
最新刊期
卷 29 , 期 2 , 2024
-
 摘要:Deep learning, a promising branch of machine learning, has made significant breakthroughs in computer vision. However, Deepfake, which refers to the set of techniques for forging human-related multimedia data using deep learning, can bring disasters to society if used maliciously. It is not only limited to facial replacement, but also other manipulations, such as fabricating facial features, manipulating expressions, synchronizing lips, modifying head gestures, entire face synthesis, and tampering related audios to videos and related texts to videos. Moreover, it can be used to generate faked pornographic videos or even faked speeches to subvert state power. Thus, deep forgery technology can greatly threaten society and individuals, thereyby detecting Deepfake has also become an important research topic in digital forensics. We conducted a systematic and critical survey to provide an overview of the latest research on Deepfake detection by exploring the recent developments in Deepfake and related forensic techniques. This survey mainly referred to papers on Deepfake in Google Scholar during 2018—2022. This survey divided the Deepfake detection techniques into two categories for analysis and comparison: input dimensions and forensic features. First, a comprehensive and systematic introduction of digital forensics is presented from the following aspects: 1) the development and security of deep forgery detection technology, 2) Deepfake technology architecture, and 3) the prevailing datasets and evaluation metrics. Then, this survey presents Deepfake techniques in several categories. Finally, future challenges and development prospects are discussed. In terms of image and video effects, Deepfake techniques are usually divided into four categories: face replacement, lip synchronization, head puppets, and attribute modification. The most commonly used Deepfake algorithms are based on self-encoders, generative adversarial networks, and diffusion models. An typical autoencoder consists of two convolutional neural networks acting as an encoder and a decoder. The encoder reduces the dimensions of the input targets’ facial image and encodes it into a vector corresponding to facial features. We share the parameters of the encoder; that is, we use the same encoder to learn only the common feature information for the encoder network. The structure of a generative adversarial network is based on a generator and a discriminator. The generator is similar to the decoder in an autoencoder, which converts the input noise into a picture and sends it to the discriminator for discrimination along with the real existing picture. The discriminator and the generator use back-propagation to optimize the parameters. Moreover, diffusion model is a parameterized Markov chain trained using variational inference to produce samples that match the data after a finite time. There are always two processes to train a diffusion model. One is the forward process, also called the diffusion process. The other process is reverse diffusion, also known as the reverse process, which slowly restores the original image from noise through continuous sampling. In the Deepfake detection task, the datasets have also evolved to fill past gaps. In general, this survey divides the Deepfake datasets into two generations. The first-generation datasets are often not large enough, and the quality of the content is not satisfying because of the low degree of research fervor. These source videos are usually from video sites or existing face datasets, which can lead to copyright and privacy concerns. The main first-generation datasets are UADFV, DF-TIMIT, FaceForensics, and diverse fake face dataset(DFFD). The second generation of face forgery datasets has improved forgery effects and image clarity. The main second-generation datasets are Celeb-DF, Deepfake detection challenge dataset(DFDC) preview, DeeperForensic-1.0, DFDC, Korean Deepfake detection dataset(KoDF), etc. In terms of input dimension, detecting Deepfake can be roughly divided into three categories: 1) the first category is inputting the image or key frame from the video, namely, inputting the image or key frame extracted from the video and judging the input data from the visual performance. This category is commonly used because it can be promoted easily to other computer vision classification models, and most Deepfake videos are conducted by frame-by-frame images. 2) The second is inputting continuous frames from video. In particular, multiple consecutive frames are inputted to allow the model to perceive the difference in the relationship between the frames from real and fake videos. 3) The third is inputting multiple frames and audio simultaneously from the video; that is, the video’s authenticity is detected by examining its video frames and audio together. The features focused on by Deepfake detection techniques also vary. This survey divides them into four categories: 1) the frequency domain-based approach looks for anomalies in the video at the signal level, treating the video as a sequence of frames and a synchronized audio signal. Such anomalies, including image mismatches and mismatches in audio-video synchronization, are usually generated from the mismatches at the signal level during Deepfake video generation. 2) The texture and spatio-temporal approaches tend to focus only on face position and feature matching in the forged video generation process, where breakdowns that violate the laws of physics and human physiology may occur. 3) The reconstruction–classification learning methods emphasize the common compact representations of genuine faces and enhance the learned representations to be aware of unknown forgery patterns. Classification learning involves mining the essential discrepancy between real and fake images, facilitating the understanding of forgeries. 4) Data-driven methods are detection methods that do not target specific features. However, they use supervised learning to feed real and fake videos into the model for training. The road to the research on deep forgery techniques and deep forgery detection is still long. We must overcome the existing shortcomings and face the challenges of future technological advances.关键词:Deepfake;machine learning;artificial intelligence;deep learning;digital forensics;digital anti-forensics
摘要:Deep learning, a promising branch of machine learning, has made significant breakthroughs in computer vision. However, Deepfake, which refers to the set of techniques for forging human-related multimedia data using deep learning, can bring disasters to society if used maliciously. It is not only limited to facial replacement, but also other manipulations, such as fabricating facial features, manipulating expressions, synchronizing lips, modifying head gestures, entire face synthesis, and tampering related audios to videos and related texts to videos. Moreover, it can be used to generate faked pornographic videos or even faked speeches to subvert state power. Thus, deep forgery technology can greatly threaten society and individuals, thereyby detecting Deepfake has also become an important research topic in digital forensics. We conducted a systematic and critical survey to provide an overview of the latest research on Deepfake detection by exploring the recent developments in Deepfake and related forensic techniques. This survey mainly referred to papers on Deepfake in Google Scholar during 2018—2022. This survey divided the Deepfake detection techniques into two categories for analysis and comparison: input dimensions and forensic features. First, a comprehensive and systematic introduction of digital forensics is presented from the following aspects: 1) the development and security of deep forgery detection technology, 2) Deepfake technology architecture, and 3) the prevailing datasets and evaluation metrics. Then, this survey presents Deepfake techniques in several categories. Finally, future challenges and development prospects are discussed. In terms of image and video effects, Deepfake techniques are usually divided into four categories: face replacement, lip synchronization, head puppets, and attribute modification. The most commonly used Deepfake algorithms are based on self-encoders, generative adversarial networks, and diffusion models. An typical autoencoder consists of two convolutional neural networks acting as an encoder and a decoder. The encoder reduces the dimensions of the input targets’ facial image and encodes it into a vector corresponding to facial features. We share the parameters of the encoder; that is, we use the same encoder to learn only the common feature information for the encoder network. The structure of a generative adversarial network is based on a generator and a discriminator. The generator is similar to the decoder in an autoencoder, which converts the input noise into a picture and sends it to the discriminator for discrimination along with the real existing picture. The discriminator and the generator use back-propagation to optimize the parameters. Moreover, diffusion model is a parameterized Markov chain trained using variational inference to produce samples that match the data after a finite time. There are always two processes to train a diffusion model. One is the forward process, also called the diffusion process. The other process is reverse diffusion, also known as the reverse process, which slowly restores the original image from noise through continuous sampling. In the Deepfake detection task, the datasets have also evolved to fill past gaps. In general, this survey divides the Deepfake datasets into two generations. The first-generation datasets are often not large enough, and the quality of the content is not satisfying because of the low degree of research fervor. These source videos are usually from video sites or existing face datasets, which can lead to copyright and privacy concerns. The main first-generation datasets are UADFV, DF-TIMIT, FaceForensics, and diverse fake face dataset(DFFD). The second generation of face forgery datasets has improved forgery effects and image clarity. The main second-generation datasets are Celeb-DF, Deepfake detection challenge dataset(DFDC) preview, DeeperForensic-1.0, DFDC, Korean Deepfake detection dataset(KoDF), etc. In terms of input dimension, detecting Deepfake can be roughly divided into three categories: 1) the first category is inputting the image or key frame from the video, namely, inputting the image or key frame extracted from the video and judging the input data from the visual performance. This category is commonly used because it can be promoted easily to other computer vision classification models, and most Deepfake videos are conducted by frame-by-frame images. 2) The second is inputting continuous frames from video. In particular, multiple consecutive frames are inputted to allow the model to perceive the difference in the relationship between the frames from real and fake videos. 3) The third is inputting multiple frames and audio simultaneously from the video; that is, the video’s authenticity is detected by examining its video frames and audio together. The features focused on by Deepfake detection techniques also vary. This survey divides them into four categories: 1) the frequency domain-based approach looks for anomalies in the video at the signal level, treating the video as a sequence of frames and a synchronized audio signal. Such anomalies, including image mismatches and mismatches in audio-video synchronization, are usually generated from the mismatches at the signal level during Deepfake video generation. 2) The texture and spatio-temporal approaches tend to focus only on face position and feature matching in the forged video generation process, where breakdowns that violate the laws of physics and human physiology may occur. 3) The reconstruction–classification learning methods emphasize the common compact representations of genuine faces and enhance the learned representations to be aware of unknown forgery patterns. Classification learning involves mining the essential discrepancy between real and fake images, facilitating the understanding of forgeries. 4) Data-driven methods are detection methods that do not target specific features. However, they use supervised learning to feed real and fake videos into the model for training. The road to the research on deep forgery techniques and deep forgery detection is still long. We must overcome the existing shortcomings and face the challenges of future technological advances.关键词:Deepfake;machine learning;artificial intelligence;deep learning;digital forensics;digital anti-forensics- 8
- |
- 5
- |
- 0
发布时间:2024-02-16 -
 摘要:With the development of the generative adversarial network (GAN) technology in recent years, facial manipulation technology has advanced significantly in both academia and industry. In particular, the deep face forgery model, represented by Deepfake has been widely used on the internet. The term “Deepfake” is a portmanteau of “deep learning” and “fake”. It refers to a face modification technology based on deep learning that can modify faces in videos and images, including face swapping, face expression editing, and face attribute editing. Deepfake can be roughly divided into two categories: identity-agnostic and identity-related manipulations. Face swapping is classified under identity-related manipulation; it aims to replace the target face area with the original face. Meanwhile, face expression and face attribute editing are classified under identity-agnostic manipulation. They attempt to modify the attributes of a face, such as its expression, hair color, age, and gender, without transforming identity. On the one hand, Deepfake technology has been widely used in film special effects, advertising, and entertainment apps. For example, some films have achieved more realistic and low-cost special effects by using such technology. For customers, the model on screen can be personalized in accordance with their body dimensions, color, and hair type before purchasing products. Simultaneously, Deepfake has inspired an increasing number of entertainment applications, such as ZAO, MeituXiuxiu, and FaceApp, which have considerably lowered the threshold of using this technology. Through these applications, users can easily replace the faces of actors in movies or television dramas with their own faces or change their hair color or makeup at will. On the other hand, Deepfake forgery is currently being applied to some scenarios that may cause adverse effects. For example, one of the most notorious Deepfake applications, DeepNude, attempts to replace the face of a porn actor with one of a star, causing serious damage to the individual privacy and even the personal reputation of citizens. In addition, Deepfake with target attributes may pass the verification of commercial applications, threatening application security and harming the property of the person who has been impersonated. To date, the fake news in which a politician speaks a speech that does not belong to him/her also poses a serious threat to social stability and national security. On this basis, some defense methods of Deepfake forgery have been proposed. Existing defense technologies can be roughly divided into two categories: passive defense and proactive defense. Passive defense is primarily based on detection. Despite their considerable accuracy, these detectors are simply passive measures against Deepfake attacks because they cannot eliminate the negative effects of the fake content that has been generated and widely disseminated. In summary, achieving prior defense is difficult and cannot intervene in the generation of Deepfake faces. Therefore, current mainstream belief assumes that proactive defense techniques are more defensive and practical. In contrast with passive defense, proactive defense disrupts Deepfake proactively by adding special adversarial perturbations or watermarks to the source images or videos before they are shared online. When a malicious user attempts to use them for Deepfake forgery, the output of the Deepfake forgery model will be seriously damaged in terms of visual quality and cannot be successfully forged. Moreover, even if indistinguishable fake images are obtained, we can trace the source through the forged images to find the malicious user. The present study principally reviews currently available Deepfake proactive defense techniques. Our overview is focused on the following perspectives: 1) a brief introduction of Deepfake forgery technologies and their effects; 2) a systematic summary of current proactive defense algorithms for Deepfake forgery, including technical principles, classification, performance, datasets, and evaluation methods; and 3) a description of the challenges faced by Deepfake proactive defense and a discussion of its future directions. From the perspective of the defense target, Deepfake forgery proactive defense can be divided into proactive disruption and proactive forensics defense technologies. Proactive disruption defense technology can be subdivided from the point of view of technical implementation into data poisoning, adversarial attack, and latent space defense methods. The data poisoning defense method destroys Deepfake forgery during the training stage, requiring the faker to use the poisoned images as training data to train the Deepfake forgery model. Meanwhile, forgery destruction of the adversarial attack defense method works in the test stage. When the faker uses the well-trained Deepfake forgery model to manipulate face images with adversarial perturbations, the output image will be destroyed. This idea of defense based on adversarial attack is the most widely used in existing studies. When implementing latent space defense methods, perturbations are not added directly to an image. By contrast, an image is first mapped into latent space, and this mapping is implemented with an elaborate transformation, such that the image is protected from the threat of Deepfake forgery. Notably, this method relies heavily on the effect of GAN inversion technology. We then provide a brief introduction of the evaluation methods and datasets used in proactive defense. The evaluation of a defense technology is typically performed from two aspects: the effect of disrupting the output of the Deepfake forgery model and the effect of maintaining the visual quality of disturbed images. These technologies are generally evaluated in terms of pixel distance, feature distance, and attack success rate. Simultaneously, some commonly used facial indicators, such as structural similarity index measure, Frechet inception distance, and normalization mean error, are considered during evaluation. Finally, we expound the challenges faced by Deepfake proactive defense, including the circumvention of proactive defense, the improvement of performance in black box scenarios, and practicality issues. In addition, we look forward to the future directions of proactive defense. More robust performance and better visual quality are identified as two major concerns. In conclusion, our survey summarizes the principal concept and classification of Deepfake proactive defense and provides detailed explanations of various methods, evaluation metrics, commonly used datasets, major challenges, and prospects. We hope that it will serve as an introduction and guide for Deepfake proactive defense research.关键词:Deepfake forgery;Deepfake defense;proactive defense;adversarial attack;generative adversarial network(GAN);deep learning
摘要:With the development of the generative adversarial network (GAN) technology in recent years, facial manipulation technology has advanced significantly in both academia and industry. In particular, the deep face forgery model, represented by Deepfake has been widely used on the internet. The term “Deepfake” is a portmanteau of “deep learning” and “fake”. It refers to a face modification technology based on deep learning that can modify faces in videos and images, including face swapping, face expression editing, and face attribute editing. Deepfake can be roughly divided into two categories: identity-agnostic and identity-related manipulations. Face swapping is classified under identity-related manipulation; it aims to replace the target face area with the original face. Meanwhile, face expression and face attribute editing are classified under identity-agnostic manipulation. They attempt to modify the attributes of a face, such as its expression, hair color, age, and gender, without transforming identity. On the one hand, Deepfake technology has been widely used in film special effects, advertising, and entertainment apps. For example, some films have achieved more realistic and low-cost special effects by using such technology. For customers, the model on screen can be personalized in accordance with their body dimensions, color, and hair type before purchasing products. Simultaneously, Deepfake has inspired an increasing number of entertainment applications, such as ZAO, MeituXiuxiu, and FaceApp, which have considerably lowered the threshold of using this technology. Through these applications, users can easily replace the faces of actors in movies or television dramas with their own faces or change their hair color or makeup at will. On the other hand, Deepfake forgery is currently being applied to some scenarios that may cause adverse effects. For example, one of the most notorious Deepfake applications, DeepNude, attempts to replace the face of a porn actor with one of a star, causing serious damage to the individual privacy and even the personal reputation of citizens. In addition, Deepfake with target attributes may pass the verification of commercial applications, threatening application security and harming the property of the person who has been impersonated. To date, the fake news in which a politician speaks a speech that does not belong to him/her also poses a serious threat to social stability and national security. On this basis, some defense methods of Deepfake forgery have been proposed. Existing defense technologies can be roughly divided into two categories: passive defense and proactive defense. Passive defense is primarily based on detection. Despite their considerable accuracy, these detectors are simply passive measures against Deepfake attacks because they cannot eliminate the negative effects of the fake content that has been generated and widely disseminated. In summary, achieving prior defense is difficult and cannot intervene in the generation of Deepfake faces. Therefore, current mainstream belief assumes that proactive defense techniques are more defensive and practical. In contrast with passive defense, proactive defense disrupts Deepfake proactively by adding special adversarial perturbations or watermarks to the source images or videos before they are shared online. When a malicious user attempts to use them for Deepfake forgery, the output of the Deepfake forgery model will be seriously damaged in terms of visual quality and cannot be successfully forged. Moreover, even if indistinguishable fake images are obtained, we can trace the source through the forged images to find the malicious user. The present study principally reviews currently available Deepfake proactive defense techniques. Our overview is focused on the following perspectives: 1) a brief introduction of Deepfake forgery technologies and their effects; 2) a systematic summary of current proactive defense algorithms for Deepfake forgery, including technical principles, classification, performance, datasets, and evaluation methods; and 3) a description of the challenges faced by Deepfake proactive defense and a discussion of its future directions. From the perspective of the defense target, Deepfake forgery proactive defense can be divided into proactive disruption and proactive forensics defense technologies. Proactive disruption defense technology can be subdivided from the point of view of technical implementation into data poisoning, adversarial attack, and latent space defense methods. The data poisoning defense method destroys Deepfake forgery during the training stage, requiring the faker to use the poisoned images as training data to train the Deepfake forgery model. Meanwhile, forgery destruction of the adversarial attack defense method works in the test stage. When the faker uses the well-trained Deepfake forgery model to manipulate face images with adversarial perturbations, the output image will be destroyed. This idea of defense based on adversarial attack is the most widely used in existing studies. When implementing latent space defense methods, perturbations are not added directly to an image. By contrast, an image is first mapped into latent space, and this mapping is implemented with an elaborate transformation, such that the image is protected from the threat of Deepfake forgery. Notably, this method relies heavily on the effect of GAN inversion technology. We then provide a brief introduction of the evaluation methods and datasets used in proactive defense. The evaluation of a defense technology is typically performed from two aspects: the effect of disrupting the output of the Deepfake forgery model and the effect of maintaining the visual quality of disturbed images. These technologies are generally evaluated in terms of pixel distance, feature distance, and attack success rate. Simultaneously, some commonly used facial indicators, such as structural similarity index measure, Frechet inception distance, and normalization mean error, are considered during evaluation. Finally, we expound the challenges faced by Deepfake proactive defense, including the circumvention of proactive defense, the improvement of performance in black box scenarios, and practicality issues. In addition, we look forward to the future directions of proactive defense. More robust performance and better visual quality are identified as two major concerns. In conclusion, our survey summarizes the principal concept and classification of Deepfake proactive defense and provides detailed explanations of various methods, evaluation metrics, commonly used datasets, major challenges, and prospects. We hope that it will serve as an introduction and guide for Deepfake proactive defense research.关键词:Deepfake forgery;Deepfake defense;proactive defense;adversarial attack;generative adversarial network(GAN);deep learning- 6
- |
- 1
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveWith the rapid development of social media, multimedia information on the internet is updated at an exponential rate. Obtaining and transmitting digital images have become convenient, considerably increasing the risk of malicious tampering and forgery of images. Accordingly, increasing attention is given to image authentication and content protection. Many image authentication schemes have emerged recently, such as watermarking, the use of digital signatures, and perceptual image hashing (PIH). PIH, also known as image abstract or image fingerprint, is an effective technique for image authentication that has attracted widespread research attention in recent years. The goal of PIH is to authenticate an image by compressing perceptual robust features into a compact hash sequence with a fixed length. However, a general dataset in this field is lacking, and the dataset constructed using other methods have many problems. On the one hand, the types of image content-preserving manipulations used in these datasets are few and the intensity of attacks is relatively weak. On the other hand, the distinct images used in these datasets are extremely different from the images that must be authenticated, making it easy to distinguish them from each other. The convolutional neural networks (CNNs) trained by these datasets have poor generalizability and can hardly cope with the complex and diverse image editing operations in reality. This important factor has limited the development of the PIH field.MethodOn the basis of the preceding knowledge, we propose a specialized dataset based on various manipulations in this study. This dataset can deal with complex image authentication scenarios. The proposed dataset is divided into three subsets: original, perceptual identical, and perceptual distinct images. The latter two correspond to the robustness and discrimination of PIH, respectively. Original images are selected from ImageNet1K, and each of them corresponds to one category. For identical images, we summarize the content-preserving manipulations commonly used in the field of PIH and group them into four major categories: geometric, enhancement, filter, and editing manipulations. Each major category is subdivided into different types, for a total of 35 single-image content-preserving manipulations. To ensure the diversity and reflect the randomness of image editing in reality, we set a threshold for each type of image content-preserving manipulation and let them randomly select the attack intensity within this range. In addition, we randomly combine multiple single-image content-preserving manipulations to form combination manipulations. Some combined manipulations in the test set have not been learned in the training set due to the randomness. This result is also in line with practical application scenarios, because many unlearned, combined image editing manipulations exist in reality. For perceptual distinct images, except for a portion of images unrelated to the original images, the other portions are selected from the same category that corresponds to each original image, increasing the difficulty of the dataset and improving the generalizability of the trained CNNs. Compared with previously adopted datasets, our dataset conforms more to the actual application scenario of the PIH task. Our dataset contains 1 200 original images, and each original image is subjected to 48 image content-preserving manipulations to generate 48 perceptual identical images. To balance the number of perceptual identical and distinct images, we also select 48 perceptual distinct images for each original image. Then, 24 images are randomly selected among them, and the other 24 images are semantically similar to the original images. Therefore, each batch contains 1 original image, 48 perceptual identical images, and 48 perceptual distinct images, for a total of 97 images. Our dataset has 1 200 original images or 116 400 images in total. The large amount of data ensures the effective training of CNNs.ResultTo validate the performance of the dataset proposed in this study (i.e., PIHD), four CNNs were trained on five datasets, including PIHD, and tested on these datasets. The receiver operating characteristic curves of each model is compared to judge its performance. The content-preserving manipulations used in this dataset are more complex and distinct images are more difficult to distinguish, the CNNs trained on this dataset provide better image authentication performance. Even without retraining or fine-tuning, they can still obtain satisfactory image authentication performance on other datasets, fully demonstrating the generalizability of the PIHD dataset. In addition, we compare the area under curve of each model on different test sets. The results demonstrate that the performance of the networks trained on other comparison datasets varies considerably across test sets, while the performance trained on PIHD remains nearly constant across datasets, reflecting the stability of the PIHD dataset. Collectively, the networks trained on our dataset are stable and exhibit certain generalization ability, enabling them to cope with complex and diverse real-world editing operations.ConclusionIn this study, we design a dataset for the PIH task that uses richer image content-preserving manipulations and exhibits a certain randomness to restore the real application scenario to the maximum extent. In addition, images with the same semantic meaning as the original images are added to the distinct images in the dataset, increasing the difficulty in compliance with the PIH task. This step enables the trained CNNs to cope with more realistic and complex practical application scenarios. We test the dataset with different models on various datasets, including our proposed dataset. A large number of experiments demonstrate the effectiveness, generalizability, and stability of this dataset. Hence, this dataset can promote the development of the PIH field.关键词:perceptual image hashing;image authentication;data augmentation;dataset;content-preserving manipulation
摘要:ObjectiveWith the rapid development of social media, multimedia information on the internet is updated at an exponential rate. Obtaining and transmitting digital images have become convenient, considerably increasing the risk of malicious tampering and forgery of images. Accordingly, increasing attention is given to image authentication and content protection. Many image authentication schemes have emerged recently, such as watermarking, the use of digital signatures, and perceptual image hashing (PIH). PIH, also known as image abstract or image fingerprint, is an effective technique for image authentication that has attracted widespread research attention in recent years. The goal of PIH is to authenticate an image by compressing perceptual robust features into a compact hash sequence with a fixed length. However, a general dataset in this field is lacking, and the dataset constructed using other methods have many problems. On the one hand, the types of image content-preserving manipulations used in these datasets are few and the intensity of attacks is relatively weak. On the other hand, the distinct images used in these datasets are extremely different from the images that must be authenticated, making it easy to distinguish them from each other. The convolutional neural networks (CNNs) trained by these datasets have poor generalizability and can hardly cope with the complex and diverse image editing operations in reality. This important factor has limited the development of the PIH field.MethodOn the basis of the preceding knowledge, we propose a specialized dataset based on various manipulations in this study. This dataset can deal with complex image authentication scenarios. The proposed dataset is divided into three subsets: original, perceptual identical, and perceptual distinct images. The latter two correspond to the robustness and discrimination of PIH, respectively. Original images are selected from ImageNet1K, and each of them corresponds to one category. For identical images, we summarize the content-preserving manipulations commonly used in the field of PIH and group them into four major categories: geometric, enhancement, filter, and editing manipulations. Each major category is subdivided into different types, for a total of 35 single-image content-preserving manipulations. To ensure the diversity and reflect the randomness of image editing in reality, we set a threshold for each type of image content-preserving manipulation and let them randomly select the attack intensity within this range. In addition, we randomly combine multiple single-image content-preserving manipulations to form combination manipulations. Some combined manipulations in the test set have not been learned in the training set due to the randomness. This result is also in line with practical application scenarios, because many unlearned, combined image editing manipulations exist in reality. For perceptual distinct images, except for a portion of images unrelated to the original images, the other portions are selected from the same category that corresponds to each original image, increasing the difficulty of the dataset and improving the generalizability of the trained CNNs. Compared with previously adopted datasets, our dataset conforms more to the actual application scenario of the PIH task. Our dataset contains 1 200 original images, and each original image is subjected to 48 image content-preserving manipulations to generate 48 perceptual identical images. To balance the number of perceptual identical and distinct images, we also select 48 perceptual distinct images for each original image. Then, 24 images are randomly selected among them, and the other 24 images are semantically similar to the original images. Therefore, each batch contains 1 original image, 48 perceptual identical images, and 48 perceptual distinct images, for a total of 97 images. Our dataset has 1 200 original images or 116 400 images in total. The large amount of data ensures the effective training of CNNs.ResultTo validate the performance of the dataset proposed in this study (i.e., PIHD), four CNNs were trained on five datasets, including PIHD, and tested on these datasets. The receiver operating characteristic curves of each model is compared to judge its performance. The content-preserving manipulations used in this dataset are more complex and distinct images are more difficult to distinguish, the CNNs trained on this dataset provide better image authentication performance. Even without retraining or fine-tuning, they can still obtain satisfactory image authentication performance on other datasets, fully demonstrating the generalizability of the PIHD dataset. In addition, we compare the area under curve of each model on different test sets. The results demonstrate that the performance of the networks trained on other comparison datasets varies considerably across test sets, while the performance trained on PIHD remains nearly constant across datasets, reflecting the stability of the PIHD dataset. Collectively, the networks trained on our dataset are stable and exhibit certain generalization ability, enabling them to cope with complex and diverse real-world editing operations.ConclusionIn this study, we design a dataset for the PIH task that uses richer image content-preserving manipulations and exhibits a certain randomness to restore the real application scenario to the maximum extent. In addition, images with the same semantic meaning as the original images are added to the distinct images in the dataset, increasing the difficulty in compliance with the PIH task. This step enables the trained CNNs to cope with more realistic and complex practical application scenarios. We test the dataset with different models on various datasets, including our proposed dataset. A large number of experiments demonstrate the effectiveness, generalizability, and stability of this dataset. Hence, this dataset can promote the development of the PIH field.关键词:perceptual image hashing;image authentication;data augmentation;dataset;content-preserving manipulation- 4
- |
- 1
- |
- 0
发布时间:2024-02-16 -
High-security image steganography with the combination of multiple competition and channel attention
 摘要:ObjectiveThe advancement of current steganographic techniques has been facing many challenges. The method of modifying the original image to hide the secret information is traceable, rendering it susceptible to detection by steganalyzers. The coverless steganographic method improves the security of steganography. However, it has limitations, such as small embedding capacity, large image database, and difficulty extracting secret information. The cover image generative steganography method also produces small and unnatural generated images. Introducing adversarial examples provides a new approach to address these limitations by adding subtle perturbations to the original image to form an adversarial image that is not visually distinguishable and causes wrong classification results to be outputted with high confidence. Thus, the security of image steganography is enhanced. However, most existing steganographic algorithms based on adversarial examples can only design adversarial samples for one steganalyzer, making them vulnerable to the latest convolutional neural network-based steganalyzers, such as SRNet and Zhu-Net. In response to this problem, a high-security image steganography method with the combination of multiple competition and channel attention is proposed in this study.MethodIn the proposed method, we generate the adversarial noise V using the generator G, which employs the U-Net architecture with added channel-attention modules. Subsequently, the adversarial noise V is added to the original image X to obtain the adversarial image. The pixel space minimum mean square error loss MSE_loss is adopted to train the generator network G. Thus, high-quality and semantically meaningful adversarial images are generated. Then, we generate the stego image from the original image X using the steganography network (SN) and input the original image X and its corresponding stego image into the steganalysis optimization network to optimize its parameters. Moreover, we build multiple steganalysis adversarial networks (SANs) to discriminate the original image X and its adversarial image and assign different scores to the adversarial and original images, providing multiple discriminant losses SDO_loss1. Furthermore, we embed secret messages into the adversarial image through the SN to generate the enhanced stego image. The adversarial image and the enhanced stego image are reinput into the optimized multiple steganalyzers to improve the antisteganalysis performance of the adversarial image. The SAN evaluates the data-hiding capability of the adversarial image and provides multiple discriminant losses SDO_loss2. Additionally, the weighted superposition of the MSE_loss, namely, the multiple steganalysis discrimination losses SDO_loss1 and SDO_loss2, is employed as the cumulative loss function of generator G to improve the image quality of the adversarial image and its antisteganalysis ability. Finally, the proposed method enables fast and stable network convergence and high stego image visual quality and antisteganalysis ability.ResultFirst, we select four high-performance deep-learning steganalyzers, namely, Xu-Net, Ye-Net, SRNet, and Zhu-Net, for simultaneous adversarial training to improve the antisteganalysis ability of adversarial images. However, simultaneously conducting experiments with four steganalysis networks may sharply increase the number of model parameters, resulting in slow training speed and long training period. Furthermore, each iteration of adversarial noise is generated according to the gradient feedback of the four steganalysis networks during the adversarial image generation process. A consequence of this approach is that the original image is subjected to excessive, unnecessary adversarial noise, leading to low-quality adversarial images. In response to this issue, we execute ablation experiments on different steganalysis networks employed in training. These experiments aim to decrease model parameters, reduce training time, and ultimately enhance the quality of adversarial images for their antisteganalysis capability improvement. The role of the generator is to produce adversarial noise, which is subsequently incorporated into the original image to generate adversarial images. Different positions of adversarial noise in the original image can cause distinct perturbations to the steganalysis network, and the quality of the generated adversarial images can be influenced differently. This study introduces ablation experiments by altering the addition of the channel attention module at various positions of the generator to examine the effectiveness of the channel attention module. The parameters of the generator loss function are fine-tuned by conducting the ablation experiment. Subsequently, we generate 2 000 adversarial images using the proposed model and evaluate the quality of these images. The results reveal that the average peak signal-to-noise ratio (PSNR) value of the 2 000 generated adversarial images is 39.925 1 dB. Furthermore, more than 99.55% of these images have a PSNR value greater than 39 dB, and more than 75% of the generated adversarial images have a PSNR value greater than 40 dB. Additionally, the average structural similarity index measure (SSIM) value of the generated adversarial images is 0.962 5. Among these images, more than 69.85% have an SSIM value greater than 0.955, and more than 55.6% of the adversarial samples have an SSIM value greater than 0.960. These results indicate that compared with the original images, the generated adversarial images exhibit high visual similarity. Finally, we conduct a comparative study of the proposed method with the current state-of-the-art methods on the BOSS Base 1.01 dataset. The experiments are conducted on the BOSS Base 1.01 dataset, and the results are compared with those of the current state-of-the-art methods. Compared with the four methods, the five steganalysis methods show decreased average accuracy by 1.6% after training on the original steganographic images. Compared with other four methods, the five steganalysis methods show decreased average accuracy by 6.8% after further training with adversarial images and enhanced steganographic images. The experimental results indicate that the proposed steganographic method significantly improves the security of the steganographic algorithm.ConclusionIn this study, we propose a steganographic architecture based on the U-Net framework with lightweight channel attention modules to generate adversarial images, which can resist multiple steganalysis networks. The experiment results demonstrate that the security and generalization of the algorithm we propose exceed those of the compared steganographic methods.关键词:steganography;steganalysis;adversarial images;channel attention;generative adversarial network(GAN)
摘要:ObjectiveThe advancement of current steganographic techniques has been facing many challenges. The method of modifying the original image to hide the secret information is traceable, rendering it susceptible to detection by steganalyzers. The coverless steganographic method improves the security of steganography. However, it has limitations, such as small embedding capacity, large image database, and difficulty extracting secret information. The cover image generative steganography method also produces small and unnatural generated images. Introducing adversarial examples provides a new approach to address these limitations by adding subtle perturbations to the original image to form an adversarial image that is not visually distinguishable and causes wrong classification results to be outputted with high confidence. Thus, the security of image steganography is enhanced. However, most existing steganographic algorithms based on adversarial examples can only design adversarial samples for one steganalyzer, making them vulnerable to the latest convolutional neural network-based steganalyzers, such as SRNet and Zhu-Net. In response to this problem, a high-security image steganography method with the combination of multiple competition and channel attention is proposed in this study.MethodIn the proposed method, we generate the adversarial noise V using the generator G, which employs the U-Net architecture with added channel-attention modules. Subsequently, the adversarial noise V is added to the original image X to obtain the adversarial image. The pixel space minimum mean square error loss MSE_loss is adopted to train the generator network G. Thus, high-quality and semantically meaningful adversarial images are generated. Then, we generate the stego image from the original image X using the steganography network (SN) and input the original image X and its corresponding stego image into the steganalysis optimization network to optimize its parameters. Moreover, we build multiple steganalysis adversarial networks (SANs) to discriminate the original image X and its adversarial image and assign different scores to the adversarial and original images, providing multiple discriminant losses SDO_loss1. Furthermore, we embed secret messages into the adversarial image through the SN to generate the enhanced stego image. The adversarial image and the enhanced stego image are reinput into the optimized multiple steganalyzers to improve the antisteganalysis performance of the adversarial image. The SAN evaluates the data-hiding capability of the adversarial image and provides multiple discriminant losses SDO_loss2. Additionally, the weighted superposition of the MSE_loss, namely, the multiple steganalysis discrimination losses SDO_loss1 and SDO_loss2, is employed as the cumulative loss function of generator G to improve the image quality of the adversarial image and its antisteganalysis ability. Finally, the proposed method enables fast and stable network convergence and high stego image visual quality and antisteganalysis ability.ResultFirst, we select four high-performance deep-learning steganalyzers, namely, Xu-Net, Ye-Net, SRNet, and Zhu-Net, for simultaneous adversarial training to improve the antisteganalysis ability of adversarial images. However, simultaneously conducting experiments with four steganalysis networks may sharply increase the number of model parameters, resulting in slow training speed and long training period. Furthermore, each iteration of adversarial noise is generated according to the gradient feedback of the four steganalysis networks during the adversarial image generation process. A consequence of this approach is that the original image is subjected to excessive, unnecessary adversarial noise, leading to low-quality adversarial images. In response to this issue, we execute ablation experiments on different steganalysis networks employed in training. These experiments aim to decrease model parameters, reduce training time, and ultimately enhance the quality of adversarial images for their antisteganalysis capability improvement. The role of the generator is to produce adversarial noise, which is subsequently incorporated into the original image to generate adversarial images. Different positions of adversarial noise in the original image can cause distinct perturbations to the steganalysis network, and the quality of the generated adversarial images can be influenced differently. This study introduces ablation experiments by altering the addition of the channel attention module at various positions of the generator to examine the effectiveness of the channel attention module. The parameters of the generator loss function are fine-tuned by conducting the ablation experiment. Subsequently, we generate 2 000 adversarial images using the proposed model and evaluate the quality of these images. The results reveal that the average peak signal-to-noise ratio (PSNR) value of the 2 000 generated adversarial images is 39.925 1 dB. Furthermore, more than 99.55% of these images have a PSNR value greater than 39 dB, and more than 75% of the generated adversarial images have a PSNR value greater than 40 dB. Additionally, the average structural similarity index measure (SSIM) value of the generated adversarial images is 0.962 5. Among these images, more than 69.85% have an SSIM value greater than 0.955, and more than 55.6% of the adversarial samples have an SSIM value greater than 0.960. These results indicate that compared with the original images, the generated adversarial images exhibit high visual similarity. Finally, we conduct a comparative study of the proposed method with the current state-of-the-art methods on the BOSS Base 1.01 dataset. The experiments are conducted on the BOSS Base 1.01 dataset, and the results are compared with those of the current state-of-the-art methods. Compared with the four methods, the five steganalysis methods show decreased average accuracy by 1.6% after training on the original steganographic images. Compared with other four methods, the five steganalysis methods show decreased average accuracy by 6.8% after further training with adversarial images and enhanced steganographic images. The experimental results indicate that the proposed steganographic method significantly improves the security of the steganographic algorithm.ConclusionIn this study, we propose a steganographic architecture based on the U-Net framework with lightweight channel attention modules to generate adversarial images, which can resist multiple steganalysis networks. The experiment results demonstrate that the security and generalization of the algorithm we propose exceed those of the compared steganographic methods.关键词:steganography;steganalysis;adversarial images;channel attention;generative adversarial network(GAN)- 5
- |
- 1
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveCovert communication is a pivotal research area in the field of information security. A highly covert and secure covert channel for transmitting sensitive information must be developed to safeguard the privacy of communication users and prevent occurrences of eavesdropping on confidential data transmissions. Most methods build covert channels by tunneling multimedia streams. However, the problem of packet loss caused by fluctuations in network transmission is not considered. This study proposes a covert communication method that is robust to network anomalies and is based on cross-modal information retrieval and provably secure steganography.MethodWe propose a general covert communication framework named robust covert communication (RoCC), which is based on cross-modal information retrieval and provably secure steganography. Artificially generated information from artificial intelligence (AI) systems, including deep synthesis models, AI-driven artwork, intelligent voice assistants, and conversational chatbots, has emerged. These AI models can synthesize multimodal data, such as videos, images, audio, and text. The practical application of provably secure steganography has become a reality as generative models make significant strides. Thus, we introduce generative models and provably secure steganography techniques into our framework, embedding secret messages within the cover text data. Furthermore, the domain of speech synthesis and recognition has witnessed the advent of numerous mature open-source models, facilitating seamless cross-modal conversion between speech and text. Our approach employs a combination of direct and indirect communication. In direct communication using voice over internet protocol (VoIP) network call service, real-time synthesized audio stream data are delivered, and the receiver can restore the text through voice recognition. Indirect communication uses a public network database for steganographic text data transmission. The receiver restores lost text semantics because of network packet loss and speech recognition errors via text semantic similarity matching. The entire communication process can be succinctly described as follows. Assuming that the sender of confidential data is Alice and the recipient is Bob, Alice and Bob share the same generative model and parameter settings for provably secure steganography. Alice embeds the confidential data into the generated text data using provably secure steganography techniques and publishes it on a publicly accessible and searchable network database. The only means of direct communication between the two parties is through VoIP network voice calls. Thus, the potential loss of network data packets is acknowledged. On the basis of the preserved semantic information, Bob performs cross-modal information retrieval from the public database and successfully locates the corresponding steganographic text data within the cover text. Subsequently, Bob recovers the confidential data from the steganographic texts by using the same generative model and parameter settings for steganography.ResultThe results of speech recognition experiments indicate that speech recognition often leads to semantic loss issues. The sentence error rate of the best model, standing at a mere 0.612 5, fails to meet the text recovery capability required for constructing covert channels through direct cross-modal transformations. Text similarity analysis experiments indicate that the best model can achieve a recall metric of 1.0, thereby theoretically enabling complete semantic information restoration. The experiment on combating network packet loss shows that RoCC achieves an impressive information recovery rate of 0.992 1 when the packet loss rate is 10% with a K value of 2. This finding demonstrates the exceptional resilience of RoCC to network anomalies and establishes it as the current state-of-the-art solution. In the experiment on real-time performance, we validate the high efficiency of the RoCC system in various components, such as speech synthesis and recognition, secure steganographic encoding and decoding, and text semantic similarity analysis. These results demonstrate the ability of RoCC to meet the real-time requirements of covert channel communication. In comparative experiments, RoCC is compared with eight representative methods. The results show that RoCC has outstanding advantages in terms of protocol versatility, robustness, and data steganography as provable security. Compared with the current robust model, RoCC shows increased resistance to packet loss rate by 5% in the antinetwork packet loss experiment.ConclusionThe covert communication framework proposed in this study combines the advantages of provably secure steganography, generative machine learning methods, and cross-modal retrieval methods, making the covert communication process increasingly stealthy and secure. We also implement the first method of using semantic similarity to restore data communication lost due to an abnormal transmission process. After experimental verification, our framework meets the requirements of real-time communication in terms of performance, and the real-time transmission rate reaches 73~136 bps.关键词:information hiding;covert communication;generative model;data cross-modal conversion;provable security steganography;multimedia information retrieval;similarity analysis
摘要:ObjectiveCovert communication is a pivotal research area in the field of information security. A highly covert and secure covert channel for transmitting sensitive information must be developed to safeguard the privacy of communication users and prevent occurrences of eavesdropping on confidential data transmissions. Most methods build covert channels by tunneling multimedia streams. However, the problem of packet loss caused by fluctuations in network transmission is not considered. This study proposes a covert communication method that is robust to network anomalies and is based on cross-modal information retrieval and provably secure steganography.MethodWe propose a general covert communication framework named robust covert communication (RoCC), which is based on cross-modal information retrieval and provably secure steganography. Artificially generated information from artificial intelligence (AI) systems, including deep synthesis models, AI-driven artwork, intelligent voice assistants, and conversational chatbots, has emerged. These AI models can synthesize multimodal data, such as videos, images, audio, and text. The practical application of provably secure steganography has become a reality as generative models make significant strides. Thus, we introduce generative models and provably secure steganography techniques into our framework, embedding secret messages within the cover text data. Furthermore, the domain of speech synthesis and recognition has witnessed the advent of numerous mature open-source models, facilitating seamless cross-modal conversion between speech and text. Our approach employs a combination of direct and indirect communication. In direct communication using voice over internet protocol (VoIP) network call service, real-time synthesized audio stream data are delivered, and the receiver can restore the text through voice recognition. Indirect communication uses a public network database for steganographic text data transmission. The receiver restores lost text semantics because of network packet loss and speech recognition errors via text semantic similarity matching. The entire communication process can be succinctly described as follows. Assuming that the sender of confidential data is Alice and the recipient is Bob, Alice and Bob share the same generative model and parameter settings for provably secure steganography. Alice embeds the confidential data into the generated text data using provably secure steganography techniques and publishes it on a publicly accessible and searchable network database. The only means of direct communication between the two parties is through VoIP network voice calls. Thus, the potential loss of network data packets is acknowledged. On the basis of the preserved semantic information, Bob performs cross-modal information retrieval from the public database and successfully locates the corresponding steganographic text data within the cover text. Subsequently, Bob recovers the confidential data from the steganographic texts by using the same generative model and parameter settings for steganography.ResultThe results of speech recognition experiments indicate that speech recognition often leads to semantic loss issues. The sentence error rate of the best model, standing at a mere 0.612 5, fails to meet the text recovery capability required for constructing covert channels through direct cross-modal transformations. Text similarity analysis experiments indicate that the best model can achieve a recall metric of 1.0, thereby theoretically enabling complete semantic information restoration. The experiment on combating network packet loss shows that RoCC achieves an impressive information recovery rate of 0.992 1 when the packet loss rate is 10% with a K value of 2. This finding demonstrates the exceptional resilience of RoCC to network anomalies and establishes it as the current state-of-the-art solution. In the experiment on real-time performance, we validate the high efficiency of the RoCC system in various components, such as speech synthesis and recognition, secure steganographic encoding and decoding, and text semantic similarity analysis. These results demonstrate the ability of RoCC to meet the real-time requirements of covert channel communication. In comparative experiments, RoCC is compared with eight representative methods. The results show that RoCC has outstanding advantages in terms of protocol versatility, robustness, and data steganography as provable security. Compared with the current robust model, RoCC shows increased resistance to packet loss rate by 5% in the antinetwork packet loss experiment.ConclusionThe covert communication framework proposed in this study combines the advantages of provably secure steganography, generative machine learning methods, and cross-modal retrieval methods, making the covert communication process increasingly stealthy and secure. We also implement the first method of using semantic similarity to restore data communication lost due to an abnormal transmission process. After experimental verification, our framework meets the requirements of real-time communication in terms of performance, and the real-time transmission rate reaches 73~136 bps.关键词:information hiding;covert communication;generative model;data cross-modal conversion;provable security steganography;multimedia information retrieval;similarity analysis- 3
- |
- 1
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveImage hiding has recently become a hotspot in the computer vision field. It aims to hide the secret image in a cover image imperceptibly and recover the secret image, preferably at the receiver. Traditional image hiding methods often adjust the cover image’s pixel value in the spatial domain or modify the cover image’s frequency coefficients to hide the secret information. These methods hide secret images through handcrafted feature information. Thus, these secret images can be detected easily by existing detection techniques. These methods have weak security and lack significant capabilities for hiding information in images. Therefore, they fall short of meeting the demands of large-capacity image hiding tasks. Image hiding methods based on deep learning have been quickly developed with the advancements in convolutional neural networks. These deep learning methods seek to achieve a high level of capacity, invisibility, and recovery accuracy. However, the existing image hiding techniques can be easily detected by deep learning analysis methods because of the rapid development of steganalysis. Handcrafted image hiding methods and image hiding methods based on deep learning are camouflaged from the content level to pursue the indistinguishability of the marked image and the cover image. The essence of image hiding is the pursuit of behavioral security; that is, the pursuit of hiding secret information is inseparable from the behavior of normal users to achieve good detection resistance. Therefore, we can camouflage at the content level and disguise at the behavior level. We innovatively use super-resolution, a common image processing technology, as our behavior camouflage means to realize image hiding from the behavior security perspective.MethodIn general, traditional image hiding techniques tend to prioritize the indistinguishability of the cover image and the secret image at the content level. However, we aim to achieve image hiding from a behavioral security perspective in our study. In particular, we aim to make steganographic behavior indistinguishable from regular super-resolution image processing behavior. The entire method can be divided into three modules: forward hiding, super-resolution behavior camouflage, and backward revealing. In the first module, a cover image and a secret image are inputted to the forward hiding module, resulting in a marked image that looks identical to the cover image but with hidden information and information that is lost during forward hiding. The second module involves a lightweight super-resolution rescaling network to realize behavior camouflage. Instead of using traditional convolution for upsampling and downsampling, bicubic interpolation is used. Moreover, we use a pretrained Visual Geometry Group-19(VGG19) network to extract high-level features and guide the generation of super-resolution behavior camouflage images. The final module is backward revealing. The marked image is first reconstructed using the reversibility of the behavior camouflage module. Then, the reconstructed image and auxiliary matrix are inputted into the backward revealing module to recover the secret image and the cover image.ResultExperiments are conducted on recovering secret images, camouflage effect of super-resolution behavior, parameter setting, and ablation. Results show that the invisibility, hiding capacity, and recovery accuracy of our method reach a good level. Only the recovery accuracy of our method is slightly lower than that of the current state-of-the-art (SOTA). In particular, the peak signal-to-noise ratio (PSNR) between the secret image and the recovered secret image using our method can reach 47.23 dB, which is approximately 0.92 dB less than that using SOTA. Moreover, the structural similarity index measure of our method can reach 0.993 8, which is 0.003 4 less than that of SOTA. However, compared with other methods besides SOTA, our method has advantages. Our method’s super-resolution behavior camouflage reaches a satisfactory level. Given the reversibility constraints, we do not look for top-of-the-line super-resolution effects. Our super-resolution behavior camouflage images have a PSNR of 27.43 dB and a perceptual index of 4.568 4, indicating that they reach the satisfaction of human eyes, whether subjectively or objectively. In addition to the above two main indicators, exploratory experiments on the selection of superparameters, module architecture, and loss function are conducted to find the optimal setting and achieve a good combination effect.ConclusionThis study proposes a new idea of image hiding in which the process of hiding the secret image, namely, super-resolution processing, is performed simultaneously to obtain a super-resolution behavioral camouflage image with secret information. Thus, the attention of unauthorized parties is diverted, and the protection of the secret image is realized. The experimental results show that our method can achieve high capacity, high invisibility, and high recovery accuracy and plays a good role in the confusion of unauthorized parties. Finally, camouflage images still maintain good visual effects.关键词:image hiding;invertible neural network(INN);behavior security;reversible behavior camouflage;super-resolution;deep learning
摘要:ObjectiveImage hiding has recently become a hotspot in the computer vision field. It aims to hide the secret image in a cover image imperceptibly and recover the secret image, preferably at the receiver. Traditional image hiding methods often adjust the cover image’s pixel value in the spatial domain or modify the cover image’s frequency coefficients to hide the secret information. These methods hide secret images through handcrafted feature information. Thus, these secret images can be detected easily by existing detection techniques. These methods have weak security and lack significant capabilities for hiding information in images. Therefore, they fall short of meeting the demands of large-capacity image hiding tasks. Image hiding methods based on deep learning have been quickly developed with the advancements in convolutional neural networks. These deep learning methods seek to achieve a high level of capacity, invisibility, and recovery accuracy. However, the existing image hiding techniques can be easily detected by deep learning analysis methods because of the rapid development of steganalysis. Handcrafted image hiding methods and image hiding methods based on deep learning are camouflaged from the content level to pursue the indistinguishability of the marked image and the cover image. The essence of image hiding is the pursuit of behavioral security; that is, the pursuit of hiding secret information is inseparable from the behavior of normal users to achieve good detection resistance. Therefore, we can camouflage at the content level and disguise at the behavior level. We innovatively use super-resolution, a common image processing technology, as our behavior camouflage means to realize image hiding from the behavior security perspective.MethodIn general, traditional image hiding techniques tend to prioritize the indistinguishability of the cover image and the secret image at the content level. However, we aim to achieve image hiding from a behavioral security perspective in our study. In particular, we aim to make steganographic behavior indistinguishable from regular super-resolution image processing behavior. The entire method can be divided into three modules: forward hiding, super-resolution behavior camouflage, and backward revealing. In the first module, a cover image and a secret image are inputted to the forward hiding module, resulting in a marked image that looks identical to the cover image but with hidden information and information that is lost during forward hiding. The second module involves a lightweight super-resolution rescaling network to realize behavior camouflage. Instead of using traditional convolution for upsampling and downsampling, bicubic interpolation is used. Moreover, we use a pretrained Visual Geometry Group-19(VGG19) network to extract high-level features and guide the generation of super-resolution behavior camouflage images. The final module is backward revealing. The marked image is first reconstructed using the reversibility of the behavior camouflage module. Then, the reconstructed image and auxiliary matrix are inputted into the backward revealing module to recover the secret image and the cover image.ResultExperiments are conducted on recovering secret images, camouflage effect of super-resolution behavior, parameter setting, and ablation. Results show that the invisibility, hiding capacity, and recovery accuracy of our method reach a good level. Only the recovery accuracy of our method is slightly lower than that of the current state-of-the-art (SOTA). In particular, the peak signal-to-noise ratio (PSNR) between the secret image and the recovered secret image using our method can reach 47.23 dB, which is approximately 0.92 dB less than that using SOTA. Moreover, the structural similarity index measure of our method can reach 0.993 8, which is 0.003 4 less than that of SOTA. However, compared with other methods besides SOTA, our method has advantages. Our method’s super-resolution behavior camouflage reaches a satisfactory level. Given the reversibility constraints, we do not look for top-of-the-line super-resolution effects. Our super-resolution behavior camouflage images have a PSNR of 27.43 dB and a perceptual index of 4.568 4, indicating that they reach the satisfaction of human eyes, whether subjectively or objectively. In addition to the above two main indicators, exploratory experiments on the selection of superparameters, module architecture, and loss function are conducted to find the optimal setting and achieve a good combination effect.ConclusionThis study proposes a new idea of image hiding in which the process of hiding the secret image, namely, super-resolution processing, is performed simultaneously to obtain a super-resolution behavioral camouflage image with secret information. Thus, the attention of unauthorized parties is diverted, and the protection of the secret image is realized. The experimental results show that our method can achieve high capacity, high invisibility, and high recovery accuracy and plays a good role in the confusion of unauthorized parties. Finally, camouflage images still maintain good visual effects.关键词:image hiding;invertible neural network(INN);behavior security;reversible behavior camouflage;super-resolution;deep learning- 3
- |
- 1
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveNowadays, many people upload their information to the Internet, but the transmission and storage processes have many security problems. In the early days, researchers used encryption technology to protect the information, easily attracting the attention of decipherers. Therefore, people began to study how to hide secret information in an image. The secret information is transmitted while avoiding the attention of potential attackers. Therefore, reversible data hiding technology has become one of the hotspots of security research. Reversible data hiding technology can embed secret data through subtle modifications to the original image. After the data are extracted, the image can be restored losslessly. The emergence of cloud storage and big data technology has encouraged many users to upload their images to the cloud server. Out of distrust of the service provider, the image is encrypted before being uploaded to the cloud server. Cloud storage service providers hope to embed additional data in images to facilitate image management, image retrieval, copyright protection, and other requirements. Therefore, for cloud applications, reversible data hiding in encrypted images (RDHEI) has attracted the attention of many researchers who hope to embed data in encrypted images for transmission to protect the carrier image effectively and ensure the security of embedded information. The existing RDHEI methods can be divided into two categories depending on whether vacating the space before encrypting the image is necessary: 1) vacating the room after encryption and 2) reserving the room before encryption (RRBE). The reversible data hiding technology for encrypted images plays an important role in military, medical, and other aspects. This algorithm can ensure that the content of the carrier is not leaked. It can also transmit secret information. However, most previous methods have problems, such as low data-embedding capacity, errors in data extraction, and poor visual quality of reconstructed images. Therefore, a reversible data hiding algorithm for high-capacity ciphertext images based on Kd-tree and entropy coding is proposed to solve these problems.MethodOur method needs preprocessing before image encryption. First, the median-edge detector(MED) predictor generates a prediction error absolute value image from the original image, and the prediction error absolute value image is divided into two regions, i.e., S0 region and S1 region. The S0 region contains the 5th bit plane to the most significant bit plane, and the Kd-tree algorithm is used to construct the Kd-tree concept subtree, which marks the blocks of the four-bit planes to determine whether the blocks can accommodate secret bits. The S1 region is from the least significant bit plane to the 4th bit plane, and the bitstream of each bit plane is compressed using arithmetic coding. The remaining space can be used to embed the secret data. After the image is encrypted with the encryption key, additional information is embedded to generate the encrypted image. During the stage of secret data embedding, the secret data are embedded according to the additional information and data hiding key to generate the secret image. In the decoding stage, the secret data are extracted, and the image is restored losslessly according to the additional information, encryption key, and data hiding key.ResultExperiments show that the proposed method can effectively reduce the number of reference pixels and additional information, thereby increasing the data embedding rate. The BOWS-2 data set is tested in the experiment. The average embedding capacity is 3.909 8 bit/pixel, which is higher than the existing five methods. Two indicators, peak signal-to-noise ratio(PSNR) and structural similarity index measure(SSIM), are used to evaluate the similarity between the original and restored images. Experimental results prove that in the data extraction and image restoration stage, the original image does not show a difference after the extraction of the secret data and the use of the image encryption key to decrypt the image. The analysis of the Kd-tree label through encryption shows that texture complexity significantly impacts the embedding of the image’s secret data. The higher the label provided by the relatively smooth image is, the higher the embedding capacity is.ConclusionFirst, the image pixels are predicted by the predictor. Then, the image pixels are classified and divided into two regions. This method adopts the framework of RRBE. The image must be preprocessed before image encryption. It achieves a higher embedding capacity than the related algorithms. It can also perfectly reconstruct the original image and ensure the security of encrypted images and additional data. At present, many disciplines are combined with deep learning. However, studies combining deep learning with reversible data hiding algorithms in the encrypted domain are lacking. In the future, we hope to achieve breakthroughs in this area and will pay considerable attention to the application of RDHEI in reality, not just in academic research.关键词:image encryption;Kd-tree label;MED predictor;reversible data hiding(RDH);prediction error
摘要:ObjectiveNowadays, many people upload their information to the Internet, but the transmission and storage processes have many security problems. In the early days, researchers used encryption technology to protect the information, easily attracting the attention of decipherers. Therefore, people began to study how to hide secret information in an image. The secret information is transmitted while avoiding the attention of potential attackers. Therefore, reversible data hiding technology has become one of the hotspots of security research. Reversible data hiding technology can embed secret data through subtle modifications to the original image. After the data are extracted, the image can be restored losslessly. The emergence of cloud storage and big data technology has encouraged many users to upload their images to the cloud server. Out of distrust of the service provider, the image is encrypted before being uploaded to the cloud server. Cloud storage service providers hope to embed additional data in images to facilitate image management, image retrieval, copyright protection, and other requirements. Therefore, for cloud applications, reversible data hiding in encrypted images (RDHEI) has attracted the attention of many researchers who hope to embed data in encrypted images for transmission to protect the carrier image effectively and ensure the security of embedded information. The existing RDHEI methods can be divided into two categories depending on whether vacating the space before encrypting the image is necessary: 1) vacating the room after encryption and 2) reserving the room before encryption (RRBE). The reversible data hiding technology for encrypted images plays an important role in military, medical, and other aspects. This algorithm can ensure that the content of the carrier is not leaked. It can also transmit secret information. However, most previous methods have problems, such as low data-embedding capacity, errors in data extraction, and poor visual quality of reconstructed images. Therefore, a reversible data hiding algorithm for high-capacity ciphertext images based on Kd-tree and entropy coding is proposed to solve these problems.MethodOur method needs preprocessing before image encryption. First, the median-edge detector(MED) predictor generates a prediction error absolute value image from the original image, and the prediction error absolute value image is divided into two regions, i.e., S0 region and S1 region. The S0 region contains the 5th bit plane to the most significant bit plane, and the Kd-tree algorithm is used to construct the Kd-tree concept subtree, which marks the blocks of the four-bit planes to determine whether the blocks can accommodate secret bits. The S1 region is from the least significant bit plane to the 4th bit plane, and the bitstream of each bit plane is compressed using arithmetic coding. The remaining space can be used to embed the secret data. After the image is encrypted with the encryption key, additional information is embedded to generate the encrypted image. During the stage of secret data embedding, the secret data are embedded according to the additional information and data hiding key to generate the secret image. In the decoding stage, the secret data are extracted, and the image is restored losslessly according to the additional information, encryption key, and data hiding key.ResultExperiments show that the proposed method can effectively reduce the number of reference pixels and additional information, thereby increasing the data embedding rate. The BOWS-2 data set is tested in the experiment. The average embedding capacity is 3.909 8 bit/pixel, which is higher than the existing five methods. Two indicators, peak signal-to-noise ratio(PSNR) and structural similarity index measure(SSIM), are used to evaluate the similarity between the original and restored images. Experimental results prove that in the data extraction and image restoration stage, the original image does not show a difference after the extraction of the secret data and the use of the image encryption key to decrypt the image. The analysis of the Kd-tree label through encryption shows that texture complexity significantly impacts the embedding of the image’s secret data. The higher the label provided by the relatively smooth image is, the higher the embedding capacity is.ConclusionFirst, the image pixels are predicted by the predictor. Then, the image pixels are classified and divided into two regions. This method adopts the framework of RRBE. The image must be preprocessed before image encryption. It achieves a higher embedding capacity than the related algorithms. It can also perfectly reconstruct the original image and ensure the security of encrypted images and additional data. At present, many disciplines are combined with deep learning. However, studies combining deep learning with reversible data hiding algorithms in the encrypted domain are lacking. In the future, we hope to achieve breakthroughs in this area and will pay considerable attention to the application of RDHEI in reality, not just in academic research.关键词:image encryption;Kd-tree label;MED predictor;reversible data hiding(RDH);prediction error- 2
- |
- 0
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveWith the rapid development of internet and communication technology, the remote desktop technique enables separating the confidential information and the screen in space. However, it also engenders information security risks of confidential information because of illegal screen shooting. How can illegal screen shooting be prevented and the related responsibility identified? Adding a robust watermark and revealing the message hidden in the shot image is preferred. By taking photos of the files displayed on the screen, the captured photos can realize efficient, high-quality information recording. The pictures taken on the screen not only record effective information but also destroy the possible watermark signal carried to a large extent, making the photo leakage behavior concealed and difficult to trace. Screen-shooting watermark is a challenging subject in digital watermark. In screen shooting, the information displayed on the screen is received through camera capturing and postprocessing operations to transmit information from the screen to the camera in the optical channel involving optical changes, digital-analog conversion, image scaling, and image distortion. Four main methods are used to deal with this subject, namely, key-point-, template-, frequency-domain-, and deep neural network(DNN)-based methods. Traditional methods and DNN-based methods have some solutions. However, neither of them could balance computational complexity, image quality, and watermark robustness. The calculation of key points in key-point based methods is always overly time-consuming for practical use. Template-based methods often bring great changes to the cover images, resulting in image quality degradation. Watermarks generated by the frequency-domain-based methods have poor robustness and could be easily destroyed. Almost all methods should correct and resize the warped image to its original image size for the following watermark extraction stage, which is the main reason why the watermarks in these methods could not achieve robustness to clipping and scaling in practice. To solve the above problems, the least dependent hiding for screen-shooting resilient watermarking method is proposed to consider computational complexity, image quality, and robustness comprehensively. The decoder-based reveal network only needs to disclose the watermark message from the corresponding location of the container image, which guarantees the semantic consistency of the reveal network and the embedding network. The embedded watermark, such as user name, time, and IP address, could be extracted under the screen-shooting attack or other attacks, and to imitate the information loss in screen shooting, an improved noise layer is designed for the training of our model.MethodFirst, the watermark embedding network in the dependent deep hiding(DDH) framework is greatly simplified, and the Sobel operator is added to introduce the edge information of the cover image. The scaling attack operation is added to the noise layer, and the perspective distortion correction preprocessing is removed because it limits the application range of screen-shooting resilient watermarking. The existing noise layer is redefined in the way that the image disturbance types are randomly selected and the parameters of the specific image disturbance types are randomly changed, which increases the sample equilibrium and diversity of the training data of the reveal network. The investigation of previous DNN-based methods reveals their watermark residuals visually approximate the edges of the cover images. A strong correlation exists between the edges of the cover images and the invisibility of the watermark. To improve robustness and reduce computation complexity, the edge map of the cover image extracted by the Sobel operator is concatenated with the feature map of the watermark. The watermark embedding network is divided into two parts according to whether the cover image is used in the convolution because the network part without cover image participating in it could be previously calculated in practice. Second, the existing noise layer is modified to simulate the image scaling operation in the screen shooting, so the widely used perspective distortion correction can be canceled. Considering the class-balance principle, a new design idea of noise layer is proposed, in which random decision modules are added to the noise layer to make the data augmentation stronger than the original image disturbing effects. When training the network, learned perceptual image patch similarity(LPIPS) loss, L2 loss, and structural similarity index measure(SSIM) loss are used to constrain the visual similarity of the cover image and the container image while information entropy loss and weighted cross entropy loss are used to reconstruct the watermark with the form of a single-channel binary image. Model training and testing is carried out based on PyTorch. PyTorch is used to implement least dependent hiding(LDH) with NVIDIA GeForce 2080Ti GPU and Intel Core i7-9700 3.00 GHz CPU. The whole neural network is optimized by Adam optimizer.The initial learning rate is set to 1e-3, which is then reduced 90% every 20 epochs. In the training, the input image resolution is 256 × 256 and the batch size is 2. A pretrained model trained without geometric transformation in the noise layer is used to initialize the model.ResultExperimental results show the proposed noise layer is more effective than the three latest methods on the DIVerse 2K(DIV2K) dataset. The proposed method achieves the highest peak signal-to-noise ratio(PSNR) and SSIM index, which improves PSNR by 12 dB and SSIM by 0.006 compared with the second-best method—universal deep hiding (UDH) if no image attacks are applied. Moreover, it ranks second in accuracy and F1 index if no image attacks are applied. Compared with the same network framework using the noise layer proposed by the previous work, our algorithm achieves better indicators and higher accuracy for the watermark extraction in both modes with and without image attacks, which proves the noise layer proposed is indeed helpful to increase the training to improve the accuracy and robustness of watermark extraction. The watermark can be extracted from the screen shot images in the range of 10 cm to more than 50 cm, and it has a high extraction success rate at a usual distance.ConclusionIn this paper, the least dependent hiding for screen-shooting resilient watermarking is proposed, which comprehensively balances computational complexity, image quality, and robustness. An effective noise layer improvement measure is also designed, which helps our algorithm perform better in image quality and watermark robustness. The proposed algorithm has the advantages of high embedding efficiency, high robustness, and high transparency, which means wider application range compared with the existing methods.关键词:digital watermark;screen-to-camera channel;fully convolutional network;dependent hiding;noise layer
摘要:ObjectiveWith the rapid development of internet and communication technology, the remote desktop technique enables separating the confidential information and the screen in space. However, it also engenders information security risks of confidential information because of illegal screen shooting. How can illegal screen shooting be prevented and the related responsibility identified? Adding a robust watermark and revealing the message hidden in the shot image is preferred. By taking photos of the files displayed on the screen, the captured photos can realize efficient, high-quality information recording. The pictures taken on the screen not only record effective information but also destroy the possible watermark signal carried to a large extent, making the photo leakage behavior concealed and difficult to trace. Screen-shooting watermark is a challenging subject in digital watermark. In screen shooting, the information displayed on the screen is received through camera capturing and postprocessing operations to transmit information from the screen to the camera in the optical channel involving optical changes, digital-analog conversion, image scaling, and image distortion. Four main methods are used to deal with this subject, namely, key-point-, template-, frequency-domain-, and deep neural network(DNN)-based methods. Traditional methods and DNN-based methods have some solutions. However, neither of them could balance computational complexity, image quality, and watermark robustness. The calculation of key points in key-point based methods is always overly time-consuming for practical use. Template-based methods often bring great changes to the cover images, resulting in image quality degradation. Watermarks generated by the frequency-domain-based methods have poor robustness and could be easily destroyed. Almost all methods should correct and resize the warped image to its original image size for the following watermark extraction stage, which is the main reason why the watermarks in these methods could not achieve robustness to clipping and scaling in practice. To solve the above problems, the least dependent hiding for screen-shooting resilient watermarking method is proposed to consider computational complexity, image quality, and robustness comprehensively. The decoder-based reveal network only needs to disclose the watermark message from the corresponding location of the container image, which guarantees the semantic consistency of the reveal network and the embedding network. The embedded watermark, such as user name, time, and IP address, could be extracted under the screen-shooting attack or other attacks, and to imitate the information loss in screen shooting, an improved noise layer is designed for the training of our model.MethodFirst, the watermark embedding network in the dependent deep hiding(DDH) framework is greatly simplified, and the Sobel operator is added to introduce the edge information of the cover image. The scaling attack operation is added to the noise layer, and the perspective distortion correction preprocessing is removed because it limits the application range of screen-shooting resilient watermarking. The existing noise layer is redefined in the way that the image disturbance types are randomly selected and the parameters of the specific image disturbance types are randomly changed, which increases the sample equilibrium and diversity of the training data of the reveal network. The investigation of previous DNN-based methods reveals their watermark residuals visually approximate the edges of the cover images. A strong correlation exists between the edges of the cover images and the invisibility of the watermark. To improve robustness and reduce computation complexity, the edge map of the cover image extracted by the Sobel operator is concatenated with the feature map of the watermark. The watermark embedding network is divided into two parts according to whether the cover image is used in the convolution because the network part without cover image participating in it could be previously calculated in practice. Second, the existing noise layer is modified to simulate the image scaling operation in the screen shooting, so the widely used perspective distortion correction can be canceled. Considering the class-balance principle, a new design idea of noise layer is proposed, in which random decision modules are added to the noise layer to make the data augmentation stronger than the original image disturbing effects. When training the network, learned perceptual image patch similarity(LPIPS) loss, L2 loss, and structural similarity index measure(SSIM) loss are used to constrain the visual similarity of the cover image and the container image while information entropy loss and weighted cross entropy loss are used to reconstruct the watermark with the form of a single-channel binary image. Model training and testing is carried out based on PyTorch. PyTorch is used to implement least dependent hiding(LDH) with NVIDIA GeForce 2080Ti GPU and Intel Core i7-9700 3.00 GHz CPU. The whole neural network is optimized by Adam optimizer.The initial learning rate is set to 1e-3, which is then reduced 90% every 20 epochs. In the training, the input image resolution is 256 × 256 and the batch size is 2. A pretrained model trained without geometric transformation in the noise layer is used to initialize the model.ResultExperimental results show the proposed noise layer is more effective than the three latest methods on the DIVerse 2K(DIV2K) dataset. The proposed method achieves the highest peak signal-to-noise ratio(PSNR) and SSIM index, which improves PSNR by 12 dB and SSIM by 0.006 compared with the second-best method—universal deep hiding (UDH) if no image attacks are applied. Moreover, it ranks second in accuracy and F1 index if no image attacks are applied. Compared with the same network framework using the noise layer proposed by the previous work, our algorithm achieves better indicators and higher accuracy for the watermark extraction in both modes with and without image attacks, which proves the noise layer proposed is indeed helpful to increase the training to improve the accuracy and robustness of watermark extraction. The watermark can be extracted from the screen shot images in the range of 10 cm to more than 50 cm, and it has a high extraction success rate at a usual distance.ConclusionIn this paper, the least dependent hiding for screen-shooting resilient watermarking is proposed, which comprehensively balances computational complexity, image quality, and robustness. An effective noise layer improvement measure is also designed, which helps our algorithm perform better in image quality and watermark robustness. The proposed algorithm has the advantages of high embedding efficiency, high robustness, and high transparency, which means wider application range compared with the existing methods.关键词:digital watermark;screen-to-camera channel;fully convolutional network;dependent hiding;noise layer- 5
- |
- 1
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveIn recent years, digital media have become central to the exchange of information in our daily lives. With the rapid development of image editing tools and deep learning techniques, tampering with transmitted images is easy. Image splicing is one of the most common types of image tampering. Malicious image splicing challenges reputation, law, and politics. Therefore, various approaches have been proposed for detecting image splicing forgeries. Deep learning has also been successfully applied in image splicing detection. However, the existing deep learning-based works usually preprocess the input images by extracting features filtered by the high-pass filters with fixed parameters, which does not consider the differences between images.MethodTherefore, a new image splicing detection algorithm is proposed in this paper. First, an adaptive residual module (ARM) is designed to highlight the splicing traces. In the ARM, the residual after the convolution operation is serialized several times, and the attention mechanism is used to realize the nonlinear interaction between channels after each connection. Unlike ordinary filters with fixed parameters, the ARM module entirely relies on the feature reuse and attention mechanism of residuals to retain and enlarge the details of the splicing. Then, a squeeze and excitation (SE) module is used to reduce the inter channel information redundancy generated by ARM residual feature extraction. The SE module uses an average adaptive pool to generate channel statistics information on global space and the gating mechanism of the Sigmoid activation function to learn channel weights from channel dependencies. Finally, a new image splicing detection algorithm is proposed by combining with the proposed ARM and the backbone network EffcientNet, a model with excellent performance in image classification.ResultExperimental results show the proposed algorithm achieves 98.95%, 98.88%, 100%, 100%, and 88.20% detection accuracies on CASIA image tampering detection evaluation database(CASIA I), CASIA II, COLUMBIA COLOR, NIST special database 16(NIST16), and FaceForensic++, respectively, and obtains higher accuracy than the existing algorithms. Moreover, the proposed ARM algorithm improves the accuracy of backbone network by 3.94% on the CASIA II dataset. Regarding the computational time, on the CASIA II dataset, the training time per batch of the proposed algorithm is 71.75 s, and the test time for a single image is 0.011 s, which is less than the existing algorithms. In addition, the size of the parameters of ARM is 0.003 6 MB, which is about 2‰ of the parameters size of the backbone network EfficientNet, and the FLOPs are about 0.037 G.ConclusionThis paper proposes an image splicing detection algorithm based on ARM, and the proposed algorithm performs well on five public datasets. The designed ARM is a plug-and-play lightweight, adaptive feature extraction module, and it can be migrated on other models, such as Xception and ResNet.关键词:image forensics;deep neural network;image splicing detection;adaptive residual;EfficientNet
摘要:ObjectiveIn recent years, digital media have become central to the exchange of information in our daily lives. With the rapid development of image editing tools and deep learning techniques, tampering with transmitted images is easy. Image splicing is one of the most common types of image tampering. Malicious image splicing challenges reputation, law, and politics. Therefore, various approaches have been proposed for detecting image splicing forgeries. Deep learning has also been successfully applied in image splicing detection. However, the existing deep learning-based works usually preprocess the input images by extracting features filtered by the high-pass filters with fixed parameters, which does not consider the differences between images.MethodTherefore, a new image splicing detection algorithm is proposed in this paper. First, an adaptive residual module (ARM) is designed to highlight the splicing traces. In the ARM, the residual after the convolution operation is serialized several times, and the attention mechanism is used to realize the nonlinear interaction between channels after each connection. Unlike ordinary filters with fixed parameters, the ARM module entirely relies on the feature reuse and attention mechanism of residuals to retain and enlarge the details of the splicing. Then, a squeeze and excitation (SE) module is used to reduce the inter channel information redundancy generated by ARM residual feature extraction. The SE module uses an average adaptive pool to generate channel statistics information on global space and the gating mechanism of the Sigmoid activation function to learn channel weights from channel dependencies. Finally, a new image splicing detection algorithm is proposed by combining with the proposed ARM and the backbone network EffcientNet, a model with excellent performance in image classification.ResultExperimental results show the proposed algorithm achieves 98.95%, 98.88%, 100%, 100%, and 88.20% detection accuracies on CASIA image tampering detection evaluation database(CASIA I), CASIA II, COLUMBIA COLOR, NIST special database 16(NIST16), and FaceForensic++, respectively, and obtains higher accuracy than the existing algorithms. Moreover, the proposed ARM algorithm improves the accuracy of backbone network by 3.94% on the CASIA II dataset. Regarding the computational time, on the CASIA II dataset, the training time per batch of the proposed algorithm is 71.75 s, and the test time for a single image is 0.011 s, which is less than the existing algorithms. In addition, the size of the parameters of ARM is 0.003 6 MB, which is about 2‰ of the parameters size of the backbone network EfficientNet, and the FLOPs are about 0.037 G.ConclusionThis paper proposes an image splicing detection algorithm based on ARM, and the proposed algorithm performs well on five public datasets. The designed ARM is a plug-and-play lightweight, adaptive feature extraction module, and it can be migrated on other models, such as Xception and ResNet.关键词:image forensics;deep neural network;image splicing detection;adaptive residual;EfficientNet- 2
- |
- 0
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveThe rapid development of the internet and the proliferation of effective and user-friendly picture editing software have resulted in an explosion of modified images on the internet. Although these modified images can bring some benefits (e.g., landscape beautification and face photo enhancement), they also have many negative effects on people
摘要:ObjectiveThe rapid development of the internet and the proliferation of effective and user-friendly picture editing software have resulted in an explosion of modified images on the internet. Although these modified images can bring some benefits (e.g., landscape beautification and face photo enhancement), they also have many negative effects on people- 2
- |
- 0
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveImage information becomes particularly important with the widespread application of intelligent power inspection. However, the rapid development of image tampering technology provides unscrupulous elements with a new way to harm power systems. As an important component of power systems, substations are responsible for the interconversion of different voltage levels. Ensuring the full-time output of stable voltage and the reasonable use of substation resources is the basis for the safe and stable operation of an entire power network. However, if the collected substation images are maliciously tampered with, then this condition may not only cause the failure of a smart grid system but also make operators misjudge the actual situation of the substation, eventually leading to power system failure and may even cause major accidents, such as large-scale power outages, resulting in irreversible losses to national production. Therefore, detecting tampered images of substations is a key task in ensuring the stability of power systems. The complex background of tampered images and the different scales of tampered contents cause existing detection models to experience the problems of false detection and leakage detection. Meanwhile, related research on image splicing tampering detection in power scenes is lacking. Accordingly, this study proposes a dual-channel detection model for splicing tampered images in substation scenes.MethodThe model consists of three parts: a Transformer channel with a feature pyramid structure, a shallow convolutional neural network (CNN) channel, and a network head. The size of the input tampered image is 512 ×512 × 3, and the output is the detection and localization results of the tampered image. Both channels use deep learning methods to extract features of the original color image and the residual image adaptively. The original color image contains rich color features and content information, while the residual image focuses on highlighting the edges of the tampered region, effectively solving the problem of difficult extraction of tampered features caused by the diversity of tampered images. In this study, the feature pyramid structure Transformer channel is used as the primary feature extraction channel, which consists of the pyramid structure Transformer and a progressive local decoder (PLD). The Transformer can efficiently extract features and establish connections between feature points via global attention from the first layer of the model in the global sensory field. Meanwhile, the use of the pyramid structure provides the network with better generalization and multi-scale feature processing capability. PLD enables features with different depths and expressiveness to guide and fuse with one another, solving the problems of attention scattering and the underestimation of local features to improve detail processing capability. The shallow CNN channel is used as an auxiliary detection channel, while the shallow network is used to extract the edge features of the tampered region in the residual image, enabling the model to locate the tampered region more easily in the overall contour. The residual block is the residual network module that forms the backbone of the shallow network. Its input is the residual image generated from the tampered image through the high-pass filtering layer. The parallel axial attention block introduces different sizes of dilated convolution to increase the perceptual field of the shallow network, and the parallel axial attention mechanism helps the network extract contextual semantic information. The features of two tributaries are fused into the network head by the channel, and the experiments conducted in this study show that merging by the channel is more effective than accumulation by elements. Finally, the network head detects the presence or absence of tampered regions in the image and accurately locates them.ResultThe experiments are first conducted on the pretraining datasets and pretraining weights are obtained. The test results show that the model in this study exhibits good detection effect on various tampering targets. The model is fine-tuned on the basis of the pretraining weights and compared with four models of the same type on the self-made substation splicing tampered dataset (SSSTD), CASIA, and NIST16. Four evaluation metrics, namely, accuracy, recall, F1, and average accuracy, are selected for quantitative analysis. In SSSTD, the accuracy, recall, F1, and average precision indexes of this study’s model improved by 0.12%, 2.17%, 1.24%, and 7.71%, respectively, compared with the model with the 2nd highest performance. In CASIA, this study’s model still achieves the best results in the four evaluation indexes. In NIST16, various detection models achieve higher values in accuracy, and this study’s model achieves higher values in recall rate. F1 and average precision indexes are substantially improved compared with the four comparison models. Qualitatively, the proposed model mitigates the problems of false detection and missed detection, while achieving higher localization accuracy. The overall detection effect is better than the other models.ConclusionThe detection of tampered substation image splicing is a key task in ensuring the stability of a power system. This study designs a new complex substation image splicing tampering detection model based on a feature pyramid structure Transformer and a shallow CNN dual channels. The feature pyramid structure Transformer channel obtains rich semantic information and visual features of tampered images through the global interaction mechanism, enhancing the accuracy and multi-scale processing capability of the detection model. As an auxiliary channel, the shallow CNN focuses on extracting residual image edge features, making it easier for the model to locate tampered regions in the overall contour. The models are measured on different splicing tampering datasets, and all the models in this study achieve optimal results. The visualization further shows that the model in this study exhibits the best detection effect in the actual substation scenario. However, this work only investigates image splicing tampering detection, while diverse types of tampering occur in reality. The next step is to investigate other types of tampered image detection to improve the compatibility of tampering detection models.关键词:substation image;splicing tampering detection;Transformer;convolutional neural network(CNN);dual-channel network;feature pyramid structure;shallow network
摘要:ObjectiveImage information becomes particularly important with the widespread application of intelligent power inspection. However, the rapid development of image tampering technology provides unscrupulous elements with a new way to harm power systems. As an important component of power systems, substations are responsible for the interconversion of different voltage levels. Ensuring the full-time output of stable voltage and the reasonable use of substation resources is the basis for the safe and stable operation of an entire power network. However, if the collected substation images are maliciously tampered with, then this condition may not only cause the failure of a smart grid system but also make operators misjudge the actual situation of the substation, eventually leading to power system failure and may even cause major accidents, such as large-scale power outages, resulting in irreversible losses to national production. Therefore, detecting tampered images of substations is a key task in ensuring the stability of power systems. The complex background of tampered images and the different scales of tampered contents cause existing detection models to experience the problems of false detection and leakage detection. Meanwhile, related research on image splicing tampering detection in power scenes is lacking. Accordingly, this study proposes a dual-channel detection model for splicing tampered images in substation scenes.MethodThe model consists of three parts: a Transformer channel with a feature pyramid structure, a shallow convolutional neural network (CNN) channel, and a network head. The size of the input tampered image is 512 ×512 × 3, and the output is the detection and localization results of the tampered image. Both channels use deep learning methods to extract features of the original color image and the residual image adaptively. The original color image contains rich color features and content information, while the residual image focuses on highlighting the edges of the tampered region, effectively solving the problem of difficult extraction of tampered features caused by the diversity of tampered images. In this study, the feature pyramid structure Transformer channel is used as the primary feature extraction channel, which consists of the pyramid structure Transformer and a progressive local decoder (PLD). The Transformer can efficiently extract features and establish connections between feature points via global attention from the first layer of the model in the global sensory field. Meanwhile, the use of the pyramid structure provides the network with better generalization and multi-scale feature processing capability. PLD enables features with different depths and expressiveness to guide and fuse with one another, solving the problems of attention scattering and the underestimation of local features to improve detail processing capability. The shallow CNN channel is used as an auxiliary detection channel, while the shallow network is used to extract the edge features of the tampered region in the residual image, enabling the model to locate the tampered region more easily in the overall contour. The residual block is the residual network module that forms the backbone of the shallow network. Its input is the residual image generated from the tampered image through the high-pass filtering layer. The parallel axial attention block introduces different sizes of dilated convolution to increase the perceptual field of the shallow network, and the parallel axial attention mechanism helps the network extract contextual semantic information. The features of two tributaries are fused into the network head by the channel, and the experiments conducted in this study show that merging by the channel is more effective than accumulation by elements. Finally, the network head detects the presence or absence of tampered regions in the image and accurately locates them.ResultThe experiments are first conducted on the pretraining datasets and pretraining weights are obtained. The test results show that the model in this study exhibits good detection effect on various tampering targets. The model is fine-tuned on the basis of the pretraining weights and compared with four models of the same type on the self-made substation splicing tampered dataset (SSSTD), CASIA, and NIST16. Four evaluation metrics, namely, accuracy, recall, F1, and average accuracy, are selected for quantitative analysis. In SSSTD, the accuracy, recall, F1, and average precision indexes of this study’s model improved by 0.12%, 2.17%, 1.24%, and 7.71%, respectively, compared with the model with the 2nd highest performance. In CASIA, this study’s model still achieves the best results in the four evaluation indexes. In NIST16, various detection models achieve higher values in accuracy, and this study’s model achieves higher values in recall rate. F1 and average precision indexes are substantially improved compared with the four comparison models. Qualitatively, the proposed model mitigates the problems of false detection and missed detection, while achieving higher localization accuracy. The overall detection effect is better than the other models.ConclusionThe detection of tampered substation image splicing is a key task in ensuring the stability of a power system. This study designs a new complex substation image splicing tampering detection model based on a feature pyramid structure Transformer and a shallow CNN dual channels. The feature pyramid structure Transformer channel obtains rich semantic information and visual features of tampered images through the global interaction mechanism, enhancing the accuracy and multi-scale processing capability of the detection model. As an auxiliary channel, the shallow CNN focuses on extracting residual image edge features, making it easier for the model to locate tampered regions in the overall contour. The models are measured on different splicing tampering datasets, and all the models in this study achieve optimal results. The visualization further shows that the model in this study exhibits the best detection effect in the actual substation scenario. However, this work only investigates image splicing tampering detection, while diverse types of tampering occur in reality. The next step is to investigate other types of tampered image detection to improve the compatibility of tampering detection models.关键词:substation image;splicing tampering detection;Transformer;convolutional neural network(CNN);dual-channel network;feature pyramid structure;shallow network- 2
- |
- 0
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveThe face recognition technique has become a part of our daily lives in recent years. However, with the rapid development of face forgery techniques based on deep learning, the cost of face forgery has not only been considerably reduced, but unexpected risks to the face recognition technique have also been raised. If someone uses a fake face image to break into a face recognition system, our personal information and property will be compromise and may even be stolen. However, distinguishing whether the face in an image is forged is difficult for the human eyes. Moreover, existing face forgery detection methods exhibit poor generalization performance and are difficult to defend against unknown attack samples due to large data distribution gaps among different forgery samples. Therefore, a reliable and general face forgery detection method is urgently required. In this regard, we introduce the concepts of “patch attribution purity” and “residual estimation reliability”, and propose a novel multitask learning network (PuRe) based on pure image patch comparison (PIPC) and reliable residual map estimation (RRME) to detect face forgery images.MethodApart from the network backbone, our neural network consists of the PIPC module and the RRME module. Both modules are helpful for improving the performance of face forgery detection. On the one hand, if the face in an image is forged, then the features extracted from face and background patches should be inconsistent. The PIPC module compares feature discrepancy between face and background patches to complete the face forgery detection task. Nevertheless, if an image patch contains face and background pixels, then the features extracted from it will have mixed face and background information, disturbing the feature comparison between face and background image patches and resulting in the overfitting of the training dataset. Considering the aforementioned problem, our PIPC module suggests using only pure image patches, which only contain face pixels (pure face image patches) or background pixels (pure background image patches). The purity of image patches guarantees the purity of the extracted features, and thus, the robustness of feature comparison is improved. On the other hand, the residual map estimation task is designed to predict the difference between the input image and the corresponding real image, causing the network backbone to strengthen the generalization of the extracted image features and improving the accuracy of face forgery detection. However, for pixels that are far from the forged edges between the forgery and real regions, the known information used to estimate the residuals will be less, resulting in unreliable residual estimation. Considering the aforementioned problem, a loss function, called the distance field weighted residual loss (DWRLoss), is designed in the RRME module to compel the neural network to give more attention to estimating the residuals near the forged edges between the forgery and real regions. In the face region (i.e., forgery region), if the pixel is far from the background region, then its loss is assigned with a smaller weight coefficient. Attention to reliable residual information improves the robustness of face forgery detection. Finally, we adopt the multitask learning strategy to train the proposed neural network. Both learning tasks guide the network backbone together to extract effective and generalized features for face forgery detection.ResultA large number of experiments are conducted to demonstrate the superiority of our method. Compared with existing superior methods, the test results on the FaceForensics++(FF++) dataset show that the accuracy (ACC) and area under the receiver operating characteristic curve (AUC) of face forgery detection are improved by 2.49% and 3.31%, respectively, by using the proposed method. Moreover, our method improves the ACC of face forgery detection on the FF++ dataset with FaceSwap(FS) and Face2Face(F2F) forgery types by 6.01% and 3.99%, respectively. In terms of the cross-dataset test, compared with 11 existing representative methods, the experimental results show that AUC on the Celeb-DF(CDF) dataset in the video and image levels is increased by 1.85% and 1.03%, respectively, with our method.ConclusionThe proposed neural network (i.e., PuRe) based on the PIPC and RRME modules exhibits excellent generalization ability and performs better than existing methods due to the purity and reliability of the extracted features.关键词:face forgery detection;deepfake;multi-task learning;generalization;pixel-wise supervision;convolutional neural network
摘要:ObjectiveThe face recognition technique has become a part of our daily lives in recent years. However, with the rapid development of face forgery techniques based on deep learning, the cost of face forgery has not only been considerably reduced, but unexpected risks to the face recognition technique have also been raised. If someone uses a fake face image to break into a face recognition system, our personal information and property will be compromise and may even be stolen. However, distinguishing whether the face in an image is forged is difficult for the human eyes. Moreover, existing face forgery detection methods exhibit poor generalization performance and are difficult to defend against unknown attack samples due to large data distribution gaps among different forgery samples. Therefore, a reliable and general face forgery detection method is urgently required. In this regard, we introduce the concepts of “patch attribution purity” and “residual estimation reliability”, and propose a novel multitask learning network (PuRe) based on pure image patch comparison (PIPC) and reliable residual map estimation (RRME) to detect face forgery images.MethodApart from the network backbone, our neural network consists of the PIPC module and the RRME module. Both modules are helpful for improving the performance of face forgery detection. On the one hand, if the face in an image is forged, then the features extracted from face and background patches should be inconsistent. The PIPC module compares feature discrepancy between face and background patches to complete the face forgery detection task. Nevertheless, if an image patch contains face and background pixels, then the features extracted from it will have mixed face and background information, disturbing the feature comparison between face and background image patches and resulting in the overfitting of the training dataset. Considering the aforementioned problem, our PIPC module suggests using only pure image patches, which only contain face pixels (pure face image patches) or background pixels (pure background image patches). The purity of image patches guarantees the purity of the extracted features, and thus, the robustness of feature comparison is improved. On the other hand, the residual map estimation task is designed to predict the difference between the input image and the corresponding real image, causing the network backbone to strengthen the generalization of the extracted image features and improving the accuracy of face forgery detection. However, for pixels that are far from the forged edges between the forgery and real regions, the known information used to estimate the residuals will be less, resulting in unreliable residual estimation. Considering the aforementioned problem, a loss function, called the distance field weighted residual loss (DWRLoss), is designed in the RRME module to compel the neural network to give more attention to estimating the residuals near the forged edges between the forgery and real regions. In the face region (i.e., forgery region), if the pixel is far from the background region, then its loss is assigned with a smaller weight coefficient. Attention to reliable residual information improves the robustness of face forgery detection. Finally, we adopt the multitask learning strategy to train the proposed neural network. Both learning tasks guide the network backbone together to extract effective and generalized features for face forgery detection.ResultA large number of experiments are conducted to demonstrate the superiority of our method. Compared with existing superior methods, the test results on the FaceForensics++(FF++) dataset show that the accuracy (ACC) and area under the receiver operating characteristic curve (AUC) of face forgery detection are improved by 2.49% and 3.31%, respectively, by using the proposed method. Moreover, our method improves the ACC of face forgery detection on the FF++ dataset with FaceSwap(FS) and Face2Face(F2F) forgery types by 6.01% and 3.99%, respectively. In terms of the cross-dataset test, compared with 11 existing representative methods, the experimental results show that AUC on the Celeb-DF(CDF) dataset in the video and image levels is increased by 1.85% and 1.03%, respectively, with our method.ConclusionThe proposed neural network (i.e., PuRe) based on the PIPC and RRME modules exhibits excellent generalization ability and performs better than existing methods due to the purity and reliability of the extracted features.关键词:face forgery detection;deepfake;multi-task learning;generalization;pixel-wise supervision;convolutional neural network- 5
- |
- 3
- |
- 0
发布时间:2024-02-16
Deep Forgery and Confrontation of Digital Media

-
 摘要:ObjectiveObject grasp pose detection in cluttered scenes is an essential skill for intelligent robots. Despite recent advances in six degrees-of-freedom grasping learning, learning the grasping configuration of small objects is extremely challenging. First, given the huge amount of raw point cloud data, points in the scene should be downsampled to reduce the computational complexity of the network and increase detection efficiency. Meanwhile, previous sampling methods sample fewer points on small objects, leading to difficulties in learning small object grasping poses. In addition, consumer-grade depth cameras currently available in the market are seriously noisy, particularly because the quality of point clouds obtained on small objects cannot be guaranteed, leading to the possibility of unclear objecthood of points on small objects predicted by the network. Some feasible grasping points are mistakenly regarded as background points, further reducing the number of sampling points on small objects, resulting in weak grasping performance on small objects.MethodA potential problem in previous grasp detection methods is that they do not consider the biased distribution of sampling points due to differences in the scale of objects in the scene, resulting in fewer sampling points on small objects. In this study, we propose an object mask-assisted sampling method that samples the same points on all objects to balance grasping distribution, solving the problem of the uneven distribution of sampling points. In the inference, without a priori knowledge of scene point-level masks, we introduce an unseen object instance segmentation network to distinguish objects in the scenario, implementing a mask-assisted sampling method. In addition, a multi-scale learning strategy is used for learning, and multi-scale cylindrical grouping is used on the partial point clouds of objects to improve local geometric representation, solving the problem of difficulty in learning to grasp operational parameters caused by differences in object scales. In particular, we set up three cylinders with different radii to sample the point cloud near the graspable point, corresponding to learning large, medium, and small object features, and then splice the features of the three scales. Subsequently, we process the spliced features with a self-attention layer to enhance the attention of the local region and improve the local geometric representation of the object. Similar to GraspNet, we design an end-to-end grasping network that consists of three parts: graspable points, approach direction, and prediction of gripper operation. Graspable points represent the high-scoring points in the scene that are suitable for grasping. They can perform the initial filtering of a large amount of point cloud data in the scene and then embedded into the proposed sampling and learning methods to further predict the approach direction and gripper operation for grasping poses on an object. By designing an end-to-end grasping network embedded with the proposed sampling and learning approach, we can effectively improve object grasping detection capability.ResultFinally, the proposed method achieves state-of-the-art performance when evaluated on the large benchmark dataset GraspNet-1Billion, wherein the grasping metrics on small objects are improved by 7% on average, and a large number of real robot experiments also show that the approach exhibits promising generalization performance on unseen objects. To more intuitively observe the improvement of the grasping performance of the proposed method on small objects, we also use the previous most representative method, i.e., graspness-based sampling network(GSNet), as the benchmark method and visualize the grasping detection results of the benchmark method and the proposed method in this study under four cluttered scenarios. The visualization results show that the previous method tends to predict grasping on large objects in the scene but does not show reasonable grasping poses on some small objects. By contrast, the proposed method can accurately predict grasping poses on small objects.ConclusionFocusing on grasping small objects, this study proposes a mask-assisted sampling method embedded into the proposed end-to-end learning network and introduces a multi-scale grouping learning strategy to improve the local geometric representation of objects, effectively improving the quality of grasping small objects and outperforming previous methods in the evaluation of grasping all objects. However, the proposed method has certain limitations. For example, when using noisy and low-quality depth maps as input, existing unseen object instance segmentation methods may produce incorrect object masks, failing in mask-assisted sampling. In the future, we plan to investigate more robust unseen object instance segmentation methods that can correct erroneous segmentation results under low-quality depth map input. This procedure will allow us to obtain more accurate object instance masks and enhance object grasping detection capability in cluttered scenes.关键词:six degrees-of-freedom grasping;sampling strategy;multiscale learning;point cloud learning;deep learning
摘要:ObjectiveObject grasp pose detection in cluttered scenes is an essential skill for intelligent robots. Despite recent advances in six degrees-of-freedom grasping learning, learning the grasping configuration of small objects is extremely challenging. First, given the huge amount of raw point cloud data, points in the scene should be downsampled to reduce the computational complexity of the network and increase detection efficiency. Meanwhile, previous sampling methods sample fewer points on small objects, leading to difficulties in learning small object grasping poses. In addition, consumer-grade depth cameras currently available in the market are seriously noisy, particularly because the quality of point clouds obtained on small objects cannot be guaranteed, leading to the possibility of unclear objecthood of points on small objects predicted by the network. Some feasible grasping points are mistakenly regarded as background points, further reducing the number of sampling points on small objects, resulting in weak grasping performance on small objects.MethodA potential problem in previous grasp detection methods is that they do not consider the biased distribution of sampling points due to differences in the scale of objects in the scene, resulting in fewer sampling points on small objects. In this study, we propose an object mask-assisted sampling method that samples the same points on all objects to balance grasping distribution, solving the problem of the uneven distribution of sampling points. In the inference, without a priori knowledge of scene point-level masks, we introduce an unseen object instance segmentation network to distinguish objects in the scenario, implementing a mask-assisted sampling method. In addition, a multi-scale learning strategy is used for learning, and multi-scale cylindrical grouping is used on the partial point clouds of objects to improve local geometric representation, solving the problem of difficulty in learning to grasp operational parameters caused by differences in object scales. In particular, we set up three cylinders with different radii to sample the point cloud near the graspable point, corresponding to learning large, medium, and small object features, and then splice the features of the three scales. Subsequently, we process the spliced features with a self-attention layer to enhance the attention of the local region and improve the local geometric representation of the object. Similar to GraspNet, we design an end-to-end grasping network that consists of three parts: graspable points, approach direction, and prediction of gripper operation. Graspable points represent the high-scoring points in the scene that are suitable for grasping. They can perform the initial filtering of a large amount of point cloud data in the scene and then embedded into the proposed sampling and learning methods to further predict the approach direction and gripper operation for grasping poses on an object. By designing an end-to-end grasping network embedded with the proposed sampling and learning approach, we can effectively improve object grasping detection capability.ResultFinally, the proposed method achieves state-of-the-art performance when evaluated on the large benchmark dataset GraspNet-1Billion, wherein the grasping metrics on small objects are improved by 7% on average, and a large number of real robot experiments also show that the approach exhibits promising generalization performance on unseen objects. To more intuitively observe the improvement of the grasping performance of the proposed method on small objects, we also use the previous most representative method, i.e., graspness-based sampling network(GSNet), as the benchmark method and visualize the grasping detection results of the benchmark method and the proposed method in this study under four cluttered scenarios. The visualization results show that the previous method tends to predict grasping on large objects in the scene but does not show reasonable grasping poses on some small objects. By contrast, the proposed method can accurately predict grasping poses on small objects.ConclusionFocusing on grasping small objects, this study proposes a mask-assisted sampling method embedded into the proposed end-to-end learning network and introduces a multi-scale grouping learning strategy to improve the local geometric representation of objects, effectively improving the quality of grasping small objects and outperforming previous methods in the evaluation of grasping all objects. However, the proposed method has certain limitations. For example, when using noisy and low-quality depth maps as input, existing unseen object instance segmentation methods may produce incorrect object masks, failing in mask-assisted sampling. In the future, we plan to investigate more robust unseen object instance segmentation methods that can correct erroneous segmentation results under low-quality depth map input. This procedure will allow us to obtain more accurate object instance masks and enhance object grasping detection capability in cluttered scenes.关键词:six degrees-of-freedom grasping;sampling strategy;multiscale learning;point cloud learning;deep learning- 2
- |
- 0
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveVideo matting is one of the most commonly used operations in visual image processing. It aims to separate a certain part of an image from the original image into a separate layer and further apply it to specific scenes for later video synthesis. In recent years, real-time portrait matting that uses neural networks has become a research hotspot in the field of computer vision. Existing related networks cannot meet real-time requirements when processing high-resolution video. Moreover, the matting results at the edges of high-resolution image targets still have blurry issues. To solve these problems, several recently proposed methods that use various auxiliary information to guide high-resolution image for mask estimation have demonstrated good performance. However, many methods cannot perfectly learn information about the edges and details of portraits. Therefore, this study proposes a high-resolution video real-time portrait matting network combined with background images.MethodA double-layer network composed of a base network and a refinement network is presented. To achieve a lightweight network, high-resolution feature maps are first downsampled at sampling rate D. In the base network, the multi-scale features of video frames are extracted by the encoder module, and these features are fused by the pyramid pooling module, because the input of the cyclic decoder network is beneficial for the cyclic decoder to learn the multi-scale features of video frames. In the cyclic decoder, a residual gated recurrent unit (GRU) is used to aggregate the time information between consecutive video frames. The masked map, foreground residual map, and hidden feature map are generated. A residual structure is used to reduce model parameters and improve the real-time performance of the network. In the residual GRU, the time information of the video is fully utilized to promote the construction of the masked map of the video frame sequence based on time information. To improve the real-time matting performance of high-resolution images, the high-resolution information guidance module designed in the refinement network, and the initial high-resolution video frames and low-resolution predicted features (masked map, foreground residual map, and hidden feature map) are used as input to pass the high-resolution information guidance module, generating high-quality portrait matting results by guiding low-resolution images with high-resolution image information. In the high-resolution information guidance module, the combination of covariance means filtering, variance means filtering, and pointwise convolution processing can effectively extract the matting quality of the detailed areas of character contours in a high-resolution video frame. Under the synergistic effects of the benchmark and refinement networks, the designed network cannot only fully extract multi-scale information from low-resolution video frames, but can also more fully learn the edge information of portraits in high-resolution video frames. This condition is conducive to more accurate prediction of masked maps and foreground images in the network structure and can also improve the generalization ability of the matting network at multiple resolutions. In addition, the high-resolution image downsampling scheme, lightweight pyramid pooling module, and residual link structure designed in the network further reduce the number of network parameters, improving the real-time performance of the network.ResultWe use PyTorch to implement our network on NVIDIA GTX 1080Ti GPU with 11 GB RAM. Batch size is 1, and the optimizer used is Adam. This study trains the benchmark network on three datasets in sequence: the Video240K SD dataset, with an input frame sequence of 15. After 8 epochs of training, the fine network is trained on the Video240K HD dataset for 1 epoch. To improve the robustness of the model in processing high-resolution videos, the refinement network was further trained on the Human2K dataset, with a downsampling rate D of 0.25 and an input frame sequence of 2 for 50 epochs of training. Compared with related network models in recent years, the experimental results show that the proposed method is superior to other methods on the Video240K SD dataset and the Human2K dataset. On the Video240K SD dataset, 26.1%, 50.6%, 56.9%, and 39.5% of the evaluation indicators (sum of absolute difference(SAD), mean squared error(MSE), gradient error(Grad), and connectivity error(Coon)) were optimized, respectively. In particular, on the high-resolution Human2K dataset, the proposed method is significantly superior to other state-of-the-art methods, optimizing the evaluation indicators (SAD, MSE, Grad, and Coon) by 18.8%, 39.2%, 40.7%, and 20.9%, respectively. Simultaneously achieving the lowest network complexity at 4 K resolution (28.78 GMac). The running speed of processing low-resolution video (512 × 288 pixels) can reach 49 frame/s, and the running speed of processing medium-resolution video (1 024 × 576 pixels) can reach 42.4 frame/s. In particular, the running speed of processing 4 K resolution video can reach 26 frame/s, while the running speed of processing HD-resolution video can reach 43 frame/s on NVIDIA GTX 1080Ti GPU. This value is significantly improved compared with other state-of-the-art methods.ConclusionThe network model proposed in this study can better complete the real-time matting task of high-resolution portraits. The pyramid pooling module in the benchmark network effectively extracts and integrates multi-scale information of video frames, while the residual GRU module significantly aggregates continuous inter-frame time information. The high-resolution information guidance module captures high-resolution information in images and guides low-resolution images to learn high-resolution information. The improved network effectively enhances the matting information of high-resolution human-oriented edges. The experiments on the high-resolution dataset Human2K show that the proposed network is more effective in predicting high-resolution montage maps. It has high real-time processing speed and can provide better support for advanced applications, such as film and television, short video social networking, and online conference.关键词:real-time human figure matting;neural network;multiscale features;time information;high resolution
摘要:ObjectiveVideo matting is one of the most commonly used operations in visual image processing. It aims to separate a certain part of an image from the original image into a separate layer and further apply it to specific scenes for later video synthesis. In recent years, real-time portrait matting that uses neural networks has become a research hotspot in the field of computer vision. Existing related networks cannot meet real-time requirements when processing high-resolution video. Moreover, the matting results at the edges of high-resolution image targets still have blurry issues. To solve these problems, several recently proposed methods that use various auxiliary information to guide high-resolution image for mask estimation have demonstrated good performance. However, many methods cannot perfectly learn information about the edges and details of portraits. Therefore, this study proposes a high-resolution video real-time portrait matting network combined with background images.MethodA double-layer network composed of a base network and a refinement network is presented. To achieve a lightweight network, high-resolution feature maps are first downsampled at sampling rate D. In the base network, the multi-scale features of video frames are extracted by the encoder module, and these features are fused by the pyramid pooling module, because the input of the cyclic decoder network is beneficial for the cyclic decoder to learn the multi-scale features of video frames. In the cyclic decoder, a residual gated recurrent unit (GRU) is used to aggregate the time information between consecutive video frames. The masked map, foreground residual map, and hidden feature map are generated. A residual structure is used to reduce model parameters and improve the real-time performance of the network. In the residual GRU, the time information of the video is fully utilized to promote the construction of the masked map of the video frame sequence based on time information. To improve the real-time matting performance of high-resolution images, the high-resolution information guidance module designed in the refinement network, and the initial high-resolution video frames and low-resolution predicted features (masked map, foreground residual map, and hidden feature map) are used as input to pass the high-resolution information guidance module, generating high-quality portrait matting results by guiding low-resolution images with high-resolution image information. In the high-resolution information guidance module, the combination of covariance means filtering, variance means filtering, and pointwise convolution processing can effectively extract the matting quality of the detailed areas of character contours in a high-resolution video frame. Under the synergistic effects of the benchmark and refinement networks, the designed network cannot only fully extract multi-scale information from low-resolution video frames, but can also more fully learn the edge information of portraits in high-resolution video frames. This condition is conducive to more accurate prediction of masked maps and foreground images in the network structure and can also improve the generalization ability of the matting network at multiple resolutions. In addition, the high-resolution image downsampling scheme, lightweight pyramid pooling module, and residual link structure designed in the network further reduce the number of network parameters, improving the real-time performance of the network.ResultWe use PyTorch to implement our network on NVIDIA GTX 1080Ti GPU with 11 GB RAM. Batch size is 1, and the optimizer used is Adam. This study trains the benchmark network on three datasets in sequence: the Video240K SD dataset, with an input frame sequence of 15. After 8 epochs of training, the fine network is trained on the Video240K HD dataset for 1 epoch. To improve the robustness of the model in processing high-resolution videos, the refinement network was further trained on the Human2K dataset, with a downsampling rate D of 0.25 and an input frame sequence of 2 for 50 epochs of training. Compared with related network models in recent years, the experimental results show that the proposed method is superior to other methods on the Video240K SD dataset and the Human2K dataset. On the Video240K SD dataset, 26.1%, 50.6%, 56.9%, and 39.5% of the evaluation indicators (sum of absolute difference(SAD), mean squared error(MSE), gradient error(Grad), and connectivity error(Coon)) were optimized, respectively. In particular, on the high-resolution Human2K dataset, the proposed method is significantly superior to other state-of-the-art methods, optimizing the evaluation indicators (SAD, MSE, Grad, and Coon) by 18.8%, 39.2%, 40.7%, and 20.9%, respectively. Simultaneously achieving the lowest network complexity at 4 K resolution (28.78 GMac). The running speed of processing low-resolution video (512 × 288 pixels) can reach 49 frame/s, and the running speed of processing medium-resolution video (1 024 × 576 pixels) can reach 42.4 frame/s. In particular, the running speed of processing 4 K resolution video can reach 26 frame/s, while the running speed of processing HD-resolution video can reach 43 frame/s on NVIDIA GTX 1080Ti GPU. This value is significantly improved compared with other state-of-the-art methods.ConclusionThe network model proposed in this study can better complete the real-time matting task of high-resolution portraits. The pyramid pooling module in the benchmark network effectively extracts and integrates multi-scale information of video frames, while the residual GRU module significantly aggregates continuous inter-frame time information. The high-resolution information guidance module captures high-resolution information in images and guides low-resolution images to learn high-resolution information. The improved network effectively enhances the matting information of high-resolution human-oriented edges. The experiments on the high-resolution dataset Human2K show that the proposed network is more effective in predicting high-resolution montage maps. It has high real-time processing speed and can provide better support for advanced applications, such as film and television, short video social networking, and online conference.关键词:real-time human figure matting;neural network;multiscale features;time information;high resolution- 2
- |
- 0
- |
- 0
发布时间:2024-02-16
Image Analysis and Recognition
-
 摘要:ObjectiveImage inpainting and outpainting tasks are significant challenges in the field of computer vision. They involve the filling of unknown regions in an image on the basis of information available in known regions. With its advancements, deep learning has become the mainstream approach for dealing with these tasks. However, existing solutions frequently regard inpainting and outpainting as separate problems, and thus, they lack the ability to adapt seamlessly between the two. Furthermore, convolutional neural networks (CNNs) are commonly used in these methods, but their limitation in capturing long-range content due to locality poses challenges. To address these issues, this study proposes a unified framework that combines CNN and Transformer models on the basis of a divide-and-conquer strategy, aiming to deal with image inpainting and outpainting effectively.MethodOur proposed approach consists of three stages: representation, prediction, and synthesis. In the representation stage, CNNs are employed to map the input images to a set of meaningful features. This step leverages the local information processing capability of CNNs and enables the extraction of relevant features from the known regions of an image. We use a CNN encoder that incorporates partial convolutions and pixel normalization to reduce the introduction of irrelevant information from unknown regions. The extracted features obtained are then passed to the prediction stage. In the prediction stage, we utilize the Transformer architecture, which excels in modeling global context, to generate predictions for the unknown regions of an image. The Transformer has been proven to be highly effective in capturing long-range dependencies and contextual information in various domains, such as natural language processing. By incorporating a Transformer, we aim to enhance the model’s ability to predict accurate and coherent content for inpainting and outpainting tasks. To address the challenge of predicting features for large-range unknown regions in parallel, we introduce a mask growth strategy. This strategy facilitates iterative feature prediction, wherein the model progressively predicts features for larger regions by gradually expanding the inpainting or outpainting task. This iterative process helps the model refine its predictions and capture more related contextual information, leading to improved results. Finally, we reconstruct the complete image in the synthesis stage by combining the predicted features with the known features from the representation stage. This synthesis aims to generate visually appealing and realistic results by leveraging the strengths of a CNN decoder that consists of multiple convolution residual blocks. Upsampling intervals are utilized, reducing the difficulty of model optimization.ResultTo evaluate the effectiveness of our proposed method, we conduct comprehensive experiments on diverse datasets that encompass objects and scenes for image inpainting and outpainting tasks. We compare our approach with state-of-the-art methods and utilize various evaluation metrics, including structural similarity index measure, peak signal-to-noise ratio, and perceptual quality metrics. The experimental results demonstrate that our unified framework surpasses existing methods across all evaluation metrics, demonstrating its superior performance. The combination of CNNs and a Transformer allows our model to capture local details and long-range dependencies, resulting in more accurate and visually appealing inpainting and outpainting results. In addition, ablation studies are conducted to confirm the effectiveness of each component of our method, including the framework structure and the mask growth strategy. Through ablation experiments, all three stages are confirmed to contribute to performance improvement, highlighting the applicability of our method. Furthermore, we empirically investigate the effect of the head and layer numbers of the Transformer model on overall performance, revealing that appropriate numbers of iterations, Transformer heads, and Transformer layers can further enhance the framework’s performance.ConclusionThis study introduces an iterative prediction unified framework for addressing image inpainting and outpainting challenges. Our proposed method outperforms existing approaches in terms of performance, with each aspect of the design contributing to overall improvement. The combination of CNNs and a Transformer enables our model to capture the local and global contexts, leading to more accurate and visually coherent image inpainting and outpainting results. These findings underscore the practical value and potential of an iterative prediction unified framework and method in the field of image inpainting and outpainting. Future research directions include exploring the application of our framework to other related tasks and further optimizing the model architecture for enhanced efficiency and scalability. Moreover, an important aspect that can be explored to enhance our proposed framework is the integration of self-supervised learning techniques with large-scale datasets. This step can potentially improve the robustness and generalization capability of our model for image inpainting and outpainting tasks.关键词:image inpainting;image outpainting;divide-and-conquer;iterative prediction;Transformer;convolutional neural network(CNN)
摘要:ObjectiveImage inpainting and outpainting tasks are significant challenges in the field of computer vision. They involve the filling of unknown regions in an image on the basis of information available in known regions. With its advancements, deep learning has become the mainstream approach for dealing with these tasks. However, existing solutions frequently regard inpainting and outpainting as separate problems, and thus, they lack the ability to adapt seamlessly between the two. Furthermore, convolutional neural networks (CNNs) are commonly used in these methods, but their limitation in capturing long-range content due to locality poses challenges. To address these issues, this study proposes a unified framework that combines CNN and Transformer models on the basis of a divide-and-conquer strategy, aiming to deal with image inpainting and outpainting effectively.MethodOur proposed approach consists of three stages: representation, prediction, and synthesis. In the representation stage, CNNs are employed to map the input images to a set of meaningful features. This step leverages the local information processing capability of CNNs and enables the extraction of relevant features from the known regions of an image. We use a CNN encoder that incorporates partial convolutions and pixel normalization to reduce the introduction of irrelevant information from unknown regions. The extracted features obtained are then passed to the prediction stage. In the prediction stage, we utilize the Transformer architecture, which excels in modeling global context, to generate predictions for the unknown regions of an image. The Transformer has been proven to be highly effective in capturing long-range dependencies and contextual information in various domains, such as natural language processing. By incorporating a Transformer, we aim to enhance the model’s ability to predict accurate and coherent content for inpainting and outpainting tasks. To address the challenge of predicting features for large-range unknown regions in parallel, we introduce a mask growth strategy. This strategy facilitates iterative feature prediction, wherein the model progressively predicts features for larger regions by gradually expanding the inpainting or outpainting task. This iterative process helps the model refine its predictions and capture more related contextual information, leading to improved results. Finally, we reconstruct the complete image in the synthesis stage by combining the predicted features with the known features from the representation stage. This synthesis aims to generate visually appealing and realistic results by leveraging the strengths of a CNN decoder that consists of multiple convolution residual blocks. Upsampling intervals are utilized, reducing the difficulty of model optimization.ResultTo evaluate the effectiveness of our proposed method, we conduct comprehensive experiments on diverse datasets that encompass objects and scenes for image inpainting and outpainting tasks. We compare our approach with state-of-the-art methods and utilize various evaluation metrics, including structural similarity index measure, peak signal-to-noise ratio, and perceptual quality metrics. The experimental results demonstrate that our unified framework surpasses existing methods across all evaluation metrics, demonstrating its superior performance. The combination of CNNs and a Transformer allows our model to capture local details and long-range dependencies, resulting in more accurate and visually appealing inpainting and outpainting results. In addition, ablation studies are conducted to confirm the effectiveness of each component of our method, including the framework structure and the mask growth strategy. Through ablation experiments, all three stages are confirmed to contribute to performance improvement, highlighting the applicability of our method. Furthermore, we empirically investigate the effect of the head and layer numbers of the Transformer model on overall performance, revealing that appropriate numbers of iterations, Transformer heads, and Transformer layers can further enhance the framework’s performance.ConclusionThis study introduces an iterative prediction unified framework for addressing image inpainting and outpainting challenges. Our proposed method outperforms existing approaches in terms of performance, with each aspect of the design contributing to overall improvement. The combination of CNNs and a Transformer enables our model to capture the local and global contexts, leading to more accurate and visually coherent image inpainting and outpainting results. These findings underscore the practical value and potential of an iterative prediction unified framework and method in the field of image inpainting and outpainting. Future research directions include exploring the application of our framework to other related tasks and further optimizing the model architecture for enhanced efficiency and scalability. Moreover, an important aspect that can be explored to enhance our proposed framework is the integration of self-supervised learning techniques with large-scale datasets. This step can potentially improve the robustness and generalization capability of our model for image inpainting and outpainting tasks.关键词:image inpainting;image outpainting;divide-and-conquer;iterative prediction;Transformer;convolutional neural network(CNN)- 2
- |
- 0
- |
- 0
发布时间:2024-02-16 -
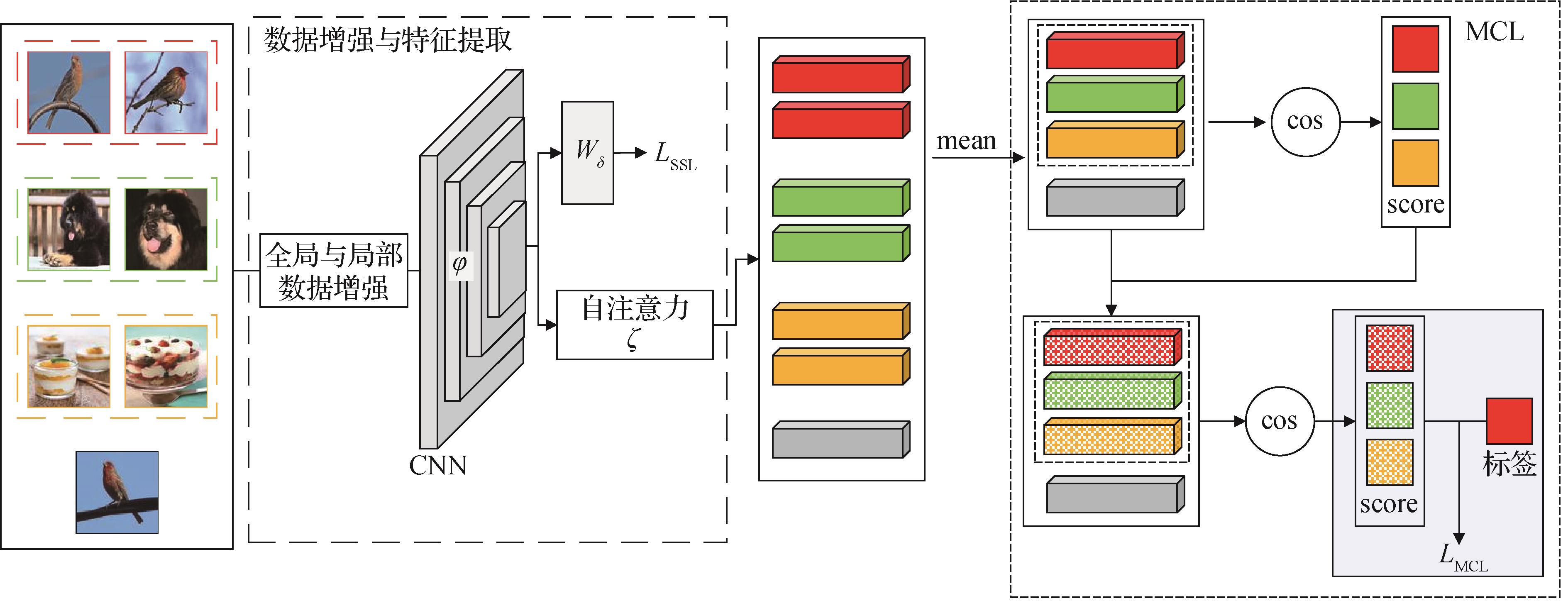 摘要:ObjectiveFew-shot learning (FSL) is a popular and difficult problem in computer vision. It aims to achieve effective classification with a few labeled samples. Recent few-shot learning methods can be divided into three major categories: metric-, transfer-, and gradient-based methods. Among them, metric-based learning methods have received considerable attention because of their simplicity and excellent performance in few-shot learning problems. In particular, metric-based learning methods consist of a feature extractor based on a convolutional neural network (CNN) and a classifier based on spatial distance. By mapping the samples into the embedding space, a simple metric function is used to calculate the similarity between the sample and the class prototype, quickly identifying the novel class sample. The metric function is used for classification, and it bypasses the optimization problem in the few-shot setting when using network learning classifiers. Therefore, a richer, more discriminative, and better generalization embedding space is the key for metric-based learning methods. From the perspective of the feature and its embedding space, and by combining the global and local features of a sample, we propose a meta-cosine loss for few-shot image classification method, called AMCL-FSIC, to improve the accuracy of metric-based learning methods.MethodOn the one hand, our primary objective is to obtain suitable features. Image information is composed of foreground and background images. The foreground image is beneficial for few-shot classification, whereas the background image is detrimental. If we can force the model to focus only on the foreground during training and evaluation and disregard the background, then this scenario is helpful for image classification. However, it is not easy to achieve. In fact, we need prior knowledge of the prospective object. As stated by previous researchers, images are roughly divided into global and local features, which are randomly cropped portions of each image. Local features contain cross-category discriminatory and transferable information, which is of considerable significance for few-shot image classification. First, we combine global and local data enhancement strategies. In particular, the local information of an image allows the model to give more attention to the uniqueness and transfer characteristics of the sample, minimizing the effect of background information. Then, the introduction of the self-attention mechanisms helps combine global and local features, gaining richer and more distinguished features. On the other hand, from the feature distribution in the embedded space, we meta-train a cosine classifier and minimize loss by calculating the strings between the sample and the prototypes. In the embedded space, features with the same category are gathered together, while different categories of features are far from one another. However, previous residue classifiers only give attention to the same class during the training period and do not completely stretch different types of samples. The direct consequence of this situation is that the generalization capacity of the model decreases when facing new test tasks with similar categories. We propose the meta-cosine loss (MCL) on the basis of the cosine classifier. During meta-training, the difference of the cosine similarity between the sample and the class prototype is used to adjust the class prototype in accordance with the parallelogram principle. MCL places the model as far away as possible from the feature clusters of different classes in the task, ensuring that the classes are more separable when the model faces a new test task and improving the generalization ability of the model.ResultWe conduct extensive experiments to verify the model’s effectiveness. Experiments are performed on five classical few-shot datasets, as follows: MiniImageNet, TieredImageNet, Cifar100, Few-shot Cifar 100(FC100), and Caltech-UCSD Birds-200-2011(CUB). The input images are resized to 84 × 84 pixels for training, the momentum parameter is set to 0.95, the learning rate is set to 0.000 2, and the weight decay is 0.000 1. The model learning procedure is accelerated using a NVIDIA GeForce RTX 3090 GPU device. To ensure the fairness of comparison, we adopt the 5-way 1-shot and 5-way 5-shot settings during the training and testing phases. The experimental results show that the image classification accuracy of MiniImageNet, TieredImageNet, Cifar100, FC100, and CUB datasets is 68.92/84.45, 72.41/87.36, 76.79/88.52, 50.86/67.19, and 81.12/91.43, respectively, on the 5-way 1-shot and 5-way 5-shot settings. Compared with the latest few-shot image classification methods, our model exhibits more advantages. Simultaneously, we perform comparative experiments on the MiniImageNet, CUB, and Cifar100 datasets to verify the effectiveness of MCL. From the comparative experimental results, the introduction of the MCL classifier can improve image classification accuracy by nearly 4% and 2% under the 1-shot and 5-shot settings, respectively. MCL has considerably improved the classification ability of the cosine classifier.ConclusionOur work proposes MCL and combines global and local data augmentation methods to improve the generalization ability of the model. This approach is suitable for any metric-based method.关键词:meta learning;few-shot learning(FSL);metric learning;meta-cosine loss(MCL);image classification
摘要:ObjectiveFew-shot learning (FSL) is a popular and difficult problem in computer vision. It aims to achieve effective classification with a few labeled samples. Recent few-shot learning methods can be divided into three major categories: metric-, transfer-, and gradient-based methods. Among them, metric-based learning methods have received considerable attention because of their simplicity and excellent performance in few-shot learning problems. In particular, metric-based learning methods consist of a feature extractor based on a convolutional neural network (CNN) and a classifier based on spatial distance. By mapping the samples into the embedding space, a simple metric function is used to calculate the similarity between the sample and the class prototype, quickly identifying the novel class sample. The metric function is used for classification, and it bypasses the optimization problem in the few-shot setting when using network learning classifiers. Therefore, a richer, more discriminative, and better generalization embedding space is the key for metric-based learning methods. From the perspective of the feature and its embedding space, and by combining the global and local features of a sample, we propose a meta-cosine loss for few-shot image classification method, called AMCL-FSIC, to improve the accuracy of metric-based learning methods.MethodOn the one hand, our primary objective is to obtain suitable features. Image information is composed of foreground and background images. The foreground image is beneficial for few-shot classification, whereas the background image is detrimental. If we can force the model to focus only on the foreground during training and evaluation and disregard the background, then this scenario is helpful for image classification. However, it is not easy to achieve. In fact, we need prior knowledge of the prospective object. As stated by previous researchers, images are roughly divided into global and local features, which are randomly cropped portions of each image. Local features contain cross-category discriminatory and transferable information, which is of considerable significance for few-shot image classification. First, we combine global and local data enhancement strategies. In particular, the local information of an image allows the model to give more attention to the uniqueness and transfer characteristics of the sample, minimizing the effect of background information. Then, the introduction of the self-attention mechanisms helps combine global and local features, gaining richer and more distinguished features. On the other hand, from the feature distribution in the embedded space, we meta-train a cosine classifier and minimize loss by calculating the strings between the sample and the prototypes. In the embedded space, features with the same category are gathered together, while different categories of features are far from one another. However, previous residue classifiers only give attention to the same class during the training period and do not completely stretch different types of samples. The direct consequence of this situation is that the generalization capacity of the model decreases when facing new test tasks with similar categories. We propose the meta-cosine loss (MCL) on the basis of the cosine classifier. During meta-training, the difference of the cosine similarity between the sample and the class prototype is used to adjust the class prototype in accordance with the parallelogram principle. MCL places the model as far away as possible from the feature clusters of different classes in the task, ensuring that the classes are more separable when the model faces a new test task and improving the generalization ability of the model.ResultWe conduct extensive experiments to verify the model’s effectiveness. Experiments are performed on five classical few-shot datasets, as follows: MiniImageNet, TieredImageNet, Cifar100, Few-shot Cifar 100(FC100), and Caltech-UCSD Birds-200-2011(CUB). The input images are resized to 84 × 84 pixels for training, the momentum parameter is set to 0.95, the learning rate is set to 0.000 2, and the weight decay is 0.000 1. The model learning procedure is accelerated using a NVIDIA GeForce RTX 3090 GPU device. To ensure the fairness of comparison, we adopt the 5-way 1-shot and 5-way 5-shot settings during the training and testing phases. The experimental results show that the image classification accuracy of MiniImageNet, TieredImageNet, Cifar100, FC100, and CUB datasets is 68.92/84.45, 72.41/87.36, 76.79/88.52, 50.86/67.19, and 81.12/91.43, respectively, on the 5-way 1-shot and 5-way 5-shot settings. Compared with the latest few-shot image classification methods, our model exhibits more advantages. Simultaneously, we perform comparative experiments on the MiniImageNet, CUB, and Cifar100 datasets to verify the effectiveness of MCL. From the comparative experimental results, the introduction of the MCL classifier can improve image classification accuracy by nearly 4% and 2% under the 1-shot and 5-shot settings, respectively. MCL has considerably improved the classification ability of the cosine classifier.ConclusionOur work proposes MCL and combines global and local data augmentation methods to improve the generalization ability of the model. This approach is suitable for any metric-based method.关键词:meta learning;few-shot learning(FSL);metric learning;meta-cosine loss(MCL);image classification- 2
- |
- 0
- |
- 1
发布时间:2024-02-16 -
 摘要:Objective3D point cloud classification is a crucial task with diverse applications in computer vision, robotics, and autonomous driving. The advancement of computing device performance in recent years has enabled researchers to apply deep learning methods to the field of 3D point cloud recognition. Deep learning-based methods that are currently in use for 3D point cloud classification typically divide the feature information captured by a network into two distinct parts: global and local features. Global features refer to the overall shape and structure of the point cloud, while local features capture more detailed information about individual points. By leveraging global and local features, these methods can achieve high accuracy in point cloud classification tasks. Edge convolution (EdgeConv) is currently the most widely used method for local feature extraction in 3D point cloud classification. This method incorporates relative position vectors into feature encoding to capture the characteristics of local structures effectively. However, when local structures in 3D point clouds are similar, the use of relative positions in feature encoding may result in similar features, leading to poor classification results. Furthermore, encoding only local features may be insufficient for achieving optimal classification results, because considering the correlation between local and global features is also crucial. Current methods frequently employ attention mechanisms to learn attention scores from global features and weigh local features accordingly, effectively establishing the correlation between local and global features. However, these methods may not fully consider the importance of global feature information and may suffer from suboptimal classification results.MethodTo address the aforementioned challenges, this study proposes a novel 3D point cloud classification network that leverages spatial structure convolution (SSConv) and attention mechanisms. The proposed network architecture consists of two parts: a local feature encoding (LFE) module and a global feature encoding (GFE) module. The former uses SSConv to encode local features from location and structure, while the latter learns global feature representation from raw coordinate data. Furthermore, to enable effective correlation and complementarity between feature information, we introduce an attention mechanism that facilitates adaptive adjustment of global features through weighted operations. The LFE module is composed of two operations: graph construction and feature extraction. The LFE module performs the K-nearest neighbor (KNN) algorithm to identify adjacent points and construct a graph structure. SSConv is a crucial feature extraction operation that involves a multilayer perceptron. Compared with EdgeConv, SSConv introduces a relative position vector between adjacent points. This operation effectively increases the correlation distance between raw input data, enriches local region structure information, and enhances the spatial expression ability of the extracted high-level semantic information. To capture more effective local structure features, feature extraction is encoded separately on the basis of structure and location. In particular, the location encoding branch encodes the coordinate information separately to obtain richer location feature information for describing the spatial location of each point. Meanwhile, the structure encoding branch encodes the relative location vector separately to learn the structure information in the local region for describing the overall geometric structure of the local neighborhood. The global feature encoding module maps raw coordinate data to high-dimensional features, which are used as the global feature representation of the point cloud. In addition, the module includes an attention mechanism to enhance the correlation between local and global features. In particular, an attention weighting method is used to guide the learning of global feature information by using local feature information. This operation enables correlation and fusion between local and global feature representations while preserving raw feature information.ResultTo evaluate the performance of the proposed network model, experimental validation is conducted on the publicly available ModelNet40 dataset, which consists of 9 843 training models and 2 468 testing models in 40 classes. Classification performance was evaluated using metrics, such as overall accuracy (OA) and mean accuracy (mAcc), in the experiments. To evaluate classification performance, the proposed model was evaluated against four pointwise methods, two convolution-based methods, two graph convolution-based methods, and four attention mechanism-based methods. The experimental results demonstrate that the proposed network exhibits good performance in the point cloud classification task and is capable of effectively representing local and global features. The proposed method achieves an OA of 93.0%, outperforming dynamic graph convolutional neural network(DGCNN) by 0.1%, PointWeb by 0.7%, and PointCNN by 0.8%. In addition, the mAcc of the proposed method reaches 89.7%. Furthermore, an experiment was designed to validate the efficacy of SSConv. By replacing SSConv with EdgeConv in the network architecture, the experimental results indicate a reduction in OA of 0.5% on the ModelNet40 dataset, demonstrating that SSConv is better suited for local representation than EdgeConv. Meanwhile, an experiment was designed to verify the diversity of input features of SSConv. The correlation of features was evaluated using Euclidean, cosine, and correlation distances. The results indicate that SSConv enhances diversity among input features more effectively than EdgeConv. Furthermore, the visualization results of the intermediate layer features in the model demonstrate that SSConv can learn more distinctive features.ConclusionThe proposed network model achieves better classification results, with an OA of 93.0% and an mAcc of 89.7%, surpassing those of existing methods. The proposed spatially structured convolution effectively enhances the variability of input features, allowing the model to learn more diverse local feature representations of objects. The proposed global feature coding method based on the attention mechanism effectively adjusts features and fully extracts the relationship between local and global feature information while preserving global features. To summarize, the proposed network model exhibits good capability for fine-grained feature extraction and achieves good classification performance.关键词:point cloud;edge convolution(EdgeConv);spatial structure;attention mechanism;classification
摘要:Objective3D point cloud classification is a crucial task with diverse applications in computer vision, robotics, and autonomous driving. The advancement of computing device performance in recent years has enabled researchers to apply deep learning methods to the field of 3D point cloud recognition. Deep learning-based methods that are currently in use for 3D point cloud classification typically divide the feature information captured by a network into two distinct parts: global and local features. Global features refer to the overall shape and structure of the point cloud, while local features capture more detailed information about individual points. By leveraging global and local features, these methods can achieve high accuracy in point cloud classification tasks. Edge convolution (EdgeConv) is currently the most widely used method for local feature extraction in 3D point cloud classification. This method incorporates relative position vectors into feature encoding to capture the characteristics of local structures effectively. However, when local structures in 3D point clouds are similar, the use of relative positions in feature encoding may result in similar features, leading to poor classification results. Furthermore, encoding only local features may be insufficient for achieving optimal classification results, because considering the correlation between local and global features is also crucial. Current methods frequently employ attention mechanisms to learn attention scores from global features and weigh local features accordingly, effectively establishing the correlation between local and global features. However, these methods may not fully consider the importance of global feature information and may suffer from suboptimal classification results.MethodTo address the aforementioned challenges, this study proposes a novel 3D point cloud classification network that leverages spatial structure convolution (SSConv) and attention mechanisms. The proposed network architecture consists of two parts: a local feature encoding (LFE) module and a global feature encoding (GFE) module. The former uses SSConv to encode local features from location and structure, while the latter learns global feature representation from raw coordinate data. Furthermore, to enable effective correlation and complementarity between feature information, we introduce an attention mechanism that facilitates adaptive adjustment of global features through weighted operations. The LFE module is composed of two operations: graph construction and feature extraction. The LFE module performs the K-nearest neighbor (KNN) algorithm to identify adjacent points and construct a graph structure. SSConv is a crucial feature extraction operation that involves a multilayer perceptron. Compared with EdgeConv, SSConv introduces a relative position vector between adjacent points. This operation effectively increases the correlation distance between raw input data, enriches local region structure information, and enhances the spatial expression ability of the extracted high-level semantic information. To capture more effective local structure features, feature extraction is encoded separately on the basis of structure and location. In particular, the location encoding branch encodes the coordinate information separately to obtain richer location feature information for describing the spatial location of each point. Meanwhile, the structure encoding branch encodes the relative location vector separately to learn the structure information in the local region for describing the overall geometric structure of the local neighborhood. The global feature encoding module maps raw coordinate data to high-dimensional features, which are used as the global feature representation of the point cloud. In addition, the module includes an attention mechanism to enhance the correlation between local and global features. In particular, an attention weighting method is used to guide the learning of global feature information by using local feature information. This operation enables correlation and fusion between local and global feature representations while preserving raw feature information.ResultTo evaluate the performance of the proposed network model, experimental validation is conducted on the publicly available ModelNet40 dataset, which consists of 9 843 training models and 2 468 testing models in 40 classes. Classification performance was evaluated using metrics, such as overall accuracy (OA) and mean accuracy (mAcc), in the experiments. To evaluate classification performance, the proposed model was evaluated against four pointwise methods, two convolution-based methods, two graph convolution-based methods, and four attention mechanism-based methods. The experimental results demonstrate that the proposed network exhibits good performance in the point cloud classification task and is capable of effectively representing local and global features. The proposed method achieves an OA of 93.0%, outperforming dynamic graph convolutional neural network(DGCNN) by 0.1%, PointWeb by 0.7%, and PointCNN by 0.8%. In addition, the mAcc of the proposed method reaches 89.7%. Furthermore, an experiment was designed to validate the efficacy of SSConv. By replacing SSConv with EdgeConv in the network architecture, the experimental results indicate a reduction in OA of 0.5% on the ModelNet40 dataset, demonstrating that SSConv is better suited for local representation than EdgeConv. Meanwhile, an experiment was designed to verify the diversity of input features of SSConv. The correlation of features was evaluated using Euclidean, cosine, and correlation distances. The results indicate that SSConv enhances diversity among input features more effectively than EdgeConv. Furthermore, the visualization results of the intermediate layer features in the model demonstrate that SSConv can learn more distinctive features.ConclusionThe proposed network model achieves better classification results, with an OA of 93.0% and an mAcc of 89.7%, surpassing those of existing methods. The proposed spatially structured convolution effectively enhances the variability of input features, allowing the model to learn more diverse local feature representations of objects. The proposed global feature coding method based on the attention mechanism effectively adjusts features and fully extracts the relationship between local and global feature information while preserving global features. To summarize, the proposed network model exhibits good capability for fine-grained feature extraction and achieves good classification performance.关键词:point cloud;edge convolution(EdgeConv);spatial structure;attention mechanism;classification- 2
- |
- 0
- |
- 0
发布时间:2024-02-16
Image Understanding and Computer Vision
-
 摘要:ObjectiveOptical remote sensing images objectively and accurately record the implementation of surface features and are widely used in the investigation, detection, analysis, and prediction forecasting of resources, environment, disasters, regions, and cities. The primary task of optical remote sensing image object detection is to locate and classify objects in the input remote sensing images with important values for research and application in the field of Earth observation. Traditional remote sensing object detection algorithms require manually designed features. However, features designed in this manner are limited, and consume considerable human and material resources but are not generalized and accurate enough to be improved. With the rapid development of deep learning in recent years, remote sensing object detection algorithms based on deep learning have achieved good results in optical image object detection. In contrast with object detection in natural scenes, objects in optical remote sensing images are rigid and most of them have key information, such as direction. Horizontal rectangular detection frames in natural scenes have problems in the field of optical remote sensing object detection, such as excessive background area, overlapping adjacent detection frames, and loss of object motion information. To achieve more accurate object detection in optical remote sensing images, a rotating rectangular frame that fits object contour is a more suitable choice. The detection of rotating remote sensing objects through the discovery of key points is one of the current mainstream approaches. However, these key point-based object detection algorithms tend to have problems, such as the overlapping of adjacent key points and inaccurate key point detection, due to the dense arrangement of remote sensing objects. To solve these key point regression problems, this study proposes an improved rotating elliptic Gaussian kernel with vector-guided point pair matching module, which achieves high-precision rotating object detection through the accurate prediction and matching of object centroids and head vertices.MethodAn hourglass network is different from the general feature extraction network, because its structure can fuse high-level features with rich semantic information and underlying features with rich spatial information. The generated high-resolution feature map can achieve the precise location of key points. The circular Gaussian kernel that returns key points in natural scenes exhibits the problems of uncertainty of Gaussian kernel radius and the overlapping of Gaussian kernels for densely arranged objects in remote sensing image object detection. The rotating elliptical Gaussian kernel proposed in this study solves the aforementioned problems. It is particularly constructed in such a way that the long and short axes of the elliptical Gaussian kernel are determined by the length and width of the rotating rectangular box of the object and the angle of the long axis of the ellipse is the same as the angle of the object. This rotated elliptical Gaussian kernel fits the shape of the object more closely, achieving better key point regression effect. In this study, the two key points of the object (i.e., the center point and the head vertex) are modeled as the core, and a point pair matching module that uses bootstrap vectors is proposed to achieve the exact pairing of the center point and the head vertex of the same object.ResultOur model is evaluated on the HRSC2016 and UCAS-AOD public datasets. The HRSC2016 dataset has 436 training images, 181 validation images, and 444 test images, with image sizes ranging from 300 × 300 to 1 500 × 900. The UCAS-AOD dataset has image sizes of 1 280 × 659, with 1 000 aircraft images and 510 vehicle images, including 7 482 aircraft objects and 7 114 vehicle objects. The annotations in the HRSC dataset contain the head vertices. The annotations of the aircraft category in the UCAS-AOD dataset contain the specific orientation angles of the objects, and thus, the head vertices of aircraft can be calculated. During the experiment, images of various sizes were cropped and deflated to 640 × 640 resolution and inputted into the network model. Four Nvidia RTX 2080Ti graphics cards were used, with a batch size of eight images per card and an initial learning rate set to 0.01. The optimizer for training was the stochastic gradient descent method with a momentum factor set to 0.9. Before training, the dataset was augmented through flipping and rotation. Recall, accuracy, and average precision are used as the evaluation metrics of the model. The experimental results on the HRSC dataset with large-aspect-ratio ship objects show that the proposed algorithm achieves better detection results than the other mainstream object detection algorithms, with an average accuracy of 90.78% (VOC 2007) and 97.85% (VOC 2012), and the precision-recall curves are also better than those of the other object detection algorithms.ConclusionOur experimental results show that the rotating object detection model that combines key points and bootstrap vectors is excellent and advanced. The rotating elliptic Gaussian kernel achieves more accurate key point regression, and the point pair matching module based on bootstrap vectors achieves accurate matching of centroids and head vertices, improving the detection of rotating objects.关键词:object detection;deep learning;rotating elliptic Gaussian kernel;guidance vectors;oriented detection
摘要:ObjectiveOptical remote sensing images objectively and accurately record the implementation of surface features and are widely used in the investigation, detection, analysis, and prediction forecasting of resources, environment, disasters, regions, and cities. The primary task of optical remote sensing image object detection is to locate and classify objects in the input remote sensing images with important values for research and application in the field of Earth observation. Traditional remote sensing object detection algorithms require manually designed features. However, features designed in this manner are limited, and consume considerable human and material resources but are not generalized and accurate enough to be improved. With the rapid development of deep learning in recent years, remote sensing object detection algorithms based on deep learning have achieved good results in optical image object detection. In contrast with object detection in natural scenes, objects in optical remote sensing images are rigid and most of them have key information, such as direction. Horizontal rectangular detection frames in natural scenes have problems in the field of optical remote sensing object detection, such as excessive background area, overlapping adjacent detection frames, and loss of object motion information. To achieve more accurate object detection in optical remote sensing images, a rotating rectangular frame that fits object contour is a more suitable choice. The detection of rotating remote sensing objects through the discovery of key points is one of the current mainstream approaches. However, these key point-based object detection algorithms tend to have problems, such as the overlapping of adjacent key points and inaccurate key point detection, due to the dense arrangement of remote sensing objects. To solve these key point regression problems, this study proposes an improved rotating elliptic Gaussian kernel with vector-guided point pair matching module, which achieves high-precision rotating object detection through the accurate prediction and matching of object centroids and head vertices.MethodAn hourglass network is different from the general feature extraction network, because its structure can fuse high-level features with rich semantic information and underlying features with rich spatial information. The generated high-resolution feature map can achieve the precise location of key points. The circular Gaussian kernel that returns key points in natural scenes exhibits the problems of uncertainty of Gaussian kernel radius and the overlapping of Gaussian kernels for densely arranged objects in remote sensing image object detection. The rotating elliptical Gaussian kernel proposed in this study solves the aforementioned problems. It is particularly constructed in such a way that the long and short axes of the elliptical Gaussian kernel are determined by the length and width of the rotating rectangular box of the object and the angle of the long axis of the ellipse is the same as the angle of the object. This rotated elliptical Gaussian kernel fits the shape of the object more closely, achieving better key point regression effect. In this study, the two key points of the object (i.e., the center point and the head vertex) are modeled as the core, and a point pair matching module that uses bootstrap vectors is proposed to achieve the exact pairing of the center point and the head vertex of the same object.ResultOur model is evaluated on the HRSC2016 and UCAS-AOD public datasets. The HRSC2016 dataset has 436 training images, 181 validation images, and 444 test images, with image sizes ranging from 300 × 300 to 1 500 × 900. The UCAS-AOD dataset has image sizes of 1 280 × 659, with 1 000 aircraft images and 510 vehicle images, including 7 482 aircraft objects and 7 114 vehicle objects. The annotations in the HRSC dataset contain the head vertices. The annotations of the aircraft category in the UCAS-AOD dataset contain the specific orientation angles of the objects, and thus, the head vertices of aircraft can be calculated. During the experiment, images of various sizes were cropped and deflated to 640 × 640 resolution and inputted into the network model. Four Nvidia RTX 2080Ti graphics cards were used, with a batch size of eight images per card and an initial learning rate set to 0.01. The optimizer for training was the stochastic gradient descent method with a momentum factor set to 0.9. Before training, the dataset was augmented through flipping and rotation. Recall, accuracy, and average precision are used as the evaluation metrics of the model. The experimental results on the HRSC dataset with large-aspect-ratio ship objects show that the proposed algorithm achieves better detection results than the other mainstream object detection algorithms, with an average accuracy of 90.78% (VOC 2007) and 97.85% (VOC 2012), and the precision-recall curves are also better than those of the other object detection algorithms.ConclusionOur experimental results show that the rotating object detection model that combines key points and bootstrap vectors is excellent and advanced. The rotating elliptic Gaussian kernel achieves more accurate key point regression, and the point pair matching module based on bootstrap vectors achieves accurate matching of centroids and head vertices, improving the detection of rotating objects.关键词:object detection;deep learning;rotating elliptic Gaussian kernel;guidance vectors;oriented detection- 2
- |
- 0
- |
- 0
发布时间:2024-02-16 -
 摘要:ObjectiveIn recent years, the efficacy of synthetic aperture radar (SAR) has been increasingly recognized in the fields of maritime surveillance and vessel detection due to its remarkable all-weather and day-to-night imaging capability. The ability of SAR systems to penetrate through clouds and fog has enabled high-quality imaging of the sea surface under various weather conditions. However, SAR imaging is frequently hindered by excessive noise and unclear imaging features, which can lead to erroneous detection in complex maritime environments. In response to this challenge, this study presents an innovative approach that combines state-of-the-art deep learning and computer vision techniques to improve the accuracy of SAR ship detection. By incorporating several critical enhancements into the YOLOv7 algorithm, the proposed method aims to enhance the capability of SAR systems to identify and track vessels accurately on the sea surface. The potential of this method is significant for maritime security and surveillance systems, because the accurate and reliable detection of vessels is paramount to ensuring the safety and security of shipping lanes and ports worldwide.MethodThe present study proposes a novel method that offers significant improvements to the YOLOv7 algorithm for SAR ship detection. In particular, a U-Net denoising module is designed in the preprocessing stage to suppress coherent speckle noise interference by leveraging deep learning techniques to model the range of parameter L. Moreover, the MLAN_SC structure is built in the YOLOv7 backbone network. To enhance key information extraction and deep feature expression abilities, the proposed method also introduces the selective kernel (SK) attention mechanism to improve the false detection rate. The contextual Transformer (COT) block is integrated into the backbone network to solve the problem of unbalanced upper and lower branch features in the multi-processings (MP) structure and improve the false detection situation. The COT block uses convolutional operations and combines local and global information for more effective feature extraction. In addition, space-to-depth convolution (SPD-Conv) is incorporated into the detection head to enhance small-object detection capability. This study further replaces the complete intersection over union loss function with the wise intersection over union (WIoU) loss function and applies a dynamic focusing mechanism to enhance target localization performance on complex images.ResultWe employed the network weights of ImageNet to train our model. The experimental data utilized in this study were selected from the SAR ship detection dataset (SSDD). SSDD contains 1 160 SAR images and 2 456 ship targets. The dataset primarily includes data from the RadarSat-2, Sentinel-1, and TerraSAR-X sensors. The target area was cropped to 500 pixels in four polarization modes: horizontal (HH), vertical (VV), cross (HV), and cross (VH), and then labeled in PASCAL VOC format. Our deep learning framework was implemented in Python, and input image size was adjusted to 640 × 640 during training. The momentum parameter was set to 0.93, and the starting learning rate was set to 0.001. We employed the cosine annealing method to attenuate the learning rate. The NVIDIA GeForce RTX3060 GPU device was used to accelerate stochastic gradient descent learning and iterate the model. Multiple ablative experiments were conducted to validate the effectiveness of the proposed module improvements on the SSDD dataset by using the original YOLOv7 network as a baseline for comparison. The baseline algorithm achieved an accuracy of 94.87%, while the addition of the denoising module resulted in a more precise extraction of targets in complex backgrounds, leading to an improvement in accuracy. The incorporation of the SK attention mechanism to construct a feature capture sampling structure significantly affected SAR ship detection, enhancing the representation of deep-level features and the extraction of key information, reducing false positives, and further improving detection accuracy. The integration of the SPD-Conv module and WIoU loss function helped the model focus on targets in complex scenes, improving localization performance and enhancing the detection ability of small dense targets in deep sea. The proposed method achieved the best AP@0.5 (99.25%) and AP@0.5∶0.95 (71.21%) on the SSDD dataset, which were 4.38% and 9.19% higher than the YOLOv7 baseline, respectively, demonstrating the effectiveness of the proposed module improvements. Comparative experiments were conducted with YOLOv7 and other popular deep learning-based object detection algorithms, such as SSD, Faster R-CNN, RetinaNet, CenterNet, FENDet, in terms of accuracy, recall, average precision, and time. The results showed that the proposed method had a recall rate that was 16.18% higher than that of Faster R-CNN and an accuracy rate that was 14.45% higher than that of RetinaNet. Furthermore, the proposed method exhibited high performance in handling missed and false positives. The precision-recall (PR) curve comparison indicated that the proposed algorithm demonstrated excellent detection performance and a stable PR curve. The detection results of different algorithms on the SSDD dataset were presented. Although several methods effectively detected ship targets, the proposed method achieved the highest accuracy in ship detection and exhibited superior performance in handling missed and false positives. Overall, the proposed algorithm has high feasibility and practicality in SAR ship detection.ConclusionIn this study, we propose an optimized version of the YOLOv7 algorithm for improving the accuracy of SAR ship detection. Our approach integrates multiple mechanisms to enhance information extraction and overcome challenges associated with noisy and complex images. In particular, we introduce a noise removal module, which effectively suppresses noise interference. The integration of the attention mechanism and self-attention mechanism strengthens feature extraction and enhances the discriminative learning ability of deep features. In addition, we incorporate SPD convolution and optimize the loss function to improve target location ability, resulting in significant improvements in false detection and missed detection rates for ships with complex backgrounds and dense small targets in near-shore SAR ship detection.关键词:SAR image;ship detection;YOLOv7;attention mechanism;contextual Transformer;space-to-depth convolution(SPD-Conv);WIoU loss function
摘要:ObjectiveIn recent years, the efficacy of synthetic aperture radar (SAR) has been increasingly recognized in the fields of maritime surveillance and vessel detection due to its remarkable all-weather and day-to-night imaging capability. The ability of SAR systems to penetrate through clouds and fog has enabled high-quality imaging of the sea surface under various weather conditions. However, SAR imaging is frequently hindered by excessive noise and unclear imaging features, which can lead to erroneous detection in complex maritime environments. In response to this challenge, this study presents an innovative approach that combines state-of-the-art deep learning and computer vision techniques to improve the accuracy of SAR ship detection. By incorporating several critical enhancements into the YOLOv7 algorithm, the proposed method aims to enhance the capability of SAR systems to identify and track vessels accurately on the sea surface. The potential of this method is significant for maritime security and surveillance systems, because the accurate and reliable detection of vessels is paramount to ensuring the safety and security of shipping lanes and ports worldwide.MethodThe present study proposes a novel method that offers significant improvements to the YOLOv7 algorithm for SAR ship detection. In particular, a U-Net denoising module is designed in the preprocessing stage to suppress coherent speckle noise interference by leveraging deep learning techniques to model the range of parameter L. Moreover, the MLAN_SC structure is built in the YOLOv7 backbone network. To enhance key information extraction and deep feature expression abilities, the proposed method also introduces the selective kernel (SK) attention mechanism to improve the false detection rate. The contextual Transformer (COT) block is integrated into the backbone network to solve the problem of unbalanced upper and lower branch features in the multi-processings (MP) structure and improve the false detection situation. The COT block uses convolutional operations and combines local and global information for more effective feature extraction. In addition, space-to-depth convolution (SPD-Conv) is incorporated into the detection head to enhance small-object detection capability. This study further replaces the complete intersection over union loss function with the wise intersection over union (WIoU) loss function and applies a dynamic focusing mechanism to enhance target localization performance on complex images.ResultWe employed the network weights of ImageNet to train our model. The experimental data utilized in this study were selected from the SAR ship detection dataset (SSDD). SSDD contains 1 160 SAR images and 2 456 ship targets. The dataset primarily includes data from the RadarSat-2, Sentinel-1, and TerraSAR-X sensors. The target area was cropped to 500 pixels in four polarization modes: horizontal (HH), vertical (VV), cross (HV), and cross (VH), and then labeled in PASCAL VOC format. Our deep learning framework was implemented in Python, and input image size was adjusted to 640 × 640 during training. The momentum parameter was set to 0.93, and the starting learning rate was set to 0.001. We employed the cosine annealing method to attenuate the learning rate. The NVIDIA GeForce RTX3060 GPU device was used to accelerate stochastic gradient descent learning and iterate the model. Multiple ablative experiments were conducted to validate the effectiveness of the proposed module improvements on the SSDD dataset by using the original YOLOv7 network as a baseline for comparison. The baseline algorithm achieved an accuracy of 94.87%, while the addition of the denoising module resulted in a more precise extraction of targets in complex backgrounds, leading to an improvement in accuracy. The incorporation of the SK attention mechanism to construct a feature capture sampling structure significantly affected SAR ship detection, enhancing the representation of deep-level features and the extraction of key information, reducing false positives, and further improving detection accuracy. The integration of the SPD-Conv module and WIoU loss function helped the model focus on targets in complex scenes, improving localization performance and enhancing the detection ability of small dense targets in deep sea. The proposed method achieved the best AP@0.5 (99.25%) and AP@0.5∶0.95 (71.21%) on the SSDD dataset, which were 4.38% and 9.19% higher than the YOLOv7 baseline, respectively, demonstrating the effectiveness of the proposed module improvements. Comparative experiments were conducted with YOLOv7 and other popular deep learning-based object detection algorithms, such as SSD, Faster R-CNN, RetinaNet, CenterNet, FENDet, in terms of accuracy, recall, average precision, and time. The results showed that the proposed method had a recall rate that was 16.18% higher than that of Faster R-CNN and an accuracy rate that was 14.45% higher than that of RetinaNet. Furthermore, the proposed method exhibited high performance in handling missed and false positives. The precision-recall (PR) curve comparison indicated that the proposed algorithm demonstrated excellent detection performance and a stable PR curve. The detection results of different algorithms on the SSDD dataset were presented. Although several methods effectively detected ship targets, the proposed method achieved the highest accuracy in ship detection and exhibited superior performance in handling missed and false positives. Overall, the proposed algorithm has high feasibility and practicality in SAR ship detection.ConclusionIn this study, we propose an optimized version of the YOLOv7 algorithm for improving the accuracy of SAR ship detection. Our approach integrates multiple mechanisms to enhance information extraction and overcome challenges associated with noisy and complex images. In particular, we introduce a noise removal module, which effectively suppresses noise interference. The integration of the attention mechanism and self-attention mechanism strengthens feature extraction and enhances the discriminative learning ability of deep features. In addition, we incorporate SPD convolution and optimize the loss function to improve target location ability, resulting in significant improvements in false detection and missed detection rates for ships with complex backgrounds and dense small targets in near-shore SAR ship detection.关键词:SAR image;ship detection;YOLOv7;attention mechanism;contextual Transformer;space-to-depth convolution(SPD-Conv);WIoU loss function- 2
- |
- 0
- |
- 0
发布时间:2024-02-16
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0