
最新刊期
卷 29 , 期 5 , 2024
-
 摘要:Semantic segmentation is a fundamental task in the field of computer vision, which aims to assign a category label to each pixel in the input image. Many semantic segmentation networks have complex structures, high computational costs, and massive parameters. As a result, they introduce considerable latency when performing pixel-level scene understanding on high-resolution images. These limitations greatly restrict the applicability of these methods in resource-constrained scenarios, such as autonomous driving, medical applications, and mobile devices. Therefore, real-time semantic segmentation methods, which produce high-precision segmentation masks with fast inference speeds, receive widespread attention. This study provides a systematic and critical review of real-time semantic segmentation algorithms based on deep learning techniques to explore the development of real-time semantic segmentation in recent years. Moreover, it covers three key aspects of real-time semantic segmentation: real-time semantic segmentation networks, mainstream datasets, and common evaluation indicators. In addition, this study conducts a quantitative evaluation of the real-time semantic segmentation methods discussed and provides some insights into the future development in this field. First, semantic segmentation and real-time semantic segmentation tasks and their application scenarios and challenges are introduced. The key challenge in real-time semantic segmentation mainly lies on how to extract high-quality semantic information with high efficiency. Second, some preliminary knowledge for studying real-time semantic segmentation algorithms is introduced in detail. Specifically, this study introduces four kinds of general model compression methods: network pruning, neural architecture search, knowledge distillation, and parameter quantification. It also introduces some popular efficient CNN modules in real-time semantic segmentation networks, such as MobileNet, ShuffleNet, EfficientNet, and efficient Transformer modules, such as external attention, SeaFormer, and MobileViT. Then, existing real-time semantic segmentation algorithms are organized and summarized. In accordance with the characteristics of the overall network structure, existing works are categorized into five categories: single-branch, two-branch, multibranch, U-shaped, and neural architecture search networks. Specifically, the encoder of a single-branch network is a single-branch hierarchical backbone network, and its decoder is usually lightweight and does not involve complex fusion of multiscale features. The two-branch network adopts a two-branch encoder structure, using one branch to capture spatial detail information and the other branch to model semantic context information. Multibranch networks are characterized by a multibranch structure in the encoder part of the network or a network with multiresolution inputs, where the input of each resolution passes through a different subnetwork. The U-shaped network has a contracting encoder and an expansive decoder, which are roughly symmetrical to the encoder. Most works of these aforementioned four categories are manually designed, while the neural architecture search networks are obtained using network architecture search technology based on the four types of architectures. These five categories of real-time semantic segmentation methods cover almost all real-time semantic segmentation algorithms based on deep learning, including CNN-based, Transformer-based, and hybrid-architecture-based segmentation networks. Moreover, commonly used datasets and evaluation indicators of accuracy, speed, and model size are introduced for real-time segmentation. We divided popular datasets into the autonomous driving scene and general scene datasets, and the evaluation indicators are divided into accuracy indicators and efficiency descriptors. In addition, this study quantitatively evaluates various real-time semantic segmentation algorithms mentioned on multiple datasets by using relevant evaluation indicators. To avoid the interference of different devices when conducting a quantitative comparison between real-time semantic segmentation algorithms, this study compares the performance of advanced methods of each category with the same devices and configuration and establishes a fair and integral real-time semantic segmentation evaluation system for subsequent research, thereby contributing to a unified standard for comparison. Finally, current challenges in real-time semantic segmentation are discussed, and possible future directions for improvements are envisioned (e.g., utilization of Transformers, applications on edge devices, knowledge transfer of visual foundation models, diversity of evaluation indicators, variety of datasets, utilization of multimodal data and weakly supervised methods, combination with incremental learning). The algorithms, datasets, and evaluation indicators mentioned in this paper are summarized at https://github.com/xzz777/Awesome-Real-time-Semantic-Segmentation for the convenience of subsequent researchers.关键词:real-time semantic segmentation;lightweight model design;efficient module design;computer vision;deep learning
摘要:Semantic segmentation is a fundamental task in the field of computer vision, which aims to assign a category label to each pixel in the input image. Many semantic segmentation networks have complex structures, high computational costs, and massive parameters. As a result, they introduce considerable latency when performing pixel-level scene understanding on high-resolution images. These limitations greatly restrict the applicability of these methods in resource-constrained scenarios, such as autonomous driving, medical applications, and mobile devices. Therefore, real-time semantic segmentation methods, which produce high-precision segmentation masks with fast inference speeds, receive widespread attention. This study provides a systematic and critical review of real-time semantic segmentation algorithms based on deep learning techniques to explore the development of real-time semantic segmentation in recent years. Moreover, it covers three key aspects of real-time semantic segmentation: real-time semantic segmentation networks, mainstream datasets, and common evaluation indicators. In addition, this study conducts a quantitative evaluation of the real-time semantic segmentation methods discussed and provides some insights into the future development in this field. First, semantic segmentation and real-time semantic segmentation tasks and their application scenarios and challenges are introduced. The key challenge in real-time semantic segmentation mainly lies on how to extract high-quality semantic information with high efficiency. Second, some preliminary knowledge for studying real-time semantic segmentation algorithms is introduced in detail. Specifically, this study introduces four kinds of general model compression methods: network pruning, neural architecture search, knowledge distillation, and parameter quantification. It also introduces some popular efficient CNN modules in real-time semantic segmentation networks, such as MobileNet, ShuffleNet, EfficientNet, and efficient Transformer modules, such as external attention, SeaFormer, and MobileViT. Then, existing real-time semantic segmentation algorithms are organized and summarized. In accordance with the characteristics of the overall network structure, existing works are categorized into five categories: single-branch, two-branch, multibranch, U-shaped, and neural architecture search networks. Specifically, the encoder of a single-branch network is a single-branch hierarchical backbone network, and its decoder is usually lightweight and does not involve complex fusion of multiscale features. The two-branch network adopts a two-branch encoder structure, using one branch to capture spatial detail information and the other branch to model semantic context information. Multibranch networks are characterized by a multibranch structure in the encoder part of the network or a network with multiresolution inputs, where the input of each resolution passes through a different subnetwork. The U-shaped network has a contracting encoder and an expansive decoder, which are roughly symmetrical to the encoder. Most works of these aforementioned four categories are manually designed, while the neural architecture search networks are obtained using network architecture search technology based on the four types of architectures. These five categories of real-time semantic segmentation methods cover almost all real-time semantic segmentation algorithms based on deep learning, including CNN-based, Transformer-based, and hybrid-architecture-based segmentation networks. Moreover, commonly used datasets and evaluation indicators of accuracy, speed, and model size are introduced for real-time segmentation. We divided popular datasets into the autonomous driving scene and general scene datasets, and the evaluation indicators are divided into accuracy indicators and efficiency descriptors. In addition, this study quantitatively evaluates various real-time semantic segmentation algorithms mentioned on multiple datasets by using relevant evaluation indicators. To avoid the interference of different devices when conducting a quantitative comparison between real-time semantic segmentation algorithms, this study compares the performance of advanced methods of each category with the same devices and configuration and establishes a fair and integral real-time semantic segmentation evaluation system for subsequent research, thereby contributing to a unified standard for comparison. Finally, current challenges in real-time semantic segmentation are discussed, and possible future directions for improvements are envisioned (e.g., utilization of Transformers, applications on edge devices, knowledge transfer of visual foundation models, diversity of evaluation indicators, variety of datasets, utilization of multimodal data and weakly supervised methods, combination with incremental learning). The algorithms, datasets, and evaluation indicators mentioned in this paper are summarized at https://github.com/xzz777/Awesome-Real-time-Semantic-Segmentation for the convenience of subsequent researchers.关键词:real-time semantic segmentation;lightweight model design;efficient module design;computer vision;deep learning- 40
- |
- 7
- |
- 0
发布时间:2024-05-15 -
 摘要:Semantic segmentation is an important and fundamental task in the field of computer vision. Its goal is to assign a semantic category label to each pixel in an image, achieving pixel-level understanding. It has wide applications in areas, such as autonomous driving, virtual reality, and medical image analysis. Given the development of deep learning in recent years, remarkable progress has been achieved in fully supervised semantic segmentation, which requires a large amount of training data with pixel-level annotations. However, accurate pixel-level annotations are difficult to provide because it sacrifices substantial time, money, and human-label resources, thus limiting their widespread application in reality. To reduce the cost of annotating data and further expand the application scenarios of semantic segmentation, researchers are paying increasing attention to weakly supervised semantic segmentation (WSSS) based on deep learning. The goal is to develop a semantic segmentation model that utilizes weak annotations information instead of dense pixel-level annotations to predict pixel-level segmentation accurately. Weak annotations mainly include image-level, bounding-box, scribble, and point annotations. The key problem in WSSS lies in how to find a way to utilize the limited annotation information, incorporate appropriate training strategies, and design powerful models to bridge the gap between weak supervision and pixel-level annotations. This study aims to classify and summarize WSSS methods based on deep learning, analyze the challenges and problems encountered by recent methods, and provide insights into future research directions. First, we introduce WSSS as a solution to the limitations of fully supervised semantic segmentation. Second, we introduce the related datasets and evaluation metrics. Third, we review and discuss the research progress of WSSS from three categories: image-level annotations, other weak annotations, and assistance from large-scale models, where the second category includes bounding-box, scribble, and point annotations. Specifically, image-level annotations only provide object categories information contained in the image, without specifying the positions of the target objects. Existing methods always follow a two-stage training process: producing a class activation map (CAM), also known as initial seed regions used to generate high-quality pixel-level pseudo labels; and training a fully supervised semantic segmentation model using the produced pixel-level pseudo labels. According to whether the pixel-level pseudo labels are updated or not during the training process in the second stage, WSSS based on image-level annotations can be further divided into offline and online approaches. For offline approaches, existing research treats two stages independently, where the initial seed regions are optimized to obtain more reliable pixel-level pseudo labels that remain unchanged throughout the second stage. They are often divided into six classes according to different optimization strategies, including the ensemble of CAM, image erasing, co-occurrence relationship decoupling, affinity propagation, additional supervised information, and self-supervised learning. For online approaches, the pixel-level pseudo labels keep updating during the entire training process in the second stage. The production of pixel-level pseudo labels and the semantic segmentation model are jointly optimized. The online counterparts can be trained end to end, making the training process more efficient. Compared with image-level annotations, other weak annotations, including bounding box, scribble, and point, are more powerful supervised signals. Among them, bounding-box annotations not only provide object category labels but also include information of object positions. The regions outside the bounding-box are always considered background, while box regions simultaneously contain foreground and background areas. Therefore, for bounding-box annotations, existing research mainly starts from accurately distinguishing foreground areas from background regions within the bounding-box, thereby producing more accurate pixel-level pseudo labels, used for training following semantic segmentation networks. Scribble and point annotations not only indicate the categories of objects contained in the image but also provide local positional information of the target objects. For scribble annotations, more complete pseudo labels can be produced to supervise semantic segmentation by inferring the category of unlabeled regions from the annotated scribble. For point annotations, the associated semantic information is expanded to the entire image through label propagation, distance metric learning, and loss function optimization. In addition, with the rapid development of large-scale models, this paper further discusses the recent research achievements in using large-scale models to assist WSSS tasks. Large-scale models can leverage their pretrained universal knowledge to understand images and generate accurate pixel-level pseudo labels, thus improving the final segmentation performance. This paper also reports the quantitative segmentation results on pattern analysis, statistical modeling and computational learning visual object classes 2012(PASCAL VOC 2012) dataset to evaluate the performance of different WSSS methods. Finally, four challenges and potential future research directions are provided. First, a certain performance gap remains between weakly supervised and fully supervised methods. To bridge this gap, research should keep on improving the accuracy of pixel-level pseudo labels. Second, when WSSS models are applied to real-world scenarios, they may encounter object categories that have never appeared in the training data. This encounter requires the models to have a certain adaptability to identify and segment unknown objects. Third, existing research mainly focuses on improving the accuracy without considering the model size and inference speed of WSSS networks, posing a major challenge for the deployment of the model in real-world applications that require real-time estimations and online decisions. Fourth, the scarcity of relevant datasets used to evaluate different WSSS models and algorithms is also a major obstacle, which leads to performance degradation and limits generalization capability. Therefore, large-scale WSSS datasets with high quality, great diversity, and wide variation of image types must be constructed.关键词:semantic segmentation;deep learning;weakly supervised semantic segmentation (WSSS);image-level annotation;bounding-box annotation;scribble annotation;point annotation;large-scale model
摘要:Semantic segmentation is an important and fundamental task in the field of computer vision. Its goal is to assign a semantic category label to each pixel in an image, achieving pixel-level understanding. It has wide applications in areas, such as autonomous driving, virtual reality, and medical image analysis. Given the development of deep learning in recent years, remarkable progress has been achieved in fully supervised semantic segmentation, which requires a large amount of training data with pixel-level annotations. However, accurate pixel-level annotations are difficult to provide because it sacrifices substantial time, money, and human-label resources, thus limiting their widespread application in reality. To reduce the cost of annotating data and further expand the application scenarios of semantic segmentation, researchers are paying increasing attention to weakly supervised semantic segmentation (WSSS) based on deep learning. The goal is to develop a semantic segmentation model that utilizes weak annotations information instead of dense pixel-level annotations to predict pixel-level segmentation accurately. Weak annotations mainly include image-level, bounding-box, scribble, and point annotations. The key problem in WSSS lies in how to find a way to utilize the limited annotation information, incorporate appropriate training strategies, and design powerful models to bridge the gap between weak supervision and pixel-level annotations. This study aims to classify and summarize WSSS methods based on deep learning, analyze the challenges and problems encountered by recent methods, and provide insights into future research directions. First, we introduce WSSS as a solution to the limitations of fully supervised semantic segmentation. Second, we introduce the related datasets and evaluation metrics. Third, we review and discuss the research progress of WSSS from three categories: image-level annotations, other weak annotations, and assistance from large-scale models, where the second category includes bounding-box, scribble, and point annotations. Specifically, image-level annotations only provide object categories information contained in the image, without specifying the positions of the target objects. Existing methods always follow a two-stage training process: producing a class activation map (CAM), also known as initial seed regions used to generate high-quality pixel-level pseudo labels; and training a fully supervised semantic segmentation model using the produced pixel-level pseudo labels. According to whether the pixel-level pseudo labels are updated or not during the training process in the second stage, WSSS based on image-level annotations can be further divided into offline and online approaches. For offline approaches, existing research treats two stages independently, where the initial seed regions are optimized to obtain more reliable pixel-level pseudo labels that remain unchanged throughout the second stage. They are often divided into six classes according to different optimization strategies, including the ensemble of CAM, image erasing, co-occurrence relationship decoupling, affinity propagation, additional supervised information, and self-supervised learning. For online approaches, the pixel-level pseudo labels keep updating during the entire training process in the second stage. The production of pixel-level pseudo labels and the semantic segmentation model are jointly optimized. The online counterparts can be trained end to end, making the training process more efficient. Compared with image-level annotations, other weak annotations, including bounding box, scribble, and point, are more powerful supervised signals. Among them, bounding-box annotations not only provide object category labels but also include information of object positions. The regions outside the bounding-box are always considered background, while box regions simultaneously contain foreground and background areas. Therefore, for bounding-box annotations, existing research mainly starts from accurately distinguishing foreground areas from background regions within the bounding-box, thereby producing more accurate pixel-level pseudo labels, used for training following semantic segmentation networks. Scribble and point annotations not only indicate the categories of objects contained in the image but also provide local positional information of the target objects. For scribble annotations, more complete pseudo labels can be produced to supervise semantic segmentation by inferring the category of unlabeled regions from the annotated scribble. For point annotations, the associated semantic information is expanded to the entire image through label propagation, distance metric learning, and loss function optimization. In addition, with the rapid development of large-scale models, this paper further discusses the recent research achievements in using large-scale models to assist WSSS tasks. Large-scale models can leverage their pretrained universal knowledge to understand images and generate accurate pixel-level pseudo labels, thus improving the final segmentation performance. This paper also reports the quantitative segmentation results on pattern analysis, statistical modeling and computational learning visual object classes 2012(PASCAL VOC 2012) dataset to evaluate the performance of different WSSS methods. Finally, four challenges and potential future research directions are provided. First, a certain performance gap remains between weakly supervised and fully supervised methods. To bridge this gap, research should keep on improving the accuracy of pixel-level pseudo labels. Second, when WSSS models are applied to real-world scenarios, they may encounter object categories that have never appeared in the training data. This encounter requires the models to have a certain adaptability to identify and segment unknown objects. Third, existing research mainly focuses on improving the accuracy without considering the model size and inference speed of WSSS networks, posing a major challenge for the deployment of the model in real-world applications that require real-time estimations and online decisions. Fourth, the scarcity of relevant datasets used to evaluate different WSSS models and algorithms is also a major obstacle, which leads to performance degradation and limits generalization capability. Therefore, large-scale WSSS datasets with high quality, great diversity, and wide variation of image types must be constructed.关键词:semantic segmentation;deep learning;weakly supervised semantic segmentation (WSSS);image-level annotation;bounding-box annotation;scribble annotation;point annotation;large-scale model- 14
- |
- 3
- |
- 0
发布时间:2024-05-15 -
 摘要:As a key technology for 3D perception in the autonomous driving domain, pure camera-based bird’s-eye-view (BEV) perception aims to generate a top-down view representation of the surrounding traffic environment using only 2D image information captured by cameras. In recent years, it has gained considerable attention in the computer vision research community. The potential of BEV is immense because it can represent image features from multiple camera viewpoints in a unified space and provide explicit position and size information of the target object. While most BEV methods focus on developing perception methods on ego-vehicle sensors, people have gradually realized the importance of using intelligent roadside cameras to extend the perception ability beyond the visual range in recent years. However, this novel and growing research field has not been reviewed recently. This paper presents a comprehensive review of pure camera-based BEV perception technology based on camera deployment and camera angle, which are segmented into three categories: 1) vehicle-side single-view perception, 2) vehicle-side surround-view perception, and 3) infrastructure-side fixed-view perception. Meanwhile, the typical processing flow, which contains three primary parts: dataset input, BEV model, and task inference output, is introduced. In the task inference output section, four typical tasks in the 3D perception of autonomous driving (i.e., 3D object detection, 3D lane detection, BEV map segmentation, and high-definition map generation) are described in detail. For supporting convenient retrieval, this study summarizes the supported tasks and official links for various datasets and provides open-source code links for representative BEV models in a table format. Simultaneously, the performance of various BEV models on public datasets is analyzed and compared. To our best knowledge, three types of BEV challenging problems must be resolved: 1) scene uncertainty problems: In an open-road scenario, many scenes never appear in the training dataset. These scenarios can include extreme weather conditions, such as dark nights, strong winds, heavy rain, and thick fog. A model’s reliability must not degrade in these unusual circumstances. However, majority of BEV models tend to suffer from considerable performance degradation when exposed to varying road scenarios. 2) Scale uncertainty problems: autonomous driving perception tasks have many extreme scale targets. For example, in a roadside scenario, placing a camera on a traffic signal or streetlight pole at least 3 m above the ground can help detect farther targets. However, facing the extremely small scale of the distant targets, existing BEV models have serious issues with false and missed detections. 3) Camera parameter sensitivity problems: most existing BEV models depend on precisely calibrated intrinsic and extrinsic camera parameters for their success during training and evaluation. The performance of these methods drastically diminishes if noisy extrinsic camera parameters are utilized or unseen intrinsic camera parameters are inputted. Meanwhile, a comprehensive outlook on the development of pure camera-based BEV perception is given: 1) vehicle-to-infrastructure (V2I) cooperation: V2I cooperation refers to the integration of information from vehicle-side and infrastructure-side to achieve the visual perception tasks of autonomous driving under communication bandwidth constraints. The design and implementation of a vehicle-infrastructure integration perception algorithm can lead to remarkable benefits, such as supplementing blind spots, expanding the field of view, and improving perception accuracy. 2) Vehicle-to-vehicle (V2V) cooperation: V2V cooperation means that connected autonomous vehicles (CAVs) can share the collected data with each other under communication bandwidth constraints. CAVs can collaborate to compensate for the shortage of data and expand view for vehicles in need, thereby augmenting perception capabilities, boosting detection accuracy, and improving driving safety. 3) Multitask learning: the purpose of multitask learning is to optimize multiple tasks at the same time to improve the efficiency and performance of algorithms, simplifying the complexity of models. In BEV models, the generated BEV features are friendly to many downstream tasks, such as 3D object detection and BEV map segmentation. Sharing models can largely increase the parameter sharing rate, save computing costs, reduce training time, and improve model generalization performance. The objective of these endeavors is to provide a comprehensive guide and reference for researchers in related fields by thoroughly summarizing and analyzing existing research and future trends in the field of pure camera-based BEV perception.关键词:autonomous driving perception;pure camera-based BEV perception;infrastructure-side perception;vehicle-side perception;multi-view image fusion
摘要:As a key technology for 3D perception in the autonomous driving domain, pure camera-based bird’s-eye-view (BEV) perception aims to generate a top-down view representation of the surrounding traffic environment using only 2D image information captured by cameras. In recent years, it has gained considerable attention in the computer vision research community. The potential of BEV is immense because it can represent image features from multiple camera viewpoints in a unified space and provide explicit position and size information of the target object. While most BEV methods focus on developing perception methods on ego-vehicle sensors, people have gradually realized the importance of using intelligent roadside cameras to extend the perception ability beyond the visual range in recent years. However, this novel and growing research field has not been reviewed recently. This paper presents a comprehensive review of pure camera-based BEV perception technology based on camera deployment and camera angle, which are segmented into three categories: 1) vehicle-side single-view perception, 2) vehicle-side surround-view perception, and 3) infrastructure-side fixed-view perception. Meanwhile, the typical processing flow, which contains three primary parts: dataset input, BEV model, and task inference output, is introduced. In the task inference output section, four typical tasks in the 3D perception of autonomous driving (i.e., 3D object detection, 3D lane detection, BEV map segmentation, and high-definition map generation) are described in detail. For supporting convenient retrieval, this study summarizes the supported tasks and official links for various datasets and provides open-source code links for representative BEV models in a table format. Simultaneously, the performance of various BEV models on public datasets is analyzed and compared. To our best knowledge, three types of BEV challenging problems must be resolved: 1) scene uncertainty problems: In an open-road scenario, many scenes never appear in the training dataset. These scenarios can include extreme weather conditions, such as dark nights, strong winds, heavy rain, and thick fog. A model’s reliability must not degrade in these unusual circumstances. However, majority of BEV models tend to suffer from considerable performance degradation when exposed to varying road scenarios. 2) Scale uncertainty problems: autonomous driving perception tasks have many extreme scale targets. For example, in a roadside scenario, placing a camera on a traffic signal or streetlight pole at least 3 m above the ground can help detect farther targets. However, facing the extremely small scale of the distant targets, existing BEV models have serious issues with false and missed detections. 3) Camera parameter sensitivity problems: most existing BEV models depend on precisely calibrated intrinsic and extrinsic camera parameters for their success during training and evaluation. The performance of these methods drastically diminishes if noisy extrinsic camera parameters are utilized or unseen intrinsic camera parameters are inputted. Meanwhile, a comprehensive outlook on the development of pure camera-based BEV perception is given: 1) vehicle-to-infrastructure (V2I) cooperation: V2I cooperation refers to the integration of information from vehicle-side and infrastructure-side to achieve the visual perception tasks of autonomous driving under communication bandwidth constraints. The design and implementation of a vehicle-infrastructure integration perception algorithm can lead to remarkable benefits, such as supplementing blind spots, expanding the field of view, and improving perception accuracy. 2) Vehicle-to-vehicle (V2V) cooperation: V2V cooperation means that connected autonomous vehicles (CAVs) can share the collected data with each other under communication bandwidth constraints. CAVs can collaborate to compensate for the shortage of data and expand view for vehicles in need, thereby augmenting perception capabilities, boosting detection accuracy, and improving driving safety. 3) Multitask learning: the purpose of multitask learning is to optimize multiple tasks at the same time to improve the efficiency and performance of algorithms, simplifying the complexity of models. In BEV models, the generated BEV features are friendly to many downstream tasks, such as 3D object detection and BEV map segmentation. Sharing models can largely increase the parameter sharing rate, save computing costs, reduce training time, and improve model generalization performance. The objective of these endeavors is to provide a comprehensive guide and reference for researchers in related fields by thoroughly summarizing and analyzing existing research and future trends in the field of pure camera-based BEV perception.关键词:autonomous driving perception;pure camera-based BEV perception;infrastructure-side perception;vehicle-side perception;multi-view image fusion- 7
- |
- 0
- |
- 0
发布时间:2024-05-15 -
 摘要:Semantic segmentation is widely used as an important research direction in the field of computer vision, and its purpose is to classify the input image at the pixel level according to predefined categories. Real-time semantic segmentation, as a subfield of semantic segmentation, adds speed requirements to segmentation methods on the basis of general semantic segmentation and is widely used in fields, such as unmanned driving, medical image analysis, video surveillance, and aerial images. The segmentation method should achieve not only high segmentation accuracy but also fast segmentation speed (specifically, the speed of processing images per unit time reaches 30 frames). With the rapid development of deep learning technology and neural networks, real-time semantic segmentation has also achieved certain research results. Majority of previous researchers have discussed semantic segmentation, but review papers on real-time semantic segmentation methods are few. In this paper, we systematically summarize the real-time semantic segmentation algorithms based on deep learning on the basis of the existing work of the previous researchers. We first introduce the concept of real-time semantic segmentation, and then, according to the number and quality of the participating training labels, the existing real-time semantic segmentation methods based on deep learning are categorized into three classes: strongly supervised learning, weakly supervised learning, and unsupervised learning. Strongly supervised learning methods are categorized from three perspectives: improving accuracy, improving speed, and other methods. Accuracy improvement methods are further divided into subcategories according to the network structure and feature fusion methods. According to the network structure, the real-time semantic segmentation methods can be categorized into encoder-decoder structure, two-branch structure, and multibranch structure; the representative networks in the encoder-decoder section are fully convolutional network (FCN) and UNet; the networks with two-branch structure are the BiSeNet series; and the multibranch structure has ICNet and DFANet. According to the different ways of feature fusion, real-time semantic segmentation methods can be categorized into multiscale feature fusion and attention mechanism. According to the different ways of feature sampling in the process of multiscale feature fusion, this study divides multiscale feature fusion into atrous spatial pyramid pooling and ordinary pyramid pooling; the attention mechanism can be further divided into self-attention mechanism, channel attention, and spatial attention according to the computation method of the attention vector. The methods to improve the speed are analyzed and discussed from the perspectives of improving convolutional blocks and lightweight networks; the methods to improve convolutional blocks can be divided into separable convolution (separable convolution can be divided into depth separable convolution and spatial separable convolution), grouped convolution, and atrous convolution. Among other methods of strongly supervised learning, we also specifically add methods of knowledge distillation, Transformer-based methods, and pruning, which are less mentioned in other literatures. Given the numerous methods for real-time semantic segmentation based on strongly supervised learning, we also perform a comparative analysis of the strengths and weaknesses of all the mentioned methods. Real-time semantic segmentation based on weakly supervised learning is classified into methods based on image-level labeling, methods based on point labeling, methods based on object box labeling, and methods based on object underlining labeling. The concept of unsupervised learning is introduced, and the commonly used unsupervised semantic segmentation methods at the present stage are described, including the method with the introduction of the generalized domain adaptation problem and the method with the introduction of unsupervised pre-adaptation task. Subsequently, the datasets and evaluation indexes commonly used in real-time semantic segmentation are introduced. In addition to the street scene dataset commonly used in unmanned counting, this study supplements the medical image dataset. In the evaluation indexes, this study provides a detailed introduction to the accuracy measure and speed measure and then compares the experimental effects of the algorithms on the datasets so far through the table to obtain the latest research progress in the field. The application scenarios of real-time semantic segmentation are further elaborated in detail. Real-time semantic segmentation can be applied to automatic driving, which can segment road scene images in a short time to help identify roads, traffic signs, pedestrians, vehicles, and other objects. By segmenting medical images at the pixel level, real-time semantic segmentation can also help doctors identify and localize lesion areas accurately. In the field of natural disaster monitoring and emergency rescue, real-time semantic segmentation can quickly identify airplanes and aircrafts and can help doctors identify and locate lesion areas accurately. Real-time semantic segmentation can quickly recognize disaster areas in aerial images; real-time segmentation of scenes and objects in surveillance videos can provide accurate and intelligent data for surveillance systems. Then, according to the specific application scenarios of real-time semantic segmentation and the problems encountered at this stage, this study considers that the challenges faced by real-time semantic segmentation include the following: 1) mobile segmentation problem, which hardly develops large-scale computation on low-storage devices; 2) how to get away from the dependence of efficient networks on hardware devices; 3) experimental accuracy of the current real-time semantic segmentation model, which hardly reaches the standard of automatic driving; 4) lack of scene data for medical image and 3D point cloud design. Finally, this study gives an outlook on the future directions of real-time semantic segmentation that are worth researching, e.g., occlusion segmentation, real-time semantic segmentation of small targets, adaptive learning model, cross-modal joint learning, data-centered real-time semantic segmentation, and small-sample real-time semantic segmentation.关键词:semantic segmentation(SS);real-time semantic segmentation;deep learning;attention;convolution
摘要:Semantic segmentation is widely used as an important research direction in the field of computer vision, and its purpose is to classify the input image at the pixel level according to predefined categories. Real-time semantic segmentation, as a subfield of semantic segmentation, adds speed requirements to segmentation methods on the basis of general semantic segmentation and is widely used in fields, such as unmanned driving, medical image analysis, video surveillance, and aerial images. The segmentation method should achieve not only high segmentation accuracy but also fast segmentation speed (specifically, the speed of processing images per unit time reaches 30 frames). With the rapid development of deep learning technology and neural networks, real-time semantic segmentation has also achieved certain research results. Majority of previous researchers have discussed semantic segmentation, but review papers on real-time semantic segmentation methods are few. In this paper, we systematically summarize the real-time semantic segmentation algorithms based on deep learning on the basis of the existing work of the previous researchers. We first introduce the concept of real-time semantic segmentation, and then, according to the number and quality of the participating training labels, the existing real-time semantic segmentation methods based on deep learning are categorized into three classes: strongly supervised learning, weakly supervised learning, and unsupervised learning. Strongly supervised learning methods are categorized from three perspectives: improving accuracy, improving speed, and other methods. Accuracy improvement methods are further divided into subcategories according to the network structure and feature fusion methods. According to the network structure, the real-time semantic segmentation methods can be categorized into encoder-decoder structure, two-branch structure, and multibranch structure; the representative networks in the encoder-decoder section are fully convolutional network (FCN) and UNet; the networks with two-branch structure are the BiSeNet series; and the multibranch structure has ICNet and DFANet. According to the different ways of feature fusion, real-time semantic segmentation methods can be categorized into multiscale feature fusion and attention mechanism. According to the different ways of feature sampling in the process of multiscale feature fusion, this study divides multiscale feature fusion into atrous spatial pyramid pooling and ordinary pyramid pooling; the attention mechanism can be further divided into self-attention mechanism, channel attention, and spatial attention according to the computation method of the attention vector. The methods to improve the speed are analyzed and discussed from the perspectives of improving convolutional blocks and lightweight networks; the methods to improve convolutional blocks can be divided into separable convolution (separable convolution can be divided into depth separable convolution and spatial separable convolution), grouped convolution, and atrous convolution. Among other methods of strongly supervised learning, we also specifically add methods of knowledge distillation, Transformer-based methods, and pruning, which are less mentioned in other literatures. Given the numerous methods for real-time semantic segmentation based on strongly supervised learning, we also perform a comparative analysis of the strengths and weaknesses of all the mentioned methods. Real-time semantic segmentation based on weakly supervised learning is classified into methods based on image-level labeling, methods based on point labeling, methods based on object box labeling, and methods based on object underlining labeling. The concept of unsupervised learning is introduced, and the commonly used unsupervised semantic segmentation methods at the present stage are described, including the method with the introduction of the generalized domain adaptation problem and the method with the introduction of unsupervised pre-adaptation task. Subsequently, the datasets and evaluation indexes commonly used in real-time semantic segmentation are introduced. In addition to the street scene dataset commonly used in unmanned counting, this study supplements the medical image dataset. In the evaluation indexes, this study provides a detailed introduction to the accuracy measure and speed measure and then compares the experimental effects of the algorithms on the datasets so far through the table to obtain the latest research progress in the field. The application scenarios of real-time semantic segmentation are further elaborated in detail. Real-time semantic segmentation can be applied to automatic driving, which can segment road scene images in a short time to help identify roads, traffic signs, pedestrians, vehicles, and other objects. By segmenting medical images at the pixel level, real-time semantic segmentation can also help doctors identify and localize lesion areas accurately. In the field of natural disaster monitoring and emergency rescue, real-time semantic segmentation can quickly identify airplanes and aircrafts and can help doctors identify and locate lesion areas accurately. Real-time semantic segmentation can quickly recognize disaster areas in aerial images; real-time segmentation of scenes and objects in surveillance videos can provide accurate and intelligent data for surveillance systems. Then, according to the specific application scenarios of real-time semantic segmentation and the problems encountered at this stage, this study considers that the challenges faced by real-time semantic segmentation include the following: 1) mobile segmentation problem, which hardly develops large-scale computation on low-storage devices; 2) how to get away from the dependence of efficient networks on hardware devices; 3) experimental accuracy of the current real-time semantic segmentation model, which hardly reaches the standard of automatic driving; 4) lack of scene data for medical image and 3D point cloud design. Finally, this study gives an outlook on the future directions of real-time semantic segmentation that are worth researching, e.g., occlusion segmentation, real-time semantic segmentation of small targets, adaptive learning model, cross-modal joint learning, data-centered real-time semantic segmentation, and small-sample real-time semantic segmentation.关键词:semantic segmentation(SS);real-time semantic segmentation;deep learning;attention;convolution- 8
- |
- 2
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveInstance segmentation is a popular topic in image processing and computer vision. It is widely used in unmanned driving, medical image segmentation, and other fields. The high overlap between objects in practical application scenarios makes instance segmentation more challenging. Instance segmentation models include two-stage and single-stage models. In a two-stage instance segmentation model, the two-layer instance segmentation network (i.e., bilayer convolutional network (BCNet) is one of the most successful networks in the field of occlusion object instance segmentation. In contrast with previous two-stage instance segmentation methods, BCNet extracts regions of interest (RoI) and simultaneously regresses the occluder and occludee regions, grouping pixels that belong to the occluder region and treating them as pixels in the occludee region, but dividing them into two independent image layers. Consequently, the boundaries of the two objects are naturally decoupled, considering the interaction between them during the mask regression phase. Thus, a two-layer convolutional network is proposed, in which the top graph convolutional network (GCN) layer detects occluder objects while the bottom GCN layer infers occludee instances. The explicit modeling of occlusion relationships on the basis of a two-layer structure naturally decouples the boundaries of occluder and occludee instances, and considers the interaction between them in mask regression. BCNet proposes a new structure for highly overlapping objects in segmentation scenes. The segmentation performance of occluded object instances is closely related to the prediction results of object contours. However, the current algorithm’s predicted object contours are not sufficiently refined, resulting in rough segmentation masks and poor object boundary segmentation performance. Therefore, this study presents a contour refinement instance segmentation method for occluded objects based on BCNet. The predicted object contour is more precise, and the segmentation mask is more complete.MethodSimple average pooling causes the loss of a significant amount of feature information and cannot generate more detailed feature information, while maximum pooling can retain more significant feature information. On this basis, the study proposes a balance pooling attention module. Global context information is collected in the form of 1D maximum pooling and 1D average pooling in parallel. The proportion of maximum pooling and average pooling is balanced through weighted feature fusion to generate more detailed information without losing overall features. The balance pooling attention module is added to ResNet to enable the feature extraction stage to extract features with more details. Features at different scales contain different feature information. High-resolution features contain more detailed information, while low-resolution features contain richer semantic information. In contrast with the input for the mask head in BCNet, this study separates the contour prediction branch from the mask prediction branch and adopts different feature inputs, extracting region of interest (RoI) features from the highest resolution features in a feature pyramid network (FPN) as features for the contour prediction branch and RoI features from the cascaded low-resolution features as input for the mask prediction branch. The features of the contour prediction branch have more detailed and spatial information, and the mask prediction branch has more abundant semantic information. To improve the segmentation effect further, the adaptive feature fusion module is proposed to fuse the features in the contour prediction branch with the features in the mask prediction branch. In the contour prediction branch, the features of the fused mask prediction branch can better determine the object category to which the contour belongs. In the mask prediction branch, the features of the fused contour prediction branch can better assist in mask positioning. The criss-cross attention module is used to infer the contours and masks of the occluder and occludee objects. It can maintain prediction accuracy and effectively reduce computational complexity compared with the non-local operator structure GCN module adopted in BCNet.ResultSegmentation accuracy is compared with classic instance segmentation models, such as mask region-based convolutional neural network(Mask R-CNN), CenterMask, and BCNet, on the common objects in context(COCO) 2017 validation set. Compared with the baseline network BCNet, average precision(AP) increases by 1.7% and 2.1% when the backbone network is ResNet-50 and ResNet-101, respectively. An evident improvement is observed in the segmentation accuracy of multi-scale targets, proving that this model is effective for improving the baseline network. The segmentation accuracy in this study is higher than those of two-stage instance segmentation algorithms, such as Mask R-CNN and CenterMask. The proposed method also exhibits advantages over single-stage segmentation algorithms, such as you only look at coefficients(YOLACT). From the contour binary graph, the boundaries extracted using this method are more precise. The experimental results show that the proposed method exhibits strong model generalization and robustness.ConclusionThe occluded object instance segmentation based on balance pooling attention and adaptive feature fusion proposed in this study can effectively improve the effectiveness of occluded object instance segmentation.关键词:occluded objects instance segmentation;balance pooling attention module(BPAM);adaptive feature fusion module (AFFM);bilayer convolutional network (BCNet);contour prediction branch;mask prediction branch
摘要:ObjectiveInstance segmentation is a popular topic in image processing and computer vision. It is widely used in unmanned driving, medical image segmentation, and other fields. The high overlap between objects in practical application scenarios makes instance segmentation more challenging. Instance segmentation models include two-stage and single-stage models. In a two-stage instance segmentation model, the two-layer instance segmentation network (i.e., bilayer convolutional network (BCNet) is one of the most successful networks in the field of occlusion object instance segmentation. In contrast with previous two-stage instance segmentation methods, BCNet extracts regions of interest (RoI) and simultaneously regresses the occluder and occludee regions, grouping pixels that belong to the occluder region and treating them as pixels in the occludee region, but dividing them into two independent image layers. Consequently, the boundaries of the two objects are naturally decoupled, considering the interaction between them during the mask regression phase. Thus, a two-layer convolutional network is proposed, in which the top graph convolutional network (GCN) layer detects occluder objects while the bottom GCN layer infers occludee instances. The explicit modeling of occlusion relationships on the basis of a two-layer structure naturally decouples the boundaries of occluder and occludee instances, and considers the interaction between them in mask regression. BCNet proposes a new structure for highly overlapping objects in segmentation scenes. The segmentation performance of occluded object instances is closely related to the prediction results of object contours. However, the current algorithm’s predicted object contours are not sufficiently refined, resulting in rough segmentation masks and poor object boundary segmentation performance. Therefore, this study presents a contour refinement instance segmentation method for occluded objects based on BCNet. The predicted object contour is more precise, and the segmentation mask is more complete.MethodSimple average pooling causes the loss of a significant amount of feature information and cannot generate more detailed feature information, while maximum pooling can retain more significant feature information. On this basis, the study proposes a balance pooling attention module. Global context information is collected in the form of 1D maximum pooling and 1D average pooling in parallel. The proportion of maximum pooling and average pooling is balanced through weighted feature fusion to generate more detailed information without losing overall features. The balance pooling attention module is added to ResNet to enable the feature extraction stage to extract features with more details. Features at different scales contain different feature information. High-resolution features contain more detailed information, while low-resolution features contain richer semantic information. In contrast with the input for the mask head in BCNet, this study separates the contour prediction branch from the mask prediction branch and adopts different feature inputs, extracting region of interest (RoI) features from the highest resolution features in a feature pyramid network (FPN) as features for the contour prediction branch and RoI features from the cascaded low-resolution features as input for the mask prediction branch. The features of the contour prediction branch have more detailed and spatial information, and the mask prediction branch has more abundant semantic information. To improve the segmentation effect further, the adaptive feature fusion module is proposed to fuse the features in the contour prediction branch with the features in the mask prediction branch. In the contour prediction branch, the features of the fused mask prediction branch can better determine the object category to which the contour belongs. In the mask prediction branch, the features of the fused contour prediction branch can better assist in mask positioning. The criss-cross attention module is used to infer the contours and masks of the occluder and occludee objects. It can maintain prediction accuracy and effectively reduce computational complexity compared with the non-local operator structure GCN module adopted in BCNet.ResultSegmentation accuracy is compared with classic instance segmentation models, such as mask region-based convolutional neural network(Mask R-CNN), CenterMask, and BCNet, on the common objects in context(COCO) 2017 validation set. Compared with the baseline network BCNet, average precision(AP) increases by 1.7% and 2.1% when the backbone network is ResNet-50 and ResNet-101, respectively. An evident improvement is observed in the segmentation accuracy of multi-scale targets, proving that this model is effective for improving the baseline network. The segmentation accuracy in this study is higher than those of two-stage instance segmentation algorithms, such as Mask R-CNN and CenterMask. The proposed method also exhibits advantages over single-stage segmentation algorithms, such as you only look at coefficients(YOLACT). From the contour binary graph, the boundaries extracted using this method are more precise. The experimental results show that the proposed method exhibits strong model generalization and robustness.ConclusionThe occluded object instance segmentation based on balance pooling attention and adaptive feature fusion proposed in this study can effectively improve the effectiveness of occluded object instance segmentation.关键词:occluded objects instance segmentation;balance pooling attention module(BPAM);adaptive feature fusion module (AFFM);bilayer convolutional network (BCNet);contour prediction branch;mask prediction branch- 5
- |
- 1
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveVideo object segmentation (VOS) aims to provide high-quality segmentation of target object instances throughout an input video sequence, obtaining pixel-level masks of the target objects, thereby finely segmenting the target from the background images. Compared with tasks such as object tracking and detection, which involve bounding-box level tasks (using rectangular frames to select targets), VOS has pixel-level accuracy, which is more conducive to locating the target accurately and outlining the details of the target’s edge. Depending on the supervision information provided, VOS can be divided into three scenarios: semisupervised VOS, interactive VOS, and unsupervised VOS. In this study, we focus on the semisupervised task. In the scenario of semisupervised VOS, pixel-level annotated masks of the first frame of the video are provided, and subsequent prediction frames can fully utilize the annotated mask of the first frame to assist in computing the segmentation results of each prediction frame. With the development of deep neural network technology, current semisupervised VOS methods are mostly based on deep learning. These methods can be divided into the following three categories: detection-, matching-, and propagation-based methods. Detection-based object segmentation algorithms treat VOS tasks as image object segmentation tasks without considering the temporal association of videos, believing that only a strong frame-level object detector and segmenter are needed to perform target segmentation frame by frame. Matching-based works typically segment video objects by calculating pixel-level matching scores or semantic feature matching scores between the template frame and the current prediction frame. Propagation-based methods propagate the multiframe feature information before the prediction frame to the prediction frame and calculate the correlation between the prediction frame feature and the previous frame feature to represent video context information. This context information locates the key areas of the entire video and can guide single-frame image segmentation. Motion-based propagation methods have two types: one introduces optical flow to train the VOS model, and the other learns deep target features from the previous frame’s target mask and refines the target mask in the current frame. Existing semisupervised video segmentation is mostly based on optical flow methods to model the feature association between key frames and the current frame. However, the optical flow method is prone to errors due to occlusions, special textures and other situations, leading to issues in multiframe fusion. Aiming to integrate multiframe features, this study extracts the appearance feature information of the first frame and the positional information of the adjacent key frames and fuses the features through the Transformer and the improved path aggregation network (PAN) module, thereby learning and integrating features based on multiframe spatiotemporal attention.MethodIn this study, we propose a semisupervised VOS method based on the fusion of features using the Transformer mechanism. This method integrates multiframe appearance feature information and positional feature information. Specifically, the algorithm is divided into the following steps: 1) appearance information feature extraction network: first, we construct an appearance information feature extraction network. This module, based on CSPDarknet53, is modified and consists of CBS (convolution, batch normalization, and Silu) modules, cross stage partial residual network(CSPRes) modules, residual spatial pyramid pooling(ResSPP) modules, and receptive field enhancement and pyramid pooling(REP) modules. The first frame of the video serves as the input, which is passed through three CBS modules to obtain the shallow features
摘要:ObjectiveVideo object segmentation (VOS) aims to provide high-quality segmentation of target object instances throughout an input video sequence, obtaining pixel-level masks of the target objects, thereby finely segmenting the target from the background images. Compared with tasks such as object tracking and detection, which involve bounding-box level tasks (using rectangular frames to select targets), VOS has pixel-level accuracy, which is more conducive to locating the target accurately and outlining the details of the target’s edge. Depending on the supervision information provided, VOS can be divided into three scenarios: semisupervised VOS, interactive VOS, and unsupervised VOS. In this study, we focus on the semisupervised task. In the scenario of semisupervised VOS, pixel-level annotated masks of the first frame of the video are provided, and subsequent prediction frames can fully utilize the annotated mask of the first frame to assist in computing the segmentation results of each prediction frame. With the development of deep neural network technology, current semisupervised VOS methods are mostly based on deep learning. These methods can be divided into the following three categories: detection-, matching-, and propagation-based methods. Detection-based object segmentation algorithms treat VOS tasks as image object segmentation tasks without considering the temporal association of videos, believing that only a strong frame-level object detector and segmenter are needed to perform target segmentation frame by frame. Matching-based works typically segment video objects by calculating pixel-level matching scores or semantic feature matching scores between the template frame and the current prediction frame. Propagation-based methods propagate the multiframe feature information before the prediction frame to the prediction frame and calculate the correlation between the prediction frame feature and the previous frame feature to represent video context information. This context information locates the key areas of the entire video and can guide single-frame image segmentation. Motion-based propagation methods have two types: one introduces optical flow to train the VOS model, and the other learns deep target features from the previous frame’s target mask and refines the target mask in the current frame. Existing semisupervised video segmentation is mostly based on optical flow methods to model the feature association between key frames and the current frame. However, the optical flow method is prone to errors due to occlusions, special textures and other situations, leading to issues in multiframe fusion. Aiming to integrate multiframe features, this study extracts the appearance feature information of the first frame and the positional information of the adjacent key frames and fuses the features through the Transformer and the improved path aggregation network (PAN) module, thereby learning and integrating features based on multiframe spatiotemporal attention.MethodIn this study, we propose a semisupervised VOS method based on the fusion of features using the Transformer mechanism. This method integrates multiframe appearance feature information and positional feature information. Specifically, the algorithm is divided into the following steps: 1) appearance information feature extraction network: first, we construct an appearance information feature extraction network. This module, based on CSPDarknet53, is modified and consists of CBS (convolution, batch normalization, and Silu) modules, cross stage partial residual network(CSPRes) modules, residual spatial pyramid pooling(ResSPP) modules, and receptive field enhancement and pyramid pooling(REP) modules. The first frame of the video serves as the input, which is passed through three CBS modules to obtain the shallow features- 5
- |
- 2
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveBy fusing color, depth, and spatial information, using RGB_D data in salient object detection typically achieves more accurate predictions compared with using a single modality. Additionally, the rise of deep learning technology has further propelled the development of RGB_D salient object detection. However, existing RGB_D deep network models for salient object detection often overlook the specificity of different modalities. They typically rely on simple fusion methods, such as element-wise addition, multiplication, or feature concatenation, to combine multimodal features. However, the existing models of significant object detection in RGB_D deep networks often ignore the specificity of different modes. They often rely on simple fusion methods, such as element addition, multiplication, or feature joining, to combine multimodal features. These simple fusion techniques lack a reasonable explanation for the interaction between RGB and depth images. These methods do not effectively take advantage of the complementary information between RGB and depth modes nor do they take advantage of the potential correlations between them. Therefore, more efficient methods must be proposed to facilitate the information interaction between RGB images and depth images so as to obtain more accurate significant object detection results. To solve this problem, the researchers simulated the relationship between RGB and depth by analyzing traditional neural networks and linear correction units (ReLU) (e.g., structures, such as constructed recurrent neural networks or convolutional neural networks). Finally, a new interactive mechanism of complementary information between RGB and depth features is designed and applied to RGB_D salient target detection for the first time. This method analyzes the correlations between RGB and depth features and uses these correlations to guide the fusion and interaction process. To explore the importance of complementary information in both modalities and more effective ways of interaction, we propose a new RGB and depth feature complementary information interaction mechanism based on analyzing the selectivity of ReLU in traditional convolutional networks. This mechanism is applied for the first time in RGB_D salient object detection.MethodFirst, on the basis of this mechanism, a complementary information interaction module is proposed to use the “redundancy” characteristics of each mode to assist each other. Then, it is inserted into two lightweight backbone networks in phases to extract RGB and depth features and implement the interaction between them. The core function of the module is based on the modified ReLU, which has a simple structure. At the top layer of the network, a cross-modal feature fusion module is designed to extract the global semantic information of the fused features. These features are passed to each scale of the backbone network and aggregated with multiscale features via a neighborhood scale feature enhancement module. In this manner, not only local and scale sensing features can be captured but also global semantic information can be obtained, thus improving the accuracy and robustness of salient target detection. At the same time, three monitoring strategies are adopted to supervise the optimization of the model effectively. First, the accuracy of depth information is constrained by depth recovery supervision to ensure the reliability of depth features. Second, edge supervision is used to guide the model to capture the boundary information of important targets and improve the positioning accuracy. Finally, deep supervision is used to improve the performance of the model further by monitoring the consistency between the fused features and the real significance graph.ResultBy conducting quantitative and qualitative experiments on widely used public datasets (Nanjing University 2K(NJU2K), national laboratory of pattern recognition(NLPR), stereo dataset(STERE), and salient person(SIP)), the salient object detection model in this study shows remarkable advantages on three main evaluation measures: Max F-measure, mean absolute error(MAE), and Max E-measure. The model performed relatively well, especially on the SIP dataset, where it achieved the best results. In addition, the processing speed of the model remarkably improved to 373.8 frame/s, while the parameter decreased to 10.8 M. Compared with the other six methods, the proposed complementary information aggregation module remarkably improved in the effect of salient target detection. By using the complementary information of RGB and depth features and through the design of cross-modal feature fusion module, the model can better capture the global semantic information of important targets and improve the accuracy and robustness of detection.ConclusionThe proposed salient object detection model in this study is based on the design of complementary information interaction module, lightweight backbone network, and cross-modal feature fusion module. The method maximizes the complementary information of RGB and depth features and achieves remarkable performance improvement through optimized network structure and monitoring strategy. Compared with other methods, this model shows better results in terms of accuracy, robustness, and computational efficiency. In RGB_D data, this work is of crucial to deepening the understanding of the importance of multimodal data fusion and promoting the research and application in the field of salient target detection.关键词:salient object detection(SOD);RGB_D;deep convolutional network;complementary information interaction;cross-modal feature fusion
摘要:ObjectiveBy fusing color, depth, and spatial information, using RGB_D data in salient object detection typically achieves more accurate predictions compared with using a single modality. Additionally, the rise of deep learning technology has further propelled the development of RGB_D salient object detection. However, existing RGB_D deep network models for salient object detection often overlook the specificity of different modalities. They typically rely on simple fusion methods, such as element-wise addition, multiplication, or feature concatenation, to combine multimodal features. However, the existing models of significant object detection in RGB_D deep networks often ignore the specificity of different modes. They often rely on simple fusion methods, such as element addition, multiplication, or feature joining, to combine multimodal features. These simple fusion techniques lack a reasonable explanation for the interaction between RGB and depth images. These methods do not effectively take advantage of the complementary information between RGB and depth modes nor do they take advantage of the potential correlations between them. Therefore, more efficient methods must be proposed to facilitate the information interaction between RGB images and depth images so as to obtain more accurate significant object detection results. To solve this problem, the researchers simulated the relationship between RGB and depth by analyzing traditional neural networks and linear correction units (ReLU) (e.g., structures, such as constructed recurrent neural networks or convolutional neural networks). Finally, a new interactive mechanism of complementary information between RGB and depth features is designed and applied to RGB_D salient target detection for the first time. This method analyzes the correlations between RGB and depth features and uses these correlations to guide the fusion and interaction process. To explore the importance of complementary information in both modalities and more effective ways of interaction, we propose a new RGB and depth feature complementary information interaction mechanism based on analyzing the selectivity of ReLU in traditional convolutional networks. This mechanism is applied for the first time in RGB_D salient object detection.MethodFirst, on the basis of this mechanism, a complementary information interaction module is proposed to use the “redundancy” characteristics of each mode to assist each other. Then, it is inserted into two lightweight backbone networks in phases to extract RGB and depth features and implement the interaction between them. The core function of the module is based on the modified ReLU, which has a simple structure. At the top layer of the network, a cross-modal feature fusion module is designed to extract the global semantic information of the fused features. These features are passed to each scale of the backbone network and aggregated with multiscale features via a neighborhood scale feature enhancement module. In this manner, not only local and scale sensing features can be captured but also global semantic information can be obtained, thus improving the accuracy and robustness of salient target detection. At the same time, three monitoring strategies are adopted to supervise the optimization of the model effectively. First, the accuracy of depth information is constrained by depth recovery supervision to ensure the reliability of depth features. Second, edge supervision is used to guide the model to capture the boundary information of important targets and improve the positioning accuracy. Finally, deep supervision is used to improve the performance of the model further by monitoring the consistency between the fused features and the real significance graph.ResultBy conducting quantitative and qualitative experiments on widely used public datasets (Nanjing University 2K(NJU2K), national laboratory of pattern recognition(NLPR), stereo dataset(STERE), and salient person(SIP)), the salient object detection model in this study shows remarkable advantages on three main evaluation measures: Max F-measure, mean absolute error(MAE), and Max E-measure. The model performed relatively well, especially on the SIP dataset, where it achieved the best results. In addition, the processing speed of the model remarkably improved to 373.8 frame/s, while the parameter decreased to 10.8 M. Compared with the other six methods, the proposed complementary information aggregation module remarkably improved in the effect of salient target detection. By using the complementary information of RGB and depth features and through the design of cross-modal feature fusion module, the model can better capture the global semantic information of important targets and improve the accuracy and robustness of detection.ConclusionThe proposed salient object detection model in this study is based on the design of complementary information interaction module, lightweight backbone network, and cross-modal feature fusion module. The method maximizes the complementary information of RGB and depth features and achieves remarkable performance improvement through optimized network structure and monitoring strategy. Compared with other methods, this model shows better results in terms of accuracy, robustness, and computational efficiency. In RGB_D data, this work is of crucial to deepening the understanding of the importance of multimodal data fusion and promoting the research and application in the field of salient target detection.关键词:salient object detection(SOD);RGB_D;deep convolutional network;complementary information interaction;cross-modal feature fusion- 5
- |
- 1
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveFew-shot semantic segmentation is one of the fundamental and challenging tasks in the field of computer vision. It aims to use a limited amount of annotated support samples to guide the segmentation of unknown objects in a query image. Compared with traditional semantic segmentation, few-shot semantic segmentation methods effectively alleviate problems, such as the high cost of per-pixel annotation greatly limiting the application of semantic segmentation technology in practical scenarios and the weak generalization ability of this model for novel class targets. The existing few-shot semantic segmentation methods mainly utilize the meta-learning architecture with dual-branch networks, where the support branch consists of the support images and their corresponding per-pixel labeled ground truth masks, and the query branch takes the input of the new image to be segmented, and both branches share the same semantic classes. The valuable information of support images in the support branch is extracted to guide the segmentation of unknown novel classes in query images. However, different instances of the same semantic class may have variations in appearance and scale, and the information extracted solely from the support branch is insufficient to guide the segmentation of unknown novel classes in query images. Although some researchers have attempted to improve the performance of few-shot semantic segmentation through bidirectional guidance, existing bidirectional guidance models overly rely on the pseudo masks predicted by the query branch in the intermediate stage. If the initial predictions of the query branch are poor, it can easily lead to a weak generalization of shared semantics, which is not conducive to improving segmentation performance.MethodA multiscale feature fusion and cross-guidance network for few-shot semantic segmentation is proposed to alleviate these problems, attempting to construct the information interaction between the support branch and the query branch to improve the performance of the few-shot semantic segmentation task. First, a set of pretrained backbone networks with shared weights are used as feature extractors to map features from the support and query branch into the same deep feature space, and then the low-level, intermediate-level, and high-level features output by them are fused at multiple scales to construct a multiscale feature set, which enriches the semantic information of features and enhances the reliability of the feature expression. Second, with the help of the ground-truth mask of the support branch, the fused support features are decomposed into the target-related foreground feature maps and task-irrelevant background feature maps. Then, a feature interaction module is designed on the basis of the cross-attention mechanism, which establishes information interaction between the target-related foreground feature maps of the support branch and the entire query branch feature map, aiming to promote the interactivity between branches while enhancing the expressiveness of task-related features. In addition, a mask average pooling strategy is used on the interactive feature map to generate a target foreground region prototype set, and a background prototype set is generated on the support background feature map. Finally, the cosine similarity measure is used to calculate the similarity values between the support features and the prototype sets and between the query features and the prototype sets; then, the corresponding mask is generated on the basis of the maximum similarity value at each position.ResultExperimental results on the classic PASCAL-5i (pattern analysis, statistical modeling and computational learning) dataset show that when Visual Geometry Group(VGG-16), residual neural network(ResNet-50), and ResNet-101 are used as backbone networks, the proposed few-shot semantic segmentation model achieves mean intersection over union (mIoU) scores of 50.2%/53.2%/57.1% and FB-IoU scores of 68.3%/69.4%/72.3% in the one-way one-shot task and mIoU scores of 52.9%/55.7%/59.7% and FB-IoU scores of 69.7%/72.5%/74.6% in the one-way five-shot task. Results on the more challenging COCO-20i dataset show that the proposed model achieves mIoU scores of 23.9%/35.1%/36.4% and FB-IoU scores of 60.1%/62.4%/64.1% in the one-way one-shot task and mIoU scores of 32.5%/37.3%/38.3% and FB-IoU scores of 64.2%/66.2%/66.7% in the one-way five-shot task when VGG-16, ResNet-50, and ResNet-101 are used as backbone networks. Furthermore, the performance gains of the proposed few-shot semantic segmentation model on the PASCAL-5i and COCO-20i (common objects in context) datasets are competitive.ConclusionCompared with current mainstream few-shot semantic segmentation models, our model can achieve higher mIoU and FB-IoU in one-way one-shot and one-way five-shot tasks, with remarkable improvement in overall performance. Further validation shows that feature interaction between the support branch and query branch can effectively improve the model’s ability to locate and segment unknown new classes in query images, and using joint loss between support branch and query branch can promote information flow between dual-branch features, enhance the reliability of prototype expression, and achieve alignment of cross-branch prototype sets.关键词:few-shot semantic segmentation;multiscale feature fusion;cross-branch cross-guidance;feature interaction;masked averaging pooling
摘要:ObjectiveFew-shot semantic segmentation is one of the fundamental and challenging tasks in the field of computer vision. It aims to use a limited amount of annotated support samples to guide the segmentation of unknown objects in a query image. Compared with traditional semantic segmentation, few-shot semantic segmentation methods effectively alleviate problems, such as the high cost of per-pixel annotation greatly limiting the application of semantic segmentation technology in practical scenarios and the weak generalization ability of this model for novel class targets. The existing few-shot semantic segmentation methods mainly utilize the meta-learning architecture with dual-branch networks, where the support branch consists of the support images and their corresponding per-pixel labeled ground truth masks, and the query branch takes the input of the new image to be segmented, and both branches share the same semantic classes. The valuable information of support images in the support branch is extracted to guide the segmentation of unknown novel classes in query images. However, different instances of the same semantic class may have variations in appearance and scale, and the information extracted solely from the support branch is insufficient to guide the segmentation of unknown novel classes in query images. Although some researchers have attempted to improve the performance of few-shot semantic segmentation through bidirectional guidance, existing bidirectional guidance models overly rely on the pseudo masks predicted by the query branch in the intermediate stage. If the initial predictions of the query branch are poor, it can easily lead to a weak generalization of shared semantics, which is not conducive to improving segmentation performance.MethodA multiscale feature fusion and cross-guidance network for few-shot semantic segmentation is proposed to alleviate these problems, attempting to construct the information interaction between the support branch and the query branch to improve the performance of the few-shot semantic segmentation task. First, a set of pretrained backbone networks with shared weights are used as feature extractors to map features from the support and query branch into the same deep feature space, and then the low-level, intermediate-level, and high-level features output by them are fused at multiple scales to construct a multiscale feature set, which enriches the semantic information of features and enhances the reliability of the feature expression. Second, with the help of the ground-truth mask of the support branch, the fused support features are decomposed into the target-related foreground feature maps and task-irrelevant background feature maps. Then, a feature interaction module is designed on the basis of the cross-attention mechanism, which establishes information interaction between the target-related foreground feature maps of the support branch and the entire query branch feature map, aiming to promote the interactivity between branches while enhancing the expressiveness of task-related features. In addition, a mask average pooling strategy is used on the interactive feature map to generate a target foreground region prototype set, and a background prototype set is generated on the support background feature map. Finally, the cosine similarity measure is used to calculate the similarity values between the support features and the prototype sets and between the query features and the prototype sets; then, the corresponding mask is generated on the basis of the maximum similarity value at each position.ResultExperimental results on the classic PASCAL-5i (pattern analysis, statistical modeling and computational learning) dataset show that when Visual Geometry Group(VGG-16), residual neural network(ResNet-50), and ResNet-101 are used as backbone networks, the proposed few-shot semantic segmentation model achieves mean intersection over union (mIoU) scores of 50.2%/53.2%/57.1% and FB-IoU scores of 68.3%/69.4%/72.3% in the one-way one-shot task and mIoU scores of 52.9%/55.7%/59.7% and FB-IoU scores of 69.7%/72.5%/74.6% in the one-way five-shot task. Results on the more challenging COCO-20i dataset show that the proposed model achieves mIoU scores of 23.9%/35.1%/36.4% and FB-IoU scores of 60.1%/62.4%/64.1% in the one-way one-shot task and mIoU scores of 32.5%/37.3%/38.3% and FB-IoU scores of 64.2%/66.2%/66.7% in the one-way five-shot task when VGG-16, ResNet-50, and ResNet-101 are used as backbone networks. Furthermore, the performance gains of the proposed few-shot semantic segmentation model on the PASCAL-5i and COCO-20i (common objects in context) datasets are competitive.ConclusionCompared with current mainstream few-shot semantic segmentation models, our model can achieve higher mIoU and FB-IoU in one-way one-shot and one-way five-shot tasks, with remarkable improvement in overall performance. Further validation shows that feature interaction between the support branch and query branch can effectively improve the model’s ability to locate and segment unknown new classes in query images, and using joint loss between support branch and query branch can promote information flow between dual-branch features, enhance the reliability of prototype expression, and achieve alignment of cross-branch prototype sets.关键词:few-shot semantic segmentation;multiscale feature fusion;cross-branch cross-guidance;feature interaction;masked averaging pooling- 9
- |
- 2
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveSemantic segmentation plays a crucial role in intelligent interpretation of remote sensing images. With the rapid advancement of remote sensing technology and the burgeoning field of big data mining, the semantic segmentation of remote sensing images has become increasingly pivotal across diverse applications, such as natural resource survey, mineral exploration, water quality monitoring, and vegetation ecological assessment. The expansive coverage of remote sensing images, coupled with intricate background intersections and considerable variations in the sizes of ground objects, underscores the difficulties and challenges to the task at hand. Existing methods exhibit limitations in achieving high segmentation accuracies, particularly when confronted with multiscale objects within intricate backgrounds. The resulting segmentation boundaries often appear fuzzy and discontinuous. Thus, a cross-layer detail perception and group attention-guided semantic segmentation network (CDGCANet) is proposed for high-resolution remote sensing images.MethodFirst, the ConvNeXt backbone network with a novel structure is used to encode the network features at each level of the input image. It combines the popular Transformer network architecture and the classic convolutional neural network architecture, takes advantage of the two mainstream architectures, and adopts the SwinTransformer design strategy to improve the structure of ResNet50, obtaining the ConvNeXt network structure. Second, the group collaborative attention module is designed to model the feature dependencies of channel and spatial dimensions in parallel, thereby modeling the spatial and channel relationships of multiscale feature features and promoting the information interaction between channels. Channel attention and spatial attention collaboratively enhance the feature information of important channels and regions and then improve the network's ability to discriminate multiscale features, especially small targets. Next, a self-attention mechanism is introduced to construct the cross-layer detail-aware module (CDM), which uses the rich detail information in low-level features to guide high-level feature layers in learning spatial details and ensure the regional integrity and boundary continuity of segmentation results. During semantic segmentation network coding, the shallow features have strong detail information but poor semantic consistency due to the limited sensing field, while the deep features are rough the spatial information due to low resolution and inability to restore the detail information. This leads to problems, such as missing segmentation edges and discontinuity. The CDM module utilizes the spatial information of the previous layers to guide the learning of the deeper detailed features and thus ensure the semantic consistency between the low level features and high level features. Finally, Taiyuan City, Shanxi Province is taken as the research area; the high-resolution remote sensing Taiyuan urban land cover dataset, termed TULCD, is self-made. Whose original remote sensing image is extracted from 1 m-level data source of Gaofen-2 domestic satellite, the size of the original image reaches 56 251 × 52 654 pixels with the overall capacity size of 12.7 GB. The overlap tiling strategy is used for the large remote sensing image cropping with the size of the sliding window of 512 and the step size of 256 to produce 512 × 512 pixel images. A total of 6 607 images are obtained, and the dataset is divided in accordance with the 8∶2 ratio, in which 5 285 images are for the training set and 1 322 images are for the validation set. The proposed method realizes the task of fine classification of land cover in the urban area of Taiyuan City.ResultThe experiments were conducted with the latest five algorithms (e.g., UNet, PSPNet, DeeplabV3+, A2-FPN, and Swin Transformer) on the self-made dataset TULCD and the public dataset Vaihingen, and three evaluation metrics were used to evaluate the model performance. The performance of the proposed CDGCANet outperforms other algorithms on the TULCD dataset, with an average pixel accuracy (mPA), average intersection over union (mIoU), and mF1 of 74.23%, 58.91%, and 72.24%, respectively, and the overall performance exceeds that of the second-ranked model PSPNet with an mPA of 4.61%, an mIoU of 1.58%, and mF1 of 1.63%. The overall performance achieved by the CDGCANet on the Vaihingen dataset is 83.22%, 77.62%, and 86.26% for mPA, mIoU, and mF1, respectively. These values are higher than those of the second-ranked model DeeplabV3+, which are 1.86%, 2.62%, and 2.06% for mPA, mIoU, and mF1, respectively. According to the visualization, the results show that the model can correctly identify the feature target with a complete segmentation area, clear details, and continuous edges. In addition, the neural network visualization tool GradCAM is used to view the category heat map output by the model. Experimental results show that the attention mechanism can help the model focus on key areas and ground objects and enhance the feature expression ability of the model.ConclusionThe semantic segmentation model of high-resolution remote sensing images proposed in this study has strong spatial and detail perception capabilities, which not only improves the accuracy of semantic segmentation but also yields more satisfactory segmentation results when handling complex remote sensing images. Looking ahead, we anticipate further optimization and in-depth research to propel the practical application of this model, contributing to remarkable breakthroughs and advancements in the field of remote sensing image interpretation.关键词:remote sensing images;semantic segmentation;fully convolutional network (FCN);attention mechanisms;group convolution
摘要:ObjectiveSemantic segmentation plays a crucial role in intelligent interpretation of remote sensing images. With the rapid advancement of remote sensing technology and the burgeoning field of big data mining, the semantic segmentation of remote sensing images has become increasingly pivotal across diverse applications, such as natural resource survey, mineral exploration, water quality monitoring, and vegetation ecological assessment. The expansive coverage of remote sensing images, coupled with intricate background intersections and considerable variations in the sizes of ground objects, underscores the difficulties and challenges to the task at hand. Existing methods exhibit limitations in achieving high segmentation accuracies, particularly when confronted with multiscale objects within intricate backgrounds. The resulting segmentation boundaries often appear fuzzy and discontinuous. Thus, a cross-layer detail perception and group attention-guided semantic segmentation network (CDGCANet) is proposed for high-resolution remote sensing images.MethodFirst, the ConvNeXt backbone network with a novel structure is used to encode the network features at each level of the input image. It combines the popular Transformer network architecture and the classic convolutional neural network architecture, takes advantage of the two mainstream architectures, and adopts the SwinTransformer design strategy to improve the structure of ResNet50, obtaining the ConvNeXt network structure. Second, the group collaborative attention module is designed to model the feature dependencies of channel and spatial dimensions in parallel, thereby modeling the spatial and channel relationships of multiscale feature features and promoting the information interaction between channels. Channel attention and spatial attention collaboratively enhance the feature information of important channels and regions and then improve the network's ability to discriminate multiscale features, especially small targets. Next, a self-attention mechanism is introduced to construct the cross-layer detail-aware module (CDM), which uses the rich detail information in low-level features to guide high-level feature layers in learning spatial details and ensure the regional integrity and boundary continuity of segmentation results. During semantic segmentation network coding, the shallow features have strong detail information but poor semantic consistency due to the limited sensing field, while the deep features are rough the spatial information due to low resolution and inability to restore the detail information. This leads to problems, such as missing segmentation edges and discontinuity. The CDM module utilizes the spatial information of the previous layers to guide the learning of the deeper detailed features and thus ensure the semantic consistency between the low level features and high level features. Finally, Taiyuan City, Shanxi Province is taken as the research area; the high-resolution remote sensing Taiyuan urban land cover dataset, termed TULCD, is self-made. Whose original remote sensing image is extracted from 1 m-level data source of Gaofen-2 domestic satellite, the size of the original image reaches 56 251 × 52 654 pixels with the overall capacity size of 12.7 GB. The overlap tiling strategy is used for the large remote sensing image cropping with the size of the sliding window of 512 and the step size of 256 to produce 512 × 512 pixel images. A total of 6 607 images are obtained, and the dataset is divided in accordance with the 8∶2 ratio, in which 5 285 images are for the training set and 1 322 images are for the validation set. The proposed method realizes the task of fine classification of land cover in the urban area of Taiyuan City.ResultThe experiments were conducted with the latest five algorithms (e.g., UNet, PSPNet, DeeplabV3+, A2-FPN, and Swin Transformer) on the self-made dataset TULCD and the public dataset Vaihingen, and three evaluation metrics were used to evaluate the model performance. The performance of the proposed CDGCANet outperforms other algorithms on the TULCD dataset, with an average pixel accuracy (mPA), average intersection over union (mIoU), and mF1 of 74.23%, 58.91%, and 72.24%, respectively, and the overall performance exceeds that of the second-ranked model PSPNet with an mPA of 4.61%, an mIoU of 1.58%, and mF1 of 1.63%. The overall performance achieved by the CDGCANet on the Vaihingen dataset is 83.22%, 77.62%, and 86.26% for mPA, mIoU, and mF1, respectively. These values are higher than those of the second-ranked model DeeplabV3+, which are 1.86%, 2.62%, and 2.06% for mPA, mIoU, and mF1, respectively. According to the visualization, the results show that the model can correctly identify the feature target with a complete segmentation area, clear details, and continuous edges. In addition, the neural network visualization tool GradCAM is used to view the category heat map output by the model. Experimental results show that the attention mechanism can help the model focus on key areas and ground objects and enhance the feature expression ability of the model.ConclusionThe semantic segmentation model of high-resolution remote sensing images proposed in this study has strong spatial and detail perception capabilities, which not only improves the accuracy of semantic segmentation but also yields more satisfactory segmentation results when handling complex remote sensing images. Looking ahead, we anticipate further optimization and in-depth research to propel the practical application of this model, contributing to remarkable breakthroughs and advancements in the field of remote sensing image interpretation.关键词:remote sensing images;semantic segmentation;fully convolutional network (FCN);attention mechanisms;group convolution- 3
- |
- 0
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveIn high intensity focused ultrasound (HIFU) treatment, the target area contains a large amount of pathological information; thus, the target area must be accurately located and extracted by ultrasound monitoring images. As biological tissues and target regions change their relative positions during treatment, the location of the treatment area may also change. At the same time, the diversity of diseases, the variability of tissues, and the complexity of target shapes pose certain challenges for target region extraction in ultrasound medical images. Nevertheless, computers can use advanced image processing and analysis algorithms, combined with big data and machine learning methods, to identify and locate target areas quickly and accurately, providing a reliable basis for quantitative clinical analysis. Traditional image segmentation algorithms mainly include methods, such as threshold segmentation, edge detection, and region growing. However, these methods still have some limitations and are sensitive to the complexity of ultrasound images, noise, and other image quality issues, resulting in poor accuracy and robustness of segmentation results. Meanwhile, traditional methods usually require manual selection of parameters, which limit the adaptive and generalization capabilities of the methods, and have a strong dependence on different images. In recent years, deep learning-based methods have attracted widespread attention and made remarkable progress in the field of medical image segmentation. Most of the methods are performed under strong supervision, yet this type of training requires a large amount of data as support for improved prediction. The amount of data in HIFU therapy ultrasound surveillance images is too small due to patient privacy, differences in acquisition devices, and the need for manual labeling of target areas by specialized physicians. It causes the network not to be adequately trained, making the segmentation results poor in accuracy and robustness. Therefore, this study proposed a method for extracting the target region of HIFU treatment by combining the latent diffusion and U-shaped network.MethodFirst, we train latent diffusion using existing ultrasound surveillance images and their masks, in which the masks are input into the model as condition vectors to generate ultrasound surveillance images with the same contours. To ensure further that the quality of the generated images is close to that of the original images, we design an automatic filtering module that calculates the Fréchet inception distance score (FID) of the generated images with respect to the original images by setting the threshold value of the FID to achieve the reliability of the data expansion of ultrasound surveillance images. Second, we propose a novel U-shaped segmentation network (NUNet), whose main body adopts the encoder and decoder of U-Net. Combining atrous spatial pyramid pooling (ASPP) on the encoder side expands the sensory field of the network to extract image features more efficiently. Inspired by the spatial attention and channel attention mechanisms, we design the dual attention skip connection module (DAttention-SK) to replace the original skip connection layer, which improves the efficiency of splicing low-level information with high-level information and reduces the risk of losing information, such as edge texture. At the same time, incorporating multiple cross entropy losses supervises the network to retain useful details and contextual information. Finally, the images generated using latent diffusion are combined with the existing ultrasound surveillance images as a training set. The effect of segmentation errors due to data scarcity in ultrasound surveillance images is reduced to improve the accuracy of segmentation further.ResultAll experiments were implemented in PyTorch on NVIDIA GeForce RTX 3080 GPU. We trained latent diffusion using datasets collected from clinical treatments and determine the quality of the generated images by FID. For the training strategy of the generative network, the initial learning rate was set to 1 × 10-4, the batch size was adjusted to 2, and the training epoch was 200. When training the segmentation network, the initial learning rate was set to 1×10-4, the batch size was adjusted to 24, and the training epoch was 100. To verify the superiority of the proposed method, we compared the popular generative and segmentation models. Experimental results showed that the ultrasound surveillance images generated using latent diffusion in exhibit better metrics on FID and learned perceptual image patch similarity (LPIPS) compared with other generative models (0.172 and 0.072, respectively). Under the training set of ultrasound surveillance images of uterine fibroids clinically treated with HIFU, the proposed segmentation algorithm obtained an improvement in mean intersection over union (MIoU) and Dice similarity coefficient (DSC) by 2.67% and 1.39%, respectively, compared with the state-of-the-art PDF-UNet. Validation was continued in a breast ultrasound image dataset to explore the generalization of the proposed algorithm. Compared with the state-of-the-art M2SNet, the proposed algorithm’s MIoU and DSC are improved by 2.11% and 1.36%, respectively.ConclusionA method for extracting the target region of HIFU treatment was proposed by combining latent diffusion and a U-shaped network. For the first time, latent diffusion was introduced into the generation of ultrasound surveillance images for HIFU treatment, solving the problems of insufficient dataset diversity and data scarcity. Combining ASPP and dual-attention skip connection module in the segmentation network reduces the risk of losing information, such as the edge texture of the target region, and achieves accurate extraction of the target region in the surveillance ultrasound image. The proposed algorithm solves the problem of insufficient diversity of datasets in surveillance ultrasound images to a certain extent and realizes the accurate extraction of target regions in surveillance ultrasound images.关键词:high intensity focused ultrasound (HIFU);image segmentation;image generation;loss function;latent-diffusion
摘要:ObjectiveIn high intensity focused ultrasound (HIFU) treatment, the target area contains a large amount of pathological information; thus, the target area must be accurately located and extracted by ultrasound monitoring images. As biological tissues and target regions change their relative positions during treatment, the location of the treatment area may also change. At the same time, the diversity of diseases, the variability of tissues, and the complexity of target shapes pose certain challenges for target region extraction in ultrasound medical images. Nevertheless, computers can use advanced image processing and analysis algorithms, combined with big data and machine learning methods, to identify and locate target areas quickly and accurately, providing a reliable basis for quantitative clinical analysis. Traditional image segmentation algorithms mainly include methods, such as threshold segmentation, edge detection, and region growing. However, these methods still have some limitations and are sensitive to the complexity of ultrasound images, noise, and other image quality issues, resulting in poor accuracy and robustness of segmentation results. Meanwhile, traditional methods usually require manual selection of parameters, which limit the adaptive and generalization capabilities of the methods, and have a strong dependence on different images. In recent years, deep learning-based methods have attracted widespread attention and made remarkable progress in the field of medical image segmentation. Most of the methods are performed under strong supervision, yet this type of training requires a large amount of data as support for improved prediction. The amount of data in HIFU therapy ultrasound surveillance images is too small due to patient privacy, differences in acquisition devices, and the need for manual labeling of target areas by specialized physicians. It causes the network not to be adequately trained, making the segmentation results poor in accuracy and robustness. Therefore, this study proposed a method for extracting the target region of HIFU treatment by combining the latent diffusion and U-shaped network.MethodFirst, we train latent diffusion using existing ultrasound surveillance images and their masks, in which the masks are input into the model as condition vectors to generate ultrasound surveillance images with the same contours. To ensure further that the quality of the generated images is close to that of the original images, we design an automatic filtering module that calculates the Fréchet inception distance score (FID) of the generated images with respect to the original images by setting the threshold value of the FID to achieve the reliability of the data expansion of ultrasound surveillance images. Second, we propose a novel U-shaped segmentation network (NUNet), whose main body adopts the encoder and decoder of U-Net. Combining atrous spatial pyramid pooling (ASPP) on the encoder side expands the sensory field of the network to extract image features more efficiently. Inspired by the spatial attention and channel attention mechanisms, we design the dual attention skip connection module (DAttention-SK) to replace the original skip connection layer, which improves the efficiency of splicing low-level information with high-level information and reduces the risk of losing information, such as edge texture. At the same time, incorporating multiple cross entropy losses supervises the network to retain useful details and contextual information. Finally, the images generated using latent diffusion are combined with the existing ultrasound surveillance images as a training set. The effect of segmentation errors due to data scarcity in ultrasound surveillance images is reduced to improve the accuracy of segmentation further.ResultAll experiments were implemented in PyTorch on NVIDIA GeForce RTX 3080 GPU. We trained latent diffusion using datasets collected from clinical treatments and determine the quality of the generated images by FID. For the training strategy of the generative network, the initial learning rate was set to 1 × 10-4, the batch size was adjusted to 2, and the training epoch was 200. When training the segmentation network, the initial learning rate was set to 1×10-4, the batch size was adjusted to 24, and the training epoch was 100. To verify the superiority of the proposed method, we compared the popular generative and segmentation models. Experimental results showed that the ultrasound surveillance images generated using latent diffusion in exhibit better metrics on FID and learned perceptual image patch similarity (LPIPS) compared with other generative models (0.172 and 0.072, respectively). Under the training set of ultrasound surveillance images of uterine fibroids clinically treated with HIFU, the proposed segmentation algorithm obtained an improvement in mean intersection over union (MIoU) and Dice similarity coefficient (DSC) by 2.67% and 1.39%, respectively, compared with the state-of-the-art PDF-UNet. Validation was continued in a breast ultrasound image dataset to explore the generalization of the proposed algorithm. Compared with the state-of-the-art M2SNet, the proposed algorithm’s MIoU and DSC are improved by 2.11% and 1.36%, respectively.ConclusionA method for extracting the target region of HIFU treatment was proposed by combining latent diffusion and a U-shaped network. For the first time, latent diffusion was introduced into the generation of ultrasound surveillance images for HIFU treatment, solving the problems of insufficient dataset diversity and data scarcity. Combining ASPP and dual-attention skip connection module in the segmentation network reduces the risk of losing information, such as the edge texture of the target region, and achieves accurate extraction of the target region in the surveillance ultrasound image. The proposed algorithm solves the problem of insufficient diversity of datasets in surveillance ultrasound images to a certain extent and realizes the accurate extraction of target regions in surveillance ultrasound images.关键词:high intensity focused ultrasound (HIFU);image segmentation;image generation;loss function;latent-diffusion- 4
- |
- 1
- |
- 0
发布时间:2024-05-15
Image/Video Semantic Segmentation

-
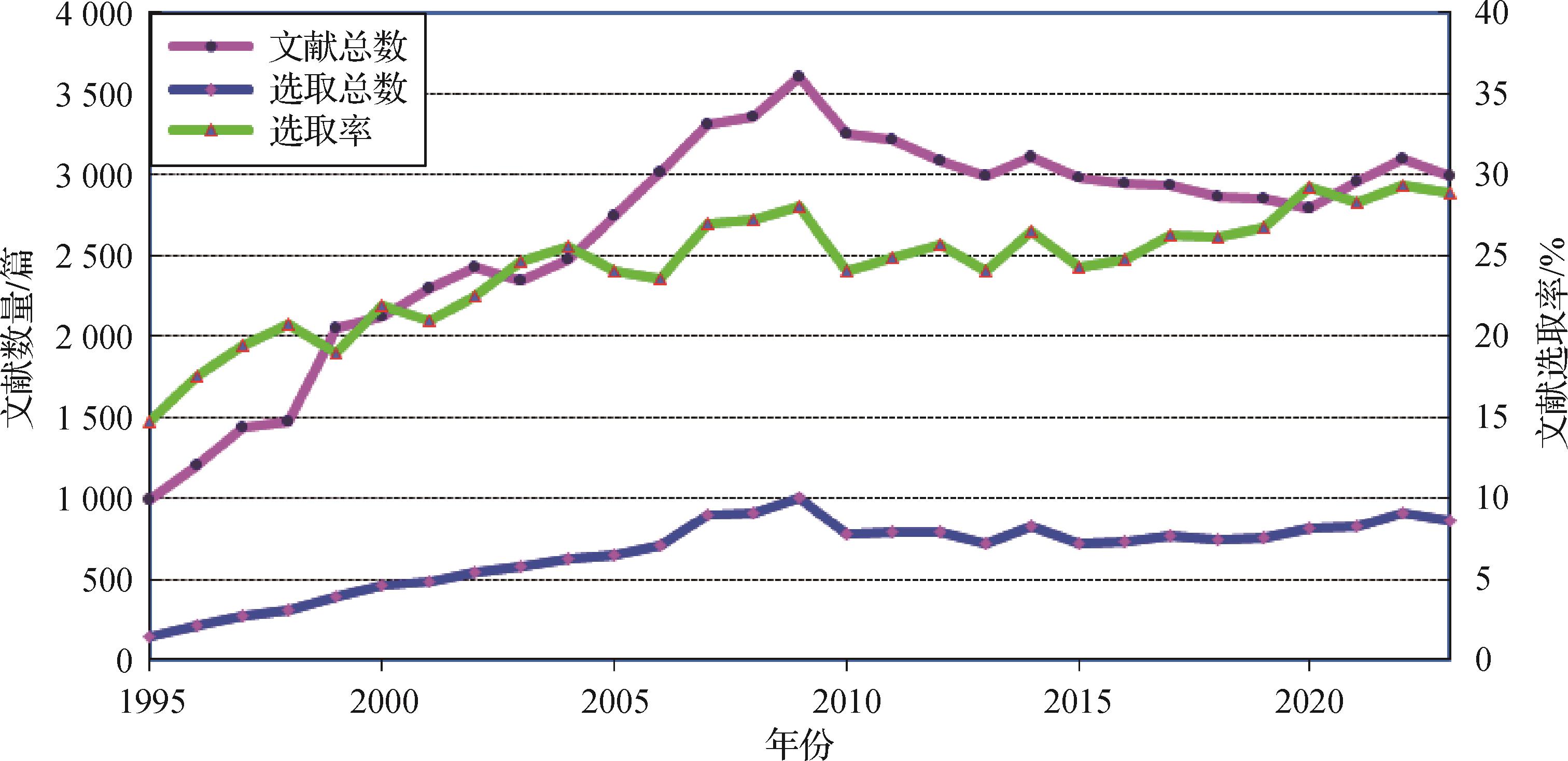 摘要:This is the 29th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Specifically, considering the wide distribution of related publications in China, all references (865) on image engineering research and technique are selected carefully from the research papers (2 989 in total) published in all issues (154) of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 18 years). Analysis and discussions about the statistics of the results of classifications by journal and by category are also presented. Analysis on the statistics in 2023 shows that: from a research perspective, image analysis has currently received the most attention, with image segmentation and primitive detection, object detection and recognition, as well as human biometric feature extraction and validation being the focus of research; from an application perspective, remote sensing, radar, sonar, surveying and mapping are the most active fields, and the development and application of new image technologies are expanding rapidly. In conclusion, this work shows a general and up-to-date picture of the various continuing progresses, either for depth or for width, of image engineering in China in 2023. The statistics for 29 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics
摘要:This is the 29th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Specifically, considering the wide distribution of related publications in China, all references (865) on image engineering research and technique are selected carefully from the research papers (2 989 in total) published in all issues (154) of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 18 years). Analysis and discussions about the statistics of the results of classifications by journal and by category are also presented. Analysis on the statistics in 2023 shows that: from a research perspective, image analysis has currently received the most attention, with image segmentation and primitive detection, object detection and recognition, as well as human biometric feature extraction and validation being the focus of research; from an application perspective, remote sensing, radar, sonar, surveying and mapping are the most active fields, and the development and application of new image technologies are expanding rapidly. In conclusion, this work shows a general and up-to-date picture of the various continuing progresses, either for depth or for width, of image engineering in China in 2023. The statistics for 29 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics- 3
- |
- 0
- |
- 0
发布时间:2024-05-15 -
 摘要:The new display industry is an important foundation for strategic emerging information industries. Under the active guidance and continuous investment of various national industrial policies, China’s new display industry has rapidly developed and has become one of the most dynamic industries. The industry scale accounts for up to 40% of the global display industry, ranking first in the world. Under the background of the current digital information age, the demand for consumer electronics, such as smart phones, tablets, computers, displays, and televisions, in various occasions, is constantly rising. This phenomenon results in a yearly rising trend in the global demand for liquid crystal display (LCD) and organic light-emitting diode (OLED) screens and other display panels. The manufacturing process of LCD and OLED is complex, and every stage of the production process will inevitably produce various defects, affecting the visual effect and user experience and even leading to serious quality problems. Fast and accurate defect detection is crucial to improving product quality and production efficiency. Therefore, the defect detection in the production process of LCD and OLED is necessary. This article reviews the research progress of defect detection methods for LCD/OLED based on machine vision in the past 20 years to provide valuable reference. First, the structure and manufacturing process of commonly used TFT-LCD and OLED are given. The defects on the surface of the LCD/OLED are classified in accordance with the causes of defects, defect size, and defect shape. The definitions of the defects are presented, and the causes of the defects are briefly described. The quantitative indicators of defects SEMU and DSEMU are given. The difficulties of surface defect detection of LCD/OLED screens based on machine vision are also explained. This paper focuses on the defect detection methods based on image processing. In actual production, the images to be detected are captured by industrial cameras, and their images are easily affected by noise and light source. First, the image preprocessing of image denoising and image brightness correction is introduced. Then, eliminating the interference of texture background before segmentation and localization of defects is necessary due to the texture background of the collected LCD/OLED images. The repetitive texture background elimination is elaborated, and the defect detection method based on background suppression method is introduced from the three methods of polynomial fitting, discrete cosine transform, and statistical analysis. The measurement standards of background suppression are also presented. Mura defects are characterized by low contrast, blurred edges, and irregular shape. Thus, traditional edge detection and threshold segmentation methods are unsuitable for Mura defect segmentation, and achieving reliable detection of Mura defects is difficult. Therefore, improved defect segmentation methods are introduced in three sections: threshold and cluster segmentation, active contour model-based method, and edge and shape detection. The evaluation indexes of defect segmentation effects are also given. Image features are the most basic attributes that characterize an image. One of the methods of defect detection is extracting and classifying local or global features of images. The defect detection methods based on feature recognition, which extract image features and use traditional machine learning such as support vector machine, support vector data description, fuzzy pattern recognition, and random forest, are explained. Considering the traditional feature extraction method or the classical background reconstruction method, the missing rate of low contrast and small area defects is still substantially high. The traditional defect detection is conducted in multiple steps, which leads to the loss of defect information, resulting in the absence of low contrast defect and restricting the detection accuracy. The poor expression capability of manually extracted features also leads to the limitation of detection accuracy. In recent years, deep learning has achieved remarkable success in object detection, which can achieve fast and accurate target identification and detection. Thus, an increasing number of scholars have applied this method to the defect detection of LCD/OLED. This paper reviews the defect detection methods based on deep learning. According to the number of samples in different periods of production line, unsupervised and supervised learning, as well as transfer learning and defect sample generation methods are summarized. Unsupervised learning based on deep learning includes generative adversarial network and auto-encoder to learn the defect-free samples, reconstruct the defective image in the test, and obtain the residual image for defect detection. Supervised learning requires a large number of defect samples to overcome the problems of texture background interference, different defect sizes, and uneven samples. No public dataset based on display defects is currently available. This paper summarizes a series of general texture surface defect data sets that can be used for texture-based background defect detection, which can be employed for transfer learning and algorithm universality verification, and evaluation indicators of model performance are introduced. Finally, the existing problems in the current LCD/OLED defect detection methods are identified. Complex background problems are still unavoidable in the detection process due to the detection difficulties caused by the characteristics of Mura defects such as low contrast and blurred edges. Limited datasets and real-time algorithm problems are also encountered. The future research direction is prospected, and important research directions in the future include dataset expansion, sample equalization, enhanced algorithm generality, transferable algorithm, deep learning model acceleration, and curved screen defect detection. Such research direction may considerably promote the application of machine vision technology in LCD/ OLED defect detection.关键词:defect detection;liquid crystal display(LCD);organic light emitting diode (OLED);machine vision;deep learning;texture background elimination;unsupervised learning
摘要:The new display industry is an important foundation for strategic emerging information industries. Under the active guidance and continuous investment of various national industrial policies, China’s new display industry has rapidly developed and has become one of the most dynamic industries. The industry scale accounts for up to 40% of the global display industry, ranking first in the world. Under the background of the current digital information age, the demand for consumer electronics, such as smart phones, tablets, computers, displays, and televisions, in various occasions, is constantly rising. This phenomenon results in a yearly rising trend in the global demand for liquid crystal display (LCD) and organic light-emitting diode (OLED) screens and other display panels. The manufacturing process of LCD and OLED is complex, and every stage of the production process will inevitably produce various defects, affecting the visual effect and user experience and even leading to serious quality problems. Fast and accurate defect detection is crucial to improving product quality and production efficiency. Therefore, the defect detection in the production process of LCD and OLED is necessary. This article reviews the research progress of defect detection methods for LCD/OLED based on machine vision in the past 20 years to provide valuable reference. First, the structure and manufacturing process of commonly used TFT-LCD and OLED are given. The defects on the surface of the LCD/OLED are classified in accordance with the causes of defects, defect size, and defect shape. The definitions of the defects are presented, and the causes of the defects are briefly described. The quantitative indicators of defects SEMU and DSEMU are given. The difficulties of surface defect detection of LCD/OLED screens based on machine vision are also explained. This paper focuses on the defect detection methods based on image processing. In actual production, the images to be detected are captured by industrial cameras, and their images are easily affected by noise and light source. First, the image preprocessing of image denoising and image brightness correction is introduced. Then, eliminating the interference of texture background before segmentation and localization of defects is necessary due to the texture background of the collected LCD/OLED images. The repetitive texture background elimination is elaborated, and the defect detection method based on background suppression method is introduced from the three methods of polynomial fitting, discrete cosine transform, and statistical analysis. The measurement standards of background suppression are also presented. Mura defects are characterized by low contrast, blurred edges, and irregular shape. Thus, traditional edge detection and threshold segmentation methods are unsuitable for Mura defect segmentation, and achieving reliable detection of Mura defects is difficult. Therefore, improved defect segmentation methods are introduced in three sections: threshold and cluster segmentation, active contour model-based method, and edge and shape detection. The evaluation indexes of defect segmentation effects are also given. Image features are the most basic attributes that characterize an image. One of the methods of defect detection is extracting and classifying local or global features of images. The defect detection methods based on feature recognition, which extract image features and use traditional machine learning such as support vector machine, support vector data description, fuzzy pattern recognition, and random forest, are explained. Considering the traditional feature extraction method or the classical background reconstruction method, the missing rate of low contrast and small area defects is still substantially high. The traditional defect detection is conducted in multiple steps, which leads to the loss of defect information, resulting in the absence of low contrast defect and restricting the detection accuracy. The poor expression capability of manually extracted features also leads to the limitation of detection accuracy. In recent years, deep learning has achieved remarkable success in object detection, which can achieve fast and accurate target identification and detection. Thus, an increasing number of scholars have applied this method to the defect detection of LCD/OLED. This paper reviews the defect detection methods based on deep learning. According to the number of samples in different periods of production line, unsupervised and supervised learning, as well as transfer learning and defect sample generation methods are summarized. Unsupervised learning based on deep learning includes generative adversarial network and auto-encoder to learn the defect-free samples, reconstruct the defective image in the test, and obtain the residual image for defect detection. Supervised learning requires a large number of defect samples to overcome the problems of texture background interference, different defect sizes, and uneven samples. No public dataset based on display defects is currently available. This paper summarizes a series of general texture surface defect data sets that can be used for texture-based background defect detection, which can be employed for transfer learning and algorithm universality verification, and evaluation indicators of model performance are introduced. Finally, the existing problems in the current LCD/OLED defect detection methods are identified. Complex background problems are still unavoidable in the detection process due to the detection difficulties caused by the characteristics of Mura defects such as low contrast and blurred edges. Limited datasets and real-time algorithm problems are also encountered. The future research direction is prospected, and important research directions in the future include dataset expansion, sample equalization, enhanced algorithm generality, transferable algorithm, deep learning model acceleration, and curved screen defect detection. Such research direction may considerably promote the application of machine vision technology in LCD/ OLED defect detection.关键词:defect detection;liquid crystal display(LCD);organic light emitting diode (OLED);machine vision;deep learning;texture background elimination;unsupervised learning- 5
- |
- 0
- |
- 0
发布时间:2024-05-15 -
 摘要:RGB-D images contain rich multilevel features, such as low-level line, planar, and high-level semantic features. These different levels of features provide valuable information for various computer vision tasks. Computer vision algorithms can extract meaningful information from RGB-D images and improve the performance of various tasks, including object detection, tracking, and indoor scene reconstruction, by leveraging these multilevel features. Terms such as feature and contour lines can be used when describing existing line features in a single RGB-D image. Line features provide crucial information regarding the spatial relationships and boundaries in the input image, aiding in the understanding and interpretation of input data. Plane and surface are used to describe planar features and those refer to flat or nearly flat regions in the RGB-D image. Terms such as instance and semantic labels can be used when describing an object. Instance labels refer to unique identifiers or labels assigned to individual instances or occurrences of objects in an image, while semantic labels represent the broad class or category to which an object belongs. Semantic labels provide a high-level understanding of the objects in the image, grouping them into meaningful categories that indicate the general type of object present. Traditional methods for extracting line features often utilize color, texture information of RGB image, and geometric information in the depth image to extract feature and contour lines. The extraction of planar features involves clustering to extract sets of points with similar properties, further facilitating planar feature extraction. Semantic feature extraction aims to assign specific semantic categories to each pixel in the RGB-D input, and most of the methods used for this task are implemented based on deep learning. The multilevel feature extraction results for RGB-D images can be used as prior knowledge aids such as indoor scene reconstruction, scene understanding, object recognition, and other tasks to improve the quality of network output. Multilevel feature extraction for RGB-D images is also one of the popular topics in the field of computer graphics. With the development and popularization of commercial depth cameras, acquiring RGB-D data has become increasingly convenient. However, the quality of captured RGB-D data is often compromised by environmental and human factors during the acquisition process. This phenomenon leads to issues such as noise and depth absence, which, in turn, negatively affects the quality of multilevel feature extraction results to some extent. These problems are detrimental to traditional methods, but the emergence of deep learning approaches has overcome these issues to a certain extent. With the rapid development of deep learning technology, numerous high-quality research results have emerged for multilevel feature extraction tasks based on deep learning. The commonly used RGB-D datasets for multilevel feature extraction tasks, such as NYU v2 and SUN RGB-D, are summarized in this paper. These datasets contain diverse scene data, comprising RGB images paired with corresponding depth images. Taking NYU v2 as an example, the dataset includes 1 499 RGB-D images, derived from 464 distinct indoor scenes across 26 scene classes. After introducing the datasets, this paper provides a summary of commonly used evaluation criteria for assessing the quality of line, planar, and semantic features. Detailed explanations are presented for the computation method of each evaluation criterion. When reviewing line feature extraction methods, a comprehensive summary based on traditional and deep learning approaches is presented. Detailed explanations of the principles, advantages, and limitations of different methods are provided. Furthermore, quantitative comparisons of the extraction results from several different methods are conducted. When summarizing planar feature extraction methods, a comprehensive overview is provided from two perspectives: traditional and deep learning-based planar feature extraction methods. Relevant research papers are gathered, and a quality comparison of planar feature extraction methods is then conducted. Additionally, detailed explanations of the advantages and limitations of each method are provided. A comprehensive review of deep learning-based semantic feature extraction methods is presented in this paper from two aspects: fully-supervised and semi-supervised learning-based semantic feature extraction methods. Relevant research papers are also summarized. When comparing different semantic feature extraction methods, this paper used evaluation metrics such as pixel accuracy (PA), mean PA (MPA), and mean intersection over union (mIoU) to measure the quality of the extraction algorithms. The results of the quantitative comparisons revealed that semantic feature extraction methods oriented toward RGB-D data exhibit superior extraction quality. These comparison results prove that feature extraction methods designed specifically for RGB-D data can achieve better results compared to methods that only utilize RGB data. The incorporation of depth information in RGB-D data facilitates accurate and robust extraction of semantic features, leading to enhanced performance in various tasks such as scene understanding and object recognition. Data annotation has certainly been a challenge for feature extraction methods based on deep learning. Annotating large-scale datasets requires considerable time and human resources. Researchers have been actively seeking ways to reduce the workload of data annotation or maximize existing annotated data to overcome these challenges. Therefore, unsupervised, semi-supervised, and transfer learning are widely investigated to leverage unlabeled or sparsely labeled data for feature extraction. Finally, the problems of the current multilevel feature extraction algorithm that must be addressed are discussed to provide guidance to the future development trend at the end of this paper.关键词:RGB-D images;multilevel features;line features;planar features;semantic features;feature extraction
摘要:RGB-D images contain rich multilevel features, such as low-level line, planar, and high-level semantic features. These different levels of features provide valuable information for various computer vision tasks. Computer vision algorithms can extract meaningful information from RGB-D images and improve the performance of various tasks, including object detection, tracking, and indoor scene reconstruction, by leveraging these multilevel features. Terms such as feature and contour lines can be used when describing existing line features in a single RGB-D image. Line features provide crucial information regarding the spatial relationships and boundaries in the input image, aiding in the understanding and interpretation of input data. Plane and surface are used to describe planar features and those refer to flat or nearly flat regions in the RGB-D image. Terms such as instance and semantic labels can be used when describing an object. Instance labels refer to unique identifiers or labels assigned to individual instances or occurrences of objects in an image, while semantic labels represent the broad class or category to which an object belongs. Semantic labels provide a high-level understanding of the objects in the image, grouping them into meaningful categories that indicate the general type of object present. Traditional methods for extracting line features often utilize color, texture information of RGB image, and geometric information in the depth image to extract feature and contour lines. The extraction of planar features involves clustering to extract sets of points with similar properties, further facilitating planar feature extraction. Semantic feature extraction aims to assign specific semantic categories to each pixel in the RGB-D input, and most of the methods used for this task are implemented based on deep learning. The multilevel feature extraction results for RGB-D images can be used as prior knowledge aids such as indoor scene reconstruction, scene understanding, object recognition, and other tasks to improve the quality of network output. Multilevel feature extraction for RGB-D images is also one of the popular topics in the field of computer graphics. With the development and popularization of commercial depth cameras, acquiring RGB-D data has become increasingly convenient. However, the quality of captured RGB-D data is often compromised by environmental and human factors during the acquisition process. This phenomenon leads to issues such as noise and depth absence, which, in turn, negatively affects the quality of multilevel feature extraction results to some extent. These problems are detrimental to traditional methods, but the emergence of deep learning approaches has overcome these issues to a certain extent. With the rapid development of deep learning technology, numerous high-quality research results have emerged for multilevel feature extraction tasks based on deep learning. The commonly used RGB-D datasets for multilevel feature extraction tasks, such as NYU v2 and SUN RGB-D, are summarized in this paper. These datasets contain diverse scene data, comprising RGB images paired with corresponding depth images. Taking NYU v2 as an example, the dataset includes 1 499 RGB-D images, derived from 464 distinct indoor scenes across 26 scene classes. After introducing the datasets, this paper provides a summary of commonly used evaluation criteria for assessing the quality of line, planar, and semantic features. Detailed explanations are presented for the computation method of each evaluation criterion. When reviewing line feature extraction methods, a comprehensive summary based on traditional and deep learning approaches is presented. Detailed explanations of the principles, advantages, and limitations of different methods are provided. Furthermore, quantitative comparisons of the extraction results from several different methods are conducted. When summarizing planar feature extraction methods, a comprehensive overview is provided from two perspectives: traditional and deep learning-based planar feature extraction methods. Relevant research papers are gathered, and a quality comparison of planar feature extraction methods is then conducted. Additionally, detailed explanations of the advantages and limitations of each method are provided. A comprehensive review of deep learning-based semantic feature extraction methods is presented in this paper from two aspects: fully-supervised and semi-supervised learning-based semantic feature extraction methods. Relevant research papers are also summarized. When comparing different semantic feature extraction methods, this paper used evaluation metrics such as pixel accuracy (PA), mean PA (MPA), and mean intersection over union (mIoU) to measure the quality of the extraction algorithms. The results of the quantitative comparisons revealed that semantic feature extraction methods oriented toward RGB-D data exhibit superior extraction quality. These comparison results prove that feature extraction methods designed specifically for RGB-D data can achieve better results compared to methods that only utilize RGB data. The incorporation of depth information in RGB-D data facilitates accurate and robust extraction of semantic features, leading to enhanced performance in various tasks such as scene understanding and object recognition. Data annotation has certainly been a challenge for feature extraction methods based on deep learning. Annotating large-scale datasets requires considerable time and human resources. Researchers have been actively seeking ways to reduce the workload of data annotation or maximize existing annotated data to overcome these challenges. Therefore, unsupervised, semi-supervised, and transfer learning are widely investigated to leverage unlabeled or sparsely labeled data for feature extraction. Finally, the problems of the current multilevel feature extraction algorithm that must be addressed are discussed to provide guidance to the future development trend at the end of this paper.关键词:RGB-D images;multilevel features;line features;planar features;semantic features;feature extraction- 2
- |
- 0
- |
- 0
发布时间:2024-05-15
Review
-
 摘要:ObjectiveVehicle re-identification (Re-ID) is a technology that uses computer vision technology to determine whether a specific target vehicle exists in an image or video sequence, which is considered a subproblem of image retrieval. Vehicle Re-ID technology can be used to monitor specific abandoned vehicles and prevent driving escape and is widely applied in the fields of intelligent surveillance and transportation. The previous methods mainly focused on supervised training in a single domain. If the effective Re-ID model in the single domain is transferred to an unlabeled new domain for testing, retrieval accuracy will significantly decrease. Some researchers have gradually proposed many cross-domain-based Re-ID methods to alleviate the manual annotation cost of massive surveillance data. This study aims to transfer the trained supervised Re-ID model from the labeled source domain to the unlabeled target domain for clustering. The entire transfer process uses unsupervised iteration and update of model parameters, thereby achieving the goal of reducing manual annotation costs. However, the existing cross-domain Re-ID tasks generally have two main challenges: on the one hand, the existing cross-domain Re-ID methods focus too much on the performance of the target domain, often neglecting the old knowledge previously learned in the source domain, which will cause catastrophic forgetting of the old knowledge. On the other hand, the large deviation between the source and target domains will directly affect the generalization ability of the Re-ID model mainly because of the significant differences in data distribution and domain attributes in different domains. Hence, a vehicle Re-ID method based on cross-domain joint learning and a shared subspace metric is proposed to overcome the above challenges.MethodFirst, a cross-confidence soft cluster is designed in cross-domain joint learning to establish the inter-domain correlation between the source and target domains. The cross-confidence soft cluster aims to introduce prior knowledge of the source domain data into the target domain by calculating the confidence level of the cross mean. The cluster also aims to jointly perform soft clustering, thereby effectively integrating prior knowledge of the source domain with new knowledge of the target domain. The training data are re-labeled with pseudo labels based on the cross-mean confidence of each type of source domain data. Moreover, the supervised information generated by the soft clustering results is ultimately retained to preserve old knowledge and generalize new knowledge. Then, a salient-aware attention mechanism is proposed to obtain the salient features of vehicles. The salient-aware attention mechanism module is embedded into the reference network to improve the Re-ID model’s ability to identify significant regions of vehicles in the channel and spatial dimensions. Then, the expression of vehicle significant region features is improved by calculating the channel and spatial weight factors. For the channel weight factor, a convolution operation with a convolution kernel of 1 is used to compress the channel dimensions of the feature matrix, and the importance of each channel in the feature matrix is calculated in a self-aware manner. In addition, global average pooling is applied to the feature matrix to prevent the loss of some channel spatial information when compressing channel dimensions. Moreover, further refined channel style attention is jointly inferred by considering channel self-attention and channel-by-channel spatial information. The original and salient features are mapped into a shared subspace, and the shared metric factors are obtained through the Jaccard distance of their respective global and local regions. Finally, a shared metric factor is used to smooth global and local pseudo-labels based on the results of cross-confidence soft clustering to further alleviate the label noise caused by domain bias. This approach enables the training model to learn further discriminating features. The proposed method in this study is trained in the Python 3.7 and Python 1.6.0 frameworks, with an operating system of Ubuntu 18.04 and CUDA 11.2. The hardware configuration is an Intel (R) Xeon (R) Silver 4210 CPU @ 2.20 GHz model CPU, a Tesla V100 graphics card with 32 GB of graphics memory, and a running memory of 64 GB. The whole training uses ResNet-50 as the baseline model, and the size of the input image is uniformly cropped to 224 × 124 pixels. The total number of training iteration epochs is 50, and the batch size is set to 64. The pre-training model on ImageNet is used as the initialization model in this study, and the initial learning rate is set to 0.000 35. Moreover, stochastic gradient descent (SGD) is used to iterate and optimize the model weight.ResultExperimental comparisons are conducted on three public vehicle Re-ID datasets, the vehicle Re-ID-776 dataset (VeRi-776), the large-scale vehicle Re-ID dataset (VehicleID), and the vehicle Re-ID dataset in the wild (VeRi-Wild), with the latest existing methods. This study uses rank-1 accuracy (Rank-1) and mean average precision (mAP) as evaluation indicators. The proposed method achieved a Rank-1 accuracy of 42.40%, 41.70%, 56.40%, and 61.90% in the target domain in the cross-domain tasks of VeRi-776→VeRi-Wild, VeRi-Wild→VeRi-776, VeRi-776→VehicleID, and VehicleID→VeRi-776, respectively. The accuracy of mAP is 22.50%, 23.10%, 41.50%, and 49.10%, respectively. The method also achieved a Rank-1 accuracy of 84.60%, 84.00%, 77.10%, and 67.00%, respectively, in accumulating old knowledge representation in the source domain. The mAP accuracy is 55.80%, 44.80%, 46.50%, and 30.70%, respectively. In addition, a series of experiments is conducted to further demonstrate the robustness of the proposed method in cross-domain tasks, including ablation comparison of different modules, comparison of different training methods, comparison of outliers and visualization of attention maps, comparison of rank lists, and comparison of t-distributed stochastic neighbor embedding (t-SNE) visualization.ConclusionIn this study, compared with unsupervised domain adaptive and unsupervised hybrid domain methods, the proposed method can effectively alleviate the problem of large domain deviation while accumulating cross-domain knowledge, thereby improving the performance of vehicle Re-ID tasks.关键词:vehicle re-identification;cross-domain joint learning(CJL);cross-confidence soft clustering;shared subspace metric(SSM);salient-aware attention mechanism;pseudo label smoothing
摘要:ObjectiveVehicle re-identification (Re-ID) is a technology that uses computer vision technology to determine whether a specific target vehicle exists in an image or video sequence, which is considered a subproblem of image retrieval. Vehicle Re-ID technology can be used to monitor specific abandoned vehicles and prevent driving escape and is widely applied in the fields of intelligent surveillance and transportation. The previous methods mainly focused on supervised training in a single domain. If the effective Re-ID model in the single domain is transferred to an unlabeled new domain for testing, retrieval accuracy will significantly decrease. Some researchers have gradually proposed many cross-domain-based Re-ID methods to alleviate the manual annotation cost of massive surveillance data. This study aims to transfer the trained supervised Re-ID model from the labeled source domain to the unlabeled target domain for clustering. The entire transfer process uses unsupervised iteration and update of model parameters, thereby achieving the goal of reducing manual annotation costs. However, the existing cross-domain Re-ID tasks generally have two main challenges: on the one hand, the existing cross-domain Re-ID methods focus too much on the performance of the target domain, often neglecting the old knowledge previously learned in the source domain, which will cause catastrophic forgetting of the old knowledge. On the other hand, the large deviation between the source and target domains will directly affect the generalization ability of the Re-ID model mainly because of the significant differences in data distribution and domain attributes in different domains. Hence, a vehicle Re-ID method based on cross-domain joint learning and a shared subspace metric is proposed to overcome the above challenges.MethodFirst, a cross-confidence soft cluster is designed in cross-domain joint learning to establish the inter-domain correlation between the source and target domains. The cross-confidence soft cluster aims to introduce prior knowledge of the source domain data into the target domain by calculating the confidence level of the cross mean. The cluster also aims to jointly perform soft clustering, thereby effectively integrating prior knowledge of the source domain with new knowledge of the target domain. The training data are re-labeled with pseudo labels based on the cross-mean confidence of each type of source domain data. Moreover, the supervised information generated by the soft clustering results is ultimately retained to preserve old knowledge and generalize new knowledge. Then, a salient-aware attention mechanism is proposed to obtain the salient features of vehicles. The salient-aware attention mechanism module is embedded into the reference network to improve the Re-ID model’s ability to identify significant regions of vehicles in the channel and spatial dimensions. Then, the expression of vehicle significant region features is improved by calculating the channel and spatial weight factors. For the channel weight factor, a convolution operation with a convolution kernel of 1 is used to compress the channel dimensions of the feature matrix, and the importance of each channel in the feature matrix is calculated in a self-aware manner. In addition, global average pooling is applied to the feature matrix to prevent the loss of some channel spatial information when compressing channel dimensions. Moreover, further refined channel style attention is jointly inferred by considering channel self-attention and channel-by-channel spatial information. The original and salient features are mapped into a shared subspace, and the shared metric factors are obtained through the Jaccard distance of their respective global and local regions. Finally, a shared metric factor is used to smooth global and local pseudo-labels based on the results of cross-confidence soft clustering to further alleviate the label noise caused by domain bias. This approach enables the training model to learn further discriminating features. The proposed method in this study is trained in the Python 3.7 and Python 1.6.0 frameworks, with an operating system of Ubuntu 18.04 and CUDA 11.2. The hardware configuration is an Intel (R) Xeon (R) Silver 4210 CPU @ 2.20 GHz model CPU, a Tesla V100 graphics card with 32 GB of graphics memory, and a running memory of 64 GB. The whole training uses ResNet-50 as the baseline model, and the size of the input image is uniformly cropped to 224 × 124 pixels. The total number of training iteration epochs is 50, and the batch size is set to 64. The pre-training model on ImageNet is used as the initialization model in this study, and the initial learning rate is set to 0.000 35. Moreover, stochastic gradient descent (SGD) is used to iterate and optimize the model weight.ResultExperimental comparisons are conducted on three public vehicle Re-ID datasets, the vehicle Re-ID-776 dataset (VeRi-776), the large-scale vehicle Re-ID dataset (VehicleID), and the vehicle Re-ID dataset in the wild (VeRi-Wild), with the latest existing methods. This study uses rank-1 accuracy (Rank-1) and mean average precision (mAP) as evaluation indicators. The proposed method achieved a Rank-1 accuracy of 42.40%, 41.70%, 56.40%, and 61.90% in the target domain in the cross-domain tasks of VeRi-776→VeRi-Wild, VeRi-Wild→VeRi-776, VeRi-776→VehicleID, and VehicleID→VeRi-776, respectively. The accuracy of mAP is 22.50%, 23.10%, 41.50%, and 49.10%, respectively. The method also achieved a Rank-1 accuracy of 84.60%, 84.00%, 77.10%, and 67.00%, respectively, in accumulating old knowledge representation in the source domain. The mAP accuracy is 55.80%, 44.80%, 46.50%, and 30.70%, respectively. In addition, a series of experiments is conducted to further demonstrate the robustness of the proposed method in cross-domain tasks, including ablation comparison of different modules, comparison of different training methods, comparison of outliers and visualization of attention maps, comparison of rank lists, and comparison of t-distributed stochastic neighbor embedding (t-SNE) visualization.ConclusionIn this study, compared with unsupervised domain adaptive and unsupervised hybrid domain methods, the proposed method can effectively alleviate the problem of large domain deviation while accumulating cross-domain knowledge, thereby improving the performance of vehicle Re-ID tasks.关键词:vehicle re-identification;cross-domain joint learning(CJL);cross-confidence soft clustering;shared subspace metric(SSM);salient-aware attention mechanism;pseudo label smoothing- 2
- |
- 0
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveText detection and recognition of natural scenes is a long-standing and challenging problem. Hence, this study aims to detect and recognize text information in natural scene images. Owing to its wide applications (e.g., traffic sign recognition and content-based image retrieval), text detection and recognition has attracted much attention in the field of computer vision. The traditional scene text detection and recognition method regards detection and recognition as two independent tasks. This method first locates and then clips to predict the text area of the input image and to clip the relevant area and then sends the clipped area into the recognizer for recognition. However, this process has some limitations, such as: 1) inaccurate detection results may seriously affect the performance of image text recognition owing to the accumulation of errors between the two tasks, and 2) the separate optimization of the two tasks may not improve the results of text recognition. In recent years, the end-to-end scene text recognition task based on deep learning has made great progress. Many studies have found that detection and recognition are closely related. End-to-end recognition, which integrates detection and recognition tasks, can promote each other and gradually become an important research direction. In the end-to-end recognition task, the natural scene image contains disturbing factors, such as light, deformation, and stain. In addition, scene text can be represented by different colors, fonts, sizes, directions, and shapes, making text detection very difficult. Limited by multi-scale, arbitrary shapes, background interference, and other issues, most end-to-end text recognizers still face the problem of incomplete mask proposals, which will affect the text recognition results of the model. Hence, we propose a mask embedding module (SAME) based on soft attention to improve the accuracy of mask prediction. This module effectively improves the robustness and accuracy of the model.MethodHigh-level features are coded, and soft attention is calculated using the global receptive field of Transformer. Then, the coding features and prediction mask are embedded to generate a mask close to the text boundary to suppress background noise. Based on these designs, we propose a simple and robust end-to-end text recognition framework, SAME-Net, because soft attention is differentiable. The proposed SAME module can propagate the recognition loss back to the detection branch to guide the text detection by learning the weight of attention so that the detection and recognition targets can jointly optimize the detection branch. SAME-Net does not need additional recognition modules, nor does it need to annotate the text at the character level.ResultThis method can effectively detect multi-scale and arbitrarily shaped text. The recall rate, accuracy rate, and H-mean value on the public arbitrarily shaped data set Total-Text are 0.884 8 and 0.879 6. Compared with the best results in the comparison method, without adding further training data, the recognition accuracy rate without dictionary guidance is increased by 2.36%, and the recognition accuracy rate of the full dictionary is increased by 5.62%. In terms of detection, the recall rate and H-mean value of this method increased from 0.868 to 0.884 8 and from 0.861 to 0.879 6, respectively, which greatly exceeded the previous method in terms of end-to-end recognition. Both obtained 83.4% strong dictionary recognition results in the multi-directional dataset ICDAR 2015(International Conference on Document Analysis and Recognition). In short, our method is superior to others.ConclusionThe performance of SAME-Net proposed in this study has significantly improved on the two scene text data machines of ICDAR 2015 and Total-Text. The best results in this task were obtained. This study proposes an end-to-end text recognition method based on SAME. The proposed method has two advantages. First, the method uses the global receptive field of Transformer to embed high-level coding features and prediction mask levels to generate a mask close to the text boundary to suppress background noise. Second, the proposed SAME module can reverse transmit the recognition loss to the detection module, and no additional text correction module is needed. Great text positioning performance can be achieved without character-level comments through the joint optimization of the detection and recognition modules.关键词:natural scene text detection;natural scene text recognition;soft attention embedding;deep learning;end-to-end natural scene text detection and recognition
摘要:ObjectiveText detection and recognition of natural scenes is a long-standing and challenging problem. Hence, this study aims to detect and recognize text information in natural scene images. Owing to its wide applications (e.g., traffic sign recognition and content-based image retrieval), text detection and recognition has attracted much attention in the field of computer vision. The traditional scene text detection and recognition method regards detection and recognition as two independent tasks. This method first locates and then clips to predict the text area of the input image and to clip the relevant area and then sends the clipped area into the recognizer for recognition. However, this process has some limitations, such as: 1) inaccurate detection results may seriously affect the performance of image text recognition owing to the accumulation of errors between the two tasks, and 2) the separate optimization of the two tasks may not improve the results of text recognition. In recent years, the end-to-end scene text recognition task based on deep learning has made great progress. Many studies have found that detection and recognition are closely related. End-to-end recognition, which integrates detection and recognition tasks, can promote each other and gradually become an important research direction. In the end-to-end recognition task, the natural scene image contains disturbing factors, such as light, deformation, and stain. In addition, scene text can be represented by different colors, fonts, sizes, directions, and shapes, making text detection very difficult. Limited by multi-scale, arbitrary shapes, background interference, and other issues, most end-to-end text recognizers still face the problem of incomplete mask proposals, which will affect the text recognition results of the model. Hence, we propose a mask embedding module (SAME) based on soft attention to improve the accuracy of mask prediction. This module effectively improves the robustness and accuracy of the model.MethodHigh-level features are coded, and soft attention is calculated using the global receptive field of Transformer. Then, the coding features and prediction mask are embedded to generate a mask close to the text boundary to suppress background noise. Based on these designs, we propose a simple and robust end-to-end text recognition framework, SAME-Net, because soft attention is differentiable. The proposed SAME module can propagate the recognition loss back to the detection branch to guide the text detection by learning the weight of attention so that the detection and recognition targets can jointly optimize the detection branch. SAME-Net does not need additional recognition modules, nor does it need to annotate the text at the character level.ResultThis method can effectively detect multi-scale and arbitrarily shaped text. The recall rate, accuracy rate, and H-mean value on the public arbitrarily shaped data set Total-Text are 0.884 8 and 0.879 6. Compared with the best results in the comparison method, without adding further training data, the recognition accuracy rate without dictionary guidance is increased by 2.36%, and the recognition accuracy rate of the full dictionary is increased by 5.62%. In terms of detection, the recall rate and H-mean value of this method increased from 0.868 to 0.884 8 and from 0.861 to 0.879 6, respectively, which greatly exceeded the previous method in terms of end-to-end recognition. Both obtained 83.4% strong dictionary recognition results in the multi-directional dataset ICDAR 2015(International Conference on Document Analysis and Recognition). In short, our method is superior to others.ConclusionThe performance of SAME-Net proposed in this study has significantly improved on the two scene text data machines of ICDAR 2015 and Total-Text. The best results in this task were obtained. This study proposes an end-to-end text recognition method based on SAME. The proposed method has two advantages. First, the method uses the global receptive field of Transformer to embed high-level coding features and prediction mask levels to generate a mask close to the text boundary to suppress background noise. Second, the proposed SAME module can reverse transmit the recognition loss to the detection module, and no additional text correction module is needed. Great text positioning performance can be achieved without character-level comments through the joint optimization of the detection and recognition modules.关键词:natural scene text detection;natural scene text recognition;soft attention embedding;deep learning;end-to-end natural scene text detection and recognition- 3
- |
- 1
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveAction recognition has become increasingly important in industrial manufacturing. Production efficiency and quality can be improved by recognizing worker actions and postures in complex production environments. In recent years, action recognition based on skeletal data has received widespread attention and research, with methods mainly based on graph convolutional networks (GCN) or long short-term memory (LSTM) networks exhibiting excellent recognition performance in experiments. However, these methods have not considered the recognition problems of occlusion, viewpoint changes, and similar subtle actions in the factory environment, which may have a significant impact on subsequent action recognition. Therefore, this study proposes a packing behavior recognition method that combines a dual-view skeleton multi-stream network.MethodThe network model consists of a main network and a sub-network. The main network uses two RGB videos from different perspectives as input and records the input of workers at the same time and action. Subsequently, the image difference method is used to convert the input video data into a difference image. Moreover, the 3D skeleton information of the character is extracted from the depth map by using the 3D pose estimation algorithm and then transmitted to the subsequent viewing angle conversion module. In the perspective conversion module, the rotation of the bone data is used to find the best viewing angle, and the converted skeleton data are passed into a three-layer stacked LSTM network. The different classification scores of the weighted fusion are obtained for the recognition results of the main network. In addition, for some similar behaviors and non-compliant “fake actions”, we use a local positioning image convolution network combined with an attention mechanism and pass it into the ResNeXt network for recognition. Moreover, we introduce a spatio-temporal attention mechanism for analyzing video action recognition sequences to focus on the key frames of the skeleton sequence. The recognition scores of the main network and the sub-network are fused in proportion to obtain the final recognition result and predict the behavior of the person.ResultFirst, convolutional neural network (CNN)-based methods usually have better performance than recurrent neural network (RNN)-based ones, whereas GCN-based methods have middling performance. Moreover, CNN and RNN network structures are combined to improve the accuracy and recall rate to greatly explore the spatiotemporal information of skeletons. However, the method proposed in this study has an identification accuracy of packing behavior of 92.31% and a recall rate of 89.72%, which is still 3.96% and 3.81% higher than the accuracy, respectively. The proposed method is significantly ahead of other existing mainstream behavior recognition methods. Second, the method based on a difference image combined with a skeleton extraction algorithm can achieve an 87.6% accuracy, which is better than RGB as the input method of the original image, although the frame rate is reduced to 55.3 frames per second, which is still within the acceptable range. Third, considering the influence of the adaptive transformation module and the multi-view module on the experiment, we find that the recognition rate of the single-stream network with the adaptive transformation module is greatly improved, but the fps is slightly decreased. The experiment finds that the learning of the module is more inclined to observe the action from the front because the front observation can scatter the skeleton as much as possible compared with the side observation. The highest degree of mutual occlusion among bones was the worst observation effect. For dual view, simply fusing two different single-stream output results can improve the performance, and the weighted average method has the best effect, which is 3.83% and 3.03% higher than the accuracy of single-stream S1 and S2, respectively. Some actions have the problem of object occlusion and human self-occlusion under a certain shooting angle. The occlusion problem can be solved by two complementary views, that is, the occluded action can be well recognized in one of the views. In addition, evaluations were carried out on the public NTU RGB+D dataset, where the performance results outperformed other networks. This result further validates the effectiveness and accuracy of the proposed method in the study.ConclusionThis method uses a two-stream network model. The main network is an adaptive multi-view RNN network. Two depth cameras under complementary perspectives are used to collect the data from the same station, and the incoming RGB image is converted into a differential image for extracting skeleton information. Then, the skeleton data are passed into the adaptive view transformation module to obtain the best skeleton observation points, and the three-layer stacked LSTM network is used to obtain the recognition results. Finally, the weighted fusion of the two view features is used, and the main network solves the influence of occlusion and background clutter. The sub-network adds the hand image recognition of skeleton positioning, and the intercepted local positioning image is sent to the ResNeXt network for recognition to make up for the problem of insufficient accuracy of “fake action” and similar action recognition. Finally, the recognition results of the main network and the sub-network are fused. The human behavior recognition method proposed in this study effectively utilizes human behavior information from multiple views and combines skeleton network and CNN models to significantly improve the accuracy of behavior recognition.关键词:action recognition;long short-term memory(LSTM);dual-view;adaptive view transformation;attention mechanism
摘要:ObjectiveAction recognition has become increasingly important in industrial manufacturing. Production efficiency and quality can be improved by recognizing worker actions and postures in complex production environments. In recent years, action recognition based on skeletal data has received widespread attention and research, with methods mainly based on graph convolutional networks (GCN) or long short-term memory (LSTM) networks exhibiting excellent recognition performance in experiments. However, these methods have not considered the recognition problems of occlusion, viewpoint changes, and similar subtle actions in the factory environment, which may have a significant impact on subsequent action recognition. Therefore, this study proposes a packing behavior recognition method that combines a dual-view skeleton multi-stream network.MethodThe network model consists of a main network and a sub-network. The main network uses two RGB videos from different perspectives as input and records the input of workers at the same time and action. Subsequently, the image difference method is used to convert the input video data into a difference image. Moreover, the 3D skeleton information of the character is extracted from the depth map by using the 3D pose estimation algorithm and then transmitted to the subsequent viewing angle conversion module. In the perspective conversion module, the rotation of the bone data is used to find the best viewing angle, and the converted skeleton data are passed into a three-layer stacked LSTM network. The different classification scores of the weighted fusion are obtained for the recognition results of the main network. In addition, for some similar behaviors and non-compliant “fake actions”, we use a local positioning image convolution network combined with an attention mechanism and pass it into the ResNeXt network for recognition. Moreover, we introduce a spatio-temporal attention mechanism for analyzing video action recognition sequences to focus on the key frames of the skeleton sequence. The recognition scores of the main network and the sub-network are fused in proportion to obtain the final recognition result and predict the behavior of the person.ResultFirst, convolutional neural network (CNN)-based methods usually have better performance than recurrent neural network (RNN)-based ones, whereas GCN-based methods have middling performance. Moreover, CNN and RNN network structures are combined to improve the accuracy and recall rate to greatly explore the spatiotemporal information of skeletons. However, the method proposed in this study has an identification accuracy of packing behavior of 92.31% and a recall rate of 89.72%, which is still 3.96% and 3.81% higher than the accuracy, respectively. The proposed method is significantly ahead of other existing mainstream behavior recognition methods. Second, the method based on a difference image combined with a skeleton extraction algorithm can achieve an 87.6% accuracy, which is better than RGB as the input method of the original image, although the frame rate is reduced to 55.3 frames per second, which is still within the acceptable range. Third, considering the influence of the adaptive transformation module and the multi-view module on the experiment, we find that the recognition rate of the single-stream network with the adaptive transformation module is greatly improved, but the fps is slightly decreased. The experiment finds that the learning of the module is more inclined to observe the action from the front because the front observation can scatter the skeleton as much as possible compared with the side observation. The highest degree of mutual occlusion among bones was the worst observation effect. For dual view, simply fusing two different single-stream output results can improve the performance, and the weighted average method has the best effect, which is 3.83% and 3.03% higher than the accuracy of single-stream S1 and S2, respectively. Some actions have the problem of object occlusion and human self-occlusion under a certain shooting angle. The occlusion problem can be solved by two complementary views, that is, the occluded action can be well recognized in one of the views. In addition, evaluations were carried out on the public NTU RGB+D dataset, where the performance results outperformed other networks. This result further validates the effectiveness and accuracy of the proposed method in the study.ConclusionThis method uses a two-stream network model. The main network is an adaptive multi-view RNN network. Two depth cameras under complementary perspectives are used to collect the data from the same station, and the incoming RGB image is converted into a differential image for extracting skeleton information. Then, the skeleton data are passed into the adaptive view transformation module to obtain the best skeleton observation points, and the three-layer stacked LSTM network is used to obtain the recognition results. Finally, the weighted fusion of the two view features is used, and the main network solves the influence of occlusion and background clutter. The sub-network adds the hand image recognition of skeleton positioning, and the intercepted local positioning image is sent to the ResNeXt network for recognition to make up for the problem of insufficient accuracy of “fake action” and similar action recognition. Finally, the recognition results of the main network and the sub-network are fused. The human behavior recognition method proposed in this study effectively utilizes human behavior information from multiple views and combines skeleton network and CNN models to significantly improve the accuracy of behavior recognition.关键词:action recognition;long short-term memory(LSTM);dual-view;adaptive view transformation;attention mechanism- 3
- |
- 0
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveHuman pose estimation is a technology that can be widely used in life. In recent years, many excellent high-precision methods have been proposed, but they are often accompanied by a very large model scale, which will encounter the problem of computing power bottleneck in application. Whether for model training or deployment, large models require considerable computing power as the basis. Most of them have low computing power. Similarly, for the scenes in daily life, the equipment needs further applicability and detection speed of the model, which is difficult to achieve by large models. Given such requirements, lightweight human pose estimation has become a hot research field. The main problem is how to achieve high detection accuracy and fast detection speed under the extremely limited number of resources. Lightweight models will inevitably fall into a disadvantage in detection accuracy compared with large models. However, fortunately, from many studies in recent years, the lightweight model can also achieve higher detection accuracy than large ones. A good balance can be reached between them.MethodBased on a high-resolution network (HRNet), a lightweight high-resolution human pose estimation network combined with a dense connection network (LDHNet) was proposed. First, dense connection and multi-scale were integrated to construct a lightweight and efficient feature extraction unit by redesigning the stage branch structure in HRNet and proposing a new lightweight feature extraction module. Then, the feature extraction module is composed of modules similar to the pyramid structure, and the dilated convolution of three scales is used to obtain a wide range of feature information in the feature map by stacking the multi-layer feature extraction modules and fusing the output of each layer. The concatenation of the output feature map of the feature extraction module is to reuse the feature map and fully extract the information contained in the feature map. These two points can make up for the problem of insufficient utilization of feature information that may exist in the lightweight model and use limited resources to achieve high feature extraction performance. Second, a wide range of cross-branch feature information interactions exists in the original HRNet structure, including feature fusion and the generation of new branches in each stage. LDHNet replaces the convolution in this process with the depthwise separable convolution by changing the size of the feature map through convolution downsampling or upsampling to add with other branch feature maps for feature fusion. This case further reduces the number of parameters of the model based on almost no loss of detection performance. In addition, LDHNet improves the original data preprocessing module and uses the double-branch form to fully extract the information from the original image. Experiments show that considerable information from the original image is of great help to improve the detection performance of the model. LDHNet also uses coordinate attention to reinforce spatial location information.ResultAfter the above improvements, the size of the model has been greatly reduced to less than one-tenth of the original HRNet. Although some gap still exists between the model size and the current smallest lightweight model LiteHRNet, the design of the lightweight model is not only concerned with the size of the model. This study mainly compares LDHNet with mainstream lightweight models. Through experimental verification on two mainstream datasets of human pose estimation MPII and common objects in context(COCO) dataset and comparison with the current mainstream methods, the following conclusions can be obtained. Compared with the top-down lightweight human pose estimation LiteHRNet on the MPII test set, the average prediction accuracy of LDHNet is improved by 1.5% by only adding a small number of parameters and calculations. The results on the COCO validation set show that compared with LiteHRNet, the average detection accuracy of LDHNet is improved by 3.4%. Compared with the improved DiteHRNet of LiteHRNet, the detection accuracy of LDHNet is improved by 2.3%. Compared with the HRFormer fused with Transformer, the detection accuracy of LDHNet is the same when the scale is smaller. The experimental results on public datasets show that LDHNet achieves excellent results in model lightweight. LDHNet achieves a very good balance between lightweight and model detection performance. For lightweight human pose estimation, the performance of LDHNet is similar to that of Transformer. In addition to experimental verification in the public data set, this study also tests the inference speed and detection accuracy of the model in the actual scene. Compared with the original HRNet, LDHNet has a significant improvement in the detection speed under GPU acceleration. Compared with other lightweight methods, such as LiteHRNet, LDHNet can make full use of hardware resources. The results of the actual test show that LDHNet has a stable performance in the face of the actual scene. The above experimental results show that LDHNet has achieved the design expectations. Moreover, using extremely limited resources, compared with other lightweight human pose estimation models, LDHNet can make full use of all the computing power regardless of the level of hardware computing power. The detection accuracy is greatly improved, and the inference speed of the model is also significantly improved.ConclusionFor LDHNet, some problems also need to be solved, mainly in that the reasoning speed of the model has not reached the level matching the improvement of the model in terms of lightweight. Follow-up works can focus on how to improve the reasoning speed of the model, make the training and reasoning of the model glass, and use the method of emphasizing parameters for reference to further improve the model. Thus, LDHNet can be further competent for the needs of actual production and life.关键词:human pose estimation;lightweight network;densely connected network;high resolution network;multi-branch structure
摘要:ObjectiveHuman pose estimation is a technology that can be widely used in life. In recent years, many excellent high-precision methods have been proposed, but they are often accompanied by a very large model scale, which will encounter the problem of computing power bottleneck in application. Whether for model training or deployment, large models require considerable computing power as the basis. Most of them have low computing power. Similarly, for the scenes in daily life, the equipment needs further applicability and detection speed of the model, which is difficult to achieve by large models. Given such requirements, lightweight human pose estimation has become a hot research field. The main problem is how to achieve high detection accuracy and fast detection speed under the extremely limited number of resources. Lightweight models will inevitably fall into a disadvantage in detection accuracy compared with large models. However, fortunately, from many studies in recent years, the lightweight model can also achieve higher detection accuracy than large ones. A good balance can be reached between them.MethodBased on a high-resolution network (HRNet), a lightweight high-resolution human pose estimation network combined with a dense connection network (LDHNet) was proposed. First, dense connection and multi-scale were integrated to construct a lightweight and efficient feature extraction unit by redesigning the stage branch structure in HRNet and proposing a new lightweight feature extraction module. Then, the feature extraction module is composed of modules similar to the pyramid structure, and the dilated convolution of three scales is used to obtain a wide range of feature information in the feature map by stacking the multi-layer feature extraction modules and fusing the output of each layer. The concatenation of the output feature map of the feature extraction module is to reuse the feature map and fully extract the information contained in the feature map. These two points can make up for the problem of insufficient utilization of feature information that may exist in the lightweight model and use limited resources to achieve high feature extraction performance. Second, a wide range of cross-branch feature information interactions exists in the original HRNet structure, including feature fusion and the generation of new branches in each stage. LDHNet replaces the convolution in this process with the depthwise separable convolution by changing the size of the feature map through convolution downsampling or upsampling to add with other branch feature maps for feature fusion. This case further reduces the number of parameters of the model based on almost no loss of detection performance. In addition, LDHNet improves the original data preprocessing module and uses the double-branch form to fully extract the information from the original image. Experiments show that considerable information from the original image is of great help to improve the detection performance of the model. LDHNet also uses coordinate attention to reinforce spatial location information.ResultAfter the above improvements, the size of the model has been greatly reduced to less than one-tenth of the original HRNet. Although some gap still exists between the model size and the current smallest lightweight model LiteHRNet, the design of the lightweight model is not only concerned with the size of the model. This study mainly compares LDHNet with mainstream lightweight models. Through experimental verification on two mainstream datasets of human pose estimation MPII and common objects in context(COCO) dataset and comparison with the current mainstream methods, the following conclusions can be obtained. Compared with the top-down lightweight human pose estimation LiteHRNet on the MPII test set, the average prediction accuracy of LDHNet is improved by 1.5% by only adding a small number of parameters and calculations. The results on the COCO validation set show that compared with LiteHRNet, the average detection accuracy of LDHNet is improved by 3.4%. Compared with the improved DiteHRNet of LiteHRNet, the detection accuracy of LDHNet is improved by 2.3%. Compared with the HRFormer fused with Transformer, the detection accuracy of LDHNet is the same when the scale is smaller. The experimental results on public datasets show that LDHNet achieves excellent results in model lightweight. LDHNet achieves a very good balance between lightweight and model detection performance. For lightweight human pose estimation, the performance of LDHNet is similar to that of Transformer. In addition to experimental verification in the public data set, this study also tests the inference speed and detection accuracy of the model in the actual scene. Compared with the original HRNet, LDHNet has a significant improvement in the detection speed under GPU acceleration. Compared with other lightweight methods, such as LiteHRNet, LDHNet can make full use of hardware resources. The results of the actual test show that LDHNet has a stable performance in the face of the actual scene. The above experimental results show that LDHNet has achieved the design expectations. Moreover, using extremely limited resources, compared with other lightweight human pose estimation models, LDHNet can make full use of all the computing power regardless of the level of hardware computing power. The detection accuracy is greatly improved, and the inference speed of the model is also significantly improved.ConclusionFor LDHNet, some problems also need to be solved, mainly in that the reasoning speed of the model has not reached the level matching the improvement of the model in terms of lightweight. Follow-up works can focus on how to improve the reasoning speed of the model, make the training and reasoning of the model glass, and use the method of emphasizing parameters for reference to further improve the model. Thus, LDHNet can be further competent for the needs of actual production and life.关键词:human pose estimation;lightweight network;densely connected network;high resolution network;multi-branch structure- 4
- |
- 1
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveGesture recognition often neglects the correlation between fingers and pays excessive attention to the node features, which is crucial for the low gesture recognition rate. For example, the index finger and thumb are physically disconnected, but their interaction is important for recognizing the “pinch” action. Thus, the low recognition rate is due to the inability to encode the spatial position of the hand node properly. Dividing the joint of the hand part into blocks is proposed to address the correlation between fingers. The aforementioned problem can be addressed byencoding the two-dimensional position of the joint through its projection coordinates. The authors believe that this study is the first to encode the two-dimensional position of the node in space.MethodThe spatiotemporal graph is generated from the gesture sequence.This graph contains the physical connection of the node and its temporal information. Thus, the spatial and temporal characteristics are learned using mask operations.According to the three-dimensional space coordinates of joint nodes, the two-dimensional projection coordinates are obtained, and the two-dimensional projection coordinates are inputted into the two-dimensional space position encoder, which comprises sine and cosine functions with different frequencies.The plane where the projection coordinates are located is divided into several grid cells, and the encoder comprising sine and cosine functions is calculated in each grid cell. The encoders in all grids are combined to form sine and cosine functions with different frequencies to generate the final spatial two-dimensional position code.Embedding the encoded information into the spatial features of the nodes not only strengthens the spatial structure between them but also avoids the disorder of the nodes in the movement process.Using the graph convolutional network to aggregate and embed the spatial encoded node and neighbor features, the spatiotemporal graph features after the graph convolution are inputted into the spatial self-attention module to extract the inter-finger correlation. Taking each finger as the research object, the distribution of nodes in the spatiotemporal graph is divided into blocks according to the biological structure of the human hand. Each finger through a linear learnable change to generate the eigenvector of the finger query (Q), key (K), value (V). The self-attention mechanism is then used to calculate the correlation between fingers in each frame of the space-time graph, the correlation weight between fingers is obtained by combining the spatial mask matrix, and each finger feature is updated. While updating the finger features, the spatial mask matrix is used to disconnect the time relationship between fingers in the spatiotemporal graph, avoiding the influence of time dimension on the spatial correlation weight matrix.The time self-attention module is similarly used to learn the timing features of fingers in the spatiotemporal graph. First, temporal sequence embedding is conducted for each frame through temporal one-dimensional position coding to obtain the temporal sequence information of each frame during model learning. The time dimension expansion strategy is used to fuse the features of the two adjacent frames to capture the interframe correlation at a long distance. A learnable linear change then generates a feature vector query (Q), key (K), and value (V) for each frame. Finally, the self-attention mechanism is utilized to calculate the correlation between each frame in the space-time graph. Simultaneously, the correlation weight matrix between frames in the space-time graph is obtained by combining the time mask matrix, and the features of each frame are updated. Updating the features of each frame also uses the temporal mask matrix to avoid the influence of spatial dimension on the temporal correlation weight matrix. The fully connected network, ReLU activation function, and layer normalization are added to the end of each attention module to improve the training efficiency of the model, and the model finally outputs the learned feature vector for gesture recognition.ResultThe model is tested on two challenging datasets: DHG-14/28 and SHREC’17 track. The experimental results show that the model achieves the best recognition rate on DHG-14/28, which is 4.47% and 2.71% higher than the HPEV and the MS-ISTGCN algorithms, respectively, on average.On the SHREC’17 track dataset, the algorithm is 0.47% higher than the HPEV algorithm on average. The ablation experiment proves the need of two-dimensional location coding in space. The experimental test shows that the model has the best recognition rate when node features are 64 dimensions and the number of self-attention head is 8.ConclusionNumerous experimental evaluations verified that the network model constructed by the block strategy and spatial two-dimensional position coding not only improves the spatial structure of the nodes but also enhances the recognition rate of gestures using the self-attention mechanism to learn the correlation between non-physically connected fingers.关键词:gesture recognition;self-attention;spatial two-dimensional position coding;spatio-temporal mask;hand segmentation
摘要:ObjectiveGesture recognition often neglects the correlation between fingers and pays excessive attention to the node features, which is crucial for the low gesture recognition rate. For example, the index finger and thumb are physically disconnected, but their interaction is important for recognizing the “pinch” action. Thus, the low recognition rate is due to the inability to encode the spatial position of the hand node properly. Dividing the joint of the hand part into blocks is proposed to address the correlation between fingers. The aforementioned problem can be addressed byencoding the two-dimensional position of the joint through its projection coordinates. The authors believe that this study is the first to encode the two-dimensional position of the node in space.MethodThe spatiotemporal graph is generated from the gesture sequence.This graph contains the physical connection of the node and its temporal information. Thus, the spatial and temporal characteristics are learned using mask operations.According to the three-dimensional space coordinates of joint nodes, the two-dimensional projection coordinates are obtained, and the two-dimensional projection coordinates are inputted into the two-dimensional space position encoder, which comprises sine and cosine functions with different frequencies.The plane where the projection coordinates are located is divided into several grid cells, and the encoder comprising sine and cosine functions is calculated in each grid cell. The encoders in all grids are combined to form sine and cosine functions with different frequencies to generate the final spatial two-dimensional position code.Embedding the encoded information into the spatial features of the nodes not only strengthens the spatial structure between them but also avoids the disorder of the nodes in the movement process.Using the graph convolutional network to aggregate and embed the spatial encoded node and neighbor features, the spatiotemporal graph features after the graph convolution are inputted into the spatial self-attention module to extract the inter-finger correlation. Taking each finger as the research object, the distribution of nodes in the spatiotemporal graph is divided into blocks according to the biological structure of the human hand. Each finger through a linear learnable change to generate the eigenvector of the finger query (Q), key (K), value (V). The self-attention mechanism is then used to calculate the correlation between fingers in each frame of the space-time graph, the correlation weight between fingers is obtained by combining the spatial mask matrix, and each finger feature is updated. While updating the finger features, the spatial mask matrix is used to disconnect the time relationship between fingers in the spatiotemporal graph, avoiding the influence of time dimension on the spatial correlation weight matrix.The time self-attention module is similarly used to learn the timing features of fingers in the spatiotemporal graph. First, temporal sequence embedding is conducted for each frame through temporal one-dimensional position coding to obtain the temporal sequence information of each frame during model learning. The time dimension expansion strategy is used to fuse the features of the two adjacent frames to capture the interframe correlation at a long distance. A learnable linear change then generates a feature vector query (Q), key (K), and value (V) for each frame. Finally, the self-attention mechanism is utilized to calculate the correlation between each frame in the space-time graph. Simultaneously, the correlation weight matrix between frames in the space-time graph is obtained by combining the time mask matrix, and the features of each frame are updated. Updating the features of each frame also uses the temporal mask matrix to avoid the influence of spatial dimension on the temporal correlation weight matrix. The fully connected network, ReLU activation function, and layer normalization are added to the end of each attention module to improve the training efficiency of the model, and the model finally outputs the learned feature vector for gesture recognition.ResultThe model is tested on two challenging datasets: DHG-14/28 and SHREC’17 track. The experimental results show that the model achieves the best recognition rate on DHG-14/28, which is 4.47% and 2.71% higher than the HPEV and the MS-ISTGCN algorithms, respectively, on average.On the SHREC’17 track dataset, the algorithm is 0.47% higher than the HPEV algorithm on average. The ablation experiment proves the need of two-dimensional location coding in space. The experimental test shows that the model has the best recognition rate when node features are 64 dimensions and the number of self-attention head is 8.ConclusionNumerous experimental evaluations verified that the network model constructed by the block strategy and spatial two-dimensional position coding not only improves the spatial structure of the nodes but also enhances the recognition rate of gestures using the self-attention mechanism to learn the correlation between non-physically connected fingers.关键词:gesture recognition;self-attention;spatial two-dimensional position coding;spatio-temporal mask;hand segmentation- 4
- |
- 0
- |
- 0
发布时间:2024-05-15
Image Analysis and Recognition
-
 摘要:ObjectiveArtificial intelligence generated content (AIGC) technology can reduce the workload of three-dimensional (3D) modeling when applied to generate virtual 3D scene models using natural language. For static 3D objects, methods have arisen in generating high-precision 3D models that match a given textual description. By contrast, for dynamic digital human body models, which is also highly popular in numerous circumstances, only two-dimensional (2D) human images or sequences of human poses can be generated corresponding to a given textual description. Dynamic 3D human models cannot be generated with the same way above using natural language. Moreover, current existing methods can lead to problems such as immutable shape and motion when generating dynamic digital human models. A method fusing variational auto-encoder (VAE), contrastive language-image pretraining (CLIP), and gate recurrent unit (GRU), which can be used to generate satisfactory dynamic 3D human models corresponding to the shapes and motions described by the text, is proposed to address the above problems.MethodA method based on the VAE network is proposed in this paper to generate dynamic 3D human models, which correspond to the body shape and action information described in the text. Notably, a variety of pose sequences with variable time duration can be generated with the proposed method. First, the shape information of the body is obtained through the body shape generation module based on the VAE network and CLIP model, and zero-shot samples are used to generate the skinned multi-person linear (SMPL) parametric human model that matches the textual description. Specifically, the VAE network encodes the body shape of the SMPL model, the CLIP model matches the textual descriptions and body shapes, and the 3D human model with the highest matching score is thus filtered. Second, variable-length 3D human pose sequences are generated through the body action generation module based on the VAE and GRU networks that match the textual description. Particularly, the VAE self-encoder encodes the dynamic human poses. The action length sampling network then obtains the length of time that matches the textual description of the action. The GRU and VAE networks encode the input text and generate the diverse dynamic 3D human pose sequences through the decoder. Finally, a dynamic 3D human model corresponding to the body shape and action description can be generated by fusing the body shape and action information generated above. The performance of the method is evaluated in this paper using the HumanML3D dataset, which comprises 14 616 motions and 44 970 linguistic annotations. Some of the motions in the dataset are mirrored before training, and some words are replaced in the motion descriptions (e.g., “left” is changed to “right”) to expand the dataset. In the experiments in this paper, the HumanML3D dataset is divided into training, testing, and validation sets in the ratios of 80%, 15%, and 5%, respectively. The experiments in this paper are conducted in an Ubuntu 18.04 environment with a Tesla V100 GPU and 16GB of video memory. The adaptive moment estimation (Adam) optimizer is trained in 300 training rounds with a learning rate of 0.000 1 and a batch size of 128 to train the motion self-encoder. The Adam optimizer performs 320 training rounds with a learning rate of 0.000 2 and a batch size of 32 to train the motion generator. This optimizer also performs 200 training rounds with a learning rate of 0.000 1 and a batch size of 64 for training the motion length network.ResultDynamic 3D human model generation experiments were conducted on the HumanML3D dataset. Compared with three other state-of-the-art methods, the proposed method shows an improvement of 0.031, 0.034, and 0.028 in the Top1, Top2, and Top3 dimensions of R-precision, 0.094 in Fréchet inception distance(FID), and 0.065 in diversity, respectively, considering the best available results. The experimental analysis for qualitative evaluation was divided into three parts: body shape feature generation, action feature generation, and dynamic 3D human model generation including body features. The body feature generation part was tested using different text descriptions (e.g., tall, short, fat, thin). For the action feature generation part, the same text descriptions are tested using this paper and other methods for generation comparison. Combining the body shape features and the action feature of the human body, the generation of dynamic 3D human models with body shape features is demonstrated. In addition, ablation experiments, including ablation comparison with different methods using different loss functions, are performed to further demonstrate the effectiveness of the method. The final experimental results show that the proposed method in this paper improves the effectiveness of the model.ConclusionThis paper presents methods for generating dynamic 3D human models that conform to textual descriptions, fusing body shape and action information. The body shape generation module can generate SMPL parameterized human models whose body shape conforms to the textual description, while the action generation module can generate variable-length 3D human pose sequences that match the textual description. Experimental results show that the proposed method can effectively generate motion dynamic 3D human models that conform to textual descriptions, and the generated human models have diverse body shape and motions. On the HumanML3D dataset, the performance of the method outperforms other similar state-of-the-art algorithms.关键词:human motion synthesis;natural language processing(NLP);deep learning;skinned multi-person linear model;variational auto-encoder network
摘要:ObjectiveArtificial intelligence generated content (AIGC) technology can reduce the workload of three-dimensional (3D) modeling when applied to generate virtual 3D scene models using natural language. For static 3D objects, methods have arisen in generating high-precision 3D models that match a given textual description. By contrast, for dynamic digital human body models, which is also highly popular in numerous circumstances, only two-dimensional (2D) human images or sequences of human poses can be generated corresponding to a given textual description. Dynamic 3D human models cannot be generated with the same way above using natural language. Moreover, current existing methods can lead to problems such as immutable shape and motion when generating dynamic digital human models. A method fusing variational auto-encoder (VAE), contrastive language-image pretraining (CLIP), and gate recurrent unit (GRU), which can be used to generate satisfactory dynamic 3D human models corresponding to the shapes and motions described by the text, is proposed to address the above problems.MethodA method based on the VAE network is proposed in this paper to generate dynamic 3D human models, which correspond to the body shape and action information described in the text. Notably, a variety of pose sequences with variable time duration can be generated with the proposed method. First, the shape information of the body is obtained through the body shape generation module based on the VAE network and CLIP model, and zero-shot samples are used to generate the skinned multi-person linear (SMPL) parametric human model that matches the textual description. Specifically, the VAE network encodes the body shape of the SMPL model, the CLIP model matches the textual descriptions and body shapes, and the 3D human model with the highest matching score is thus filtered. Second, variable-length 3D human pose sequences are generated through the body action generation module based on the VAE and GRU networks that match the textual description. Particularly, the VAE self-encoder encodes the dynamic human poses. The action length sampling network then obtains the length of time that matches the textual description of the action. The GRU and VAE networks encode the input text and generate the diverse dynamic 3D human pose sequences through the decoder. Finally, a dynamic 3D human model corresponding to the body shape and action description can be generated by fusing the body shape and action information generated above. The performance of the method is evaluated in this paper using the HumanML3D dataset, which comprises 14 616 motions and 44 970 linguistic annotations. Some of the motions in the dataset are mirrored before training, and some words are replaced in the motion descriptions (e.g., “left” is changed to “right”) to expand the dataset. In the experiments in this paper, the HumanML3D dataset is divided into training, testing, and validation sets in the ratios of 80%, 15%, and 5%, respectively. The experiments in this paper are conducted in an Ubuntu 18.04 environment with a Tesla V100 GPU and 16GB of video memory. The adaptive moment estimation (Adam) optimizer is trained in 300 training rounds with a learning rate of 0.000 1 and a batch size of 128 to train the motion self-encoder. The Adam optimizer performs 320 training rounds with a learning rate of 0.000 2 and a batch size of 32 to train the motion generator. This optimizer also performs 200 training rounds with a learning rate of 0.000 1 and a batch size of 64 for training the motion length network.ResultDynamic 3D human model generation experiments were conducted on the HumanML3D dataset. Compared with three other state-of-the-art methods, the proposed method shows an improvement of 0.031, 0.034, and 0.028 in the Top1, Top2, and Top3 dimensions of R-precision, 0.094 in Fréchet inception distance(FID), and 0.065 in diversity, respectively, considering the best available results. The experimental analysis for qualitative evaluation was divided into three parts: body shape feature generation, action feature generation, and dynamic 3D human model generation including body features. The body feature generation part was tested using different text descriptions (e.g., tall, short, fat, thin). For the action feature generation part, the same text descriptions are tested using this paper and other methods for generation comparison. Combining the body shape features and the action feature of the human body, the generation of dynamic 3D human models with body shape features is demonstrated. In addition, ablation experiments, including ablation comparison with different methods using different loss functions, are performed to further demonstrate the effectiveness of the method. The final experimental results show that the proposed method in this paper improves the effectiveness of the model.ConclusionThis paper presents methods for generating dynamic 3D human models that conform to textual descriptions, fusing body shape and action information. The body shape generation module can generate SMPL parameterized human models whose body shape conforms to the textual description, while the action generation module can generate variable-length 3D human pose sequences that match the textual description. Experimental results show that the proposed method can effectively generate motion dynamic 3D human models that conform to textual descriptions, and the generated human models have diverse body shape and motions. On the HumanML3D dataset, the performance of the method outperforms other similar state-of-the-art algorithms.关键词:human motion synthesis;natural language processing(NLP);deep learning;skinned multi-person linear model;variational auto-encoder network- 2
- |
- 0
- |
- 0
发布时间:2024-05-15 -
 摘要:ObjectiveMicro-expressions are unconscious facial actions made by people under external information and stimulation. These expressions are crucial proofs to judge people’s emotions and thoughts. Micro-expressions are widely used in the fields of social security, business negotiation, and psychological counseling. This type of expression is different from the general macro-expression and demonstrates characteristics of short duration, low expression intensity, and fast change speed. Therefore, compared with macro-expressions, micro-expressions are more difficult to recognize and locate. Before the emergence of deep learning, researchers mostly used the traditional hand-crafted method, which utilizes the artificially designed micro-expression extractors and complex parameter adjustment processes and algorithms to extract features. Some excellent algorithms can achieve competitive results, such as local binary pattern-three orthogonal plane and main directional mean optical flow (MDMO). However, these algorithms mostly only extract shallow features, and improving their accuracy is difficult. With the development of machine learning in the field of computer vision, the research method of micro-expression based on deep learning has immediately become the mainstream. This method generally uses convolutional neural network to extract and classify the image or video features. The accuracy of micro-expression identification is markedly improved due to its powerful feature extraction and learning capability. However, the spotting and classification of micro-expressions are still difficult tasks due to the subtle characteristics of micro-expressions and the difficulty of extracting effective features. Therefore, this paper proposes a dual-branch optical flow spotting network based on optical flow window, which can promote the solution of these problems.MethodFirst, the size of the optical flow window is selected in accordance with the number of video frames, and three frames at both ends of the window are taken to stabilize the optical flow intensity. Dlib library is used to detect faces, and Farneback method is used to extract facial optical flow features and preprocess the optical flow image. The image size is finally converted into 224 × 224 pixels.The dual-branch network is then inputted for two classifications to address the presence or absence of micro-expression and the rising or falling state of micro-expression. The twice classification should be judged in accordance with the same characteristics. Therefore, the same network backbone is used, and then the branches are utilized to process the characteristics, thereby focusing on different directions. Combining two loss functions can suppress the overfitting of the network, complete classification, and improve the network performance. Finally, the micro-expression state in the video window is obtained by sliding the window, and the intensity curve is drawn. Multiple windows are selected for positioning due to the different durations of micro-expression, and the highest point among them is taken as the apex frame. The classification network is different from the location network in two aspects. First, the front end of the window is the second to the fourth frame of the video and the back end uses the micro-expression part of the video. Second, Euler motion magnification is used to process video. This method can amplify facial motion and improve expression intensity but will destroy some optical flow features; thus, the method is not used in the positioning network. When classifying videos, the apex frame of the positioning network is taken as the center, and the five surrounding positions are selected as the input of the classification network. The classification network uses the uncomplicated network structure and obtains good results, proving the importance of apex frame spotting.ResultThe micro-expression spotting network is based on leave-one-subject-out cross-validation method on the Chinese Academy of Sciences Micro-expression Database II (CASME II) and the Chinese Academy of Sciences Micro-expression Database (CASME), which is the most commonly used validation method in the current micro-expression identification research. Compared with the current best spotting method, the lowest normalized mean absolute error (NMAE) value of 0.101 7 is obtained on the CASME II, which is 9% lower than the current best spotting method. The NMAE value obtained on the CASME is 0.137 8, which is currently the second lowest number. Using this micro-expression spotting network, the classification network achieved 89.79% accuracy of three categories (positive, negative, and surprise) in the micro-expression classification experiment of CASME II and 66.06% accuracy of four categories (disgust, tense, repression, and surprise) in the micro-expression classification experiment of CASME. Using the apex frame in dataset, the classification network achieved 91.83% and 76.96% accuracy on CASME II and CASME, respectively.ConclusionThe proposed micro-expression spotting network can effectively locate the position of the apex frame in the video and then extract its effective micro-expression information. Extensive experimental evaluation proved that the spotting network has good spotting effect. The subsequent classification network shows that the extraction of effective micro-expression information such as an apex frame can significantly help the network in classifying micro-expressions. Overall, the proposed micro-expression spotting network can substantially improve the accuracy of micro-expression recognition.关键词:micro-expression spotting;affective computing;apex frame;micro-expression classification;image recognition;deep learning
摘要:ObjectiveMicro-expressions are unconscious facial actions made by people under external information and stimulation. These expressions are crucial proofs to judge people’s emotions and thoughts. Micro-expressions are widely used in the fields of social security, business negotiation, and psychological counseling. This type of expression is different from the general macro-expression and demonstrates characteristics of short duration, low expression intensity, and fast change speed. Therefore, compared with macro-expressions, micro-expressions are more difficult to recognize and locate. Before the emergence of deep learning, researchers mostly used the traditional hand-crafted method, which utilizes the artificially designed micro-expression extractors and complex parameter adjustment processes and algorithms to extract features. Some excellent algorithms can achieve competitive results, such as local binary pattern-three orthogonal plane and main directional mean optical flow (MDMO). However, these algorithms mostly only extract shallow features, and improving their accuracy is difficult. With the development of machine learning in the field of computer vision, the research method of micro-expression based on deep learning has immediately become the mainstream. This method generally uses convolutional neural network to extract and classify the image or video features. The accuracy of micro-expression identification is markedly improved due to its powerful feature extraction and learning capability. However, the spotting and classification of micro-expressions are still difficult tasks due to the subtle characteristics of micro-expressions and the difficulty of extracting effective features. Therefore, this paper proposes a dual-branch optical flow spotting network based on optical flow window, which can promote the solution of these problems.MethodFirst, the size of the optical flow window is selected in accordance with the number of video frames, and three frames at both ends of the window are taken to stabilize the optical flow intensity. Dlib library is used to detect faces, and Farneback method is used to extract facial optical flow features and preprocess the optical flow image. The image size is finally converted into 224 × 224 pixels.The dual-branch network is then inputted for two classifications to address the presence or absence of micro-expression and the rising or falling state of micro-expression. The twice classification should be judged in accordance with the same characteristics. Therefore, the same network backbone is used, and then the branches are utilized to process the characteristics, thereby focusing on different directions. Combining two loss functions can suppress the overfitting of the network, complete classification, and improve the network performance. Finally, the micro-expression state in the video window is obtained by sliding the window, and the intensity curve is drawn. Multiple windows are selected for positioning due to the different durations of micro-expression, and the highest point among them is taken as the apex frame. The classification network is different from the location network in two aspects. First, the front end of the window is the second to the fourth frame of the video and the back end uses the micro-expression part of the video. Second, Euler motion magnification is used to process video. This method can amplify facial motion and improve expression intensity but will destroy some optical flow features; thus, the method is not used in the positioning network. When classifying videos, the apex frame of the positioning network is taken as the center, and the five surrounding positions are selected as the input of the classification network. The classification network uses the uncomplicated network structure and obtains good results, proving the importance of apex frame spotting.ResultThe micro-expression spotting network is based on leave-one-subject-out cross-validation method on the Chinese Academy of Sciences Micro-expression Database II (CASME II) and the Chinese Academy of Sciences Micro-expression Database (CASME), which is the most commonly used validation method in the current micro-expression identification research. Compared with the current best spotting method, the lowest normalized mean absolute error (NMAE) value of 0.101 7 is obtained on the CASME II, which is 9% lower than the current best spotting method. The NMAE value obtained on the CASME is 0.137 8, which is currently the second lowest number. Using this micro-expression spotting network, the classification network achieved 89.79% accuracy of three categories (positive, negative, and surprise) in the micro-expression classification experiment of CASME II and 66.06% accuracy of four categories (disgust, tense, repression, and surprise) in the micro-expression classification experiment of CASME. Using the apex frame in dataset, the classification network achieved 91.83% and 76.96% accuracy on CASME II and CASME, respectively.ConclusionThe proposed micro-expression spotting network can effectively locate the position of the apex frame in the video and then extract its effective micro-expression information. Extensive experimental evaluation proved that the spotting network has good spotting effect. The subsequent classification network shows that the extraction of effective micro-expression information such as an apex frame can significantly help the network in classifying micro-expressions. Overall, the proposed micro-expression spotting network can substantially improve the accuracy of micro-expression recognition.关键词:micro-expression spotting;affective computing;apex frame;micro-expression classification;image recognition;deep learning- 2
- |
- 0
- |
- 0
发布时间:2024-05-15
Image Understanding and Computer Vision
-
 摘要:ObjectiveWith the rapid development of remote sensing observation technology, the resolutions of remote sensing images (RSIs) are increasing. Thus, how to extract discriminative features effectively from high-resolution RSIs for ground-object change detection has become a challenging problem. The existing RSI change detection methods can be divided into two categories: methods based on conventional image processing approaches and methods based on deep learning (DL) theory. The former extracts low-level or mid-level features from RSIs for change detection, making it easy to implement and have high detection efficiency. However, the increasing resolution of RSIs result in the images having rich ground objects and complex background clutter; thus, the low- or mid-level features can hardly meet the demand of precise change detection. In recent years, DL has been introduced into the field of high-resolution RSI change detection because of its powerful feature extraction capability. Various methods based on convolutional neural networks (CNNs) have been proposed for RSI change detection. Compared with conventional image processing methods, CNNs can extract high-level semantic information for high-resolution RSIs, which is beneficial to precise detection. Although CNNs have greatly raised the accuracy of change detection, they always involve numerous parameters and have high computational complexity. To raise the efficiency of change detection, many scholars have proposed to perform parameter pruning on pretrained models or design simple network structures. However, these strategies lead to the loss of some crucial image information, including semantics and location information, thus reducing the detection accuracy. Therefore, this study proposes a novel Ghost-UNet++ (GUNet++) network for precise RSI change detection to address the problems.MethodFirst, a high-resolution network called HRNet, which has a multibranch architecture, is designed to replace the traditional UNet++ backbone and thus extract additional discriminative deep features from bitemporal RSIs. In contrast to series structures, HRNet owns a special parallel architecture, which can extract additional discriminative features through multiscale feature fusion. In addition, we choose a lightweight structure (i.e., HRNet-W16) on the basis of a thorough analysis of various existing HRNet structures to ensure that the whole network possesses low complexity. Second, when applying the UNet++ decoding structure for difference discrimination, the Ghost module is introduced to replace the conventional convolutional module and thus reduce the network parameters; meanwhile, a dense skip connection is designed to enhance the information transmission further and reduce the loss of location information. The core idea of the Ghost module is to adopt simple linear operations instead of the traditional convolutional operations to generate Ghost maps for original features, which may save substantial computational cost. Third, an ensemble attention module is constructed to aggregate and refine the multilevel semantic features of the network, thereby suppressing the loss of semantic and location information and further enhancing the feature representation ability for final accurate change detection. Features generated at various levels usually contain different meanings: shallow ones always contain detailed spatial information, while deep ones reflect rich semantic content. On this basis, we propose an adaptive channel selection mechanism to integrate these different features effectively. Finally, we propose to combine two different loss functions, i.e., the sigmoid loss function and the dice loss function, for the whole model training to enhance the detection performance further. Compared with the methods that merely use one loss function, this scheme can improve detection performance.ResultA series of experiments is conducted on two publicly available datasets, including LEVIR-CD and Google DataSet, to validate the effectiveness of the proposed method. The experiments consist of ablation analysis and comparison experiments. Specifically, three kinds of ablation analyses are performed. The first one verifies the effects of the modified HRNet-based discriminative feature extraction, the second one mainly evaluates the effectiveness of the ensemble attention modules and the Ghost modules for the whole network, and the third one aims to find the optimal values of a key parameter in the Ghost models. In the comparison experiments, some state-of-the-art algorithms are selected for comparison to verify the superiority of the proposed network. Extensive experimental results demonstrate that for the two famous datasets, the proposed method achieves high change detection accuracy rates of 99.62% and 99.16%. In addition, the parameter of the network is only 1.93 M. Compared with some mainstream change detection approaches, the proposed method is remarkably superior.ConclusionThe proposed method comprehensively considers the effect of semantic and location information in RSIs on the performance of change detection. In addition, the method possesses good feature extraction and representation capabilities. Therefore, the accuracy and efficiency for change detection are higher than those of existing comparable algorithms. In the future, we plan to optimize the proposed architecture by increasing the number and diversity of the training samples to enhance the robustness of models, by using more advanced software and hardware environments for experiments to reduce the training time, and by applying our trained model to other tasks.关键词:high-resolution remote sensing image;change detection;deep learning(DL);Ghost module;ensemble attention
摘要:ObjectiveWith the rapid development of remote sensing observation technology, the resolutions of remote sensing images (RSIs) are increasing. Thus, how to extract discriminative features effectively from high-resolution RSIs for ground-object change detection has become a challenging problem. The existing RSI change detection methods can be divided into two categories: methods based on conventional image processing approaches and methods based on deep learning (DL) theory. The former extracts low-level or mid-level features from RSIs for change detection, making it easy to implement and have high detection efficiency. However, the increasing resolution of RSIs result in the images having rich ground objects and complex background clutter; thus, the low- or mid-level features can hardly meet the demand of precise change detection. In recent years, DL has been introduced into the field of high-resolution RSI change detection because of its powerful feature extraction capability. Various methods based on convolutional neural networks (CNNs) have been proposed for RSI change detection. Compared with conventional image processing methods, CNNs can extract high-level semantic information for high-resolution RSIs, which is beneficial to precise detection. Although CNNs have greatly raised the accuracy of change detection, they always involve numerous parameters and have high computational complexity. To raise the efficiency of change detection, many scholars have proposed to perform parameter pruning on pretrained models or design simple network structures. However, these strategies lead to the loss of some crucial image information, including semantics and location information, thus reducing the detection accuracy. Therefore, this study proposes a novel Ghost-UNet++ (GUNet++) network for precise RSI change detection to address the problems.MethodFirst, a high-resolution network called HRNet, which has a multibranch architecture, is designed to replace the traditional UNet++ backbone and thus extract additional discriminative deep features from bitemporal RSIs. In contrast to series structures, HRNet owns a special parallel architecture, which can extract additional discriminative features through multiscale feature fusion. In addition, we choose a lightweight structure (i.e., HRNet-W16) on the basis of a thorough analysis of various existing HRNet structures to ensure that the whole network possesses low complexity. Second, when applying the UNet++ decoding structure for difference discrimination, the Ghost module is introduced to replace the conventional convolutional module and thus reduce the network parameters; meanwhile, a dense skip connection is designed to enhance the information transmission further and reduce the loss of location information. The core idea of the Ghost module is to adopt simple linear operations instead of the traditional convolutional operations to generate Ghost maps for original features, which may save substantial computational cost. Third, an ensemble attention module is constructed to aggregate and refine the multilevel semantic features of the network, thereby suppressing the loss of semantic and location information and further enhancing the feature representation ability for final accurate change detection. Features generated at various levels usually contain different meanings: shallow ones always contain detailed spatial information, while deep ones reflect rich semantic content. On this basis, we propose an adaptive channel selection mechanism to integrate these different features effectively. Finally, we propose to combine two different loss functions, i.e., the sigmoid loss function and the dice loss function, for the whole model training to enhance the detection performance further. Compared with the methods that merely use one loss function, this scheme can improve detection performance.ResultA series of experiments is conducted on two publicly available datasets, including LEVIR-CD and Google DataSet, to validate the effectiveness of the proposed method. The experiments consist of ablation analysis and comparison experiments. Specifically, three kinds of ablation analyses are performed. The first one verifies the effects of the modified HRNet-based discriminative feature extraction, the second one mainly evaluates the effectiveness of the ensemble attention modules and the Ghost modules for the whole network, and the third one aims to find the optimal values of a key parameter in the Ghost models. In the comparison experiments, some state-of-the-art algorithms are selected for comparison to verify the superiority of the proposed network. Extensive experimental results demonstrate that for the two famous datasets, the proposed method achieves high change detection accuracy rates of 99.62% and 99.16%. In addition, the parameter of the network is only 1.93 M. Compared with some mainstream change detection approaches, the proposed method is remarkably superior.ConclusionThe proposed method comprehensively considers the effect of semantic and location information in RSIs on the performance of change detection. In addition, the method possesses good feature extraction and representation capabilities. Therefore, the accuracy and efficiency for change detection are higher than those of existing comparable algorithms. In the future, we plan to optimize the proposed architecture by increasing the number and diversity of the training samples to enhance the robustness of models, by using more advanced software and hardware environments for experiments to reduce the training time, and by applying our trained model to other tasks.关键词:high-resolution remote sensing image;change detection;deep learning(DL);Ghost module;ensemble attention- 3
- |
- 0
- |
- 0
发布时间:2024-05-15
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0