current challenge lies in the fact that most existing models are designed for specific degradation scenarios. This complexity introduces a significant amount of prior knowledge and causes difficulty in adapting to other degradation scenarios. The construction of existing visual understanding models in adverse scenarios relies on downstream task information, including target domain data distribution, degradation priors, and pre-trained models for downstream tasks. This reliance causes difficulty in achieving robustness for arbitrary tasks and analysis models. Moreover, most methods are limited to a specific machine analysis downstream task and cannot generalize to new downstream task scenarios. Finally, in recent years, large models have achieved significant accomplishments in various fields. Currently, many studies have demonstrated unprecedented potential for large models in tasks like enhancing reconstruction and other low-level computational visual tasks. However, the high complexity of large models also presents challenges, including substantial computational resource requirements, long training times, and difficulties in model optimization. At the same time, the generalization capability of models in adverse scenarios is a pressing challenge that requires more comprehensive data construction strategies and more effective model optimization methods. How to improve the performance and reliability of large visual models in visual perception and understanding tasks in adverse scenarios is a key problem that remains unsolved.关键词:adverse scenarios;visual perception;visual understanding;image and video enhancement;image and video processing;deep learning
摘要:Visual media such as images and videos are crucial means for humans to acquire, express, and convey information. The widespread application of foundational technologies like artificial intelligence and big data has facilitated the gradual integration of systems for the perception and understanding of images and videos into all aspects of production and daily life. However, the emergence of massive applications also brings challenges. Specifically, in open environments, various applications generate vast amounts of heterogeneous data, which leads to complex visual degradation in images and videos. For instance, adverse weather conditions like heavy fog can reduce visibility, which results in the loss of details. Data captured in rainy or snowy weather can exhibit deformations in objects or individuals due to raindrops, which result in structured noise. Low-light conditions can cause severe loss of details and structured information in images. Visual degradation not only diminishes the visual presentation and perceptual experience of images and videos but also significantly affects the usability and effectiveness of existing visual analysis and understanding systems. In today’s era of intelligence and information technology, with explosive growth in visual media data, especially in challenging scenarios, visual perception and understanding technologies hold significant scientific significance and practical value. Traditional visual enhancement techniques can be divided into two methods: spatial domain-based and frequency domain-based. Spatial domain methods directly process 2D spatial data, including grayscale transformation, histogram transformation, and spatial domain filtering. Frequency domain methods transform data into the frequency domain through models, like Fourier transform, for processing and then restore it to the spatial domain. The development of computer vision technology has facilitated the emergence of more well-designed and robust visual enhancement algorithms, such as dehazing algorithms based on dark channel priors. Since 2010s, the rapid advancement in artificial intelligence technology has enabled the development of many visual enhancement methods based on deep learning models. These methods not only can reconstruct damaged visual information but also can further improve the visual presentation, which comprehensively enhances the visual perceptual experience of images and videos captured in challenging scenarios. As computer vision technology becomes more widespread, intelligent visual analysis and understanding are penetrating various aspects of society, such as face recognition and autonomous driving. However, visual enhancement in traditional digital image processing frameworks mainly focuses on improving visual effects, which ignores the impact on high-level analysis tasks. This oversight severely reduces the usability and effectiveness of existing visual understanding systems. In recent years, several visual understanding datasets for challenging scenarios have been established, which leads to the development of numerous visual analysis and understanding algorithms for these scenarios. Domain transfer methods from ordinary scenes to challenging scenes are gaining attention in further reducing reliance on datasets. Coordinating and optimizing the relationship between visual perception and visual presentation, which are two different task objectives, are also important research problems in the field of visual computing. To address the development needs of the visual computing field in challenging scenarios, this study extensively reviews the challenges of the aforementioned research, outlines the developmental trends, and explores the cutting-edge dynamics. Specifically, this study reviews the technologies related to visual degradation modeling, visual enhancement, and visual analysis and understanding in challenging scenarios. In the section on visual data and degradation modeling, various methods for modeling image and video degradation processes in different degradation scenarios are discussed. These methods include noise modeling, downsampling modeling, illumination modeling, and rain and fog modeling. For noise modeling, Poissonian-Gaussian noise modeling is the most commonly used. For downsampling modeling, classical methods include bicubic interpolation and blurring kernel. Noise including JPEG compression is also considered. A recent comprehensive model jointly uses blurring, downsampling, and noise. For illumination modeling, the Retinex theory is one of the most widely used. It decomposes images into illumination and reflectance. For rain and fog modeling, images are generally decomposed into rain and background layers. In the traditional visual enhancement section, numerous visual enhancement algorithms have been developed to address the degradation of image and video information in adverse scenarios. Early algorithms often employed simple strategies, such as super-resolution methods primarily based on interpolation techniques. However, these methods are constrained by linear models and struggle to restore high-frequency details. Researchers have proposed more sophisticated algorithms to address the complex degradation issues in adverse scenarios. These algorithms include techniques such as histogram equalization, Retinex theory, and filtering methods. Deep neural networks have shown remarkable performance in various fields such as image classification, object detection, and facial recognition. Simultaneously, in low-level computer vision tasks such as super-resolution, style transfer, color conversion, and texture transfer, they also demonstrate excellent performance. With the continuous evolution of deep neural network frameworks, researchers have proposed diverse visual enhancement methods. The section on visual enhancement based on deep learning models takes an innovative approach to model architecture. It discusses architectures like convolutional neural networks, Transformer models, and diffusion models. Unlike traditional visual enhancement, which aims to comprehensively improve human visual perception of images and videos, the new generation of visual enhancement and analysis methods considers the interpretive performance of machine vision in degraded scenarios. The section on visual understanding technology in challenging scenarios discusses visual understanding and its corresponding datasets in challenging scenarios based on deep learning models. It also explores the collaborative computation of visual enhancement and understanding in challenging scenarios. Finally, based on the analysis, it provides prospects for the future development of visual perception and understanding in adverse scenarios. When facing complex degradation scenarios, real-world images may be simultaneously influenced by various factors such as heavy rain and fog, dynamic changes in lighting, low-light environments, and image corruption. This condition requires models to handle unknown and diverse image features. The current challenge lies in the fact that most existing models are designed for specific degradation scenarios. This complexity introduces a significant amount of prior knowledge and causes difficulty in adapting to other degradation scenarios. The construction of existing visual understanding models in adverse scenarios relies on downstream task information, including target domain data distribution, degradation priors, and pre-trained models for downstream tasks. This reliance causes difficulty in achieving robustness for arbitrary tasks and analysis models. Moreover, most methods are limited to a specific machine analysis downstream task and cannot generalize to new downstream task scenarios. Finally, in recent years, large models have achieved significant accomplishments in various fields. Currently, many studies have demonstrated unprecedented potential for large models in tasks like enhancing reconstruction and other low-level computational visual tasks. However, the high complexity of large models also presents challenges, including substantial computational resource requirements, long training times, and difficulties in model optimization. At the same time, the generalization capability of models in adverse scenarios is a pressing challenge that requires more comprehensive data construction strategies and more effective model optimization methods. How to improve the performance and reliability of large visual models in visual perception and understanding tasks in adverse scenarios is a key problem that remains unsolved.关键词:adverse scenarios;visual perception;visual understanding;image and video enhancement;image and video processing;deep learning- 5
- |
- 3
- |
- 0
发布时间:2024-06-27
Image Reconstruction and Video Enhancement
-
 摘要:China’s ethnic scripts differ in their structure types, creation periods, and regions of usage and scope. The historical documents and various literary materials written, recorded, and printed in ethnic scripts are even more voluminous, which leave an invaluable wealth for exploring the civilization and development history of different ethnic groups. Compared with mainstream languages, the study of ethnic minority scripts often faces low-resource conditions. In recent years, the protection and inheritance of the intangible cultural heritage of ethnic minorities have attracted increased attention from the country, which has great importance and application value for the protection of irreparable diverse cultural resources. By applying traditional image processing, pattern recognition, and machine learning methods, certain results have been achieved in text recognition and document recognition in Mongolian, Tibetan, Uyghur, Kazakh, Korean, and other major languages. Compared with mainstream languages such as English and Chinese, the research on the character recognition of minority languages, the analysis of document images, and the development of application systems is relatively lagging behind. Since the 21st century, the research and application of ethnic script text analysis and recognition have received extensive attention and made remarkable progress due to the continuous development and application of technologies in the field of document image analysis and recognition. They have become the research hotspots in the field of document analysis and recognition and artificial intelligence. However, a large number of problems still need to be solved in the field of minority script text and recognition research due to the large number of minority scripts, the wide range of application scenarios, and the scarcity of datasets. This study reviews the development history and recent progress in this field at home and abroad to better summarize previous works and provide support for the subsequent research. It focuses on four subtasks: printed text recognition, handwriting recognition, historical document recognition, and scene text recognition of several minority texts. It mainly includes Tibetan, Mongolian, Uighur, Yi, Manchu, and Dongba. These studies are mainly related to the following areas. 1) In the document image preprocessing stage, the system performs a series of operations on the input image, such as binarization, noise removal, skew correction, and image enhancement. The goal of preprocessing is to improve the accuracy of subsequent analysis and recognition. 2) Layout analysis, such as layout segmentation, text line segmentation, and character segmentation, helps understand the organizational structure of documents and extract useful information. 3) Text recognition is one of the core tasks of document image analysis, which identifies the text in a document through various technical approaches. This task may involve traditional methods such as text recognition based on single character classifiers, or it may include end-to-end text line recognition in deep learning methods. 4) Dataset construction involves constructing various datasets for training and evaluating algorithms, such as document image binarization datasets, layout analysis datasets, text line datasets, and character datasets. By contrast, analysis and recognition of historical documents are difficult due to the complexities of rough, degraded, and damaged historical book papers, which result in severe background noise in the document image layout, sticky text strokes, unclear handwriting, and damage. At present, a practical recognition system for historical documents is lacking. First, the importance and value of minority script text analysis and recognition are explained, and some minority script texts, especially historical documents, and their characteristics are introduced. Then, the history of the development of the field and the current state of the research are reviewed, and the representative results of the research of the traditional methods and the progress of the research of the deep learning methods are analyzed and summarized. Current research objects are expanding in depth and breadth, with processing methods comprehensively shifting to deep neural network models and deep learning methods. The recognition performance is also greatly improved, and the application scenarios are constantly expanding. One of the studies realizes effective modeling under low resources. It further proposes a unified multilingual joint modeling technology to identify multiple languages through one model, greatly reduce the overhead of hardware resources, and significantly improve the image and text recognition effect and generalization in multilingual scenarios. At present, it can recognize images and texts in 18 key languages or ethnic languages, including English, French, German, Japanese, Russian, Korean, Arabic, Uyghur, Kazakh, and Inner Mongolian. Based on relevant analyses, obvious deficiencies are observed in recognition accuracy and generalization ability, and differences with Chinese text recognition of ethnic script text recognition are found. The characteristics of the characters and documents of each language are completely different from those of Chinese characters and Chinese documents. For example, in the development of the Yi language, variant characters are particularly abundant due to various factors, and “one-to-many, many-to-one” characters and interpretations are the norm. The arbitrariness and diversity of historical Yi handwriting have brought great challenges to the recognition of historical Yi script. Moreover, the Tibetan script uses arabesque, the shape of the letters is complex, the black plum script is intertwined with each other, some strokes even span several characters before and after, and the connection between the letters is also relatively unique. Thus, the multi-style Tibetan recognition with high complexity and difficulty needs to be solved to achieve true multi-font text recognition. Finally, the main difficulties and challenges faced in the field of minority text recognition are discussed, and the future research trends and technical development goals are prospected. For example, research and application system development are conducted in combination with the characteristics of different languages, layout formats, and varying application scenarios. A certain gap still exists between the recognition of most ethnic languages and the development of Chinese recognition, especially in applications related to education, security, and people’s livelihood. This gap can be addressed by actively expanding new application directions. Opportunities for expansion are abundant, such as migrating large language models to ethnic minority scripts and text recognition and developing a unified multilingual joint modeling and application system.关键词:multiethnic scripts;document analysis and recognition;print recognition;handwriting recognition;historical document recognition;scene image text recognition
摘要:China’s ethnic scripts differ in their structure types, creation periods, and regions of usage and scope. The historical documents and various literary materials written, recorded, and printed in ethnic scripts are even more voluminous, which leave an invaluable wealth for exploring the civilization and development history of different ethnic groups. Compared with mainstream languages, the study of ethnic minority scripts often faces low-resource conditions. In recent years, the protection and inheritance of the intangible cultural heritage of ethnic minorities have attracted increased attention from the country, which has great importance and application value for the protection of irreparable diverse cultural resources. By applying traditional image processing, pattern recognition, and machine learning methods, certain results have been achieved in text recognition and document recognition in Mongolian, Tibetan, Uyghur, Kazakh, Korean, and other major languages. Compared with mainstream languages such as English and Chinese, the research on the character recognition of minority languages, the analysis of document images, and the development of application systems is relatively lagging behind. Since the 21st century, the research and application of ethnic script text analysis and recognition have received extensive attention and made remarkable progress due to the continuous development and application of technologies in the field of document image analysis and recognition. They have become the research hotspots in the field of document analysis and recognition and artificial intelligence. However, a large number of problems still need to be solved in the field of minority script text and recognition research due to the large number of minority scripts, the wide range of application scenarios, and the scarcity of datasets. This study reviews the development history and recent progress in this field at home and abroad to better summarize previous works and provide support for the subsequent research. It focuses on four subtasks: printed text recognition, handwriting recognition, historical document recognition, and scene text recognition of several minority texts. It mainly includes Tibetan, Mongolian, Uighur, Yi, Manchu, and Dongba. These studies are mainly related to the following areas. 1) In the document image preprocessing stage, the system performs a series of operations on the input image, such as binarization, noise removal, skew correction, and image enhancement. The goal of preprocessing is to improve the accuracy of subsequent analysis and recognition. 2) Layout analysis, such as layout segmentation, text line segmentation, and character segmentation, helps understand the organizational structure of documents and extract useful information. 3) Text recognition is one of the core tasks of document image analysis, which identifies the text in a document through various technical approaches. This task may involve traditional methods such as text recognition based on single character classifiers, or it may include end-to-end text line recognition in deep learning methods. 4) Dataset construction involves constructing various datasets for training and evaluating algorithms, such as document image binarization datasets, layout analysis datasets, text line datasets, and character datasets. By contrast, analysis and recognition of historical documents are difficult due to the complexities of rough, degraded, and damaged historical book papers, which result in severe background noise in the document image layout, sticky text strokes, unclear handwriting, and damage. At present, a practical recognition system for historical documents is lacking. First, the importance and value of minority script text analysis and recognition are explained, and some minority script texts, especially historical documents, and their characteristics are introduced. Then, the history of the development of the field and the current state of the research are reviewed, and the representative results of the research of the traditional methods and the progress of the research of the deep learning methods are analyzed and summarized. Current research objects are expanding in depth and breadth, with processing methods comprehensively shifting to deep neural network models and deep learning methods. The recognition performance is also greatly improved, and the application scenarios are constantly expanding. One of the studies realizes effective modeling under low resources. It further proposes a unified multilingual joint modeling technology to identify multiple languages through one model, greatly reduce the overhead of hardware resources, and significantly improve the image and text recognition effect and generalization in multilingual scenarios. At present, it can recognize images and texts in 18 key languages or ethnic languages, including English, French, German, Japanese, Russian, Korean, Arabic, Uyghur, Kazakh, and Inner Mongolian. Based on relevant analyses, obvious deficiencies are observed in recognition accuracy and generalization ability, and differences with Chinese text recognition of ethnic script text recognition are found. The characteristics of the characters and documents of each language are completely different from those of Chinese characters and Chinese documents. For example, in the development of the Yi language, variant characters are particularly abundant due to various factors, and “one-to-many, many-to-one” characters and interpretations are the norm. The arbitrariness and diversity of historical Yi handwriting have brought great challenges to the recognition of historical Yi script. Moreover, the Tibetan script uses arabesque, the shape of the letters is complex, the black plum script is intertwined with each other, some strokes even span several characters before and after, and the connection between the letters is also relatively unique. Thus, the multi-style Tibetan recognition with high complexity and difficulty needs to be solved to achieve true multi-font text recognition. Finally, the main difficulties and challenges faced in the field of minority text recognition are discussed, and the future research trends and technical development goals are prospected. For example, research and application system development are conducted in combination with the characteristics of different languages, layout formats, and varying application scenarios. A certain gap still exists between the recognition of most ethnic languages and the development of Chinese recognition, especially in applications related to education, security, and people’s livelihood. This gap can be addressed by actively expanding new application directions. Opportunities for expansion are abundant, such as migrating large language models to ethnic minority scripts and text recognition and developing a unified multilingual joint modeling and application system.关键词:multiethnic scripts;document analysis and recognition;print recognition;handwriting recognition;historical document recognition;scene image text recognition- 3
- |
- 0
- |
- 0
发布时间:2024-06-27 -
 摘要:Compared with natural and multispectral images, hyperspectral images contain rich spatial-spectral information. They not only can retain the spatial information of the target but also can obtain highly distinguishable spectral information and provide more detailed target feature information. Therefore, hyperspectral images have become one of the most commonly used data types for Earth observation and are widely used in important fields that actually affect human livelihoods, such as natural disaster monitoring, urban landscape mapping, agricultural surveys, environmental management, and homeland security. Change detection refers to the timely observation of land cover changes by analyzing images of the same geographical area and different phases. It is one of the important research directions in remote sensing image processing. With the increasing popularity and application of remote sensing technology, various remote sensing image processing technologies such as target detection and change detection have played an indispensable role in Earth observation tasks, such as natural disaster monitoring, agricultural surveys, environmental management, and homeland security. The important areas for exploration are as follows. Many problems and challenges still exist in the process of change detection in hyperspectral images. On the one hand, hyperspectral images have a large number of spectral bands, which leads to too high dimensions of data. This condition easily causes dimensionality disaster. Moreover, processing high-dimensional data requires a high degree of computing resources. Therefore, in real application scenarios, hyperspectral image change detection is difficult to achieve. Data processing and method design are often easily limited by device storage performance and computing performance. On the other hand, hyperspectral images acquired at different time points may have differences in spectral response due to factors such as illumination and atmospheric conditions. They may also have inconsistencies in resolution and spatial location, which increases the complexity of change detection. Spectral mixing is also one of the important challenges facing hyperspectral change detection. Pixels in hyperspectral data may contain a variety of ground object information, which seriously interferes with the accuracy of change detection. In addition, with the rapid development of hyperspectral remote sensing technology, equipment such as drones and satellites continue to collect a large number of hyperspectral images for use in important fields such as disaster monitoring, mineral exploration, and homeland security. However, differences exist in the shooting angle, height, and resolution of the sensors configured on different devices, and the acquired hyperspectral images also have distinctions in data structures. The existing isomorphism-based change detection methods for hyperspectral images cannot be directly applied to heterogeneous hyperspectral image change detection task. Therefore, the problem of change detection in heterogeneous hyperspectral images from different types of sensors also brings new challenges to hyperspectral image change detection. Therefore, alleviating the highly complex data characteristics of hyperspectral images and designing practical and effective processing solutions are important to improve the change detection effect. Among existing change detection methods for hyperspectral images, traditional methods usually use manually designed methods for feature extraction, which may fail to effectively extract discriminative features, and selecting appropriate thresholds to accurately detect land cover changes is difficult. Research on change detection technology for hyperspectral images has been greatly developed due to in-depth research on deep learning theory. Existing change detection methods based on deep learning can be roughly divided into two categories. One is based on temporal dependence and spatial spectrum information. The extraction method uses the temporal dependence and correlation between images to obtain more discriminative features and enhance the change detection performance. The other type is the method based on endmember extraction and unmixing, which is solved by the endmember extraction and unmixing method. Spectral mixing problem for hyperspectral images aims to improve change detection accuracy. In addition, in the face of heterogeneous hyperspectral image data acquired from different sensors such as drones and satellites, existing methods learn the structural relationships of heterogeneous images based on graph theory. They convert them into the public domain based on image transformation to make changes. With regard to detection and processing, certain temporal dependencies and correlations exist between multiple input images in the change detection task. Thus, effectively utilizing the temporal dependencies and correlations between images and combining the existing deep learning module design to improve the hyperspectral image change detection effect are also current issues. Regarding the research hotspots, this study starts from the new designs, new methods, and application scenarios in the field of hyperspectral image change detection, and the main developments in this field are sorted out by synthesizing domestic and foreign cutting-edge literature. First, it introduces the key preprocessing technologies for hyperspectral image change detection. Second, for the problem of isomorphic hyperspectral image change detection, traditional and deep learning-based methods for hyperspectral image change detection are introduced, and each type of method is systematically introduced and compared according to the different implementation methods. For heterogeneous hyperspectral image change detection and spectral image change detection problem, this study introduces and summarizes the existing heterogeneous change detection methods for hyperspectral images. Next, the current status of application of change detection methods for hyperspectral images in real industrial practice is discussed. Finally, the current research and development status at home and abroad is compared, and the development trend of hyperspectral image change detection is prospected.关键词:hyperspectral image;change detection;temporal feature extraction;endmember unmixing;heterogeneous hyperspectral image change detection
摘要:Compared with natural and multispectral images, hyperspectral images contain rich spatial-spectral information. They not only can retain the spatial information of the target but also can obtain highly distinguishable spectral information and provide more detailed target feature information. Therefore, hyperspectral images have become one of the most commonly used data types for Earth observation and are widely used in important fields that actually affect human livelihoods, such as natural disaster monitoring, urban landscape mapping, agricultural surveys, environmental management, and homeland security. Change detection refers to the timely observation of land cover changes by analyzing images of the same geographical area and different phases. It is one of the important research directions in remote sensing image processing. With the increasing popularity and application of remote sensing technology, various remote sensing image processing technologies such as target detection and change detection have played an indispensable role in Earth observation tasks, such as natural disaster monitoring, agricultural surveys, environmental management, and homeland security. The important areas for exploration are as follows. Many problems and challenges still exist in the process of change detection in hyperspectral images. On the one hand, hyperspectral images have a large number of spectral bands, which leads to too high dimensions of data. This condition easily causes dimensionality disaster. Moreover, processing high-dimensional data requires a high degree of computing resources. Therefore, in real application scenarios, hyperspectral image change detection is difficult to achieve. Data processing and method design are often easily limited by device storage performance and computing performance. On the other hand, hyperspectral images acquired at different time points may have differences in spectral response due to factors such as illumination and atmospheric conditions. They may also have inconsistencies in resolution and spatial location, which increases the complexity of change detection. Spectral mixing is also one of the important challenges facing hyperspectral change detection. Pixels in hyperspectral data may contain a variety of ground object information, which seriously interferes with the accuracy of change detection. In addition, with the rapid development of hyperspectral remote sensing technology, equipment such as drones and satellites continue to collect a large number of hyperspectral images for use in important fields such as disaster monitoring, mineral exploration, and homeland security. However, differences exist in the shooting angle, height, and resolution of the sensors configured on different devices, and the acquired hyperspectral images also have distinctions in data structures. The existing isomorphism-based change detection methods for hyperspectral images cannot be directly applied to heterogeneous hyperspectral image change detection task. Therefore, the problem of change detection in heterogeneous hyperspectral images from different types of sensors also brings new challenges to hyperspectral image change detection. Therefore, alleviating the highly complex data characteristics of hyperspectral images and designing practical and effective processing solutions are important to improve the change detection effect. Among existing change detection methods for hyperspectral images, traditional methods usually use manually designed methods for feature extraction, which may fail to effectively extract discriminative features, and selecting appropriate thresholds to accurately detect land cover changes is difficult. Research on change detection technology for hyperspectral images has been greatly developed due to in-depth research on deep learning theory. Existing change detection methods based on deep learning can be roughly divided into two categories. One is based on temporal dependence and spatial spectrum information. The extraction method uses the temporal dependence and correlation between images to obtain more discriminative features and enhance the change detection performance. The other type is the method based on endmember extraction and unmixing, which is solved by the endmember extraction and unmixing method. Spectral mixing problem for hyperspectral images aims to improve change detection accuracy. In addition, in the face of heterogeneous hyperspectral image data acquired from different sensors such as drones and satellites, existing methods learn the structural relationships of heterogeneous images based on graph theory. They convert them into the public domain based on image transformation to make changes. With regard to detection and processing, certain temporal dependencies and correlations exist between multiple input images in the change detection task. Thus, effectively utilizing the temporal dependencies and correlations between images and combining the existing deep learning module design to improve the hyperspectral image change detection effect are also current issues. Regarding the research hotspots, this study starts from the new designs, new methods, and application scenarios in the field of hyperspectral image change detection, and the main developments in this field are sorted out by synthesizing domestic and foreign cutting-edge literature. First, it introduces the key preprocessing technologies for hyperspectral image change detection. Second, for the problem of isomorphic hyperspectral image change detection, traditional and deep learning-based methods for hyperspectral image change detection are introduced, and each type of method is systematically introduced and compared according to the different implementation methods. For heterogeneous hyperspectral image change detection and spectral image change detection problem, this study introduces and summarizes the existing heterogeneous change detection methods for hyperspectral images. Next, the current status of application of change detection methods for hyperspectral images in real industrial practice is discussed. Finally, the current research and development status at home and abroad is compared, and the development trend of hyperspectral image change detection is prospected.关键词:hyperspectral image;change detection;temporal feature extraction;endmember unmixing;heterogeneous hyperspectral image change detection- 4
- |
- 0
- |
- 0
发布时间:2024-06-27 -
 摘要:In remote sensing of Earth observation, multi-source data can be captured by multiple platforms, multiple sensors, and multiple perspectives. These data provide complementary information for interpreting remote sensing scenes. Although these data offer richer information, they also increase the demand for model depth and complexity. Deep learning plays a pivotal role in unlocking the potential of remote sensing data by delving deep into the semantic layers of scenes and extracting intricate features from images. Recent advancements in artificial intelligence have greatly enhanced this process. However, deep learning networks have limitations when applied to remote sensing images. 1) The huge number of parameters and the difficulty in training, as well as the over-reliance on labeled training data, can affect these images. Remote sensing images are characterized by “data miscellaneous marking difficulty”, which makes manual labeling insufficient for meeting the training needs of deep learning. 2) Variations in remote sensing platforms, sensors, shooting angles, resolution, time, location, and weather can all impact remote sensing images. Thus, the interpreted images and training samples cannot have the same distribution. This inconsistency results in weak generalization ability in existing models, especially when dealing with data from different distributions. To address this issue, cross-domain remote sensing scene interpretation aims to train a model on labeled remote sensing scene data (source domain) and apply it to new, unlabeled scene data (target domain) in an appropriate way. This approach reduces the dependence on target domain data and relaxes the assumption of the same distribution in existing deep learning tasks. The shallow layers of convolutional neural networks can be used as general-purpose feature extractors, but deeper layers are more task-specific and may introduce bias when applied to other tasks. Therefore, the migration model must be modified to accomplish the task of interpreting the target domain. Cross-domain interpretation tasks aim to establish a model that can adapt to various scene changes by utilizing migration learning, domain adaptation and other techniques for reducing model prediction inaccuracy caused by changes in the data domain. This approach improves the robustness and generalization ability of the model. Interpreting cross-domain remote sensing scenes typically requires using data from multiple remote sensing sources, including radar, aerial and satellite imagery. These images may have varying views, resolutions, wavelength bands, lighting conditions and noise levels. They may also originate from different locations or sensors. As the Global Earth Observation Systems continues to advance, remote sensing images now include cross-platform, cross-sensor, cross-resolution, and cross-region, which results in enormous distributional variances. Therefore, the study of cross-domain remote sensing scene interpretation is essential for the commercial use of remote sensing data and has theoretical and practical importance. This report categorizes scene decoding tasks into four main types based on the labeled set of data: methods based on closed-set domain adaptation, partial-domain adaptation, open-set domain adaptation and generalized domain adaptation. Approaches based on closed-set domain adaptation focus on tasks where the label set of the target domain is the same as that of the source domain. Partial domain adaptation focuses on tasks where the label set of the target domain is a subset of the source domain. Open-set domain adaptation aims to research tasks where the label set of the source domain is a subset of the label set of the target domain, and it does not apply restrictions in the approach of generalized domain adaptation. This study provides an in-depth investigation of two typical tasks in cross-domain remote sensing interpretation: scene recognition and target knowledge. The first part of the study utilizes domestic and international literature to provide a comprehensive assessment of the current research status of the four types of methods. Within the target recognition task, cross-domain tasks are further subdivided into cross-domain for visible light data and cross-domain from visible light to Synthetic Aperture Radar images. After a quantitative analysis of the sample distribution characteristics of different datasets, a unified experimental setup for cross-domain tasks is proposed. In the scene classification task, the dataset is explored by classifying it according to the label set categorization, and specific examples are given to provide the corresponding experimental setup for the readers’ reference. The fourth part of the study discusses the research trends in cross-domain remote sensing interpretation, which highlights four challenging research directions: few-shot learning, source domain data selection, multi-source domain interpretation, and cross-modal interpretation. These areas will be important directions for the future development of remote sensing scene interpretation, which offers potential choices for readers’ subsequent research directions.关键词:cross-domain remote sensing scene interpretation;out-of-distribution generalization;model generalization;diverse dataset;migration learning;adaptive algorithm
摘要:In remote sensing of Earth observation, multi-source data can be captured by multiple platforms, multiple sensors, and multiple perspectives. These data provide complementary information for interpreting remote sensing scenes. Although these data offer richer information, they also increase the demand for model depth and complexity. Deep learning plays a pivotal role in unlocking the potential of remote sensing data by delving deep into the semantic layers of scenes and extracting intricate features from images. Recent advancements in artificial intelligence have greatly enhanced this process. However, deep learning networks have limitations when applied to remote sensing images. 1) The huge number of parameters and the difficulty in training, as well as the over-reliance on labeled training data, can affect these images. Remote sensing images are characterized by “data miscellaneous marking difficulty”, which makes manual labeling insufficient for meeting the training needs of deep learning. 2) Variations in remote sensing platforms, sensors, shooting angles, resolution, time, location, and weather can all impact remote sensing images. Thus, the interpreted images and training samples cannot have the same distribution. This inconsistency results in weak generalization ability in existing models, especially when dealing with data from different distributions. To address this issue, cross-domain remote sensing scene interpretation aims to train a model on labeled remote sensing scene data (source domain) and apply it to new, unlabeled scene data (target domain) in an appropriate way. This approach reduces the dependence on target domain data and relaxes the assumption of the same distribution in existing deep learning tasks. The shallow layers of convolutional neural networks can be used as general-purpose feature extractors, but deeper layers are more task-specific and may introduce bias when applied to other tasks. Therefore, the migration model must be modified to accomplish the task of interpreting the target domain. Cross-domain interpretation tasks aim to establish a model that can adapt to various scene changes by utilizing migration learning, domain adaptation and other techniques for reducing model prediction inaccuracy caused by changes in the data domain. This approach improves the robustness and generalization ability of the model. Interpreting cross-domain remote sensing scenes typically requires using data from multiple remote sensing sources, including radar, aerial and satellite imagery. These images may have varying views, resolutions, wavelength bands, lighting conditions and noise levels. They may also originate from different locations or sensors. As the Global Earth Observation Systems continues to advance, remote sensing images now include cross-platform, cross-sensor, cross-resolution, and cross-region, which results in enormous distributional variances. Therefore, the study of cross-domain remote sensing scene interpretation is essential for the commercial use of remote sensing data and has theoretical and practical importance. This report categorizes scene decoding tasks into four main types based on the labeled set of data: methods based on closed-set domain adaptation, partial-domain adaptation, open-set domain adaptation and generalized domain adaptation. Approaches based on closed-set domain adaptation focus on tasks where the label set of the target domain is the same as that of the source domain. Partial domain adaptation focuses on tasks where the label set of the target domain is a subset of the source domain. Open-set domain adaptation aims to research tasks where the label set of the source domain is a subset of the label set of the target domain, and it does not apply restrictions in the approach of generalized domain adaptation. This study provides an in-depth investigation of two typical tasks in cross-domain remote sensing interpretation: scene recognition and target knowledge. The first part of the study utilizes domestic and international literature to provide a comprehensive assessment of the current research status of the four types of methods. Within the target recognition task, cross-domain tasks are further subdivided into cross-domain for visible light data and cross-domain from visible light to Synthetic Aperture Radar images. After a quantitative analysis of the sample distribution characteristics of different datasets, a unified experimental setup for cross-domain tasks is proposed. In the scene classification task, the dataset is explored by classifying it according to the label set categorization, and specific examples are given to provide the corresponding experimental setup for the readers’ reference. The fourth part of the study discusses the research trends in cross-domain remote sensing interpretation, which highlights four challenging research directions: few-shot learning, source domain data selection, multi-source domain interpretation, and cross-modal interpretation. These areas will be important directions for the future development of remote sensing scene interpretation, which offers potential choices for readers’ subsequent research directions.关键词:cross-domain remote sensing scene interpretation;out-of-distribution generalization;model generalization;diverse dataset;migration learning;adaptive algorithm- 6
- |
- 2
- |
- 0
发布时间:2024-06-27 -
 摘要:The core of 3D visual reasoning is to understand the relationships among different visual entities in point cloud scenes. Traditional 3D visual reasoning typically requires users to possess professional expertise. However, nonprofessional users face difficulty conveying their intentions to computers, which hinders the popularization and advancement of this technology. Users now anticipate a more convenient way to convey their intentions to the computer for achieving information exchange and gaining personalized results. Researchers utilize natural language as a semantic background or query criteria to reflect user intentions for addressing the aforementioned issue. They further accomplish various missions by interacting such natural language with 3D point clouds. By multimodal interaction, often employing techniques such as the Transformer or graph neural network, current approaches not only can locate the entities mentioned by users (e.g., visual grounding and open-vocabulary recognition) but also can generate user-required content (e.g., dense captioning, visual question answering, and scene generation). Specifically, 3D visual grounding is intended to locate desired objects or regions in the 3D point cloud scene based on the object-related linguistic query. Open-vocabulary 3D recognition aims to identify and localize 3D objects of novel classes defined by an unbounded (open) vocabulary at inference, which can generalize beyond the limited number of base classes labeled during the training phase. 3D dense captioning aims to identify all possible instances within the 3D point cloud scene and generate the corresponding natural language description for each instance. The goal of 3D visual question answering is to comprehend an entire 3D scene and provide an appropriate answer. Text-guided scene generation is to synthesize a realistic 3D scene composed of complex background and multiple objects from natural language descriptions. The aforementioned paradigm, which is known as 3D visual-language understanding, has gained significant traction in various fields, such as autonomous driving, robot navigation, and human-computer interaction, in recent years. Consequently, it has become a highly anticipated research direction within the computer vision domain. Over the past 3 years, 3D visual-language understanding technology has rapidly developed and showcased a blossoming trend. However, comprehensive summaries regarding the latest research progress remain lacking. Therefore, the necessary tasks are to systematically summarize recent studies, comprehensively evaluate the performance of different approaches, and prospectively point out future research directions. This situation motivates this survey to fill this gap. For this purpose, this study aims to focus on two of the most representative works of 3D visual-language understanding technologies and systematically summarizes their latest research advancements: anchor box prediction and content generation. First, the study provides an overview of the problem definition and existing challenges in 3D visual-language understanding, and it also outlines some common backbones used in this area. The challenges in 3D visual-language understanding include 3D-language alignment and complex scene understanding. Meanwhile, some common backbones involve priori rules, multilayer perceptrons, graph neural networks, and Transformer architectures. Subsequently, the study delves into downstream scenarios, which emphasize two types of 3D visual-language understanding techniques, including bounding box predation and content generation. This study thoroughly explores the advantages and disadvantages of each method. Furthermore, the study compares and analyzes the performance of various methods on different benchmark datasets. Finally, the study concludes by looking ahead to the future prospects of 3D visual-language reasoning technology, which can promote profound research and widespread application in this field. The major contributions of this study can be summarized as follows: 1) Systematic survey of 3D visual-language understanding. To the best of our knowledge, this survey is the first to thoroughly discuss the recent advances in 3D visual-language understanding. We categorize algorithms into different taxonomies from the perspective of downstream scenarios to provide readers with a clear comprehension of our article. 2) Comprehensive performance evaluation and analysis. We compare the existing 3D visual-language understanding approaches on several publicly available datasets. Our in-depth analysis can help researchers in selecting the baseline suitable for their specific applications while also offering valuable insights on the modification of existing methods. 3) Insightful discussion of future prospects. Based on the systematic survey and comprehensive performance comparison, some promising future research directions are discussed, including large-scale 3D foundation model, computational efficiency of 3D modeling, and incorporation of additional modalities.关键词:deep learning;computer vision;3D visual-language understanding;cross-modal learning;visual grounding;dense captioning;visual question answering;scene generation
摘要:The core of 3D visual reasoning is to understand the relationships among different visual entities in point cloud scenes. Traditional 3D visual reasoning typically requires users to possess professional expertise. However, nonprofessional users face difficulty conveying their intentions to computers, which hinders the popularization and advancement of this technology. Users now anticipate a more convenient way to convey their intentions to the computer for achieving information exchange and gaining personalized results. Researchers utilize natural language as a semantic background or query criteria to reflect user intentions for addressing the aforementioned issue. They further accomplish various missions by interacting such natural language with 3D point clouds. By multimodal interaction, often employing techniques such as the Transformer or graph neural network, current approaches not only can locate the entities mentioned by users (e.g., visual grounding and open-vocabulary recognition) but also can generate user-required content (e.g., dense captioning, visual question answering, and scene generation). Specifically, 3D visual grounding is intended to locate desired objects or regions in the 3D point cloud scene based on the object-related linguistic query. Open-vocabulary 3D recognition aims to identify and localize 3D objects of novel classes defined by an unbounded (open) vocabulary at inference, which can generalize beyond the limited number of base classes labeled during the training phase. 3D dense captioning aims to identify all possible instances within the 3D point cloud scene and generate the corresponding natural language description for each instance. The goal of 3D visual question answering is to comprehend an entire 3D scene and provide an appropriate answer. Text-guided scene generation is to synthesize a realistic 3D scene composed of complex background and multiple objects from natural language descriptions. The aforementioned paradigm, which is known as 3D visual-language understanding, has gained significant traction in various fields, such as autonomous driving, robot navigation, and human-computer interaction, in recent years. Consequently, it has become a highly anticipated research direction within the computer vision domain. Over the past 3 years, 3D visual-language understanding technology has rapidly developed and showcased a blossoming trend. However, comprehensive summaries regarding the latest research progress remain lacking. Therefore, the necessary tasks are to systematically summarize recent studies, comprehensively evaluate the performance of different approaches, and prospectively point out future research directions. This situation motivates this survey to fill this gap. For this purpose, this study aims to focus on two of the most representative works of 3D visual-language understanding technologies and systematically summarizes their latest research advancements: anchor box prediction and content generation. First, the study provides an overview of the problem definition and existing challenges in 3D visual-language understanding, and it also outlines some common backbones used in this area. The challenges in 3D visual-language understanding include 3D-language alignment and complex scene understanding. Meanwhile, some common backbones involve priori rules, multilayer perceptrons, graph neural networks, and Transformer architectures. Subsequently, the study delves into downstream scenarios, which emphasize two types of 3D visual-language understanding techniques, including bounding box predation and content generation. This study thoroughly explores the advantages and disadvantages of each method. Furthermore, the study compares and analyzes the performance of various methods on different benchmark datasets. Finally, the study concludes by looking ahead to the future prospects of 3D visual-language reasoning technology, which can promote profound research and widespread application in this field. The major contributions of this study can be summarized as follows: 1) Systematic survey of 3D visual-language understanding. To the best of our knowledge, this survey is the first to thoroughly discuss the recent advances in 3D visual-language understanding. We categorize algorithms into different taxonomies from the perspective of downstream scenarios to provide readers with a clear comprehension of our article. 2) Comprehensive performance evaluation and analysis. We compare the existing 3D visual-language understanding approaches on several publicly available datasets. Our in-depth analysis can help researchers in selecting the baseline suitable for their specific applications while also offering valuable insights on the modification of existing methods. 3) Insightful discussion of future prospects. Based on the systematic survey and comprehensive performance comparison, some promising future research directions are discussed, including large-scale 3D foundation model, computational efficiency of 3D modeling, and incorporation of additional modalities.关键词:deep learning;computer vision;3D visual-language understanding;cross-modal learning;visual grounding;dense captioning;visual question answering;scene generation- 5
- |
- 2
- |
- 0
发布时间:2024-06-27 -
 摘要:In the field of digital simulation technology applications, especially in the development of autonomous driving, object detection is a crucial component. It involves the perception of objects in the surrounding environment, which provides essential information for the decision-making process and planning of intelligent systems. Traditional object detection methods typically involve steps such as feature extraction, object classification, and position regression on images. However, these methods are limited by manually designed features and the performance of classifiers, which restrict their effectiveness in complex scenes and for objects with significant variations. The advent of deep learning technology has led to the widespread adoption of object detection methods based on deep neural networks. Notably, the convolutional neural network (CNN) has emerged as one of the most prominent approaches in this field. By leveraging multiple layers of convolution and pooling operations, CNNs are capable of automatically extracting meaningful feature representations from image data. In addition to image data, light detection and ranging (LiDAR) data play a crucial role in object detection tasks, particularly for 3D object detection. LiDAR data represent objects through a set of unordered and discrete points on their surfaces. Accurately detecting point cloud clusters representing objects and providing their pose estimation from these unordered points is a challenging task. LiDAR data, with their unique characteristics, offer high-precision obstacle detection and distance measurement, which contributes to the perception of surrounding roadways, vehicles, and pedestrian targets. In real-world autonomous driving and related environmental perception scenarios, using a single modality often presents numerous challenges. For instance, while image data can provide a wide variety of high-resolution visual information such as color, texture, and shape, it is susceptible to lighting conditions. In addition, models may struggle to handle occlusions caused by objects obstructing the view due to inherent limitations in camera perspectives. Fortunately, LiDAR exhibits exceptional performance in challenging lighting conditions and excels at accurately spatially locating objects in diverse and harsh weather scenarios. However, it possesses certain limitations. Specifically, the low resolution of LiDAR input data results in sparse point cloud when detecting distant targets. Extracting semantic information from LiDAR data is also more challenging than that from image data. Thus, an increasing number of researchers are emphasizing multimodal environmental object detection. A robust multimodal perception algorithm can offer richer feature information, enhanced adaptability to diverse environments, and improved detection accuracy. Such capabilities empower the perception system to deliver reliable results across various environmental conditions. Certainly, multimodal object detection algorithms also face certain limitations and pressing challenges that require immediate attention. One challenge is the difficulty in data annotation. Annotating point cloud and image data is relatively complex and time consuming, particularly for large-scale datasets. Moreover, accurately labeling point cloud data is challenging due to their sparsity and the presence of noisy points. Addressing these issues is crucial for further advancements in multimodal object detection. Moreover, the data structure and feature representation of point cloud and image data, as two distinct perception modalities, differ significantly. The current research focus lies in effectively integrating the information from the two modalities and extracting accurate and comprehensive features that can be utilized effectively. Furthermore, processing large-scale point cloud data are equally challenging. Point cloud data typically encompass a substantial number of 3D coordinates, which necessitates greater demands on computing resources and algorithmic efficiency compared with pure image data. This study aims to summarize and refine existing approaches to facilitate researchers in gaining a deeper and more efficient understanding of object detection algorithms that integrate images and point clouds. It classifies object detection algorithms based on multimodal fusion of point clouds, images, and combinations of both. Furthermore, we analyze the strengths and weaknesses of various methods while discussing potential solutions. Moreover, we provide a comprehensive review of the development of object detection algorithms that fuse point clouds and images, with considerations of aspects such as data collection, representation, and model design. Ultimately, we give a perspective on the future development direction of environmental target detection, and the goal is to enhance overall capabilities in autonomous systems.关键词:point cloud;autonomous driving;multimodal;object detection;fusion
摘要:In the field of digital simulation technology applications, especially in the development of autonomous driving, object detection is a crucial component. It involves the perception of objects in the surrounding environment, which provides essential information for the decision-making process and planning of intelligent systems. Traditional object detection methods typically involve steps such as feature extraction, object classification, and position regression on images. However, these methods are limited by manually designed features and the performance of classifiers, which restrict their effectiveness in complex scenes and for objects with significant variations. The advent of deep learning technology has led to the widespread adoption of object detection methods based on deep neural networks. Notably, the convolutional neural network (CNN) has emerged as one of the most prominent approaches in this field. By leveraging multiple layers of convolution and pooling operations, CNNs are capable of automatically extracting meaningful feature representations from image data. In addition to image data, light detection and ranging (LiDAR) data play a crucial role in object detection tasks, particularly for 3D object detection. LiDAR data represent objects through a set of unordered and discrete points on their surfaces. Accurately detecting point cloud clusters representing objects and providing their pose estimation from these unordered points is a challenging task. LiDAR data, with their unique characteristics, offer high-precision obstacle detection and distance measurement, which contributes to the perception of surrounding roadways, vehicles, and pedestrian targets. In real-world autonomous driving and related environmental perception scenarios, using a single modality often presents numerous challenges. For instance, while image data can provide a wide variety of high-resolution visual information such as color, texture, and shape, it is susceptible to lighting conditions. In addition, models may struggle to handle occlusions caused by objects obstructing the view due to inherent limitations in camera perspectives. Fortunately, LiDAR exhibits exceptional performance in challenging lighting conditions and excels at accurately spatially locating objects in diverse and harsh weather scenarios. However, it possesses certain limitations. Specifically, the low resolution of LiDAR input data results in sparse point cloud when detecting distant targets. Extracting semantic information from LiDAR data is also more challenging than that from image data. Thus, an increasing number of researchers are emphasizing multimodal environmental object detection. A robust multimodal perception algorithm can offer richer feature information, enhanced adaptability to diverse environments, and improved detection accuracy. Such capabilities empower the perception system to deliver reliable results across various environmental conditions. Certainly, multimodal object detection algorithms also face certain limitations and pressing challenges that require immediate attention. One challenge is the difficulty in data annotation. Annotating point cloud and image data is relatively complex and time consuming, particularly for large-scale datasets. Moreover, accurately labeling point cloud data is challenging due to their sparsity and the presence of noisy points. Addressing these issues is crucial for further advancements in multimodal object detection. Moreover, the data structure and feature representation of point cloud and image data, as two distinct perception modalities, differ significantly. The current research focus lies in effectively integrating the information from the two modalities and extracting accurate and comprehensive features that can be utilized effectively. Furthermore, processing large-scale point cloud data are equally challenging. Point cloud data typically encompass a substantial number of 3D coordinates, which necessitates greater demands on computing resources and algorithmic efficiency compared with pure image data. This study aims to summarize and refine existing approaches to facilitate researchers in gaining a deeper and more efficient understanding of object detection algorithms that integrate images and point clouds. It classifies object detection algorithms based on multimodal fusion of point clouds, images, and combinations of both. Furthermore, we analyze the strengths and weaknesses of various methods while discussing potential solutions. Moreover, we provide a comprehensive review of the development of object detection algorithms that fuse point clouds and images, with considerations of aspects such as data collection, representation, and model design. Ultimately, we give a perspective on the future development direction of environmental target detection, and the goal is to enhance overall capabilities in autonomous systems.关键词:point cloud;autonomous driving;multimodal;object detection;fusion- 4
- |
- 2
- |
- 0
发布时间:2024-06-27
Scene Recognition and Cross-modal Learning
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0