
最新刊期
2024 年 第 29 卷 第 8 期

-
 摘要:热红外高光谱遥感影像蕴含着丰富的光谱特性和温度信息,能够反映出地物、气体等特有的诊断特征,在矿物识别、环境监测和军事等众多领域发挥着重要作用。然而,由于热红外高光谱观测数据受到地表温度和发射率、大气环境和仪器测量噪声等共同影响,引起背景噪声与目标信号差异较小、耦合信号无法精确分离等问题,使得热红外高光谱影像信息提取存在巨大的挑战,难以有效实施应用。针对热红外高光谱信息提取的研究进展和现存难点,本文系统梳理了热红外高光谱影像信息提取方法,主要包括地表温度和发射率地表参量反演、热红外高光谱混合光谱分解、影像分类及目标探测。在此基础上,总结现有热红外高光谱信息提取的现状和问题,包括高光谱丰富光谱信息在地气参数反演方面尚未得到充分的利用,基于深度学习理论实现热红外高光谱地表参量反演及混合像元分解、地物分类、目标探测应用仍处于起步阶段且面临数据集匮乏。如何充分利用热红外高光谱密集通道,融合物理模型和深度学习理论实现智能化、高精度的地气参数一体化反演,并在此基础上进行热红外高光谱混合像元分解、地物分类、目标探测是热红外高光谱遥感影像信息提取未来可能的发展趋势和研究方向。关键词:热红外高光谱;地表参量反演;混合光谱分解;影像分类;目标探测1406|1654|0更新时间:2024-08-13
摘要:热红外高光谱遥感影像蕴含着丰富的光谱特性和温度信息,能够反映出地物、气体等特有的诊断特征,在矿物识别、环境监测和军事等众多领域发挥着重要作用。然而,由于热红外高光谱观测数据受到地表温度和发射率、大气环境和仪器测量噪声等共同影响,引起背景噪声与目标信号差异较小、耦合信号无法精确分离等问题,使得热红外高光谱影像信息提取存在巨大的挑战,难以有效实施应用。针对热红外高光谱信息提取的研究进展和现存难点,本文系统梳理了热红外高光谱影像信息提取方法,主要包括地表温度和发射率地表参量反演、热红外高光谱混合光谱分解、影像分类及目标探测。在此基础上,总结现有热红外高光谱信息提取的现状和问题,包括高光谱丰富光谱信息在地气参数反演方面尚未得到充分的利用,基于深度学习理论实现热红外高光谱地表参量反演及混合像元分解、地物分类、目标探测应用仍处于起步阶段且面临数据集匮乏。如何充分利用热红外高光谱密集通道,融合物理模型和深度学习理论实现智能化、高精度的地气参数一体化反演,并在此基础上进行热红外高光谱混合像元分解、地物分类、目标探测是热红外高光谱遥感影像信息提取未来可能的发展趋势和研究方向。关键词:热红外高光谱;地表参量反演;混合光谱分解;影像分类;目标探测1406|1654|0更新时间:2024-08-13 -
 摘要:光谱图像超分辨率技术的目的是从低空间分辨率和光谱分辨率的图像中恢复高空间分辨率和光谱分辨率的图像,在植被调查、地质勘探、环境保护、异常检测和目标追踪等遥感领域有着广泛应用。随着深度学习的兴起,基于深度学习的光谱图像超分辨率算法如雨后春笋般涌现,特别是卷积神经网络、Transformer、生成对抗网络以及深度展开网络等技术的出现使图像融合性能产生了质的飞跃。本文全面探讨和分析了不同光谱图像超分辨率任务场景下的前沿深度学习算法。首先,介绍了光谱图像超分辨率的基本概念,以及不同超分辨率场景的定义。针对单图超分辨率和融合超分辨率两大场景,从超分辨率维度、数据类型、基本框架和监督方式等多个角度详细阐述了各类方法的基本思想和特点。其次,总结了各类算法存在的局限性,并提出了进一步改进的方向。然后,简要介绍了不同融合场景中常用的数据集,并明确了各种评估指标的具体定义。对于每种超分辨率任务,从定性评估、定量评估等多个角度全面比较了代表性算法的性能。最后,总结了研究结果,并探讨了光谱图像超分辨率领域所面临的一些严峻挑战,同时对未来可能的研究方向进行了展望。所提及的算法和数据集已汇总至https://github.com/ColinTaoZhang/DL-based-spectral-super-resolution。关键词:深度学习;超分辨率;光谱图像;单图超分辨率;融合超分辨率2064|3135|0更新时间:2024-08-13
摘要:光谱图像超分辨率技术的目的是从低空间分辨率和光谱分辨率的图像中恢复高空间分辨率和光谱分辨率的图像,在植被调查、地质勘探、环境保护、异常检测和目标追踪等遥感领域有着广泛应用。随着深度学习的兴起,基于深度学习的光谱图像超分辨率算法如雨后春笋般涌现,特别是卷积神经网络、Transformer、生成对抗网络以及深度展开网络等技术的出现使图像融合性能产生了质的飞跃。本文全面探讨和分析了不同光谱图像超分辨率任务场景下的前沿深度学习算法。首先,介绍了光谱图像超分辨率的基本概念,以及不同超分辨率场景的定义。针对单图超分辨率和融合超分辨率两大场景,从超分辨率维度、数据类型、基本框架和监督方式等多个角度详细阐述了各类方法的基本思想和特点。其次,总结了各类算法存在的局限性,并提出了进一步改进的方向。然后,简要介绍了不同融合场景中常用的数据集,并明确了各种评估指标的具体定义。对于每种超分辨率任务,从定性评估、定量评估等多个角度全面比较了代表性算法的性能。最后,总结了研究结果,并探讨了光谱图像超分辨率领域所面临的一些严峻挑战,同时对未来可能的研究方向进行了展望。所提及的算法和数据集已汇总至https://github.com/ColinTaoZhang/DL-based-spectral-super-resolution。关键词:深度学习;超分辨率;光谱图像;单图超分辨率;融合超分辨率2064|3135|0更新时间:2024-08-13 -
 摘要:随着对地观测技术的不断发展,从星载、机载和地面平台上众多的一体化立体观测设施被发射,这些传感器设备可以动态提供不同空间、时间和光谱分辨率的多模态遥感图像,只有充分利用各类多模态遥感图像才能有效地为自然资源管理、防灾减灾和环境监测等不同应用提供更可靠和全面的对地观测结果。但是由于不同传感器之间的成像机理不同,多模态图像之间呈现显著的辐射差异、几何差异、时相差异和视角差异等,给多模态遥感图像高精度的配准带来了巨大的挑战。为推进多模态遥感图像配准研究技术的发展,本文对当前主流的多模态遥感图像配准方法系统性地进行了梳理、分析、介绍和总结。首先梳理了单模态到多模态遥感图像配准的研究发展演化过程;然后分别分析了基于区域、基于特征和基于深度学习方法中代表性算法的核心思想,并给出已开源代码的链接;同时分享了现有公开的多模态遥感图像配准数据集,介绍了数据集的详细内容和特点;最后给出了现阶段多模态遥感图像高精度配准研究中所存在的一些问题和严峻挑战,并对未来研究的发展趋势进行了前瞻性的展望,旨在推动多模态遥感图像配准领域实现更加深入的突破和创新。关键词:遥感;传感器;多模态图像;图像配准;配准数据集2950|6070|3更新时间:2024-08-13
摘要:随着对地观测技术的不断发展,从星载、机载和地面平台上众多的一体化立体观测设施被发射,这些传感器设备可以动态提供不同空间、时间和光谱分辨率的多模态遥感图像,只有充分利用各类多模态遥感图像才能有效地为自然资源管理、防灾减灾和环境监测等不同应用提供更可靠和全面的对地观测结果。但是由于不同传感器之间的成像机理不同,多模态图像之间呈现显著的辐射差异、几何差异、时相差异和视角差异等,给多模态遥感图像高精度的配准带来了巨大的挑战。为推进多模态遥感图像配准研究技术的发展,本文对当前主流的多模态遥感图像配准方法系统性地进行了梳理、分析、介绍和总结。首先梳理了单模态到多模态遥感图像配准的研究发展演化过程;然后分别分析了基于区域、基于特征和基于深度学习方法中代表性算法的核心思想,并给出已开源代码的链接;同时分享了现有公开的多模态遥感图像配准数据集,介绍了数据集的详细内容和特点;最后给出了现阶段多模态遥感图像高精度配准研究中所存在的一些问题和严峻挑战,并对未来研究的发展趋势进行了前瞻性的展望,旨在推动多模态遥感图像配准领域实现更加深入的突破和创新。关键词:遥感;传感器;多模态图像;图像配准;配准数据集2950|6070|3更新时间:2024-08-13 -
 摘要:目的海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。方法受到自然环境和人为因素的共同影响,海岸带外部形态变化快,目前的卫星遥感和常规的人工测量、船载作业等监测方式已难以满足实时观测的要求。因此本文首先利用无人机对海岸带典型生态群落进行拍摄、采集和标注,构建了面向海岸带生态系统的基准数据集,名为OUC-UAV-SEG。接着,通过统计的方法,对OUC-UAV-SEG进行定量分析,并对数据集中存在的挑战进行了深入探讨。最后,使用典型视觉语义分割算法对OUC-UAV-SEG展开评估。结果对OUC-UAV-SEG数据集进行了基准测试,评估了当前可用的语义分割算法在该数据集上的性能,并揭示了这些算法的局限性。结论OUC-UAV-SEG数据集的建立为海岸带生态系统的监测提供了新的资源,有助于科学家、生态学家和决策者们更好地了解海岸带生态系统的现状和变化趋势,为海洋生态保护和管理提供更精确的信息。该数据集链接:https://github.com/OucCVLab/OUC-UAV-SEG。关键词:海岸带生态系统;遥感;无人机(UAV);基准数据集;语义分割1012|1060|1更新时间:2024-08-13
摘要:目的海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。方法受到自然环境和人为因素的共同影响,海岸带外部形态变化快,目前的卫星遥感和常规的人工测量、船载作业等监测方式已难以满足实时观测的要求。因此本文首先利用无人机对海岸带典型生态群落进行拍摄、采集和标注,构建了面向海岸带生态系统的基准数据集,名为OUC-UAV-SEG。接着,通过统计的方法,对OUC-UAV-SEG进行定量分析,并对数据集中存在的挑战进行了深入探讨。最后,使用典型视觉语义分割算法对OUC-UAV-SEG展开评估。结果对OUC-UAV-SEG数据集进行了基准测试,评估了当前可用的语义分割算法在该数据集上的性能,并揭示了这些算法的局限性。结论OUC-UAV-SEG数据集的建立为海岸带生态系统的监测提供了新的资源,有助于科学家、生态学家和决策者们更好地了解海岸带生态系统的现状和变化趋势,为海洋生态保护和管理提供更精确的信息。该数据集链接:https://github.com/OucCVLab/OUC-UAV-SEG。关键词:海岸带生态系统;遥感;无人机(UAV);基准数据集;语义分割1012|1060|1更新时间:2024-08-13 -
 摘要:目的高光谱图像分类可实现对地物目标的逐像素识别,是对地观测中的关键技术。由于采集环境变迁与成像设备差异等因素的影响,不同高光谱图像特征分布偏移,影响现有模型的跨数据集分类精度。针对此,提出了一种融合特征优化的无监督跨数据集高光谱图像分类方法。方法提出了基于奇异值抑制的特征均衡策略实现数据内独立优化,通过限制奇异值正则项兼顾特征的可迁移性与可鉴别性;提出了基于隐式增广的特征匹配策略实现数据间特征协同优化,引导源域特征逼近目标域提高模型的泛化性;设计了基于隐式鉴别器的对抗学习框架实现数据间特征类别级优化,提高了预测多样性,实现跨数据集分类。结果实验在Pavia数据集组和HyRANK数据集组上进行,与多种最新的跨数据高光谱图像分类方法进行了对比,在Pavia数据集组中,相比于性能第2的模型,总体精度、平均精度和к系数分别提高了1.75%、3.55%和2.17%;在HyRANK数据集组中,相比于性能第2的模型,总体精度、平均精度和к系数分别提高了6.58%、13.10%和7.96%。同时进行了消融实验,研究了各个模块对高光谱图像分类效果的影响。实验结果表明,每一模块在提高高光谱图像分类效果方面都是有效的。结论本文提出的融合特征优化的跨数据集高光谱图像分类方法可以在无监督的条件下显著提高跨数据集高光谱图像分类精度,提高分类预测的多样性,得到更好的分类效果。关键词:高光谱图像分类;跨数据集分类;特征优化;领域自适应;无监督分类;域对抗网络563|1162|0更新时间:2024-08-13
摘要:目的高光谱图像分类可实现对地物目标的逐像素识别,是对地观测中的关键技术。由于采集环境变迁与成像设备差异等因素的影响,不同高光谱图像特征分布偏移,影响现有模型的跨数据集分类精度。针对此,提出了一种融合特征优化的无监督跨数据集高光谱图像分类方法。方法提出了基于奇异值抑制的特征均衡策略实现数据内独立优化,通过限制奇异值正则项兼顾特征的可迁移性与可鉴别性;提出了基于隐式增广的特征匹配策略实现数据间特征协同优化,引导源域特征逼近目标域提高模型的泛化性;设计了基于隐式鉴别器的对抗学习框架实现数据间特征类别级优化,提高了预测多样性,实现跨数据集分类。结果实验在Pavia数据集组和HyRANK数据集组上进行,与多种最新的跨数据高光谱图像分类方法进行了对比,在Pavia数据集组中,相比于性能第2的模型,总体精度、平均精度和к系数分别提高了1.75%、3.55%和2.17%;在HyRANK数据集组中,相比于性能第2的模型,总体精度、平均精度和к系数分别提高了6.58%、13.10%和7.96%。同时进行了消融实验,研究了各个模块对高光谱图像分类效果的影响。实验结果表明,每一模块在提高高光谱图像分类效果方面都是有效的。结论本文提出的融合特征优化的跨数据集高光谱图像分类方法可以在无监督的条件下显著提高跨数据集高光谱图像分类精度,提高分类预测的多样性,得到更好的分类效果。关键词:高光谱图像分类;跨数据集分类;特征优化;领域自适应;无监督分类;域对抗网络563|1162|0更新时间:2024-08-13 -
 摘要:目的异质遥感图像由不同类型的传感器所获取,在数据结构、分辨率及辐射特性上均存在巨大差异。变化检测任务旨在通过分析在不同时间获取的同一目标区域的图像来检测地表覆盖物变化,然而异质遥感图像的数据异构特性会使得变化检测过程更加困难。针对这个问题,提出了一种嵌入聚类分析的双边对抗自编码网络来实现异质遥感图像地物变化的精确检测。方法构造双边对抗自编码网络对异质遥感图像进行重构和风格转换,通过结构一致性损失和对抗损失对网络训练进行约束,迫使网络将异质图像转换到公共数据域。考虑到变化区域像素对于对抗损失函数在网络优化中的不利影响,对映射到公共数据域的两对同质图像进行聚类分析,基于此提出一种新的语义信息约束的对抗损失函数,迫使网络生成具有更加一致风格的图像。结果在4组典型的异质遥感图像数据集上对提出的变化检测网络性能进行测试,在Italy数据集、California数据集、Tianhe数据集以及Shuguang数据集上的总体检测精度分别达到0.970 5、0.938 2、0.994 7以及0.982 6。与现有的传统以及深度学习方法对比,提出算法在视觉及定量分析结果上均取得了较好的检测性能。结论针对异质遥感图像变化检测所要面临的由环境、数据异构等因素造成的检测困难、错检率高的问题,提出的基于双边对抗自编码网络的无监督异质遥感图像变化检测方法,既可以实现变化检测过程完全无监督,又充分利用网络特性和语义信息,提高了变化检测性能。关键词:域转换;聚类分析;语义信息;无监督变化检测;异质遥感图像403|686|0更新时间:2024-08-13
摘要:目的异质遥感图像由不同类型的传感器所获取,在数据结构、分辨率及辐射特性上均存在巨大差异。变化检测任务旨在通过分析在不同时间获取的同一目标区域的图像来检测地表覆盖物变化,然而异质遥感图像的数据异构特性会使得变化检测过程更加困难。针对这个问题,提出了一种嵌入聚类分析的双边对抗自编码网络来实现异质遥感图像地物变化的精确检测。方法构造双边对抗自编码网络对异质遥感图像进行重构和风格转换,通过结构一致性损失和对抗损失对网络训练进行约束,迫使网络将异质图像转换到公共数据域。考虑到变化区域像素对于对抗损失函数在网络优化中的不利影响,对映射到公共数据域的两对同质图像进行聚类分析,基于此提出一种新的语义信息约束的对抗损失函数,迫使网络生成具有更加一致风格的图像。结果在4组典型的异质遥感图像数据集上对提出的变化检测网络性能进行测试,在Italy数据集、California数据集、Tianhe数据集以及Shuguang数据集上的总体检测精度分别达到0.970 5、0.938 2、0.994 7以及0.982 6。与现有的传统以及深度学习方法对比,提出算法在视觉及定量分析结果上均取得了较好的检测性能。结论针对异质遥感图像变化检测所要面临的由环境、数据异构等因素造成的检测困难、错检率高的问题,提出的基于双边对抗自编码网络的无监督异质遥感图像变化检测方法,既可以实现变化检测过程完全无监督,又充分利用网络特性和语义信息,提高了变化检测性能。关键词:域转换;聚类分析;语义信息;无监督变化检测;异质遥感图像403|686|0更新时间:2024-08-13 -
 摘要:目的现有场景分类方法主要面向高空间分辨率图像,但这些图像包含极为有限的光谱信息,且现有基于卷积神经网络(convolutional neural network,CNN)的方法由于卷积操作的局部性忽略了远程上下文信息的捕获。针对上述问题,提出了一种面向高光谱场景分类的空—谱模型蒸馏网络(spatial-spectral model distillation network for hyperspectral scene classification,SSMD)。方法选择基于空—谱注意力的ViT方法(spatial-spectral vision Transformer,SSViT)探测不同类别的光谱信息,通过寻找光谱信息之间的差异性对地物进行精细分类。利用知识蒸馏将教师模型SSViT捕获的长距离依赖信息传递给学生模型VGG16(Visual Geometry Group 16)进行学习,二者协同合作,教师模型提取的光谱信息和全局信息与学生模型提取的局部信息融合,进一步提升学生分类性能并保持较低的时间代价。结果实验在3个数据集上与10种分类方法(5种传统CNN分类方法和5种较新场景分类方法)进行了比较。综合考虑时间成本和分类精度,本文方法在不同数据集上取得了不同程度的领先。在OHID-SC(Orbita hyperspectral image scene classification dataset)、OHS-SC(Orbita hyperspectral scene classification dataset)和HSRS-SC(hyperspectral remote sensing dataset for scene classification)数据集上的精度,相比于性能第2的模型,分类精度分别提高了13.1%、2.9%和0.74%。同时在OHID-SC数据集中进行的对比实验表明提出的算法有效提高了高光谱场景分类精度。结论提出的SSMD网络不仅有效利用高光谱数据目标光谱信息,并探索全局与局部间的特征关系,综合了传统模型和深度学习模型的优点,使分类结果更加准确。关键词:高光谱场景分类;卷积神经网络(CNN);Transformer;空—谱联合自注意力机制;知识蒸馏(KD)276|855|0更新时间:2024-08-13
摘要:目的现有场景分类方法主要面向高空间分辨率图像,但这些图像包含极为有限的光谱信息,且现有基于卷积神经网络(convolutional neural network,CNN)的方法由于卷积操作的局部性忽略了远程上下文信息的捕获。针对上述问题,提出了一种面向高光谱场景分类的空—谱模型蒸馏网络(spatial-spectral model distillation network for hyperspectral scene classification,SSMD)。方法选择基于空—谱注意力的ViT方法(spatial-spectral vision Transformer,SSViT)探测不同类别的光谱信息,通过寻找光谱信息之间的差异性对地物进行精细分类。利用知识蒸馏将教师模型SSViT捕获的长距离依赖信息传递给学生模型VGG16(Visual Geometry Group 16)进行学习,二者协同合作,教师模型提取的光谱信息和全局信息与学生模型提取的局部信息融合,进一步提升学生分类性能并保持较低的时间代价。结果实验在3个数据集上与10种分类方法(5种传统CNN分类方法和5种较新场景分类方法)进行了比较。综合考虑时间成本和分类精度,本文方法在不同数据集上取得了不同程度的领先。在OHID-SC(Orbita hyperspectral image scene classification dataset)、OHS-SC(Orbita hyperspectral scene classification dataset)和HSRS-SC(hyperspectral remote sensing dataset for scene classification)数据集上的精度,相比于性能第2的模型,分类精度分别提高了13.1%、2.9%和0.74%。同时在OHID-SC数据集中进行的对比实验表明提出的算法有效提高了高光谱场景分类精度。结论提出的SSMD网络不仅有效利用高光谱数据目标光谱信息,并探索全局与局部间的特征关系,综合了传统模型和深度学习模型的优点,使分类结果更加准确。关键词:高光谱场景分类;卷积神经网络(CNN);Transformer;空—谱联合自注意力机制;知识蒸馏(KD)276|855|0更新时间:2024-08-13 -
 摘要:目的基于深度学习的解混方法在信息挖掘和泛化性能上优于传统方法,但主要关注光谱信息,对空间信息的利用仍停留在滤波、卷积的表层处理。这使得构建解混网络时需要堆叠多层网络,易丢失部分图像信息,影响解混准确性。Transformer网络因其强大的特征表达能力广泛应用于高光谱图像处理,但将其直接应用于解混学习容易丢失图像局部细节。本文基于Transformer网络提出了改进方法。方法本文以TNT(Transformer in Transformer)构架为基础提出了一种深度嵌套式解混网络(deep embedded Transformer network, DETN),通过内外嵌入式策略实现编码器中局部与整体空间信息共享,不仅保留了高光谱图像的空间细节,而且在编码器中只涉及少量卷积运算,大幅度提升了学习效率。在解码器中,通过一次卷积运算来恢复数据结构以便生成端元与丰度,并在最后使用Softmax 层来保障丰度的物理意义。结果最后,本文分别采用模拟数据集和真实高光谱数据集进行对比实验,在50 dB模拟数据集中平均光谱角距离和均方根误差取得最优值,分别为0.038 6 和0.004 5,在真实高光谱数据集Samson、Jasper Ridge中取得最优平均光谱角距离,分别为0.119 4,0.102 7。结论实验结果验证了DETN 方法的有效性和优势,并且能为实现深度解混提供新的技术支撑和理论参考。关键词:遥感图像处理;高光谱遥感;混合像元分解;深度学习;Transformer网络414|709|0更新时间:2024-08-13
摘要:目的基于深度学习的解混方法在信息挖掘和泛化性能上优于传统方法,但主要关注光谱信息,对空间信息的利用仍停留在滤波、卷积的表层处理。这使得构建解混网络时需要堆叠多层网络,易丢失部分图像信息,影响解混准确性。Transformer网络因其强大的特征表达能力广泛应用于高光谱图像处理,但将其直接应用于解混学习容易丢失图像局部细节。本文基于Transformer网络提出了改进方法。方法本文以TNT(Transformer in Transformer)构架为基础提出了一种深度嵌套式解混网络(deep embedded Transformer network, DETN),通过内外嵌入式策略实现编码器中局部与整体空间信息共享,不仅保留了高光谱图像的空间细节,而且在编码器中只涉及少量卷积运算,大幅度提升了学习效率。在解码器中,通过一次卷积运算来恢复数据结构以便生成端元与丰度,并在最后使用Softmax 层来保障丰度的物理意义。结果最后,本文分别采用模拟数据集和真实高光谱数据集进行对比实验,在50 dB模拟数据集中平均光谱角距离和均方根误差取得最优值,分别为0.038 6 和0.004 5,在真实高光谱数据集Samson、Jasper Ridge中取得最优平均光谱角距离,分别为0.119 4,0.102 7。结论实验结果验证了DETN 方法的有效性和优势,并且能为实现深度解混提供新的技术支撑和理论参考。关键词:遥感图像处理;高光谱遥感;混合像元分解;深度学习;Transformer网络414|709|0更新时间:2024-08-13
多源遥感数据融合与智能解译
-
 摘要:语音深度伪造技术是利用深度学习方法进行合成或生成语音的技术。人工智能生成内容技术的快速迭代与优化,推动了语音深度伪造技术在伪造语音的自然度、逼真度和多样性等方面取得显著提升,同时也使得语音深度伪造检测技术面临着巨大挑战。本文对语音深度伪造及其检测技术的研究进展进行全面梳理回顾。首先,介绍以语音合成(speech synthesis,SS)和语音转换(voice conversion,VC)为代表的伪造技术。然后,介绍语音深度伪造检测领域的常用数据集和相关评价指标。在此基础上,从数据增强、特征提取和优化以及学习机制等处理流程的角度对现有的语音深度伪造检测技术进行分类与深入分析。具体而言,从语音加噪、掩码增强、信道增强和压缩增强等数据增强的角度来分析不同增强方式对伪造检测技术性能的影响,从基于手工特征的伪造检测、基于混合特征的伪造检测、基于端到端的伪造检测和基于特征融合的伪造检测等特征提取和优化的角度对比分析各类方法的优缺点,从自监督学习、对抗训练和多任务学习等学习机制的角度对伪造检测技术的训练方式进行探讨。最后,总结分析语音深度伪造检测技术存在的挑战性问题,并对未来研究进行展望。本文汇总的相关数据集和代码可在https://github.com/media-sec-lab/Audio-Deepfake-Detection访问。关键词:语音深度伪造;语音深度伪造检测;语音合成(SS);语音转换(VC);人工智能生成内容(AIGC);自监督学习;对抗训练2092|5909|0更新时间:2024-08-13
摘要:语音深度伪造技术是利用深度学习方法进行合成或生成语音的技术。人工智能生成内容技术的快速迭代与优化,推动了语音深度伪造技术在伪造语音的自然度、逼真度和多样性等方面取得显著提升,同时也使得语音深度伪造检测技术面临着巨大挑战。本文对语音深度伪造及其检测技术的研究进展进行全面梳理回顾。首先,介绍以语音合成(speech synthesis,SS)和语音转换(voice conversion,VC)为代表的伪造技术。然后,介绍语音深度伪造检测领域的常用数据集和相关评价指标。在此基础上,从数据增强、特征提取和优化以及学习机制等处理流程的角度对现有的语音深度伪造检测技术进行分类与深入分析。具体而言,从语音加噪、掩码增强、信道增强和压缩增强等数据增强的角度来分析不同增强方式对伪造检测技术性能的影响,从基于手工特征的伪造检测、基于混合特征的伪造检测、基于端到端的伪造检测和基于特征融合的伪造检测等特征提取和优化的角度对比分析各类方法的优缺点,从自监督学习、对抗训练和多任务学习等学习机制的角度对伪造检测技术的训练方式进行探讨。最后,总结分析语音深度伪造检测技术存在的挑战性问题,并对未来研究进行展望。本文汇总的相关数据集和代码可在https://github.com/media-sec-lab/Audio-Deepfake-Detection访问。关键词:语音深度伪造;语音深度伪造检测;语音合成(SS);语音转换(VC);人工智能生成内容(AIGC);自监督学习;对抗训练2092|5909|0更新时间:2024-08-13 -
 摘要:单目标跟踪任务旨在对人类动态视觉系统进行建模,让机器在复杂环境中具备类人的运动目标跟踪能力,并已广泛应用于无人驾驶、视频监控、机器人视觉等领域。研究者从算法设计的角度开展了大量工作,并在代表性数据集中表现出良好性能。然而,在面临如目标形变、快速运动、光照变化等挑战因素时,现有算法的跟踪效果和人类预期相比还存在着较大差距,揭示了当前的评测技术发展仍存在滞后性和局限性。综上,区别于以算法设计为核心的传统综述思路,本文依托单目标跟踪任务、从视觉智能评估技术出发,对评测流程中涉及的各个关键性环节(评测任务、评测环境、待测对象和评估机制)进行系统梳理。首先,对单目标跟踪任务的发展历程和挑战因素进行介绍,并详细对比了评估所需的评测环境(数据集、竞赛等)。其次,对单目标跟踪待测对象进行介绍,不仅包含以相关滤波和孪生神经网络为代表的跟踪算法,同时也涉及跨学科领域开展的人类视觉跟踪实验。最后,从“机机对抗”和“人机对抗”两个角度对单目标跟踪评估机制进行回顾,并对当前待测对象的目标跟踪能力进行分析和总结。在此基础上,对单目标跟踪智能评估的发展趋势进行总结和展望,进一步分析未来研究中存在的挑战因素,并探讨了下一步可能的研究方向。关键词:智能评估技术;竞赛和数据集;视觉跟踪能力;单目标跟踪(SOT);目标跟踪算法649|2559|0更新时间:2024-08-13
摘要:单目标跟踪任务旨在对人类动态视觉系统进行建模,让机器在复杂环境中具备类人的运动目标跟踪能力,并已广泛应用于无人驾驶、视频监控、机器人视觉等领域。研究者从算法设计的角度开展了大量工作,并在代表性数据集中表现出良好性能。然而,在面临如目标形变、快速运动、光照变化等挑战因素时,现有算法的跟踪效果和人类预期相比还存在着较大差距,揭示了当前的评测技术发展仍存在滞后性和局限性。综上,区别于以算法设计为核心的传统综述思路,本文依托单目标跟踪任务、从视觉智能评估技术出发,对评测流程中涉及的各个关键性环节(评测任务、评测环境、待测对象和评估机制)进行系统梳理。首先,对单目标跟踪任务的发展历程和挑战因素进行介绍,并详细对比了评估所需的评测环境(数据集、竞赛等)。其次,对单目标跟踪待测对象进行介绍,不仅包含以相关滤波和孪生神经网络为代表的跟踪算法,同时也涉及跨学科领域开展的人类视觉跟踪实验。最后,从“机机对抗”和“人机对抗”两个角度对单目标跟踪评估机制进行回顾,并对当前待测对象的目标跟踪能力进行分析和总结。在此基础上,对单目标跟踪智能评估的发展趋势进行总结和展望,进一步分析未来研究中存在的挑战因素,并探讨了下一步可能的研究方向。关键词:智能评估技术;竞赛和数据集;视觉跟踪能力;单目标跟踪(SOT);目标跟踪算法649|2559|0更新时间:2024-08-13 -
 摘要:三维重建场景的纹理优化是计算机图形学和计算机视觉等领域的基础任务之一,其目的是优化纹理映射,减小重建几何体和纹理之间的对齐误差,提升重建场景的细节表现。为了对三维重建场景纹理优化算法的现状进行全面研究,本文从传统优化算法和基于深度学习的优化算法两个方面对现有三维重建场景的纹理优化算法进行综述。传统的纹理优化算法一般通过优化相机姿态、校正图像颜色、提高重建几何精度等步骤达到三维场景纹理优化的目的,按照优化方式的不同,主要包括基于图像融合的优化算法、基于图像拼接的优化算法以及纹理与几何联合优化算法,而基于深度学习的优化算法则利用神经网络优化三维场景纹理。同时,本文汇总了常用的三维重建场景纹理优化的数据集与评价指标,并重点讨论了不同数据集和评价指标的特点与用法。此外,本文对现有的各类纹理优化算法进行了定性分析和定量对比,重点阐述了这些算法的原理及优缺点,最后探讨了三维重建场景的纹理优化面临的挑战和发展方向。关键词:场景重建;纹理优化;图像融合;图像拼接;联合优化533|1187|0更新时间:2024-08-13
摘要:三维重建场景的纹理优化是计算机图形学和计算机视觉等领域的基础任务之一,其目的是优化纹理映射,减小重建几何体和纹理之间的对齐误差,提升重建场景的细节表现。为了对三维重建场景纹理优化算法的现状进行全面研究,本文从传统优化算法和基于深度学习的优化算法两个方面对现有三维重建场景的纹理优化算法进行综述。传统的纹理优化算法一般通过优化相机姿态、校正图像颜色、提高重建几何精度等步骤达到三维场景纹理优化的目的,按照优化方式的不同,主要包括基于图像融合的优化算法、基于图像拼接的优化算法以及纹理与几何联合优化算法,而基于深度学习的优化算法则利用神经网络优化三维场景纹理。同时,本文汇总了常用的三维重建场景纹理优化的数据集与评价指标,并重点讨论了不同数据集和评价指标的特点与用法。此外,本文对现有的各类纹理优化算法进行了定性分析和定量对比,重点阐述了这些算法的原理及优缺点,最后探讨了三维重建场景的纹理优化面临的挑战和发展方向。关键词:场景重建;纹理优化;图像融合;图像拼接;联合优化533|1187|0更新时间:2024-08-13 -
 摘要:随着互联网技术的普及和发展,用户数据和隐私的保护已经成为一个热门的研究领域。网络空间安全防御从被动防御发展到主动防御,防御性能和成功率获得了显著的提升。然而,传统的被动防御和主动防御本质上都是功能和安全松耦合的外壳式防御,对未知攻击的防御性能较差。网络空间拟态防御(cyberspace mimic defense, CMD)是在传统网络安全防御方式上发展出来的网络内生安全实现形式,核心架构为动态异构冗余架构,架构实现主体主要由异构执行体集合、分发器、拟态变换器和表决器4部分组成,同时以CMD三定理及网络安全不完全交集定理为理论基础。其中,通过异构执行体增加系统的异构性,并由表决算法决定异构执行体中上下线的个体,最终由调度算法完成系统中执行体的上下线过程。本文主要从网络空间安全发展的历史沿革出发,对比传统防御方式与拟态防御的差异,着重介绍拟态架构中异构策略、调度策略以及表决策略的具体实现形式,并罗列在实践过程中融合拟态防御思想的应用实例。拟态防御已经在各个领域有了较为广泛的应用基础,在此基础上的研究可以将现有网络安全体系推进到新的阶段。关键词:网络安全;内生安全;拟态防御;冗余性;动态异构408|1129|0更新时间:2024-08-13
摘要:随着互联网技术的普及和发展,用户数据和隐私的保护已经成为一个热门的研究领域。网络空间安全防御从被动防御发展到主动防御,防御性能和成功率获得了显著的提升。然而,传统的被动防御和主动防御本质上都是功能和安全松耦合的外壳式防御,对未知攻击的防御性能较差。网络空间拟态防御(cyberspace mimic defense, CMD)是在传统网络安全防御方式上发展出来的网络内生安全实现形式,核心架构为动态异构冗余架构,架构实现主体主要由异构执行体集合、分发器、拟态变换器和表决器4部分组成,同时以CMD三定理及网络安全不完全交集定理为理论基础。其中,通过异构执行体增加系统的异构性,并由表决算法决定异构执行体中上下线的个体,最终由调度算法完成系统中执行体的上下线过程。本文主要从网络空间安全发展的历史沿革出发,对比传统防御方式与拟态防御的差异,着重介绍拟态架构中异构策略、调度策略以及表决策略的具体实现形式,并罗列在实践过程中融合拟态防御思想的应用实例。拟态防御已经在各个领域有了较为广泛的应用基础,在此基础上的研究可以将现有网络安全体系推进到新的阶段。关键词:网络安全;内生安全;拟态防御;冗余性;动态异构408|1129|0更新时间:2024-08-13
综述
-
 摘要:目的彩色图像的灰度化是计算机视觉领域的研究热点。针对传统彩色图像灰度化方法得到的灰度图像存在对比度保持不足、细节模糊及层次感欠缺等问题,本文结合t分布随机邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)提出了一种更加简单、高效的彩色图像灰度化新方法。方法首先,将t-SNE降维思想引入到彩色图像的灰度化过程中,设计了一种基于t-SNE最大化的彩色图像灰度化新模型,通过最大化能量函数使原始彩色图像中对比度较小的区域在灰度化后其对比度能够适当地变大或保持,让灰度图像更好地保持原始彩色图像的对比度特征和层次感。其次,在新模型中设计了一种自适应的对比度保持策略,根据颜色对比度信息来自适应地调节原始彩色图像不同区域的灰度化力度,更好地保留原始彩色图像的细节和对比度信息。最后,采用了一种高效的离散搜索方法以快速求解所提新模型。结果基于Cadik、CSDD(complex scene decolorization dataset)和Color250数据集的大量实验结果表明,与传统方法相比,本文方法得到的灰度图像具有更好的表现,在颜色对比度保持率(color contrast preserving ratio, CCPR)指标上,本文方法在上述3个数据集上的平均CCPR值最高,分别为0.874、0.862和0.864。另外,在相同硬件上测试不同灰度化方法的运行效率时,本文方法的运行时间最短。结论相较于传统灰度化方法,本文方法不仅能够更好地保持原始彩色图像的对比度、细节特征和层次感,而且在主观评价和客观评价方面均有更好的表现。关键词:彩色图像灰度化;t分布随机邻域嵌入(t-SNE);对比度保持;离散搜索;细节保持289|1544|0更新时间:2024-08-13
摘要:目的彩色图像的灰度化是计算机视觉领域的研究热点。针对传统彩色图像灰度化方法得到的灰度图像存在对比度保持不足、细节模糊及层次感欠缺等问题,本文结合t分布随机邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)提出了一种更加简单、高效的彩色图像灰度化新方法。方法首先,将t-SNE降维思想引入到彩色图像的灰度化过程中,设计了一种基于t-SNE最大化的彩色图像灰度化新模型,通过最大化能量函数使原始彩色图像中对比度较小的区域在灰度化后其对比度能够适当地变大或保持,让灰度图像更好地保持原始彩色图像的对比度特征和层次感。其次,在新模型中设计了一种自适应的对比度保持策略,根据颜色对比度信息来自适应地调节原始彩色图像不同区域的灰度化力度,更好地保留原始彩色图像的细节和对比度信息。最后,采用了一种高效的离散搜索方法以快速求解所提新模型。结果基于Cadik、CSDD(complex scene decolorization dataset)和Color250数据集的大量实验结果表明,与传统方法相比,本文方法得到的灰度图像具有更好的表现,在颜色对比度保持率(color contrast preserving ratio, CCPR)指标上,本文方法在上述3个数据集上的平均CCPR值最高,分别为0.874、0.862和0.864。另外,在相同硬件上测试不同灰度化方法的运行效率时,本文方法的运行时间最短。结论相较于传统灰度化方法,本文方法不仅能够更好地保持原始彩色图像的对比度、细节特征和层次感,而且在主观评价和客观评价方面均有更好的表现。关键词:彩色图像灰度化;t分布随机邻域嵌入(t-SNE);对比度保持;离散搜索;细节保持289|1544|0更新时间:2024-08-13
图像处理和编码
-
 摘要:目的基于可见光和红外双模态图像融合的目标检测算法是解决复杂场景下目标检测任务的有效手段。然而现有双光检测算法中的特征融合过程存在两大问题:一是特征融合方式较为简单,逐特征元素相加或者并联操作导致特征融合效果不佳;二是算法结构中仅有特征融合过程,而缺少特征选择过程,导致有用特征无法得到高效利用。为解决上述问题,提出了一种基于动态特征选择的可见光红外图像融合目标检测算法。方法本文算法包含特征的动态融合层和动态选择层两个创新模块:动态融合层嵌入在骨干网络中,利用Transformer结构,多次对多源的图像特征图进行特征融合,以丰富特征表达;动态选择层嵌入在颈部网络中,利用3种注意力机制对多尺度特征图进行特征增强,以筛选有用特征。结果本文算法在FLIR、LLVIP(visible-infrared paired dataset for low-light vision)和VEDAI(vehicle detection in aerial imagery) 3个公开数据集上开展实验验证,与多种特征融合方式进行平均精度均值(mean average precision,mAP)性能比较,mAP50指标相比于基线模型分别提升了1.3%、0.6%和3.9%;mAP75指标相比于基线模型分别提升了4.6%、2.6%和7.5%;mAP指标相比于基线模型分别提升了3.2%、2.1%和3.1%。同时设计了相关结构的消融实验,验证了所提算法的有效性。结论提出的基于动态特征选择的可见光红外图像融合目标检测算法,可以有效地融合可见光和红外两种图像模态的特征信息,提升了目标检测的性能。关键词:红外图像;目标检测;注意力机制;特征融合;深度神经网络554|2092|0更新时间:2024-08-13
摘要:目的基于可见光和红外双模态图像融合的目标检测算法是解决复杂场景下目标检测任务的有效手段。然而现有双光检测算法中的特征融合过程存在两大问题:一是特征融合方式较为简单,逐特征元素相加或者并联操作导致特征融合效果不佳;二是算法结构中仅有特征融合过程,而缺少特征选择过程,导致有用特征无法得到高效利用。为解决上述问题,提出了一种基于动态特征选择的可见光红外图像融合目标检测算法。方法本文算法包含特征的动态融合层和动态选择层两个创新模块:动态融合层嵌入在骨干网络中,利用Transformer结构,多次对多源的图像特征图进行特征融合,以丰富特征表达;动态选择层嵌入在颈部网络中,利用3种注意力机制对多尺度特征图进行特征增强,以筛选有用特征。结果本文算法在FLIR、LLVIP(visible-infrared paired dataset for low-light vision)和VEDAI(vehicle detection in aerial imagery) 3个公开数据集上开展实验验证,与多种特征融合方式进行平均精度均值(mean average precision,mAP)性能比较,mAP50指标相比于基线模型分别提升了1.3%、0.6%和3.9%;mAP75指标相比于基线模型分别提升了4.6%、2.6%和7.5%;mAP指标相比于基线模型分别提升了3.2%、2.1%和3.1%。同时设计了相关结构的消融实验,验证了所提算法的有效性。结论提出的基于动态特征选择的可见光红外图像融合目标检测算法,可以有效地融合可见光和红外两种图像模态的特征信息,提升了目标检测的性能。关键词:红外图像;目标检测;注意力机制;特征融合;深度神经网络554|2092|0更新时间:2024-08-13 -
 摘要:目的在行人重识别任务中,行人外观特征会因为遮挡发生变化,从而降低行人特征的辨别性,仅基于可视部分的传统方法仍会识别错误。针对此问题,提出了一种融合姿态引导和多尺度特征的遮挡行人重识别方法。方法首先,构建了一种特征修复模块,根据遮挡部位邻近信息恢复特征空间中被遮挡区域的语义信息,实现缺失部位特征的修补。然后,为了从修复的图像中提取有效的姿态信息,设计了一种姿态引导模块,通过姿态估计引导特征提取,实现更加精准的行人匹配。最后,搭建了特征增强模块,并融合显著性区域检测方法增强有效的身体部位特征,同时消除背景信息造成的干扰。结果在3个公开的数据集上进行了对比实验和消融实验,在Market1501、DukeMTMC-reID(Duke multi-tracking multi-camera re-identification)和Occluded-DukeMTMC(occluded Duke multi-tracking multi-camera re-identification)数据集上的平均精度均值(mean average precision, mAP)和首次命中率(rank-1 accuracy, Rank-1)分别为88.8%和95.5%、79.2%和89.3%、51.7%和60.3%。对比实验结果表明提出的融合算法提高了行人匹配的准确率,具有较好的竞争优势。结论本文所提的姿态引导和多尺度融合方法,修复了因遮挡而缺失的部位特征,结合姿态信息融合了不同粒度的图像特征,提高了模型的识别准确率,能有效缓解遮挡导致的误识别现象,验证了方法的有效性。关键词:行人重识别(ReID);遮挡;姿态引导;特征融合;特征修补352|519|0更新时间:2024-08-13
摘要:目的在行人重识别任务中,行人外观特征会因为遮挡发生变化,从而降低行人特征的辨别性,仅基于可视部分的传统方法仍会识别错误。针对此问题,提出了一种融合姿态引导和多尺度特征的遮挡行人重识别方法。方法首先,构建了一种特征修复模块,根据遮挡部位邻近信息恢复特征空间中被遮挡区域的语义信息,实现缺失部位特征的修补。然后,为了从修复的图像中提取有效的姿态信息,设计了一种姿态引导模块,通过姿态估计引导特征提取,实现更加精准的行人匹配。最后,搭建了特征增强模块,并融合显著性区域检测方法增强有效的身体部位特征,同时消除背景信息造成的干扰。结果在3个公开的数据集上进行了对比实验和消融实验,在Market1501、DukeMTMC-reID(Duke multi-tracking multi-camera re-identification)和Occluded-DukeMTMC(occluded Duke multi-tracking multi-camera re-identification)数据集上的平均精度均值(mean average precision, mAP)和首次命中率(rank-1 accuracy, Rank-1)分别为88.8%和95.5%、79.2%和89.3%、51.7%和60.3%。对比实验结果表明提出的融合算法提高了行人匹配的准确率,具有较好的竞争优势。结论本文所提的姿态引导和多尺度融合方法,修复了因遮挡而缺失的部位特征,结合姿态信息融合了不同粒度的图像特征,提高了模型的识别准确率,能有效缓解遮挡导致的误识别现象,验证了方法的有效性。关键词:行人重识别(ReID);遮挡;姿态引导;特征融合;特征修补352|519|0更新时间:2024-08-13 -
 摘要:目的在复杂的自然场景下,人脸表情识别存在着眼镜、手部动作和发型等局部遮挡的问题,这些遮挡区域会降低模型的情感判别能力。因此,本文提出了一种注意力引导局部特征联合学习的人脸表情识别方法。方法该方法由全局特征提取模块、全局特征增强模块和局部特征联合学习模块组成。全局特征提取模块用于提取中间层全局特征;全局特征增强模块用于抑制人脸识别预训练模型带来的冗余特征,并增强全局人脸图像中与情感最相关的特征图语义信息;局部特征联合学习模块利用混合注意力机制来学习不同人脸局部区域的细粒度显著特征并使用联合损失进行约束。结果在2个自然场景数据集RAF-DB(real-world affective faces database)和FERPlus上进行了相关实验验证。在RAF-DB数据集中,识别准确率为89.24%,与MA-Net(global multi-scale and local attention network)相比有0.84%的性能提升;在FERPlus数据集中,识别准确率为90.04%,与FER-VT(FER framework with two attention mechanisms)的性能相当。实验结果表明该方法具有良好的鲁棒性。结论本文方法通过先全局增强后局部细化的学习顺序,有效地减少了局部遮挡问题的干扰。关键词:人脸表情识别;注意力机制;局部遮挡;局部显著特征;联合学习369|631|0更新时间:2024-08-13
摘要:目的在复杂的自然场景下,人脸表情识别存在着眼镜、手部动作和发型等局部遮挡的问题,这些遮挡区域会降低模型的情感判别能力。因此,本文提出了一种注意力引导局部特征联合学习的人脸表情识别方法。方法该方法由全局特征提取模块、全局特征增强模块和局部特征联合学习模块组成。全局特征提取模块用于提取中间层全局特征;全局特征增强模块用于抑制人脸识别预训练模型带来的冗余特征,并增强全局人脸图像中与情感最相关的特征图语义信息;局部特征联合学习模块利用混合注意力机制来学习不同人脸局部区域的细粒度显著特征并使用联合损失进行约束。结果在2个自然场景数据集RAF-DB(real-world affective faces database)和FERPlus上进行了相关实验验证。在RAF-DB数据集中,识别准确率为89.24%,与MA-Net(global multi-scale and local attention network)相比有0.84%的性能提升;在FERPlus数据集中,识别准确率为90.04%,与FER-VT(FER framework with two attention mechanisms)的性能相当。实验结果表明该方法具有良好的鲁棒性。结论本文方法通过先全局增强后局部细化的学习顺序,有效地减少了局部遮挡问题的干扰。关键词:人脸表情识别;注意力机制;局部遮挡;局部显著特征;联合学习369|631|0更新时间:2024-08-13
图像分析和识别
-
 摘要:目的针对现有点云语义分割方法对几何与语义特征信息利用不充分,导致分割性能不佳,特别是局部细粒度分割精度不足的问题,提出一种结合双边交叉增强与自注意力补偿的充分融合几何与语义上下文信息的点云语义分割新算法以提升分割性能。方法首先,设计基于双边交叉增强的空间聚合模块,将局部几何与语义上下文信息映射到同一空间进行交叉学习增强后聚合为局部上下文信息。然后,基于自注意力机制提取全局上下文信息与增强后的局部上下文信息进行融合,补偿局部上下文信息的单一性,得到完备特征图。最后,将空间聚合模块各阶段输出的多分辨率特征输入特征融合模块进行多尺度特征融合,得到最终的综合特征图以实现高性能语义分割。结果实验结果表明,在S3DIS(Stanford 3D indoor spaces dataset)数据集上,本文算法的平均交并比(mean intersection over union,mIoU)、平均类别精度(mean class accuracy,mAcc)和总体精度(overall accuracy,OA)分别为70.2%、81.7%和88.3%,与现有优秀算法RandLA-Net相比,分别提高2.4%、2.0%和1.0%。同时,对S3DIS数据集Area 5单独测试,本文算法的mIoU为66.2%,较RandLA-Net提高5.0%。结论空间聚合模块不仅能够充分利用局部几何与语义上下文信息增强局部上下文信息,而且基于自注意力机制融合局部与全局上下文信息,增强了特征的完备性以及局部与全局的关联性,可以有效提升点云局部细粒度的分割精度。在可视化分析中,相较于对比算法,本文算法对点云场景的局部细粒度分割效果明显提升,验证了本文算法的有效性。关键词:点云;语义分割;双边交叉增强;自注意力机制;特征融合358|550|0更新时间:2024-08-13
摘要:目的针对现有点云语义分割方法对几何与语义特征信息利用不充分,导致分割性能不佳,特别是局部细粒度分割精度不足的问题,提出一种结合双边交叉增强与自注意力补偿的充分融合几何与语义上下文信息的点云语义分割新算法以提升分割性能。方法首先,设计基于双边交叉增强的空间聚合模块,将局部几何与语义上下文信息映射到同一空间进行交叉学习增强后聚合为局部上下文信息。然后,基于自注意力机制提取全局上下文信息与增强后的局部上下文信息进行融合,补偿局部上下文信息的单一性,得到完备特征图。最后,将空间聚合模块各阶段输出的多分辨率特征输入特征融合模块进行多尺度特征融合,得到最终的综合特征图以实现高性能语义分割。结果实验结果表明,在S3DIS(Stanford 3D indoor spaces dataset)数据集上,本文算法的平均交并比(mean intersection over union,mIoU)、平均类别精度(mean class accuracy,mAcc)和总体精度(overall accuracy,OA)分别为70.2%、81.7%和88.3%,与现有优秀算法RandLA-Net相比,分别提高2.4%、2.0%和1.0%。同时,对S3DIS数据集Area 5单独测试,本文算法的mIoU为66.2%,较RandLA-Net提高5.0%。结论空间聚合模块不仅能够充分利用局部几何与语义上下文信息增强局部上下文信息,而且基于自注意力机制融合局部与全局上下文信息,增强了特征的完备性以及局部与全局的关联性,可以有效提升点云局部细粒度的分割精度。在可视化分析中,相较于对比算法,本文算法对点云场景的局部细粒度分割效果明显提升,验证了本文算法的有效性。关键词:点云;语义分割;双边交叉增强;自注意力机制;特征融合358|550|0更新时间:2024-08-13 -
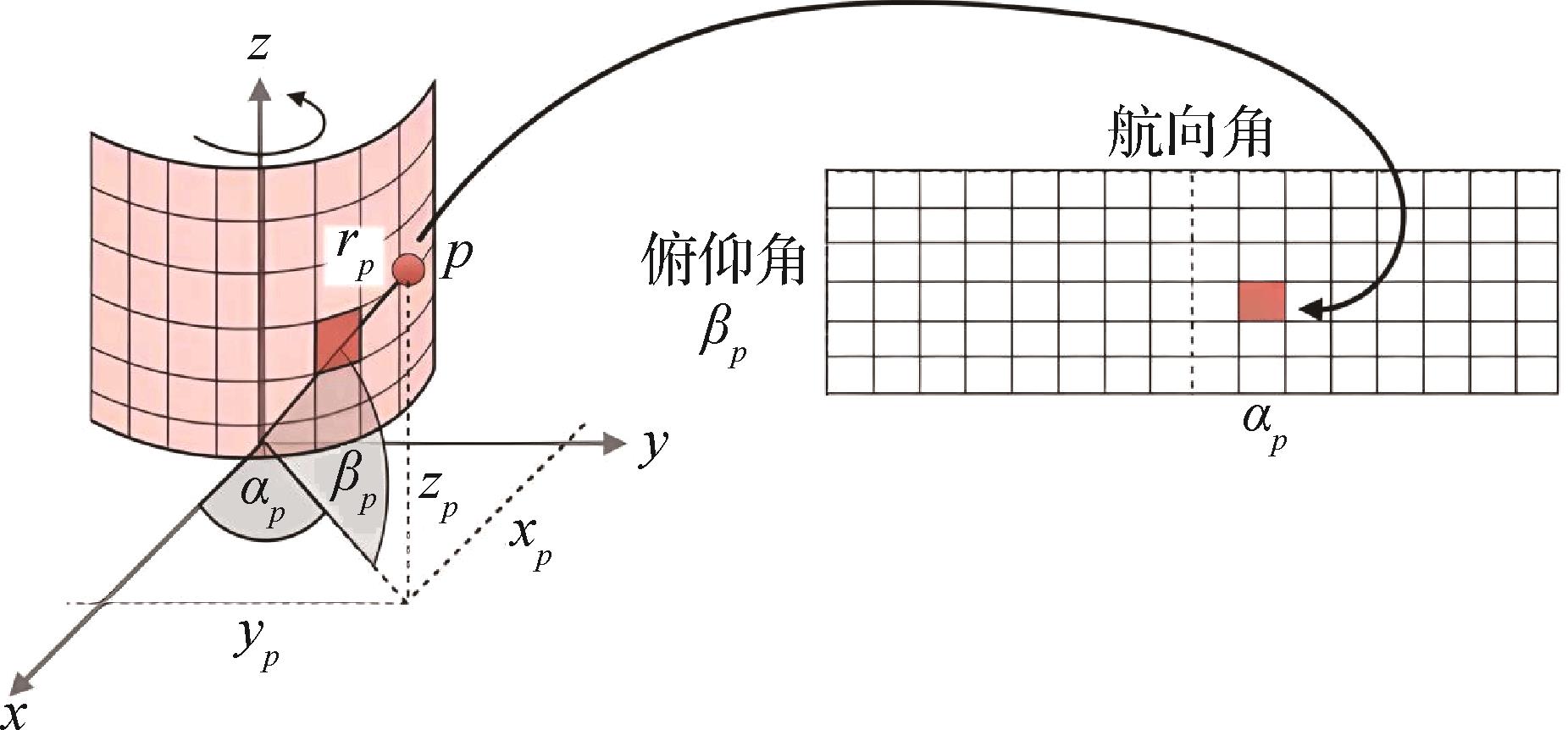 摘要:目的基于点云的3D目标检测是自动驾驶领域的重要技术之一。由于点云的非结构化特性,通常将点云进行体素化处理,然后基于体素特征完成3D目标检测任务。在基于体素的3D目标检测算法中,对点云进行体素化时会导致部分点云的数据信息和结构信息的损失,降低检测效果。针对该问题,本文提出一种融合点云深度信息的方法,有效提高了3D目标检测的精度。方法首先将点云通过球面投影的方法转换为深度图像,然后将深度图像与3D目标检测算法提取的特征图进行融合,从而对损失信息进行补全。由于此时的融合特征以2D伪图像的形式表示,因此使用YOLOv7(you only look once v7)中的主干网络提取融合特征。最后设计回归与分类网络,将提取到的融合特征送入到网络中预测目标的位置、大小以及类别。结果本文方法在KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)数据集和DAIR-V2X数据集上进行测试。以AP(average precision )值为评价指标,在KITTI数据集上,改进算法PP-Depth相较于PointPillars在汽车、行人和自行车类别上分别有0.84%、2.3%和1.77%的提升。以自行车简单难度为例,改进算法PP-YOLO-Depth相较于PointPillars、PP-YOLO和PP-Depth分别有5.15%、1.1%和2.75%的提升。在DAIR-V2X数据集上,PP-Depth相较于PointPillars在汽车、行人和自行车类别上分别有17.46%、20.72%和12.7%的提升。以汽车简单难度为例,PP-YOLO-Depth相较于PointPillars、PP-YOLO和PP-Depth分别有13.53%、5.59%和1.08%的提升。结论本文方法在KITTI数据集和DAIR-V2X数据集上都取得了较好表现,减少了点云在体素化过程中的信息损失并提高了网络对融合特征的提取能力和多尺度目标的检测性能,使目标检测结果更加准确。关键词:自动驾驶;3D点云目标检测;深度信息融合;点云体素化;KITTI数据集256|697|0更新时间:2024-08-13
摘要:目的基于点云的3D目标检测是自动驾驶领域的重要技术之一。由于点云的非结构化特性,通常将点云进行体素化处理,然后基于体素特征完成3D目标检测任务。在基于体素的3D目标检测算法中,对点云进行体素化时会导致部分点云的数据信息和结构信息的损失,降低检测效果。针对该问题,本文提出一种融合点云深度信息的方法,有效提高了3D目标检测的精度。方法首先将点云通过球面投影的方法转换为深度图像,然后将深度图像与3D目标检测算法提取的特征图进行融合,从而对损失信息进行补全。由于此时的融合特征以2D伪图像的形式表示,因此使用YOLOv7(you only look once v7)中的主干网络提取融合特征。最后设计回归与分类网络,将提取到的融合特征送入到网络中预测目标的位置、大小以及类别。结果本文方法在KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)数据集和DAIR-V2X数据集上进行测试。以AP(average precision )值为评价指标,在KITTI数据集上,改进算法PP-Depth相较于PointPillars在汽车、行人和自行车类别上分别有0.84%、2.3%和1.77%的提升。以自行车简单难度为例,改进算法PP-YOLO-Depth相较于PointPillars、PP-YOLO和PP-Depth分别有5.15%、1.1%和2.75%的提升。在DAIR-V2X数据集上,PP-Depth相较于PointPillars在汽车、行人和自行车类别上分别有17.46%、20.72%和12.7%的提升。以汽车简单难度为例,PP-YOLO-Depth相较于PointPillars、PP-YOLO和PP-Depth分别有13.53%、5.59%和1.08%的提升。结论本文方法在KITTI数据集和DAIR-V2X数据集上都取得了较好表现,减少了点云在体素化过程中的信息损失并提高了网络对融合特征的提取能力和多尺度目标的检测性能,使目标检测结果更加准确。关键词:自动驾驶;3D点云目标检测;深度信息融合;点云体素化;KITTI数据集256|697|0更新时间:2024-08-13 -
 摘要:目的近年来,采用神经网络完成立体匹配任务已成为计算机视觉领域的研究热点,目前现有方法存在弱纹理目标缺乏全局表征的问题,为此本文提出一种基于Transformer架构的密集特征提取网络。方法首先,采用空间池化窗口策略使得Transformer层可以在维持线性计算复杂度的同时,捕获广泛的上下文表示,弥补局部弱纹理导致的特征匮乏问题。其次,通过卷积与转置卷积实现重叠式块嵌入,使得所有特征点都尽可能多地捕捉邻近特征,便于细粒度匹配。再者,通过将跳跃查询策略应用于编码器和解码器间的特征融合部分,以此实现高效信息传递。最后,针对立体像对存在的遮挡情况,对固定区域内的匹配概率进行截断求和,输出更为合理的遮挡置信度。结果在Scene Flow数据集上进行了消融实验,实验结果表明,本文网络获得了0.33的绝对像素距离,0.92%的异常像素占比和98%的遮挡预测交并比。为了验证模型在实际路况场景下的有效性,在KITTI-2015数据集上进行了补充对比实验,本文方法获得了1.78%的平均异常值百分比,上述指标均优于STTR(stereo Transformer)等主流方法。此外,在KITTI-2015、MPI-Sintel(max planck institute sintel)和Middlebury-2014数据集的测试中,本文模型具备较强的泛化性。结论本文提出了一个纯粹的基于Transformer架构的密集特征提取器,使用空间池化窗口策略减小注意力计算的空间规模,并利用跳跃查询策略对编码器和解码器的特征进行了有效融合,可以较好地提高Transformer架构下的特征提取性能。关键词:立体匹配;弱纹理目标;Transformer;空间池化窗口;跳跃查询;截断求和;Scene Flow;KITTI-2015508|1240|1更新时间:2024-08-13
摘要:目的近年来,采用神经网络完成立体匹配任务已成为计算机视觉领域的研究热点,目前现有方法存在弱纹理目标缺乏全局表征的问题,为此本文提出一种基于Transformer架构的密集特征提取网络。方法首先,采用空间池化窗口策略使得Transformer层可以在维持线性计算复杂度的同时,捕获广泛的上下文表示,弥补局部弱纹理导致的特征匮乏问题。其次,通过卷积与转置卷积实现重叠式块嵌入,使得所有特征点都尽可能多地捕捉邻近特征,便于细粒度匹配。再者,通过将跳跃查询策略应用于编码器和解码器间的特征融合部分,以此实现高效信息传递。最后,针对立体像对存在的遮挡情况,对固定区域内的匹配概率进行截断求和,输出更为合理的遮挡置信度。结果在Scene Flow数据集上进行了消融实验,实验结果表明,本文网络获得了0.33的绝对像素距离,0.92%的异常像素占比和98%的遮挡预测交并比。为了验证模型在实际路况场景下的有效性,在KITTI-2015数据集上进行了补充对比实验,本文方法获得了1.78%的平均异常值百分比,上述指标均优于STTR(stereo Transformer)等主流方法。此外,在KITTI-2015、MPI-Sintel(max planck institute sintel)和Middlebury-2014数据集的测试中,本文模型具备较强的泛化性。结论本文提出了一个纯粹的基于Transformer架构的密集特征提取器,使用空间池化窗口策略减小注意力计算的空间规模,并利用跳跃查询策略对编码器和解码器的特征进行了有效融合,可以较好地提高Transformer架构下的特征提取性能。关键词:立体匹配;弱纹理目标;Transformer;空间池化窗口;跳跃查询;截断求和;Scene Flow;KITTI-2015508|1240|1更新时间:2024-08-13
图像理解和计算机视觉
-
 摘要:目的视网膜眼底图像广泛用于临床筛查和诊断眼科疾病,但由于散焦、光线条件不佳等引起的眼底图像模糊,导致医生无法正确诊断,且现有图像增强方法恢复的图像仍存在模糊、高频信息缺失以及噪点增多问题。本文提出了一个卷积字典扩散模型,将卷积字典学习的去噪能力与条件扩散模型的灵活性相结合,从而解决了上述问题。方法算法主要包括两个过程:扩散过程和去噪过程。首先向输入图像中逐步添加随机噪声,得到趋于纯粹噪声的图像;然后训练一个神经网络逐渐将噪声从图像中移除,直到获得一幅清晰图像。本文利用卷积网络来实现卷积字典学习并获取图像稀疏表示,该算法充分利用图像的先验信息,有效避免重建图像高频信息缺失和噪点增多的问题。结果将本文模型在EyePACS数据集上进行训练,并分别在合成数据集DRIVE (dgital retinal images for vessel extraction)、CHASEDB1(child heart and health study in England)、ROC(retinopathy online challenge)和真实数据集RF(real fundus)、HRF(high-resolution fundus)上进行测试,验证了所提方法在图像增强任务上的性能及跨数据集的泛化能力,其评价指标峰值信噪比(peak signal-to-noise ratio,PSNR)和学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)与原始扩散模型(learning enhancement from degradation,Led)相比平均分别提升了1.992 9 dB和0.028 9。此外,将本文方法用于真实眼科图像下游任务的前处理能够有效提升下游任务的表现,在含有分割标签的DRIVE数据集上进行的视网膜血管分割实验结果显示,相较于原始扩散模型,其分割指标对比其受试者工作特征曲线下面积(area under the curve,AUC),准确率(accuracy,Acc)和敏感性(sensitivity,Sen)平均分别提升0.031 4,0.003 0和0.073 8。结论提出的方法能够在保留真实眼底特征的同时去除模糊、恢复更丰富的细节,从而有利于临床图像的分析和应用。关键词:眼底图像增强;卷积字典学习;稀疏表示;扩散模型;条件扩散模型469|823|0更新时间:2024-08-13
摘要:目的视网膜眼底图像广泛用于临床筛查和诊断眼科疾病,但由于散焦、光线条件不佳等引起的眼底图像模糊,导致医生无法正确诊断,且现有图像增强方法恢复的图像仍存在模糊、高频信息缺失以及噪点增多问题。本文提出了一个卷积字典扩散模型,将卷积字典学习的去噪能力与条件扩散模型的灵活性相结合,从而解决了上述问题。方法算法主要包括两个过程:扩散过程和去噪过程。首先向输入图像中逐步添加随机噪声,得到趋于纯粹噪声的图像;然后训练一个神经网络逐渐将噪声从图像中移除,直到获得一幅清晰图像。本文利用卷积网络来实现卷积字典学习并获取图像稀疏表示,该算法充分利用图像的先验信息,有效避免重建图像高频信息缺失和噪点增多的问题。结果将本文模型在EyePACS数据集上进行训练,并分别在合成数据集DRIVE (dgital retinal images for vessel extraction)、CHASEDB1(child heart and health study in England)、ROC(retinopathy online challenge)和真实数据集RF(real fundus)、HRF(high-resolution fundus)上进行测试,验证了所提方法在图像增强任务上的性能及跨数据集的泛化能力,其评价指标峰值信噪比(peak signal-to-noise ratio,PSNR)和学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)与原始扩散模型(learning enhancement from degradation,Led)相比平均分别提升了1.992 9 dB和0.028 9。此外,将本文方法用于真实眼科图像下游任务的前处理能够有效提升下游任务的表现,在含有分割标签的DRIVE数据集上进行的视网膜血管分割实验结果显示,相较于原始扩散模型,其分割指标对比其受试者工作特征曲线下面积(area under the curve,AUC),准确率(accuracy,Acc)和敏感性(sensitivity,Sen)平均分别提升0.031 4,0.003 0和0.073 8。结论提出的方法能够在保留真实眼底特征的同时去除模糊、恢复更丰富的细节,从而有利于临床图像的分析和应用。关键词:眼底图像增强;卷积字典学习;稀疏表示;扩散模型;条件扩散模型469|823|0更新时间:2024-08-13
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0