
最新刊期
卷 29 , 期 11 , 2024
-
 摘要:Since the mid-1980s, numerous research institutions have been developing autonomous driving technologies. The main idea of autonomous driving technology is to perceive the ego-vehicle states and its surroundings in real time through sensors, utilize an intelligent system for decision-making planning, and execute the driving operation through the control system. The decision-making module, which is an important component in autonomous driving systems, bridges perception and vehicle control. This module is mainly responsible for finding optimal paths or correct and reliable behaviors for the ego-vehicle to effectively drive on the road. In the research process of autonomous driving decision-making technologies, which are remarkably strict for safety, if the training is performed directly in the real world, then it will not only lead to a considerable cost increment but will also miss some marginal driving scenarios. In this case, numerous studies are first conducted in the simulation world before applying new autonomous driving models in the real world. However, the simulation can only provide an approximate model of vehicle dynamics and its interaction with the surrounding environment, and the vehicle agent trained only in the simulation world cannot be generalized to the real world. A gap still exists between reality and simulation, which is called the reality gap (RG) and poses a challenge for the transfer of developed autonomous driving models from simulated vehicles to real vehicles. Researchers have proposed numerous approaches to addressing the reality gap. This paper presents the principles and state-of-the-art methods of transferring knowledge from simulation to reality (sim2real) and parallel intelligence (PI), as well as their applications in decision-making for autonomous driving. Sim2real approaches reduce RG by simply transferring the learned models from the simulation to the reality environment. In autonomous driving, the basic idea of sim2real is to train the vehicle agent in the simulation environment and then transfer it to the reality environment using various methods, which can substantially reduce the number of interactions between the vehicle agent and the reality environment. Sim2real can also improve the effectiveness and performance of decision-making algorithms for autonomous driving. At present, the main sim2real methods include robust reinforcement learning (RL), meta-learning, curriculum learning, knowledge distillation, and transfer learning, as well as some other helpful techniques such as domain randomization and system identification, which have their own way of reducing the reality gap. For example, transfer learning bridges the reality gap by directly addressing the differences between domains. Vehicle agents in the real world may be exposed to problems that do not exist in the simulation world; thus, some researchers use meta-learning to bridge the gap. Sim2real methods handle the RG problem in some way, but their computational cost remains a challenge, especially when dealing with complex and dynamic environments, which limits the application range of sim2real methods. The PI, which solves the RG problem by parallelly performing the simulation environment with the reality environment, is proposed to solve the aforementioned problem. PI is a new paradigm based on the ACP method (artificial society, computational experiment, and parallel execution), which deeply integrates simulated and real scenarios. The main process of parallel intelligence involves the formation of a complete system through repeated interactions between the artificial and physical systems and the reduction of the RG through parallel execution and computational experiments. Among them, the computational experiment is divided into description learning, prediction learning, and prescriptive learning, which gradually transitions from the simulation environment to the real world. Parallel intelligence and sim2real technologies extend the physical space to the virtual space and model the real world through virtual-real interaction. Therefore, the vehicle agent can gain knowledge and experience through the simulation and real-life environments. The core technology of PI is to make decisions through the interaction between the real and artificial driving systems and realize the management and control of the driving system using comparison, learning, and experimentation of the two systems. Compared with sim2real methods, parallel intelligence deals with the relationship between simulated and real scenarios from a higher technical level, solves complex modeling problems, and markedly reduces the difference between simulated and real scenarios. In the field of autonomous driving, PI has developed several branches, mainly including the parallel system, parallel learning, parallel driving, and parallel planning. Moreover, the theoretical system has been continuously developed and has achieved remarkable results in numerous fields, such as transportation, medical treatment, manufacturing, and control. Subsequently, some autonomous driving simulators, such as AirSim and CARLA, are presented in this paper. Simulators for autonomous driving generally aim to minimize the mismatch between real and simulated setups by providing training data and experience, thus enabling the deployment of vehicle agents into the real world. Finally, existing challenges and future perspectives in sim2real and PI methods are summarized. With the continuous development of simulation-to-reality technologies, additional breakthroughs and progress in autonomous driving will be achieved in the future.关键词:autonomous driving;decision technology;reality gap(RG);sim2real;parallel intelligence(PI)
摘要:Since the mid-1980s, numerous research institutions have been developing autonomous driving technologies. The main idea of autonomous driving technology is to perceive the ego-vehicle states and its surroundings in real time through sensors, utilize an intelligent system for decision-making planning, and execute the driving operation through the control system. The decision-making module, which is an important component in autonomous driving systems, bridges perception and vehicle control. This module is mainly responsible for finding optimal paths or correct and reliable behaviors for the ego-vehicle to effectively drive on the road. In the research process of autonomous driving decision-making technologies, which are remarkably strict for safety, if the training is performed directly in the real world, then it will not only lead to a considerable cost increment but will also miss some marginal driving scenarios. In this case, numerous studies are first conducted in the simulation world before applying new autonomous driving models in the real world. However, the simulation can only provide an approximate model of vehicle dynamics and its interaction with the surrounding environment, and the vehicle agent trained only in the simulation world cannot be generalized to the real world. A gap still exists between reality and simulation, which is called the reality gap (RG) and poses a challenge for the transfer of developed autonomous driving models from simulated vehicles to real vehicles. Researchers have proposed numerous approaches to addressing the reality gap. This paper presents the principles and state-of-the-art methods of transferring knowledge from simulation to reality (sim2real) and parallel intelligence (PI), as well as their applications in decision-making for autonomous driving. Sim2real approaches reduce RG by simply transferring the learned models from the simulation to the reality environment. In autonomous driving, the basic idea of sim2real is to train the vehicle agent in the simulation environment and then transfer it to the reality environment using various methods, which can substantially reduce the number of interactions between the vehicle agent and the reality environment. Sim2real can also improve the effectiveness and performance of decision-making algorithms for autonomous driving. At present, the main sim2real methods include robust reinforcement learning (RL), meta-learning, curriculum learning, knowledge distillation, and transfer learning, as well as some other helpful techniques such as domain randomization and system identification, which have their own way of reducing the reality gap. For example, transfer learning bridges the reality gap by directly addressing the differences between domains. Vehicle agents in the real world may be exposed to problems that do not exist in the simulation world; thus, some researchers use meta-learning to bridge the gap. Sim2real methods handle the RG problem in some way, but their computational cost remains a challenge, especially when dealing with complex and dynamic environments, which limits the application range of sim2real methods. The PI, which solves the RG problem by parallelly performing the simulation environment with the reality environment, is proposed to solve the aforementioned problem. PI is a new paradigm based on the ACP method (artificial society, computational experiment, and parallel execution), which deeply integrates simulated and real scenarios. The main process of parallel intelligence involves the formation of a complete system through repeated interactions between the artificial and physical systems and the reduction of the RG through parallel execution and computational experiments. Among them, the computational experiment is divided into description learning, prediction learning, and prescriptive learning, which gradually transitions from the simulation environment to the real world. Parallel intelligence and sim2real technologies extend the physical space to the virtual space and model the real world through virtual-real interaction. Therefore, the vehicle agent can gain knowledge and experience through the simulation and real-life environments. The core technology of PI is to make decisions through the interaction between the real and artificial driving systems and realize the management and control of the driving system using comparison, learning, and experimentation of the two systems. Compared with sim2real methods, parallel intelligence deals with the relationship between simulated and real scenarios from a higher technical level, solves complex modeling problems, and markedly reduces the difference between simulated and real scenarios. In the field of autonomous driving, PI has developed several branches, mainly including the parallel system, parallel learning, parallel driving, and parallel planning. Moreover, the theoretical system has been continuously developed and has achieved remarkable results in numerous fields, such as transportation, medical treatment, manufacturing, and control. Subsequently, some autonomous driving simulators, such as AirSim and CARLA, are presented in this paper. Simulators for autonomous driving generally aim to minimize the mismatch between real and simulated setups by providing training data and experience, thus enabling the deployment of vehicle agents into the real world. Finally, existing challenges and future perspectives in sim2real and PI methods are summarized. With the continuous development of simulation-to-reality technologies, additional breakthroughs and progress in autonomous driving will be achieved in the future.关键词:autonomous driving;decision technology;reality gap(RG);sim2real;parallel intelligence(PI)- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
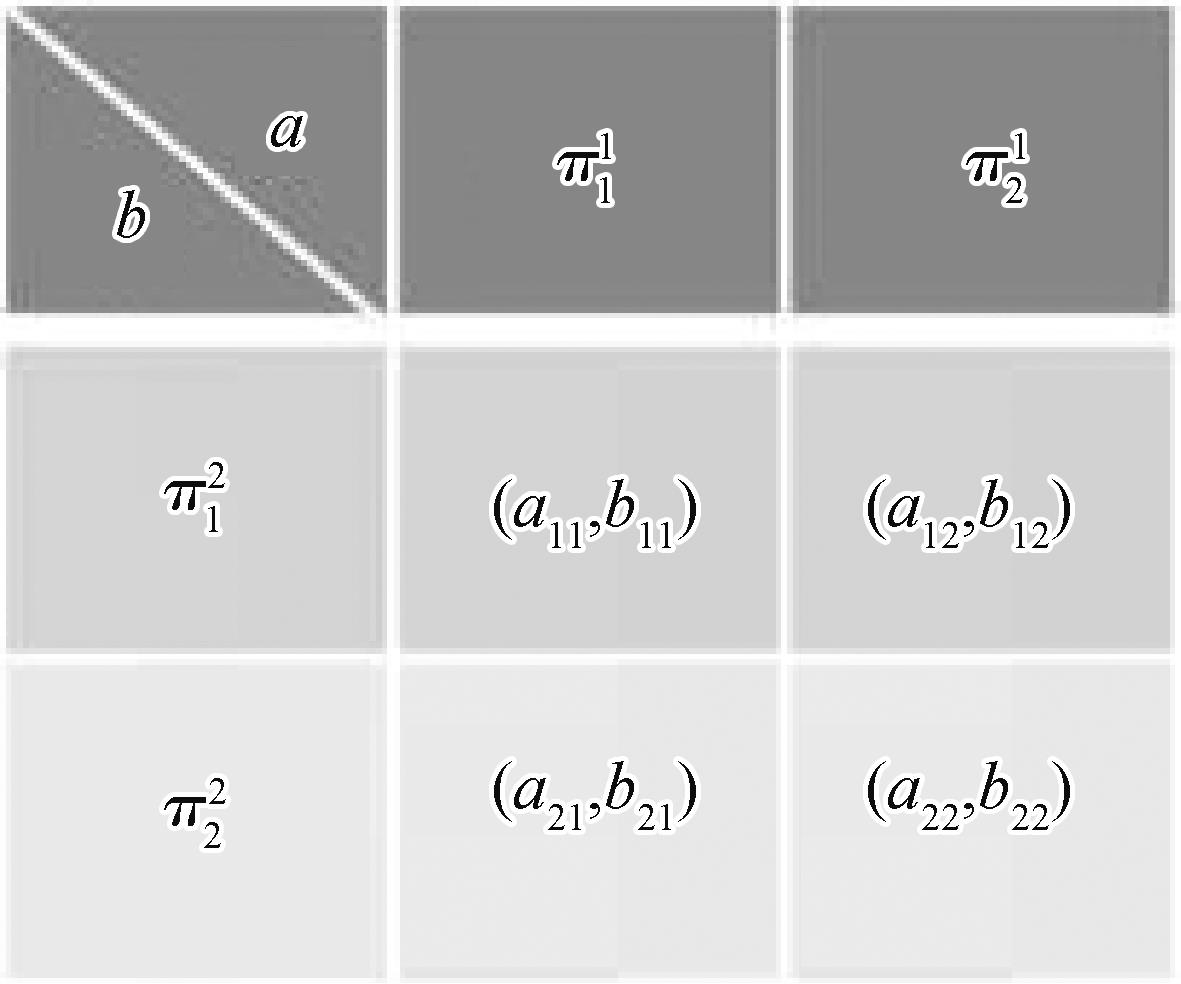 摘要:In the pursuit of furthering the understanding of unmanned swarm systems, this paper embarks on an expansive journey, delving even deeper into the intricacies of cooperative decision-making and game control. The two methodological pillars, carefully chosen for their unique contributions, play a pivotal role in steering unmanned swarm systems toward heightened efficiency and adaptability across diverse environments. First, the implementation of cooperative control stands as a cornerstone, fostering enhanced communication and collaboration among agents within the unmanned swarm system. This strategic approach not only minimizes conflicts but also streamlines tasks, contributing substantially to the augmentation of system efficiency. Cooperative control establishes a foundation for improved information exchange and seamless cooperation by promoting a cohesive environment where agents work in tandem. Second, the integration of game control methodologies plays a pivotal role in empowering agents to navigate conflicts of interest effectively. This approach goes beyond conflict resolution; it actively contributes to elevating decision-making processes and optimizing the overall interests of the cluster system. The dynamic nature of game control ensures that agents can strategically navigate complex scenarios, maximizing collective interests and ensuring the sustained efficiency of the unmanned swarm system. Additionally, in practical large-scale problems, a balanced combination of cooperation and games enhances the adaptive capabilities of intelligent system clusters in diverse environments. This approach effectively resolves conflicts of interest and decision-making challenges that may arise between agents. Regarding the implementation of the two methods, this study concentrates on utilizing the collaborative control method for tasks such as formation control, cluster path planning, and cluster task collaboration. Specific technical implementations are allocated to corresponding sub-items. The game control methods center around various game types, including self-play, evolutionary play, and reinforcement learning play. These approaches offer new prospects for addressing optimization challenges in cluster control. This study comprehensively reviews the application of cooperative and game control methods in the unmanned swarm system. Explicit explanations of fundamental concepts, including agents, swarm intelligence, and unmanned swarm systems, are provided to establish a basic understanding for readers. Subsequently, the mathematical models of cooperative and game control, swarm cooperation and game decisions, swarm cooperative control methods, swarm game control methods, and other algorithms are introduced. The emphasis is placed on the theoretical foundations of cooperative decision-making and game control, along with their applications in improving overall system performance in the unmanned swarm system. Furthermore, the paper delves into illustrative application scenarios, providing concrete examples of how swarm cooperation and game control methodologies find practical relevance across diverse fields. These exemplary cases span a spectrum of industries, including intelligent transportation, unmanned aerial vehicle(UAV) formation, logistics and distribution, and military domains. The paper offers valuable insights into the versatility and adaptability of unmanned swarm systems by demonstrating the tangible applications of these technologies in real-world settings. Finally, the paper discusses future research directions and challenges, emphasizing the necessity for new technologies and methods to address evolving needs and problems. The highlighted complex challenges, including the intricacy of large-scale swarm systems, collaboration among heterogeneous agents, adaptability to dynamic environments, autonomy of clusters, interpretability and safety of unmanned swarm systems, and self-healing capability, undoubtedly serve as key research focal points for future unmanned systems. Overall, this paper serves as a comprehensive guide and reference, not only delving into the theoretical foundations but also providing practical insights into the application of cooperative decision-making and game control in unmanned swarm systems. The forward-looking approach of this paper positions it as a valuable resource for those seeking to advance the field, foster development and innovation, and contribute to the ongoing scientific and technological progress in this domain.关键词:unmanned swarm systems(USS);intelligent decision;game control;cooperative control;reinforcement learning(RL)
摘要:In the pursuit of furthering the understanding of unmanned swarm systems, this paper embarks on an expansive journey, delving even deeper into the intricacies of cooperative decision-making and game control. The two methodological pillars, carefully chosen for their unique contributions, play a pivotal role in steering unmanned swarm systems toward heightened efficiency and adaptability across diverse environments. First, the implementation of cooperative control stands as a cornerstone, fostering enhanced communication and collaboration among agents within the unmanned swarm system. This strategic approach not only minimizes conflicts but also streamlines tasks, contributing substantially to the augmentation of system efficiency. Cooperative control establishes a foundation for improved information exchange and seamless cooperation by promoting a cohesive environment where agents work in tandem. Second, the integration of game control methodologies plays a pivotal role in empowering agents to navigate conflicts of interest effectively. This approach goes beyond conflict resolution; it actively contributes to elevating decision-making processes and optimizing the overall interests of the cluster system. The dynamic nature of game control ensures that agents can strategically navigate complex scenarios, maximizing collective interests and ensuring the sustained efficiency of the unmanned swarm system. Additionally, in practical large-scale problems, a balanced combination of cooperation and games enhances the adaptive capabilities of intelligent system clusters in diverse environments. This approach effectively resolves conflicts of interest and decision-making challenges that may arise between agents. Regarding the implementation of the two methods, this study concentrates on utilizing the collaborative control method for tasks such as formation control, cluster path planning, and cluster task collaboration. Specific technical implementations are allocated to corresponding sub-items. The game control methods center around various game types, including self-play, evolutionary play, and reinforcement learning play. These approaches offer new prospects for addressing optimization challenges in cluster control. This study comprehensively reviews the application of cooperative and game control methods in the unmanned swarm system. Explicit explanations of fundamental concepts, including agents, swarm intelligence, and unmanned swarm systems, are provided to establish a basic understanding for readers. Subsequently, the mathematical models of cooperative and game control, swarm cooperation and game decisions, swarm cooperative control methods, swarm game control methods, and other algorithms are introduced. The emphasis is placed on the theoretical foundations of cooperative decision-making and game control, along with their applications in improving overall system performance in the unmanned swarm system. Furthermore, the paper delves into illustrative application scenarios, providing concrete examples of how swarm cooperation and game control methodologies find practical relevance across diverse fields. These exemplary cases span a spectrum of industries, including intelligent transportation, unmanned aerial vehicle(UAV) formation, logistics and distribution, and military domains. The paper offers valuable insights into the versatility and adaptability of unmanned swarm systems by demonstrating the tangible applications of these technologies in real-world settings. Finally, the paper discusses future research directions and challenges, emphasizing the necessity for new technologies and methods to address evolving needs and problems. The highlighted complex challenges, including the intricacy of large-scale swarm systems, collaboration among heterogeneous agents, adaptability to dynamic environments, autonomy of clusters, interpretability and safety of unmanned swarm systems, and self-healing capability, undoubtedly serve as key research focal points for future unmanned systems. Overall, this paper serves as a comprehensive guide and reference, not only delving into the theoretical foundations but also providing practical insights into the application of cooperative decision-making and game control in unmanned swarm systems. The forward-looking approach of this paper positions it as a valuable resource for those seeking to advance the field, foster development and innovation, and contribute to the ongoing scientific and technological progress in this domain.关键词:unmanned swarm systems(USS);intelligent decision;game control;cooperative control;reinforcement learning(RL)- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:Deep learning technologies have accelerated the development and advancement of end-to-end autonomous driving frameworks in recent years, sparking the emergence of numerous cutting-edge research topics and application deployment solutions. The “divide and conquer” architecture design concept, which aims to construct multiple independent but related module components, integrate them into the developed software system in a specific semantic or geometric order, and ultimately deploy these components to the actual vehicle, is the foundation for the majority of the autonomous driving systems currently in use, also known as modular systems. However, a well-developed modular design typically comprises thousands of components, placing a considerable burden on the graphics memory and processing capacity of automotive CPUs. Furthermore, the intrinsic mistakes of each stacked module during prediction will rise with the number of stacked modules, and upstream flaws cannot be fixed in downstream modules, presenting a major risk to vehicle safety. A multitask architecture based on the “task parallelism” principle aims to efficiently infer multiple tasks in parallel by designing various decoded heads with a shared backbone network to reduce computational consumption. However, the optimization goals for various tasks may not be consistent, and sharing features mindlessly can even degrade the overall performance of the system. In contrast to the previous two system architectures, the end-to-end technology paradigm eliminates information bottlenecks and cumulative errors due to the integration of numerous intermediate components based on rule interfaces, allowing the network to continually optimize toward a unified objective. A large model can be used to generate low-level control signals or vehicle motion planning based on inputs such as sensor data and vehicle status. With sensors serving as inputs, the early end-to-end design based on imitation and reinforcement learning directly outputs the final control commands for steering, braking, and acceleration. However, no explicit representation of driving scenarios in this completely “black box” network, which is also referred to as weakly interpretable end-to-end methods, is available. Thus, understanding the reasoning behind the decision or prediction of a vehicle is difficult for humans, making debugging, validation, and optimization challenging. Even worse, once the model malfunctions or unexpected situations occur, accurately detecting, avoiding, and repairing problems in a timely manner becomes difficult, all of which are crucial for maintaining the safe operation of intelligent vehicles. The component decoupling approach facilitates the development and optimization of individual modules in the conventional modular system, thereby guaranteeing steady representation performance and strong interpretability for each submodule. Unfortunately, this method falls short of achieving unified goals at the optimization level, that is, integrating optimization and learning toward the ultimate planning goal. A modular joint end-to-end autonomous driving architecture, which preserves the modular driving system while allowing the differentiability of each module, is a workable solution to ensure that every module has sufficient interpretability and overall automatic optimization capabilities. The basic idea behind this technology lies in the creation of a unique neural network that connects all independent modules and enables the gradients from the planning modules to be fed back down to the initial sensor input for end-to-end execution. In other words, this kind of approach merely modifies the submodule connection mechanism while maintaining the classic modular technology stack; that is, this approach substitutes a new implicit interface for the previous explicit interfaces, which were rule-based and required manual creation. Modular joint end-to-end procedures offer a certain interpretability because of the distinct separation between modules. The explicit end-to-end system is a relative decoupling based on overall design and exhibits some degree of logic in its sequential functioning from perception to prediction, and then to planning modules during decision inference. The model can be intentionally adjusted when it encounters unknown and uncontrollable results by understanding the operational logic underlying the explicit solution. Furthermore, visualization methods, such as internal features or intermediate results of specific tasks or modules, can be utilized to analyze the decision-making operation mechanism, which can prevent potential risks caused by black box models and ensure the safe and efficient driving of intelligent vehicles. Therefore, this article conducts comprehensive analysis and research on the emerging field of end-to-end autonomous driving with promising development prospects, which summarizes the main technical routes and representative research methods around the development path of end-to-end driving systems. More specifically, this article, which begins with the classic modular system, analyzes the shortcomings of conventional modular and multitasking approaches while providing a brief introduction to the four functional modules of the autonomous driving system. These modules primarily include perception, prediction, planning, and decision making. Subsequently, extensive research on the emerging end-to-end autonomous driving frameworks is conducted from the perspective of input-output modality to system architecture, describing in detail the two dominant paradigms and delving into the shortcomings and drawbacks of existing research work. The existing end-to-end architecture can be categorized into two categories based on interpretable performance: weakly interpretable end-to-end, which is explored from the aspects of imitation learning, reinforcement learning, and interpretability; or modular joint end-to-end, which is progressively investigated from bird’s-eye view representation, to joint perception prediction, and ultimately, planning-oriented end-to-end methods. Afterward, a thorough discussion of the end-to-end driving system assessment is provided for closed- and open-loop evaluations, along with the corresponding situations. Finally, the research works on end-to-end autonomous driving systems are summarized, and the potential challenges and key problems that still need to be addressed are discussed from the perspectives of data mining and architecture design.关键词:artificial intelligence(AI);autonomous driving;modular driving system;end-to-end system;data driven;interpretability
摘要:Deep learning technologies have accelerated the development and advancement of end-to-end autonomous driving frameworks in recent years, sparking the emergence of numerous cutting-edge research topics and application deployment solutions. The “divide and conquer” architecture design concept, which aims to construct multiple independent but related module components, integrate them into the developed software system in a specific semantic or geometric order, and ultimately deploy these components to the actual vehicle, is the foundation for the majority of the autonomous driving systems currently in use, also known as modular systems. However, a well-developed modular design typically comprises thousands of components, placing a considerable burden on the graphics memory and processing capacity of automotive CPUs. Furthermore, the intrinsic mistakes of each stacked module during prediction will rise with the number of stacked modules, and upstream flaws cannot be fixed in downstream modules, presenting a major risk to vehicle safety. A multitask architecture based on the “task parallelism” principle aims to efficiently infer multiple tasks in parallel by designing various decoded heads with a shared backbone network to reduce computational consumption. However, the optimization goals for various tasks may not be consistent, and sharing features mindlessly can even degrade the overall performance of the system. In contrast to the previous two system architectures, the end-to-end technology paradigm eliminates information bottlenecks and cumulative errors due to the integration of numerous intermediate components based on rule interfaces, allowing the network to continually optimize toward a unified objective. A large model can be used to generate low-level control signals or vehicle motion planning based on inputs such as sensor data and vehicle status. With sensors serving as inputs, the early end-to-end design based on imitation and reinforcement learning directly outputs the final control commands for steering, braking, and acceleration. However, no explicit representation of driving scenarios in this completely “black box” network, which is also referred to as weakly interpretable end-to-end methods, is available. Thus, understanding the reasoning behind the decision or prediction of a vehicle is difficult for humans, making debugging, validation, and optimization challenging. Even worse, once the model malfunctions or unexpected situations occur, accurately detecting, avoiding, and repairing problems in a timely manner becomes difficult, all of which are crucial for maintaining the safe operation of intelligent vehicles. The component decoupling approach facilitates the development and optimization of individual modules in the conventional modular system, thereby guaranteeing steady representation performance and strong interpretability for each submodule. Unfortunately, this method falls short of achieving unified goals at the optimization level, that is, integrating optimization and learning toward the ultimate planning goal. A modular joint end-to-end autonomous driving architecture, which preserves the modular driving system while allowing the differentiability of each module, is a workable solution to ensure that every module has sufficient interpretability and overall automatic optimization capabilities. The basic idea behind this technology lies in the creation of a unique neural network that connects all independent modules and enables the gradients from the planning modules to be fed back down to the initial sensor input for end-to-end execution. In other words, this kind of approach merely modifies the submodule connection mechanism while maintaining the classic modular technology stack; that is, this approach substitutes a new implicit interface for the previous explicit interfaces, which were rule-based and required manual creation. Modular joint end-to-end procedures offer a certain interpretability because of the distinct separation between modules. The explicit end-to-end system is a relative decoupling based on overall design and exhibits some degree of logic in its sequential functioning from perception to prediction, and then to planning modules during decision inference. The model can be intentionally adjusted when it encounters unknown and uncontrollable results by understanding the operational logic underlying the explicit solution. Furthermore, visualization methods, such as internal features or intermediate results of specific tasks or modules, can be utilized to analyze the decision-making operation mechanism, which can prevent potential risks caused by black box models and ensure the safe and efficient driving of intelligent vehicles. Therefore, this article conducts comprehensive analysis and research on the emerging field of end-to-end autonomous driving with promising development prospects, which summarizes the main technical routes and representative research methods around the development path of end-to-end driving systems. More specifically, this article, which begins with the classic modular system, analyzes the shortcomings of conventional modular and multitasking approaches while providing a brief introduction to the four functional modules of the autonomous driving system. These modules primarily include perception, prediction, planning, and decision making. Subsequently, extensive research on the emerging end-to-end autonomous driving frameworks is conducted from the perspective of input-output modality to system architecture, describing in detail the two dominant paradigms and delving into the shortcomings and drawbacks of existing research work. The existing end-to-end architecture can be categorized into two categories based on interpretable performance: weakly interpretable end-to-end, which is explored from the aspects of imitation learning, reinforcement learning, and interpretability; or modular joint end-to-end, which is progressively investigated from bird’s-eye view representation, to joint perception prediction, and ultimately, planning-oriented end-to-end methods. Afterward, a thorough discussion of the end-to-end driving system assessment is provided for closed- and open-loop evaluations, along with the corresponding situations. Finally, the research works on end-to-end autonomous driving systems are summarized, and the potential challenges and key problems that still need to be addressed are discussed from the perspectives of data mining and architecture design.关键词:artificial intelligence(AI);autonomous driving;modular driving system;end-to-end system;data driven;interpretability- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:Conventional two-dimensional (2D) object detection technology primarily emphasizes classifying the target to be detected and defining its bounding box in image space coordinates but lacks the capability to provide accurate information regarding the real three-dimensional (3D) spatial position of the target. This limitation restricts its applicability in autonomous driving systems (ADs), particularly for tasks such as obstacle avoidance and path planning in real 3D environments. The emerging field of 3D object detection represents a substantial technological advancement. This field primarily relies on neural networks to extract features from input data, commonly obtained from camera images or LiDAR-captured point clouds. Following feature extraction, 3D object detection predicts the category of the target and furnishes crucial data, including its spatial coordinates, dimensions, and yaw angles in a real-world coordinate system. This detection facilitates the provision of essential preliminary information for subsequent operations, such as object tracking, trajectory forecasting, and path planning. Consequently, this technology has assumed a vital role within the field of ADs, serving as a cornerstone within the domain of perception tasks. The field of 3D object detection has currently witnessed the emergence of numerous exceptional methodologies, exhibiting notable accomplishments. Several scholars have conducted comprehensive reviews and in-depth assessments of these pertinent works and their associated outcomes. However, prior reviews may have omitted the latest developments due to the rapid evolution of technology within the domain of computer vision. Therefore, constantly monitoring the most recent advancements and continuing at the frontline of this realm is not only an imperative task for the academic community but is also a fundamental endeavor to effectively respond to the emerging challenges posed by the incessant and expeditious technological advancements and progression. Based on the preceding considerations, this paper conducts a systematic review of the latest developments and cutting-edge theories in the realm of existing 3D object detection. In contrast to earlier review studies, the current work offers distinct advantages because it encompasses the inclusion of more cutting-edge methodologies and encompasses a broader spectrum of fields. For example, while most prior review works predominantly concentrated on individual sensors, this work uniquely incorporates a multitude of diverse sensor types. Moreover, this work encompasses a wide array of distinct training strategies, ranging from semi-supervised and weak-supervised methods to active learning and knowledge distillation techniques, thereby substantially enhancing the breadth and depth of research within this field. Specifically, this work starts with a concise contextualization of the progress of the field and conducts a brief examination of pertinent review research. Subsequently, the fundamental definition of 3D object detection is explored, and multiple widely used datasets are comprehensively summarized based on data scale and diversity, extending the discourse to the introduction of the evaluation criteria integral to the relevant benchmark assessments. Among these datasets, three widely recognized datasets are particularly highlighted: KITTI, nuScenes, and Waymo Open. Next, the multitude of detection methods proposed in the previous year is categorized into five distinct groups, primarily dictated by the type and quantity of sensors involved: monocular-based, stereo-based, multi-view-based, LiDAR-based, and multimodal-based. Additionally, further subcategorization is conducted within each group according to the specific data preprocessing methods or model architectures utilized. Within each method category grounded in distinct sensor types, the examination starts with a comprehensive review of the pioneering representative algorithms. An intricate exposition of the latest and most advanced methodologies within that specific domain is then offered. Furthermore, an in-depth analysis of the prospective pathways for development and the formidable challenges currently encountered by this category is conducted. Among the five categories, the monocular method relies solely on a single camera for the classification and localization of environmental objects. This approach is cost-effective and easy to implement. However, it grapples with the challenge of ill-posed depth information regression from monocular images, which frequently results in reduced accuracy for this method. The stereo-based method leverages stereo images to enforce geometric constraints, leading to more precise depth estimation and comparatively higher detection accuracy. However, the requirement for stereo camera calibration drives up the deployment costs of this method, thereby maintaining its susceptibility to environmental factors. The multi-view-based method seeks to establish a unified feature space through the utilization of multiple surrounding cameras. Unlike the first two approaches, this method provides improved safety and practicality due to its panoramic perspective. However, the absence of direct constraints between cameras results in its inherent ill-posed nature. LiDAR-based methods excel in directly providing accurate depth information, which eliminates the need for additional depth estimation. This method leads to enhanced detection efficiency and accuracy compared to image-centric methods. Despite these advantages, the substantial hardware costs associated with LiDAR pose a considerable financial burden on real-world deployments. The multimodal-based approaches leverage the advantages of image and point cloud data, albeit at the cost of increased computational time required for the concurrent processing of these data modalities. In a broader context, each of the five method categories exhibits unique strengths and limitations, necessitating a careful selection based on financial considerations and specific application prerequisites during real-world engineering deployment. Upon concluding the exhaustive review of all methodologies, comprehensive statistical analyses of these techniques are conducted on datasets such as KITTI, nuScenes, and Waymo Open. The statistical evaluations encompassed aspects pertaining to detection performance and inference time. In this research, we have meticulously reviewed 3Dobject detection algorithms in the context of AD. This comprehensive study encompasses detection algorithms based on various mainstream sensors and includes an exploration of the latest advancements in this field. Subsequently, we perform a comprehensive statistical analysis and comparison of the performance and latency demonstrated by all the methods on widely recognized datasets. A summary of the current research status is presented, and prospects for future research directions are provided.关键词:autonomous driving;3D object detection;monocular;stereo;multi-view;light detection and ranging(LiDAR);multi-modal
摘要:Conventional two-dimensional (2D) object detection technology primarily emphasizes classifying the target to be detected and defining its bounding box in image space coordinates but lacks the capability to provide accurate information regarding the real three-dimensional (3D) spatial position of the target. This limitation restricts its applicability in autonomous driving systems (ADs), particularly for tasks such as obstacle avoidance and path planning in real 3D environments. The emerging field of 3D object detection represents a substantial technological advancement. This field primarily relies on neural networks to extract features from input data, commonly obtained from camera images or LiDAR-captured point clouds. Following feature extraction, 3D object detection predicts the category of the target and furnishes crucial data, including its spatial coordinates, dimensions, and yaw angles in a real-world coordinate system. This detection facilitates the provision of essential preliminary information for subsequent operations, such as object tracking, trajectory forecasting, and path planning. Consequently, this technology has assumed a vital role within the field of ADs, serving as a cornerstone within the domain of perception tasks. The field of 3D object detection has currently witnessed the emergence of numerous exceptional methodologies, exhibiting notable accomplishments. Several scholars have conducted comprehensive reviews and in-depth assessments of these pertinent works and their associated outcomes. However, prior reviews may have omitted the latest developments due to the rapid evolution of technology within the domain of computer vision. Therefore, constantly monitoring the most recent advancements and continuing at the frontline of this realm is not only an imperative task for the academic community but is also a fundamental endeavor to effectively respond to the emerging challenges posed by the incessant and expeditious technological advancements and progression. Based on the preceding considerations, this paper conducts a systematic review of the latest developments and cutting-edge theories in the realm of existing 3D object detection. In contrast to earlier review studies, the current work offers distinct advantages because it encompasses the inclusion of more cutting-edge methodologies and encompasses a broader spectrum of fields. For example, while most prior review works predominantly concentrated on individual sensors, this work uniquely incorporates a multitude of diverse sensor types. Moreover, this work encompasses a wide array of distinct training strategies, ranging from semi-supervised and weak-supervised methods to active learning and knowledge distillation techniques, thereby substantially enhancing the breadth and depth of research within this field. Specifically, this work starts with a concise contextualization of the progress of the field and conducts a brief examination of pertinent review research. Subsequently, the fundamental definition of 3D object detection is explored, and multiple widely used datasets are comprehensively summarized based on data scale and diversity, extending the discourse to the introduction of the evaluation criteria integral to the relevant benchmark assessments. Among these datasets, three widely recognized datasets are particularly highlighted: KITTI, nuScenes, and Waymo Open. Next, the multitude of detection methods proposed in the previous year is categorized into five distinct groups, primarily dictated by the type and quantity of sensors involved: monocular-based, stereo-based, multi-view-based, LiDAR-based, and multimodal-based. Additionally, further subcategorization is conducted within each group according to the specific data preprocessing methods or model architectures utilized. Within each method category grounded in distinct sensor types, the examination starts with a comprehensive review of the pioneering representative algorithms. An intricate exposition of the latest and most advanced methodologies within that specific domain is then offered. Furthermore, an in-depth analysis of the prospective pathways for development and the formidable challenges currently encountered by this category is conducted. Among the five categories, the monocular method relies solely on a single camera for the classification and localization of environmental objects. This approach is cost-effective and easy to implement. However, it grapples with the challenge of ill-posed depth information regression from monocular images, which frequently results in reduced accuracy for this method. The stereo-based method leverages stereo images to enforce geometric constraints, leading to more precise depth estimation and comparatively higher detection accuracy. However, the requirement for stereo camera calibration drives up the deployment costs of this method, thereby maintaining its susceptibility to environmental factors. The multi-view-based method seeks to establish a unified feature space through the utilization of multiple surrounding cameras. Unlike the first two approaches, this method provides improved safety and practicality due to its panoramic perspective. However, the absence of direct constraints between cameras results in its inherent ill-posed nature. LiDAR-based methods excel in directly providing accurate depth information, which eliminates the need for additional depth estimation. This method leads to enhanced detection efficiency and accuracy compared to image-centric methods. Despite these advantages, the substantial hardware costs associated with LiDAR pose a considerable financial burden on real-world deployments. The multimodal-based approaches leverage the advantages of image and point cloud data, albeit at the cost of increased computational time required for the concurrent processing of these data modalities. In a broader context, each of the five method categories exhibits unique strengths and limitations, necessitating a careful selection based on financial considerations and specific application prerequisites during real-world engineering deployment. Upon concluding the exhaustive review of all methodologies, comprehensive statistical analyses of these techniques are conducted on datasets such as KITTI, nuScenes, and Waymo Open. The statistical evaluations encompassed aspects pertaining to detection performance and inference time. In this research, we have meticulously reviewed 3Dobject detection algorithms in the context of AD. This comprehensive study encompasses detection algorithms based on various mainstream sensors and includes an exploration of the latest advancements in this field. Subsequently, we perform a comprehensive statistical analysis and comparison of the performance and latency demonstrated by all the methods on widely recognized datasets. A summary of the current research status is presented, and prospects for future research directions are provided.关键词:autonomous driving;3D object detection;monocular;stereo;multi-view;light detection and ranging(LiDAR);multi-modal- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveWith the rapid development of visual perception technology, autonomous driving can already be applied to simple scenarios. However, in actual complex urban road applications, especially in safety-critical scenarios such as sudden lane changes by other vehicles, the intrusion of pedestrians, and the appearance of obstacles, some challenges must still be resolved. First, most existing autonomous driving systems still use the vast majority of daily natural scenes or heuristically generated adversarial scenes for training and evaluation. Among them, safety-critical scenarios, which refer to a collection of scenes in areas where cars are in danger of collision, especially scenes involving vulnerable traffic groups such as pedestrians, play an important role in the safety performance evaluation of autonomous driving systems. However, this type of scenario generally has a low probability of occurring in the real world, and such critical scene data have long-tail distribution problems, causing data-driven autonomous driving risk perception to face technical bottlenecks. Second, creating new scenes using current scene generation methods or virtual simulation scene automatic generation frameworks based on certain rules is difficult, and the generated driving scenes are often insufficiently realistic and lack a certain degree of diversity. By contrast, the scene generation method based on the diffusion model not only fully explores the characteristics of real data and supplements the gaps in the existing collected real data, but also facilitates interpretable and controllable scene generation. In addition, the difficult problem of limited system risk perception capabilities is still encountered in safety-critical scenarios. For risk-aware safety assessment technology, traditional methods based on convolutional neural networks can achieve the simple extraction of features of each object in the scene but cannot obtain high-level semantic information, that is, the relationship between various traffic entities. Obtaining such high-level information is still challenging because most potential risks are hidden at the semantic and behavioral levels. Autonomous driving risk assessment based on traffic scene graphs has become a popular research topic in recent years. Potential risks can be effectively understood and predicted by constructing and analyzing traffic scene graphs and capturing the overall relationships and interactions in the traffic scene, providing a basis for autonomous driving. The system delivers highly accurate decision support. Starting from the visual perception of human drivers, different traffic entities have various risk impacts on autonomous vehicles. However, risk perception methods based on traffic scene graphs generally use graph convolution to iteratively update the feature representation of each node. This method ignores the importance of different types of edges between nodes during message transmission. Considering these challenges and difficulties, this paper proposes a risk-enhanced perception framework based on the parallel vision to realize the automatic generation of safety-critical scene data and examines the importance of different types of edges between adjacent traffic entities.MethodThis method is based on the interactive ACP theory and integrates descriptive, prescriptive, and predictive intelligence under a parallel vision framework to achieve vision-based enhanced risk perception. Specifically, based on descriptive and prescriptive learning, a background adaptive module and a feature fusion encoder are first introduced into the diffusion model structure, thereby reducing the boundary contours of pedestrians and improving image quality. The controllable generation of risk sequences in safety-critical scenarios can be achieved by controlling the specific locations where dangerous elements, such as pedestrians, are generated. Second, a cognitive scene graph construction method based on spatial rules is used to obtain the spatial position of each entity in the scene through target detection. Based on the spatial relative position information and setting relevant threshold information, the distance, orientation, and affiliation relationships between entities in the traffic scene are extracted. The extraction of interactive relationships is mainly based on the changes in spatial information between traffic entities over time. Finally, under the predictive learning framework, a new graph model-based risk enhancement perception method, which integrates the relational graph attention network and the Transformer encoder module, is proposed to perform spatiotemporal modeling of scene graph sequence data. The relational graph attention network (RGAT) introduces an attention mechanism, assigns different weight values to different neighborhood relationships, and obtains the feature representation of nodes through weighted summation. The temporal Transformer encoder module is used to model the temporal dynamics of scene graph sequence data, ultimately outputting risk-aware visual reasoning results.ResultExperiments were conducted on three datasets (MRSG-144, IESG, and 1043-carla-sg) to compare the performance with five mainstream risk perception methods based on graph-structured data and verify the effectiveness of the proposed method. This method achieved F1-score values of 0.956, 0.944, and 0.916 on the three datasets, surpassing the existing mainstream methods and achieving optimal results. Additionally, ablation experiments revealed the contributions of each module to the performance of the model. The introduction of virtual scene data notably boosted the performance of the risk perception model, revealing an increase in accuracy, area under curve, and F1-score by 0.4%, 1.1%, and 1.2%, respectively.ConclusionThis article is a practical application of parallel vision in the field of autonomous driving risk perception, which holds considerable importance in enhancing the risk perception capabilities of autonomous vehicles in complex traffic scenarios and ensuring the safety of autonomous driving systems.关键词:autonomous driving;parallel vision;cognitive scene graph;diffusion generation;risk perception
摘要:ObjectiveWith the rapid development of visual perception technology, autonomous driving can already be applied to simple scenarios. However, in actual complex urban road applications, especially in safety-critical scenarios such as sudden lane changes by other vehicles, the intrusion of pedestrians, and the appearance of obstacles, some challenges must still be resolved. First, most existing autonomous driving systems still use the vast majority of daily natural scenes or heuristically generated adversarial scenes for training and evaluation. Among them, safety-critical scenarios, which refer to a collection of scenes in areas where cars are in danger of collision, especially scenes involving vulnerable traffic groups such as pedestrians, play an important role in the safety performance evaluation of autonomous driving systems. However, this type of scenario generally has a low probability of occurring in the real world, and such critical scene data have long-tail distribution problems, causing data-driven autonomous driving risk perception to face technical bottlenecks. Second, creating new scenes using current scene generation methods or virtual simulation scene automatic generation frameworks based on certain rules is difficult, and the generated driving scenes are often insufficiently realistic and lack a certain degree of diversity. By contrast, the scene generation method based on the diffusion model not only fully explores the characteristics of real data and supplements the gaps in the existing collected real data, but also facilitates interpretable and controllable scene generation. In addition, the difficult problem of limited system risk perception capabilities is still encountered in safety-critical scenarios. For risk-aware safety assessment technology, traditional methods based on convolutional neural networks can achieve the simple extraction of features of each object in the scene but cannot obtain high-level semantic information, that is, the relationship between various traffic entities. Obtaining such high-level information is still challenging because most potential risks are hidden at the semantic and behavioral levels. Autonomous driving risk assessment based on traffic scene graphs has become a popular research topic in recent years. Potential risks can be effectively understood and predicted by constructing and analyzing traffic scene graphs and capturing the overall relationships and interactions in the traffic scene, providing a basis for autonomous driving. The system delivers highly accurate decision support. Starting from the visual perception of human drivers, different traffic entities have various risk impacts on autonomous vehicles. However, risk perception methods based on traffic scene graphs generally use graph convolution to iteratively update the feature representation of each node. This method ignores the importance of different types of edges between nodes during message transmission. Considering these challenges and difficulties, this paper proposes a risk-enhanced perception framework based on the parallel vision to realize the automatic generation of safety-critical scene data and examines the importance of different types of edges between adjacent traffic entities.MethodThis method is based on the interactive ACP theory and integrates descriptive, prescriptive, and predictive intelligence under a parallel vision framework to achieve vision-based enhanced risk perception. Specifically, based on descriptive and prescriptive learning, a background adaptive module and a feature fusion encoder are first introduced into the diffusion model structure, thereby reducing the boundary contours of pedestrians and improving image quality. The controllable generation of risk sequences in safety-critical scenarios can be achieved by controlling the specific locations where dangerous elements, such as pedestrians, are generated. Second, a cognitive scene graph construction method based on spatial rules is used to obtain the spatial position of each entity in the scene through target detection. Based on the spatial relative position information and setting relevant threshold information, the distance, orientation, and affiliation relationships between entities in the traffic scene are extracted. The extraction of interactive relationships is mainly based on the changes in spatial information between traffic entities over time. Finally, under the predictive learning framework, a new graph model-based risk enhancement perception method, which integrates the relational graph attention network and the Transformer encoder module, is proposed to perform spatiotemporal modeling of scene graph sequence data. The relational graph attention network (RGAT) introduces an attention mechanism, assigns different weight values to different neighborhood relationships, and obtains the feature representation of nodes through weighted summation. The temporal Transformer encoder module is used to model the temporal dynamics of scene graph sequence data, ultimately outputting risk-aware visual reasoning results.ResultExperiments were conducted on three datasets (MRSG-144, IESG, and 1043-carla-sg) to compare the performance with five mainstream risk perception methods based on graph-structured data and verify the effectiveness of the proposed method. This method achieved F1-score values of 0.956, 0.944, and 0.916 on the three datasets, surpassing the existing mainstream methods and achieving optimal results. Additionally, ablation experiments revealed the contributions of each module to the performance of the model. The introduction of virtual scene data notably boosted the performance of the risk perception model, revealing an increase in accuracy, area under curve, and F1-score by 0.4%, 1.1%, and 1.2%, respectively.ConclusionThis article is a practical application of parallel vision in the field of autonomous driving risk perception, which holds considerable importance in enhancing the risk perception capabilities of autonomous vehicles in complex traffic scenarios and ensuring the safety of autonomous driving systems.关键词:autonomous driving;parallel vision;cognitive scene graph;diffusion generation;risk perception- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveAutonomous driving planning methods currently assume the certainty of the information obtained. However, the actual situation contains a variety of uncertainties, and ignoring these uncertainties may lead to safety problems. The measurements provided by the sensors generally include the value of the state and the uncertainty of the state value, which is typically represented by the covariance matrix. At present, most planning methods do not utilize this uncertainty and choose to ignore it directly. These uncertainties will also have an impact on planning; when accumulated over time, the impact may even be sufficiently large to cause serious accidents. If a method or framework that can deal with this uncertainty is available, then additional reference information can be provided for the planning system, which will have a positive effect on driving safety. This paper aims to address a critical challenge in the field of autonomous driving: the effective consideration of uncertainty, particularly focusing on sensor measurement errors. In the complex and dynamic environment of autonomous driving, uncertainties can arise from various sources, posing substantial hurdles to accurate and safe planning. The study delves deep into understanding the intricacies of sensor measurement errors by concentrating on sensor uncertainty, which are vital components of perception systems in autonomous vehicles. The primary objective is to develop robust planning algorithms that can account for these uncertainties, ensuring that autonomous vehicles can make informed decisions even under imperfect or noisy sensor data. This research is pivotal for enhancing the reliability and safety of autonomous driving systems, ultimately paving the way for the widespread adoption of autonomous vehicles by addressing one of the key challenges in their deployment.MethodThe methodology in this article revolves around the innovative use of the grid map, a mathematical framework employed to characterize uncertainty as the occupancy probability within a grid map. The process begins by transforming the prior map into a grid map, establishing a global reference. Subsequently, the local grid map is initialized through integration with the localization system, enabling the propagation of localization uncertainty within this localized context. The computational complexity of the planning algorithm is substantially reduced by integrating localization and sensing uncertainties into the grid graph. This integration not only streamlines the planning process but also ensures the efficient and safe generation of optimal trajectories. Path planning is executed within the Frenet coordinate system, where the occupancy probability of the grid map plays a pivotal role. This comprehensive methodology not only accounts for sensor measurement errors but also provides a systematic framework for path planning, ultimately enhancing the reliability and safety of autonomous vehicles in uncertain driving environments.ResultResearch findings, validated through extensive simulation tests in the CARLA simulator, confirm the robustness of the proposed methodology. The integration of the approach with the robot operating system (ROS)-based system design, encompassing critical modules such as the map engine, path planning, and scene generation, proved pivotal in achieving these results. Specifically, the experiments demonstrated that considering localization uncertainty led to a notable improvement in the success rate across a range of obstacle avoidance scenarios. The proposed method exhibited exceptional performance, enabling smooth long-distance driving even in environments characterized by positioning uncertainty. The method not only ensured the safe navigation of the vehicle, effectively avoiding obstacles, but also achieved an impressive average arrival rate of over 90% in diverse obstacle avoidance scenarios. These compelling outcomes emphasize the effectiveness and reliability of the developed approach, positioning it as a promising solution for enhancing the safety and efficiency of autonomous vehicles in real-world driving conditions.ConclusionThis research addresses a fundamental challenge in autonomous driving by focusing on the critical aspect of sensor measurement errors, particularly localization uncertainty. The study introduces an innovative grid-map-based planning method, implemented and rigorously tested within the CARLA simulator using the ROS framework. Through meticulous experimentation, the research demonstrates that considering localization uncertainty substantially improves the success rate in various obstacle avoidance scenarios. The proposed approach enables smooth, long-distance driving under positioning uncertainty, ensuring safe obstacle avoidance, and achieving an outstanding average arrival rate of over 90% in diverse scenarios. These results highlight the efficacy and practicality of the developed methodology, demonstrating its potential for real-world application in autonomous driving systems. Through the seamless integration of localization and sensing uncertainties into the planning algorithm, this research not only enhances the reliability and safety of autonomous vehicles but also contributes valuable insights into the ongoing efforts to make autonomous driving a mainstream reality. Future research can further improve the robustness and adaptability of autonomous driving systems by combining the grid-map-based representation framework with the uncertainty of other sensors such as LiDAR and cameras. This comprehensive approach can provide a complete and accurate environmental perception of the system, thereby increasing confidence in decision-making. Researchers can effectively simulate and understand complex situations in actual driving environments by introducing the uncertainty of multiple sensors, thereby providing a reliable foundation for the safe navigation and intelligent decision-making of autonomous vehicles. This scalable research path will have substantial implications for future research on autonomous driving, providing new directions for promoting innovation and development in this field.关键词:uncertainty;autonomous driving;grid map;trajectory planning;Frenet planning;sensor error
摘要:ObjectiveAutonomous driving planning methods currently assume the certainty of the information obtained. However, the actual situation contains a variety of uncertainties, and ignoring these uncertainties may lead to safety problems. The measurements provided by the sensors generally include the value of the state and the uncertainty of the state value, which is typically represented by the covariance matrix. At present, most planning methods do not utilize this uncertainty and choose to ignore it directly. These uncertainties will also have an impact on planning; when accumulated over time, the impact may even be sufficiently large to cause serious accidents. If a method or framework that can deal with this uncertainty is available, then additional reference information can be provided for the planning system, which will have a positive effect on driving safety. This paper aims to address a critical challenge in the field of autonomous driving: the effective consideration of uncertainty, particularly focusing on sensor measurement errors. In the complex and dynamic environment of autonomous driving, uncertainties can arise from various sources, posing substantial hurdles to accurate and safe planning. The study delves deep into understanding the intricacies of sensor measurement errors by concentrating on sensor uncertainty, which are vital components of perception systems in autonomous vehicles. The primary objective is to develop robust planning algorithms that can account for these uncertainties, ensuring that autonomous vehicles can make informed decisions even under imperfect or noisy sensor data. This research is pivotal for enhancing the reliability and safety of autonomous driving systems, ultimately paving the way for the widespread adoption of autonomous vehicles by addressing one of the key challenges in their deployment.MethodThe methodology in this article revolves around the innovative use of the grid map, a mathematical framework employed to characterize uncertainty as the occupancy probability within a grid map. The process begins by transforming the prior map into a grid map, establishing a global reference. Subsequently, the local grid map is initialized through integration with the localization system, enabling the propagation of localization uncertainty within this localized context. The computational complexity of the planning algorithm is substantially reduced by integrating localization and sensing uncertainties into the grid graph. This integration not only streamlines the planning process but also ensures the efficient and safe generation of optimal trajectories. Path planning is executed within the Frenet coordinate system, where the occupancy probability of the grid map plays a pivotal role. This comprehensive methodology not only accounts for sensor measurement errors but also provides a systematic framework for path planning, ultimately enhancing the reliability and safety of autonomous vehicles in uncertain driving environments.ResultResearch findings, validated through extensive simulation tests in the CARLA simulator, confirm the robustness of the proposed methodology. The integration of the approach with the robot operating system (ROS)-based system design, encompassing critical modules such as the map engine, path planning, and scene generation, proved pivotal in achieving these results. Specifically, the experiments demonstrated that considering localization uncertainty led to a notable improvement in the success rate across a range of obstacle avoidance scenarios. The proposed method exhibited exceptional performance, enabling smooth long-distance driving even in environments characterized by positioning uncertainty. The method not only ensured the safe navigation of the vehicle, effectively avoiding obstacles, but also achieved an impressive average arrival rate of over 90% in diverse obstacle avoidance scenarios. These compelling outcomes emphasize the effectiveness and reliability of the developed approach, positioning it as a promising solution for enhancing the safety and efficiency of autonomous vehicles in real-world driving conditions.ConclusionThis research addresses a fundamental challenge in autonomous driving by focusing on the critical aspect of sensor measurement errors, particularly localization uncertainty. The study introduces an innovative grid-map-based planning method, implemented and rigorously tested within the CARLA simulator using the ROS framework. Through meticulous experimentation, the research demonstrates that considering localization uncertainty substantially improves the success rate in various obstacle avoidance scenarios. The proposed approach enables smooth, long-distance driving under positioning uncertainty, ensuring safe obstacle avoidance, and achieving an outstanding average arrival rate of over 90% in diverse scenarios. These results highlight the efficacy and practicality of the developed methodology, demonstrating its potential for real-world application in autonomous driving systems. Through the seamless integration of localization and sensing uncertainties into the planning algorithm, this research not only enhances the reliability and safety of autonomous vehicles but also contributes valuable insights into the ongoing efforts to make autonomous driving a mainstream reality. Future research can further improve the robustness and adaptability of autonomous driving systems by combining the grid-map-based representation framework with the uncertainty of other sensors such as LiDAR and cameras. This comprehensive approach can provide a complete and accurate environmental perception of the system, thereby increasing confidence in decision-making. Researchers can effectively simulate and understand complex situations in actual driving environments by introducing the uncertainty of multiple sensors, thereby providing a reliable foundation for the safe navigation and intelligent decision-making of autonomous vehicles. This scalable research path will have substantial implications for future research on autonomous driving, providing new directions for promoting innovation and development in this field.关键词:uncertainty;autonomous driving;grid map;trajectory planning;Frenet planning;sensor error- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveWith the recent advancement of vehicle-to-everything (V2X) technology, connected and automated cars (CAVs) have received remarkable attention in industry and academia. The market penetration rate (MPR) of CAVs is expected to increase substantially in the near future. Furthermore, CAV deployment scenarios, such as mixed traffic (including conventional vehicles and CAVs) on urban road networks, will become increasingly complex. Therefore, the technological demand for advanced CAV modules (e.g., sensing, perception, awareness, and motion planning) will notably increase to ensure efficiency and safety. Infrastructure-aided solutions using roadside units (RSUs) are often used to meet increasing technological demand in a complex traffic scenario. RSUs can help promote CAV deployment by providing vehicles with scalable communication, sensor, and computational support. As a general rule, V2X connectivity and CAV performance improve as the number of RSUs increases. However, the majority of existing RSUs are built in fixed locations, resulting in important concerns such as restricted deployment coverage and utilization efficiency. Furthermore, updating its capabilities (for example, developing next-generation communication technologies) is exceedingly challenging. Therefore, the necessity for flexible and intelligent resource allocation in the Transportation 5.0 era cannot be met. As an emerging technology, drones offer a viable answer to the aforementioned difficulties. To fill the technological gaps in deploying CAVs, a framework integrating drones with the existing infrastructure-aided system to assist in CAV deployment is proposed, and a dynamic on-demand operation algorithm for drones under the framework considering sensing and communication tasks is introduced.MethodThe on-demand operation approach, which involves deploying drones to perform sensing and communication tasks, is introduced to verify the feasibility of the proposed framework. The operation of drones is based on a bi-level approach, where the upper level corresponds to task planning in a discrete-time dimension and the lower level corresponds to motion planning with a finer time granularity. In this approach, the upper level sets performance constraints for the lower level during task planning, while the upper level assesses the feasibility of these constraints and performs corresponding motion planning. A continuous feedback loop exists between the levels in the hierarchical structure of drone operations to ensure coordination between the upper and lower levels.The details of the deployment method at the upper level, which aims to deploy drones in an efficient and cost-effective manner, are described. Additionally, the motion planning of the drones at the lower level based on the virtual force field model is introduced in response to dynamic sensing and communication demand. The lower level of the operation approach models the demands for optimal coverage as a virtual force field. The force field includes two kinds of virtual forces: the attractive force toward CAVs is introduced to facilitate the precise deployment of drones to cover the sensing and communication demands of CAVs. Meanwhile, the repulsive forces push away two drones between which the distance is closer than the desired value. Each drone then follows this force field to move toward its proper position.ResultExperiments and analyses are conducted to demonstrate the feasibility of the proposed framework in a simulated traffic network with fixed RSU and dynamic CAV distributions with different MPRs. A series of experiments, which set the time step of the update frequency to 10 min, is also conducted to validate the deployment efficacy of the bi-level deployment algorithm. Utilizing experiment settings as the basis, the distribution of CAV on road segments in the network is generated with different MPRs. The sensing and communication demands of CAVs in accordance with the penetration rate are estimated. The interaction probability between CAVs and human-driven vehicles (HDVs) is estimated using numerical simulations and Monte Carlo-based statistical analysis. The number of interactions between CAVs and HDVs in this network initially rises and reaches its peak at 50% as the penetration rate of CAVs increases. When the penetration rate exceeds 20%, a single RSU with peak data rates of 650 Mbps is no longer sufficient to meet the communication demand on the road segment during peak hours. The results indicate that employing drones instead of RSUs to support autonomous driving perception and communication enables the accomplishment of additional perception and communication tasks within limited quantities and time constraints due to the dynamic distribution of CAV demands, which demonstrate substantial fluctuation within a day. The results of the deployment algorithm indicate that if a traditional vehicle-infrastructure(VI) solution is employed by installing RSUs for each target location on the demand list, then an idle rate of more than 60% is obtained for the RSUs. Specifically, the idle rates of RSUs in the VI framework are calculated with an MPR of 10%, 50%, and 90%, and the temporal variation of the idle rates in the target area is compared. Integrating drones into the current VI framework and adopting an on-demand operation approach show potential for reducing idle rates.ConclusionOverall, this paper proposes a novel framework to boost CAV deployment in mixed traffic scenarios by adopting drones in the existing infrastructure-aided system. The proposed framework shows its potential to boost CAV deployment in a flexible, intelligent, and cost-efficient manner. The simulation experiments indicate that the framework facilitates improved communication coverage and alleviates congestion issues.关键词:autonomous driving;cross-domain collaboration;on-demand scheduling of drones;bi-level scheduling algorithm;trajectory planning based on virtual force field
摘要:ObjectiveWith the recent advancement of vehicle-to-everything (V2X) technology, connected and automated cars (CAVs) have received remarkable attention in industry and academia. The market penetration rate (MPR) of CAVs is expected to increase substantially in the near future. Furthermore, CAV deployment scenarios, such as mixed traffic (including conventional vehicles and CAVs) on urban road networks, will become increasingly complex. Therefore, the technological demand for advanced CAV modules (e.g., sensing, perception, awareness, and motion planning) will notably increase to ensure efficiency and safety. Infrastructure-aided solutions using roadside units (RSUs) are often used to meet increasing technological demand in a complex traffic scenario. RSUs can help promote CAV deployment by providing vehicles with scalable communication, sensor, and computational support. As a general rule, V2X connectivity and CAV performance improve as the number of RSUs increases. However, the majority of existing RSUs are built in fixed locations, resulting in important concerns such as restricted deployment coverage and utilization efficiency. Furthermore, updating its capabilities (for example, developing next-generation communication technologies) is exceedingly challenging. Therefore, the necessity for flexible and intelligent resource allocation in the Transportation 5.0 era cannot be met. As an emerging technology, drones offer a viable answer to the aforementioned difficulties. To fill the technological gaps in deploying CAVs, a framework integrating drones with the existing infrastructure-aided system to assist in CAV deployment is proposed, and a dynamic on-demand operation algorithm for drones under the framework considering sensing and communication tasks is introduced.MethodThe on-demand operation approach, which involves deploying drones to perform sensing and communication tasks, is introduced to verify the feasibility of the proposed framework. The operation of drones is based on a bi-level approach, where the upper level corresponds to task planning in a discrete-time dimension and the lower level corresponds to motion planning with a finer time granularity. In this approach, the upper level sets performance constraints for the lower level during task planning, while the upper level assesses the feasibility of these constraints and performs corresponding motion planning. A continuous feedback loop exists between the levels in the hierarchical structure of drone operations to ensure coordination between the upper and lower levels.The details of the deployment method at the upper level, which aims to deploy drones in an efficient and cost-effective manner, are described. Additionally, the motion planning of the drones at the lower level based on the virtual force field model is introduced in response to dynamic sensing and communication demand. The lower level of the operation approach models the demands for optimal coverage as a virtual force field. The force field includes two kinds of virtual forces: the attractive force toward CAVs is introduced to facilitate the precise deployment of drones to cover the sensing and communication demands of CAVs. Meanwhile, the repulsive forces push away two drones between which the distance is closer than the desired value. Each drone then follows this force field to move toward its proper position.ResultExperiments and analyses are conducted to demonstrate the feasibility of the proposed framework in a simulated traffic network with fixed RSU and dynamic CAV distributions with different MPRs. A series of experiments, which set the time step of the update frequency to 10 min, is also conducted to validate the deployment efficacy of the bi-level deployment algorithm. Utilizing experiment settings as the basis, the distribution of CAV on road segments in the network is generated with different MPRs. The sensing and communication demands of CAVs in accordance with the penetration rate are estimated. The interaction probability between CAVs and human-driven vehicles (HDVs) is estimated using numerical simulations and Monte Carlo-based statistical analysis. The number of interactions between CAVs and HDVs in this network initially rises and reaches its peak at 50% as the penetration rate of CAVs increases. When the penetration rate exceeds 20%, a single RSU with peak data rates of 650 Mbps is no longer sufficient to meet the communication demand on the road segment during peak hours. The results indicate that employing drones instead of RSUs to support autonomous driving perception and communication enables the accomplishment of additional perception and communication tasks within limited quantities and time constraints due to the dynamic distribution of CAV demands, which demonstrate substantial fluctuation within a day. The results of the deployment algorithm indicate that if a traditional vehicle-infrastructure(VI) solution is employed by installing RSUs for each target location on the demand list, then an idle rate of more than 60% is obtained for the RSUs. Specifically, the idle rates of RSUs in the VI framework are calculated with an MPR of 10%, 50%, and 90%, and the temporal variation of the idle rates in the target area is compared. Integrating drones into the current VI framework and adopting an on-demand operation approach show potential for reducing idle rates.ConclusionOverall, this paper proposes a novel framework to boost CAV deployment in mixed traffic scenarios by adopting drones in the existing infrastructure-aided system. The proposed framework shows its potential to boost CAV deployment in a flexible, intelligent, and cost-efficient manner. The simulation experiments indicate that the framework facilitates improved communication coverage and alleviates congestion issues.关键词:autonomous driving;cross-domain collaboration;on-demand scheduling of drones;bi-level scheduling algorithm;trajectory planning based on virtual force field- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveSafety is the most important consideration for autonomous driving vehicles. New autonomous driving methods need numerous training and testing processes before their application in real vehicles. However, training and testing autonomous driving methods directly in real-world scenarios is a costly and risky task. Many researchers first train and test their methods in simulated-world scenarios and then transfer the trained knowledge to real-world scenarios. However, many differences in scene modeling, light, and vehicle dynamics are observed between the two-world scenarios. Therefore, the autonomous driving model trained in simulated-world scenarios cannot be effectively generalized to real-world scenarios. With the development of deep learning technologies, image translation, which aims to transform the content of an image from one presentation form to another, has made considerable achievements in many fields, such as image beautification, style transfer, scene design, and video special effects. If image translation technology is applied to the translation of simulated driving scenarios to real ones, then this technology can not only solve the problem of poor generalization capability of autonomous driving models but can also effectively reduce the cost and risk of training in the real scenarios. Unfortunately, existing image translation methods applied in autonomous driving lack datasets of paired simulated and real scenarios, and most of the mainstream image translation methods are based on generative adversarial network (GAN), which have problems of mode collapse and unstable training. The generated images also suffer from numerous detail problems, such as distorted object contours and unnatural small objects in the scene. These problems will not only further affect the perception of automatic driving, which will then impact the decision regarding automatic driving, but will also influence the evaluation metrics of image translation. In this paper, a multimodal conditional diffusion model based on the denoising diffusion probabilistic model (DDPM), which has achieved remarkable success in various image generation tasks, is proposed to address the problems of insufficient paired simulation-real data, mode collapse, unstable training, and inadequate diversity of generated data in existing image translation.MethodFirst, an image translation method based on the diffusion model with good training stability and generative diversity is proposed to solve the problems of mode collapse and unstable training in existing mainstream image translation methods based on GAN. Second, a multimodal feature fusion method based on a multihead self-attention mechanism is developed in this paper to address the problem of traditional diffusion models, which cannot integrate prior information without controlling the image generation process. The proposed method can send the early fused data to the convolutional layer, extract the high-level features, and then obtain the high-level fused feature vectors through the multihead self-attention mechanism. Finally, considering the semantic segmentation and depth maps, which can precisely represent the contour and depth information, respectively, the conditional diffusion model (CDM) is designed by fusing the semantic segmentation and depth maps with the noise image before sending them to the denoising network. In this model, the semantic segmentation map, depth map, and noise image can perceive each other through the proposed multimodal feature fusion method. The output fusion features will then be fed to the next sublayer in the network. After the denoising iterative process, the final output of the denoising network contains semantic and depth information; thus, the semantic segmentation and depth maps can play a conditional guiding role in the diffusion model. According to the settings in the DDPM, the U-Net network is utilized as the denoising network. Compared with the U-Net in DDPM, the self-attention layer is modified to match the improved self-attention proposed in this paper for effectively learning the fusion features. The proposed model can be applied to the image translation of simulated-to-real scenarios after training the denoising network in the CDM. Noise is first added to the simulated images collected from the Carla simulator, and paired semantic segmentation and depth maps are then sent to the denoising network to perform a step-by-step denoising process. Finally, real driving scene images are obtained to realize image translation with highly precise contour details and consistent distance in simulated and real images.ResultThe model is trained on the Cityscapes dataset and compared with state-of-the-art (SOTA) methods in recent years. Experimental results indicate that the proposed approach achieves a superior translation result with improved semantic precision and additional contour details. The evaluation metrics include Fréchet inception distance (FID) and the learned perceptual image patch similarity (LPIPS), which indicate the similarity between the generated and original images, and the difference between the generated images, respectively. A lower FID score represents better generation quality with a smaller gap between the generated and real image distributions, while a higher LPIPS value indicates better generation diversity. Compared with the comparative SOTA methods, the proposed method can achieve better results in the FID and LPIPS indicators, revealing scores of 44.20 and 0.377, respectively.ConclusionIn this paper, a novel image-to-image translation method based on a conditional diffusion model and a multimodal fusion method with a multihead attention mechanism for autonomous driving scenarios are proposed. Experimental results show that the proposed method can effectively solve the problems of insufficient paired datasets, imprecise translation results, unstable training, and insufficient generation diversity in existing image translation methods. Thus, this method improves the image translation precision of driving scenarios and provides theoretical support and a data basis to realize safe and practical autonomous driving systems.关键词:simulation to reality;image translation;diffusion model;multi-modal fusion;driving scenario
摘要:ObjectiveSafety is the most important consideration for autonomous driving vehicles. New autonomous driving methods need numerous training and testing processes before their application in real vehicles. However, training and testing autonomous driving methods directly in real-world scenarios is a costly and risky task. Many researchers first train and test their methods in simulated-world scenarios and then transfer the trained knowledge to real-world scenarios. However, many differences in scene modeling, light, and vehicle dynamics are observed between the two-world scenarios. Therefore, the autonomous driving model trained in simulated-world scenarios cannot be effectively generalized to real-world scenarios. With the development of deep learning technologies, image translation, which aims to transform the content of an image from one presentation form to another, has made considerable achievements in many fields, such as image beautification, style transfer, scene design, and video special effects. If image translation technology is applied to the translation of simulated driving scenarios to real ones, then this technology can not only solve the problem of poor generalization capability of autonomous driving models but can also effectively reduce the cost and risk of training in the real scenarios. Unfortunately, existing image translation methods applied in autonomous driving lack datasets of paired simulated and real scenarios, and most of the mainstream image translation methods are based on generative adversarial network (GAN), which have problems of mode collapse and unstable training. The generated images also suffer from numerous detail problems, such as distorted object contours and unnatural small objects in the scene. These problems will not only further affect the perception of automatic driving, which will then impact the decision regarding automatic driving, but will also influence the evaluation metrics of image translation. In this paper, a multimodal conditional diffusion model based on the denoising diffusion probabilistic model (DDPM), which has achieved remarkable success in various image generation tasks, is proposed to address the problems of insufficient paired simulation-real data, mode collapse, unstable training, and inadequate diversity of generated data in existing image translation.MethodFirst, an image translation method based on the diffusion model with good training stability and generative diversity is proposed to solve the problems of mode collapse and unstable training in existing mainstream image translation methods based on GAN. Second, a multimodal feature fusion method based on a multihead self-attention mechanism is developed in this paper to address the problem of traditional diffusion models, which cannot integrate prior information without controlling the image generation process. The proposed method can send the early fused data to the convolutional layer, extract the high-level features, and then obtain the high-level fused feature vectors through the multihead self-attention mechanism. Finally, considering the semantic segmentation and depth maps, which can precisely represent the contour and depth information, respectively, the conditional diffusion model (CDM) is designed by fusing the semantic segmentation and depth maps with the noise image before sending them to the denoising network. In this model, the semantic segmentation map, depth map, and noise image can perceive each other through the proposed multimodal feature fusion method. The output fusion features will then be fed to the next sublayer in the network. After the denoising iterative process, the final output of the denoising network contains semantic and depth information; thus, the semantic segmentation and depth maps can play a conditional guiding role in the diffusion model. According to the settings in the DDPM, the U-Net network is utilized as the denoising network. Compared with the U-Net in DDPM, the self-attention layer is modified to match the improved self-attention proposed in this paper for effectively learning the fusion features. The proposed model can be applied to the image translation of simulated-to-real scenarios after training the denoising network in the CDM. Noise is first added to the simulated images collected from the Carla simulator, and paired semantic segmentation and depth maps are then sent to the denoising network to perform a step-by-step denoising process. Finally, real driving scene images are obtained to realize image translation with highly precise contour details and consistent distance in simulated and real images.ResultThe model is trained on the Cityscapes dataset and compared with state-of-the-art (SOTA) methods in recent years. Experimental results indicate that the proposed approach achieves a superior translation result with improved semantic precision and additional contour details. The evaluation metrics include Fréchet inception distance (FID) and the learned perceptual image patch similarity (LPIPS), which indicate the similarity between the generated and original images, and the difference between the generated images, respectively. A lower FID score represents better generation quality with a smaller gap between the generated and real image distributions, while a higher LPIPS value indicates better generation diversity. Compared with the comparative SOTA methods, the proposed method can achieve better results in the FID and LPIPS indicators, revealing scores of 44.20 and 0.377, respectively.ConclusionIn this paper, a novel image-to-image translation method based on a conditional diffusion model and a multimodal fusion method with a multihead attention mechanism for autonomous driving scenarios are proposed. Experimental results show that the proposed method can effectively solve the problems of insufficient paired datasets, imprecise translation results, unstable training, and insufficient generation diversity in existing image translation methods. Thus, this method improves the image translation precision of driving scenarios and provides theoretical support and a data basis to realize safe and practical autonomous driving systems.关键词:simulation to reality;image translation;diffusion model;multi-modal fusion;driving scenario- 2
- |
- 0
- |
- 0
发布时间:2024-11-16
Parallel decision intelligence for unmanned systems

-
 摘要:Within the various subfields of computer vision, human pose estimation stands out as an interesting area of research. This estimation aims to precisely localize body parts or keypoints of the human instance from a given image or video and reconstruct the skeleton structure of the human body. Human pose estimation offers technical support for various applications, such as human pose tracking, human action recognition, person re-identification, human-object interactions, and person image generation. The uses of human pose estimation span across entertainment (such as virtual reality, augmented reality, and animation), health (such as healthcare and sports), and security (such as surveillance). Consequently, high-performance and real-time human pose estimation have emerged as prominent focus areas in current computer vision research. Extensive research on human pose estimation methods has been conducted in recent years. A part of the research focuses on developing and refining high-performance or lightweight network architectures. Notable examples include Hourglass, SimpleBaseline, high resolution net(HRNet), and Lite-HRNet. These architectures have found broad utility in various visual tasks, including object detection and instance segmentation. Another facet of research is dedicated to introducing innovative pose encoding and decoding schemes. These novel schemes are intended to construct accurate and robust human pose estimation models. The encoding and decoding processes for human pose estimation represent a pivotal stage in extracting features from the input data and translating this information into comprehensible human poses. The encoding process primarily involves extracting features from the initial input data and molding them into an intermediate representation. This intermediate form, which could be feature maps or latent vectors, simplifies processing and comprehension; the subsequent decoding process retrieves the ultimate human pose from this encoded structure. Despite the considerable progress made in current research on human pose estimation, the issue of ambiguity remains a major obstacle in real-world scenarios. Diverse poses might be mapped to similar or overlapping low-dimensional representations, primarily due to variables such as illumination, motion blur, occlusions, complex poses, perspective, and resolution. This approach leads to ambiguous and uncertain resultant poses, constituting the ambiguity challenge in human pose estimation. This challenge encompasses distributive, scale, and associative ambiguity. For example, in scenarios where a hand is obscured, the precise location of the wrist becomes uncertain, thus yielding distributive ambiguity. Second, the scale of the body in the image diminishes when the camera is positioned farther from the human instance, often making it difficult to ascertain the accurate scale without ample contextual details, leading to scale ambiguity. Third, precisely assigning the identified keypoints to corresponding human instances becomes intricate when two human instances obscure each other, thereby introducing associative ambiguity. The well-designed methods for encoding and decoding human poses enable the suitable modeling and solving of human pose estimation. These methods provide effective optimization objectives and feature representations for the model, allowing for the construction of highly reasonable and robust human pose estimation models. Therefore, investigating encoding and decoding for human pose estimation carries substantial importance for research. The majority of past review papers on human pose estimation have primarily focused on the design of network structures, while the ambiguity problem can markedly influence the performance of human pose estimation. The objective is to provide a summarized analysis of the current research on pose encoding and decoding methods. This analysis will encompass a thorough investigation of the inherent ambiguity challenge associated with human pose estimation. In this paper, human pose modeling techniques are first introduced, which directly impact the potential for expressive human pose representation. Second, the pose encoding and decoding methods are categorized into distributive, scale, and associative ambiguity. Three strategies are explored to address distributive ambiguity: distributive, structural, and iterative constraints. The scale ambiguity is further refined into the keypoint- and pixel-wise scale ambiguity problem. The former is mainly addressed through representative-based methods, and the latter can be solved using unbiased and integral-based methods. Possible approaches for associative ambiguity can be categorized into the following four groups: graph-, limb-, center-, and embedding-based methods. These diverse methods provide multiple potential solutions for dealing with associative ambiguity. A summary and performance comparison of the methods used for encoding and decoding human poses are provided to help understand the strengths and limitations of each approach. Finally, potential directions for future development are elucidated. This paper aims to establish a novel research trajectory for researchers: addressing the ambiguity problem in human pose estimation through encoding and decoding. The resolution of ambiguity challenges in human pose estimation is expected to broaden its potential applications.关键词:deep learning;human pose estimation;ambiguity problem;human pose encoding and decoding;human pose modeling
摘要:Within the various subfields of computer vision, human pose estimation stands out as an interesting area of research. This estimation aims to precisely localize body parts or keypoints of the human instance from a given image or video and reconstruct the skeleton structure of the human body. Human pose estimation offers technical support for various applications, such as human pose tracking, human action recognition, person re-identification, human-object interactions, and person image generation. The uses of human pose estimation span across entertainment (such as virtual reality, augmented reality, and animation), health (such as healthcare and sports), and security (such as surveillance). Consequently, high-performance and real-time human pose estimation have emerged as prominent focus areas in current computer vision research. Extensive research on human pose estimation methods has been conducted in recent years. A part of the research focuses on developing and refining high-performance or lightweight network architectures. Notable examples include Hourglass, SimpleBaseline, high resolution net(HRNet), and Lite-HRNet. These architectures have found broad utility in various visual tasks, including object detection and instance segmentation. Another facet of research is dedicated to introducing innovative pose encoding and decoding schemes. These novel schemes are intended to construct accurate and robust human pose estimation models. The encoding and decoding processes for human pose estimation represent a pivotal stage in extracting features from the input data and translating this information into comprehensible human poses. The encoding process primarily involves extracting features from the initial input data and molding them into an intermediate representation. This intermediate form, which could be feature maps or latent vectors, simplifies processing and comprehension; the subsequent decoding process retrieves the ultimate human pose from this encoded structure. Despite the considerable progress made in current research on human pose estimation, the issue of ambiguity remains a major obstacle in real-world scenarios. Diverse poses might be mapped to similar or overlapping low-dimensional representations, primarily due to variables such as illumination, motion blur, occlusions, complex poses, perspective, and resolution. This approach leads to ambiguous and uncertain resultant poses, constituting the ambiguity challenge in human pose estimation. This challenge encompasses distributive, scale, and associative ambiguity. For example, in scenarios where a hand is obscured, the precise location of the wrist becomes uncertain, thus yielding distributive ambiguity. Second, the scale of the body in the image diminishes when the camera is positioned farther from the human instance, often making it difficult to ascertain the accurate scale without ample contextual details, leading to scale ambiguity. Third, precisely assigning the identified keypoints to corresponding human instances becomes intricate when two human instances obscure each other, thereby introducing associative ambiguity. The well-designed methods for encoding and decoding human poses enable the suitable modeling and solving of human pose estimation. These methods provide effective optimization objectives and feature representations for the model, allowing for the construction of highly reasonable and robust human pose estimation models. Therefore, investigating encoding and decoding for human pose estimation carries substantial importance for research. The majority of past review papers on human pose estimation have primarily focused on the design of network structures, while the ambiguity problem can markedly influence the performance of human pose estimation. The objective is to provide a summarized analysis of the current research on pose encoding and decoding methods. This analysis will encompass a thorough investigation of the inherent ambiguity challenge associated with human pose estimation. In this paper, human pose modeling techniques are first introduced, which directly impact the potential for expressive human pose representation. Second, the pose encoding and decoding methods are categorized into distributive, scale, and associative ambiguity. Three strategies are explored to address distributive ambiguity: distributive, structural, and iterative constraints. The scale ambiguity is further refined into the keypoint- and pixel-wise scale ambiguity problem. The former is mainly addressed through representative-based methods, and the latter can be solved using unbiased and integral-based methods. Possible approaches for associative ambiguity can be categorized into the following four groups: graph-, limb-, center-, and embedding-based methods. These diverse methods provide multiple potential solutions for dealing with associative ambiguity. A summary and performance comparison of the methods used for encoding and decoding human poses are provided to help understand the strengths and limitations of each approach. Finally, potential directions for future development are elucidated. This paper aims to establish a novel research trajectory for researchers: addressing the ambiguity problem in human pose estimation through encoding and decoding. The resolution of ambiguity challenges in human pose estimation is expected to broaden its potential applications.关键词:deep learning;human pose estimation;ambiguity problem;human pose encoding and decoding;human pose modeling- 2
- |
- 0
- |
- 0
发布时间:2024-11-16
Review
-
 摘要:ObjectiveWith the rapid development of deep learning technology, the task of handwritten Chinese character recognition (HCCR) has made breakthrough progress. Initially, text recognition research focused primarily on the recognition of English characters and numbers. However, with the deepening of artificial intelligence technology, numerous researchers have begun to focus on the field of Chinese character recognition. In recent years, Chinese character recognition has been widely used in several application scenarios and currently has a wide range of application scenarios in the fields of bank bill recognition, mail sorting, and office automation. Chinese characters are the most widely used language in the world with the richest information meaning and are an important language carrier for people’s communication. Therefore, the research on Chinese character recognition has a crucial value. However, despite these advancements, the recognition of irregular handwritten Chinese characters remains a challenging task. Handwritten Chinese characters are often influenced by various calligraphic styles and individual writing habits, leading to notable deviations from regular printed fonts. These variations can result in considerable differences in the overall structure of characters within the same category. Therefore, recognition models trained on these regular datasets may struggle to accurately identify irregularly handwritten Chinese characters encountered in real-world scenarios. For example, when sending a picture to WeChat, the text in the picture may involve sensitive words. During the identification of words by the text recognition engine, if these words are regular writing, then the engine can accurately identify and filter these sensitive words. However, some people intentionally avoid the identification of the text recognition engine due to irregular handwriting to circumvent regulation; thus, the search engine cannot recognize these words. Therefore, the research on the recognition of irregular handwritten Chinese characters is of considerable importance and can be applied in the fields of information security and filtering.MethodThe dataset of irregular handwritten Chinese characters can be classified into the following types: missing or wrong order of strokes, problems with the connection or separation of strokes, maliciously enlarged or shrunken radicals, serious distortion of the character shape, saki change of the form, and excessive horizontal and vertical amplitudes, resulting in misplacement of the entire spatial structure of the characters and easily leading to ambiguities and misinterpretations. This paper collects the first irregular handwritten Chinese character dataset (IHCCD), which currently contains a total of 3 755 categories with 30 samples for each category to promote the research work on the recognition of irregular handwritten Chinese characters. In the experiment, the first 20 samples were used as training samples, and the next 10 samples were used as test samples. IHCCD is performed by different irregular handwriters who handwrite on A4 printing paper and use a scanner as the input device to convert handwritten character samples into digital image samples. These irregular handwriters do not need to write exactly according to the regular Chinese character stroke order during the dataset collection process. They can freely adjust the stroke thickness, length, and position and enlarge or reduce the radicals arbitrarily. Moreover, they can change the tilt of the Chinese characters, resulting in distorted shapes and misaligned spatial structures, bypassing the current text recognition engine. A series of image processing techniques must be adopted for the collected dataset of irregular handwritten Chinese characters. These image processing techniques, including image skew correction, single character segmentation, Otsu binarization, and character normalization, must be adopted to construct the IHCCD dataset.ResultIn this paper, detailed experiments were conducted on the IHCCD and CASIA-HWDB1.1 datasets to compare the recognition performance of the classical network models, such as ResNet, CBAM-ResNet, Vision Transformer, and Swin Transformer, under different experimental settings., and the experimental results show that although the above classical network models can achieve good performance on the canonically written CASIA-HWDB1.1 dataset. Among them, Swin Transformer achieves the highest accuracy of 95.31% on the CASIA-HWDB1.1 dataset, but the network model trained using the CASIA-HWDB1.1 training set has poor recognition results on the IHCCD test set, and the highest accuracy can only reach 30.20%. After adding the IHCCD training set, the recognition performance of all the classical models on the IHCCD test set is markedly improved, and the highest accuracy can only reach 30.20%,showing that the IHCCD dataset is crucial for the study of irregular written Chinese character recognition.ConclusionThe existing optical character recognition(OCR) recognition models still have limitations, and the dataset collected in this paper can effectively enhance the generalization performance of the recognition models. However, even for the Swin Transformer model, which has the best performance, a large gap still exists between the recognition accuracy of irregular written Chinese characters and that of regular written Chinese characters, which requires researchers to conduct further in-depth study on this problem. Link to download this dataset:https://pan.baidu.com/s/1PtcfWj3yUSz68o2ZzvPJOQ?pwd=66Y7.关键词:irregular writing;handwritten Chinese character recognition(HCCR);IHCCD dataset;deep learning;classical classification model
摘要:ObjectiveWith the rapid development of deep learning technology, the task of handwritten Chinese character recognition (HCCR) has made breakthrough progress. Initially, text recognition research focused primarily on the recognition of English characters and numbers. However, with the deepening of artificial intelligence technology, numerous researchers have begun to focus on the field of Chinese character recognition. In recent years, Chinese character recognition has been widely used in several application scenarios and currently has a wide range of application scenarios in the fields of bank bill recognition, mail sorting, and office automation. Chinese characters are the most widely used language in the world with the richest information meaning and are an important language carrier for people’s communication. Therefore, the research on Chinese character recognition has a crucial value. However, despite these advancements, the recognition of irregular handwritten Chinese characters remains a challenging task. Handwritten Chinese characters are often influenced by various calligraphic styles and individual writing habits, leading to notable deviations from regular printed fonts. These variations can result in considerable differences in the overall structure of characters within the same category. Therefore, recognition models trained on these regular datasets may struggle to accurately identify irregularly handwritten Chinese characters encountered in real-world scenarios. For example, when sending a picture to WeChat, the text in the picture may involve sensitive words. During the identification of words by the text recognition engine, if these words are regular writing, then the engine can accurately identify and filter these sensitive words. However, some people intentionally avoid the identification of the text recognition engine due to irregular handwriting to circumvent regulation; thus, the search engine cannot recognize these words. Therefore, the research on the recognition of irregular handwritten Chinese characters is of considerable importance and can be applied in the fields of information security and filtering.MethodThe dataset of irregular handwritten Chinese characters can be classified into the following types: missing or wrong order of strokes, problems with the connection or separation of strokes, maliciously enlarged or shrunken radicals, serious distortion of the character shape, saki change of the form, and excessive horizontal and vertical amplitudes, resulting in misplacement of the entire spatial structure of the characters and easily leading to ambiguities and misinterpretations. This paper collects the first irregular handwritten Chinese character dataset (IHCCD), which currently contains a total of 3 755 categories with 30 samples for each category to promote the research work on the recognition of irregular handwritten Chinese characters. In the experiment, the first 20 samples were used as training samples, and the next 10 samples were used as test samples. IHCCD is performed by different irregular handwriters who handwrite on A4 printing paper and use a scanner as the input device to convert handwritten character samples into digital image samples. These irregular handwriters do not need to write exactly according to the regular Chinese character stroke order during the dataset collection process. They can freely adjust the stroke thickness, length, and position and enlarge or reduce the radicals arbitrarily. Moreover, they can change the tilt of the Chinese characters, resulting in distorted shapes and misaligned spatial structures, bypassing the current text recognition engine. A series of image processing techniques must be adopted for the collected dataset of irregular handwritten Chinese characters. These image processing techniques, including image skew correction, single character segmentation, Otsu binarization, and character normalization, must be adopted to construct the IHCCD dataset.ResultIn this paper, detailed experiments were conducted on the IHCCD and CASIA-HWDB1.1 datasets to compare the recognition performance of the classical network models, such as ResNet, CBAM-ResNet, Vision Transformer, and Swin Transformer, under different experimental settings., and the experimental results show that although the above classical network models can achieve good performance on the canonically written CASIA-HWDB1.1 dataset. Among them, Swin Transformer achieves the highest accuracy of 95.31% on the CASIA-HWDB1.1 dataset, but the network model trained using the CASIA-HWDB1.1 training set has poor recognition results on the IHCCD test set, and the highest accuracy can only reach 30.20%. After adding the IHCCD training set, the recognition performance of all the classical models on the IHCCD test set is markedly improved, and the highest accuracy can only reach 30.20%,showing that the IHCCD dataset is crucial for the study of irregular written Chinese character recognition.ConclusionThe existing optical character recognition(OCR) recognition models still have limitations, and the dataset collected in this paper can effectively enhance the generalization performance of the recognition models. However, even for the Swin Transformer model, which has the best performance, a large gap still exists between the recognition accuracy of irregular written Chinese characters and that of regular written Chinese characters, which requires researchers to conduct further in-depth study on this problem. Link to download this dataset:https://pan.baidu.com/s/1PtcfWj3yUSz68o2ZzvPJOQ?pwd=66Y7.关键词:irregular writing;handwritten Chinese character recognition(HCCR);IHCCD dataset;deep learning;classical classification model- 2
- |
- 0
- |
- 0
发布时间:2024-11-16
Dataset
-
 摘要:ObjectiveAdverse weather conditions, such as the presence of haze, along with the absorption and scattering of light by atmospheric particles, as well as insufficient and colored artificial light sources, pose a series of challenges for nighttime image dehazing. These challenges include hazing, low illumination, and color deviations, resulting in substantial degradation of images obtained by intelligent image capture systems. Consequently, the demand for advanced nighttime image processing technology continues to rise. At present, traditional nighttime dehazing methods are generally tailored for specific situations involving phenomena such as glow or low illuminance without considering various factors found in nighttime images, including low-illumination conditions, color discrepancies, and image blurring. This limitation leads to subpar performance when handling complex nighttime scenes. Meanwhile, most nighttime dehazing methods build upon daytime dehazing techniques as their foundation. However, daytime dehazing methods often overlook the impact of artificial light sources. Consequently, these methods can result in color distortions and insufficient brightness when applied directly to nighttime images. Furthermore, deep learning-based methods for nighttime image dehazing demand a substantial volume of training data and high-performance computing resources to achieve visually pleasing results. However, neglecting the fundamental principles of image formation in hazy conditions results in diminished interpretability of their results. A nighttime image dehazing method based on transmittance correction and layered optimization is presented to address the aforementioned challenge. On the one hand, the atmospheric light function is used to model nighttime scenes, while the non-uniform distribution of nighttime atmospheric light is considered to correct the transmittance. On the other hand, the structure and texture are optimized in layers to solve problems such as color deviation and low illumination.MethodFirst, a novel transmittance correction method is introduced. This method establishes clear initial transmittance maps by setting maximum and minimum boundary values through boundary constraints. Subsequently, compensation and normalization are conducted based on whether the initial transmittance map corresponds to the light source area of the image. This process ensures the relevance and effectiveness of dehazing, resulting in the final transmittance map. Haze is concentrated on the haze line within the RGB color space and can be precisely mapped onto the gray component of the Y channel in the YUV color space. This relationship between the Y channel and haze is leveraged to obtain the final atmospheric light map. This approach is achieved by employing the quadratic Gaussian filtering method, which involves conducting an initial Gaussian filter on the Y channel to extract relevant information and applying a second Gaussian filter to all channels. Afterward, image dehazing is accomplished by utilizing the two resulting maps obtained via the nighttime imaging model. Second, a STAR model based on the YUV color space (STAR-YUV) is introduced. This model decomposes the Y channels, which can reflect the lighting information of each component, into structural and texture layers and enhances the image features accordingly. For structural layers with rich color information, gamma correction is applied for illumination compensation, and MSRCR color correction is used to effectively correct color deviations, obtaining natural color output. For texture layers with rich detail information, Laplacian Gaussian filters are employed to enrich and sharpen complex details while preserving image edges and texture information, resulting in detail enhancement output. Finally, a novel two-stage nighttime image fusion method is introduced to achieve a superior visual result and integrate the previous two steps. In the first stage, a nonlinear fusion approach is employed on the structural and texture layers to preserve structural details and fine features, respectively, based on the principles of the Retinex theory. In the second stage, a linear fusion method is applied to merge the dehazing results with the outcomes of the first stage, thereby leveraging the advantages of dehazing and image enhancement to generate a high-quality and visually appealing final image. Considering the distinctive characteristics of nighttime images and addressing the limitations of existing approaches, this method consolidates the transmittance correction method for transmittance compensation with structural and textural optimization, thereby offering a highly effective solution for enhancing nighttime images.ResultBased on theoretical analysis and extensive experiments conducted on two distinct test datasets, the proposed algorithm is shown to achieve dehazing of nighttime images. On the ZS330 test dataset images, the visual quality of the processed images was improved, with the average values of AG, IE, and NIQE indicators reaching 7.836, 7.461, and 2.683, respectively. On the HC770 test dataset images, the processed images also exhibited better performance, with PSNR, SSIM, AG, IE, and NIQE indicators reaching 17.024 dB, 0.765, 7.371, 7.595, and 2.702, respectively. Across the entire test dataset, the average PSNR, SSIM, AG, IE, and NIQE indicators reached 17.024 dB, 0.765, 7.604, 7.528, and 2.693, respectively. Compared to traditional and deep learning-based algorithms used in the paper, this approach consistently ranks among the top performers across various indicators. The proposed algorithm displays strong performance in restoring image details, preserving naturalness, and effectively addressing severe color deviations commonly observed in nighttime images. Additionally, the algorithm demonstrates robustness by effectively enhancing images in scenarios with or without artificial light sources.ConclusionThis approach combines a novel transmittance correction method with structural and texture layer optimization. Leveraging the strengths of the two methods has resulted in advancements in restoring the clarity of nighttime images, improving lighting conditions, correcting color deviations, and preserving intricate details.关键词:nighttime image dehazing;transmittance correction method;structure and texture optimization;two stages;image fusion
摘要:ObjectiveAdverse weather conditions, such as the presence of haze, along with the absorption and scattering of light by atmospheric particles, as well as insufficient and colored artificial light sources, pose a series of challenges for nighttime image dehazing. These challenges include hazing, low illumination, and color deviations, resulting in substantial degradation of images obtained by intelligent image capture systems. Consequently, the demand for advanced nighttime image processing technology continues to rise. At present, traditional nighttime dehazing methods are generally tailored for specific situations involving phenomena such as glow or low illuminance without considering various factors found in nighttime images, including low-illumination conditions, color discrepancies, and image blurring. This limitation leads to subpar performance when handling complex nighttime scenes. Meanwhile, most nighttime dehazing methods build upon daytime dehazing techniques as their foundation. However, daytime dehazing methods often overlook the impact of artificial light sources. Consequently, these methods can result in color distortions and insufficient brightness when applied directly to nighttime images. Furthermore, deep learning-based methods for nighttime image dehazing demand a substantial volume of training data and high-performance computing resources to achieve visually pleasing results. However, neglecting the fundamental principles of image formation in hazy conditions results in diminished interpretability of their results. A nighttime image dehazing method based on transmittance correction and layered optimization is presented to address the aforementioned challenge. On the one hand, the atmospheric light function is used to model nighttime scenes, while the non-uniform distribution of nighttime atmospheric light is considered to correct the transmittance. On the other hand, the structure and texture are optimized in layers to solve problems such as color deviation and low illumination.MethodFirst, a novel transmittance correction method is introduced. This method establishes clear initial transmittance maps by setting maximum and minimum boundary values through boundary constraints. Subsequently, compensation and normalization are conducted based on whether the initial transmittance map corresponds to the light source area of the image. This process ensures the relevance and effectiveness of dehazing, resulting in the final transmittance map. Haze is concentrated on the haze line within the RGB color space and can be precisely mapped onto the gray component of the Y channel in the YUV color space. This relationship between the Y channel and haze is leveraged to obtain the final atmospheric light map. This approach is achieved by employing the quadratic Gaussian filtering method, which involves conducting an initial Gaussian filter on the Y channel to extract relevant information and applying a second Gaussian filter to all channels. Afterward, image dehazing is accomplished by utilizing the two resulting maps obtained via the nighttime imaging model. Second, a STAR model based on the YUV color space (STAR-YUV) is introduced. This model decomposes the Y channels, which can reflect the lighting information of each component, into structural and texture layers and enhances the image features accordingly. For structural layers with rich color information, gamma correction is applied for illumination compensation, and MSRCR color correction is used to effectively correct color deviations, obtaining natural color output. For texture layers with rich detail information, Laplacian Gaussian filters are employed to enrich and sharpen complex details while preserving image edges and texture information, resulting in detail enhancement output. Finally, a novel two-stage nighttime image fusion method is introduced to achieve a superior visual result and integrate the previous two steps. In the first stage, a nonlinear fusion approach is employed on the structural and texture layers to preserve structural details and fine features, respectively, based on the principles of the Retinex theory. In the second stage, a linear fusion method is applied to merge the dehazing results with the outcomes of the first stage, thereby leveraging the advantages of dehazing and image enhancement to generate a high-quality and visually appealing final image. Considering the distinctive characteristics of nighttime images and addressing the limitations of existing approaches, this method consolidates the transmittance correction method for transmittance compensation with structural and textural optimization, thereby offering a highly effective solution for enhancing nighttime images.ResultBased on theoretical analysis and extensive experiments conducted on two distinct test datasets, the proposed algorithm is shown to achieve dehazing of nighttime images. On the ZS330 test dataset images, the visual quality of the processed images was improved, with the average values of AG, IE, and NIQE indicators reaching 7.836, 7.461, and 2.683, respectively. On the HC770 test dataset images, the processed images also exhibited better performance, with PSNR, SSIM, AG, IE, and NIQE indicators reaching 17.024 dB, 0.765, 7.371, 7.595, and 2.702, respectively. Across the entire test dataset, the average PSNR, SSIM, AG, IE, and NIQE indicators reached 17.024 dB, 0.765, 7.604, 7.528, and 2.693, respectively. Compared to traditional and deep learning-based algorithms used in the paper, this approach consistently ranks among the top performers across various indicators. The proposed algorithm displays strong performance in restoring image details, preserving naturalness, and effectively addressing severe color deviations commonly observed in nighttime images. Additionally, the algorithm demonstrates robustness by effectively enhancing images in scenarios with or without artificial light sources.ConclusionThis approach combines a novel transmittance correction method with structural and texture layer optimization. Leveraging the strengths of the two methods has resulted in advancements in restoring the clarity of nighttime images, improving lighting conditions, correcting color deviations, and preserving intricate details.关键词:nighttime image dehazing;transmittance correction method;structure and texture optimization;two stages;image fusion- 2
- |
- 0
- |
- 0
发布时间:2024-11-16
Image Processing and Coding
-
 摘要:ObjectiveThe task of image classification based on few-shot learning refers to the training of a machine learning model that can effectively classify target images in the presence of limited target training samples available. The main challenge in few-shot image classification lies in the lack of a sufficient dataset, that is, only a small amount of labeled data is available for model training. Numerous advanced models have been proposed to tackle this challenge. A common and efficient strategy is to use deep networks as feature extractors. Deep networks are models that can automatically extract valuable features from input images. These networks can extract feature vectors from the image by using multilayer convolution and pooling operations. These feature vectors can be used to determine the category of the images and realize the goal of image classification. During model training, the feature extractor gradually learns to extract relevant information related to the category of the image, which can then be used as the feature vector. Using deep networks as feature extractors is a common and efficient strategy for few-shot image classification. Even when trained on limited labeled data, these models can achieve high accuracy by leveraging the power of deep learning. However, in the process of extracting features in the form of vectors, a risk of losing valuable information, including information strongly associated with the specific category, is evident. This risk can result in the disregard of crucial information that could substantially enhance image classification accuracy. The extracted feature vectors must encompass a maximum amount of category-specific information to enhance the accuracy of classification. This paper introduces a novel rich representation feature extractor (RireFeat) based on the base class to achieve an extensive and comprehensive image representation.MethodThis paper proposes a feature extractor called RireFeat to achieve highly comprehensive and class-specific feature extraction. RireFeat mainly aims to enhance the exchange and flow of information within the feature extractor, thereby facilitating the extraction of class-related features. Additionally, this method focuses on the multilayer feature vectors before and after the training of the feature extractor to ensure that the positive information for classification is retained during the feature extraction process. RireFeat employs a pyramid-like design that divides the feature extractor into multiple levels. Each level will receive the image coding information from its upper level, and the obtained information will flow to the next level after several convolution and pooling operations at this level. This hierarchical structure facilitates the transfer and fusion of information between different levels, maximizing the utilization of image extraction information within the feature extractor. The category correlation of feature vectors is subsequently deepened, leading to improved accuracy in image classification. Furthermore, RireFeat demonstrates superior generalization capabilities and can readily adapt to novel image classification tasks. Specifically, this paper starts with the process of feature extraction. Local features related to categories are extracted after the image information traverses a multilayered hierarchical structure, while information unrelated to categories is ignored. However, this process may also lead to the removal of certain category-specific information. The rich representation feature extractor (RireFeat), which integrates a small shaping module to add the shaping module at a distance across the hierarchy, is proposed in this paper to address this issue. Therefore, image information can still flow and merge with each other after crossing the hierarchy. This design enables the network to pay additional attention to changes in features before and after each level, facilitating the effective extraction of local features while disregarding information that is unrelated to the specific category. Consequently, this approach notably enhances the classification accuracy. Simultaneously, this paper also introduces the idea of contrastive learning into few-shot image classification and combines it with deep Brownian distance covariance to measure image features from multiple scales to contrastive loss functions. This method aims to bring the embeddings of the same distribution closer while pushing those of different distributions farther away, thereby improving classification accuracy. In the experiment, the SetFeat method was used to extract the feature set for each image. In terms of training, similar to other few-shot image learning methods, the entire network is initially pre-trained and then finetuned in the meta-training stage. In the meta-training phase, the classification is performed by calculating the distance between the query (test) and support (training) sample sets.Result1-shot and 5-shot classification training are conducted on the standard small sample datasets, such as MiniImageNet, TierdeImageNet, and CUB, to verify the validity of the proposed feature extraction structure. Experimental results show that RireFeat achieves 0.64% and 1.10% higher accuracy than SetFeat in a 1-shot and 5-shot convolution-based backbone network on the MiniImageNet dataset, respectively. The ResNet12-based structure is 1.51% and 1.46% higher than SetFeat in 1-shot and 5-shot cases, respectively. CUB datasets provide gains 0.03% and 0.61% higher than SetFeat at 1-shot and 5-shot, respectively, in convolution-based backbone networks, demonstrating improvements of 0.66% and 0.75% over SetFeat in 1-shot and 5-shot scenarios, respectively, in the Resnet12-based structure. In TieredImageNet evaluation, the convolution-based backbone network architecture achieves 0.21% and 0.38% improvement over SetFeat under 1-shot and 5-shot conditions, respectively.ConclusionThis paper proposes a rich representation feature extractor (RireFeat) to obtain a rich, comprehensive, and accurate feature representation for few-shot image classification. Different from traditional feature extractors and feature extraction forms, RireFeat increases the flow of information between feature extraction networks by paying attention to the changes in features before and after network transmission. RireFeat effectively reintegrates the category information lost during feature extraction into the feature representation. In addition, the concept of contrastive learning combined with deep Brownian distance covariance is introduced into the few-shot learning image classification to learn additional categorical representations for each image. Therefore, this extractor can capture highly nuanced differences between images from various categories, resulting in improved classification performance. In addition, the feature vector set is extracted from the image to provide strong support for the subsequent classification task. The proposed method achieves high classification accuracy on the MiniImageNet, TieredImageNet, and CUB datasets. Moreover, this paper verifies the universality of the proposed method with the current popular deep learning backbones, such as convolutional and residual backbones, highlighting its applicability to current state-of-the-art models.关键词:few-shot image classification;attention mechanism;multi-scale measurement;feature representation;constrastive learning;deep Brovonian distance convariance
摘要:ObjectiveThe task of image classification based on few-shot learning refers to the training of a machine learning model that can effectively classify target images in the presence of limited target training samples available. The main challenge in few-shot image classification lies in the lack of a sufficient dataset, that is, only a small amount of labeled data is available for model training. Numerous advanced models have been proposed to tackle this challenge. A common and efficient strategy is to use deep networks as feature extractors. Deep networks are models that can automatically extract valuable features from input images. These networks can extract feature vectors from the image by using multilayer convolution and pooling operations. These feature vectors can be used to determine the category of the images and realize the goal of image classification. During model training, the feature extractor gradually learns to extract relevant information related to the category of the image, which can then be used as the feature vector. Using deep networks as feature extractors is a common and efficient strategy for few-shot image classification. Even when trained on limited labeled data, these models can achieve high accuracy by leveraging the power of deep learning. However, in the process of extracting features in the form of vectors, a risk of losing valuable information, including information strongly associated with the specific category, is evident. This risk can result in the disregard of crucial information that could substantially enhance image classification accuracy. The extracted feature vectors must encompass a maximum amount of category-specific information to enhance the accuracy of classification. This paper introduces a novel rich representation feature extractor (RireFeat) based on the base class to achieve an extensive and comprehensive image representation.MethodThis paper proposes a feature extractor called RireFeat to achieve highly comprehensive and class-specific feature extraction. RireFeat mainly aims to enhance the exchange and flow of information within the feature extractor, thereby facilitating the extraction of class-related features. Additionally, this method focuses on the multilayer feature vectors before and after the training of the feature extractor to ensure that the positive information for classification is retained during the feature extraction process. RireFeat employs a pyramid-like design that divides the feature extractor into multiple levels. Each level will receive the image coding information from its upper level, and the obtained information will flow to the next level after several convolution and pooling operations at this level. This hierarchical structure facilitates the transfer and fusion of information between different levels, maximizing the utilization of image extraction information within the feature extractor. The category correlation of feature vectors is subsequently deepened, leading to improved accuracy in image classification. Furthermore, RireFeat demonstrates superior generalization capabilities and can readily adapt to novel image classification tasks. Specifically, this paper starts with the process of feature extraction. Local features related to categories are extracted after the image information traverses a multilayered hierarchical structure, while information unrelated to categories is ignored. However, this process may also lead to the removal of certain category-specific information. The rich representation feature extractor (RireFeat), which integrates a small shaping module to add the shaping module at a distance across the hierarchy, is proposed in this paper to address this issue. Therefore, image information can still flow and merge with each other after crossing the hierarchy. This design enables the network to pay additional attention to changes in features before and after each level, facilitating the effective extraction of local features while disregarding information that is unrelated to the specific category. Consequently, this approach notably enhances the classification accuracy. Simultaneously, this paper also introduces the idea of contrastive learning into few-shot image classification and combines it with deep Brownian distance covariance to measure image features from multiple scales to contrastive loss functions. This method aims to bring the embeddings of the same distribution closer while pushing those of different distributions farther away, thereby improving classification accuracy. In the experiment, the SetFeat method was used to extract the feature set for each image. In terms of training, similar to other few-shot image learning methods, the entire network is initially pre-trained and then finetuned in the meta-training stage. In the meta-training phase, the classification is performed by calculating the distance between the query (test) and support (training) sample sets.Result1-shot and 5-shot classification training are conducted on the standard small sample datasets, such as MiniImageNet, TierdeImageNet, and CUB, to verify the validity of the proposed feature extraction structure. Experimental results show that RireFeat achieves 0.64% and 1.10% higher accuracy than SetFeat in a 1-shot and 5-shot convolution-based backbone network on the MiniImageNet dataset, respectively. The ResNet12-based structure is 1.51% and 1.46% higher than SetFeat in 1-shot and 5-shot cases, respectively. CUB datasets provide gains 0.03% and 0.61% higher than SetFeat at 1-shot and 5-shot, respectively, in convolution-based backbone networks, demonstrating improvements of 0.66% and 0.75% over SetFeat in 1-shot and 5-shot scenarios, respectively, in the Resnet12-based structure. In TieredImageNet evaluation, the convolution-based backbone network architecture achieves 0.21% and 0.38% improvement over SetFeat under 1-shot and 5-shot conditions, respectively.ConclusionThis paper proposes a rich representation feature extractor (RireFeat) to obtain a rich, comprehensive, and accurate feature representation for few-shot image classification. Different from traditional feature extractors and feature extraction forms, RireFeat increases the flow of information between feature extraction networks by paying attention to the changes in features before and after network transmission. RireFeat effectively reintegrates the category information lost during feature extraction into the feature representation. In addition, the concept of contrastive learning combined with deep Brownian distance covariance is introduced into the few-shot learning image classification to learn additional categorical representations for each image. Therefore, this extractor can capture highly nuanced differences between images from various categories, resulting in improved classification performance. In addition, the feature vector set is extracted from the image to provide strong support for the subsequent classification task. The proposed method achieves high classification accuracy on the MiniImageNet, TieredImageNet, and CUB datasets. Moreover, this paper verifies the universality of the proposed method with the current popular deep learning backbones, such as convolutional and residual backbones, highlighting its applicability to current state-of-the-art models.关键词:few-shot image classification;attention mechanism;multi-scale measurement;feature representation;constrastive learning;deep Brovonian distance convariance- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveZero-shot Chinese character recognition (ZSCCR) has attracted increasing attention in recent years due to its importance in recognizing unseen Chinese characters with zero/few training samples. The fundamental concept of zero-shot learning is to solve the new class recognition problem by generalizing semantic knowledge from seen classes to unseen classes, usually represented by auxiliary information such as attribute descriptions shared between different classes. Chinese characters comprise multiple radicals; therefore, radicals are often used as shared attributes between different Chinese character classes. Most existing ZSCCR methods adopt the radical-based sequence matching framework that recognizes the character by predicting the radical sequence, followed by minimum edit distance (MED) matching based on the ideographic description sequence (IDS) dictionary. The MED can quickly compare the predicted radical sequences individually with the IDS dictionary to measure the difference between the two sequences and thus determine the unseen Chinese character category. However, this algorithm is mainly based on a framework where the insertion, deletion, and substitution costs are all set to 1, assuming that the cost is the same between all pairs of radicals. However, in practice, the substitution cost between similar radicals should be lower than that between non-similar radicals. Moreover, this approach needs increased flexibility due to the excessively long or short length of the predicted IDS sequence, resulting in redundant insertion or deletion costs. Consequently, a character-aware edit distance (CAED) is proposed to extract refined radical substitution costs, and the impacts of insertion and deletion costs are considered.MethodThe CAED in this study adaptively adjusts the cost of substitution, insertion, and deletion in edit distance to match the unseen Chinese character category according to the sensitivity of each Chinese character. In ZSCCR, the key to the radical-based approach lies in identifying radical sequences and the metrics between predicted and candidate sequences, and the accuracy of the metrics will directly determine the performance of the final model. Therefore, the metrics between radical sequences must be refined. Specifically, the CAED proposed in this paper analyzes the cost of editing distance. The similarity probability between different radicals is calculated as the substitution cost by assigning weights to the structure of the radicals, number of strokes, partials, and four-corner method information. Thus, the cost of the distance between different radicals is finely adjusted to improve the robustness and performance of MED. In addition, a radical counting module is introduced to predict the number of radicals. Constraints on the cost of insertions and deletions are imposed by comparing the radical counts with the number of radicals in the predicted sequence to help mitigate the problem of excessively long or short predicted sequences of radicals. Therefore, refined distances are obtained between radical sequences. Compared to traditional methods, the proposed method can accurately match the correct character class with the shortest distance, regardless of misrecognition of similar radicals, mismatch of radical sequences, or both simultaneously.ResultExperiments are conducted on the handwriting database (HWDB) and the 12th International Conference on Document Analysis and Recognition (ICDAR 2013) datasets, the Chinese text in the wild (CTW) datasets, and the ancient handwritten characters database (AHCDB). Initially, on the handwritten and scene Chinese character datasets, the proposed CAED consistently outperformed current state-of-the-art methods in ZSCCR, demonstrating the superiority of CAED. Subsequently, CAED was integrated with other networks in the ancient Chinese dataset to emphasize its scalability. Additionally, the performance of the radical counting module was evaluated, recognizing its direct impact on cost gating. Subsequent ablation experiments validated the effectiveness of the insertion and deletion cost constraint modules and the substitution cost refinement module. Combinatorial analysis was conducted on the multiple pieces of information contributing to the substitution cost to determine their respective values. Finally, traditional Chinese character recognition experiments were conducted to evaluate the performance of CAED in recognizing purely visible Chinese character categories, and the accuracy reached 97.02% on ICDAR 2013. Although it failed to reach optimal performance, CAED is still highly competitive and performs excellently in all comparison results. Experimental outcomes revealed a notable improvement in unseen Chinese character accuracy, with CAED achieving a 4.64%, 1.1%, and 5.08% enhancement compared to other methods on the HWDB, ICDAR 2013, CTW, and AHCDB datasets.ConclusionA CAED for zero-shot Chinese character recognition, in which the cost of editing in edit distance depends adaptively on the character, is proposed. The method refines the substitution cost between radicals with multiple pieces of information, which can correct similar radicals misrecognized as confusing by the model. Moreover, introducing a radical counting module to form a cost gating is used to constrain the cost of insertions and deletions, thus alleviating the problem of mismatched radical sequence lengths. In addition, the method can be combined with any network based on radical sequence recognition to improve the resistance to misrecognition.关键词:zero-shot Chinese character recognition (ZSCCR);ideographic description sequence (IDS);edit distance;character-aware;radical information;cost gate
摘要:ObjectiveZero-shot Chinese character recognition (ZSCCR) has attracted increasing attention in recent years due to its importance in recognizing unseen Chinese characters with zero/few training samples. The fundamental concept of zero-shot learning is to solve the new class recognition problem by generalizing semantic knowledge from seen classes to unseen classes, usually represented by auxiliary information such as attribute descriptions shared between different classes. Chinese characters comprise multiple radicals; therefore, radicals are often used as shared attributes between different Chinese character classes. Most existing ZSCCR methods adopt the radical-based sequence matching framework that recognizes the character by predicting the radical sequence, followed by minimum edit distance (MED) matching based on the ideographic description sequence (IDS) dictionary. The MED can quickly compare the predicted radical sequences individually with the IDS dictionary to measure the difference between the two sequences and thus determine the unseen Chinese character category. However, this algorithm is mainly based on a framework where the insertion, deletion, and substitution costs are all set to 1, assuming that the cost is the same between all pairs of radicals. However, in practice, the substitution cost between similar radicals should be lower than that between non-similar radicals. Moreover, this approach needs increased flexibility due to the excessively long or short length of the predicted IDS sequence, resulting in redundant insertion or deletion costs. Consequently, a character-aware edit distance (CAED) is proposed to extract refined radical substitution costs, and the impacts of insertion and deletion costs are considered.MethodThe CAED in this study adaptively adjusts the cost of substitution, insertion, and deletion in edit distance to match the unseen Chinese character category according to the sensitivity of each Chinese character. In ZSCCR, the key to the radical-based approach lies in identifying radical sequences and the metrics between predicted and candidate sequences, and the accuracy of the metrics will directly determine the performance of the final model. Therefore, the metrics between radical sequences must be refined. Specifically, the CAED proposed in this paper analyzes the cost of editing distance. The similarity probability between different radicals is calculated as the substitution cost by assigning weights to the structure of the radicals, number of strokes, partials, and four-corner method information. Thus, the cost of the distance between different radicals is finely adjusted to improve the robustness and performance of MED. In addition, a radical counting module is introduced to predict the number of radicals. Constraints on the cost of insertions and deletions are imposed by comparing the radical counts with the number of radicals in the predicted sequence to help mitigate the problem of excessively long or short predicted sequences of radicals. Therefore, refined distances are obtained between radical sequences. Compared to traditional methods, the proposed method can accurately match the correct character class with the shortest distance, regardless of misrecognition of similar radicals, mismatch of radical sequences, or both simultaneously.ResultExperiments are conducted on the handwriting database (HWDB) and the 12th International Conference on Document Analysis and Recognition (ICDAR 2013) datasets, the Chinese text in the wild (CTW) datasets, and the ancient handwritten characters database (AHCDB). Initially, on the handwritten and scene Chinese character datasets, the proposed CAED consistently outperformed current state-of-the-art methods in ZSCCR, demonstrating the superiority of CAED. Subsequently, CAED was integrated with other networks in the ancient Chinese dataset to emphasize its scalability. Additionally, the performance of the radical counting module was evaluated, recognizing its direct impact on cost gating. Subsequent ablation experiments validated the effectiveness of the insertion and deletion cost constraint modules and the substitution cost refinement module. Combinatorial analysis was conducted on the multiple pieces of information contributing to the substitution cost to determine their respective values. Finally, traditional Chinese character recognition experiments were conducted to evaluate the performance of CAED in recognizing purely visible Chinese character categories, and the accuracy reached 97.02% on ICDAR 2013. Although it failed to reach optimal performance, CAED is still highly competitive and performs excellently in all comparison results. Experimental outcomes revealed a notable improvement in unseen Chinese character accuracy, with CAED achieving a 4.64%, 1.1%, and 5.08% enhancement compared to other methods on the HWDB, ICDAR 2013, CTW, and AHCDB datasets.ConclusionA CAED for zero-shot Chinese character recognition, in which the cost of editing in edit distance depends adaptively on the character, is proposed. The method refines the substitution cost between radicals with multiple pieces of information, which can correct similar radicals misrecognized as confusing by the model. Moreover, introducing a radical counting module to form a cost gating is used to constrain the cost of insertions and deletions, thus alleviating the problem of mismatched radical sequence lengths. In addition, the method can be combined with any network based on radical sequence recognition to improve the resistance to misrecognition.关键词:zero-shot Chinese character recognition (ZSCCR);ideographic description sequence (IDS);edit distance;character-aware;radical information;cost gate- 2
- |
- 0
- |
- 0
发布时间:2024-11-16
Image Analysis and Recognition
-
 摘要:ObjectiveKnowledge distillation is a simple and effective method for compressing neural networks and has become a popular topic in model compression research. This method features a “teacher–student” architecture where a large network guides the training of a small network to improve its performance in application scenarios, indirectly achieving network compression. In traditional methods, the training of the student model relies on the training data of the teacher, and the quality of the student model depends on the quality of the training data. When faced with data scarcity, these methods fail to produce satisfactory results. Data-free knowledge distillation successfully addresses the issue of limited training data by introducing synthetic data. Such methods mainly synthesize training data by refining teacher network knowledge. For example, they use the intermediate representations of the teacher network for image inversion synthesis or employ the teacher network as a fixed discriminator to supervise the generator of synthetic images for training the student network. Compared with traditional methods, the training of data-free knowledge distillation does not rely on the original training data of the teacher network, which markedly expands the application scope of knowledge distillation. However, the training process may have a certain efficiency discount compared with traditional methods due to the need for additional synthetic training data. Furthermore, in practical applications, focus is often only provided on a few target classes. However, existing data-free knowledge distillation methods encounter difficulties in selectively learning the knowledge of the target class, especially when the number of teacher model classes is large, the model convergence is complex, and achieving sufficient compactness through the student model is difficult. Therefore, this paper proposes a novel data-free knowledge distillation method, namely masked distillation for target classes (MDTC). This method allows the student model to selectively learn the knowledge of target classes, maintaining good performance even in the presence of numerous classes in the teacher network. Compared to traditional methods, MDTC reduces the training difficulty and improves the training efficiency of data-free knowledge distillation.MethodThe MDTC method utilizes a generator to learn the batch-normalized parameter distribution of raw data and trains a generator that can generate target class samples by creating a mask to block the gradient backpropagation of non-target classes in the gradient update process of the generator. This method successfully extracts target knowledge from the teacher model while generating synthetic data that is similar to the original data. In addition, MDTC introduces the teacher model into the feature learning process of the middle layer of the generator, supervises the training of the generator, and optimizes the initial parameter settings and parameter update strategies of the generator to accelerate the convergence of the model. The MDTC algorithm is divided into two stages: the first is the data synthesis stage, which fixes the student network and only updates the generated network. During the process of generating network updates, MDTC extracts three synthetic samples from the shallow, medium, and deep layers of the generator, inputs them into the teacher network for prediction, and updates the parameters of the generation network according to the feedback of the teacher network. When updating shallow and middle layer parameters, the other layer parameters of the generated network are fixed and updated separately for that layer. Finally, when updating the output layer of the generative network, the parameters of the entire generative network are updated to gradually guide the generator to learn and synthesize the target image. The second stage is the learning stage, in which the generation network is fixed and the synthetic samples are inputted into the teacher and student networks for prediction. The target knowledge of the teacher is extracted by the mask, and Kullback-Leibler(KL) divergence is used to calculate the predicted output of the student network to update the student network.ResultFour standard image classification datasets, namely, MNIST, SVHN, CIFAR10, and CIFAR100, are divided into 13 subclassification tasks by Pearson similarity calculation, including eight difficult tasks and five easy tasks. The performance of MDTC on subclassification tasks with different difficulties is evaluated by classification accuracy. The method is also compared with five mainstream data-free knowledge distillation methods and the vanilla KD method. Experimental results show that the proposed method outperforms the other mainstream data-free distillation models on 11 subtasks. Moreover, in MNIST1, MNIST2, SVHN1, SVHN3, CIFAR102, and CIFAR104 (6 of the 13 subclassification tasks), the proposed method even surpasses the teacher model trained on the original data, achieving accuracy rates of 99.61%, 99.46%, 95.85%, 95.80%, 94.57%, and 95.00%, demonstrating a remarkable 3.6% improvement over the 91.40% accuracy of the teacher network in CIFAR104.ConclusionIn this study, a novel data-free knowledge distillation method, MDTC, is proposed. The experimental results indicate that MDTC outperforms existing data-free distillation models overall, especially in efficiently learning knowledge for easy sample classification tasks and when knowledge classes have a low proportion. The method displays excellent performance when extracting knowledge from a limited set of categories.关键词:deep learning;image classification;model compression;data-free knowledge distillation;generators
摘要:ObjectiveKnowledge distillation is a simple and effective method for compressing neural networks and has become a popular topic in model compression research. This method features a “teacher–student” architecture where a large network guides the training of a small network to improve its performance in application scenarios, indirectly achieving network compression. In traditional methods, the training of the student model relies on the training data of the teacher, and the quality of the student model depends on the quality of the training data. When faced with data scarcity, these methods fail to produce satisfactory results. Data-free knowledge distillation successfully addresses the issue of limited training data by introducing synthetic data. Such methods mainly synthesize training data by refining teacher network knowledge. For example, they use the intermediate representations of the teacher network for image inversion synthesis or employ the teacher network as a fixed discriminator to supervise the generator of synthetic images for training the student network. Compared with traditional methods, the training of data-free knowledge distillation does not rely on the original training data of the teacher network, which markedly expands the application scope of knowledge distillation. However, the training process may have a certain efficiency discount compared with traditional methods due to the need for additional synthetic training data. Furthermore, in practical applications, focus is often only provided on a few target classes. However, existing data-free knowledge distillation methods encounter difficulties in selectively learning the knowledge of the target class, especially when the number of teacher model classes is large, the model convergence is complex, and achieving sufficient compactness through the student model is difficult. Therefore, this paper proposes a novel data-free knowledge distillation method, namely masked distillation for target classes (MDTC). This method allows the student model to selectively learn the knowledge of target classes, maintaining good performance even in the presence of numerous classes in the teacher network. Compared to traditional methods, MDTC reduces the training difficulty and improves the training efficiency of data-free knowledge distillation.MethodThe MDTC method utilizes a generator to learn the batch-normalized parameter distribution of raw data and trains a generator that can generate target class samples by creating a mask to block the gradient backpropagation of non-target classes in the gradient update process of the generator. This method successfully extracts target knowledge from the teacher model while generating synthetic data that is similar to the original data. In addition, MDTC introduces the teacher model into the feature learning process of the middle layer of the generator, supervises the training of the generator, and optimizes the initial parameter settings and parameter update strategies of the generator to accelerate the convergence of the model. The MDTC algorithm is divided into two stages: the first is the data synthesis stage, which fixes the student network and only updates the generated network. During the process of generating network updates, MDTC extracts three synthetic samples from the shallow, medium, and deep layers of the generator, inputs them into the teacher network for prediction, and updates the parameters of the generation network according to the feedback of the teacher network. When updating shallow and middle layer parameters, the other layer parameters of the generated network are fixed and updated separately for that layer. Finally, when updating the output layer of the generative network, the parameters of the entire generative network are updated to gradually guide the generator to learn and synthesize the target image. The second stage is the learning stage, in which the generation network is fixed and the synthetic samples are inputted into the teacher and student networks for prediction. The target knowledge of the teacher is extracted by the mask, and Kullback-Leibler(KL) divergence is used to calculate the predicted output of the student network to update the student network.ResultFour standard image classification datasets, namely, MNIST, SVHN, CIFAR10, and CIFAR100, are divided into 13 subclassification tasks by Pearson similarity calculation, including eight difficult tasks and five easy tasks. The performance of MDTC on subclassification tasks with different difficulties is evaluated by classification accuracy. The method is also compared with five mainstream data-free knowledge distillation methods and the vanilla KD method. Experimental results show that the proposed method outperforms the other mainstream data-free distillation models on 11 subtasks. Moreover, in MNIST1, MNIST2, SVHN1, SVHN3, CIFAR102, and CIFAR104 (6 of the 13 subclassification tasks), the proposed method even surpasses the teacher model trained on the original data, achieving accuracy rates of 99.61%, 99.46%, 95.85%, 95.80%, 94.57%, and 95.00%, demonstrating a remarkable 3.6% improvement over the 91.40% accuracy of the teacher network in CIFAR104.ConclusionIn this study, a novel data-free knowledge distillation method, MDTC, is proposed. The experimental results indicate that MDTC outperforms existing data-free distillation models overall, especially in efficiently learning knowledge for easy sample classification tasks and when knowledge classes have a low proportion. The method displays excellent performance when extracting knowledge from a limited set of categories.关键词:deep learning;image classification;model compression;data-free knowledge distillation;generators- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveIn today’s industrial environment, large-scale automatic production lines are gradually replacing the traditional manual production mode, and the concept of an intelligent factory has also received increasing attention from several enterprises. Among them, automatic guided vehicles (AGVs) are used to replace manual handling of goods in many modern factories. The factory pastes a QR code every two meters on the path of the AGV operation. The central control system of the factory continuously assigns different meanings to each QR code. When the AGV drives on the road of the factory and covers one of the QR codes, the scanning system at the bottom will read the QR code information to determine whether the next step is to turn, accelerate, lift, or unload heavy objects. When hundreds of AGVs in the workshop are running simultaneously, the central control system of the workshop will plan the most efficient path and then transmit the control information to the AGV as the physical terminal through two-dimensional codes to realize the intelligent transportation of goods in the factory. When an obstacle is in front of the AGV, regardless of whether the object will hinder the normal operation of the AGV, the common solution is to provide the AGV with a control signal to stop it when the sensor in front of the AGV detects an object. When the AGV is in an environment with many people or goods in the factory, the working efficiency of the AGV is substantially reduced due to frequent parking. Therefore, providing the AGV with specific information regarding the obstacles ahead is necessary to effectively conduct subsequent obstacle avoidance. Therefore, a multiscale encoding for single-stage 3D object detectors from point clouds (MSE-SSD) is introduced to help AGV detect various obstacles in complex industrial scenes.MethodFirst, the learnable downsampling module of the foreground points is used to sample the point cloud, and the foreground points are accurately and efficiently obtained from the point cloud. This module can gradually extract the semantic features of the input point cloud through the multiple-layer perceptron operation and quantify the semantic features of the points into the foreground score. The Top-K method then selects the first K points as the front attractions according to the foreground score to filter out the front attractions with rich target information. Second, the point cloud space with only the foreground points is sent to the multi-abstract scale feature extraction module. In this module, the point cloud space is compressed into a bird’s-eye view (BEV) after voxelization. During the BEV feature extraction, three abstract scale feature maps are extracted from the convolution layer, and attention is used to adaptively fuse them to generate the final feature map and reduce the loss of feature information caused by two-dimensional BEV. Despite the complex plant environment, the target information is relatively simple and clear. The three abstract scale feature maps can provide the computer with almost all target semantic information. The final feature map is used to predict the heatmap, which is sent to the next module. The multi-distance scale feature aggregation module then obtains the center point of each target from the heatmap and aggregates the foreground points near each center point in the voxel space. The module quickly obtains the foreground points through a voxel query and groups them according to the different distances between them and the center point. When the probability that the foreground point close to the center point belongs to this target is high, the probability that the foreground point far away belongs to the center point target is low. Therefore, networks with different weights are used to encode the groups of foreground points to obtain distance-sensitive multiscale semantic features. Finally, the semantic feature and the center point jointly predict the bounding box, where the center point represents the center coordinate of the bounding box and the semantic feature predicts the confidence, size, and deflection angle of the bounding box.ResultThe official data sets KITTI and Waymo are used to evaluate the performance of the model, and the custom data set is then utilized to evaluate the final combat effect of the model. In the KITTI test set, the nine most popular methods at present are compared. MSE-SSD ranked third in detection speed, and the frames per second reached 34. Simultaneously, in the comparison of average precision (AP), MSE-SSD and the most advanced single-stage detector at present were almost the same. In the Waymo verification set, compared with other single-stage detectors, the average accuracy of multiple indicators (pedestrians and bicycles) of MSE-SSD for relatively complex targets ranked first. In the customized data set, the following three targets are detected: empty AGV, loaded AGV, and pedestrian. Under the simple level, the AP of MSE-SSD in the cargo AGV and pedestrian targets is 0.08% and 0.71% higher than the second, respectively. At this difficulty level, the AP of MSE-SSD is 1.27% higher than the second in the empty AGV target. Simultaneously, the detection speed of MSE-SSD reached the second level at 65 frame/s. The trained network is deployed on the TXR demoboard carried by the AGV car, and the detection speed reached 7.3 frame/s.ConclusionConsidering the transportation problem in the industrial scene, an obstacle avoidance detection method for AGV is introduced based on two point cloud scales. This method has high detection accuracy and speed and provides a detection guarantee for AGV when running on mobile devices.关键词:3D object detection;single-stage detector;point cloud down-sampling;point cloud feature extraction;point cloud feature aggregation
摘要:ObjectiveIn today’s industrial environment, large-scale automatic production lines are gradually replacing the traditional manual production mode, and the concept of an intelligent factory has also received increasing attention from several enterprises. Among them, automatic guided vehicles (AGVs) are used to replace manual handling of goods in many modern factories. The factory pastes a QR code every two meters on the path of the AGV operation. The central control system of the factory continuously assigns different meanings to each QR code. When the AGV drives on the road of the factory and covers one of the QR codes, the scanning system at the bottom will read the QR code information to determine whether the next step is to turn, accelerate, lift, or unload heavy objects. When hundreds of AGVs in the workshop are running simultaneously, the central control system of the workshop will plan the most efficient path and then transmit the control information to the AGV as the physical terminal through two-dimensional codes to realize the intelligent transportation of goods in the factory. When an obstacle is in front of the AGV, regardless of whether the object will hinder the normal operation of the AGV, the common solution is to provide the AGV with a control signal to stop it when the sensor in front of the AGV detects an object. When the AGV is in an environment with many people or goods in the factory, the working efficiency of the AGV is substantially reduced due to frequent parking. Therefore, providing the AGV with specific information regarding the obstacles ahead is necessary to effectively conduct subsequent obstacle avoidance. Therefore, a multiscale encoding for single-stage 3D object detectors from point clouds (MSE-SSD) is introduced to help AGV detect various obstacles in complex industrial scenes.MethodFirst, the learnable downsampling module of the foreground points is used to sample the point cloud, and the foreground points are accurately and efficiently obtained from the point cloud. This module can gradually extract the semantic features of the input point cloud through the multiple-layer perceptron operation and quantify the semantic features of the points into the foreground score. The Top-K method then selects the first K points as the front attractions according to the foreground score to filter out the front attractions with rich target information. Second, the point cloud space with only the foreground points is sent to the multi-abstract scale feature extraction module. In this module, the point cloud space is compressed into a bird’s-eye view (BEV) after voxelization. During the BEV feature extraction, three abstract scale feature maps are extracted from the convolution layer, and attention is used to adaptively fuse them to generate the final feature map and reduce the loss of feature information caused by two-dimensional BEV. Despite the complex plant environment, the target information is relatively simple and clear. The three abstract scale feature maps can provide the computer with almost all target semantic information. The final feature map is used to predict the heatmap, which is sent to the next module. The multi-distance scale feature aggregation module then obtains the center point of each target from the heatmap and aggregates the foreground points near each center point in the voxel space. The module quickly obtains the foreground points through a voxel query and groups them according to the different distances between them and the center point. When the probability that the foreground point close to the center point belongs to this target is high, the probability that the foreground point far away belongs to the center point target is low. Therefore, networks with different weights are used to encode the groups of foreground points to obtain distance-sensitive multiscale semantic features. Finally, the semantic feature and the center point jointly predict the bounding box, where the center point represents the center coordinate of the bounding box and the semantic feature predicts the confidence, size, and deflection angle of the bounding box.ResultThe official data sets KITTI and Waymo are used to evaluate the performance of the model, and the custom data set is then utilized to evaluate the final combat effect of the model. In the KITTI test set, the nine most popular methods at present are compared. MSE-SSD ranked third in detection speed, and the frames per second reached 34. Simultaneously, in the comparison of average precision (AP), MSE-SSD and the most advanced single-stage detector at present were almost the same. In the Waymo verification set, compared with other single-stage detectors, the average accuracy of multiple indicators (pedestrians and bicycles) of MSE-SSD for relatively complex targets ranked first. In the customized data set, the following three targets are detected: empty AGV, loaded AGV, and pedestrian. Under the simple level, the AP of MSE-SSD in the cargo AGV and pedestrian targets is 0.08% and 0.71% higher than the second, respectively. At this difficulty level, the AP of MSE-SSD is 1.27% higher than the second in the empty AGV target. Simultaneously, the detection speed of MSE-SSD reached the second level at 65 frame/s. The trained network is deployed on the TXR demoboard carried by the AGV car, and the detection speed reached 7.3 frame/s.ConclusionConsidering the transportation problem in the industrial scene, an obstacle avoidance detection method for AGV is introduced based on two point cloud scales. This method has high detection accuracy and speed and provides a detection guarantee for AGV when running on mobile devices.关键词:3D object detection;single-stage detector;point cloud down-sampling;point cloud feature extraction;point cloud feature aggregation- 2
- |
- 0
- |
- 0
发布时间:2024-11-16
Image Understanding and Computer Vision
-
 摘要:ObjectiveCerebral ventricles are one of the most prominent cerebral structures. The size and shape changes of the cerebral ventricle are closely associated with diverse acute and chronic neurological diseases. Accurate ventricle segmentation can help diagnose brain-related diseases by providing valuable auxiliary information. However, manual delineation of cerebral ventricles is a time-consuming task; thus, automatic ventricle segmentation is necessary. Fortunately, with the rapid development of deep learning in the field of medical image processing, automatic medical image segmentation has made considerable progress. However, the ventricle segmentation in patients with intraventricular hemorrhage (IVH) remains unexplored. A few studies focus on the ventricle segmentation of patients with IVH.MethodCerebral ventricle segmentation can be categorized into healthy/normal and IVH cases. Cerebral ventricles in healthy/normal cases are characterized by their high contrast and clear boundaries. The main challenge lies in the segmentation of small-scale cerebral ventricles in some slices. Notably, in healthy/normal cases, cerebral ventricles are not perfectly symmetric; therefore, penalizing a symmetry constraint would be helpful, especially in dealing with the low-contrast small-scale regions. Cerebral ventricle segmentation in healthy/normal cases is generally less challenging. According to the sizes of IVH, the IVH cases are further classified into small- and large-scale IVH cases. For the small-scale IVH cases, though parts of the cerebral ventricles are completely filled by hemorrhages, only the boundary regions would be affected during segmentation. In these cases, the IVH problem would not significantly degrade the segmentation performance because those regions (i.e., cerebral ventricles filled by IVH) are of high contrast compared to the background, and segmenting the high-contrast regions is roughly equal to cerebral ventricle segmentation. Large-scale IVH cases are the most challenging problem in cerebral ventricle segmentation. Considering the large hemorrhages, the hemorrhages not only cover parts of the cerebral ventricles but also several background regions. All the regions share similar appearances and contrasts. Classifying these regions as background would produce numerous false negatives, while segmenting them as cerebral ventricles would generate quite a few false positives. Therefore, large-scale IVH would poorly affect cerebral ventricle segmentation performance. Based on the above analysis, this study focuses on the cerebral ventricle segmentation problems of patients with IVH and proposes targeted ventricle segmentation methods for the problems of target occlusion and unclear boundaries. The core idea of the proposed framework is to utilize the symmetry of cerebral ventricles as guidance to alleviate the occlusions formed by IVH. Thus, an end-to-end contrastive learning-based symmetry-aware ventricle segmentation network is proposed in the paper. The model first implements adaptive image correction based on spatial transform networks without additional annotations to obtain the ventricle symmetric images of the input images at any position. A symmetry-aware learning loop is then constructed. The symmetric image pairs are simultaneously inputted into the segmentation network. The ventricles predicted by the network are forced to be symmetric by emphasizing the similarity of the segmentation result pairs. Thus, the occlusions formed by IVH could be alleviated by referring to the healthy ventricles. The ventricles are not completely symmetric; thus, pursuing “hard” symmetry during training is infeasible. Therefore, the contrastive learning algorithm is further combined with the weighted symmetry loss function to impose symmetry constraints on the images. The network can be trained end-to-end, enabling the upstream network to collaborate with the downstream segmentation task.ResultExperimental results based on different segmentation network models demonstrate that the approach proposed in this paper can achieve consistent performance improvements in multiple evaluation metrics in the ventricle segmentation task of patients with IVH. The average increase in patient- and slice-wise dice coefficients based on different baseline models when introducing the proposed method is 1.09% and 1.28%, respectively. When evaluated on the patient level, the optimal model achieved a Dice coefficient and recall of 85.17% and 84.03%, respectively, by incorporating the algorithm proposed in this paper. The qualitative results also reveal the superior performance of the proposed algorithm, which achieves smooth boundaries and complete ventricles with fewer false positives.ConclusionThis paper focuses on cerebral ventricle segmentation, especially with the existence of IVH. Compared to cerebral ventricle segmentation in healthy/normal cases, occlusions formed by IVH would make it challenging for segmentation. Based on the symmetry of cerebral ventricles, a symmetry-aware approach combined with contrastive self-supervised learning is introduced. Therefore, the occlusions are effectively alleviated by referring to the healthy/normal parts of the cerebral ventricles. Experimental results on two different datasets demonstrate a notable advancement in ventricle segmentation of computed tomography(CT) and magnetic resonance(MR) images of healthy/normal and IVH cases. Moreover, the IVH cases demonstrate considerable improvement. More importantly, the proposed approach is independent of specific deep learning architectures and introduces no additional computational complexity. Therefore, the method presented in this paper has strong portability and can be applied to various segmentation networks.关键词:cerebral ventricle segmentation;deep learning;intraventricular hemorrhage(IVH);symmetry-aware;end-to-end network
摘要:ObjectiveCerebral ventricles are one of the most prominent cerebral structures. The size and shape changes of the cerebral ventricle are closely associated with diverse acute and chronic neurological diseases. Accurate ventricle segmentation can help diagnose brain-related diseases by providing valuable auxiliary information. However, manual delineation of cerebral ventricles is a time-consuming task; thus, automatic ventricle segmentation is necessary. Fortunately, with the rapid development of deep learning in the field of medical image processing, automatic medical image segmentation has made considerable progress. However, the ventricle segmentation in patients with intraventricular hemorrhage (IVH) remains unexplored. A few studies focus on the ventricle segmentation of patients with IVH.MethodCerebral ventricle segmentation can be categorized into healthy/normal and IVH cases. Cerebral ventricles in healthy/normal cases are characterized by their high contrast and clear boundaries. The main challenge lies in the segmentation of small-scale cerebral ventricles in some slices. Notably, in healthy/normal cases, cerebral ventricles are not perfectly symmetric; therefore, penalizing a symmetry constraint would be helpful, especially in dealing with the low-contrast small-scale regions. Cerebral ventricle segmentation in healthy/normal cases is generally less challenging. According to the sizes of IVH, the IVH cases are further classified into small- and large-scale IVH cases. For the small-scale IVH cases, though parts of the cerebral ventricles are completely filled by hemorrhages, only the boundary regions would be affected during segmentation. In these cases, the IVH problem would not significantly degrade the segmentation performance because those regions (i.e., cerebral ventricles filled by IVH) are of high contrast compared to the background, and segmenting the high-contrast regions is roughly equal to cerebral ventricle segmentation. Large-scale IVH cases are the most challenging problem in cerebral ventricle segmentation. Considering the large hemorrhages, the hemorrhages not only cover parts of the cerebral ventricles but also several background regions. All the regions share similar appearances and contrasts. Classifying these regions as background would produce numerous false negatives, while segmenting them as cerebral ventricles would generate quite a few false positives. Therefore, large-scale IVH would poorly affect cerebral ventricle segmentation performance. Based on the above analysis, this study focuses on the cerebral ventricle segmentation problems of patients with IVH and proposes targeted ventricle segmentation methods for the problems of target occlusion and unclear boundaries. The core idea of the proposed framework is to utilize the symmetry of cerebral ventricles as guidance to alleviate the occlusions formed by IVH. Thus, an end-to-end contrastive learning-based symmetry-aware ventricle segmentation network is proposed in the paper. The model first implements adaptive image correction based on spatial transform networks without additional annotations to obtain the ventricle symmetric images of the input images at any position. A symmetry-aware learning loop is then constructed. The symmetric image pairs are simultaneously inputted into the segmentation network. The ventricles predicted by the network are forced to be symmetric by emphasizing the similarity of the segmentation result pairs. Thus, the occlusions formed by IVH could be alleviated by referring to the healthy ventricles. The ventricles are not completely symmetric; thus, pursuing “hard” symmetry during training is infeasible. Therefore, the contrastive learning algorithm is further combined with the weighted symmetry loss function to impose symmetry constraints on the images. The network can be trained end-to-end, enabling the upstream network to collaborate with the downstream segmentation task.ResultExperimental results based on different segmentation network models demonstrate that the approach proposed in this paper can achieve consistent performance improvements in multiple evaluation metrics in the ventricle segmentation task of patients with IVH. The average increase in patient- and slice-wise dice coefficients based on different baseline models when introducing the proposed method is 1.09% and 1.28%, respectively. When evaluated on the patient level, the optimal model achieved a Dice coefficient and recall of 85.17% and 84.03%, respectively, by incorporating the algorithm proposed in this paper. The qualitative results also reveal the superior performance of the proposed algorithm, which achieves smooth boundaries and complete ventricles with fewer false positives.ConclusionThis paper focuses on cerebral ventricle segmentation, especially with the existence of IVH. Compared to cerebral ventricle segmentation in healthy/normal cases, occlusions formed by IVH would make it challenging for segmentation. Based on the symmetry of cerebral ventricles, a symmetry-aware approach combined with contrastive self-supervised learning is introduced. Therefore, the occlusions are effectively alleviated by referring to the healthy/normal parts of the cerebral ventricles. Experimental results on two different datasets demonstrate a notable advancement in ventricle segmentation of computed tomography(CT) and magnetic resonance(MR) images of healthy/normal and IVH cases. Moreover, the IVH cases demonstrate considerable improvement. More importantly, the proposed approach is independent of specific deep learning architectures and introduces no additional computational complexity. Therefore, the method presented in this paper has strong portability and can be applied to various segmentation networks.关键词:cerebral ventricle segmentation;deep learning;intraventricular hemorrhage(IVH);symmetry-aware;end-to-end network- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveHistopathology is the gold standard for tumor diagnosis. With the development of digital pathology slide scanners, digital pathology has introduced revolutionary changes to clinical pathological diagnosis. Pathologists use digital images to examine tissues and make diagnoses based on the characteristics of the observed tissues. Simultaneously, these digital images are fed into a computer-aided diagnostic system for automated diagnosis, thereby speeding up diagnosis. However, the quality of digital pathology images is blurred locally or globally by the focusing errors produced in the scanning process. For pathologists, these blurred areas will prevent accurate observations of tissue and cellular structures, leading to misdiagnosis. Therefore, studying the focus quality evaluation for pathological images is crucial. Methods based on machine and deep learning are currently available for this research. In machine learning-based methods, features are artificially designed with the help of a priori knowledge, such as optical or microscopic imaging, and fed into a classifier to automatically obtain focused predictions. However, these methods do not automatically learn the focus features in pathological images, resulting in low evaluation accuracy. Meanwhile, deep learning-based methods automatically learn complex features, substantially improving evaluation accuracy. Current learning-based work enhances the capability to process global focus information from pathological images by introducing attention mechanisms. However, the receptive scope of these attention mechanisms is limited, which results in inadequate global focus information. By contrast, the existing networks with better performance require a larger number of parameters and computations, increasing the difficulty of their application in practice. In this paper, a focus quality assessment network with amplified receptive field (ARF-FQANet) is proposed to address challenges such as poor global information extraction and excessive computations.MethodIn ARF-FQANet, a large convolution kernel is used to amplify the receptive field of the network, and the dual-stream large kernel attention (DsLKA) mechanism is then integrated. In DsLKA, large kernel channel and spatial attentions are proposed to capture the global focus information in channels and spaces, respectively. The proposed large kernel channel attention is better than the classical channel attention mechanism, and the introduced large kernel retransmit squeeze (LKRS) method redistributes the weights in the space, thus avoiding the problem of losing saliency weights in classical channel attention. However, the local cellular semantic information gradually becomes salient with the downsampling of input features, which may affect the capability of the network to represent focus information. A local stable downsampling block (LSDSB) is designed to address the above problems. Extraneous information is minimized during the upsampling and downsampling processes by integrating LSDSB, thus ensuring the local stability of the features. A short branch is introduced to create a residual attention block (RAB) based on DsLKAB and LSDSB modules. In this short branch, the noise is extracted using a minimum pooling operation, which effectively suppresses the learning of noisy information during backpropagation, thus improving the capability of the network to represent focus information. In addition, an initial feature enhancement block (IFEB) is introduced at the initial stage of the network to enhance the capability of the initial layer to represent the focus information. The features obtained by IFEB provide highly comprehensive information for subsequent networks. A strategy to decompose large convolutional kernels is introduced to obtain a lightweight network, which substantially reduces the number of parameters and computational requirements. By contrast, the network parameters are reduced to achieve further compression. The network is then optimized into three aspects: large, medium, and small, each with a reduced number of parameters.ResultComparative experiments are performed on a publicly available dataset of focused quality assessment of pathology images. The compared networks are categorized as small, medium, and large according to the number of their parameters. In terms of large networks, the proposed large network performs the best with 0.765 8, 0.957 8, 0.956 2, and 0.852 3 for RMSE, SRCC, PLCC, and KRCC, respectively. These results show that the predicted focus scores are highly consistent with the actual focus scores. In terms of small and medium networks, the performance of the proposed small and medium networks is slightly degraded, but its parameters and computational complexity are notably reduced. Compared with self-defined convolutional neural network (SDCNN), the parameters of the small network (ARF-FQANet-S), the floating-point operations, and the CPU reference time (CPU-Time) are reduced by 39.06%, 95.11%, and 51.91%, respectively. The small network may not be able to outperform the FocusLiteNN network in terms of speed; however, performance comparable to larger networks is still provided. This paper visualizes the receptive field of several networks in different stages. The results indicate that the ARF-FQANet proposed in this paper obtains larger receptive fields, especially in the initial layer of the network. Thus, additional global focusing information is obtained at the initial layer of the network, which contributes to the stable performance of the small ARF-FQANet.ConclusionCompared with similar methods, the proposed network efficiently extracts global focus information from pathological images. In this network, a large convolutional kernel is used to expand the receptive field of the network, and DsLKA is introduced to enhance the global information within the learning space and channels. This strategy ensures that the network maintains competitive performance even after notable parameter reductions. The small network (ARF-FQANet-S) offers remarkable advantages in terms of CPU inference time and is ideal for lightweight deployments on edge devices. Overall, the results provide a technical reference for the lightweight models.关键词:digital pathological images;focus quality assessment;amplified receptive field;attention mechanism;lightweight
摘要:ObjectiveHistopathology is the gold standard for tumor diagnosis. With the development of digital pathology slide scanners, digital pathology has introduced revolutionary changes to clinical pathological diagnosis. Pathologists use digital images to examine tissues and make diagnoses based on the characteristics of the observed tissues. Simultaneously, these digital images are fed into a computer-aided diagnostic system for automated diagnosis, thereby speeding up diagnosis. However, the quality of digital pathology images is blurred locally or globally by the focusing errors produced in the scanning process. For pathologists, these blurred areas will prevent accurate observations of tissue and cellular structures, leading to misdiagnosis. Therefore, studying the focus quality evaluation for pathological images is crucial. Methods based on machine and deep learning are currently available for this research. In machine learning-based methods, features are artificially designed with the help of a priori knowledge, such as optical or microscopic imaging, and fed into a classifier to automatically obtain focused predictions. However, these methods do not automatically learn the focus features in pathological images, resulting in low evaluation accuracy. Meanwhile, deep learning-based methods automatically learn complex features, substantially improving evaluation accuracy. Current learning-based work enhances the capability to process global focus information from pathological images by introducing attention mechanisms. However, the receptive scope of these attention mechanisms is limited, which results in inadequate global focus information. By contrast, the existing networks with better performance require a larger number of parameters and computations, increasing the difficulty of their application in practice. In this paper, a focus quality assessment network with amplified receptive field (ARF-FQANet) is proposed to address challenges such as poor global information extraction and excessive computations.MethodIn ARF-FQANet, a large convolution kernel is used to amplify the receptive field of the network, and the dual-stream large kernel attention (DsLKA) mechanism is then integrated. In DsLKA, large kernel channel and spatial attentions are proposed to capture the global focus information in channels and spaces, respectively. The proposed large kernel channel attention is better than the classical channel attention mechanism, and the introduced large kernel retransmit squeeze (LKRS) method redistributes the weights in the space, thus avoiding the problem of losing saliency weights in classical channel attention. However, the local cellular semantic information gradually becomes salient with the downsampling of input features, which may affect the capability of the network to represent focus information. A local stable downsampling block (LSDSB) is designed to address the above problems. Extraneous information is minimized during the upsampling and downsampling processes by integrating LSDSB, thus ensuring the local stability of the features. A short branch is introduced to create a residual attention block (RAB) based on DsLKAB and LSDSB modules. In this short branch, the noise is extracted using a minimum pooling operation, which effectively suppresses the learning of noisy information during backpropagation, thus improving the capability of the network to represent focus information. In addition, an initial feature enhancement block (IFEB) is introduced at the initial stage of the network to enhance the capability of the initial layer to represent the focus information. The features obtained by IFEB provide highly comprehensive information for subsequent networks. A strategy to decompose large convolutional kernels is introduced to obtain a lightweight network, which substantially reduces the number of parameters and computational requirements. By contrast, the network parameters are reduced to achieve further compression. The network is then optimized into three aspects: large, medium, and small, each with a reduced number of parameters.ResultComparative experiments are performed on a publicly available dataset of focused quality assessment of pathology images. The compared networks are categorized as small, medium, and large according to the number of their parameters. In terms of large networks, the proposed large network performs the best with 0.765 8, 0.957 8, 0.956 2, and 0.852 3 for RMSE, SRCC, PLCC, and KRCC, respectively. These results show that the predicted focus scores are highly consistent with the actual focus scores. In terms of small and medium networks, the performance of the proposed small and medium networks is slightly degraded, but its parameters and computational complexity are notably reduced. Compared with self-defined convolutional neural network (SDCNN), the parameters of the small network (ARF-FQANet-S), the floating-point operations, and the CPU reference time (CPU-Time) are reduced by 39.06%, 95.11%, and 51.91%, respectively. The small network may not be able to outperform the FocusLiteNN network in terms of speed; however, performance comparable to larger networks is still provided. This paper visualizes the receptive field of several networks in different stages. The results indicate that the ARF-FQANet proposed in this paper obtains larger receptive fields, especially in the initial layer of the network. Thus, additional global focusing information is obtained at the initial layer of the network, which contributes to the stable performance of the small ARF-FQANet.ConclusionCompared with similar methods, the proposed network efficiently extracts global focus information from pathological images. In this network, a large convolutional kernel is used to expand the receptive field of the network, and DsLKA is introduced to enhance the global information within the learning space and channels. This strategy ensures that the network maintains competitive performance even after notable parameter reductions. The small network (ARF-FQANet-S) offers remarkable advantages in terms of CPU inference time and is ideal for lightweight deployments on edge devices. Overall, the results provide a technical reference for the lightweight models.关键词:digital pathological images;focus quality assessment;amplified receptive field;attention mechanism;lightweight- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveWith the rapid advancement of medical imaging technology, medical image segmentation has become a popular topic in the field of medical image processing and has been the subject of extensive study. Medical image segmentation has a wide range of applications and research values in medical research and practice. The segmentation results of medical images can be used by physicians to determine the location, size, and shape of lesions, providing an accurate basis for diagnosis and treatment. In recent years, UNet based on convolutional neural networks (CNNs) has become a baseline architecture for medical image segmentation. However, this architecture cannot effectively extract global context information due to the limited receptive field of CNNs. The Transformer was originally designed to solve this problem but was limited in capturing local information. Therefore, hybrid networks of CNN and Transformer based on UNet architecture are gradually becoming popular. However, existing methods encounter some shortcomings. For example, these methods typically cannot effectively combine the global and local information extracted by CNN and Transformer. By contrast, while the original skip connection can recover some location information lost by the target features in the downsampling stage, this connection may fail to capture all the fine-grained details, ultimately affecting the accuracy of the predicted segmentation. This paper proposes a dual-encoder global-local cross-attention network with CNN and Transformer (DGLCANet) to address these issues.MethodFirst, a dual-encoder network is adopted to extract rich local and global information from the images, which combines the advantages of CNNs and Transformer networks. In the encoder stage, Transformer and CNN branches are used to extract global and local information, respectively. In addition, the CSWin Transformer with low calculation costs is used in the Transformer branch to reduce the calculation cost of the model. Next, a global-local cross-attention Transformer module is proposed to fully utilize the global and local information extracted by the dual-encoder branch. The core of this module is the cross-attention mechanism, which can further obtain the correlation between global and local features by interacting the information of the two branches. Finally, a feature adaptation block is designed in the skip connection of DGLCANet to compensate for the shortcomings of the original skip connections. The feature adaptation module aims to adaptively match the features between the encoder and decoder, reducing the feature gap between them and improving the adaptive capability of the model. Meanwhile, the module can also recover detailed positional information lost during the encoder downsampling process. Tests are performed on four public datasets, including ISIC-2017, ISIC-2018, BUSI, and the 2018 Data Science Bowl. Among them, ISIC-2017 and ISIC-2018 are used for dermoscopic images of melanoma detection, containing 2 000 and 2 596 images, respectively. The BUSI dataset, which contains 780 images, is a breast ultrasound dataset for detecting breast cancer. The 2018 Data Science Bowl dataset, which contains a total of 670 images, is used for examining cell nuclei in different microscope images. The resolution of all images is set to 256 × 256 pixels and randomly divided into training and test sets according to the ratio of 8∶2. DGLCANet is implemented in the PyTorch framework and was trained on an NVIDIA GeForce RTX 3090Ti GPU with 24 GB of memory. In the experiment, the binary cross-entropy and dice loss functions are mixed in proportion to construct a new loss function. Furthermore, the Adam optimizer with an initial learning rate of 0.001, a momentum parameter of 0.9, and a weight decay of 0.000 1 is employed.ResultIn this study, four evaluation metrics, including intersection over union, Dice coefficient (Dice), accuracy, and recall, are used to evaluate the effectiveness of the proposed method. In theory, large values of these evaluation metrics lead to superior segmentation effects. Experimental results show that on the four datasets, the dice coefficient reaches 91.88%, 90.82%, 80.71%, and 92.25%, which are 5.87%, 5.37%, 4.65%, and 2.92% higher than the classic method UNet, respectively. Compared with recent state-of-the-art methods, the proposed method also demonstrates its superiority. Furthermore, the graph of the visualized results demonstrates that the proposed method effectively predicts the boundary area of the image and distinguishes the lesion area from the normal area. Meanwhile, compared with other methods, the proposed method can still achieve better segmentation results under the condition of multiple interference factors such as brightness, which are remarkably close to the ground truth. The results of a series of ablation experiments also show that each of the proposed components demonstrates satisfactory performance.ConclusionIn this study, a dual-encoder medical image segmentation method that integrates global-local attention mechanism is proposed. The experimental results demonstrate that the proposed method not only improves segmentation accuracy but also obtains satisfactory segmentation results when processing complex medical images. Future work will focus on further optimization and in-depth research to promote the practical application of this method and will contribute to important breakthroughs and advancements in the field of medical image segmentation.关键词:medical image segmentation;convolutional neural network(CNN);dual-encoder;cross attention mechanism;Transformer
摘要:ObjectiveWith the rapid advancement of medical imaging technology, medical image segmentation has become a popular topic in the field of medical image processing and has been the subject of extensive study. Medical image segmentation has a wide range of applications and research values in medical research and practice. The segmentation results of medical images can be used by physicians to determine the location, size, and shape of lesions, providing an accurate basis for diagnosis and treatment. In recent years, UNet based on convolutional neural networks (CNNs) has become a baseline architecture for medical image segmentation. However, this architecture cannot effectively extract global context information due to the limited receptive field of CNNs. The Transformer was originally designed to solve this problem but was limited in capturing local information. Therefore, hybrid networks of CNN and Transformer based on UNet architecture are gradually becoming popular. However, existing methods encounter some shortcomings. For example, these methods typically cannot effectively combine the global and local information extracted by CNN and Transformer. By contrast, while the original skip connection can recover some location information lost by the target features in the downsampling stage, this connection may fail to capture all the fine-grained details, ultimately affecting the accuracy of the predicted segmentation. This paper proposes a dual-encoder global-local cross-attention network with CNN and Transformer (DGLCANet) to address these issues.MethodFirst, a dual-encoder network is adopted to extract rich local and global information from the images, which combines the advantages of CNNs and Transformer networks. In the encoder stage, Transformer and CNN branches are used to extract global and local information, respectively. In addition, the CSWin Transformer with low calculation costs is used in the Transformer branch to reduce the calculation cost of the model. Next, a global-local cross-attention Transformer module is proposed to fully utilize the global and local information extracted by the dual-encoder branch. The core of this module is the cross-attention mechanism, which can further obtain the correlation between global and local features by interacting the information of the two branches. Finally, a feature adaptation block is designed in the skip connection of DGLCANet to compensate for the shortcomings of the original skip connections. The feature adaptation module aims to adaptively match the features between the encoder and decoder, reducing the feature gap between them and improving the adaptive capability of the model. Meanwhile, the module can also recover detailed positional information lost during the encoder downsampling process. Tests are performed on four public datasets, including ISIC-2017, ISIC-2018, BUSI, and the 2018 Data Science Bowl. Among them, ISIC-2017 and ISIC-2018 are used for dermoscopic images of melanoma detection, containing 2 000 and 2 596 images, respectively. The BUSI dataset, which contains 780 images, is a breast ultrasound dataset for detecting breast cancer. The 2018 Data Science Bowl dataset, which contains a total of 670 images, is used for examining cell nuclei in different microscope images. The resolution of all images is set to 256 × 256 pixels and randomly divided into training and test sets according to the ratio of 8∶2. DGLCANet is implemented in the PyTorch framework and was trained on an NVIDIA GeForce RTX 3090Ti GPU with 24 GB of memory. In the experiment, the binary cross-entropy and dice loss functions are mixed in proportion to construct a new loss function. Furthermore, the Adam optimizer with an initial learning rate of 0.001, a momentum parameter of 0.9, and a weight decay of 0.000 1 is employed.ResultIn this study, four evaluation metrics, including intersection over union, Dice coefficient (Dice), accuracy, and recall, are used to evaluate the effectiveness of the proposed method. In theory, large values of these evaluation metrics lead to superior segmentation effects. Experimental results show that on the four datasets, the dice coefficient reaches 91.88%, 90.82%, 80.71%, and 92.25%, which are 5.87%, 5.37%, 4.65%, and 2.92% higher than the classic method UNet, respectively. Compared with recent state-of-the-art methods, the proposed method also demonstrates its superiority. Furthermore, the graph of the visualized results demonstrates that the proposed method effectively predicts the boundary area of the image and distinguishes the lesion area from the normal area. Meanwhile, compared with other methods, the proposed method can still achieve better segmentation results under the condition of multiple interference factors such as brightness, which are remarkably close to the ground truth. The results of a series of ablation experiments also show that each of the proposed components demonstrates satisfactory performance.ConclusionIn this study, a dual-encoder medical image segmentation method that integrates global-local attention mechanism is proposed. The experimental results demonstrate that the proposed method not only improves segmentation accuracy but also obtains satisfactory segmentation results when processing complex medical images. Future work will focus on further optimization and in-depth research to promote the practical application of this method and will contribute to important breakthroughs and advancements in the field of medical image segmentation.关键词:medical image segmentation;convolutional neural network(CNN);dual-encoder;cross attention mechanism;Transformer- 2
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveDepression is currently one of the most common neuropsychiatric disorders in the world. However, its pathophysiological mechanisms are still unclear. The diagnosis of depression in clinical practice typically depends on neuropsychological scores and treatment responses, lacking objective evaluation tools, resulting in low consistency in diagnosis. In recent years, an increasing number of people have begun to use machine learning technology to extract imaging biomarkers for the intelligent diagnosis of depression due to the capability of functional magnetic resonance imaging to provide in vivo brain function and structural information. The brain network-based model has remarkable potential as an imaging marker for effectively distinguishing depression from normal controls. Graph neural networks (GNNs) are highly suitable for graph classification tasks because they directly acquire graph structure information and maintain the topological characteristics of the graph during task execution. However, most GNN studies only model a single space (sample or feature space), and the aggregation of GNN information can lead to over-smooth effects, resulting in poor model classification performance. This study aims to integrate multiple feature space information and propose a multispace fusion algorithm for the intelligent diagnosis of depression patients.MethodLeave-one-site cross-validation (LOSCV) is used to ensure the generalization of the model. The data are first preprocessed, and then a brain network is constructed using Pearson-related functional connectivity methods. The entire algorithm is mainly based on a genetic algorithm (GA), where the fitness function is a classification algorithm based on a graph convolutional network (GCN). The solution space searched by GA is the similarity between the subject networks. The main steps of GA are as follows: 1) Set the search range of the solution space [0.05, 0.7]; 2) Generate an initial population; 3) Based on LOSCV, GCN is used to classify the data, with the F1 value as the target value of the fitness function, and the threshold with the best fitness is finally retained (representing A *); 4) Generate new populations through selection, crossover, and mutation operations (representing A); 5) Compare A with A *. If the fitness value of A is better than A *, then A replaces A *; 6) Determine whether the number of iterations for updating the population has reached the preset value. If not, then proceed to step 3 and continue executing the algorithm; if the threshold is reached, then the algorithm ends. The GA has a chromosome length of 8 bits and a threshold of 20 iterations. This paper aims to determine the similarity threshold between individuals with the highest classification capability in the population network. The GCN module comprises two networks connected in series: one mainly obtains information regarding the feature space of the brain network of a single subject, while the other network takes the subject as a node in the network. All subjects form a network to extract information from the sample space. The classification of a certain subject can be achieved through the joint learning of two levels of GCN. The two-level GCN architecture mainly includes f-GCN and p-GCN, and the basic ideas for constructing each architecture are as follows: f-GCN is a potential information representation for learning the connectivity relationships of each brain region and transforming it into a highly efficient information representation for each brain network. F-GCN uses GCN to learn the embedding representation of a single brain region and then uses Eigenpooling to embed all brain region nodes into a single supernode to represent the information representation of the entire brain network. Eigenpooling is a pooling method in graph convolution neural network (GCN), which uses the eigenvectors of the Laplacian matrix to represent the information of nodes, transforms the original graph nodes into coordinates in the feature space, and associates each node with a specific number of high-energy eigenvectors, which are determined by the eigenvalues of the Laplacian matrix. The feature vector represents the position of a node in the feature space, and its corresponding feature values indicate node importance. P-GCN constructs a topological structure based on the relationship between subject brain networks and the representation of graph information acquired by f-GCN. The graph convolutional kernel aggregates the information representations of adjacent node entities of the subject and further reduces the dimensionality of the node information representation through graph pooling to generate the current supernode information representation. In this case, the hypernode represents the information of the entity as a whole. The graph information of the entire subject can be accurately represented through this super node, and the parameters of the f-GCN and p-GCN can be jointly updated through backpropagation to improve recognition accuracy. A scaled exponential similarity kernel is used for p-GCN to determine the similarity between samples.ResultAll data came from the REST-meta-MDD project, and a total of 1160 functional magnetic resonance imaging data from 10 sites (male 434, female 726) were included in this experiment. The experiment is a comparison of four representative algorithms of different types. The algorithm achieved the highest accuracy of 64.27%, which is 4.47% higher than the second-place support vector machine (SVM). Based on the BrainNetCNN method, the accuracy is only 56.69%, demonstrating the worst classification performance. The accuracy of the Graphormer is 57.43%, and the hierarchical GCN also adopts the fusion of two networks, resulting in a classification accuracy of 58.28%. The sample similarity threshold also impacts the final result, with an interval of 0.4–0.5 during identification of the optimal solution.ConclusionThe intelligent diagnosis framework for depression based on GA and GCN proposed in this article combines the advantages of traditional and deep learning models. The results show that the proposed algorithm is not only superior to traditional machine learning algorithms (such as SVM), but also better than several mainstream GCN algorithms, with good generalization. This algorithm is likely to provide important information for clinical depression diagnosis in the future.关键词:major disorder depression;graph convolutional network(GCN);intelligent diagnosis;fusion algorithm;individual similarity
摘要:ObjectiveDepression is currently one of the most common neuropsychiatric disorders in the world. However, its pathophysiological mechanisms are still unclear. The diagnosis of depression in clinical practice typically depends on neuropsychological scores and treatment responses, lacking objective evaluation tools, resulting in low consistency in diagnosis. In recent years, an increasing number of people have begun to use machine learning technology to extract imaging biomarkers for the intelligent diagnosis of depression due to the capability of functional magnetic resonance imaging to provide in vivo brain function and structural information. The brain network-based model has remarkable potential as an imaging marker for effectively distinguishing depression from normal controls. Graph neural networks (GNNs) are highly suitable for graph classification tasks because they directly acquire graph structure information and maintain the topological characteristics of the graph during task execution. However, most GNN studies only model a single space (sample or feature space), and the aggregation of GNN information can lead to over-smooth effects, resulting in poor model classification performance. This study aims to integrate multiple feature space information and propose a multispace fusion algorithm for the intelligent diagnosis of depression patients.MethodLeave-one-site cross-validation (LOSCV) is used to ensure the generalization of the model. The data are first preprocessed, and then a brain network is constructed using Pearson-related functional connectivity methods. The entire algorithm is mainly based on a genetic algorithm (GA), where the fitness function is a classification algorithm based on a graph convolutional network (GCN). The solution space searched by GA is the similarity between the subject networks. The main steps of GA are as follows: 1) Set the search range of the solution space [0.05, 0.7]; 2) Generate an initial population; 3) Based on LOSCV, GCN is used to classify the data, with the F1 value as the target value of the fitness function, and the threshold with the best fitness is finally retained (representing A *); 4) Generate new populations through selection, crossover, and mutation operations (representing A); 5) Compare A with A *. If the fitness value of A is better than A *, then A replaces A *; 6) Determine whether the number of iterations for updating the population has reached the preset value. If not, then proceed to step 3 and continue executing the algorithm; if the threshold is reached, then the algorithm ends. The GA has a chromosome length of 8 bits and a threshold of 20 iterations. This paper aims to determine the similarity threshold between individuals with the highest classification capability in the population network. The GCN module comprises two networks connected in series: one mainly obtains information regarding the feature space of the brain network of a single subject, while the other network takes the subject as a node in the network. All subjects form a network to extract information from the sample space. The classification of a certain subject can be achieved through the joint learning of two levels of GCN. The two-level GCN architecture mainly includes f-GCN and p-GCN, and the basic ideas for constructing each architecture are as follows: f-GCN is a potential information representation for learning the connectivity relationships of each brain region and transforming it into a highly efficient information representation for each brain network. F-GCN uses GCN to learn the embedding representation of a single brain region and then uses Eigenpooling to embed all brain region nodes into a single supernode to represent the information representation of the entire brain network. Eigenpooling is a pooling method in graph convolution neural network (GCN), which uses the eigenvectors of the Laplacian matrix to represent the information of nodes, transforms the original graph nodes into coordinates in the feature space, and associates each node with a specific number of high-energy eigenvectors, which are determined by the eigenvalues of the Laplacian matrix. The feature vector represents the position of a node in the feature space, and its corresponding feature values indicate node importance. P-GCN constructs a topological structure based on the relationship between subject brain networks and the representation of graph information acquired by f-GCN. The graph convolutional kernel aggregates the information representations of adjacent node entities of the subject and further reduces the dimensionality of the node information representation through graph pooling to generate the current supernode information representation. In this case, the hypernode represents the information of the entity as a whole. The graph information of the entire subject can be accurately represented through this super node, and the parameters of the f-GCN and p-GCN can be jointly updated through backpropagation to improve recognition accuracy. A scaled exponential similarity kernel is used for p-GCN to determine the similarity between samples.ResultAll data came from the REST-meta-MDD project, and a total of 1160 functional magnetic resonance imaging data from 10 sites (male 434, female 726) were included in this experiment. The experiment is a comparison of four representative algorithms of different types. The algorithm achieved the highest accuracy of 64.27%, which is 4.47% higher than the second-place support vector machine (SVM). Based on the BrainNetCNN method, the accuracy is only 56.69%, demonstrating the worst classification performance. The accuracy of the Graphormer is 57.43%, and the hierarchical GCN also adopts the fusion of two networks, resulting in a classification accuracy of 58.28%. The sample similarity threshold also impacts the final result, with an interval of 0.4–0.5 during identification of the optimal solution.ConclusionThe intelligent diagnosis framework for depression based on GA and GCN proposed in this article combines the advantages of traditional and deep learning models. The results show that the proposed algorithm is not only superior to traditional machine learning algorithms (such as SVM), but also better than several mainstream GCN algorithms, with good generalization. This algorithm is likely to provide important information for clinical depression diagnosis in the future.关键词:major disorder depression;graph convolutional network(GCN);intelligent diagnosis;fusion algorithm;individual similarity- 1
- |
- 0
- |
- 0
发布时间:2024-11-16 -
 摘要:ObjectiveEsophageal cancer is one of the most common malignant tumors that seriously threaten human health. At present, endoscopy combined with histopathological biopsy is the “gold standard” for diagnosing early esophageal cancer. Among them, Lugol’s chromo endoscopy (LCE) has a unique advantage in gastroenterology because of its good lesion visibility, diagnostic accuracy, and low cost. However, with the rising number of patients, the imbalance between the number of doctors and patients is becoming increasingly serious. The manual diagnosis process based on endoscopic images is susceptible to several factors, such as the experience and mental state of the doctor, the limitation of diagnosis time, the enormous image base, and the complex and variable appearance of the lesion. Therefore, the clinical diagnosis of artificial esophageal lesions still has a high rate of missed diagnoses and misdiagnosis. In recent years, the application of artificial intelligence (AI) in the field of medical imaging has provided strong support for doctors, and the AI-assisted diagnosis system based on deep learning can assist doctors to accurately diagnose the location and type of lesions, reducing their burden. However, deep learning models need sufficient and high-quality data. For esophageal endoscopic images, LCE esophageal endoscopic images will inevitably be affected by the built-in light source of the acquisition device during the acquisition process. The light distribution of LCE esophageal endoscopic images will be uneven due to the limited illumination direction and angle of the built-in light source, affecting the overall quality of the images, which is unfavorable to the subsequent training of the intelligent lesion detection model. The existing low-light image enhancement algorithms are not ideal for the enhancement of LCE esophageal endoscopic images due to the special nature of LCE esophageal endoscopic images, complex illumination, color sensitivity, and lack of high-quality reference (paired or unpaired) datasets.MethodBased on the “generative” decomposition strategy of the RetinexDIP algorithm, instead of the Retinex model, this paper uses convolutional neural networks to generate image illumination and reflection components to decompose images and proposes a stable generating network (SgNet) to solve the aforementioned problem. The encoder-decoder structure is adopted in this network. The channel attention adjustment module proposed in this paper is used to adjust the feature graphs with the same number of channels in the encoder-decoder process to ensure that the corresponding feature channel weights remain consistent. This module aims to reduce the influence of irrelevant or redundant feature channels, minimize noise interference to the network, enhance the stability of the generated network, and improve the quality of the generated image. Simultaneously, a new color model, “fixed proportion light” (FPL), which independently represents the brightness and color proportion information of the image, is proposed, and the entire light enhancement process of the image is only adjusted on the brightness channel. Thus, the overall color information of LCE esophageal endoscopic images is not disordered.ResultThe effectiveness of the proposed algorithm is tested on the self-built LCE low-light image dataset, and the visual effect and objective index evaluation are compared with numerous mainstream low-light image enhancement algorithms. Two methods of quality assessment without reference images were used: the natural image quality evaluator (NIQE) and the blind/referenceless image spatial quality evaluator (BRISQUE). NIQE estimates image quality by measuring the deviation between the natural image and statistical law, which is more in line with human subjective quality evaluation. Meanwhile, the BRISQUE index can measure the degree of image distortion and estimate the quality score of the image from the brightness, contrast, sharpness, color saturation, and other factors. From the comparison results of visual effects, the proposed algorithm has advantages in color fidelity, contrast enhancement, and noise reduction. Meanwhile, from the comparison results of objective indicators, the proposed algorithm ranks first in the NIQE index and second only to the GCP algorithm in the BRISQUE index. Overall, the algorithm proposed in this paper has certain advantages in visual effect and objective index. In addition, tests on four publicly available low-light image datasets, including DICM, Fusion, LIME, and NPE, as well as the publicly available low-light endoscopic image dataset Endo4IE, show that the proposed algorithm has good performance on different datasets, especially for the complex low-light characteristics of endoscopic images.ConclusionThe SgNet network proposed in this paper effectively utilizes the feature channel weight information in the encoder-decoder process to improve the quality of the generated image. The illumination and reflection components of the image can be effectively generated without the need for a low-light–normal-light image pair. The proposed FPL color model can effectively ensure that the overall color information of LCE esophageal endoscopic images is not disorganized during the enhancement process. According to the experimental results, the proposed algorithm not only enhances the brightness of LCE esophageal endoscopy images but also effectively maintains the color and texture details of the images, which can help doctors observe the lesion tissue structure and details, improve diagnostic accuracy, and provide high-quality image data for the subsequent intelligent detection of lesions.关键词:image enhancement;Lugol’s chromo endoscopy(LCE);Retinex model;image generation;color model
摘要:ObjectiveEsophageal cancer is one of the most common malignant tumors that seriously threaten human health. At present, endoscopy combined with histopathological biopsy is the “gold standard” for diagnosing early esophageal cancer. Among them, Lugol’s chromo endoscopy (LCE) has a unique advantage in gastroenterology because of its good lesion visibility, diagnostic accuracy, and low cost. However, with the rising number of patients, the imbalance between the number of doctors and patients is becoming increasingly serious. The manual diagnosis process based on endoscopic images is susceptible to several factors, such as the experience and mental state of the doctor, the limitation of diagnosis time, the enormous image base, and the complex and variable appearance of the lesion. Therefore, the clinical diagnosis of artificial esophageal lesions still has a high rate of missed diagnoses and misdiagnosis. In recent years, the application of artificial intelligence (AI) in the field of medical imaging has provided strong support for doctors, and the AI-assisted diagnosis system based on deep learning can assist doctors to accurately diagnose the location and type of lesions, reducing their burden. However, deep learning models need sufficient and high-quality data. For esophageal endoscopic images, LCE esophageal endoscopic images will inevitably be affected by the built-in light source of the acquisition device during the acquisition process. The light distribution of LCE esophageal endoscopic images will be uneven due to the limited illumination direction and angle of the built-in light source, affecting the overall quality of the images, which is unfavorable to the subsequent training of the intelligent lesion detection model. The existing low-light image enhancement algorithms are not ideal for the enhancement of LCE esophageal endoscopic images due to the special nature of LCE esophageal endoscopic images, complex illumination, color sensitivity, and lack of high-quality reference (paired or unpaired) datasets.MethodBased on the “generative” decomposition strategy of the RetinexDIP algorithm, instead of the Retinex model, this paper uses convolutional neural networks to generate image illumination and reflection components to decompose images and proposes a stable generating network (SgNet) to solve the aforementioned problem. The encoder-decoder structure is adopted in this network. The channel attention adjustment module proposed in this paper is used to adjust the feature graphs with the same number of channels in the encoder-decoder process to ensure that the corresponding feature channel weights remain consistent. This module aims to reduce the influence of irrelevant or redundant feature channels, minimize noise interference to the network, enhance the stability of the generated network, and improve the quality of the generated image. Simultaneously, a new color model, “fixed proportion light” (FPL), which independently represents the brightness and color proportion information of the image, is proposed, and the entire light enhancement process of the image is only adjusted on the brightness channel. Thus, the overall color information of LCE esophageal endoscopic images is not disordered.ResultThe effectiveness of the proposed algorithm is tested on the self-built LCE low-light image dataset, and the visual effect and objective index evaluation are compared with numerous mainstream low-light image enhancement algorithms. Two methods of quality assessment without reference images were used: the natural image quality evaluator (NIQE) and the blind/referenceless image spatial quality evaluator (BRISQUE). NIQE estimates image quality by measuring the deviation between the natural image and statistical law, which is more in line with human subjective quality evaluation. Meanwhile, the BRISQUE index can measure the degree of image distortion and estimate the quality score of the image from the brightness, contrast, sharpness, color saturation, and other factors. From the comparison results of visual effects, the proposed algorithm has advantages in color fidelity, contrast enhancement, and noise reduction. Meanwhile, from the comparison results of objective indicators, the proposed algorithm ranks first in the NIQE index and second only to the GCP algorithm in the BRISQUE index. Overall, the algorithm proposed in this paper has certain advantages in visual effect and objective index. In addition, tests on four publicly available low-light image datasets, including DICM, Fusion, LIME, and NPE, as well as the publicly available low-light endoscopic image dataset Endo4IE, show that the proposed algorithm has good performance on different datasets, especially for the complex low-light characteristics of endoscopic images.ConclusionThe SgNet network proposed in this paper effectively utilizes the feature channel weight information in the encoder-decoder process to improve the quality of the generated image. The illumination and reflection components of the image can be effectively generated without the need for a low-light–normal-light image pair. The proposed FPL color model can effectively ensure that the overall color information of LCE esophageal endoscopic images is not disorganized during the enhancement process. According to the experimental results, the proposed algorithm not only enhances the brightness of LCE esophageal endoscopy images but also effectively maintains the color and texture details of the images, which can help doctors observe the lesion tissue structure and details, improve diagnostic accuracy, and provide high-quality image data for the subsequent intelligent detection of lesions.关键词:image enhancement;Lugol’s chromo endoscopy(LCE);Retinex model;image generation;color model- 2
- |
- 0
- |
- 0
发布时间:2024-11-16
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0