
最新刊期
2025 年 第 30 卷 第 1 期
-
视觉基础模型研究现状与发展趋势 AI导读
“在计算机视觉领域,视觉基础模型的研究进展为解决传统深度学习模型依赖大量标注数据和泛化能力不足的问题提供了新方案。” 摘要:在计算机视觉领域,尽管传统的深度学习视觉模型在特定任务上表现出色,但它们对大量标注数据的高度依赖及在新场景下性能泛化的局限性,大大增加了使用成本并限制了模型的应用范围。近年来,以Transformer为核心的新型模型结构,特别是在自监督学习领域的应用,为解决这些挑战提供了新的解决方案。这些模型通常通过大规模数据预训练,在处理复杂视觉场景中展现出强大的泛化能力,其被广泛称为视觉基础模型。本文深入探讨了视觉基础模型的研究现状与未来发展趋势,并重点关注该领域的关键技术进展及其对未来计算机视觉的潜在影响。首先回顾和梳理了视觉基础模型的背景与发展历程,然后介绍了在这一发展历程中出现的关键模型基础结构,介绍并分析了构建视觉基础模型所采用的各类预训练任务的设计思路,并根据其特性对现有的视觉基础模型进行分类。同时,对不同类型视觉基础模型中的代表性工作进行了介绍,并整理了目前可用于视觉基础模型预训练的数据集。最后,对视觉基础模型的研究现状进行总结和思考,提出了目前存在的一些挑战,并展望未来可能的研究方向。关键词:基础模型;计算机视觉(CV);预训练模型;自监督学习;多任务学习709|467|0更新时间:2025-04-11
摘要:在计算机视觉领域,尽管传统的深度学习视觉模型在特定任务上表现出色,但它们对大量标注数据的高度依赖及在新场景下性能泛化的局限性,大大增加了使用成本并限制了模型的应用范围。近年来,以Transformer为核心的新型模型结构,特别是在自监督学习领域的应用,为解决这些挑战提供了新的解决方案。这些模型通常通过大规模数据预训练,在处理复杂视觉场景中展现出强大的泛化能力,其被广泛称为视觉基础模型。本文深入探讨了视觉基础模型的研究现状与未来发展趋势,并重点关注该领域的关键技术进展及其对未来计算机视觉的潜在影响。首先回顾和梳理了视觉基础模型的背景与发展历程,然后介绍了在这一发展历程中出现的关键模型基础结构,介绍并分析了构建视觉基础模型所采用的各类预训练任务的设计思路,并根据其特性对现有的视觉基础模型进行分类。同时,对不同类型视觉基础模型中的代表性工作进行了介绍,并整理了目前可用于视觉基础模型预训练的数据集。最后,对视觉基础模型的研究现状进行总结和思考,提出了目前存在的一些挑战,并展望未来可能的研究方向。关键词:基础模型;计算机视觉(CV);预训练模型;自监督学习;多任务学习709|467|0更新时间:2025-04-11 -
基于机器视觉的半导体晶圆缺陷检测方法综述 AI导读
“集成电路技术发展离不开半导体晶圆,其缺陷检测对保证芯片性能至关重要。综述了晶圆缺陷检测方法的研究进展,为提高晶圆良品率和生产率提供解决方案。” 摘要:当今许多新兴科技领域的发展需要集成电路(integrated circuit, IC)技术的支撑。半导体晶圆作为集成电路芯片中的关键角色,因制作工艺复杂,容易产生各种缺陷,其故障会极大地影响芯片的最终工作性能并增加成本。因此半导体晶圆的缺陷检测是保证其良品率和生产率的重要手段。结合机器视觉算法的晶圆缺陷检测方法普适性强、速度快,能更好地满足工业检测的相关需求。鉴于此,综述了近十几年来半导体晶圆缺陷检测方法的研究进展,介绍了晶圆制造的复杂工艺、表面缺陷检测的流程,根据不同的标准将晶圆缺陷进行分类。重点阐述了基于学习的方法,包括有监督机器学习、无监督机器学习、混合学习、半监督学习以及迁移学习5大类。对晶圆缺陷检测的深度神经网络分类为检测网络、分类网络、分割网络与组合网络。随后梳理了在晶圆缺陷检测领域常用的数据集以及性能评价指标。最后总结了晶圆缺陷检测当前存在的问题,对未来的研究方向进行了展望。关键词:半导体晶圆;缺陷检测;机器视觉;深度神经网络(DNN);机器学习;晶圆缺陷数据集377|156|0更新时间:2025-04-11
摘要:当今许多新兴科技领域的发展需要集成电路(integrated circuit, IC)技术的支撑。半导体晶圆作为集成电路芯片中的关键角色,因制作工艺复杂,容易产生各种缺陷,其故障会极大地影响芯片的最终工作性能并增加成本。因此半导体晶圆的缺陷检测是保证其良品率和生产率的重要手段。结合机器视觉算法的晶圆缺陷检测方法普适性强、速度快,能更好地满足工业检测的相关需求。鉴于此,综述了近十几年来半导体晶圆缺陷检测方法的研究进展,介绍了晶圆制造的复杂工艺、表面缺陷检测的流程,根据不同的标准将晶圆缺陷进行分类。重点阐述了基于学习的方法,包括有监督机器学习、无监督机器学习、混合学习、半监督学习以及迁移学习5大类。对晶圆缺陷检测的深度神经网络分类为检测网络、分类网络、分割网络与组合网络。随后梳理了在晶圆缺陷检测领域常用的数据集以及性能评价指标。最后总结了晶圆缺陷检测当前存在的问题,对未来的研究方向进行了展望。关键词:半导体晶圆;缺陷检测;机器视觉;深度神经网络(DNN);机器学习;晶圆缺陷数据集377|156|0更新时间:2025-04-11 -
水下图像复原和增强方法研究进展 AI导读
“在海洋强国战略背景下,中国专家全面梳理了水下图像清晰化方法,为解决水下机器视觉感知难题提供解决方案。” 摘要:自2012年中国提出海洋强国战略以来,水下图像清晰化已成为机器视觉领域的研究热点和挑战。与陆地良好环境中拍摄的图像不同,光在水下传播时受水下介质吸收和散射影响,导致水下图像存在颜色失真、细节模糊、低对比度、亮度不均等问题。低质量水下图像使得水下机器视觉感知面临看不清的挑战,因此研究有效的水下图像增强方法是当前水下视觉领域亟待解决的重要问题。本文在广泛调研的基础上梳理了水下图像质量提升的方法,主要包括图像复原和图像增强两大类。随后,深入讨论了代表性方法,并通过定性和定量评估分析,详细探讨了这些方法的优势和局限性。此外,全面概述了水下图像质量退化问题、提升方法、数据集及评估指标,分析了其在不同场景下的性能,提供了全面的水下图像清晰化方法研究现状。最后,根据水下图像增强和复原方法的难点与目前面临的主要问题对研究方向和发展趋势进行了归纳和展望。这一综合性研究为未来相关领域的研究和实践提供了建议。关键词:水下图像质量退化;光的散射与吸收;水下图像清晰化;水下图像质量评估407|324|0更新时间:2025-04-11
摘要:自2012年中国提出海洋强国战略以来,水下图像清晰化已成为机器视觉领域的研究热点和挑战。与陆地良好环境中拍摄的图像不同,光在水下传播时受水下介质吸收和散射影响,导致水下图像存在颜色失真、细节模糊、低对比度、亮度不均等问题。低质量水下图像使得水下机器视觉感知面临看不清的挑战,因此研究有效的水下图像增强方法是当前水下视觉领域亟待解决的重要问题。本文在广泛调研的基础上梳理了水下图像质量提升的方法,主要包括图像复原和图像增强两大类。随后,深入讨论了代表性方法,并通过定性和定量评估分析,详细探讨了这些方法的优势和局限性。此外,全面概述了水下图像质量退化问题、提升方法、数据集及评估指标,分析了其在不同场景下的性能,提供了全面的水下图像清晰化方法研究现状。最后,根据水下图像增强和复原方法的难点与目前面临的主要问题对研究方向和发展趋势进行了归纳和展望。这一综合性研究为未来相关领域的研究和实践提供了建议。关键词:水下图像质量退化;光的散射与吸收;水下图像清晰化;水下图像质量评估407|324|0更新时间:2025-04-11
综述

-
用于阴影去除的小波非均匀扩散模型 AI导读
“最新研究提出了一种小波非均匀扩散模型,有效去除图像阴影,恢复颜色亮度和细节,提升图像质量。”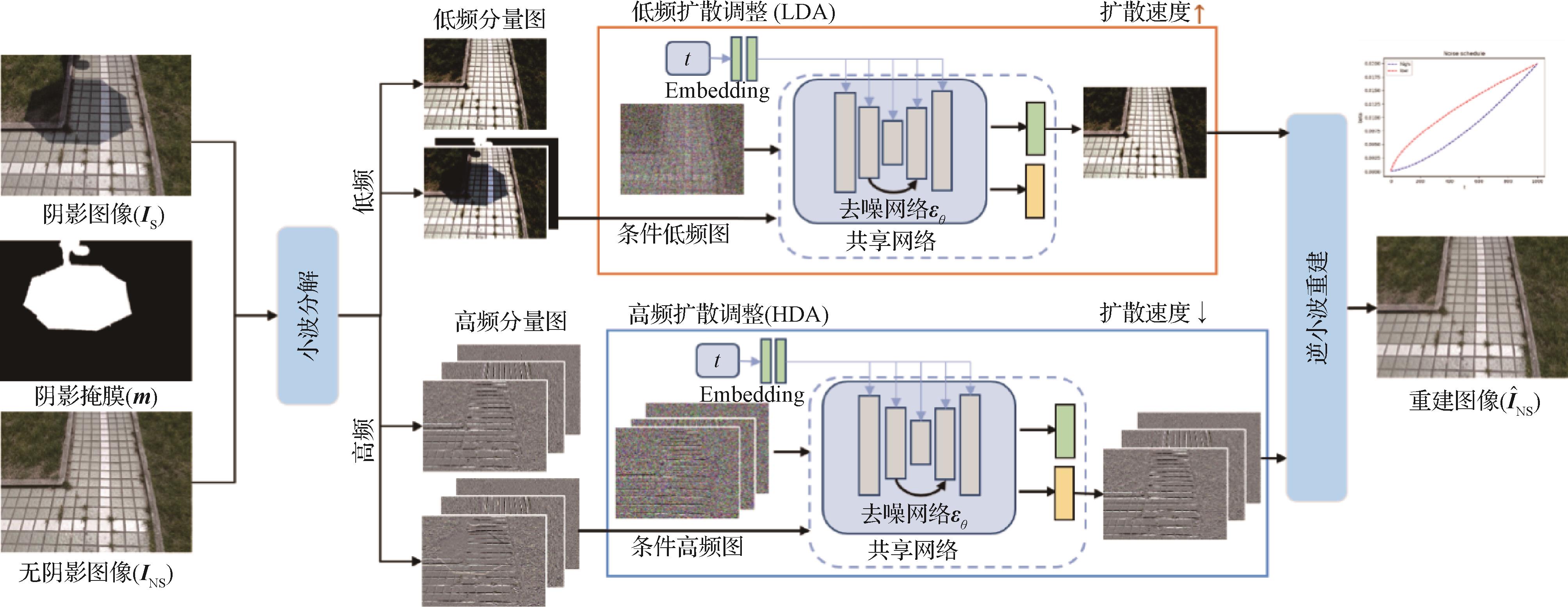 摘要:目的现有的阴影去除方法通常依赖于像素级重建,旨在学习阴影图像和无阴影图像之间的确定性映射关系。然而阴影去除关注阴影区域的局部恢复,容易导致在去除阴影的同时破坏非阴影区域。此外,现有的大多数扩散模型在恢复图像时存在耗时过长和对分辨率敏感等问题。为此,提出了一种用于阴影去除的小波非均匀扩散模型。方法首先将图像通过小波分解为低频分量与高频分量,然后针对低频和高频分量分别设计扩散生成网络来重建无阴影图像的小波域分布,并分别恢复这些分量中的各种退化信息,如低频(颜色、亮度)和高频细节等。结果实验在3个阴影数据集上进行训练和测试,在SRD(shadow removal dataset)数据集中,与9种代表性方法进行比较,在非阴影区域和整幅图像上,峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity index,SSIM)和均方根误差(root mean square error,RMSE)均取得最优或次优的结果;在ISTD+(augmented dataset with image shadow triplets)数据集中,与6种代表性方法进行比较,在非阴影区域上,性能取得了最佳,PSNR和RMSE分别提高了0.47 dB和0.1。除此之外,在SRD数据集上,ShadowDiffusion方法在生成不同分辨率图像时性能有明显差异,而本文方法性能基本保持稳定。此外,本文方法生成速度与其相比提高了约4倍。结论提出的方法能够加快扩散模型的采样速度,在去除阴影的同时,恢复出阴影区域缺失的颜色、亮度和丰富的细节等信息。关键词:阴影去除;扩散模型(DM);小波变换;双分支网络;噪声调度表189|129|0更新时间:2025-04-11
摘要:目的现有的阴影去除方法通常依赖于像素级重建,旨在学习阴影图像和无阴影图像之间的确定性映射关系。然而阴影去除关注阴影区域的局部恢复,容易导致在去除阴影的同时破坏非阴影区域。此外,现有的大多数扩散模型在恢复图像时存在耗时过长和对分辨率敏感等问题。为此,提出了一种用于阴影去除的小波非均匀扩散模型。方法首先将图像通过小波分解为低频分量与高频分量,然后针对低频和高频分量分别设计扩散生成网络来重建无阴影图像的小波域分布,并分别恢复这些分量中的各种退化信息,如低频(颜色、亮度)和高频细节等。结果实验在3个阴影数据集上进行训练和测试,在SRD(shadow removal dataset)数据集中,与9种代表性方法进行比较,在非阴影区域和整幅图像上,峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity index,SSIM)和均方根误差(root mean square error,RMSE)均取得最优或次优的结果;在ISTD+(augmented dataset with image shadow triplets)数据集中,与6种代表性方法进行比较,在非阴影区域上,性能取得了最佳,PSNR和RMSE分别提高了0.47 dB和0.1。除此之外,在SRD数据集上,ShadowDiffusion方法在生成不同分辨率图像时性能有明显差异,而本文方法性能基本保持稳定。此外,本文方法生成速度与其相比提高了约4倍。结论提出的方法能够加快扩散模型的采样速度,在去除阴影的同时,恢复出阴影区域缺失的颜色、亮度和丰富的细节等信息。关键词:阴影去除;扩散模型(DM);小波变换;双分支网络;噪声调度表189|129|0更新时间:2025-04-11 -
面向非均质图像去雾的解耦合三阶段增强网络 AI导读
“在图像处理领域,专家提出了一种解耦合三阶段增强网络,有效去除非均质雾霾图像中的雾霾并还原真实细节信息和颜色。” 摘要:目的在雾霾环境下拍摄的图像通常具有结构对比度较低、细节信息模糊和颜色饱和度失真等特点。虽然目前的去雾算法已经能较好地处理均质雾霾图像,但是对于非均质雾霾图像的去雾能力仍较差。为此,提出了一种面向非均质雾霾图像去雾的解耦合三阶段增强网络。方法通过颜色空间变换将输入图像解耦为亮度、饱和度和色度3个通道之后,该算法首先通过对比度增强模块增强亮度图的对比度,使去雾结果具有更清晰的结构和细节信息;然后,通过饱和度增强模块增强图像的饱和度,使去雾结果具有更鲜艳的颜色;最后,使用颜色矫正增强模块对总体颜色进行微调,使去雾结果更符合人眼视觉感知。特别地,在饱和度增强模块中设计了一个雾霾密度编码矩阵,通过计算亮度图在对比度增强前后的梯度差异,估计出雾霾图像的雾霾密度信息,为饱和度增强模块提供指导,以保证饱和度恢复的准确性。结果在3个数据集上与14种方法进行了对比实验,本文方法在NHD(non-homogeneous dataset)数据集上得到了最优结果,相比于性能第2的模型,平均峰值信噪比提升了8.5 dB,平均结构相似性提升了0.12;在Real-World数据集中,本文方法的感知雾密度预测值为0.47,雾密度估计值为0.21,均处于前列;在SOTS(synthetic object testing set)数据集中,本文方法的平均峰值信噪比为16.52 dB,平均结构相似性为0.80,在人眼感知效果方面不输于已有方法。结论本文所提方法对于非均质雾霾图像具有优秀的处理能力,可以有效地去除图像的雾霾并还原出雾霾图像的真实细节信息和颜色。关键词:深度学习;非均质图像去雾;饱和度增强;对比度增强;三阶段增强,雾霾密度编码矩阵152|171|0更新时间:2025-04-11
摘要:目的在雾霾环境下拍摄的图像通常具有结构对比度较低、细节信息模糊和颜色饱和度失真等特点。虽然目前的去雾算法已经能较好地处理均质雾霾图像,但是对于非均质雾霾图像的去雾能力仍较差。为此,提出了一种面向非均质雾霾图像去雾的解耦合三阶段增强网络。方法通过颜色空间变换将输入图像解耦为亮度、饱和度和色度3个通道之后,该算法首先通过对比度增强模块增强亮度图的对比度,使去雾结果具有更清晰的结构和细节信息;然后,通过饱和度增强模块增强图像的饱和度,使去雾结果具有更鲜艳的颜色;最后,使用颜色矫正增强模块对总体颜色进行微调,使去雾结果更符合人眼视觉感知。特别地,在饱和度增强模块中设计了一个雾霾密度编码矩阵,通过计算亮度图在对比度增强前后的梯度差异,估计出雾霾图像的雾霾密度信息,为饱和度增强模块提供指导,以保证饱和度恢复的准确性。结果在3个数据集上与14种方法进行了对比实验,本文方法在NHD(non-homogeneous dataset)数据集上得到了最优结果,相比于性能第2的模型,平均峰值信噪比提升了8.5 dB,平均结构相似性提升了0.12;在Real-World数据集中,本文方法的感知雾密度预测值为0.47,雾密度估计值为0.21,均处于前列;在SOTS(synthetic object testing set)数据集中,本文方法的平均峰值信噪比为16.52 dB,平均结构相似性为0.80,在人眼感知效果方面不输于已有方法。结论本文所提方法对于非均质雾霾图像具有优秀的处理能力,可以有效地去除图像的雾霾并还原出雾霾图像的真实细节信息和颜色。关键词:深度学习;非均质图像去雾;饱和度增强;对比度增强;三阶段增强,雾霾密度编码矩阵152|171|0更新时间:2025-04-11
图像处理和编码
- “在图像识别领域,专家提出了BSGAN-GP模型,有效提升了少数类识别准确度,为深度学习图像识别提供新方案。”
 摘要:目的已有的深度学习图像识别模型严重依赖于大量专业人员手工标记的数据,这些专业图像标签信息难以获取,人工标记代价昂贵。实际场景中的数据集大多具有不平衡性,正负样本偏差严重导致模型在拟合时常偏向多数类,对少数类的识别精度不足。这严重阻碍了深度学习在实际图像识别中的广泛应用。方法结合半监督生成式对抗网络(semi-supervised generative adversarial netowrk)提出了一种新的平衡模型架构BSGAN-GP(balancing semi-supervised generative adversarial network-gradient penalty),使得半监督生成式对抗网络的鉴别器可以公平地判别每一个类。其中,提出的类别均衡随机选择算法(class balancing random selection,CBRS)可以解决图像样本类别不均导致少数类识别准确度低的问题。将真实数据中有标签数据按类别随机选择,使得输入的有标签数据每个类别都有相同的数量,然后将训练后参数固定的生成器NetG生成每个类同等数量的假样本输入鉴别器,更新鉴别器NetD保证了鉴别器可以公平地判别所有类;同时BSGAN-GP在鉴别器损失函数中添加了一个额外的梯度惩罚项,使得模型训练更稳定。结果实验在3个主流数据集上与9种图像识别方法(包含6种半监督方法和3种全监督方法)进行了比较。为了证明对少数类的识别准确度提升,制定了3个数据集的不平衡版本。在Fashion-MNIST 数据集中,相比于基线模型,总体准确率提高了3.281%,少数类识别率提升了7.14%;在MNIST数据集中,相比于基线模型,对应的4个少数类识别率提升了2.68%~7.40%;在SVHN(street view house number)数据集中,相比于基线模型,总体准确率提高了3.515%。同时也在3个数据集中进行了合成图像质量对比以验证CBRS算法的有效性,其少数类合成图像质量以及数量的提升证明了其效果。消融实验评估了所提出模块CBRS与引进模块在网络中的重要性。结论本文所提出的BSGAN-GP模型能够实现更公平的图像识别以及更高质量的合成图像结果。实验结果开放源代码地址为https://github.com/zrm0616/BSGAN-GP.git。关键词:深度学习;半监督学习(SSL);生成式对抗网络(GAN);不平衡性图像识别;梯度惩罚141|142|0更新时间:2025-04-11
摘要:目的已有的深度学习图像识别模型严重依赖于大量专业人员手工标记的数据,这些专业图像标签信息难以获取,人工标记代价昂贵。实际场景中的数据集大多具有不平衡性,正负样本偏差严重导致模型在拟合时常偏向多数类,对少数类的识别精度不足。这严重阻碍了深度学习在实际图像识别中的广泛应用。方法结合半监督生成式对抗网络(semi-supervised generative adversarial netowrk)提出了一种新的平衡模型架构BSGAN-GP(balancing semi-supervised generative adversarial network-gradient penalty),使得半监督生成式对抗网络的鉴别器可以公平地判别每一个类。其中,提出的类别均衡随机选择算法(class balancing random selection,CBRS)可以解决图像样本类别不均导致少数类识别准确度低的问题。将真实数据中有标签数据按类别随机选择,使得输入的有标签数据每个类别都有相同的数量,然后将训练后参数固定的生成器NetG生成每个类同等数量的假样本输入鉴别器,更新鉴别器NetD保证了鉴别器可以公平地判别所有类;同时BSGAN-GP在鉴别器损失函数中添加了一个额外的梯度惩罚项,使得模型训练更稳定。结果实验在3个主流数据集上与9种图像识别方法(包含6种半监督方法和3种全监督方法)进行了比较。为了证明对少数类的识别准确度提升,制定了3个数据集的不平衡版本。在Fashion-MNIST 数据集中,相比于基线模型,总体准确率提高了3.281%,少数类识别率提升了7.14%;在MNIST数据集中,相比于基线模型,对应的4个少数类识别率提升了2.68%~7.40%;在SVHN(street view house number)数据集中,相比于基线模型,总体准确率提高了3.515%。同时也在3个数据集中进行了合成图像质量对比以验证CBRS算法的有效性,其少数类合成图像质量以及数量的提升证明了其效果。消融实验评估了所提出模块CBRS与引进模块在网络中的重要性。结论本文所提出的BSGAN-GP模型能够实现更公平的图像识别以及更高质量的合成图像结果。实验结果开放源代码地址为https://github.com/zrm0616/BSGAN-GP.git。关键词:深度学习;半监督学习(SSL);生成式对抗网络(GAN);不平衡性图像识别;梯度惩罚141|142|0更新时间:2025-04-11 -
特征重排列注意力机制的双池化残差分类网络 AI导读
“在图像分类领域,FDPRNet通过特征重排列注意力机制和双池化残差结构,显著提升了分类准确率和模型泛化能力。” 摘要:目的针对残差图像分类网络中通道信息交互不充分导致通道特征没有得到有效利用,同时残差结构使部分特征信息丢失的问题,本文提出特征重排列注意力机制的双池化残差分类网络(double-pooling residual classification network of feature reordering attention mechanism,FDPRNet)。方法FDPRNet以ResNet-34 (residual network)残差网络为基础,首先将第1层卷积核尺寸从
摘要:目的针对残差图像分类网络中通道信息交互不充分导致通道特征没有得到有效利用,同时残差结构使部分特征信息丢失的问题,本文提出特征重排列注意力机制的双池化残差分类网络(double-pooling residual classification network of feature reordering attention mechanism,FDPRNet)。方法FDPRNet以ResNet-34 (residual network)残差网络为基础,首先将第1层卷积核尺寸从 - “在行为识别领域,研究者提出了基于判别行为信息增量学习的空—地场景多视角行为识别方法,显著提高了网络的特征学习能力,为多视角任务提供了新解决方案。”
 摘要:目的随着社会民生需求的日益增长,地面设备联合无人机等空中设备进行空—地多视角场景下的行为识别应运而生。现有方法只关注水平空间视角变化时的视角关系,忽视了垂直空间变化带来的巨大判别行为差异。由于高度不同,同一物体的观测特征差异显著,对传统的多视角动作识别方法在应对垂直空间视角变化时构成了重大挑战。方法本文将显著的动作外观差异定义为辨别动作信息的差异,提出了一种基于判别行为信息增量学习(discriminative action information incremental learning,DAIL)的空—地场景多视角行为识别方法,根据视角高度和信息量判别地面视角和空中视角。引入类脑“由易到难,循序渐进”的思想,分别蒸馏不同视角的判别行为信息,将地面视角(简单)样本的判别行为信息增量到空中视角(困难)样本中,辅助网络学习空中视角样本。结果在Drone-Action和UAV(unmanned aerial vehicle)两个数据集上进行了实验,对比于当前先进方法SBP(stochastic backpropagation),在两个数据集上准确率分别提高了18.0%和16.2%;对比于强基线方法,本文方法在UAV数据集上参数量减少了2.4 M,计算量减少了6.9 G。结论所提出的方法表明通过使用简单样本增强复杂样本,显著提高了网络的特征学习能力。相反,尝试反向操作会导致准确性下降。本文从新角度讨论多视角行为识别任务,兼具效果和性能,在常见的高空视角数据集中优于代表性的方法且可拓展到其他多视角任务。关键词:多视角行为识别;增量学习;样本分类;判别行为信息;蒸馏学习87|116|0更新时间:2025-04-11
摘要:目的随着社会民生需求的日益增长,地面设备联合无人机等空中设备进行空—地多视角场景下的行为识别应运而生。现有方法只关注水平空间视角变化时的视角关系,忽视了垂直空间变化带来的巨大判别行为差异。由于高度不同,同一物体的观测特征差异显著,对传统的多视角动作识别方法在应对垂直空间视角变化时构成了重大挑战。方法本文将显著的动作外观差异定义为辨别动作信息的差异,提出了一种基于判别行为信息增量学习(discriminative action information incremental learning,DAIL)的空—地场景多视角行为识别方法,根据视角高度和信息量判别地面视角和空中视角。引入类脑“由易到难,循序渐进”的思想,分别蒸馏不同视角的判别行为信息,将地面视角(简单)样本的判别行为信息增量到空中视角(困难)样本中,辅助网络学习空中视角样本。结果在Drone-Action和UAV(unmanned aerial vehicle)两个数据集上进行了实验,对比于当前先进方法SBP(stochastic backpropagation),在两个数据集上准确率分别提高了18.0%和16.2%;对比于强基线方法,本文方法在UAV数据集上参数量减少了2.4 M,计算量减少了6.9 G。结论所提出的方法表明通过使用简单样本增强复杂样本,显著提高了网络的特征学习能力。相反,尝试反向操作会导致准确性下降。本文从新角度讨论多视角行为识别任务,兼具效果和性能,在常见的高空视角数据集中优于代表性的方法且可拓展到其他多视角任务。关键词:多视角行为识别;增量学习;样本分类;判别行为信息;蒸馏学习87|116|0更新时间:2025-04-11 -
STNet:羽毛球运动小目标定位跟踪网络 AI导读
“在羽毛球定位跟踪领域,STNet算法通过热力图轮廓检测和时域特征提取,实现了羽毛球的准确定位和稳定跟踪,性能优于现有方法。” 摘要:目的相比于一般视频目标检测跟踪任务,视频羽毛球的实时定位跟踪主要面临两大难点:1)羽毛球属于小目标,同时伴有严重的运动模糊以及相似目标的干扰,使用基于矩形框的目标检测跟踪方法准确率低且会带来中心点误差问题;2)单帧图像很难准确定位羽毛球目标,利用视频前后帧的时域特征则可以跟踪到羽毛球目标,而现有提取时域特征的网络模块结构复杂,难以满足实时性要求。针对以上问题,本文使用热力图轮廓检测方法,提出了羽毛球运动小目标的定位跟踪网络算法(shuttlecock track net,STNet)。方法网络主体采用“U”型编解码结构;针对小目标像素信息少的问题,基于SE(squeeze and excitation)通道注意力与残差结构设计高效特征提取模块(SE channel attention and residual,SECAR),实现了空域信息的高效提取与传递,提高了网络的定位性能;针对目标丢失与相似目标干扰问题,设计了时序网络(temporal network,TPN)结构用于提取和记忆视频时域特征,提高了网络跟踪性能。结果在羽毛球比赛公开数据集TrackNetv2与自制数据集上的实验表明,本文方法在多个指标上取得了最好的性能表现。相较于现有性能较好的羽毛球定位跟踪方法TrackNetv2,本文方法在准确率、精确率和F1上分别提高7.5%、15.7%和7.5%,并且显著降低了参数量,满足实时处理需求(54帧/s)。结论本文提出的STNet羽毛球定位跟踪网络,在面对羽毛球目标外观剧烈变化以及背景干扰严重时,能够准确定位羽毛球比赛视频帧中可能存在的羽毛球,实现羽毛球的稳定跟踪,相比其他羽毛球定位跟踪网络,具有更优的性能。关键词:羽毛球定位跟踪;小目标;热力图;轮廓检测;编解码网络;时序网络134|191|0更新时间:2025-04-11
摘要:目的相比于一般视频目标检测跟踪任务,视频羽毛球的实时定位跟踪主要面临两大难点:1)羽毛球属于小目标,同时伴有严重的运动模糊以及相似目标的干扰,使用基于矩形框的目标检测跟踪方法准确率低且会带来中心点误差问题;2)单帧图像很难准确定位羽毛球目标,利用视频前后帧的时域特征则可以跟踪到羽毛球目标,而现有提取时域特征的网络模块结构复杂,难以满足实时性要求。针对以上问题,本文使用热力图轮廓检测方法,提出了羽毛球运动小目标的定位跟踪网络算法(shuttlecock track net,STNet)。方法网络主体采用“U”型编解码结构;针对小目标像素信息少的问题,基于SE(squeeze and excitation)通道注意力与残差结构设计高效特征提取模块(SE channel attention and residual,SECAR),实现了空域信息的高效提取与传递,提高了网络的定位性能;针对目标丢失与相似目标干扰问题,设计了时序网络(temporal network,TPN)结构用于提取和记忆视频时域特征,提高了网络跟踪性能。结果在羽毛球比赛公开数据集TrackNetv2与自制数据集上的实验表明,本文方法在多个指标上取得了最好的性能表现。相较于现有性能较好的羽毛球定位跟踪方法TrackNetv2,本文方法在准确率、精确率和F1上分别提高7.5%、15.7%和7.5%,并且显著降低了参数量,满足实时处理需求(54帧/s)。结论本文提出的STNet羽毛球定位跟踪网络,在面对羽毛球目标外观剧烈变化以及背景干扰严重时,能够准确定位羽毛球比赛视频帧中可能存在的羽毛球,实现羽毛球的稳定跟踪,相比其他羽毛球定位跟踪网络,具有更优的性能。关键词:羽毛球定位跟踪;小目标;热力图;轮廓检测;编解码网络;时序网络134|191|0更新时间:2025-04-11
图像分析和识别
-
知识增强的特征编辑重建蒸馏 AI导读
“在目标检测领域,研究者提出了一种新的知识蒸馏方法,有效提升了模型性能,并适用于多种检测器。” 摘要:目的知识蒸馏作为一种有效可行的模型压缩方法现已在图像分类领域得到了广泛的研究。由于目标检测网络的复杂性加大了知识蒸馏的难度,现有应用于目标检测的知识蒸馏方法效果并不理想。为此,提出一种适用于目标检测任务的知识蒸馏方法,即基于知识增强的特征编辑重建蒸馏,实现对目标检测模型的有效压缩。方法针对现有方法只在教师模型和学生模型的对应特征层之间进行蒸馏,无法充分利用教师模型中隐藏的“暗知识”的问题,通过空间注意力和通道注意力分别对教师特征进行自下而上和自上而下的多尺度特征融合以进行知识增强;针对当教师模型和学生模型能力差距过大时,学生模型无法理解教师模型的知识导致蒸馏性能受限的问题,通过将教师模型的部分特征作为先验知识融合到学生模型的特征中,以缩小教师模型和学生模型之间的表征能力差距,并删除学生模型特征的边缘、轮廓等细节信息,实现特征编辑,然后迫使学生模型利用剩余特征结合先验知识通过一个简单的卷积块来恢复删除的细节信息,进行特征重建,使学生模型在此过程中得到正向的反馈,从而学习到更好的特征。结果实验在两个数据集上采用基于ResNet50(residual network)的RetinaNet(retina network)、Faster R-CNN(faster region-based convolutional neural network)、FCOS(fully convolutional one-stage object detection)3种不同类型的检测器与最新的4种方法进行了比较,VOC2007(visual object classes 2007)测试集的平均精度均值(mean average precision,mAP)对比基线分别提高了2.1%、2.7%和3.8%;NEU-DET(Northeastern University surface defect database)测试集的mAP对比基线分别提高了2.7%、2.6%和2.1%,均高于当前性能最优的算法。结论本文所提出的方法能充分挖掘出教师模型的能力,有效提升学生模型的性能,同时适用于多种类型的目标检测器。关键词:模型压缩;知识蒸馏;知识增强;特征重建;目标检测90|111|0更新时间:2025-04-11
摘要:目的知识蒸馏作为一种有效可行的模型压缩方法现已在图像分类领域得到了广泛的研究。由于目标检测网络的复杂性加大了知识蒸馏的难度,现有应用于目标检测的知识蒸馏方法效果并不理想。为此,提出一种适用于目标检测任务的知识蒸馏方法,即基于知识增强的特征编辑重建蒸馏,实现对目标检测模型的有效压缩。方法针对现有方法只在教师模型和学生模型的对应特征层之间进行蒸馏,无法充分利用教师模型中隐藏的“暗知识”的问题,通过空间注意力和通道注意力分别对教师特征进行自下而上和自上而下的多尺度特征融合以进行知识增强;针对当教师模型和学生模型能力差距过大时,学生模型无法理解教师模型的知识导致蒸馏性能受限的问题,通过将教师模型的部分特征作为先验知识融合到学生模型的特征中,以缩小教师模型和学生模型之间的表征能力差距,并删除学生模型特征的边缘、轮廓等细节信息,实现特征编辑,然后迫使学生模型利用剩余特征结合先验知识通过一个简单的卷积块来恢复删除的细节信息,进行特征重建,使学生模型在此过程中得到正向的反馈,从而学习到更好的特征。结果实验在两个数据集上采用基于ResNet50(residual network)的RetinaNet(retina network)、Faster R-CNN(faster region-based convolutional neural network)、FCOS(fully convolutional one-stage object detection)3种不同类型的检测器与最新的4种方法进行了比较,VOC2007(visual object classes 2007)测试集的平均精度均值(mean average precision,mAP)对比基线分别提高了2.1%、2.7%和3.8%;NEU-DET(Northeastern University surface defect database)测试集的mAP对比基线分别提高了2.7%、2.6%和2.1%,均高于当前性能最优的算法。结论本文所提出的方法能充分挖掘出教师模型的能力,有效提升学生模型的性能,同时适用于多种类型的目标检测器。关键词:模型压缩;知识蒸馏;知识增强;特征重建;目标检测90|111|0更新时间:2025-04-11 -
多模态数据特征融合的广角图像生成 AI导读
“在图像拼接领域,研究人员提出了一种基于多模态数据特征融合的算法,有效提升了拼接效果和场景感知信息。” 摘要:目的图像拼接通过整合不同视角的可见光数据获得广角合成图。不利的天气因素会使采集到的可见光数据退化,导致拼接效果不佳。红外传感器通过热辐射成像,在不利的条件下也能突出目标,克服环境和人为因素的影响。方法考虑到红外传感器和可见光传感器的成像互补性,本文提出了一个基于多模态数据(红外和可见光数据)特征融合的图像拼接算法。首先利用红外数据准确的结构特征和可见光数据丰富的纹理细节由粗到细地进行偏移估计,并通过非参数化的直接线性变换得到变形矩阵。然后将拼接后的红外和可见光数据进行融合,丰富了场景感知信息。结果本文选择包含530对可拼接多模态图像的真实数据集以及包含200对合成数据集作为测试数据,选取了3个最新的融合方法,包括RFN(residual fusion network)、ReCoNet(recurrent correction network)和DATFuse(dual attention transformer),以及7个拼接方法,包括APAP(as projective as possible)、SPW(single-perspective warps)、WPIS(wide parallax image stitching)、SLAS(seam-guided local alignment and stitching)、VFIS(view-free image stitching)、RSFI(reconstructing stitched features to images)和UDIS++(unsupervised deep image stitching)组成的21种融合—拼接策略进行了定性和定量的性能对比。在拼接性能上,本文方法实现了准确的跨视角场景对齐,平均角点误差降低了53%,避免了鬼影的出现;在多模态互补信息整合方面,本文方法能自适应兼顾红外图像的结构信息以及可见光图像的丰富纹理细节,信息熵较DATFuse-UDIS++策略提升了24.6%。结论本文方法在结合了红外和可见光图像成像互补优势的基础上,通过多尺度递归估计实现了更加准确的大视角场景生成;与常规可见光图像拼接相比鲁棒性更强。关键词:多模态图像融合;图像拼接;卷积神经网络(CNN);红外—可见光图像;多尺度金字塔125|96|0更新时间:2025-04-11
摘要:目的图像拼接通过整合不同视角的可见光数据获得广角合成图。不利的天气因素会使采集到的可见光数据退化,导致拼接效果不佳。红外传感器通过热辐射成像,在不利的条件下也能突出目标,克服环境和人为因素的影响。方法考虑到红外传感器和可见光传感器的成像互补性,本文提出了一个基于多模态数据(红外和可见光数据)特征融合的图像拼接算法。首先利用红外数据准确的结构特征和可见光数据丰富的纹理细节由粗到细地进行偏移估计,并通过非参数化的直接线性变换得到变形矩阵。然后将拼接后的红外和可见光数据进行融合,丰富了场景感知信息。结果本文选择包含530对可拼接多模态图像的真实数据集以及包含200对合成数据集作为测试数据,选取了3个最新的融合方法,包括RFN(residual fusion network)、ReCoNet(recurrent correction network)和DATFuse(dual attention transformer),以及7个拼接方法,包括APAP(as projective as possible)、SPW(single-perspective warps)、WPIS(wide parallax image stitching)、SLAS(seam-guided local alignment and stitching)、VFIS(view-free image stitching)、RSFI(reconstructing stitched features to images)和UDIS++(unsupervised deep image stitching)组成的21种融合—拼接策略进行了定性和定量的性能对比。在拼接性能上,本文方法实现了准确的跨视角场景对齐,平均角点误差降低了53%,避免了鬼影的出现;在多模态互补信息整合方面,本文方法能自适应兼顾红外图像的结构信息以及可见光图像的丰富纹理细节,信息熵较DATFuse-UDIS++策略提升了24.6%。结论本文方法在结合了红外和可见光图像成像互补优势的基础上,通过多尺度递归估计实现了更加准确的大视角场景生成;与常规可见光图像拼接相比鲁棒性更强。关键词:多模态图像融合;图像拼接;卷积神经网络(CNN);红外—可见光图像;多尺度金字塔125|96|0更新时间:2025-04-11 -
面向行人再识别的朝向感知特征学习 AI导读
“在行人再识别领域,提出了朝向感知特征学习,有效改善了关联效果,为解决行人再识别问题提供新方案。” 摘要:目的在行人再识别中,行人朝向变化会导致表观变化,进而导致关联错误。现有方法通过朝向表示学习和基于朝向的损失函数来改善这一问题。然而,大多数朝向表示学习方法主要以嵌入朝向标签为主,并没有显式的向模型传达行人姿态的空间结构,从而减弱了模型对朝向的感知能力。此外,基于朝向的损失函数通常对相同身份的行人进行朝向聚类,忽略了由表观相似且朝向相同的负样本造成的错误关联的问题。方法为了应对这些挑战,提出了面向行人再识别的朝向感知特征学习。首先,提出了基于人体姿态的朝向特征学习,它能够显式地捕捉人体姿态的空间结构。其次,提出的朝向自适应的三元组损失主动增大表观相似且相同朝向行人之间的间隔,进而将它们分离。结果本文方法在大规模的行人再识别公开数据集MSMT17(multi-scene multi-time person ReID dataset)、Market1501等上进行测试。其中,在MSMT17数据集上,相比于性能第2的UniHCP(unified model for human-centric perceptions)模型,Rank1和mAP值分别提高了1.7%和1.3%;同时,在MSMT17数据集上的消融实验结果证明本文提出的算法有效改善了行人再识别的关联效果。结论本文方法能够有效处理上述挑战导致的行人再识别系统中关联效果变差的问题。关键词:行人再识别;行人朝向;自适应朝向;表观相似;朝向感知94|113|0更新时间:2025-04-11
摘要:目的在行人再识别中,行人朝向变化会导致表观变化,进而导致关联错误。现有方法通过朝向表示学习和基于朝向的损失函数来改善这一问题。然而,大多数朝向表示学习方法主要以嵌入朝向标签为主,并没有显式的向模型传达行人姿态的空间结构,从而减弱了模型对朝向的感知能力。此外,基于朝向的损失函数通常对相同身份的行人进行朝向聚类,忽略了由表观相似且朝向相同的负样本造成的错误关联的问题。方法为了应对这些挑战,提出了面向行人再识别的朝向感知特征学习。首先,提出了基于人体姿态的朝向特征学习,它能够显式地捕捉人体姿态的空间结构。其次,提出的朝向自适应的三元组损失主动增大表观相似且相同朝向行人之间的间隔,进而将它们分离。结果本文方法在大规模的行人再识别公开数据集MSMT17(multi-scene multi-time person ReID dataset)、Market1501等上进行测试。其中,在MSMT17数据集上,相比于性能第2的UniHCP(unified model for human-centric perceptions)模型,Rank1和mAP值分别提高了1.7%和1.3%;同时,在MSMT17数据集上的消融实验结果证明本文提出的算法有效改善了行人再识别的关联效果。结论本文方法能够有效处理上述挑战导致的行人再识别系统中关联效果变差的问题。关键词:行人再识别;行人朝向;自适应朝向;表观相似;朝向感知94|113|0更新时间:2025-04-11 -
面向平面扫描图像的用户定制意图理解智能体 AI导读
“在移动端应用领域,专家提出了用户定制意图理解智能体,有效应对小样本增量问题,为平面扫描图像理解提供新思路。” 摘要:目的移动端应用中对平面扫描图像的用户意图理解是常见的现实需求,传统方法主要是利用大量用户历史行为数据进行建模,预测用户对新图像的意图,但该应用场景面临着定制化问题、交互次数少等挑战,限制了传统方法的效果。而近几年出现的智能体方法可以较好地应对这些挑战,为定制意图理解任务提供了新的思路。基于此,提出了一个面向平面扫描图像的用户定制意图理解智能体。方法智能体由任务感知、任务规划、任务执行与反馈校正模块构成,并针对方法面临的小样本增量问题以及计算资源有限、基准数据集不足等技术挑战,首先提出了“分而治之”的域泛化方法,将基任务与定制化任务的推理解耦,使其互不影响。其次通过模板匹配进行意图理解,以实现无需微调即可应对新的定制化任务的功能。然后通过自提升策略减少意图理解结果噪声,提升域泛化的可靠性。此外还构建了平面扫描图像的定制意图理解基准数据集。结果本文智能体在所提出的基准数据集上与其他7种方法进行了比较,在平均交并比(mean intersection over union, mIoU)指标上,智能体的mIoU达90.47%,相比于性能第2的方法提高了15.60%,总正确率提高了22.10%。同时进行了消融实验,验证了智能体各部分的有效性。最后将智能体应用在公开票据数据集CORD(consolidated receipt dataset)上,验证了智能体的泛化能力。结论本文提出的智能体超越了前沿检测和分割模型在平面扫描图像的定制意图理解任务上的表现,同时回避了对每个子任务微调模型的过程,方法具有有效性和高效性。关键词:用户意图理解;智能体;小样本增量学习;显著性检测;交互式分割88|94|0更新时间:2025-04-11
摘要:目的移动端应用中对平面扫描图像的用户意图理解是常见的现实需求,传统方法主要是利用大量用户历史行为数据进行建模,预测用户对新图像的意图,但该应用场景面临着定制化问题、交互次数少等挑战,限制了传统方法的效果。而近几年出现的智能体方法可以较好地应对这些挑战,为定制意图理解任务提供了新的思路。基于此,提出了一个面向平面扫描图像的用户定制意图理解智能体。方法智能体由任务感知、任务规划、任务执行与反馈校正模块构成,并针对方法面临的小样本增量问题以及计算资源有限、基准数据集不足等技术挑战,首先提出了“分而治之”的域泛化方法,将基任务与定制化任务的推理解耦,使其互不影响。其次通过模板匹配进行意图理解,以实现无需微调即可应对新的定制化任务的功能。然后通过自提升策略减少意图理解结果噪声,提升域泛化的可靠性。此外还构建了平面扫描图像的定制意图理解基准数据集。结果本文智能体在所提出的基准数据集上与其他7种方法进行了比较,在平均交并比(mean intersection over union, mIoU)指标上,智能体的mIoU达90.47%,相比于性能第2的方法提高了15.60%,总正确率提高了22.10%。同时进行了消融实验,验证了智能体各部分的有效性。最后将智能体应用在公开票据数据集CORD(consolidated receipt dataset)上,验证了智能体的泛化能力。结论本文提出的智能体超越了前沿检测和分割模型在平面扫描图像的定制意图理解任务上的表现,同时回避了对每个子任务微调模型的过程,方法具有有效性和高效性。关键词:用户意图理解;智能体;小样本增量学习;显著性检测;交互式分割88|94|0更新时间:2025-04-11 - “在目标跟踪领域,研究者提出了融合上下文感知注意力的Transformer跟踪方法,有效提升了跟踪性能。”
 摘要:目的近年来,Transformer跟踪器取得突破性的进展,其中自注意力机制发挥了重要作用。当前,自注意力机制中独立关联计算易导致权重不明显现象,限制了跟踪方法性能。为此,提出了一种融合上下文感知注意力的Transformer目标跟踪方法。方法首先,引入SwinTransformer(hierarchical vision Transformer using shifted windows)以提取视觉特征,利用跨尺度策略整合深层与浅层的特征信息,提高网络对复杂场景中目标表征能力。其次,构建了基于上下文感知注意力的编解码器,充分融合模板特征和搜索特征。上下文感知注意力使用嵌套注意计算,加入分配权重的目标掩码,可有效抑制由相关性计算不准确导致的噪声。最后,使用角点预测头估计目标边界框,通过相似度分数结果更新模板图像。结果在TrackingNet(large-scale object tracking dataset)、LaSOT(large-scale single object tracking)和GOT-10K(generic object tracking benchmark)等多个公开数据集上开展大量测试,本文方法均取得了优异性能。在GOT-10K上平均重叠率达到73.9%,在所有对比方法中排在第1位;在LaSOT上的AUC(area under curve)得分和精准度为0.687、0.749,与性能第2的ToMP(transforming model prediction for tracking)相比分别提高了1.1%和2.7%;在TrackingNet上的AUC得分和精准度为0.831、0.807,较第 2 名分别高出 0.8%和0.3%。结论所提方法利用上下文感知注意力聚焦特征序列中的目标信息,提高了向量交互的精确性,可有效应对快速运动、相似物干扰等问题,提升了跟踪性能。关键词:计算机视觉;目标跟踪;上下文感知注意力;Transformer;特征融合120|168|0更新时间:2025-04-11
摘要:目的近年来,Transformer跟踪器取得突破性的进展,其中自注意力机制发挥了重要作用。当前,自注意力机制中独立关联计算易导致权重不明显现象,限制了跟踪方法性能。为此,提出了一种融合上下文感知注意力的Transformer目标跟踪方法。方法首先,引入SwinTransformer(hierarchical vision Transformer using shifted windows)以提取视觉特征,利用跨尺度策略整合深层与浅层的特征信息,提高网络对复杂场景中目标表征能力。其次,构建了基于上下文感知注意力的编解码器,充分融合模板特征和搜索特征。上下文感知注意力使用嵌套注意计算,加入分配权重的目标掩码,可有效抑制由相关性计算不准确导致的噪声。最后,使用角点预测头估计目标边界框,通过相似度分数结果更新模板图像。结果在TrackingNet(large-scale object tracking dataset)、LaSOT(large-scale single object tracking)和GOT-10K(generic object tracking benchmark)等多个公开数据集上开展大量测试,本文方法均取得了优异性能。在GOT-10K上平均重叠率达到73.9%,在所有对比方法中排在第1位;在LaSOT上的AUC(area under curve)得分和精准度为0.687、0.749,与性能第2的ToMP(transforming model prediction for tracking)相比分别提高了1.1%和2.7%;在TrackingNet上的AUC得分和精准度为0.831、0.807,较第 2 名分别高出 0.8%和0.3%。结论所提方法利用上下文感知注意力聚焦特征序列中的目标信息,提高了向量交互的精确性,可有效应对快速运动、相似物干扰等问题,提升了跟踪性能。关键词:计算机视觉;目标跟踪;上下文感知注意力;Transformer;特征融合120|168|0更新时间:2025-04-11 -
多视图一致性约束的神经隐式表面重建 AI导读
“在三维重建领域,研究者提出了一种结合多视图一致性约束的神经隐式表面重建方法,有效提高了复杂结构物体的重建质量。” 摘要:目的通过体渲染学习的神经隐式表面表达是近两年涌现的多视图三维重建方法。针对具有开放表面非水密特点的目标物体,基于无符号距离函数(unsigned distance function,UDF)的神经隐式表面重建能够解决有符号距离函数(signed distance function,SDF)神经隐式表面重建方法的缺陷,重建精度更高。但是,该方法难以捕获多视图特征,对结构复杂、自遮挡的物体的三维重建容易出现模型缺失、形状偏差等问题。鉴于此,提出一种将多视图一致性约束与神经隐式表面重建相结合的方法。方法首先介绍在体渲染阶段使用的渲染权重和采样权重函数,确保实现无偏渲染,提高体渲染阶段精度以约束UDF网络的训练。然后,提出多视图几何一致性约束,关注重建模型中较大的光滑区域,通过显式约束获取更多复杂几何和纹理信息。最后结合多视图几何重建中提取特征的卷积网络,获取多视角的二维图像特征,通过最小化多视图深度特征提高学习隐式表面的神经网络的重建精度。结果实验在DTU数据集、DF3D(DeepFashion3D)服装数据集以及自采集的植物数据集上得到了更精细的表面,渲染结果更接近原始图像。在DTU数据集上与基准NeuS方法相比,倒角距离表示的几何结构误差平均值降低了0.16 mm,峰值信噪比表示的重建指标平均值提高了1.04 dB;在DF3D数据集上与NeuS、NeUDF方法相比,倒角距离平均值分别降低了2.76 mm、0.11 mm。重建得到的植物模型与服装模型具有高精度和完整的结构。结论本文提出的多视图一致性约束的神经隐式表面重建方法充分利用多视角图像的特征信息,提高了三维重建模型的质量,在复杂结构(如生长过程中的植物)和具有开放表面非水密的物体的三维重建上明显优于现有的先进方法。关键词:三维重建;神经隐式表面;几何一致性;多视图特征一致性;网格模型89|114|0更新时间:2025-04-11
摘要:目的通过体渲染学习的神经隐式表面表达是近两年涌现的多视图三维重建方法。针对具有开放表面非水密特点的目标物体,基于无符号距离函数(unsigned distance function,UDF)的神经隐式表面重建能够解决有符号距离函数(signed distance function,SDF)神经隐式表面重建方法的缺陷,重建精度更高。但是,该方法难以捕获多视图特征,对结构复杂、自遮挡的物体的三维重建容易出现模型缺失、形状偏差等问题。鉴于此,提出一种将多视图一致性约束与神经隐式表面重建相结合的方法。方法首先介绍在体渲染阶段使用的渲染权重和采样权重函数,确保实现无偏渲染,提高体渲染阶段精度以约束UDF网络的训练。然后,提出多视图几何一致性约束,关注重建模型中较大的光滑区域,通过显式约束获取更多复杂几何和纹理信息。最后结合多视图几何重建中提取特征的卷积网络,获取多视角的二维图像特征,通过最小化多视图深度特征提高学习隐式表面的神经网络的重建精度。结果实验在DTU数据集、DF3D(DeepFashion3D)服装数据集以及自采集的植物数据集上得到了更精细的表面,渲染结果更接近原始图像。在DTU数据集上与基准NeuS方法相比,倒角距离表示的几何结构误差平均值降低了0.16 mm,峰值信噪比表示的重建指标平均值提高了1.04 dB;在DF3D数据集上与NeuS、NeUDF方法相比,倒角距离平均值分别降低了2.76 mm、0.11 mm。重建得到的植物模型与服装模型具有高精度和完整的结构。结论本文提出的多视图一致性约束的神经隐式表面重建方法充分利用多视角图像的特征信息,提高了三维重建模型的质量,在复杂结构(如生长过程中的植物)和具有开放表面非水密的物体的三维重建上明显优于现有的先进方法。关键词:三维重建;神经隐式表面;几何一致性;多视图特征一致性;网格模型89|114|0更新时间:2025-04-11 - “在直升机桨叶检测领域,研究人员提出了一种融合多特征与自注意力的旋转目标检测器FMSA-RD,有效提升了室外复杂光照背景下桨叶的检测精度和速度。”
 摘要:目的桨叶运动参数是直升机设计到生产的重要指标,传统的视觉测量方法直接应用于室外环境下,由于受复杂光照背景影响,存在找不到桨叶区域、不能进行准确测量的问题。据此,本文提出一种融合多特征与自注意力的旋转目标检测器(fusion multi-feature and self-attention rotating detector,FMSA-RD)。方法首先,针对YOLOv5s(you only look once)特征提取能力不足和冗余问题,在主干网络中设计了更为有效的多特征提取和融合模块,结合不同时刻位置与尺度下的特征信息以提高网络对室外桨叶的检测精度;并去掉部分无关卷积层以简化模块结构参数。其次,融合多头自注意力机制与CSP(crossstage partial convolution)瓶颈结构,整合全局信息以抑制室外复杂光照背景干扰。最后,引入倾斜交并比(skew intersection over union,SKEWIOU)损失和角度损失,改进损失函数,进一步提升桨叶检测精度。结果本文进行了多组对比实验,分别在自制的室外直升机桨叶数据集和公共数据集DOTA-v1.0(dataset for object detection in aerial images)上进行验证,对比基线YOLOv5s目标检测网络,本文模型平均精度均值(mean average precision,mAP)分别提高6.6%和12.8%,帧速率(frames per second,FPS)分别提高21.8%和47.7%。结论本文设计的旋转目标检测模型,提升了室外复杂光照背景下桨叶的检测精度和速度。关键词:室外直升机桨叶;旋转目标检测;多特征;多头自注意力机制(MHSA);损失函数83|64|0更新时间:2025-04-11
摘要:目的桨叶运动参数是直升机设计到生产的重要指标,传统的视觉测量方法直接应用于室外环境下,由于受复杂光照背景影响,存在找不到桨叶区域、不能进行准确测量的问题。据此,本文提出一种融合多特征与自注意力的旋转目标检测器(fusion multi-feature and self-attention rotating detector,FMSA-RD)。方法首先,针对YOLOv5s(you only look once)特征提取能力不足和冗余问题,在主干网络中设计了更为有效的多特征提取和融合模块,结合不同时刻位置与尺度下的特征信息以提高网络对室外桨叶的检测精度;并去掉部分无关卷积层以简化模块结构参数。其次,融合多头自注意力机制与CSP(crossstage partial convolution)瓶颈结构,整合全局信息以抑制室外复杂光照背景干扰。最后,引入倾斜交并比(skew intersection over union,SKEWIOU)损失和角度损失,改进损失函数,进一步提升桨叶检测精度。结果本文进行了多组对比实验,分别在自制的室外直升机桨叶数据集和公共数据集DOTA-v1.0(dataset for object detection in aerial images)上进行验证,对比基线YOLOv5s目标检测网络,本文模型平均精度均值(mean average precision,mAP)分别提高6.6%和12.8%,帧速率(frames per second,FPS)分别提高21.8%和47.7%。结论本文设计的旋转目标检测模型,提升了室外复杂光照背景下桨叶的检测精度和速度。关键词:室外直升机桨叶;旋转目标检测;多特征;多头自注意力机制(MHSA);损失函数83|64|0更新时间:2025-04-11 - “在三维人体姿态估计领域,CFJCNet算法通过联合多视图融合和关节相关性,优化二维估计结果,有效提高三维姿态估计精确度。”
 摘要:目的多视图三维人体姿态估计能够从多方位的二维图像中估计出各个关节点的深度信息,克服单目三维人体姿态估计中因遮挡和深度模糊导致的不适定性问题,但如果系统性能被二维姿态估计结果的有效性所约束,则难以实现最终三维估计精度的进一步提升。为此,提出了一种联合多视图可控融合和关节相关性的三维人体姿态估计算法CFJCNet(controlled fusion and joint correlation network),包括多视图融合优化模块、二维姿态细化模块和结构化三角剖分模块3部分。方法首先,基于极线几何框架的多视图可控融合优化模块有选择地利用极线几何原理提高二维热图的估计质量,并减少噪声引入;然后,基于图卷积与注意力机制联合学习的二维姿态细化方法以单视图中关节点之间的联系性为约束,更好地学习人体的整体和局部信息,优化二维姿态估计;最后,引入结构化三角剖分以获取人体骨长先验知识,嵌入三维重建过程,改进三维人体姿态的估计性能。结果该算法在两个公共数据集Human3.6M、Total Capture和一个合成数据集Occlusion-Person上进行了评估实验,平均关节误差为17.1 mm、18.7 mm和10.2 mm,明显优于现有的多视图三维人体姿态估计算法。结论本文提出了一个能够构建多视图间人体关节一致性联系以及各自视图中人体骨架内在拓扑约束的多视图三维人体姿态估计算法,优化二维估计结果,修正错误姿态,有效地提高了三维人体姿态估计的精确度,取得了最佳的估计结果。关键词:多视图;三维人体姿态估计;关节相关性;图卷积网络(GCN);注意力机制;三角剖分78|92|0更新时间:2025-04-11
摘要:目的多视图三维人体姿态估计能够从多方位的二维图像中估计出各个关节点的深度信息,克服单目三维人体姿态估计中因遮挡和深度模糊导致的不适定性问题,但如果系统性能被二维姿态估计结果的有效性所约束,则难以实现最终三维估计精度的进一步提升。为此,提出了一种联合多视图可控融合和关节相关性的三维人体姿态估计算法CFJCNet(controlled fusion and joint correlation network),包括多视图融合优化模块、二维姿态细化模块和结构化三角剖分模块3部分。方法首先,基于极线几何框架的多视图可控融合优化模块有选择地利用极线几何原理提高二维热图的估计质量,并减少噪声引入;然后,基于图卷积与注意力机制联合学习的二维姿态细化方法以单视图中关节点之间的联系性为约束,更好地学习人体的整体和局部信息,优化二维姿态估计;最后,引入结构化三角剖分以获取人体骨长先验知识,嵌入三维重建过程,改进三维人体姿态的估计性能。结果该算法在两个公共数据集Human3.6M、Total Capture和一个合成数据集Occlusion-Person上进行了评估实验,平均关节误差为17.1 mm、18.7 mm和10.2 mm,明显优于现有的多视图三维人体姿态估计算法。结论本文提出了一个能够构建多视图间人体关节一致性联系以及各自视图中人体骨架内在拓扑约束的多视图三维人体姿态估计算法,优化二维估计结果,修正错误姿态,有效地提高了三维人体姿态估计的精确度,取得了最佳的估计结果。关键词:多视图;三维人体姿态估计;关节相关性;图卷积网络(GCN);注意力机制;三角剖分78|92|0更新时间:2025-04-11
图像理解和计算机视觉
- “在乳腺肿瘤诊断领域,专家提出了融合时空特征与时间约束的双模态模型STFTCM,有效提升诊断准确性,为患者生存率提高奠定基础。”
 摘要:目的综合考虑B型超声(B-mode ultrasound, B-US)和对比增强超声(contrast-enhanced ultrasound, CEUS)双模态信息有助于提升乳腺肿瘤诊断的准确性,从而利于提高患者生存率。然而,目前大多数模型只关注B-US的特征提取,忽视了CEUS特征的学习和双模态信息的融合处理。为解决上述问题,提出了一个融合时空特征与时间约束的双模态乳腺肿瘤诊断模型(spatio-temporal feature and temporal-constrained model, STFTCM)。方法首先,基于双模态信息的数据特点,采用异构双分支网络学习B-US和CEUS包含的时空特征。然后,设计时间注意力损失函数引导CEUS分支关注造影剂流入病灶区的时间窗口,从该窗口期内提取CEUS特征。最后,借助特征融合模块实现双分支网络之间的横向连接,通过将B-US特征作为CEUS分支补充信息的方式,完成双模态特征融合。结果在收集到的数据集上进行对比实验,STFTCM预测的正确率、敏感性、宏平均F1和AUC(area under the curve)指标均表现优秀,其中预测正确率达88.2%,领先于其他先进模型。消融实验中,时间注意力约束将模型预测正确率提升5.8%,特征融合使得模型诊断正确率相较于单分支模型至少提升2.9%。结论本文提出的STFTCM能有效地提取并融合处理B-US和CEUS双模态信息,给出准确的诊断结果。同时,时间注意力约束和特征融合模块可以显著地提升模型性能。关键词:双模态乳腺肿瘤诊断;时空特征;时间注意力约束;对比增强超声(CEUS);B型超声(B-US)114|79|0更新时间:2025-04-11
摘要:目的综合考虑B型超声(B-mode ultrasound, B-US)和对比增强超声(contrast-enhanced ultrasound, CEUS)双模态信息有助于提升乳腺肿瘤诊断的准确性,从而利于提高患者生存率。然而,目前大多数模型只关注B-US的特征提取,忽视了CEUS特征的学习和双模态信息的融合处理。为解决上述问题,提出了一个融合时空特征与时间约束的双模态乳腺肿瘤诊断模型(spatio-temporal feature and temporal-constrained model, STFTCM)。方法首先,基于双模态信息的数据特点,采用异构双分支网络学习B-US和CEUS包含的时空特征。然后,设计时间注意力损失函数引导CEUS分支关注造影剂流入病灶区的时间窗口,从该窗口期内提取CEUS特征。最后,借助特征融合模块实现双分支网络之间的横向连接,通过将B-US特征作为CEUS分支补充信息的方式,完成双模态特征融合。结果在收集到的数据集上进行对比实验,STFTCM预测的正确率、敏感性、宏平均F1和AUC(area under the curve)指标均表现优秀,其中预测正确率达88.2%,领先于其他先进模型。消融实验中,时间注意力约束将模型预测正确率提升5.8%,特征融合使得模型诊断正确率相较于单分支模型至少提升2.9%。结论本文提出的STFTCM能有效地提取并融合处理B-US和CEUS双模态信息,给出准确的诊断结果。同时,时间注意力约束和特征融合模块可以显著地提升模型性能。关键词:双模态乳腺肿瘤诊断;时空特征;时间注意力约束;对比增强超声(CEUS);B型超声(B-US)114|79|0更新时间:2025-04-11
医学图像处理
- “在遥感飞机细粒度识别领域,专家提出了融合边界框高斯建模与特征聚合分发的YOLOv5s算法,有效提高了小目标检测精度。实验结果显示,模型精确度分别达到了99.10%和95.36%,检测精度最佳。”
 摘要:目的遥感飞机影像由于目标尺寸差距大,采集过程中受光照、遮挡等因素的影响,导致不同型号飞机特征相似,小目标检测效果不好,类内无法实现细粒度区分。为了解决上述问题,提出了一种融合边界框高斯建模与特征聚合分发的YOLOv5s(you only look once)遥感飞机细粒度识别算法。方法首先,将归一化高斯瓦瑟斯坦距离(normalized Gaussian Wasserstein distance, NWD)与交并比(intersection over union,IoU)及其衍生指标相结合,并合理地设置两者的比例参数,改进YOLOv5s位置损失的计算方式,从而提高模型对小目标的敏感度。其次,在YOLOv5s的Neck部分引入特征聚合分发模块(gather-and-distribute, GD),在原网络“自顶向下、横向连接”的特征融合方式的基础上做到了跨层融合信息,增强网络细粒度特征、全局特征提取能力,提高了整体检测精度。为检验本算法在军用飞机上的细粒度和小目标识别优势,使用遥感飞机细粒度数据集MAR20(military aircraft recognition 20)和遥感飞机小目标数据集CORS-ADD(complex optical remote-sensing aircraft detection dataset)进行实验。结果实验结果显示:对于数据集MAR20和CORS-ADD,本文模型精确度分别达到了99.10%和95.36%,与原YOLOv5s、YOLOv8s、Gold-YOLO和Faster R-CNN相比,检测精度最佳。实验验证了模型在细粒度和小目标检测方面性能更加优秀,在检测结果上与真实结果更加接近,改进算法细粒度和小目标检测精度最佳。结论实验结果表明,本文算法在检测性能和模型精度上的表现优于上述4种目标检测算法,模型具有良好的实用价值。关键词:目标检测;改进YOLOv5s;遥感飞机影像;细粒度识别;特征融合111|103|0更新时间:2025-04-11
摘要:目的遥感飞机影像由于目标尺寸差距大,采集过程中受光照、遮挡等因素的影响,导致不同型号飞机特征相似,小目标检测效果不好,类内无法实现细粒度区分。为了解决上述问题,提出了一种融合边界框高斯建模与特征聚合分发的YOLOv5s(you only look once)遥感飞机细粒度识别算法。方法首先,将归一化高斯瓦瑟斯坦距离(normalized Gaussian Wasserstein distance, NWD)与交并比(intersection over union,IoU)及其衍生指标相结合,并合理地设置两者的比例参数,改进YOLOv5s位置损失的计算方式,从而提高模型对小目标的敏感度。其次,在YOLOv5s的Neck部分引入特征聚合分发模块(gather-and-distribute, GD),在原网络“自顶向下、横向连接”的特征融合方式的基础上做到了跨层融合信息,增强网络细粒度特征、全局特征提取能力,提高了整体检测精度。为检验本算法在军用飞机上的细粒度和小目标识别优势,使用遥感飞机细粒度数据集MAR20(military aircraft recognition 20)和遥感飞机小目标数据集CORS-ADD(complex optical remote-sensing aircraft detection dataset)进行实验。结果实验结果显示:对于数据集MAR20和CORS-ADD,本文模型精确度分别达到了99.10%和95.36%,与原YOLOv5s、YOLOv8s、Gold-YOLO和Faster R-CNN相比,检测精度最佳。实验验证了模型在细粒度和小目标检测方面性能更加优秀,在检测结果上与真实结果更加接近,改进算法细粒度和小目标检测精度最佳。结论实验结果表明,本文算法在检测性能和模型精度上的表现优于上述4种目标检测算法,模型具有良好的实用价值。关键词:目标检测;改进YOLOv5s;遥感飞机影像;细粒度识别;特征融合111|103|0更新时间:2025-04-11 -
多粒度上下文网络的SAR船舶检测 AI导读
“在SAR船舶检测领域,专家提出了多粒度上下文网络,有效提高了检测准确性。” 摘要:目的合成孔径雷达(synthetic aperture radar, SAR)是一种主动式微波传感器,能够获取高分辨率的遥感图像,在海上船舶检测中至关重要。然而,SAR船舶检测主要面临两个挑战:复杂背景和船舶目标尺寸的多样性。为此,提出了适用于SAR船舶检测的多粒度上下文网络。方法首先,设计了多粒度通道注意力(multi-granularity channel attention, MCA)模块,对全局和局部的不同粒度的上下文信息进行加权,以增强对船舶目标重要信息的关注,降低复杂背景对检测结果的干扰。然后,设计了多粒度空洞自适应空间特征融合(multi-granularity atrous adaptive spatial feature fusion, MAASFF) 模块,采用自适应空间特征融合的方法,将3种不同扩张率(1、2和3)的空洞卷积提取的特征图进行融合,以减少特征图生成中的上下文信息损失,增强特征金字塔的表示能力,从而提高不同尺寸船舶的检测效果。结果实验结果表明,本文方法在SAR-Ship-Dataset和SSDD(SAR ship detection dataset)两个数据集上与其他9种方法进行比较均取得最佳的检测结果,平均精度分别达到了96.1%和97.0%,进一步验证了该网络在SAR船舶检测任务中出色的性能表现。结论本文提出了一种多粒度上下文网络,旨在抑制复杂背景干扰并增强对多尺寸船舶特征的提取能力,有效提高了SAR船舶检测的准确性。关键词:SAR图像;船舶检测;多粒度;通道注意力;特征融合116|119|0更新时间:2025-04-11
摘要:目的合成孔径雷达(synthetic aperture radar, SAR)是一种主动式微波传感器,能够获取高分辨率的遥感图像,在海上船舶检测中至关重要。然而,SAR船舶检测主要面临两个挑战:复杂背景和船舶目标尺寸的多样性。为此,提出了适用于SAR船舶检测的多粒度上下文网络。方法首先,设计了多粒度通道注意力(multi-granularity channel attention, MCA)模块,对全局和局部的不同粒度的上下文信息进行加权,以增强对船舶目标重要信息的关注,降低复杂背景对检测结果的干扰。然后,设计了多粒度空洞自适应空间特征融合(multi-granularity atrous adaptive spatial feature fusion, MAASFF) 模块,采用自适应空间特征融合的方法,将3种不同扩张率(1、2和3)的空洞卷积提取的特征图进行融合,以减少特征图生成中的上下文信息损失,增强特征金字塔的表示能力,从而提高不同尺寸船舶的检测效果。结果实验结果表明,本文方法在SAR-Ship-Dataset和SSDD(SAR ship detection dataset)两个数据集上与其他9种方法进行比较均取得最佳的检测结果,平均精度分别达到了96.1%和97.0%,进一步验证了该网络在SAR船舶检测任务中出色的性能表现。结论本文提出了一种多粒度上下文网络,旨在抑制复杂背景干扰并增强对多尺寸船舶特征的提取能力,有效提高了SAR船舶检测的准确性。关键词:SAR图像;船舶检测;多粒度;通道注意力;特征融合116|119|0更新时间:2025-04-11
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0