
最新刊期
卷 30 , 期 2 , 2025
- “在三维视觉领域,点云补全算法取得重要进展,专家系统综述了深度学习背景下的点云补全技术,为3D重建等研究提供重要参考。”
 摘要:Point clouds have become the main form of 3D vision because of their rich information expression ability. However, the actual collected point cloud data are often sparse or incomplete due to the characteristics of the measured object, the performance of the measuring instrument, and environmental and human factors, which seriously affect the subsequent processing of the point cloud. The point cloud completion algorithm aims to reconstruct a complete point cloud model from incomplete point cloud data, which is an important research basis for 3D reconstruction, object detection, and shape classification. With the rapid development of deep learning methods, their efficient feature extraction ability and excellent data processing ability have led them to be widely used in 3D point cloud algorithms. At present, point cloud completion algorithms based on deep learning have gradually become a research hotspot in the field of 3D point clouds. However, challenges such as model structure, accuracy, and efficiency in completion tasks hinder the development of point cloud completion algorithms. Examples include the problems of missing key structural information, fine-grained reconstruction, and inefficiency of the algorithm model. This study systematically reviews point cloud completion algorithms in the context of deep learning. First, according to the network input modality, the point cloud completion algorithms are divided into two categories, namely, single-modality-based methods and multimodality-based methods. Then, according to the representation of 3D data, the methods based on a single modality are divided into three categories, namely, voxel-based methods, view-based methods, and point-based methods. The classical methods and the latest methods are systematically analyzed and summarized. The method characteristics and network performance of point cloud completion algorithms under various models were reviewed. Then, practical application analysis of the multimodal method is conducted, and the performance of the algorithm is compared with that of the diffusion model and other methods. Then, different datasets and evaluation criteria commonly used in point cloud completion tasks are summarized, the performance of existing point cloud completion algorithms based on deep learning on real datasets and synthetic datasets with a variety of evaluation criteria is compared, and the performance of existing point cloud completion algorithms is analyzed. Finally, according to the advantages and disadvantages of each classification, the future development and research trends of point cloud completion algorithms in the field of deep learning are proposed. The research results are as follows: since the concept of the point cloud completion algorithm was proposed in 2018, most methods based on a single mode use the point method for completion and combine hotspot models for algorithm optimization, such as generative adversarial networks (GANs), Transformer models, and the Mamba model. Multimodal methods have developed rapidly since they were proposed in 2021, especially since the diffusion model was applied to the point cloud completion algorithm, which truly realizes multimodal input and output. Many researchers have explored multimodal information fusion at the feature level to improve the model accuracy of the completion algorithm. This scheme also provides an updated algorithm theoretical basis for multivehicle cooperative intelligent perception technology in robotics and autonomous driving. Point cloud completion based on multimodal methods is also the development trend of point cloud completion algorithms in the future. Through a comprehensive survey and review of point cloud completion algorithms based on deep learning, the current research results have improved the ability of point cloud data feature extraction and model generation to a certain extent. However, the following research difficulties still exist: 1) features and fine-grained methods: at present, most algorithms are dedicated to making full use of structural information for prediction and generating fine-grained and more complete point cloud shapes. Multiple fusion operations of the geometric structure and attribute information based on the point cloud data structure must still be performed to enrich the high-quality generation of point cloud data. 2) Multimodal data fusion: point cloud data are usually fused with other sensor data to obtain more comprehensive information, such as RGB images and depth images. How to improve the method of multimodal feature extraction and fusion and explore the smart fusion of multimodal data to improve the accuracy and robustness of the point cloud completion algorithm will be the difficulties of future research. In the future, the development of point cloud completion algorithms will realize that all modes from text and image to point cloud will be completely opened, and any input and output will be realized in the real sense. 3) Data augmentation and diversity: large models of point clouds will be popular research topics in the future. Improving the generalization ability and data diversity of point cloud completion algorithms in various scenarios via data augmentation or model diffusion has also become difficult in the field of point clouds. 4) Real-time and interactivity: real-time requirements limit the development of point cloud completion algorithms in applications such as autonomous driving and robotics. The high complexity of the algorithm, the difficulty of multimodal feature information fusion, and the difficulty of large-scale data processing make the algorithm model inefficient, resulting in poor real-time performance. How to reduce the size of the data through data preprocessing, downsampling, and selecting a relatively lightweight model structure, such as the Mamba model, to improve model efficiency was investigated. Moreover, the rapid adjustment and optimization of high-quality point cloud completion results according to user interaction information will be difficult for future development. A systematic review of point cloud completion algorithms against the background of deep learning provides important reference value for researchers of completion algorithms in the field of 3D vision.关键词:point cloud completion;voxel-based method;multimodal-based method;Transformer model;diffusion model483|485|0更新时间:2025-04-11
摘要:Point clouds have become the main form of 3D vision because of their rich information expression ability. However, the actual collected point cloud data are often sparse or incomplete due to the characteristics of the measured object, the performance of the measuring instrument, and environmental and human factors, which seriously affect the subsequent processing of the point cloud. The point cloud completion algorithm aims to reconstruct a complete point cloud model from incomplete point cloud data, which is an important research basis for 3D reconstruction, object detection, and shape classification. With the rapid development of deep learning methods, their efficient feature extraction ability and excellent data processing ability have led them to be widely used in 3D point cloud algorithms. At present, point cloud completion algorithms based on deep learning have gradually become a research hotspot in the field of 3D point clouds. However, challenges such as model structure, accuracy, and efficiency in completion tasks hinder the development of point cloud completion algorithms. Examples include the problems of missing key structural information, fine-grained reconstruction, and inefficiency of the algorithm model. This study systematically reviews point cloud completion algorithms in the context of deep learning. First, according to the network input modality, the point cloud completion algorithms are divided into two categories, namely, single-modality-based methods and multimodality-based methods. Then, according to the representation of 3D data, the methods based on a single modality are divided into three categories, namely, voxel-based methods, view-based methods, and point-based methods. The classical methods and the latest methods are systematically analyzed and summarized. The method characteristics and network performance of point cloud completion algorithms under various models were reviewed. Then, practical application analysis of the multimodal method is conducted, and the performance of the algorithm is compared with that of the diffusion model and other methods. Then, different datasets and evaluation criteria commonly used in point cloud completion tasks are summarized, the performance of existing point cloud completion algorithms based on deep learning on real datasets and synthetic datasets with a variety of evaluation criteria is compared, and the performance of existing point cloud completion algorithms is analyzed. Finally, according to the advantages and disadvantages of each classification, the future development and research trends of point cloud completion algorithms in the field of deep learning are proposed. The research results are as follows: since the concept of the point cloud completion algorithm was proposed in 2018, most methods based on a single mode use the point method for completion and combine hotspot models for algorithm optimization, such as generative adversarial networks (GANs), Transformer models, and the Mamba model. Multimodal methods have developed rapidly since they were proposed in 2021, especially since the diffusion model was applied to the point cloud completion algorithm, which truly realizes multimodal input and output. Many researchers have explored multimodal information fusion at the feature level to improve the model accuracy of the completion algorithm. This scheme also provides an updated algorithm theoretical basis for multivehicle cooperative intelligent perception technology in robotics and autonomous driving. Point cloud completion based on multimodal methods is also the development trend of point cloud completion algorithms in the future. Through a comprehensive survey and review of point cloud completion algorithms based on deep learning, the current research results have improved the ability of point cloud data feature extraction and model generation to a certain extent. However, the following research difficulties still exist: 1) features and fine-grained methods: at present, most algorithms are dedicated to making full use of structural information for prediction and generating fine-grained and more complete point cloud shapes. Multiple fusion operations of the geometric structure and attribute information based on the point cloud data structure must still be performed to enrich the high-quality generation of point cloud data. 2) Multimodal data fusion: point cloud data are usually fused with other sensor data to obtain more comprehensive information, such as RGB images and depth images. How to improve the method of multimodal feature extraction and fusion and explore the smart fusion of multimodal data to improve the accuracy and robustness of the point cloud completion algorithm will be the difficulties of future research. In the future, the development of point cloud completion algorithms will realize that all modes from text and image to point cloud will be completely opened, and any input and output will be realized in the real sense. 3) Data augmentation and diversity: large models of point clouds will be popular research topics in the future. Improving the generalization ability and data diversity of point cloud completion algorithms in various scenarios via data augmentation or model diffusion has also become difficult in the field of point clouds. 4) Real-time and interactivity: real-time requirements limit the development of point cloud completion algorithms in applications such as autonomous driving and robotics. The high complexity of the algorithm, the difficulty of multimodal feature information fusion, and the difficulty of large-scale data processing make the algorithm model inefficient, resulting in poor real-time performance. How to reduce the size of the data through data preprocessing, downsampling, and selecting a relatively lightweight model structure, such as the Mamba model, to improve model efficiency was investigated. Moreover, the rapid adjustment and optimization of high-quality point cloud completion results according to user interaction information will be difficult for future development. A systematic review of point cloud completion algorithms against the background of deep learning provides important reference value for researchers of completion algorithms in the field of 3D vision.关键词:point cloud completion;voxel-based method;multimodal-based method;Transformer model;diffusion model483|485|0更新时间:2025-04-11 - “风格化数字人技术在计算机图形学等领域迅速发展,专家系统性综述了其风格化生成、多模态驱动与用户交互的研究进展,为后续研究提供参考。”
 摘要:Stylized digital characters have emerged as a fundamental force in reshaping the landscape of computer graphics, visual arts, and game design. Their unparalleled ability to mimic human appearance and behavior, coupled with their flexibility in adapting to a wide array of artistic styles and narrative frameworks, underscores their growing importance in crafting immersive and engaging digital experiences. This comprehensive exploration delves deeply into the complex world of stylized digital humans, explores their current development status, identifies the latest trends, and addresses the pressing challenges that lie ahead in three foundational research domains: the creation of stylized digital humans, multimodal driving mechanisms, and user interaction modalities. The first domain, creation of stylized digital humans, examines the innovative methodologies employed in generating lifelike but stylistically diverse characters that can seamlessly integrate into various digital environments. From advancements in 3D modeling and texturing to the integration of artificial intelligence for dynamic character development, this section provides a thorough analysis of the tools and technologies that are pushing the boundaries of what digital characters can achieve. In the realm of multimodal driving mechanisms, this study investigates evolving techniques for animating and controlling digital humans by using a range of inputs, such as voice, gesture, and real-time motion capture. This section delves into how these mechanisms not only enhance the realism of character interactions but also open new avenues for creators to involve users in interactive narratives in more meaningful ways. Finally, the discussion of user interaction modalities explores the various ways in which end-users can engage with and influence the behavior of digital humans. From immersive virtual and augmented reality experiences to interactive web and mobile platforms, this segment evaluates the effectiveness of different modalities in creating a two-way interaction that enriches the user’s experience and deepens their connection to digital characters. At the heart of this exploration lies the creation of stylized digital humans, a field that has witnessed remarkable progress in recent years. The generation of these characters can be broadly classified into two categories: explicit 3D models and implicit 3D models. Explicit 3D digital human stylization encompasses a range of methodologies, including optimization-based approaches that meticulously refine digital meshes to conform to specific stylistic attributes. These techniques often involve iterative processes that adjust geometric details, textures, and lighting to achieve the desired aesthetic. Generative adversarial networks, as cornerstones of deep learning, have revolutionized this landscape by enabling the automatic generation of novel stylized forms that capture intricate nuances of various artistic styles. Furthermore, engine-based methods harness the power of advanced rendering engines to apply artistic filters and affect real time, offering unparalleled flexibility and control over the final visual output. Implicit 3D digital human stylization draws inspiration from the realm of implicit scene stylization, particularly via neural implicit representations. These approaches offer a more holistic and flexible approach for representing and manipulating 3D geometry and appearance, enabling stylization that transcends traditional mesh-based limitations. Within this framework, facial stylization holds a special place, requiring a profound understanding of facial anatomy, expression dynamics, and cultural nuances. Specialized methods have been developed to capture and manipulate facial features in a nuanced and artistic manner, fostering a level of realism and emotional expressiveness that is crucial for believable digital humans. Animating and controlling the behavior of stylized digital humans necessitates the use of diverse driving signals, which serve as the lifeblood of these virtual beings. This study delves into three primary sources of these signals: explicit audio drivers, text drivers, and video drivers. Audio drivers leverage speech recognition and prosody analysis to synchronize digital human movements with spoken language, enabling them to lip-sync and gesture in a natural and expressive manner. Conversely, text drivers rely on natural language processing (NLP) techniques to interpret textual commands or prompts and convert them into coherent actions, allowing for a more directive form of control. Video drivers, which are perhaps the most advanced in terms of realism, employ computer vision algorithms to track and mimic the movements of real-world actors, providing a seamless bridge between the virtual and physical worlds. These drivers are supported by sophisticated implementation algorithms, many of which rely on intermediate variable-driven coding-decoding structures. Keypoint-based methods play a pivotal role in capturing and transferring motion, allowing for the precise replication of movements across different characters. Moreover, 3D face-based approaches focus on facial animation and utilize detailed facial models and advanced animation techniques to achieve unparalleled realism in expressions and emotions. Meanwhile, optical flow-based techniques offer a holistic approach to motion estimation, synthesis, capture, and reproduction of complex motion patterns across the entire digital human body. The true magic of stylized digital humans lies in their ability to engage with users in meaningful and natural interactions. Voice interaction, currently the mainstream mode of communication, relies heavily on automatic speech recognition for accurate speech-to-text conversion and text-to-speech synthesis for generating natural-sounding synthetic speech. The dialog system module, a cornerstone of virtual human interaction, emphasizes the importance of natural language understanding for interpreting user inputs and natural language generation for crafting appropriate responses. When these capabilities are seamlessly integrated, stylized digital humans are capable of engaging in fluid and contextually relevant conversations with users, fostering a sense of intimacy and connection. The study of stylized digital characters will likely continue its ascendancy, fueled by advancements in deep learning, computer vision, and NLP. Future research may delve into integrating multiple modalities for richer and more nuanced interactions, pushing the boundaries of what is possible in virtual human communication. Innovative stylization techniques that bridge the gap between reality and fiction will also be explored, enabling the creation of digital humans that are both fantastic and relatable. Moreover, the development of intelligent agents capable of autonomous creativity and learning will revolutionize the way stylized digital humans can contribute to various industries, including entertainment, education, healthcare, and beyond. As technology continues to evolve, stylized digital humans will undoubtedly play an increasingly substantial role in shaping how people engage with digital content and with each other, ushering in a new era of digital creativity and expression. This study serves as a valuable resource for researchers and practitioners alike, offering a comprehensive overview of the current state of the art and guiding the way forward in this dynamic, exciting field.关键词:stylization;digital characters;face driven;human-computer interaction;3D modeling;deep learning;neural network297|339|0更新时间:2025-04-11
摘要:Stylized digital characters have emerged as a fundamental force in reshaping the landscape of computer graphics, visual arts, and game design. Their unparalleled ability to mimic human appearance and behavior, coupled with their flexibility in adapting to a wide array of artistic styles and narrative frameworks, underscores their growing importance in crafting immersive and engaging digital experiences. This comprehensive exploration delves deeply into the complex world of stylized digital humans, explores their current development status, identifies the latest trends, and addresses the pressing challenges that lie ahead in three foundational research domains: the creation of stylized digital humans, multimodal driving mechanisms, and user interaction modalities. The first domain, creation of stylized digital humans, examines the innovative methodologies employed in generating lifelike but stylistically diverse characters that can seamlessly integrate into various digital environments. From advancements in 3D modeling and texturing to the integration of artificial intelligence for dynamic character development, this section provides a thorough analysis of the tools and technologies that are pushing the boundaries of what digital characters can achieve. In the realm of multimodal driving mechanisms, this study investigates evolving techniques for animating and controlling digital humans by using a range of inputs, such as voice, gesture, and real-time motion capture. This section delves into how these mechanisms not only enhance the realism of character interactions but also open new avenues for creators to involve users in interactive narratives in more meaningful ways. Finally, the discussion of user interaction modalities explores the various ways in which end-users can engage with and influence the behavior of digital humans. From immersive virtual and augmented reality experiences to interactive web and mobile platforms, this segment evaluates the effectiveness of different modalities in creating a two-way interaction that enriches the user’s experience and deepens their connection to digital characters. At the heart of this exploration lies the creation of stylized digital humans, a field that has witnessed remarkable progress in recent years. The generation of these characters can be broadly classified into two categories: explicit 3D models and implicit 3D models. Explicit 3D digital human stylization encompasses a range of methodologies, including optimization-based approaches that meticulously refine digital meshes to conform to specific stylistic attributes. These techniques often involve iterative processes that adjust geometric details, textures, and lighting to achieve the desired aesthetic. Generative adversarial networks, as cornerstones of deep learning, have revolutionized this landscape by enabling the automatic generation of novel stylized forms that capture intricate nuances of various artistic styles. Furthermore, engine-based methods harness the power of advanced rendering engines to apply artistic filters and affect real time, offering unparalleled flexibility and control over the final visual output. Implicit 3D digital human stylization draws inspiration from the realm of implicit scene stylization, particularly via neural implicit representations. These approaches offer a more holistic and flexible approach for representing and manipulating 3D geometry and appearance, enabling stylization that transcends traditional mesh-based limitations. Within this framework, facial stylization holds a special place, requiring a profound understanding of facial anatomy, expression dynamics, and cultural nuances. Specialized methods have been developed to capture and manipulate facial features in a nuanced and artistic manner, fostering a level of realism and emotional expressiveness that is crucial for believable digital humans. Animating and controlling the behavior of stylized digital humans necessitates the use of diverse driving signals, which serve as the lifeblood of these virtual beings. This study delves into three primary sources of these signals: explicit audio drivers, text drivers, and video drivers. Audio drivers leverage speech recognition and prosody analysis to synchronize digital human movements with spoken language, enabling them to lip-sync and gesture in a natural and expressive manner. Conversely, text drivers rely on natural language processing (NLP) techniques to interpret textual commands or prompts and convert them into coherent actions, allowing for a more directive form of control. Video drivers, which are perhaps the most advanced in terms of realism, employ computer vision algorithms to track and mimic the movements of real-world actors, providing a seamless bridge between the virtual and physical worlds. These drivers are supported by sophisticated implementation algorithms, many of which rely on intermediate variable-driven coding-decoding structures. Keypoint-based methods play a pivotal role in capturing and transferring motion, allowing for the precise replication of movements across different characters. Moreover, 3D face-based approaches focus on facial animation and utilize detailed facial models and advanced animation techniques to achieve unparalleled realism in expressions and emotions. Meanwhile, optical flow-based techniques offer a holistic approach to motion estimation, synthesis, capture, and reproduction of complex motion patterns across the entire digital human body. The true magic of stylized digital humans lies in their ability to engage with users in meaningful and natural interactions. Voice interaction, currently the mainstream mode of communication, relies heavily on automatic speech recognition for accurate speech-to-text conversion and text-to-speech synthesis for generating natural-sounding synthetic speech. The dialog system module, a cornerstone of virtual human interaction, emphasizes the importance of natural language understanding for interpreting user inputs and natural language generation for crafting appropriate responses. When these capabilities are seamlessly integrated, stylized digital humans are capable of engaging in fluid and contextually relevant conversations with users, fostering a sense of intimacy and connection. The study of stylized digital characters will likely continue its ascendancy, fueled by advancements in deep learning, computer vision, and NLP. Future research may delve into integrating multiple modalities for richer and more nuanced interactions, pushing the boundaries of what is possible in virtual human communication. Innovative stylization techniques that bridge the gap between reality and fiction will also be explored, enabling the creation of digital humans that are both fantastic and relatable. Moreover, the development of intelligent agents capable of autonomous creativity and learning will revolutionize the way stylized digital humans can contribute to various industries, including entertainment, education, healthcare, and beyond. As technology continues to evolve, stylized digital humans will undoubtedly play an increasingly substantial role in shaping how people engage with digital content and with each other, ushering in a new era of digital creativity and expression. This study serves as a valuable resource for researchers and practitioners alike, offering a comprehensive overview of the current state of the art and guiding the way forward in this dynamic, exciting field.关键词:stylization;digital characters;face driven;human-computer interaction;3D modeling;deep learning;neural network297|339|0更新时间:2025-04-11
Review

- “在高空无人机多模态目标跟踪领域,专家构建了HiAl数据集,旨在推动相关技术研究。”
 摘要:ObjectiveUnmanned aerial vehicles (UAVs) have become crucial tools in both modern military and civilian contexts owing to their flexibility and ease of operation. High-altitude UAVs provide unique and distinct advantages over low-altitude UAVs, such as wider fields of view and stronger concealment, making them highly valuable in intelligence reconnaissance, emergency rescue, and disaster relief tasks. However, tracking objects with high-altitude UAVs introduces considerable challenges, including UAV rotation, tiny objects, complex background changes, and low object resolution. The current research on multi-modal object tracking of UAVs focuses primarily on low-altitude UAVs, such as the dataset named VTUAV (visible-thermal UAV) for multi-modal object tracking of UAVs, which is shot in low-altitude airspace of 5–20 m and can fully show the unique perspective of UAVs. However, the scenes captured by high-altitude UAVs significantly differ from those captured by low-altitude UAVs. Thus, this dataset cannot provide strong support for the development of high-altitude UAV multi-modal object tracking, which is also the bottleneck of the lack of data support in the research field of multi-modal object tracking of high-altitude UAVs. Given the lack of an evaluation dataset to evaluate the multi-modal object tracking method of high-altitude UAVs, this limitation hinders research and development in this field.MethodThis study proposes an evaluation dataset named HiAl specifically for multi-modal object tracking methods of high-altitude UAVs captured at approximately 500 m. The UAV shooting this dataset is equipped with a hybrid sensor, which can capture video in both visible and infrared modes. The collected multimodal videos with high-quality videos were registered to provide a higher level of ground truth annotation and evaluate different multi-modal object tracking methods more fairly. First, the two video modalities were manually aligned to ensure that the same tracking object in each pair of videos occupied the same position within the frame. During the registration process, ensuring accurate registration of the area where the tracking object is located is the top priority, and under this premise, other areas in the image also become roughly aligned. Then, accurate ground truth annotations are provided to each frame of the video on the basis of the high alignment of the two modalities. The horizontal annotation boxes were used to label the position of the target in a way that best fits the contour of the tracked object. In the abovementioned modal alignment, two video modalities can share the same ground truth, which allows better evaluation of different multi-modal object tracking methods under the high-altitude UAV platform. Tracking attributes, scenes, and object categories was comprehensively considered during the data collection process to ensure the diversity and authenticity of the dataset. The dataset considers different lighting conditions and weather factors, including night and foggy days, for nine common object categories in high-altitude UAV scenes. The dataset has 12 tracking attributes; two are unique to UAVs, which have rich practical significance and high challenges. In contrast to existing multimodal tracking datasets, this dataset tracks mostly small targets, which is also a realistic challenge associated with high-altitude UAV shooting.ResultThe performances of 10 mainstream multi-modal tracking methods on this dataset are compared with those on a nonhigh-altitude UAV scene dataset. This study employs common quantitative evaluation metrics, namely, the precision rate (PR) and success rate (SR), to assess the performance of each method. Taking the two outstanding methods as examples, the PR value of the template-bridged search region interaction (TBSI) method on the RGB-thermal dataset (RGBT234) reached 0.871, whereas it was only 0.527 on the dataset proposed in this study, which decreased by 39.5%; its SR value decreased from 0.637 on RGBT234 to 0.468 on the dataset proposed in this study, which decreased by 26.5%. Compared with those of RGBT234, the PR and SR of the hierarchical multi-modal fusion tracker (HMFT) on the HiAl dataset decreased by 23.6% and 14%, respectively. In addition, the dataset HiAlto was used to retrain six methods. Comparative results indicated improved performance of all the retraining methods. For example, the PR value of the duality-gated mutual condition network (DMCNet) is increased from 0.485 before training to 0.524, and the SR value increased from 0.512 before training to 0.526. These experimental results reflect the high challenge and necessity of the dataset.ConclusionAn evaluation dataset designed to assess the performance of multi-modal object tracking methods for high-altitude UAVs is introduced in this study. The multimodal data collected in the real scene and provided frame-level ground truth annotations were carefully registered to provide a dedicated dataset for high-quality multi-modal tracking of high-altitude UAVs. This proposed dataset HiAl can serve as a’standard evaluation tool for future research, offering researchers access to authentic and varied data to evaluate their algorithms performance. The experimental results of 10 mainstream tracking algorithms in HiAl with other datasets were compared, and the experimental results of retraining 6 tracking algorithms, including the limitations of existing algorithms in the multi-modal object tracking task of high-altitude UAVs, were analyzed. The potential research directions were extracted for researchers’ reference. The HiAl dataset is available at https://github.com/mmic-lcl/Datasets-and-benchmark-code/tree/main.关键词:multi-modal object tracking;high altitude unmanned aerial vehicle;small object;high quality alignment;dataset660|316|0更新时间:2025-04-11
摘要:ObjectiveUnmanned aerial vehicles (UAVs) have become crucial tools in both modern military and civilian contexts owing to their flexibility and ease of operation. High-altitude UAVs provide unique and distinct advantages over low-altitude UAVs, such as wider fields of view and stronger concealment, making them highly valuable in intelligence reconnaissance, emergency rescue, and disaster relief tasks. However, tracking objects with high-altitude UAVs introduces considerable challenges, including UAV rotation, tiny objects, complex background changes, and low object resolution. The current research on multi-modal object tracking of UAVs focuses primarily on low-altitude UAVs, such as the dataset named VTUAV (visible-thermal UAV) for multi-modal object tracking of UAVs, which is shot in low-altitude airspace of 5–20 m and can fully show the unique perspective of UAVs. However, the scenes captured by high-altitude UAVs significantly differ from those captured by low-altitude UAVs. Thus, this dataset cannot provide strong support for the development of high-altitude UAV multi-modal object tracking, which is also the bottleneck of the lack of data support in the research field of multi-modal object tracking of high-altitude UAVs. Given the lack of an evaluation dataset to evaluate the multi-modal object tracking method of high-altitude UAVs, this limitation hinders research and development in this field.MethodThis study proposes an evaluation dataset named HiAl specifically for multi-modal object tracking methods of high-altitude UAVs captured at approximately 500 m. The UAV shooting this dataset is equipped with a hybrid sensor, which can capture video in both visible and infrared modes. The collected multimodal videos with high-quality videos were registered to provide a higher level of ground truth annotation and evaluate different multi-modal object tracking methods more fairly. First, the two video modalities were manually aligned to ensure that the same tracking object in each pair of videos occupied the same position within the frame. During the registration process, ensuring accurate registration of the area where the tracking object is located is the top priority, and under this premise, other areas in the image also become roughly aligned. Then, accurate ground truth annotations are provided to each frame of the video on the basis of the high alignment of the two modalities. The horizontal annotation boxes were used to label the position of the target in a way that best fits the contour of the tracked object. In the abovementioned modal alignment, two video modalities can share the same ground truth, which allows better evaluation of different multi-modal object tracking methods under the high-altitude UAV platform. Tracking attributes, scenes, and object categories was comprehensively considered during the data collection process to ensure the diversity and authenticity of the dataset. The dataset considers different lighting conditions and weather factors, including night and foggy days, for nine common object categories in high-altitude UAV scenes. The dataset has 12 tracking attributes; two are unique to UAVs, which have rich practical significance and high challenges. In contrast to existing multimodal tracking datasets, this dataset tracks mostly small targets, which is also a realistic challenge associated with high-altitude UAV shooting.ResultThe performances of 10 mainstream multi-modal tracking methods on this dataset are compared with those on a nonhigh-altitude UAV scene dataset. This study employs common quantitative evaluation metrics, namely, the precision rate (PR) and success rate (SR), to assess the performance of each method. Taking the two outstanding methods as examples, the PR value of the template-bridged search region interaction (TBSI) method on the RGB-thermal dataset (RGBT234) reached 0.871, whereas it was only 0.527 on the dataset proposed in this study, which decreased by 39.5%; its SR value decreased from 0.637 on RGBT234 to 0.468 on the dataset proposed in this study, which decreased by 26.5%. Compared with those of RGBT234, the PR and SR of the hierarchical multi-modal fusion tracker (HMFT) on the HiAl dataset decreased by 23.6% and 14%, respectively. In addition, the dataset HiAlto was used to retrain six methods. Comparative results indicated improved performance of all the retraining methods. For example, the PR value of the duality-gated mutual condition network (DMCNet) is increased from 0.485 before training to 0.524, and the SR value increased from 0.512 before training to 0.526. These experimental results reflect the high challenge and necessity of the dataset.ConclusionAn evaluation dataset designed to assess the performance of multi-modal object tracking methods for high-altitude UAVs is introduced in this study. The multimodal data collected in the real scene and provided frame-level ground truth annotations were carefully registered to provide a dedicated dataset for high-quality multi-modal tracking of high-altitude UAVs. This proposed dataset HiAl can serve as a’standard evaluation tool for future research, offering researchers access to authentic and varied data to evaluate their algorithms performance. The experimental results of 10 mainstream tracking algorithms in HiAl with other datasets were compared, and the experimental results of retraining 6 tracking algorithms, including the limitations of existing algorithms in the multi-modal object tracking task of high-altitude UAVs, were analyzed. The potential research directions were extracted for researchers’ reference. The HiAl dataset is available at https://github.com/mmic-lcl/Datasets-and-benchmark-code/tree/main.关键词:multi-modal object tracking;high altitude unmanned aerial vehicle;small object;high quality alignment;dataset660|316|0更新时间:2025-04-11 - “在人物图像生成领域,专家构建了大规模高清人物图像数据集PersonHD,为高分辨率姿态引导图像生成提供新平台。”
 摘要:ObjectivePose-guided person image generation has attracted considerable attention because of its wide application potential. In the early stages of development, researchers relied mainly on manually designing features and models, matching key points between different characters, and then achieving pose transfer via interpolation or transformation. With the rapid development of deep learning technology, the emergence of generative adversarial networks (GANs) has led to considerable progress in posture transfer. GANs can learn and generate realistic images, and variants of related generative adversarial networks have been widely used in pose transfer tasks. Moreover, deep learning has made progress in key point detection technology. Advanced key point detection models, such as OpenPose, can more accurately capture human pose information, providing tremendous assistance for the development of algorithms in related fields and the construction of datasets. Recent works have achieved great success in pose-guided person image generation tasks with low-definition scenes. However, in high-resolution scenes, existing human pose transfer datasets suffer from low resolution or poor diversity, and relevant high-resolution image generation methods are lacking. This issue is addressed by constructing a large-scale high-definition human image dataset named PersonHD with multimodal auxiliary data.MethodThis study constructs a large-scale, high-resolution human image dataset called PersonHD. Compared with other datasets, this dataset has several advantages. 1) Higher image resolution: the cropped human images in PersonHD have a resolution of 1 520 × 880 pixels. 2) More diverse pose variations: the actions of the subjects are closer to real-life scenarios, introducing more fine-grained nonrigid deformation of the human body. 3) Larger image size. The PersonHD dataset contains 299 817 images from 100 different people in 4 000 videos. On the basis of the proposed PersonHD, this study further constructs two benchmarks and designs a practical high-resolution human image generation framework. Given that most existing works address human images with a resolution of 256 × 256 pixels, this study first establishes a low-resolution (256 × 256 pixels) benchmark for general evaluation, evaluates the performance of these methods on the PersonHD dataset, and further improves the performance of the state-of-the-art methods. This study also constructs a high-definition benchmark (512 × 512 pixels) to verify the performance of the state-of-the-art methods on the PersonHD dataset. These two benchmarks also enable this study to rigorously evaluate the performance of existing and future human pose transfer methods. In addition, this study proposes a practical framework to generate higher-resolution and higher-quality human images. In particular, this study first designs semantically enhanced partwise augmentation to solve the challenging overfitting problem in human image generation. A conditional upsampling module is then introduced for the generation and further refinement of high-resolution images.ResultCompared with existing datasets, PersonHD has significant advantages in terms of higher image resolution, more diverse pose variance, and larger sample sizes. On the PersonHD dataset, experiments systematically evaluate the current representative pose-guided character image generation methods on two different resolution evaluation benchmarks and systematically validate the effectiveness of each module of the framework proposed in this study. The experiment used five indicators to quantitatively analyze the performance of the model, including the structure similarity index measure(SSIM), Frechet inception distance(FID), learned perceptual image patch similarity(LPIPS), mask LPIPS, and percentage of correct keypoints with head-normalization(PCKh). For low-resolution benchmarks, most current methods are designed for low-resolution images of size 256 × 256 pixels. The image size was adjusted to 256 × 256 pixels during the experiment to evaluate these methods on the PersonHD dataset. Moreover, PersonHD was split into two subsets, namely, a clean subset and a complex subset, to evaluate the processing ability of different models for different backgrounds. This method compares several of the latest methods on two subsets of PersonHD, including pose-attentional transfer network(PATN), Must-GAN, Xing-GAN, pose-guided image synthesis and editing(PISE), and semantic part-based generation network(SPGNet). During the experiment, semantically enhanced partwise augmentation and one-shot-driven personalization were used to improve the performance of SPGNet as the baseline. The semantically enhanced partwise augmentation and one-shot driven personalization proposed in this research improve the performance of SPGNet in terms of multiple indicators, and the relevant modules of the framework significantly improve the model’s performance. For high-resolution benchmarks, given the limited work on pose-guided character image generation at high resolution, this study uses a conditional upsampling module to design the most advanced SPGNet model and further improves performance by using semantically enhanced partwise augmentation methods and one-shot-driven personalization. The experimental results indicate that the framework has good performance.ConclusionA large-scale high-resolution person image dataset called PersonHD, which contains 299 817 high-quality images, was developed. Compared with existing datasets, PersonHD has significant superiority in terms of higher image resolution, more diverse pose-variance, and larger scale samples. The high-definition character image generation benchmark dataset proposed in this article has the characteristics of a large scale and strong diversity of high-resolution data, which helps to comprehensively evaluate pose-guided character image generation algorithms. Comprehensive benchmarks were established, and extensive experimental evaluations were implemented on the basis of general low-definition protocols and the first proposed high-definition protocols, which could contribute to an important platform for analyzing recent state-of-the-art person image generation methods. A unified framework for high-definition person image generation, including semantically enhanced partwise augmentation and a conditional upsampling module, was also used. Both modules are flexible and can work separately in a plug-and-play manner. The dataset and code proposed in this work are available at https://github.com/BraveGroup/PersonHD.关键词:human image synthesis;pose-guided transfer;high-definition dataset;low-definition benchmark;high definition benchmark96|127|0更新时间:2025-04-11
摘要:ObjectivePose-guided person image generation has attracted considerable attention because of its wide application potential. In the early stages of development, researchers relied mainly on manually designing features and models, matching key points between different characters, and then achieving pose transfer via interpolation or transformation. With the rapid development of deep learning technology, the emergence of generative adversarial networks (GANs) has led to considerable progress in posture transfer. GANs can learn and generate realistic images, and variants of related generative adversarial networks have been widely used in pose transfer tasks. Moreover, deep learning has made progress in key point detection technology. Advanced key point detection models, such as OpenPose, can more accurately capture human pose information, providing tremendous assistance for the development of algorithms in related fields and the construction of datasets. Recent works have achieved great success in pose-guided person image generation tasks with low-definition scenes. However, in high-resolution scenes, existing human pose transfer datasets suffer from low resolution or poor diversity, and relevant high-resolution image generation methods are lacking. This issue is addressed by constructing a large-scale high-definition human image dataset named PersonHD with multimodal auxiliary data.MethodThis study constructs a large-scale, high-resolution human image dataset called PersonHD. Compared with other datasets, this dataset has several advantages. 1) Higher image resolution: the cropped human images in PersonHD have a resolution of 1 520 × 880 pixels. 2) More diverse pose variations: the actions of the subjects are closer to real-life scenarios, introducing more fine-grained nonrigid deformation of the human body. 3) Larger image size. The PersonHD dataset contains 299 817 images from 100 different people in 4 000 videos. On the basis of the proposed PersonHD, this study further constructs two benchmarks and designs a practical high-resolution human image generation framework. Given that most existing works address human images with a resolution of 256 × 256 pixels, this study first establishes a low-resolution (256 × 256 pixels) benchmark for general evaluation, evaluates the performance of these methods on the PersonHD dataset, and further improves the performance of the state-of-the-art methods. This study also constructs a high-definition benchmark (512 × 512 pixels) to verify the performance of the state-of-the-art methods on the PersonHD dataset. These two benchmarks also enable this study to rigorously evaluate the performance of existing and future human pose transfer methods. In addition, this study proposes a practical framework to generate higher-resolution and higher-quality human images. In particular, this study first designs semantically enhanced partwise augmentation to solve the challenging overfitting problem in human image generation. A conditional upsampling module is then introduced for the generation and further refinement of high-resolution images.ResultCompared with existing datasets, PersonHD has significant advantages in terms of higher image resolution, more diverse pose variance, and larger sample sizes. On the PersonHD dataset, experiments systematically evaluate the current representative pose-guided character image generation methods on two different resolution evaluation benchmarks and systematically validate the effectiveness of each module of the framework proposed in this study. The experiment used five indicators to quantitatively analyze the performance of the model, including the structure similarity index measure(SSIM), Frechet inception distance(FID), learned perceptual image patch similarity(LPIPS), mask LPIPS, and percentage of correct keypoints with head-normalization(PCKh). For low-resolution benchmarks, most current methods are designed for low-resolution images of size 256 × 256 pixels. The image size was adjusted to 256 × 256 pixels during the experiment to evaluate these methods on the PersonHD dataset. Moreover, PersonHD was split into two subsets, namely, a clean subset and a complex subset, to evaluate the processing ability of different models for different backgrounds. This method compares several of the latest methods on two subsets of PersonHD, including pose-attentional transfer network(PATN), Must-GAN, Xing-GAN, pose-guided image synthesis and editing(PISE), and semantic part-based generation network(SPGNet). During the experiment, semantically enhanced partwise augmentation and one-shot-driven personalization were used to improve the performance of SPGNet as the baseline. The semantically enhanced partwise augmentation and one-shot driven personalization proposed in this research improve the performance of SPGNet in terms of multiple indicators, and the relevant modules of the framework significantly improve the model’s performance. For high-resolution benchmarks, given the limited work on pose-guided character image generation at high resolution, this study uses a conditional upsampling module to design the most advanced SPGNet model and further improves performance by using semantically enhanced partwise augmentation methods and one-shot-driven personalization. The experimental results indicate that the framework has good performance.ConclusionA large-scale high-resolution person image dataset called PersonHD, which contains 299 817 high-quality images, was developed. Compared with existing datasets, PersonHD has significant superiority in terms of higher image resolution, more diverse pose-variance, and larger scale samples. The high-definition character image generation benchmark dataset proposed in this article has the characteristics of a large scale and strong diversity of high-resolution data, which helps to comprehensively evaluate pose-guided character image generation algorithms. Comprehensive benchmarks were established, and extensive experimental evaluations were implemented on the basis of general low-definition protocols and the first proposed high-definition protocols, which could contribute to an important platform for analyzing recent state-of-the-art person image generation methods. A unified framework for high-definition person image generation, including semantically enhanced partwise augmentation and a conditional upsampling module, was also used. Both modules are flexible and can work separately in a plug-and-play manner. The dataset and code proposed in this work are available at https://github.com/BraveGroup/PersonHD.关键词:human image synthesis;pose-guided transfer;high-definition dataset;low-definition benchmark;high definition benchmark96|127|0更新时间:2025-04-11
Dataset
- “在计算摄影领域,专家提出了高斯—维纳表示下的稠密焦栈图生成方法,有效解决了焦栈图像稠密化难题,为景深导向的视觉应用提供关键技术。”
 摘要:ObjectiveIn optical imaging systems, the depth of field (DoF) is typically limited by the properties of optical lenses, resulting in the ability to focus only on a limited region of the scene. Thus, expanding the depth of field for optical systems is a challenging task in the community for both academia and industry. For example, in computational photography, when dense focus stack images are captured, photographers can select different focal points and depths of field in postprocessing to achieve the desired artistic effects. In macro- and micro-imaging, dense focus stack images can provide clearer and more detailed images for more accurate analysis and measurement. For interactive and immersive media, dense focus stack images can provide a more realistic and immersive visual experience. However, achieving dense focus stack images also faces some challenges. First, the performance of hardware devices limits the speed and quality of image acquisition. During the shooting process, the camera needs to adjust the focus quickly and accurately and capture multiple images to build a focus stack. Therefore, high-performance cameras and adaptive autofocus algorithms are required. In addition, changes in the shooting environment, such as object motion or manual operations by photographers, can also introduce image blurring and alignment issues. These challenges are addressed by introducing the block-based Gaussian-Wiener bidirectional prediction model to provide an effective solution. When the image is embedded into blocks and the characteristics of local blocks for prediction are utilized, the computational complexity can be reduced, and the prediction accuracy can be improved. Gaussian-Wiener filtering can smooth prediction results and reduce the impact of artifacts and noise, which can improve image quality. The bidirectional prediction method combines the original sparse focal stack images(FoSIs) with the prediction results to generate dense FoSIs, thereby expanding the DoF of the optical system. The Gaussian-Wiener bidirectional prediction model provides an innovative method for capturing dense focus stack images. It can be applied to various scenarios and application fields, providing greater creative freedom and image processing capabilities for photographers, scientists, engineers, and artists.MethodThis work abstracts the FoS as a Gaussian-Wiener representation. The proposed bidirectional prediction model includes a bidirectional fitting module and a prediction generation module. On the basis of the Gaussian-Wiener representation model, a bidirectional fitting model is constructed to solve for the bidirectional prediction parameters and draw a new focal stack image. First, on the basis of the given sparse focus stack image sequence, the number ranges from near to far according to the focal length. These numbers start from 0 and are incremented according to a certain rule, such as increasing by 2 each time to ensure that all the numbers are even. These results in a set of sparse focus stack images arranged in serial order. Then, all images were divided into blocks according to predefined block sizes. The size of each block can be selected on the basis of specific needs and algorithms. The blocks located in adjacent numbers are combined to form a block pair, which becomes the most basic unit for bidirectional prediction. Before conducting bidirectional prediction, the image was preprocessed by dividing the focus stack image into blocks and recombining them into block pairs. This preprocessing process can be achieved by using image segmentation algorithms and block pair combination strategies. For each block pair, bidirectional prediction was performed to obtain the prediction parameters. These prediction parameters can be determined on the basis of specific prediction models and algorithms, such as the block-based Gaussian-Wiener bidirectional prediction model. In the bidirectional prediction module, block pairs can be used to fit the best bidirectional fitting parameters, and on this basis, the prediction generation parameters can be solved. When the information of the prediction generation parameters and block pairs is applied, new prediction blocks can be generated. Finally, when all the prediction blocks are concatenated according to their positions in the image, new prediction focus stack images can be obtained.ResultThis experiment is performed on 11 sparse focal stack images, with evaluation metrics using the peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). The average PSNR of the 11 sequence generated results is 40.861 dB, and the average SSIM is 0.976. Compared with the two comparison methods of generalized Gaussian and spatial coordinates, the PSNR is improved by 6.503 dB and 6.467 dB, respectively, and the SSIM is improved by 0.057 and 0.092, respectively. The average PSNR and SSIM of each sequence improved by at least 3.474 dB and 0.012, respectively.ConclusionThe experimental results show that the method proposed in this study outperforms both the subjective and objective comparison methods and has good performance on 11 different scene sequences. Combined with ablation experiments, the advantages of bidirectional prediction in the proposed method have been demonstrated. The results indicate that the proposed bidirectional prediction method can effectively generate new focal pile images and play a crucial role in visual applications that target various depths of the field.关键词:focal stack image(FoSI);prediction model;Gaussian-Wiener;representation model;bidirectional prediction111|113|0更新时间:2025-04-11
摘要:ObjectiveIn optical imaging systems, the depth of field (DoF) is typically limited by the properties of optical lenses, resulting in the ability to focus only on a limited region of the scene. Thus, expanding the depth of field for optical systems is a challenging task in the community for both academia and industry. For example, in computational photography, when dense focus stack images are captured, photographers can select different focal points and depths of field in postprocessing to achieve the desired artistic effects. In macro- and micro-imaging, dense focus stack images can provide clearer and more detailed images for more accurate analysis and measurement. For interactive and immersive media, dense focus stack images can provide a more realistic and immersive visual experience. However, achieving dense focus stack images also faces some challenges. First, the performance of hardware devices limits the speed and quality of image acquisition. During the shooting process, the camera needs to adjust the focus quickly and accurately and capture multiple images to build a focus stack. Therefore, high-performance cameras and adaptive autofocus algorithms are required. In addition, changes in the shooting environment, such as object motion or manual operations by photographers, can also introduce image blurring and alignment issues. These challenges are addressed by introducing the block-based Gaussian-Wiener bidirectional prediction model to provide an effective solution. When the image is embedded into blocks and the characteristics of local blocks for prediction are utilized, the computational complexity can be reduced, and the prediction accuracy can be improved. Gaussian-Wiener filtering can smooth prediction results and reduce the impact of artifacts and noise, which can improve image quality. The bidirectional prediction method combines the original sparse focal stack images(FoSIs) with the prediction results to generate dense FoSIs, thereby expanding the DoF of the optical system. The Gaussian-Wiener bidirectional prediction model provides an innovative method for capturing dense focus stack images. It can be applied to various scenarios and application fields, providing greater creative freedom and image processing capabilities for photographers, scientists, engineers, and artists.MethodThis work abstracts the FoS as a Gaussian-Wiener representation. The proposed bidirectional prediction model includes a bidirectional fitting module and a prediction generation module. On the basis of the Gaussian-Wiener representation model, a bidirectional fitting model is constructed to solve for the bidirectional prediction parameters and draw a new focal stack image. First, on the basis of the given sparse focus stack image sequence, the number ranges from near to far according to the focal length. These numbers start from 0 and are incremented according to a certain rule, such as increasing by 2 each time to ensure that all the numbers are even. These results in a set of sparse focus stack images arranged in serial order. Then, all images were divided into blocks according to predefined block sizes. The size of each block can be selected on the basis of specific needs and algorithms. The blocks located in adjacent numbers are combined to form a block pair, which becomes the most basic unit for bidirectional prediction. Before conducting bidirectional prediction, the image was preprocessed by dividing the focus stack image into blocks and recombining them into block pairs. This preprocessing process can be achieved by using image segmentation algorithms and block pair combination strategies. For each block pair, bidirectional prediction was performed to obtain the prediction parameters. These prediction parameters can be determined on the basis of specific prediction models and algorithms, such as the block-based Gaussian-Wiener bidirectional prediction model. In the bidirectional prediction module, block pairs can be used to fit the best bidirectional fitting parameters, and on this basis, the prediction generation parameters can be solved. When the information of the prediction generation parameters and block pairs is applied, new prediction blocks can be generated. Finally, when all the prediction blocks are concatenated according to their positions in the image, new prediction focus stack images can be obtained.ResultThis experiment is performed on 11 sparse focal stack images, with evaluation metrics using the peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). The average PSNR of the 11 sequence generated results is 40.861 dB, and the average SSIM is 0.976. Compared with the two comparison methods of generalized Gaussian and spatial coordinates, the PSNR is improved by 6.503 dB and 6.467 dB, respectively, and the SSIM is improved by 0.057 and 0.092, respectively. The average PSNR and SSIM of each sequence improved by at least 3.474 dB and 0.012, respectively.ConclusionThe experimental results show that the method proposed in this study outperforms both the subjective and objective comparison methods and has good performance on 11 different scene sequences. Combined with ablation experiments, the advantages of bidirectional prediction in the proposed method have been demonstrated. The results indicate that the proposed bidirectional prediction method can effectively generate new focal pile images and play a crucial role in visual applications that target various depths of the field.关键词:focal stack image(FoSI);prediction model;Gaussian-Wiener;representation model;bidirectional prediction111|113|0更新时间:2025-04-11
Image Processing and Coding
- “在动作检测领域,研究者提出了一种高效时空动作检测模型EAD,通过建模全局关键信息,提高了实时动作检测准确度。”
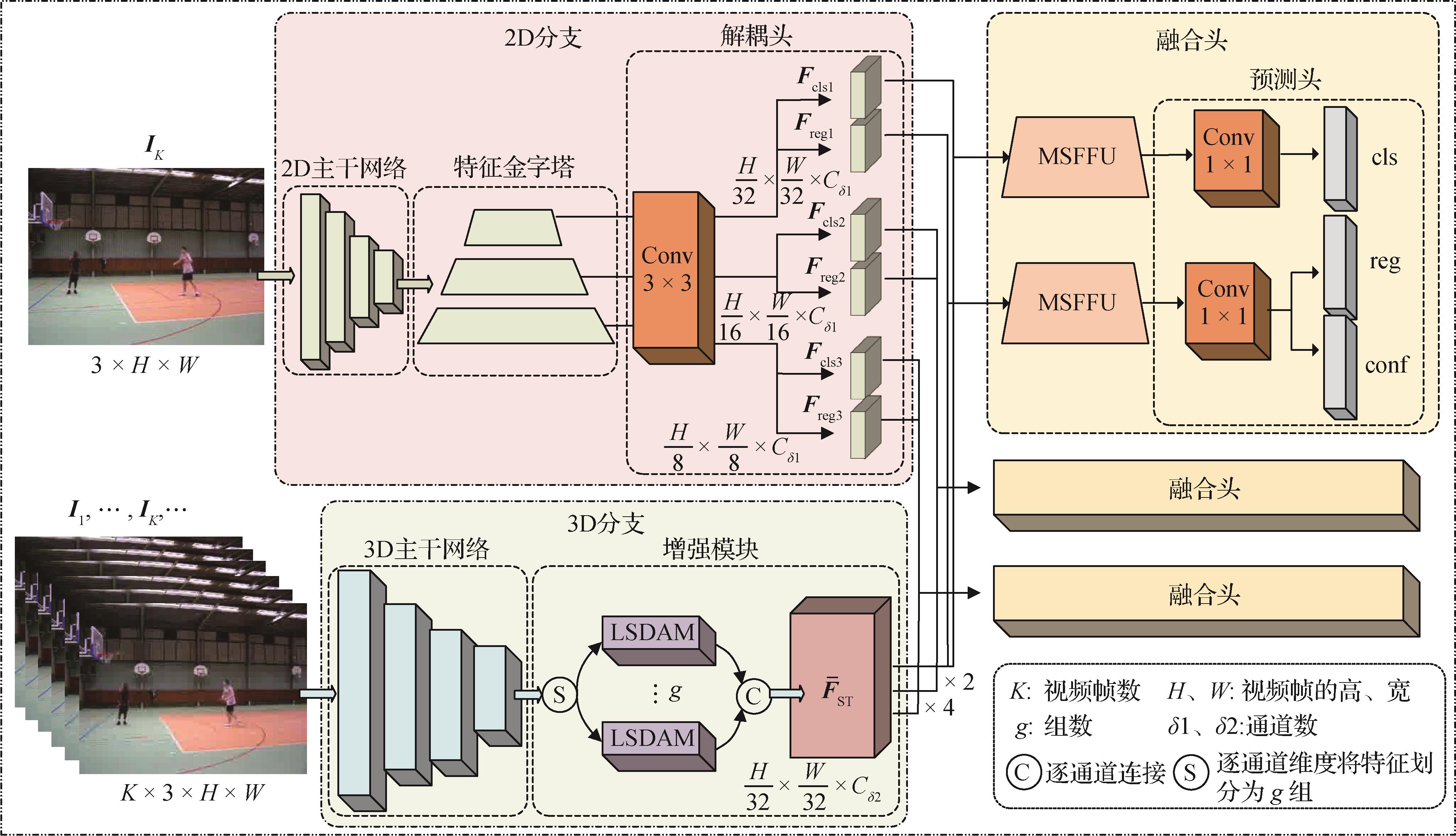 摘要:ObjectiveSpatial-temporal action detection (STAD) represents a significant challenge in the field of video understanding. The objective is to identify the temporal and spatial localization of actions occurring in a video and categorize related action classes. The majority of existing methods rely on the backbone for the feature modeling of video clips, which captures only local features and ignores the global contextual information of the interaction with the actors. The results are represented by a model that cannot fully comprehend the nuances of the entire scene. The current mainstream methods for real-time STAD tasks are dual-stream network-based methods. However, a simple channel-by-channel connection is typically employed to handle dual-branch network fusion, which results in a significant redundancy of the fused features and certain semantic differences in the branch features. This scheme affects the accuracy of the model. Here, an efficient STAD model called the efficient action detector (EAD), which can address the shortcomings of current methods, is proposed.MethodThe EAD model consists of three key components: the 2D branch, the 3D branch, and the fusion head. Among them, the 2D branch consists of a pretrained 2D backbone network, feature pyramid, and decoupling head; the 3D branch consists of a 3D backbone network and augmentation module; and the fusion head consists of a multiscale feature fusion unit (MSFFU) and a prediction head. First, key frames are extracted from the video clips and fed into the pretrained 2D branch backbone (YOLOv7) to detect the actors in the scene and obtain spatially decoupled features, which are classification features and localization features. Video spatial-temporal features are extracted from video clips via a pretrained lightweight video backbone network (Shufflenetv2). Second, the lightweight spatial dilated augmented module (LSDAM) uses the grouping idea to address spatial-temporal features, which serves to save resources. LSDAM consists of a dilated module (DM) and a spatial augmented module (SAM). The DM employs dilatation convolution with different dilation rates, which fully aggregates contextual feature information and reduces the loss of spatial resolution. The SAM takes the key information in the global features captured via the DM to focus and enhance the expression of the target features. The LSDAM receives the spatial-temporal features and sends them first to the DM to expand the sensory field, then subsequently to the SAM to extract the key information, and finally to the global, low-noise contextual information. Then, the enhanced features are dimensionally aligned with the spatially separated features and fed into the MSFFU for feature fusion. The MSFFU module refines the feature information via multiscale fusion and reduces the redundancy of the fused features, which enables the model to better understand the information in the whole scene. The MSFFU performs multiple levels of feature extraction for the double-branching features by utilizing different DO-Conv structures, and the individual MSFFU uses different DO-Conv structures to extract features from the dual-branch features at multiple levels, integrates each branch via element-by-element multiplication or addition, and then filters the irrelevant information in the features via a convolution operation. DO-Conv can accelerate the convergence of the network and improve the generalizability of the model, thereby improving the training speed of the model. Finally, the features at different levels are fed into the anchorless frame-based prediction head for STAD.ResultComparative detection results between EAD and existing algorithms were analyzed for the public datasets UCF101-24 and atomic visual actions (AVA) version 2.2. For the UCF101-24 dataset, frame-mAP, video-mAP, frame per second(FPS), GFLOPs, and Params are used as evaluation metrics to assess the accuracy and spatial-temporal complexity of the model. For the AVA dataset, frame-mAP and GFLOPs are used as evaluation metrics. In this work, ablation experiments on the EAD model are performed on the UCF101-24 dataset. The frame-mAP is 79.52%, and the video-mAP is 49.29% after the addition of the MSFFU, which are improvements of 0.41% and 0.14%, respectively, from the baseline. The frame-mAP is 80.96%, and the video-mAP is 49.72% after the addition of the LSDAM, which are improvements of 1.85% and 0.57%, respectively, from the baseline. The final model of the EAD frame-mAP is 80.93%, the video-mAP is 50.41%, the FPS is 53 f/s, the number of GFLOPs is 2.77, and the number of parameters is 10.92 M, which are improvements of 1.82% and 1.26%, respectively, compared with the baseline frame-averaged accuracy and video-averaged accuracy. The leakage and misdetection phenomenon of the baseline method also improved. In addition, EAD is compared with existing real-time STAD algorithms, in which the frame-mAP is improved by 0.53% and 0.43%, and the GFLOPs are reduced by 40.93 and 0.13 compared with those of YOWO and YOWOv2, respectively. On the AVA dataset, the frame-mAP and GFLOPs reach 13.74% and 2.77, respectively, for an input frame count of 16; moreover, the frame-mAP and GFLOPs reach 15.92% and 4.4%, respectively, for an input frame count of 32. Compared with other mainstream methods, EAD uses a lighter backbone network to achieve lower computational costs while achieving impressive results.ConclusionThis study proposes an STAD model called EAD, which is based on a two-stream network, to address the problems of missing global contextual information about actors’ interactions and the poor characterization of fused features. The results of the experimental results of the proposed model on the UCF101-24 and AVA datasets verify its robustness and effectiveness in STAD tasks by comparing it with the baseline and current mainstream methods. The proposed model can also be applied to the fields of intelligent monitoring, automatic driving, intelligent medical care, and other fields.关键词:deep learning;spatial-temporal action detection(STAD);two-branch network;dilated augmented module(DAM);multi-scale fusion146|135|0更新时间:2025-04-11
摘要:ObjectiveSpatial-temporal action detection (STAD) represents a significant challenge in the field of video understanding. The objective is to identify the temporal and spatial localization of actions occurring in a video and categorize related action classes. The majority of existing methods rely on the backbone for the feature modeling of video clips, which captures only local features and ignores the global contextual information of the interaction with the actors. The results are represented by a model that cannot fully comprehend the nuances of the entire scene. The current mainstream methods for real-time STAD tasks are dual-stream network-based methods. However, a simple channel-by-channel connection is typically employed to handle dual-branch network fusion, which results in a significant redundancy of the fused features and certain semantic differences in the branch features. This scheme affects the accuracy of the model. Here, an efficient STAD model called the efficient action detector (EAD), which can address the shortcomings of current methods, is proposed.MethodThe EAD model consists of three key components: the 2D branch, the 3D branch, and the fusion head. Among them, the 2D branch consists of a pretrained 2D backbone network, feature pyramid, and decoupling head; the 3D branch consists of a 3D backbone network and augmentation module; and the fusion head consists of a multiscale feature fusion unit (MSFFU) and a prediction head. First, key frames are extracted from the video clips and fed into the pretrained 2D branch backbone (YOLOv7) to detect the actors in the scene and obtain spatially decoupled features, which are classification features and localization features. Video spatial-temporal features are extracted from video clips via a pretrained lightweight video backbone network (Shufflenetv2). Second, the lightweight spatial dilated augmented module (LSDAM) uses the grouping idea to address spatial-temporal features, which serves to save resources. LSDAM consists of a dilated module (DM) and a spatial augmented module (SAM). The DM employs dilatation convolution with different dilation rates, which fully aggregates contextual feature information and reduces the loss of spatial resolution. The SAM takes the key information in the global features captured via the DM to focus and enhance the expression of the target features. The LSDAM receives the spatial-temporal features and sends them first to the DM to expand the sensory field, then subsequently to the SAM to extract the key information, and finally to the global, low-noise contextual information. Then, the enhanced features are dimensionally aligned with the spatially separated features and fed into the MSFFU for feature fusion. The MSFFU module refines the feature information via multiscale fusion and reduces the redundancy of the fused features, which enables the model to better understand the information in the whole scene. The MSFFU performs multiple levels of feature extraction for the double-branching features by utilizing different DO-Conv structures, and the individual MSFFU uses different DO-Conv structures to extract features from the dual-branch features at multiple levels, integrates each branch via element-by-element multiplication or addition, and then filters the irrelevant information in the features via a convolution operation. DO-Conv can accelerate the convergence of the network and improve the generalizability of the model, thereby improving the training speed of the model. Finally, the features at different levels are fed into the anchorless frame-based prediction head for STAD.ResultComparative detection results between EAD and existing algorithms were analyzed for the public datasets UCF101-24 and atomic visual actions (AVA) version 2.2. For the UCF101-24 dataset, frame-mAP, video-mAP, frame per second(FPS), GFLOPs, and Params are used as evaluation metrics to assess the accuracy and spatial-temporal complexity of the model. For the AVA dataset, frame-mAP and GFLOPs are used as evaluation metrics. In this work, ablation experiments on the EAD model are performed on the UCF101-24 dataset. The frame-mAP is 79.52%, and the video-mAP is 49.29% after the addition of the MSFFU, which are improvements of 0.41% and 0.14%, respectively, from the baseline. The frame-mAP is 80.96%, and the video-mAP is 49.72% after the addition of the LSDAM, which are improvements of 1.85% and 0.57%, respectively, from the baseline. The final model of the EAD frame-mAP is 80.93%, the video-mAP is 50.41%, the FPS is 53 f/s, the number of GFLOPs is 2.77, and the number of parameters is 10.92 M, which are improvements of 1.82% and 1.26%, respectively, compared with the baseline frame-averaged accuracy and video-averaged accuracy. The leakage and misdetection phenomenon of the baseline method also improved. In addition, EAD is compared with existing real-time STAD algorithms, in which the frame-mAP is improved by 0.53% and 0.43%, and the GFLOPs are reduced by 40.93 and 0.13 compared with those of YOWO and YOWOv2, respectively. On the AVA dataset, the frame-mAP and GFLOPs reach 13.74% and 2.77, respectively, for an input frame count of 16; moreover, the frame-mAP and GFLOPs reach 15.92% and 4.4%, respectively, for an input frame count of 32. Compared with other mainstream methods, EAD uses a lighter backbone network to achieve lower computational costs while achieving impressive results.ConclusionThis study proposes an STAD model called EAD, which is based on a two-stream network, to address the problems of missing global contextual information about actors’ interactions and the poor characterization of fused features. The results of the experimental results of the proposed model on the UCF101-24 and AVA datasets verify its robustness and effectiveness in STAD tasks by comparing it with the baseline and current mainstream methods. The proposed model can also be applied to the fields of intelligent monitoring, automatic driving, intelligent medical care, and other fields.关键词:deep learning;spatial-temporal action detection(STAD);two-branch network;dilated augmented module(DAM);multi-scale fusion146|135|0更新时间:2025-04-11 - “在深度伪造检测领域,专家提出了跨域人脸伪造检测模型NIG-FFD,有效提升了跨域和本域检测性能。”
 摘要:ObjectiveWith the rapid development of multimedia, mobile internet, and artificial intelligence technologies, facial recognition has achieved tremendous success in areas such as identity verification and security monitoring. However, with its widespread application, the risk of facial forgery attacks is gradually increasing. These attacks leverage deep learning models to create fraudulent digital content, including images, videos, and audio, posing a potential threat to societal stability and national security. Therefore, achieving deepfake detection is crucial for maintaining individual and organizational interests, ensuring public safety, and promoting the sustainable development of innovative technologies. According to different modes of image representation, deepfake detection methods can generally be divided into two categories. First, methods based on traditional image feature description typically involve image processing and feature extraction based on signal transformation models. Second, methods based on deep learning strategies for forged facial detection employ complex deep neural networks to obtain more discriminative high-dimensional nonlinear facial feature descriptions, thereby improving forgery detection accuracy. Both of these methods have achieved satisfactory results in deepfake detection experiments. However, most training and testing samples for these models are collected from the same data domain, resulting in excellent performance under such conditions; subsequently, it becomes challenging to obtain testing samples that are consistent with the distribution of the original training samples in practical applications, which may limit the application of these models in free-scene forgery detection tasks and even lead to complete model failure. Therefore, some scholars have proposed a data augmentation framework based on structural feature mining to increase the performance of convolutional neural network detectors. However, when faces are seamlessly integrated with backgrounds at the pixel level, the recognition accuracy significantly decreases. Consequently, some scholars have utilized transformer network architectures to construct deep forgery detection frameworks. Although this model achieves satisfactory generalization by deeply understanding the manipulated regions, it lacks descriptions of local tampering representations, and its detection efficiency is also quite low. On this basis, the main challenges faced in constructing deepfake detection models in cross-domain scenarios can be summarized as follows: 1) extracting discriminative representations of forged facial images. The forgery process of facial images typically involves tampering or replacing local features of the image, posing challenges for obtaining discriminative features. 2) Improving the generalizability of detection models. Overreliance on current domain data during model training reduces the generalizability of recognition to other domain data, and when facing more challenging free-forgery detection scenarios, model failure may occur. This study addresses these challenges by introducing a cross-domain detection model that is based on diverse negative instance generations.MethodThe model achieves feature augmentation of forged negative instances and enhances the cross-domain recognition accuracy and generalizability by constructing a Siamese autoencoder network architecture with multiview feature fusion. It consists of the following three parts: 1) the model implements discriminative multiview feature fusion under contrastive constraints. First, a Siamese autoencoder network is constructed to extract different view features. Second, contrastive constraints are employed to achieve multiview feature fusion. Given that typical facial forgery image manipulation involves only small-scale replacements and tampering, the global features of forged facial images are remarkably similar to those of real faces. Contrastive loss enables the differentiation of weakly discriminative hard samples. It maximizes the similarity of intraclass features while minimizing the similarity of interclass features. Finally, comprehensive learning is facilitated by guiding the supervised feature extraction network to retain important feature information of the original input, an approach for emphasizing the learning of discriminative feature representations. This study proposes the use of reconstruction loss to constrain the feature network by computing the difference between the decoder output and the original input. 2) The model achieves diversity in negative instance feature augmentation to enhance model generalizability, ensuring satisfactory recognition performance on cross-domain datasets. First, the rules for generating the fused samples are defined. This study statistically visualizes the network output feature histograms of constructed samples with different labels via feature visualization, analyzes the statistical patterns of negative samples, and defines feature-level sample generation rules: except when both view features are from positive samples, all other combinations of feature samples are generated as negative samples. Second, diverse forged feature sets are constructed using selected samples to enable the network to learn more discriminative features. Finally, a global training sample set is obtained by connecting the original training samples and augmented samples. 3) The model implements a discriminator construction with importance sample weighting. When the abovementioned feature augmentation of negative instances is achieved, the number of original negative instances can be significantly increased. This study introduces an importance weighting mechanism to avoid model overfitting on negative samples and underfitting on positive samples. First, the matrix is initialized to set different weights for each class sample, allowing negative samples to be weighted according to their predicted probabilities while keeping positive samples unchanged, thereby approximately achieving class balance during the loss calculation. Through negative sample weighting, the model is guided to pay more attention to positive sample features and prevent the classification decision boundary from biasing toward negative samples. Second, the distance between the predicted probability distribution and the true probability distribution was measured via cross-entropy loss as the classification loss function to supervise the classification results. Finally, the total loss function for model training is obtained.ResultExperiments were conducted on three publicly available datasets to verify the effectiveness of the proposed method in a cross-domain environment. The model was subsequently compared with other popular methods, namely, FaceForensics++ (FF++), Celeb-DFv2, and the Deepfake Detection Challenge, and the results were analyzed. The FF++ dataset comprises three versions based on different compression levels: c0 (original), c23 (high quality), and c40 (low quality). This study utilized the c23 and c40 versions for experimentation. The Celeb-DFv2 dataset is widely employed to test the models’ generalization capabilities, as its forged images lack obvious visual artifact characteristics of deepfake manipulation, posing significant challenges in generalization detection. In the experiments, 100 genuine videos and 100 forged videos were randomly selected, with one image extracted every 30 frames. For the DFDC dataset, 140 videos were randomly selected, with 20 frames extracted from each video for testing. According to the experimental results, the proposed model exhibited a 10% improvement in the area under the curve (AUC) of the receiver operating characteristics compared with other state-of-the-art methods. Additionally, the model’s detection results in the native domain environment were validated, showing an approximate 10% and 5% increase in the ACC (accuracy score) and AUC values, respectively, compared with those of the other methods.ConclusionThe method proposed in this study achieves superior performance in both cross-domain and in-domain deepfake detection.关键词:DeepFake detection;cross-domain face forgery detection;multi-view feature fusion;feature generation;contrastive constrain45|85|0更新时间:2025-04-11
摘要:ObjectiveWith the rapid development of multimedia, mobile internet, and artificial intelligence technologies, facial recognition has achieved tremendous success in areas such as identity verification and security monitoring. However, with its widespread application, the risk of facial forgery attacks is gradually increasing. These attacks leverage deep learning models to create fraudulent digital content, including images, videos, and audio, posing a potential threat to societal stability and national security. Therefore, achieving deepfake detection is crucial for maintaining individual and organizational interests, ensuring public safety, and promoting the sustainable development of innovative technologies. According to different modes of image representation, deepfake detection methods can generally be divided into two categories. First, methods based on traditional image feature description typically involve image processing and feature extraction based on signal transformation models. Second, methods based on deep learning strategies for forged facial detection employ complex deep neural networks to obtain more discriminative high-dimensional nonlinear facial feature descriptions, thereby improving forgery detection accuracy. Both of these methods have achieved satisfactory results in deepfake detection experiments. However, most training and testing samples for these models are collected from the same data domain, resulting in excellent performance under such conditions; subsequently, it becomes challenging to obtain testing samples that are consistent with the distribution of the original training samples in practical applications, which may limit the application of these models in free-scene forgery detection tasks and even lead to complete model failure. Therefore, some scholars have proposed a data augmentation framework based on structural feature mining to increase the performance of convolutional neural network detectors. However, when faces are seamlessly integrated with backgrounds at the pixel level, the recognition accuracy significantly decreases. Consequently, some scholars have utilized transformer network architectures to construct deep forgery detection frameworks. Although this model achieves satisfactory generalization by deeply understanding the manipulated regions, it lacks descriptions of local tampering representations, and its detection efficiency is also quite low. On this basis, the main challenges faced in constructing deepfake detection models in cross-domain scenarios can be summarized as follows: 1) extracting discriminative representations of forged facial images. The forgery process of facial images typically involves tampering or replacing local features of the image, posing challenges for obtaining discriminative features. 2) Improving the generalizability of detection models. Overreliance on current domain data during model training reduces the generalizability of recognition to other domain data, and when facing more challenging free-forgery detection scenarios, model failure may occur. This study addresses these challenges by introducing a cross-domain detection model that is based on diverse negative instance generations.MethodThe model achieves feature augmentation of forged negative instances and enhances the cross-domain recognition accuracy and generalizability by constructing a Siamese autoencoder network architecture with multiview feature fusion. It consists of the following three parts: 1) the model implements discriminative multiview feature fusion under contrastive constraints. First, a Siamese autoencoder network is constructed to extract different view features. Second, contrastive constraints are employed to achieve multiview feature fusion. Given that typical facial forgery image manipulation involves only small-scale replacements and tampering, the global features of forged facial images are remarkably similar to those of real faces. Contrastive loss enables the differentiation of weakly discriminative hard samples. It maximizes the similarity of intraclass features while minimizing the similarity of interclass features. Finally, comprehensive learning is facilitated by guiding the supervised feature extraction network to retain important feature information of the original input, an approach for emphasizing the learning of discriminative feature representations. This study proposes the use of reconstruction loss to constrain the feature network by computing the difference between the decoder output and the original input. 2) The model achieves diversity in negative instance feature augmentation to enhance model generalizability, ensuring satisfactory recognition performance on cross-domain datasets. First, the rules for generating the fused samples are defined. This study statistically visualizes the network output feature histograms of constructed samples with different labels via feature visualization, analyzes the statistical patterns of negative samples, and defines feature-level sample generation rules: except when both view features are from positive samples, all other combinations of feature samples are generated as negative samples. Second, diverse forged feature sets are constructed using selected samples to enable the network to learn more discriminative features. Finally, a global training sample set is obtained by connecting the original training samples and augmented samples. 3) The model implements a discriminator construction with importance sample weighting. When the abovementioned feature augmentation of negative instances is achieved, the number of original negative instances can be significantly increased. This study introduces an importance weighting mechanism to avoid model overfitting on negative samples and underfitting on positive samples. First, the matrix is initialized to set different weights for each class sample, allowing negative samples to be weighted according to their predicted probabilities while keeping positive samples unchanged, thereby approximately achieving class balance during the loss calculation. Through negative sample weighting, the model is guided to pay more attention to positive sample features and prevent the classification decision boundary from biasing toward negative samples. Second, the distance between the predicted probability distribution and the true probability distribution was measured via cross-entropy loss as the classification loss function to supervise the classification results. Finally, the total loss function for model training is obtained.ResultExperiments were conducted on three publicly available datasets to verify the effectiveness of the proposed method in a cross-domain environment. The model was subsequently compared with other popular methods, namely, FaceForensics++ (FF++), Celeb-DFv2, and the Deepfake Detection Challenge, and the results were analyzed. The FF++ dataset comprises three versions based on different compression levels: c0 (original), c23 (high quality), and c40 (low quality). This study utilized the c23 and c40 versions for experimentation. The Celeb-DFv2 dataset is widely employed to test the models’ generalization capabilities, as its forged images lack obvious visual artifact characteristics of deepfake manipulation, posing significant challenges in generalization detection. In the experiments, 100 genuine videos and 100 forged videos were randomly selected, with one image extracted every 30 frames. For the DFDC dataset, 140 videos were randomly selected, with 20 frames extracted from each video for testing. According to the experimental results, the proposed model exhibited a 10% improvement in the area under the curve (AUC) of the receiver operating characteristics compared with other state-of-the-art methods. Additionally, the model’s detection results in the native domain environment were validated, showing an approximate 10% and 5% increase in the ACC (accuracy score) and AUC values, respectively, compared with those of the other methods.ConclusionThe method proposed in this study achieves superior performance in both cross-domain and in-domain deepfake detection.关键词:DeepFake detection;cross-domain face forgery detection;multi-view feature fusion;feature generation;contrastive constrain45|85|0更新时间:2025-04-11 - “在表情识别领域,专家提出了一种双一致性半监督方法,显著提升了模型在头部姿态变化下的表情识别精度,为解决头部姿态对表情识别影响问题提供解决方案。”
 摘要:ObjectiveThe field of facial expression recognition (FER) has long been a vibrant area of research, with a focus on improving the accuracy of identifying expressions across a wide range of faces. However, despite these advancements, a crucial aspect that has not been adequately explored is the robustness of FER models to changes in head pose. In real-world applications, where faces are captured at various angles and poses, existing methods often struggle to accurately recognize expressions in faces with considerable pose variations. This limitation has created an urgent need to understand the extent to which head pose affects FER models and to develop robust models that can handle diverse poses effectively. First, the impact of head pose on FER was analyzed. Rigorous experimentation has provided strong evidence that existing FER approaches are indeed vulnerable when faced with faces exhibiting large head poses. This vulnerability not only limits the practical applicability of these methods but also highlights the critical need for research focused on enhancing the pose robustness of FER models. This challenge is addressed by introducing a semi-supervised framework that leverages unlabeled nonfrontal facial expression samples to increase the pose robustness of FER models. This framework aims to overcome the limitations of existing methods by exploring unlabeled data to supplement labeled frontal face data, allowing the model to learn representations that are invariant to head pose variations. Incorporating unlabeled data expands the model’s exposure to a wider range of poses, ultimately enhancing robustness and accuracy in FER. This study highlights the importance of pose robustness in FER and proposes a semi-supervised framework to address this critical limitation. Rigorous experimentation and analysis provide insights into the impact of head pose on FER, and a robust model to accurately recognize facial expressions across diverse poses is developed. This approach paves the way for more practical and reliable FER systems in real-world applications.MethodThe AffectNet dataset was reorganized via a deterministic resampling procedure to examine the impact of head pose on FER. In this procedure, the same numbers of faces from different expression categories and head pose intervals were uniformly and randomly sampled to build a new challenging FER dataset called AffectNet-Yaw, whose test samples were balanced both in the category axis and the head pose axis. The AffectNet-Yaw dataset enables a deep investigation into how head pose affects the performance of an FER model. A semi-supervised framework for FER called dual consistency constraints (DCSSLs) was used to improve the robustness of the model to head poses. This framework leverages a spatial consistency module to force the model to produce consistent category activation maps for each face and its flipped mirror during training, which allows the model to prioritize the key facial regions for FER. A semantic consistency module is also employed to force the model to extract consistent features of two augmentations of the same face that exhibit similar semantics. In particular, two different data augmentations were applied to a face. One of the arguments is weak, and the other is strong. The weakly augmented face was flipped, and model predictions of this sample and its flipped mirror were obtained. Only those unlabeled nonfrontal faces for which the model makes the same prediction with high confidence are retained. Their predicted categories together with their strongly augmented variant comprise “date-label” pairs that are utilized for model training as pseudolabeled positives. This scheme increases data variation to benefit model optimization. Within the framework, a joint optimization target that can integrate cross-entropy loss, the spatial consistency constraint, and the semantic consistency constraint was devised to balance supervised learning and semi-supervised learning. Owing to the joint training, the proposed framework requires no manual labeling of nonfrontal faces; instead, it directly learns from labeled frontal faces and unlabeled nonfrontal faces, highly boosting its robustness and generalizability.ResultThe evaluation results of various fully supervised FER methods on both the AffectNet and AffectNet-Yaw datasets underscore the profound impact of head pose variability in real-world scenarios, emphasizing the critical need to increase the robustness of the FER model to such challenges. Empirical findings confirm that the AffectNet-Yaw dataset serves as a rigorous and effective platform for comprehensive investigations into how head pose influences FER model performance. Comparative analyses between baseline models and state-of-the-art methods on the AffectNet and AffectNet-Yaw datasets reveal compelling insights. In particular, the novel DCSSL framework considerably enhances the model’s ability to adapt to head pose variations, showing substantial improvement over existing benchmarks. When MA-NET and EfficientFace are used as benchmarks, the DCSSL framework achieves considerable average performance improvements of 5.40% and 17.01%, respectively. In addition, the effectiveness of this approach was determined by comparing the models that have performed well in the field of expression recognition in the last three years on two separate datasets. In terms of weighting parameter settings, different weighting choices have a considerable effect on model performance. A series of parameter selection experiments were conducted via the control variable approach, and the model achieves optimal expression recognition performance on the AffectNet-Yaw test data when the weight of the spatial consistency constraint loss is set to 1 and that of the semantic consistency constraint loss is set to 5. These results highlight the efficacy of the proposed DCSSL framework in mitigating the detrimental effects of head pose variations on FER accuracy. When spatial and semantic consistency modules are integrated, the proposed approach can not only improve model robustness but also demonstrate its ability to adapt and generalize effectively across diverse head poses encountered in real-world applications. This study not only contributes to a challenging new dataset named AffectNet-Yaw for advancing FER research under realistic conditions but also establishes a novel methodology named DCSSL that sets a new standard for addressing head pose challenges in FER. These advancements are pivotal for enhancing the reliability and applicability of FER systems in practical settings where head pose variability is prevalent.ConclusionThe proposed DCSSL framework in this work can efficiently exploit both frontal and nonfrontal faces, successfully increasing the accuracy of FER under diverse head poses. The new AffectNet-Yaw dataset has a more balanced data distribution, both along the category axis and the head pose axis, enabling a comprehensive study of the impact of head poses on FER. Both of these elements hold substantial value for building robust FER models.关键词:facial expression recognition (FER);head pose;dual-consistency constraint;semi-supervised learning;AffectNet;image recognition62|80|0更新时间:2025-04-11
摘要:ObjectiveThe field of facial expression recognition (FER) has long been a vibrant area of research, with a focus on improving the accuracy of identifying expressions across a wide range of faces. However, despite these advancements, a crucial aspect that has not been adequately explored is the robustness of FER models to changes in head pose. In real-world applications, where faces are captured at various angles and poses, existing methods often struggle to accurately recognize expressions in faces with considerable pose variations. This limitation has created an urgent need to understand the extent to which head pose affects FER models and to develop robust models that can handle diverse poses effectively. First, the impact of head pose on FER was analyzed. Rigorous experimentation has provided strong evidence that existing FER approaches are indeed vulnerable when faced with faces exhibiting large head poses. This vulnerability not only limits the practical applicability of these methods but also highlights the critical need for research focused on enhancing the pose robustness of FER models. This challenge is addressed by introducing a semi-supervised framework that leverages unlabeled nonfrontal facial expression samples to increase the pose robustness of FER models. This framework aims to overcome the limitations of existing methods by exploring unlabeled data to supplement labeled frontal face data, allowing the model to learn representations that are invariant to head pose variations. Incorporating unlabeled data expands the model’s exposure to a wider range of poses, ultimately enhancing robustness and accuracy in FER. This study highlights the importance of pose robustness in FER and proposes a semi-supervised framework to address this critical limitation. Rigorous experimentation and analysis provide insights into the impact of head pose on FER, and a robust model to accurately recognize facial expressions across diverse poses is developed. This approach paves the way for more practical and reliable FER systems in real-world applications.MethodThe AffectNet dataset was reorganized via a deterministic resampling procedure to examine the impact of head pose on FER. In this procedure, the same numbers of faces from different expression categories and head pose intervals were uniformly and randomly sampled to build a new challenging FER dataset called AffectNet-Yaw, whose test samples were balanced both in the category axis and the head pose axis. The AffectNet-Yaw dataset enables a deep investigation into how head pose affects the performance of an FER model. A semi-supervised framework for FER called dual consistency constraints (DCSSLs) was used to improve the robustness of the model to head poses. This framework leverages a spatial consistency module to force the model to produce consistent category activation maps for each face and its flipped mirror during training, which allows the model to prioritize the key facial regions for FER. A semantic consistency module is also employed to force the model to extract consistent features of two augmentations of the same face that exhibit similar semantics. In particular, two different data augmentations were applied to a face. One of the arguments is weak, and the other is strong. The weakly augmented face was flipped, and model predictions of this sample and its flipped mirror were obtained. Only those unlabeled nonfrontal faces for which the model makes the same prediction with high confidence are retained. Their predicted categories together with their strongly augmented variant comprise “date-label” pairs that are utilized for model training as pseudolabeled positives. This scheme increases data variation to benefit model optimization. Within the framework, a joint optimization target that can integrate cross-entropy loss, the spatial consistency constraint, and the semantic consistency constraint was devised to balance supervised learning and semi-supervised learning. Owing to the joint training, the proposed framework requires no manual labeling of nonfrontal faces; instead, it directly learns from labeled frontal faces and unlabeled nonfrontal faces, highly boosting its robustness and generalizability.ResultThe evaluation results of various fully supervised FER methods on both the AffectNet and AffectNet-Yaw datasets underscore the profound impact of head pose variability in real-world scenarios, emphasizing the critical need to increase the robustness of the FER model to such challenges. Empirical findings confirm that the AffectNet-Yaw dataset serves as a rigorous and effective platform for comprehensive investigations into how head pose influences FER model performance. Comparative analyses between baseline models and state-of-the-art methods on the AffectNet and AffectNet-Yaw datasets reveal compelling insights. In particular, the novel DCSSL framework considerably enhances the model’s ability to adapt to head pose variations, showing substantial improvement over existing benchmarks. When MA-NET and EfficientFace are used as benchmarks, the DCSSL framework achieves considerable average performance improvements of 5.40% and 17.01%, respectively. In addition, the effectiveness of this approach was determined by comparing the models that have performed well in the field of expression recognition in the last three years on two separate datasets. In terms of weighting parameter settings, different weighting choices have a considerable effect on model performance. A series of parameter selection experiments were conducted via the control variable approach, and the model achieves optimal expression recognition performance on the AffectNet-Yaw test data when the weight of the spatial consistency constraint loss is set to 1 and that of the semantic consistency constraint loss is set to 5. These results highlight the efficacy of the proposed DCSSL framework in mitigating the detrimental effects of head pose variations on FER accuracy. When spatial and semantic consistency modules are integrated, the proposed approach can not only improve model robustness but also demonstrate its ability to adapt and generalize effectively across diverse head poses encountered in real-world applications. This study not only contributes to a challenging new dataset named AffectNet-Yaw for advancing FER research under realistic conditions but also establishes a novel methodology named DCSSL that sets a new standard for addressing head pose challenges in FER. These advancements are pivotal for enhancing the reliability and applicability of FER systems in practical settings where head pose variability is prevalent.ConclusionThe proposed DCSSL framework in this work can efficiently exploit both frontal and nonfrontal faces, successfully increasing the accuracy of FER under diverse head poses. The new AffectNet-Yaw dataset has a more balanced data distribution, both along the category axis and the head pose axis, enabling a comprehensive study of the impact of head poses on FER. Both of these elements hold substantial value for building robust FER models.关键词:facial expression recognition (FER);head pose;dual-consistency constraint;semi-supervised learning;AffectNet;image recognition62|80|0更新时间:2025-04-11 - “在工业缺陷检测领域,研究者提出了基于归一化流的多模态多尺度缺陷检测方法,有效提高了检测精度和鲁棒性,满足了现代工业质量控制需求。”
 摘要:ObjectiveDefect detection stands as a fundamental cornerstone in modern industrial quality control frameworks. As industries have advanced, the array of defect types has become increasingly diverse. Some defects present formidable challenges, as they are scarcely perceptible when examined using individual RGB images. This approach necessitates additional information from complementary modalities to aid in detection. Consequently, conventional deep learning methods, which rely solely on single modal data for defect identification, have proven inadequate for meeting the dynamic demands of contemporary industrial environments. Here, an innovative approach is proposed to address the nuanced challenges inherent in multimodal defect detection scenarios prevalent in modern industries, where defects vary considerably in shape and size and often exhibit low perceptibility within individual modalities. The proposed method can integrate a novel multimodal multiscale defect detection framework grounded in the principles of normalizing flows once the inherent noise interference within single modal feature spaces is addressed and the synergies between multimodal information are harnessed.MethodThe proposed method is structured into four main components: feature extraction, unsupervised feature fusion, an information bottleneck mechanism, and multiscale normalizing flow. First, in the feature extraction stage, features at different levels are assumed to contain varying degrees of spatial and semantic information. Low-level features contain more spatial information, whereas high-level features convey richer semantic information. Given the emphasis on spatial detail information in pixel-level defect localization tasks. Vision transformers and point transformers were used to extract features from RGB images and 3D point clouds, with a focus on blocks 1, 3, and 11, to obtain multimodal representations at different levels. The representations are subsequently fused and structured into a feature pyramid. This approach not only preserves spatial information from low-level features to aid in defect localization but also enhances the model’s robustness to defects of varying shapes and sizes. Second, in the unsupervised feature fusion stage, the multimodal interaction was streamlined by employing the point feature alignment technique to align 3D point cloud features with the RGB image plane. Unsupervised multimodal feature fusion was achieved by constructing a contrastive learning matrix, thereby facilitating interaction between different modalities. Moreover, in the information bottleneck mechanism stage, a proxy task is designed to extend the information bottleneck mechanism to unsupervised settings. The aim is to obtain a more comprehensive and robust multimodal representation by minimizing noise interference within single-modal raw feature spaces while preserving the original information as much as possible. Finally, in the multiscale normalizing flow stage, the structure uses parallel flows to capture feature information at different scales. Through the fusion of these flows, interactions between features at various scales are realized. Additionally, an innovative approach for anomaly scoring is employed, wherein the average of the Top-K values in the anomaly score map replaces traditional methods such as those that use the mean or maximum values. This approach yields the final defect detection results.ResultThe proposed method is evaluated on the MVTec-3D AD dataset. This dataset is meticulously curated, encompassing 10 distinct categories of industrial products, with a comprehensive collection of 2 656 training samples and 1 137 testing samples. Each category is meticulously segmented into subclasses, delineated by the nature of the defects. The proposed method was experimentally validated, and the results demonstrated its exceptional performance. An AUCROC of 93.3%, a segmentation AUPRO of 96.1%, and a segmentation AUCROC of 98.8% were achieved. These metrics not only reflect the method’s effectiveness but also have advantages over the majority of existing multimodal defect detection methodologies. Moreover, visualizations were conducted on selected samples, comparing the detection outcomes using only RGB images against those utilizing RGB images in conjunction with 3D point clouds. The latter combination has revealed defects that remain elusive when relying solely on RGB imagery. This empirical evidence firmly establishes the advantage of integrating data from both modalities, as posited in the hypothesis of this study. The ablation studies conducted provide additional insights into the efficacy of the proposed method. The introduction of an information bottleneck resulted in incremental improvements across all three metrics: 1.4% in the detection AUCROC, 2.1% in the segmentation AUPRO, and 3.5% in the segmentation AUCROC. The integration of a multiscale normalizing flow further enhanced the performance, with gains of 2.5%, 3.6%, and 1.6% across the respective metrics. These findings are indicative of the substantial contributions of both the information bottleneck and the multiscale normalizing flow to the overall performance of the defect detection framework used in this work.ConclusionThe main contributions of this study are as follows: unsupervised feature fusion was employed to encourage information exchange between different modalities. An information bottleneck was introduced into the feature fusion module to mitigate the impact of noise in the original feature space of single modalities on multimodal interaction. Additionally, multimodal representations were utilized at different levels to construct feature pyramids, addressing the issue of the poor performance of previous flow-based methods in handling defects of varying scales. The proposed method demonstrates promising detection performance across defects of diverse shapes and sizes, including those with low perceptibility on RGB images. When the impact of noise within the original feature space on the multimodal representation is mitigated, the proposed approach can not only improve the robustness of the method but also enhance its ability to generalize the defects of varying characteristics. This approach effectively aligns with the stringent demands of modern industry for accurate and reliable defect detection methodologies.关键词:multimodal and multi-scale industrial scene;anomaly detection;unsupervised feature fusion(UFF);pretext task;normalizing flow94|125|0更新时间:2025-04-11
摘要:ObjectiveDefect detection stands as a fundamental cornerstone in modern industrial quality control frameworks. As industries have advanced, the array of defect types has become increasingly diverse. Some defects present formidable challenges, as they are scarcely perceptible when examined using individual RGB images. This approach necessitates additional information from complementary modalities to aid in detection. Consequently, conventional deep learning methods, which rely solely on single modal data for defect identification, have proven inadequate for meeting the dynamic demands of contemporary industrial environments. Here, an innovative approach is proposed to address the nuanced challenges inherent in multimodal defect detection scenarios prevalent in modern industries, where defects vary considerably in shape and size and often exhibit low perceptibility within individual modalities. The proposed method can integrate a novel multimodal multiscale defect detection framework grounded in the principles of normalizing flows once the inherent noise interference within single modal feature spaces is addressed and the synergies between multimodal information are harnessed.MethodThe proposed method is structured into four main components: feature extraction, unsupervised feature fusion, an information bottleneck mechanism, and multiscale normalizing flow. First, in the feature extraction stage, features at different levels are assumed to contain varying degrees of spatial and semantic information. Low-level features contain more spatial information, whereas high-level features convey richer semantic information. Given the emphasis on spatial detail information in pixel-level defect localization tasks. Vision transformers and point transformers were used to extract features from RGB images and 3D point clouds, with a focus on blocks 1, 3, and 11, to obtain multimodal representations at different levels. The representations are subsequently fused and structured into a feature pyramid. This approach not only preserves spatial information from low-level features to aid in defect localization but also enhances the model’s robustness to defects of varying shapes and sizes. Second, in the unsupervised feature fusion stage, the multimodal interaction was streamlined by employing the point feature alignment technique to align 3D point cloud features with the RGB image plane. Unsupervised multimodal feature fusion was achieved by constructing a contrastive learning matrix, thereby facilitating interaction between different modalities. Moreover, in the information bottleneck mechanism stage, a proxy task is designed to extend the information bottleneck mechanism to unsupervised settings. The aim is to obtain a more comprehensive and robust multimodal representation by minimizing noise interference within single-modal raw feature spaces while preserving the original information as much as possible. Finally, in the multiscale normalizing flow stage, the structure uses parallel flows to capture feature information at different scales. Through the fusion of these flows, interactions between features at various scales are realized. Additionally, an innovative approach for anomaly scoring is employed, wherein the average of the Top-K values in the anomaly score map replaces traditional methods such as those that use the mean or maximum values. This approach yields the final defect detection results.ResultThe proposed method is evaluated on the MVTec-3D AD dataset. This dataset is meticulously curated, encompassing 10 distinct categories of industrial products, with a comprehensive collection of 2 656 training samples and 1 137 testing samples. Each category is meticulously segmented into subclasses, delineated by the nature of the defects. The proposed method was experimentally validated, and the results demonstrated its exceptional performance. An AUCROC of 93.3%, a segmentation AUPRO of 96.1%, and a segmentation AUCROC of 98.8% were achieved. These metrics not only reflect the method’s effectiveness but also have advantages over the majority of existing multimodal defect detection methodologies. Moreover, visualizations were conducted on selected samples, comparing the detection outcomes using only RGB images against those utilizing RGB images in conjunction with 3D point clouds. The latter combination has revealed defects that remain elusive when relying solely on RGB imagery. This empirical evidence firmly establishes the advantage of integrating data from both modalities, as posited in the hypothesis of this study. The ablation studies conducted provide additional insights into the efficacy of the proposed method. The introduction of an information bottleneck resulted in incremental improvements across all three metrics: 1.4% in the detection AUCROC, 2.1% in the segmentation AUPRO, and 3.5% in the segmentation AUCROC. The integration of a multiscale normalizing flow further enhanced the performance, with gains of 2.5%, 3.6%, and 1.6% across the respective metrics. These findings are indicative of the substantial contributions of both the information bottleneck and the multiscale normalizing flow to the overall performance of the defect detection framework used in this work.ConclusionThe main contributions of this study are as follows: unsupervised feature fusion was employed to encourage information exchange between different modalities. An information bottleneck was introduced into the feature fusion module to mitigate the impact of noise in the original feature space of single modalities on multimodal interaction. Additionally, multimodal representations were utilized at different levels to construct feature pyramids, addressing the issue of the poor performance of previous flow-based methods in handling defects of varying scales. The proposed method demonstrates promising detection performance across defects of diverse shapes and sizes, including those with low perceptibility on RGB images. When the impact of noise within the original feature space on the multimodal representation is mitigated, the proposed approach can not only improve the robustness of the method but also enhance its ability to generalize the defects of varying characteristics. This approach effectively aligns with the stringent demands of modern industry for accurate and reliable defect detection methodologies.关键词:multimodal and multi-scale industrial scene;anomaly detection;unsupervised feature fusion(UFF);pretext task;normalizing flow94|125|0更新时间:2025-04-11 - “在桥梁缆索和隧道病害检测领域,专家提出了基于融合注意力及增强感受野的深度网络模型,有效提升了病害提取精度和抗干扰能力。”
 摘要:ObjectiveUsing computer image technology to identify defects in bridge cables and tunnel linings is an efficient and convenient method. Surface defect detection on bridge cables and tunnel linings faces multiple challenges: high costs of manual defect localization in complex structures. Insufficient tunnel lighting, complex defect features, and imbalanced target-background ratios often present apparent shortcomings in traditional image technology for defect area detection, such as poor anti-interference ability, low recognition rates, and subpar segmentation effects. Therefore, this study proposes a deep network model based on the fusion attention and enhanced receptive field.MethodThe model employs a backbone network integrating a fused Transformer to extract target feature information and establish a more closely related global texture feature representation, which solves the problem of a lack of local features caused by insufficient lighting. Additionally, spatial reduction attention is introduced to reduce the parameter count of the backbone. The series-parallel atrous convolutional pyramid (SACP) module was introduced to further expand the convolutional receptive field and integrate it, thereby enhancing the perception of the complete defect scope with multiscale characteristics. The decoder uses a concentration-based attention module(CBAM) to strengthen the effective boundary feature weights of shallow features and suppress some occluded features, which sharpens the segmentation results. The model employs a composite loss function that combines cross-entropy loss and Dice loss to balance the contributions of positive and negative samples. Datasets for experimentation were constructed via the onsite collection of tunnel lining defect images and bridge cable climbing robot-acquired cable defect images.ResultThe results demonstrate the following: 1) the proposed multitransformer backbone reduces computational complexity while maintaining feature extraction capabilities. 2) The optimized SACP module improves the segmentation accuracy by 2%, and the use of depthwise separable convolution effectively reduces the complexity. 3) Owing to the use of an improved composite loss function, the convergence speed of the network has accelerated. 4) The proposed network model achieves an accuracy of 94.4%, a mean intersection over union of 78.14%, and an F1 score of 76.45% for the tunnel lining dataset. The generalization ability of the proposed model was also demonstrated in the bridge cable dataset.ConclusionCompared with mainstream segmentation networks, the proposed model improves the accuracy of bridge cable and tunnel lining defect detection, demonstrating enhanced extraction efficacy and anti-interference capability. Therefore, this model can better meet the engineering requirements for defect detection in complex environments.关键词:deep learning;attention mechanism;convolution receptive field;image analysis;automated defect detection;structure surface defect recognition67|101|0更新时间:2025-04-11
摘要:ObjectiveUsing computer image technology to identify defects in bridge cables and tunnel linings is an efficient and convenient method. Surface defect detection on bridge cables and tunnel linings faces multiple challenges: high costs of manual defect localization in complex structures. Insufficient tunnel lighting, complex defect features, and imbalanced target-background ratios often present apparent shortcomings in traditional image technology for defect area detection, such as poor anti-interference ability, low recognition rates, and subpar segmentation effects. Therefore, this study proposes a deep network model based on the fusion attention and enhanced receptive field.MethodThe model employs a backbone network integrating a fused Transformer to extract target feature information and establish a more closely related global texture feature representation, which solves the problem of a lack of local features caused by insufficient lighting. Additionally, spatial reduction attention is introduced to reduce the parameter count of the backbone. The series-parallel atrous convolutional pyramid (SACP) module was introduced to further expand the convolutional receptive field and integrate it, thereby enhancing the perception of the complete defect scope with multiscale characteristics. The decoder uses a concentration-based attention module(CBAM) to strengthen the effective boundary feature weights of shallow features and suppress some occluded features, which sharpens the segmentation results. The model employs a composite loss function that combines cross-entropy loss and Dice loss to balance the contributions of positive and negative samples. Datasets for experimentation were constructed via the onsite collection of tunnel lining defect images and bridge cable climbing robot-acquired cable defect images.ResultThe results demonstrate the following: 1) the proposed multitransformer backbone reduces computational complexity while maintaining feature extraction capabilities. 2) The optimized SACP module improves the segmentation accuracy by 2%, and the use of depthwise separable convolution effectively reduces the complexity. 3) Owing to the use of an improved composite loss function, the convergence speed of the network has accelerated. 4) The proposed network model achieves an accuracy of 94.4%, a mean intersection over union of 78.14%, and an F1 score of 76.45% for the tunnel lining dataset. The generalization ability of the proposed model was also demonstrated in the bridge cable dataset.ConclusionCompared with mainstream segmentation networks, the proposed model improves the accuracy of bridge cable and tunnel lining defect detection, demonstrating enhanced extraction efficacy and anti-interference capability. Therefore, this model can better meet the engineering requirements for defect detection in complex environments.关键词:deep learning;attention mechanism;convolution receptive field;image analysis;automated defect detection;structure surface defect recognition67|101|0更新时间:2025-04-11
Image Analysis and Recognition
- “在目标跟踪领域,研究者提出了LinDATrack算法,有效降低边缘端计算量和延迟,为边缘计算目标跟踪提供新方案。”
 摘要:ObjectiveThe transfer and deployment of tracking algorithms designed for server ends to edge ends has high practical value. This transformation leads to a remarkable decrease in energy consumption, particularly in situations where resources are limited. In recent years, tracking algorithms that incorporate the Transformer architecture have achieved considerable progress because of their superior performance. Nonetheless, the adaptation of these algorithms for edge computing often encounters difficulties, primarily because of the increased latency. This latency is attributed to the complex nature of the Transformer’s attention mechanism, which requires extensive computational resources. This issue is addressed by introducing an innovative solution called the linearly decomposed attention (LinDA) module, which is designed expressly for edge computing. By drastically lowering the computational demands and reducing the inference time of the Transformer, the LinDA module facilitates more effective and efficient tracking at the edge end.MethodLinDA innovatively approximates the multihead attention mechanism as two components: a data-dependent component and a data-independent component. For the data-dependent aspect, LinDA adopts a computationally economic approach. Rather than relying on traditional, resource-intensive methods of transposition and matrix multiplication, LinDA employs direct elementwise multiplication and the addition of vectors. This method markedly reduces computational complexity, rendering it exceptionally well suited for edge computing environments where resources are scarce. Regarding the data-independent facet, LinDA integrates a statistically derived attention matrix that encapsulates global contextual insights. This matrix is further refined with a learnable bias vector, enhancing the model’s adaptability and versatility. This decomposition strategy empowers LinDA to achieve good precision and considerable efficiency on devices constrained by limited resources. An advanced knowledge distillation strategy, which plays a crucial role in bolstering the student model’s capabilities, is introduced to mitigate potential compromises in accuracy because of the linear decomposition approach. This strategy encompasses two specialized distillation losses integrated into the baseline loss function, each meticulously designed to capture and convey critical insights from the teacher model to the student model. First, the hard label knowledge distillation technique involves replacing the ground-truth bounding box with the bounding box predicted by the teacher model, which serves as the supervision target for the student model. This method allows the student model to learn directly from the teacher’s discernment, thereby enhancing its predictive precision. Consequently, the student model captures the teacher’s knowledge of the problem, which enables it to yield more accurate predictions. Second, the relation matching knowledge distillation strategy harnesses the relationship between the teacher model’s predictions as the supervisory target. This innovative approach captures the complex relationships among different predictions, such as the relative significance of distinct objects or their spatial interrelations. When this relational knowledge is embedded into the student model during training, the model’s performance can be further improved, rendering it more robust and powerful. In summary, this elaborate knowledge distillation framework successfully imparts the teacher model’s insights into the student model, effectively overcoming the potential precision degradation associated with linear decomposition. This scheme ensures that the student model inherits the teacher’s expertise, thereby enabling it to deliver more precise predictions and attain superior performance. This study further implements an edge-end-oriented object tracking algorithm called LinDATrack, which is based on LinDA and distillation. The algorithm is deployed on the domestic edge computing host HS240.ResultComprehensive experiments of the tracker are conducted across various public datasets to test its performance and capability metrics. The experimental results validate the system’s outstanding tracking speed and good precision. With this computing host, LinDATrack achieves an impressive tracking speed of approximately 62 frames per second, facilitating efficient tracking in real-time settings. Furthermore, the system operates with a power consumption of approximately 79.5 watts, which represents only 6.2% of the energy used by the server-end configurations. This dramatic reduction in energy usage underscores the system’s exceptional energy efficiency, positioning it as an ideal choice for deployment in settings with limited resources. In an era where energy conservation and sustainability are increasingly important, this system presents a compelling alternative to more energy-intensive options, contributing significantly to a more sustainable computing landscape. In addition to its remarkable tracking speed and low power consumption, the system also exhibits consistently high tracking accuracy, distinguishing it within the realm of object tracking. Compared with the server-end baseline algorithm SwinTrack-T, the system’s tracking accuracy, as determined by the success rate metric, shows only a slight decrease of approximately 1.8%. This minor decrease in accuracy reflects the system’s capacity to balance performance with efficiency. The scheme can maintain precise tracking functionality while reducing resource usage, rendering it a versatile solution for a broad spectrum of tracking applications.ConclusionLinDATrack is distinguished by its exceptional balance of speed and accuracy, positioning it as a premier option for object tracking applications. Its performance is marked by efficiency, facilitating real-time tracking that users can rely on. Additionally, LinDATrack demonstrates considerable strengths when deployed at the edge, making it exceptionally well suited for environments with limited resources. This combination of speed, accuracy, and edge-oriented advantages firmly establishes LinDATrack as a leading solution for edge-end tracking tasks.关键词:object tracking;edge end;Transformer;multi-head attention(MHA);knowledge distillation70|138|0更新时间:2025-04-11
摘要:ObjectiveThe transfer and deployment of tracking algorithms designed for server ends to edge ends has high practical value. This transformation leads to a remarkable decrease in energy consumption, particularly in situations where resources are limited. In recent years, tracking algorithms that incorporate the Transformer architecture have achieved considerable progress because of their superior performance. Nonetheless, the adaptation of these algorithms for edge computing often encounters difficulties, primarily because of the increased latency. This latency is attributed to the complex nature of the Transformer’s attention mechanism, which requires extensive computational resources. This issue is addressed by introducing an innovative solution called the linearly decomposed attention (LinDA) module, which is designed expressly for edge computing. By drastically lowering the computational demands and reducing the inference time of the Transformer, the LinDA module facilitates more effective and efficient tracking at the edge end.MethodLinDA innovatively approximates the multihead attention mechanism as two components: a data-dependent component and a data-independent component. For the data-dependent aspect, LinDA adopts a computationally economic approach. Rather than relying on traditional, resource-intensive methods of transposition and matrix multiplication, LinDA employs direct elementwise multiplication and the addition of vectors. This method markedly reduces computational complexity, rendering it exceptionally well suited for edge computing environments where resources are scarce. Regarding the data-independent facet, LinDA integrates a statistically derived attention matrix that encapsulates global contextual insights. This matrix is further refined with a learnable bias vector, enhancing the model’s adaptability and versatility. This decomposition strategy empowers LinDA to achieve good precision and considerable efficiency on devices constrained by limited resources. An advanced knowledge distillation strategy, which plays a crucial role in bolstering the student model’s capabilities, is introduced to mitigate potential compromises in accuracy because of the linear decomposition approach. This strategy encompasses two specialized distillation losses integrated into the baseline loss function, each meticulously designed to capture and convey critical insights from the teacher model to the student model. First, the hard label knowledge distillation technique involves replacing the ground-truth bounding box with the bounding box predicted by the teacher model, which serves as the supervision target for the student model. This method allows the student model to learn directly from the teacher’s discernment, thereby enhancing its predictive precision. Consequently, the student model captures the teacher’s knowledge of the problem, which enables it to yield more accurate predictions. Second, the relation matching knowledge distillation strategy harnesses the relationship between the teacher model’s predictions as the supervisory target. This innovative approach captures the complex relationships among different predictions, such as the relative significance of distinct objects or their spatial interrelations. When this relational knowledge is embedded into the student model during training, the model’s performance can be further improved, rendering it more robust and powerful. In summary, this elaborate knowledge distillation framework successfully imparts the teacher model’s insights into the student model, effectively overcoming the potential precision degradation associated with linear decomposition. This scheme ensures that the student model inherits the teacher’s expertise, thereby enabling it to deliver more precise predictions and attain superior performance. This study further implements an edge-end-oriented object tracking algorithm called LinDATrack, which is based on LinDA and distillation. The algorithm is deployed on the domestic edge computing host HS240.ResultComprehensive experiments of the tracker are conducted across various public datasets to test its performance and capability metrics. The experimental results validate the system’s outstanding tracking speed and good precision. With this computing host, LinDATrack achieves an impressive tracking speed of approximately 62 frames per second, facilitating efficient tracking in real-time settings. Furthermore, the system operates with a power consumption of approximately 79.5 watts, which represents only 6.2% of the energy used by the server-end configurations. This dramatic reduction in energy usage underscores the system’s exceptional energy efficiency, positioning it as an ideal choice for deployment in settings with limited resources. In an era where energy conservation and sustainability are increasingly important, this system presents a compelling alternative to more energy-intensive options, contributing significantly to a more sustainable computing landscape. In addition to its remarkable tracking speed and low power consumption, the system also exhibits consistently high tracking accuracy, distinguishing it within the realm of object tracking. Compared with the server-end baseline algorithm SwinTrack-T, the system’s tracking accuracy, as determined by the success rate metric, shows only a slight decrease of approximately 1.8%. This minor decrease in accuracy reflects the system’s capacity to balance performance with efficiency. The scheme can maintain precise tracking functionality while reducing resource usage, rendering it a versatile solution for a broad spectrum of tracking applications.ConclusionLinDATrack is distinguished by its exceptional balance of speed and accuracy, positioning it as a premier option for object tracking applications. Its performance is marked by efficiency, facilitating real-time tracking that users can rely on. Additionally, LinDATrack demonstrates considerable strengths when deployed at the edge, making it exceptionally well suited for environments with limited resources. This combination of speed, accuracy, and edge-oriented advantages firmly establishes LinDATrack as a leading solution for edge-end tracking tasks.关键词:object tracking;edge end;Transformer;multi-head attention(MHA);knowledge distillation70|138|0更新时间:2025-04-11 - “DDAPs技术通过双模态提示学习微调CLIP模型,提升了域适应任务性能,为解决域差异问题提供新方案。”
 摘要:ObjectiveDomain adaptation aims to utilize information from a labeled source domain to assist tasks in the unlabeled target domain. Recently, contrastive language-image pre-training (CLIP) has demonstrated impressive generalization capabilities in classification downstream tasks. Some methods have incorporated CLIP into domain adaptation, enhancing the model’s generalization ability in the target domain. However, current domain adaptation methods based on CLIP typically adjust only the features of the textual modality, leaving the visual modality features unchanged. These existing methods overlook the importance of enhancing the discriminative capability of image features during classification and neglect the synergistic role of the visual modality in eliminating domain discrepancy. This issue is addressed by introducing a domain adaptation method for the image classification task guided by dual-modality domain-agnostic prompts (DDAPs).MethodDDAPs introduces dual-modality prompt learning, simultaneously fine-tunes textual and visual features, and collaboratively addresses domain discrepancies. The key modules of DDAPs are the domain-agnostic textual prompt module and the domain-agnostic visual prompt module. The former employs textual prompt learning techniques to fine-tune the text encoder, fostering domain-agnostic and discriminative text features across domains. DDAPs adopts task-level text prompt learning, sharing the textual prompt module across various domains and categories. Similarly, the domain-agnostic visual prompt module uses visual prompt learning techniques to enhance the image encoder, cultivating domain-agnostic and discriminative image features. Task-level visual prompt learning is employed, ensuring that the visual prompt module is shared across diverse domains and samples. The added DDAPs were learned via classification loss and alignment loss to fine-tune the model. On the one hand, as the original pre-training task for CLIP involves matching paired images and text, it needs to learn more discriminative text and image features specific to the current downstream classification task. Therefore, DDAPs uses classification loss to train the added dual-modality domain-invariant prompt modules, enhancing the discriminative power of the features. For the source domain, the classification loss can directly use the existing labels, whereas for the target domain, the classification loss can use the collected pseudo labels. On the other hand, given the considerable visual differences between the images of the two domains, the extracted image representations contain domain-specific features. The target domain is encouraged to fully utilize the beneficial information from the source domain. Therefore, the maximum mean discrepancy loss of DDAPs is used to align the image feature distributions of the source and target domains, and domain-invariant and image features are learned. In image feature distribution alignment, the fusion results of image features and classification probabilities are aligned to enhance the discriminative capability of the aligned features and reduce incorrect category matching between the source and target domains.ResultThe experiments encompass three datasets: Office-Home, VisDa-2017, and Office-31. During training, all weights of the CLIP pre-trained model remain fixed, with only the weights of the newly added domain-invariant textual and visual prompt learning modules being updated. Experiments on single-source domain adaptation were conducted across these three datasets to assess DDAPs against existing methods. Average classification accuracies of 87.1%, 89.6%, and 91.6% were obtained, indicating current state-of-the-art performance. Additionally, the versatility of DDAPs extended to multi-source domain adaptation, where it achieved an average classification accuracy of 88.6% on the Office-Home dataset. Ablation studies on the Office-Home dataset further confirm the importance of the domain-agnostic text prompt module and the domain-agnostic visual prompt module. Notably, the comprehensive version of DDAPs exceled, surpassing the performance of individually added single-modality prompt modules, and showed a 5% improvement over the CLIP pre-trained model. This situation underscores the effectiveness of employing dual-modality domain-agnostic prompts to collectively mitigate domain discrepancy. Moreover, experiments explored the sensitivity of hyperparameters. In the proposed DDAPs method, the primary hyperparameters include the weight of the alignment loss and the lengths of the prompt vectors. The findings reveal that when the weight of the alignment loss approaches its optimal value, the performance of the target domain remains stable. Similarly, variations in the lengths of prompt vectors do not significantly affect DDAPs performance. For a more intuitive grasp of DDAP, this study also employs t-distributed stochastic neighbor embedding to visualize the image features of different models, and the visualization demonstrates the superiority of DDAPs in addressing domain adaptation problems.ConclusionThis study introduces a domain adaptation method called DDAPs for image classification tasks. DDAPs uses domain-invariant textual and visual prompts to eliminate domain discrepancies between the source and target domains collaboratively and learns domain-invariant and discriminative images and text features to enhance model performance in the target domain. DDAPs can be applied to both single-source domain adaptation and multi-source domain adaptation. The proposed DDAPs has been experimentally validated across multiple datasets, achieving state-of-the-art results and demonstrating the significance of collaborative handling of domain discrepancy from a dual-modality perspective.关键词:single-source domain adaptation;multi-source domain adaptation;domain adaptation;transfer learning;dual-modality prompt learning64|83|0更新时间:2025-04-11
摘要:ObjectiveDomain adaptation aims to utilize information from a labeled source domain to assist tasks in the unlabeled target domain. Recently, contrastive language-image pre-training (CLIP) has demonstrated impressive generalization capabilities in classification downstream tasks. Some methods have incorporated CLIP into domain adaptation, enhancing the model’s generalization ability in the target domain. However, current domain adaptation methods based on CLIP typically adjust only the features of the textual modality, leaving the visual modality features unchanged. These existing methods overlook the importance of enhancing the discriminative capability of image features during classification and neglect the synergistic role of the visual modality in eliminating domain discrepancy. This issue is addressed by introducing a domain adaptation method for the image classification task guided by dual-modality domain-agnostic prompts (DDAPs).MethodDDAPs introduces dual-modality prompt learning, simultaneously fine-tunes textual and visual features, and collaboratively addresses domain discrepancies. The key modules of DDAPs are the domain-agnostic textual prompt module and the domain-agnostic visual prompt module. The former employs textual prompt learning techniques to fine-tune the text encoder, fostering domain-agnostic and discriminative text features across domains. DDAPs adopts task-level text prompt learning, sharing the textual prompt module across various domains and categories. Similarly, the domain-agnostic visual prompt module uses visual prompt learning techniques to enhance the image encoder, cultivating domain-agnostic and discriminative image features. Task-level visual prompt learning is employed, ensuring that the visual prompt module is shared across diverse domains and samples. The added DDAPs were learned via classification loss and alignment loss to fine-tune the model. On the one hand, as the original pre-training task for CLIP involves matching paired images and text, it needs to learn more discriminative text and image features specific to the current downstream classification task. Therefore, DDAPs uses classification loss to train the added dual-modality domain-invariant prompt modules, enhancing the discriminative power of the features. For the source domain, the classification loss can directly use the existing labels, whereas for the target domain, the classification loss can use the collected pseudo labels. On the other hand, given the considerable visual differences between the images of the two domains, the extracted image representations contain domain-specific features. The target domain is encouraged to fully utilize the beneficial information from the source domain. Therefore, the maximum mean discrepancy loss of DDAPs is used to align the image feature distributions of the source and target domains, and domain-invariant and image features are learned. In image feature distribution alignment, the fusion results of image features and classification probabilities are aligned to enhance the discriminative capability of the aligned features and reduce incorrect category matching between the source and target domains.ResultThe experiments encompass three datasets: Office-Home, VisDa-2017, and Office-31. During training, all weights of the CLIP pre-trained model remain fixed, with only the weights of the newly added domain-invariant textual and visual prompt learning modules being updated. Experiments on single-source domain adaptation were conducted across these three datasets to assess DDAPs against existing methods. Average classification accuracies of 87.1%, 89.6%, and 91.6% were obtained, indicating current state-of-the-art performance. Additionally, the versatility of DDAPs extended to multi-source domain adaptation, where it achieved an average classification accuracy of 88.6% on the Office-Home dataset. Ablation studies on the Office-Home dataset further confirm the importance of the domain-agnostic text prompt module and the domain-agnostic visual prompt module. Notably, the comprehensive version of DDAPs exceled, surpassing the performance of individually added single-modality prompt modules, and showed a 5% improvement over the CLIP pre-trained model. This situation underscores the effectiveness of employing dual-modality domain-agnostic prompts to collectively mitigate domain discrepancy. Moreover, experiments explored the sensitivity of hyperparameters. In the proposed DDAPs method, the primary hyperparameters include the weight of the alignment loss and the lengths of the prompt vectors. The findings reveal that when the weight of the alignment loss approaches its optimal value, the performance of the target domain remains stable. Similarly, variations in the lengths of prompt vectors do not significantly affect DDAPs performance. For a more intuitive grasp of DDAP, this study also employs t-distributed stochastic neighbor embedding to visualize the image features of different models, and the visualization demonstrates the superiority of DDAPs in addressing domain adaptation problems.ConclusionThis study introduces a domain adaptation method called DDAPs for image classification tasks. DDAPs uses domain-invariant textual and visual prompts to eliminate domain discrepancies between the source and target domains collaboratively and learns domain-invariant and discriminative images and text features to enhance model performance in the target domain. DDAPs can be applied to both single-source domain adaptation and multi-source domain adaptation. The proposed DDAPs has been experimentally validated across multiple datasets, achieving state-of-the-art results and demonstrating the significance of collaborative handling of domain discrepancy from a dual-modality perspective.关键词:single-source domain adaptation;multi-source domain adaptation;domain adaptation;transfer learning;dual-modality prompt learning64|83|0更新时间:2025-04-11 - “UEDA网络通过不确定性增强提升跨域图像分类能力,为少样本学习领域提供新解决方案。”
 摘要:ObjectiveInspired by the fast learning properties of humans and transfer learning, researchers have proposed a new machine learning paradigm——few-shot learning. The purpose of few-shot learning is to enable models to quickly learn new knowledge or concepts from a limited amount of labeled data that can be used in unknown categories. Currently, few-shot image classification is based on the framework of meta-learning, which divides the model learning process into a meta-training phase and a meta-testing phase. Existing solutions can be broadly classified according to the following differences in concepts: 1) optimization-based methods, the basic idea of which is to allow the model to find the parameters that can optimize performance under the training of multiple sets of task data; 2) metric learning-based methods, whose core idea is to construct an optimal embedding space for measuring distances so that the distance between similar samples is as small as possible; and 3) data manipulation-based methods, which use some basic data augmentation (e.g., rotating, clipping, and adding noise) to increase the diversity of the training samples and the amount of data in these three main categories. However, these works tend to follow strict assumptions, such as the smoothness assumption, clustering assumption, and prevalence assumption, and require that the training data and test data come from the same distribution. This situation makes it difficult to ensure data from the same distribution setting during the training process of the model in certain real-world scenarios, such as medical imaging, military applications, and finance, where issues such as difficulty in data access and data privacy make it challenging to use labeled data from other domains to provide a priori knowledge. Here, an uncertainty enhancement-based domain-awareness network(UEDA) is proposed to alleviate the problem of domain distribution bias encountered in the learning process of the few-shot model.MethodThe uncertainty enhancement-based domain-awareness approach explores and extracts key knowledge from the feature channel perspective, which can be used to mitigate domain bias. An uncertainty feature augmentation approach is first proposed, where the feature channel contains both domain-relevant and domain-independent information, suggesting that the generalized learning of the model may be correlated with the feature channel’s ability to extract domain-generalized knowledge. However, most of these works consider feature statistics to be deterministic and use additive perturbations (i.e., swapping and interpolation) to achieve augmentation, practices that may lead to models that are negatively affected by voluminous domain-specific information. The uncertainty enhancement approach models the uncertainty distribution by defining the feature sufficient statistics fixed value as a probabilistic representation of uncertainty obeying a Gaussian distribution with the source feature sufficient statistic as the center of the distribution and the standard deviation defined as being the potential range of variation of the probability. The new features generated by the uncertainty enhancement method can be effectively distinguished from the source domain features. The second part of the UEDA is a domain-awareness approach. In the domain-aware module, source and generated features are considered information from different domains and ensure that both features are within a reasonable challenging offset by maximizing the interdomain differences. A domain discriminator is also introduced to compute the correlation between each channel, and the domain information is used as a way to extract effective generalizable knowledge.ResultThe cross-domain generalization performance of the proposed method was evaluated on five datasets, namely, Mini-ImageNet, CUB, Plantae, Cropdiseases, and EuroSAT. The experiments follow single-domain generalization, use the Mini-ImageNet dataset as the source domain and the latter four datasets as the target domains. Then, the initial findings are compared with current mainstream methods under three classification frameworks, namely, MatchingNet, RelationNet, and the GNN. The subsequent experiments follow 5-way 1-shot and 5-way 5-shot settings on the CUB, Plantae, EuroSAT, and Cropdiseases datasets, and the accuracies of the proposed UEDA are 41.01%, 58.78%, 38.07% and 51.36%, respectively; under the MatchingNet classifier, 58.37%, 80.45%, 59.48%, and 69.91%; and under the GNN classifier, the accuracies of the UEDA are 49.36%, 69.65%, 38.48%, 56.49%, 68.98%, 89.11%, 64.87% and 85.29%, respectively. Comparative experimental results demonstrate that the proposed UEDA method can effectively improve the cross-domain generalizability of the model. Furthermore, ablation experiments were conducted to validate the effectiveness of the modules of the proposed methodology, and the results show that the modules are mutually reinforcing and indispensable in the overall methodology.ConclusionThe uncertainty enhancement-based domain-awareness network proposed in this study allows the model to adapt to various domain offsets during the training phase and learn effective generalizable knowledge from them, thus improving cross-domain image classification with fewer samples.关键词:image classification;cross-domain few-shot image classification;few-shot learning(FSL);domain generalization;deep learning56|101|0更新时间:2025-04-11
摘要:ObjectiveInspired by the fast learning properties of humans and transfer learning, researchers have proposed a new machine learning paradigm——few-shot learning. The purpose of few-shot learning is to enable models to quickly learn new knowledge or concepts from a limited amount of labeled data that can be used in unknown categories. Currently, few-shot image classification is based on the framework of meta-learning, which divides the model learning process into a meta-training phase and a meta-testing phase. Existing solutions can be broadly classified according to the following differences in concepts: 1) optimization-based methods, the basic idea of which is to allow the model to find the parameters that can optimize performance under the training of multiple sets of task data; 2) metric learning-based methods, whose core idea is to construct an optimal embedding space for measuring distances so that the distance between similar samples is as small as possible; and 3) data manipulation-based methods, which use some basic data augmentation (e.g., rotating, clipping, and adding noise) to increase the diversity of the training samples and the amount of data in these three main categories. However, these works tend to follow strict assumptions, such as the smoothness assumption, clustering assumption, and prevalence assumption, and require that the training data and test data come from the same distribution. This situation makes it difficult to ensure data from the same distribution setting during the training process of the model in certain real-world scenarios, such as medical imaging, military applications, and finance, where issues such as difficulty in data access and data privacy make it challenging to use labeled data from other domains to provide a priori knowledge. Here, an uncertainty enhancement-based domain-awareness network(UEDA) is proposed to alleviate the problem of domain distribution bias encountered in the learning process of the few-shot model.MethodThe uncertainty enhancement-based domain-awareness approach explores and extracts key knowledge from the feature channel perspective, which can be used to mitigate domain bias. An uncertainty feature augmentation approach is first proposed, where the feature channel contains both domain-relevant and domain-independent information, suggesting that the generalized learning of the model may be correlated with the feature channel’s ability to extract domain-generalized knowledge. However, most of these works consider feature statistics to be deterministic and use additive perturbations (i.e., swapping and interpolation) to achieve augmentation, practices that may lead to models that are negatively affected by voluminous domain-specific information. The uncertainty enhancement approach models the uncertainty distribution by defining the feature sufficient statistics fixed value as a probabilistic representation of uncertainty obeying a Gaussian distribution with the source feature sufficient statistic as the center of the distribution and the standard deviation defined as being the potential range of variation of the probability. The new features generated by the uncertainty enhancement method can be effectively distinguished from the source domain features. The second part of the UEDA is a domain-awareness approach. In the domain-aware module, source and generated features are considered information from different domains and ensure that both features are within a reasonable challenging offset by maximizing the interdomain differences. A domain discriminator is also introduced to compute the correlation between each channel, and the domain information is used as a way to extract effective generalizable knowledge.ResultThe cross-domain generalization performance of the proposed method was evaluated on five datasets, namely, Mini-ImageNet, CUB, Plantae, Cropdiseases, and EuroSAT. The experiments follow single-domain generalization, use the Mini-ImageNet dataset as the source domain and the latter four datasets as the target domains. Then, the initial findings are compared with current mainstream methods under three classification frameworks, namely, MatchingNet, RelationNet, and the GNN. The subsequent experiments follow 5-way 1-shot and 5-way 5-shot settings on the CUB, Plantae, EuroSAT, and Cropdiseases datasets, and the accuracies of the proposed UEDA are 41.01%, 58.78%, 38.07% and 51.36%, respectively; under the MatchingNet classifier, 58.37%, 80.45%, 59.48%, and 69.91%; and under the GNN classifier, the accuracies of the UEDA are 49.36%, 69.65%, 38.48%, 56.49%, 68.98%, 89.11%, 64.87% and 85.29%, respectively. Comparative experimental results demonstrate that the proposed UEDA method can effectively improve the cross-domain generalizability of the model. Furthermore, ablation experiments were conducted to validate the effectiveness of the modules of the proposed methodology, and the results show that the modules are mutually reinforcing and indispensable in the overall methodology.ConclusionThe uncertainty enhancement-based domain-awareness network proposed in this study allows the model to adapt to various domain offsets during the training phase and learn effective generalizable knowledge from them, thus improving cross-domain image classification with fewer samples.关键词:image classification;cross-domain few-shot image classification;few-shot learning(FSL);domain generalization;deep learning56|101|0更新时间:2025-04-11 - “在图像修复领域,研究者提出了一种基于语义解耦前景背景的图像修复方法,有效减少了语义混乱和边界模糊的影响,修复后生成的图像前景背景边界清晰,颜色风格和谐,语义连贯。”
 摘要:ObjectiveImage inpainting is a technique that infers and repairs damaged or missing regions of an image on the basis of the known content of the image. It originated from artists restoring damaged paintings or photographs to restore their quality as close as possible to the original image. This technique has been widely applied in fields such as cultural heritage preservation, image editing, and medical image processing. The development of image inpainting technology has undergone a transition from traditional methods to modern methods. Traditional methods are typically good at handling small areas of simple structured image textures, but they often fail to achieve satisfactory results when faced with large missing areas and complex structural and textual information. With the rise of the big data era, deep learning methods such as generative adversarial networks have rapidly developed, substantially improving the effectiveness of image inpainting. Compared with traditional image inpainting algorithms, deep learning methods can better understand the semantic information of images, improving the accuracy and efficiency of repair. Deep learning models can fully understand the semantic information of images and generate highly accurate repair results when a large amount of data is learned. However, current methods usually treat images as a whole for repair. From a semantic perspective, the foreground and background have significant differences. Treating the foreground and background may lead to problems such as blurred edges and structural deformation, resulting in unsatisfactory results. This issue is addressed by adopting a new image inpainting framework that uses semantic label maps to separate the foreground and background for repair.MethodThe image inpainting method includes three modules: a semantic inpainting module, a foreground inpainting module, and an overall inpainting module. The purpose of the semantic repair module is to repair the defective semantic map to guide the subsequent semantic decoupling of the foreground and background areas. In the semantic repair phase, the missing semantic tag graph can be repaired, and the semantic information of the missing region can be enhanced. Then, the foreground mask is extracted via the repaired semantic map to obtain the accurate boundary and shape information of the foreground region. In the foreground restoration stage, the foreground region of the defect image is extracted on the basis of the foreground mask, and then the foreground restoration module is used to restore the texture and fill the missing region. The foreground area usually contains the key information in the image. Highly accurate and detailed foreground objects and their semantic information can be obtained when the foreground is repaired. The restored foreground region is subsequently embedded into the missing image. Finally, the missing image with foreground restoration completed is input to the overall repair module, which completes the two tasks of repairing the background region of the missing image and foreground–background fusion. The overall inpainting module repairs the entire image on the basis of the context information of the foreground, maintaining the consistency and smoothness of the image and further improving the inpainting effect of the foreground region. A joint loss function was employed for the three stages of image inpainting. The semantic inpainting module uses adversarial loss and semantic distribution loss to further improve the accuracy of semantic inpainting. The foreground inpainting and overall inpainting modules further incorporate perceptual loss, style loss, and global loss in addition to the losses. In particular, perceptual loss is used to ensure that the restoration results closely resemble the original image in terms of perception; style loss is used to reduce the occurrence of checkerboard artifacts caused by transposed convolution layers; and global loss is used to guarantee that the restored results exhibit a more coherent structure and content across the entire image. When these different types of loss functions are utilized, the proposed method can generate more realistic and natural images while maintaining high-quality inpainting results.ResultComparative experiments with other current image restoration methods demonstrated that the proposed approach outperforms other methods in terms of learned perceptual image patch similarity, the peak signal-to-noise ratio, and the structural similarity index on the CelebA-HQ and Cityscapes public datasets. Compared with the best average values of the baseline methods, on the CelebA-HQ dataset, the learned perceptual image patch similarity decreased by 8.86%, the structure similarity index measure (SSIM) improved by 1.1%, and the average peak signal-to-noise ratio(PSNR) was 27.09 dB. For the Cityscapes dataset, the LPIPS decreased by 4.62%, the SSIM improved by 0.45%, and the average PSNR was 27.31 dB. Furthermore, ablation experiments confirm the necessity and effectiveness of each component in the algorithm used in this study.ConclusionThis image inpainting method decouples the semantics of the foreground and background and uses a three-stage algorithm process to complete the image inpainting step by step, which effectively reduces the impact of semantic confusion and fuzzy boundaries. The foreground and background boundaries of the repaired image are clear, and the color style is more reasonable.关键词:image inpainting;semantic repair;priori knowledge;foreground-background decoupling56|116|0更新时间:2025-04-11
摘要:ObjectiveImage inpainting is a technique that infers and repairs damaged or missing regions of an image on the basis of the known content of the image. It originated from artists restoring damaged paintings or photographs to restore their quality as close as possible to the original image. This technique has been widely applied in fields such as cultural heritage preservation, image editing, and medical image processing. The development of image inpainting technology has undergone a transition from traditional methods to modern methods. Traditional methods are typically good at handling small areas of simple structured image textures, but they often fail to achieve satisfactory results when faced with large missing areas and complex structural and textual information. With the rise of the big data era, deep learning methods such as generative adversarial networks have rapidly developed, substantially improving the effectiveness of image inpainting. Compared with traditional image inpainting algorithms, deep learning methods can better understand the semantic information of images, improving the accuracy and efficiency of repair. Deep learning models can fully understand the semantic information of images and generate highly accurate repair results when a large amount of data is learned. However, current methods usually treat images as a whole for repair. From a semantic perspective, the foreground and background have significant differences. Treating the foreground and background may lead to problems such as blurred edges and structural deformation, resulting in unsatisfactory results. This issue is addressed by adopting a new image inpainting framework that uses semantic label maps to separate the foreground and background for repair.MethodThe image inpainting method includes three modules: a semantic inpainting module, a foreground inpainting module, and an overall inpainting module. The purpose of the semantic repair module is to repair the defective semantic map to guide the subsequent semantic decoupling of the foreground and background areas. In the semantic repair phase, the missing semantic tag graph can be repaired, and the semantic information of the missing region can be enhanced. Then, the foreground mask is extracted via the repaired semantic map to obtain the accurate boundary and shape information of the foreground region. In the foreground restoration stage, the foreground region of the defect image is extracted on the basis of the foreground mask, and then the foreground restoration module is used to restore the texture and fill the missing region. The foreground area usually contains the key information in the image. Highly accurate and detailed foreground objects and their semantic information can be obtained when the foreground is repaired. The restored foreground region is subsequently embedded into the missing image. Finally, the missing image with foreground restoration completed is input to the overall repair module, which completes the two tasks of repairing the background region of the missing image and foreground–background fusion. The overall inpainting module repairs the entire image on the basis of the context information of the foreground, maintaining the consistency and smoothness of the image and further improving the inpainting effect of the foreground region. A joint loss function was employed for the three stages of image inpainting. The semantic inpainting module uses adversarial loss and semantic distribution loss to further improve the accuracy of semantic inpainting. The foreground inpainting and overall inpainting modules further incorporate perceptual loss, style loss, and global loss in addition to the losses. In particular, perceptual loss is used to ensure that the restoration results closely resemble the original image in terms of perception; style loss is used to reduce the occurrence of checkerboard artifacts caused by transposed convolution layers; and global loss is used to guarantee that the restored results exhibit a more coherent structure and content across the entire image. When these different types of loss functions are utilized, the proposed method can generate more realistic and natural images while maintaining high-quality inpainting results.ResultComparative experiments with other current image restoration methods demonstrated that the proposed approach outperforms other methods in terms of learned perceptual image patch similarity, the peak signal-to-noise ratio, and the structural similarity index on the CelebA-HQ and Cityscapes public datasets. Compared with the best average values of the baseline methods, on the CelebA-HQ dataset, the learned perceptual image patch similarity decreased by 8.86%, the structure similarity index measure (SSIM) improved by 1.1%, and the average peak signal-to-noise ratio(PSNR) was 27.09 dB. For the Cityscapes dataset, the LPIPS decreased by 4.62%, the SSIM improved by 0.45%, and the average PSNR was 27.31 dB. Furthermore, ablation experiments confirm the necessity and effectiveness of each component in the algorithm used in this study.ConclusionThis image inpainting method decouples the semantics of the foreground and background and uses a three-stage algorithm process to complete the image inpainting step by step, which effectively reduces the impact of semantic confusion and fuzzy boundaries. The foreground and background boundaries of the repaired image are clear, and the color style is more reasonable.关键词:image inpainting;semantic repair;priori knowledge;foreground-background decoupling56|116|0更新时间:2025-04-11 - “最新研究进展:专家提出触觉增强图卷积点云超分网络,有效提升高分辨率点云质量,对噪声具鲁棒性。”
 摘要:ObjectiveWith the rapid development of 3D scanners and 3D point cloud acquisition technologies, the application of 3D point clouds in computer vision, robot guidance, industrial design, and other fields has become increasingly widespread. As long as the point cloud is sufficiently dense, accurate models can be constructed to meet the demands of various advanced point cloud tasks. Accurate point clouds facilitate better performance in tasks such as semantic segmentation, completion, and classification. However, given the limitations of sensor resolution, scanning time, and scanning conditions, the acquired point clouds are often sparse. Existing point cloud upsampling methods address only single low-resolution point clouds, yield poor results when highly sparse point clouds are upsampled at relatively high magnification rates, and do not use additional modalities for assistance. Moreover, tactile information has gradually been applied to 3D reconstruction tasks, reconstructing complete 3D models via multimodal information such as RGB images, depth images, and tactile information. However, tactile point clouds have not yet been applied to point cloud superresolution tasks.MethodA tactile-enhanced graph convolutional point cloud superresolution network that uses dynamic graph convolution is proposed in this study. The proposed network is used to extract tactile features and fuse them with low-resolution point cloud features to obtain more accurate high-resolution point clouds. This network consists of a feature extraction module and an upsampling module. The feature extraction module extracts features from low-resolution point clouds and tactile point clouds, whereas the upsampling module performs feature expansion and coordinate reconstruction to output high-resolution point clouds. The key to this network lies in extracting features from tactile point clouds and fusing them with low-resolution point cloud features. The tactile feature extraction module adopts a multilayer perceptron (MLP) and 4-layer cascaded dynamic graph convolution. The tactile point cloud is mapped to a high-dimensional space by using a multilayer perceptron for subsequent feature extraction. The dynamic graph convolution module consists mainly of K-nearest neighbors (KNN) and edge convolution. In each dynamic graph convolution, the KNN algorithm is used to recompute the neighboring points of each point and construct the graph structure. The KNN algorithm can effectively aggregate local feature information, and edge convolution extracts features of center points and neighboring points. The K-nearest neighbors of each point vary in different network layers, leading to the graph structure being dynamically updated in each layer. The feature extraction for the low-resolution point cloud adopts graph convolution. The graph structure is first constructed via the KNN algorithm and then shared with subsequent layers. After the features of the low-resolution point cloud and the tactile point cloud are fused, the point cloud features undergo further progressive feature extraction, mainly via dense connected graph convolution modules. The bottleneck layer compresses features to reduce the computational complexity in subsequent layers. Two parallel dense graph convolutions extract local features, whereas the global pooling layer extracts global features. Finally, the feature rearrangement module and coordinate reconstruction module map the high-dimensional features back to the 3D coordinate system. Compared with low-resolution point clouds, local tactile point clouds are denser and more precise, whereas low-resolution point clouds are often sparser and contain less local information. With the assistance of tactile information, enhanced local features can be obtained.ResultA 3D Vision and Touch point cloud superresolution dataset with tactile information was reconstructed and trained. This dataset contains a diverse range of object categories and a sufficiently large number of samples. Using the chamfer distance as the evaluation metric, the experimental results reveal that without adding tactile information, the average chamfer distance is 3.009 × 10-3; when one instance of tactile information is added, the average chamfer distance decreases to 1.931 × 10-3; and when two instances of tactile information are added, the average chamfer distance further decreases to 1.916 × 10-3. Tactile point clouds can enhance the quality of high-resolution point clouds and serve as auxiliary aids in point cloud superresolution tasks. Visualizations of different objects demonstrate that the distribution of upsampled point clouds becomes more uniform, and the edges become smoother with the assistance of tactile information. With the assistance of tactile point clouds, the network can better fill in the holes in the point cloud and reduce the generation of outliers. The quantitative results of chamfer distance and density-aware chamfer distance obtained by superresolution experiments on different objects confirm the effectiveness of tactile point cloud assistance in the superresolution task. Furthermore, for complex objects, this improvement is even more pronounced. The noise experiments show that at a noise level of 1%, the average chamfer distance without tactile information is 3.132 × 10-3, whereas with the inclusion of two instances of tactile information, the average chamfer distance is 1.954 × 10-3. At a noise level of 3%, the average chamfer distance without tactile information is 3.331 × 10-3, and with the inclusion of two instances of tactile information, the average chamfer distance is 2.001 × 10-3. The experiments demonstrate that with the assistance of tactile information, the impact of noise on the network is reduced, indicating that the network exhibits strong robustness.ConclusionDynamic graph convolution can effectively extract initial features from tactile point clouds, and the tactile point cloud features contain rich local information. Through feature fusion, it can effectively assist in the point cloud superresolution task. The proposed tactile-enhanced graph convolutional point cloud superresolution network in this study uses dynamic graph convolution to extract tactile features and fuse them with low-resolution point cloud features, effectively improving the quality of high-resolution point clouds and exhibiting strong robustness. The superiority of the method lies in its ability to achieve better results by incorporating tactile information without updating the network architecture. This method can provide high-quality point clouds for advanced visual tasks such as point cloud classification and object detection, laying the foundation for further development and application of point clouds.关键词:Point Cloud Super-resolution;Tactile Point Clouds;feature extraction;feature fusion;dynamic graph convolution;multimodality71|165|0更新时间:2025-04-11
摘要:ObjectiveWith the rapid development of 3D scanners and 3D point cloud acquisition technologies, the application of 3D point clouds in computer vision, robot guidance, industrial design, and other fields has become increasingly widespread. As long as the point cloud is sufficiently dense, accurate models can be constructed to meet the demands of various advanced point cloud tasks. Accurate point clouds facilitate better performance in tasks such as semantic segmentation, completion, and classification. However, given the limitations of sensor resolution, scanning time, and scanning conditions, the acquired point clouds are often sparse. Existing point cloud upsampling methods address only single low-resolution point clouds, yield poor results when highly sparse point clouds are upsampled at relatively high magnification rates, and do not use additional modalities for assistance. Moreover, tactile information has gradually been applied to 3D reconstruction tasks, reconstructing complete 3D models via multimodal information such as RGB images, depth images, and tactile information. However, tactile point clouds have not yet been applied to point cloud superresolution tasks.MethodA tactile-enhanced graph convolutional point cloud superresolution network that uses dynamic graph convolution is proposed in this study. The proposed network is used to extract tactile features and fuse them with low-resolution point cloud features to obtain more accurate high-resolution point clouds. This network consists of a feature extraction module and an upsampling module. The feature extraction module extracts features from low-resolution point clouds and tactile point clouds, whereas the upsampling module performs feature expansion and coordinate reconstruction to output high-resolution point clouds. The key to this network lies in extracting features from tactile point clouds and fusing them with low-resolution point cloud features. The tactile feature extraction module adopts a multilayer perceptron (MLP) and 4-layer cascaded dynamic graph convolution. The tactile point cloud is mapped to a high-dimensional space by using a multilayer perceptron for subsequent feature extraction. The dynamic graph convolution module consists mainly of K-nearest neighbors (KNN) and edge convolution. In each dynamic graph convolution, the KNN algorithm is used to recompute the neighboring points of each point and construct the graph structure. The KNN algorithm can effectively aggregate local feature information, and edge convolution extracts features of center points and neighboring points. The K-nearest neighbors of each point vary in different network layers, leading to the graph structure being dynamically updated in each layer. The feature extraction for the low-resolution point cloud adopts graph convolution. The graph structure is first constructed via the KNN algorithm and then shared with subsequent layers. After the features of the low-resolution point cloud and the tactile point cloud are fused, the point cloud features undergo further progressive feature extraction, mainly via dense connected graph convolution modules. The bottleneck layer compresses features to reduce the computational complexity in subsequent layers. Two parallel dense graph convolutions extract local features, whereas the global pooling layer extracts global features. Finally, the feature rearrangement module and coordinate reconstruction module map the high-dimensional features back to the 3D coordinate system. Compared with low-resolution point clouds, local tactile point clouds are denser and more precise, whereas low-resolution point clouds are often sparser and contain less local information. With the assistance of tactile information, enhanced local features can be obtained.ResultA 3D Vision and Touch point cloud superresolution dataset with tactile information was reconstructed and trained. This dataset contains a diverse range of object categories and a sufficiently large number of samples. Using the chamfer distance as the evaluation metric, the experimental results reveal that without adding tactile information, the average chamfer distance is 3.009 × 10-3; when one instance of tactile information is added, the average chamfer distance decreases to 1.931 × 10-3; and when two instances of tactile information are added, the average chamfer distance further decreases to 1.916 × 10-3. Tactile point clouds can enhance the quality of high-resolution point clouds and serve as auxiliary aids in point cloud superresolution tasks. Visualizations of different objects demonstrate that the distribution of upsampled point clouds becomes more uniform, and the edges become smoother with the assistance of tactile information. With the assistance of tactile point clouds, the network can better fill in the holes in the point cloud and reduce the generation of outliers. The quantitative results of chamfer distance and density-aware chamfer distance obtained by superresolution experiments on different objects confirm the effectiveness of tactile point cloud assistance in the superresolution task. Furthermore, for complex objects, this improvement is even more pronounced. The noise experiments show that at a noise level of 1%, the average chamfer distance without tactile information is 3.132 × 10-3, whereas with the inclusion of two instances of tactile information, the average chamfer distance is 1.954 × 10-3. At a noise level of 3%, the average chamfer distance without tactile information is 3.331 × 10-3, and with the inclusion of two instances of tactile information, the average chamfer distance is 2.001 × 10-3. The experiments demonstrate that with the assistance of tactile information, the impact of noise on the network is reduced, indicating that the network exhibits strong robustness.ConclusionDynamic graph convolution can effectively extract initial features from tactile point clouds, and the tactile point cloud features contain rich local information. Through feature fusion, it can effectively assist in the point cloud superresolution task. The proposed tactile-enhanced graph convolutional point cloud superresolution network in this study uses dynamic graph convolution to extract tactile features and fuse them with low-resolution point cloud features, effectively improving the quality of high-resolution point clouds and exhibiting strong robustness. The superiority of the method lies in its ability to achieve better results by incorporating tactile information without updating the network architecture. This method can provide high-quality point clouds for advanced visual tasks such as point cloud classification and object detection, laying the foundation for further development and application of point clouds.关键词:Point Cloud Super-resolution;Tactile Point Clouds;feature extraction;feature fusion;dynamic graph convolution;multimodality71|165|0更新时间:2025-04-11
Image Understanding and Computer Vision
- “在3D场景重建领域,研究者提出了一种新的神经辐射场分类网络,通过图像增强和分类优化,提升了场景重建的语义一致性和外观泛化能力,为场景编辑和资源使用提供了新方案。”
 摘要:ObjectiveReconstruction of indoor and outdoor 3D scenes and placement of 3D resources in the real world constitute important development directions in the field of computer vision. Early researchers used voxel, occupancy, grid, and other computer graphics representation methods to achieve good results in terms of storage and rendering efficiency in a variety of mature application areas. However, these methods require time-consuming and laborious manual modeling, experienced modelers, and considerable time and energy. The time-consuming, laborious, and difficult modeling process must be simplified to enhance the application prospects in the 3D scene reconstruction field. By invoking and calculating the implicit field representation, researchers can obtain a realistic scene end-to-end, eliminating the complicated process of traditional modeling. The neural radiance field (NeRF) is the most popular implicit field representation method. Compared with other implicit field methods, the neural implicit field is known for its simplicity and ease of use, but its problems still exist and are rooted in the defects of the implicit field itself. The implicit field is a multidimensional function defined on spatial and directional coordinates, which codifies the geometry of the scene together with the appearance color, resulting in the entangled representation of the independent attributes of the target, causing inconvenience to the application of 3D resources. An important direction regarding implicit fields is “disentanglement” between geometry and appearance. First, the intrinsic decomposition uses some physical priors to avoid the initialization of complex networks. Second, the image is preprocessed into an albedo image independent of the observation direction and a shading image dependent on that. Intrinsic NeRF was the first to apply intrinsic decomposition methods in NeRF, but the decomposition they have used could not produce more reasonable appearance editing results.MethodIn this study, a NeRF classification network is proposed to learn the intrinsic properties of objects and target characteristics. It separates specular factors from 2D images via the image enhancement method, extracts the intrinsic colors (performs intrinsic decomposition) via the classification method, and then presents shading maps and direct illuminations of semantic-level objects in scenes via intrinsic decomposition expression. On this basis, the NeRF is learned, and the semantic consistency is provided with the help of “the front-point dominance module”, which is a module from the volume rendering stage that optimizes the albedo by “front points”. The consistency between views of the scene is provided with the help of “the color classification layer module”, which is a fully connected neural network from the reconstruction stage that fixes the albedo between different perspectives. Finally, a neural radiation field representing the intrinsic properties of the scene is reconstructed. After the rays are obtained by the internal and external parameters of the image, the positions of the sampling points and the directions of the rays are calculated in the neural network, producing the corresponding 3D properties. In the embedding layer, the position and direction are embedded and transformed into high-dimensional embedding features, which are the inputs of the network. After the 8-layer fully connected multilayer perceptron, the network outputs a 1-dimensional volume density, a 256-dimensional feature vector, and an N-dimensional semantic vector (where N is the number of semantic classes). The 256-dimensional feature vectors are then input into each 1-layer fully connected network to obtain color, a shading map, and direct illumination. In the inference stage, the model uses the Monte Carlo integral method to transform properties based on sampling points into properties based on rays (i.e., pixels), resulting in a synthetic result of the novel view. The model can disentangle attributes independent of and dependent on the observer. The resulting albedo output has semantic and multiview consistency independent of the observation direction. The implicit field shows good generalization for appearance and supports scene recoloring, relighting, and editing for shadows and specular factors.ResultCompared with the existing Intrinsic NeRF method for intrinsic decomposition based on NeRF learning, experiments on the Replica dataset show that under limited GPU memory and running time, this work can obtain intrinsic decomposition results with semantic and multiview consistency. For the “front-point dominance module”, which ensures semantic consistency, this work improves the performance by 4.1% compared with that of the Semantic NeRF. The ablation study revealed an improvement of 3.9% over the baseline model. For the “color classification layer module”, which improves semantic multiview consistency, this work improves the Intrinsic NeRF’s intrinsic decomposition method by 10.2% and the baseline model by 1.7%.ConclusionA novel NeRF classification network that can learn the intrinsic properties of objects and target characteristics is proposed. Experiments show that the work in this study can produce intrinsic decomposition results with semantic and multiview consistency. Moreover, an implicit field of albedo classification is constructed, which can describe the geometric relationship of complex scenes and shows good generalization for appearance. Realistic and multiview-consistent effects are achieved in tasks of scene recoloring, relighting, and shadow and specular factor editing.关键词:image processing;scene reconstruction;neural radiance field(NeRF);intrinsic decomposition;scene editing63|112|0更新时间:2025-04-11
摘要:ObjectiveReconstruction of indoor and outdoor 3D scenes and placement of 3D resources in the real world constitute important development directions in the field of computer vision. Early researchers used voxel, occupancy, grid, and other computer graphics representation methods to achieve good results in terms of storage and rendering efficiency in a variety of mature application areas. However, these methods require time-consuming and laborious manual modeling, experienced modelers, and considerable time and energy. The time-consuming, laborious, and difficult modeling process must be simplified to enhance the application prospects in the 3D scene reconstruction field. By invoking and calculating the implicit field representation, researchers can obtain a realistic scene end-to-end, eliminating the complicated process of traditional modeling. The neural radiance field (NeRF) is the most popular implicit field representation method. Compared with other implicit field methods, the neural implicit field is known for its simplicity and ease of use, but its problems still exist and are rooted in the defects of the implicit field itself. The implicit field is a multidimensional function defined on spatial and directional coordinates, which codifies the geometry of the scene together with the appearance color, resulting in the entangled representation of the independent attributes of the target, causing inconvenience to the application of 3D resources. An important direction regarding implicit fields is “disentanglement” between geometry and appearance. First, the intrinsic decomposition uses some physical priors to avoid the initialization of complex networks. Second, the image is preprocessed into an albedo image independent of the observation direction and a shading image dependent on that. Intrinsic NeRF was the first to apply intrinsic decomposition methods in NeRF, but the decomposition they have used could not produce more reasonable appearance editing results.MethodIn this study, a NeRF classification network is proposed to learn the intrinsic properties of objects and target characteristics. It separates specular factors from 2D images via the image enhancement method, extracts the intrinsic colors (performs intrinsic decomposition) via the classification method, and then presents shading maps and direct illuminations of semantic-level objects in scenes via intrinsic decomposition expression. On this basis, the NeRF is learned, and the semantic consistency is provided with the help of “the front-point dominance module”, which is a module from the volume rendering stage that optimizes the albedo by “front points”. The consistency between views of the scene is provided with the help of “the color classification layer module”, which is a fully connected neural network from the reconstruction stage that fixes the albedo between different perspectives. Finally, a neural radiation field representing the intrinsic properties of the scene is reconstructed. After the rays are obtained by the internal and external parameters of the image, the positions of the sampling points and the directions of the rays are calculated in the neural network, producing the corresponding 3D properties. In the embedding layer, the position and direction are embedded and transformed into high-dimensional embedding features, which are the inputs of the network. After the 8-layer fully connected multilayer perceptron, the network outputs a 1-dimensional volume density, a 256-dimensional feature vector, and an N-dimensional semantic vector (where N is the number of semantic classes). The 256-dimensional feature vectors are then input into each 1-layer fully connected network to obtain color, a shading map, and direct illumination. In the inference stage, the model uses the Monte Carlo integral method to transform properties based on sampling points into properties based on rays (i.e., pixels), resulting in a synthetic result of the novel view. The model can disentangle attributes independent of and dependent on the observer. The resulting albedo output has semantic and multiview consistency independent of the observation direction. The implicit field shows good generalization for appearance and supports scene recoloring, relighting, and editing for shadows and specular factors.ResultCompared with the existing Intrinsic NeRF method for intrinsic decomposition based on NeRF learning, experiments on the Replica dataset show that under limited GPU memory and running time, this work can obtain intrinsic decomposition results with semantic and multiview consistency. For the “front-point dominance module”, which ensures semantic consistency, this work improves the performance by 4.1% compared with that of the Semantic NeRF. The ablation study revealed an improvement of 3.9% over the baseline model. For the “color classification layer module”, which improves semantic multiview consistency, this work improves the Intrinsic NeRF’s intrinsic decomposition method by 10.2% and the baseline model by 1.7%.ConclusionA novel NeRF classification network that can learn the intrinsic properties of objects and target characteristics is proposed. Experiments show that the work in this study can produce intrinsic decomposition results with semantic and multiview consistency. Moreover, an implicit field of albedo classification is constructed, which can describe the geometric relationship of complex scenes and shows good generalization for appearance. Realistic and multiview-consistent effects are achieved in tasks of scene recoloring, relighting, and shadow and specular factor editing.关键词:image processing;scene reconstruction;neural radiance field(NeRF);intrinsic decomposition;scene editing63|112|0更新时间:2025-04-11
Computer Graphics
- “在医学图像分割领域,研究者提出了分布感知均值教师网络,有效提升了半监督分割性能,尤其在标记数据较少时表现优异。”
 摘要:ObjectiveMedical image segmentation has great potential for application in clinical diagnosis. Although supervised medical image segmentation models can achieve good segmentation results, they rely heavily on pixel-level annotated training data. However, acquiring labeled data is costly and can only be performed by experts. In particular, in the case of 3D medical datasets, the annotation process is more intricate and time-consuming than in 2D datasets. Semi-supervised learning is an effective solution that combines labeled and unlabeled data for improved segmentation results. However, existing semi-supervised methods do not address the performance impact caused by the distribution gap between labeled and unlabeled data, especially when the proportion of labeled data is low.MethodA distribution-aware mean teacher network (DAMTN) is proposed for semi-supervised medical image segmentation to reduce the performance impact caused by the distribution gap between labeled and unlabeled data. This method utilizes the distribution information of both labeled and unlabeled data to guide the learning of the model, aiming to ensure that the segmentation results of labeled and unlabeled data have similar distributions during the training phase. The DAMTN adopts a teacher-student architecture, consisting of a teacher model and a student model. In addition, both the teacher model and the student model’s network architectures are based on the V-Net design, which includes an encoder and three decoders. The residual connections between the encoder and decoder have been removed. The decoders are differentiated by embedding different attention modules, which are used to introduce perturbations at the model level. These attention methods, including cross-sampling mutual attention (CMA), position attention (PA), and channel attention (CA), are employed to process high-level features. The CMA is used for inter-sample feature interaction and alignment, the PA is employed to handle spatial position information in the feature maps, the CA is utilized to address channel correlations in the feature maps, and the DAMTN comprises three key modules: the distribution-aware (DA) module, integrity supervision (IS), and uncertainty minimization (UM) module. These three modules compute the losses for the outputs of the student model, and the outputs of the teacher model are used to calculate the consistency loss with the corresponding outputs of the student model. The DA module encourages the model to learn features when the distribution information from labeled and unlabeled data is similar. Each decoder branch is equipped with a dual normalization block consisting of two normalization layers (
摘要:ObjectiveMedical image segmentation has great potential for application in clinical diagnosis. Although supervised medical image segmentation models can achieve good segmentation results, they rely heavily on pixel-level annotated training data. However, acquiring labeled data is costly and can only be performed by experts. In particular, in the case of 3D medical datasets, the annotation process is more intricate and time-consuming than in 2D datasets. Semi-supervised learning is an effective solution that combines labeled and unlabeled data for improved segmentation results. However, existing semi-supervised methods do not address the performance impact caused by the distribution gap between labeled and unlabeled data, especially when the proportion of labeled data is low.MethodA distribution-aware mean teacher network (DAMTN) is proposed for semi-supervised medical image segmentation to reduce the performance impact caused by the distribution gap between labeled and unlabeled data. This method utilizes the distribution information of both labeled and unlabeled data to guide the learning of the model, aiming to ensure that the segmentation results of labeled and unlabeled data have similar distributions during the training phase. The DAMTN adopts a teacher-student architecture, consisting of a teacher model and a student model. In addition, both the teacher model and the student model’s network architectures are based on the V-Net design, which includes an encoder and three decoders. The residual connections between the encoder and decoder have been removed. The decoders are differentiated by embedding different attention modules, which are used to introduce perturbations at the model level. These attention methods, including cross-sampling mutual attention (CMA), position attention (PA), and channel attention (CA), are employed to process high-level features. The CMA is used for inter-sample feature interaction and alignment, the PA is employed to handle spatial position information in the feature maps, the CA is utilized to address channel correlations in the feature maps, and the DAMTN comprises three key modules: the distribution-aware (DA) module, integrity supervision (IS), and uncertainty minimization (UM) module. These three modules compute the losses for the outputs of the student model, and the outputs of the teacher model are used to calculate the consistency loss with the corresponding outputs of the student model. The DA module encourages the model to learn features when the distribution information from labeled and unlabeled data is similar. Each decoder branch is equipped with a dual normalization block consisting of two normalization layers ( - “在结肠息肉图像分割领域,专家提出了一种自知识蒸馏框架,实现了准确的边界提取,为医学图像分割任务提供新方案。”
 摘要:ObjectiveColorectal cancer remains a formidable global health challenge, underscoring the pressing need for early detection strategies to improve treatment outcomes. Among these strategies, colonoscopy stands out as a primary diagnostic tool, relying on the visual acumen of medical professionals to identify potentially cancerous abnormalities, such as polyps, within the colon and rectum. However, the effectiveness of colonoscopy is heavily contingent upon the skill and experience of the operator, leading to variability and limitations in detection rates across different practitioners and settings. In response to these challenges, the integration of artificial intelligence and computer vision techniques has garnered increasing attention as a means to augment the accuracy and efficiency of colorectal cancer screening. Various algorithms have been developed to automatically segment colorectal images, with the overarching goal of precisely delineating polyps from the surrounding tissue. Despite advancements in this domain, many existing models confront inherent inefficiencies and limited effectiveness stemming from their intricate architectures and dependence on manual feature engineering.MethodThis study proposes a novel end-to-end boundary self-knowledge distillation (BA-KD) framework, which aims to achieve precise polyp segmentation. In contrast to conventional methods, BA-KD seamlessly integrates boundary and polyp segmentation networks into a unified framework, facilitating effective knowledge transfer between the two domains. BA-KD represents a pioneering contribution in this field, aiming to harness the synergistic benefits of both boundary and polyp information for increased segmentation accuracy. The BA-KD framework comprises two interconnected branches: a boundary segmentation network serving as the teacher branch and a polyp segmentation network acting as the student branch. The inherent challenges associated with delineating polyp boundaries are addressed by introducing a boundary detection operator to automatically generate boundary masks, which are subsequently leveraged when training both branches. This approach not only enhances the segmentation performance of the student branch but also enriches the knowledge base of the teacher branch, thereby fostering mutual learning and refinement. A key distinguishing feature of BA-KD is the shared image feature extractors between the student and teacher branches, facilitating robust knowledge transfer across both domains. Two innovative structures, namely, reverse multilevel feature fusion (RMLF) and reverse feature fusion (RFM), are proposed to facilitate the effective fusion of feature information at various hierarchical levels. RMLF enables the integration of high-level features to generate a comprehensive global feature map, whereas RFM synergistically combines reverse shallow features with high-level features aggregated via RMLF to produce the final segmentation mask.ResultA comprehensive experimental validation of the BA-KD results is conducted against seven state-of-the-art methods across four different datasets: CVC-ClinicDB, CVC-ColonDB, Kvasir, and HAM10000. The comparative models include U-Net, Double-UNet, UNet++, TransFuse, PraNet, DuAT, RaBit, GroupSeg, and G-CASCADE. These models serve as benchmarks in the polyp segmentation and general medical image segmentation domains. The results on CVC-ClinicDB show that BA-KD demonstrates exceptional performance in terms of mSpe and mDSC, with values of 0.997 and 0.955 5, respectively. BA-KD outperforms all the competitors in terms of mDSC and mIoU, with improvements of 0.45% and 0.68%, respectively, over RaBit. For the CVC-ColonDB dataset, BA-KD outperforms all the other methods across all the evaluation metrics, achieving improvements of 2.20% in the mIoU and 1.51% in the mDSC compared with the optimal performance achieved by TransFuse. For the Kvasir dataset, BA-KD achieves an mIoU of 0.889 and an mDSC of 0.937, surpassing the best-performing RaBit by approximately 1.08% and 1.14%, respectively. Furthermore, the generalization ability of BA-KD is evaluated on other medical segmentation tasks via the HAM10000 dataset, which includes dermoscopic images from different populations. Compared with existing medical segmentation baselines, BA-KD excels in all metrics on HAM10000, achieving significant scores in mDSC (0.956 2) and mIoU (0.922 3), surpassing the best-performing Double UNet by 1.45% and 2.25%, respectively.ConclusionThe experimental results clearly demonstrate that BA-KD outperforms existing state-of-the-art segmentation methods, with substantial improvements in the Dice similarity coefficient (DSC)and mean intersection over union metrics (mIoU).关键词:polyp segmentation;medical image processing;deep learning;knowledge distillation;boundary segmentation78|124|0更新时间:2025-04-11
摘要:ObjectiveColorectal cancer remains a formidable global health challenge, underscoring the pressing need for early detection strategies to improve treatment outcomes. Among these strategies, colonoscopy stands out as a primary diagnostic tool, relying on the visual acumen of medical professionals to identify potentially cancerous abnormalities, such as polyps, within the colon and rectum. However, the effectiveness of colonoscopy is heavily contingent upon the skill and experience of the operator, leading to variability and limitations in detection rates across different practitioners and settings. In response to these challenges, the integration of artificial intelligence and computer vision techniques has garnered increasing attention as a means to augment the accuracy and efficiency of colorectal cancer screening. Various algorithms have been developed to automatically segment colorectal images, with the overarching goal of precisely delineating polyps from the surrounding tissue. Despite advancements in this domain, many existing models confront inherent inefficiencies and limited effectiveness stemming from their intricate architectures and dependence on manual feature engineering.MethodThis study proposes a novel end-to-end boundary self-knowledge distillation (BA-KD) framework, which aims to achieve precise polyp segmentation. In contrast to conventional methods, BA-KD seamlessly integrates boundary and polyp segmentation networks into a unified framework, facilitating effective knowledge transfer between the two domains. BA-KD represents a pioneering contribution in this field, aiming to harness the synergistic benefits of both boundary and polyp information for increased segmentation accuracy. The BA-KD framework comprises two interconnected branches: a boundary segmentation network serving as the teacher branch and a polyp segmentation network acting as the student branch. The inherent challenges associated with delineating polyp boundaries are addressed by introducing a boundary detection operator to automatically generate boundary masks, which are subsequently leveraged when training both branches. This approach not only enhances the segmentation performance of the student branch but also enriches the knowledge base of the teacher branch, thereby fostering mutual learning and refinement. A key distinguishing feature of BA-KD is the shared image feature extractors between the student and teacher branches, facilitating robust knowledge transfer across both domains. Two innovative structures, namely, reverse multilevel feature fusion (RMLF) and reverse feature fusion (RFM), are proposed to facilitate the effective fusion of feature information at various hierarchical levels. RMLF enables the integration of high-level features to generate a comprehensive global feature map, whereas RFM synergistically combines reverse shallow features with high-level features aggregated via RMLF to produce the final segmentation mask.ResultA comprehensive experimental validation of the BA-KD results is conducted against seven state-of-the-art methods across four different datasets: CVC-ClinicDB, CVC-ColonDB, Kvasir, and HAM10000. The comparative models include U-Net, Double-UNet, UNet++, TransFuse, PraNet, DuAT, RaBit, GroupSeg, and G-CASCADE. These models serve as benchmarks in the polyp segmentation and general medical image segmentation domains. The results on CVC-ClinicDB show that BA-KD demonstrates exceptional performance in terms of mSpe and mDSC, with values of 0.997 and 0.955 5, respectively. BA-KD outperforms all the competitors in terms of mDSC and mIoU, with improvements of 0.45% and 0.68%, respectively, over RaBit. For the CVC-ColonDB dataset, BA-KD outperforms all the other methods across all the evaluation metrics, achieving improvements of 2.20% in the mIoU and 1.51% in the mDSC compared with the optimal performance achieved by TransFuse. For the Kvasir dataset, BA-KD achieves an mIoU of 0.889 and an mDSC of 0.937, surpassing the best-performing RaBit by approximately 1.08% and 1.14%, respectively. Furthermore, the generalization ability of BA-KD is evaluated on other medical segmentation tasks via the HAM10000 dataset, which includes dermoscopic images from different populations. Compared with existing medical segmentation baselines, BA-KD excels in all metrics on HAM10000, achieving significant scores in mDSC (0.956 2) and mIoU (0.922 3), surpassing the best-performing Double UNet by 1.45% and 2.25%, respectively.ConclusionThe experimental results clearly demonstrate that BA-KD outperforms existing state-of-the-art segmentation methods, with substantial improvements in the Dice similarity coefficient (DSC)and mean intersection over union metrics (mIoU).关键词:polyp segmentation;medical image processing;deep learning;knowledge distillation;boundary segmentation78|124|0更新时间:2025-04-11 - “在影像引导的脊柱手术机器人领域,研究者提出了基于语义边缘提取的2D/3D配准方法,有效提高了配准精度和效率,满足临床需求。”
 摘要:ObjectiveIn image-guided spine surgery-based robotic systems, 2D/3D registration refers to aligning preoperative 3D computed tomography (CT) images with intraoperative 2D X-rays to achieve precise spatial localization of the surgical robot for human tissues. The prevalent approach involves the use of landmark points for initial coarse registration and subsequently applying the intensity-based method to rectify the position. However, the landmark-based registration method typically uses a heatmap regression method, which can be GPU intensive. Simultaneously, the random field of view during intraoperative X-rays and the overlapping of human tissues on X-rays can result in the loss of tissue information. This loss can cause incorrect predictions or predictions with a considerable deviation of landmark points. The intensity-based method is considered the most accurate and efficient approach because it utilizes the entire image information. However, intensity-based methods usually have problems such as a small capture range and sensitivity to the initial pose. The accuracy of 2D/3D registration when physical edges are used as features is low because of the overlap of spinal joint edges and the low quality of intraoperative radiographs. Here, a 2D/3D registration method based on semantic edge extraction is proposed.MethodThe semantic edge-based 2D/3D registration method uses noverlapping pedicle edges and edges on both sides of the vertebra in the X-ray as semantic features for 2D/3D registration. The real-time detection Transformer model is first used to predict the bounding boxes of the vertebrae to be registered in intraoperative X-rays. The CT images of the vertebrae to be registered are then extracted from the known vertebrae masks. The semantic edges of the vertebrae from the intraoperative X-rays and the digitally reconstructed radiological images from the CT image projection are extracted by spacing constrained and efficient UNet Transformers (SCE-UNETR). Finally, the pose is updated iteratively by minimizing the reprojection error until convergence. The SCE-UNETR network uses a U-shaped structure for encoding and decoding; it comprises an encoder module, skip connection layers, and a decoder. The SCE-UNETR encoder consists of a vision Transformer (ViT) network, where the image features are connected to the decoder by skipping connection layers. The ViT network contains a total of 12 groups of Transformer blocks, each consisting of two normalization layers, a multihead attention layer, and a multilayer perceptron. In this study, the skip connection layer and the decoder of SCE-UNETR are illuminated by a multiaxis group Hadamard product attention module instead of a convolutional operation, which changes the quadratic complexity into linear complexity and reduces the quantity of network parameters. In addition, the network incorporates the loss of the vertebral spacing constraint as a priori information, which further improves the accuracy of multivertebra semantic edge extraction.ResultThe method proposed in this study was quantitatively and qualitatively evaluated from different perspectives, including semantic edge extraction, coarse registration, pose refinement, method comparison, registration accuracy, and registration time. For the semantic edge extraction task, the SCE-UNETR was compared with SwinUNETR, TransUNet, and UNETR. SCE-UNETR has approximately half the number of network parameters of the other networks. However, in terms of the metrics of segmentation overlap, average Dice, average intersection over union, and average 95% Hausdorff distance, the SCE-UNETR is better than those of the other three networks. In addition, all networks show some improvement in semantic edge extraction accuracy after the spacing constraint loss term is combined with Dice loss. For the 2D/3D registration task, the experiments demonstrate that the proposed method outperforms the state-of-the-art methods on both simulated and real data. Following pose refinement, the proposed method achieves a translation error of less than 1 mm and a rotation error of less than 0.1°. The registration process itself takes approximately 5 s, which is well suited to the clinical environment.ConclusionThe proposed semantic edge-based 2D/3D registration method effectively reduces the search space of the subsequent pose refinement process, thus improving the registration accuracy. In terms of edge extraction, the network is illuminated, and the vertebrae spacing constraint loss is added, thereby improving the efficiency and accuracy of semantic edge extraction. Therefore, the proposed method can better meet the accuracy and real-time requirements of 2D/3D registration.关键词:2D/3D registration;spinal surgery robot;vertebra;semantic edge extraction;vision Transformer(ViT)64|88|0更新时间:2025-04-11
摘要:ObjectiveIn image-guided spine surgery-based robotic systems, 2D/3D registration refers to aligning preoperative 3D computed tomography (CT) images with intraoperative 2D X-rays to achieve precise spatial localization of the surgical robot for human tissues. The prevalent approach involves the use of landmark points for initial coarse registration and subsequently applying the intensity-based method to rectify the position. However, the landmark-based registration method typically uses a heatmap regression method, which can be GPU intensive. Simultaneously, the random field of view during intraoperative X-rays and the overlapping of human tissues on X-rays can result in the loss of tissue information. This loss can cause incorrect predictions or predictions with a considerable deviation of landmark points. The intensity-based method is considered the most accurate and efficient approach because it utilizes the entire image information. However, intensity-based methods usually have problems such as a small capture range and sensitivity to the initial pose. The accuracy of 2D/3D registration when physical edges are used as features is low because of the overlap of spinal joint edges and the low quality of intraoperative radiographs. Here, a 2D/3D registration method based on semantic edge extraction is proposed.MethodThe semantic edge-based 2D/3D registration method uses noverlapping pedicle edges and edges on both sides of the vertebra in the X-ray as semantic features for 2D/3D registration. The real-time detection Transformer model is first used to predict the bounding boxes of the vertebrae to be registered in intraoperative X-rays. The CT images of the vertebrae to be registered are then extracted from the known vertebrae masks. The semantic edges of the vertebrae from the intraoperative X-rays and the digitally reconstructed radiological images from the CT image projection are extracted by spacing constrained and efficient UNet Transformers (SCE-UNETR). Finally, the pose is updated iteratively by minimizing the reprojection error until convergence. The SCE-UNETR network uses a U-shaped structure for encoding and decoding; it comprises an encoder module, skip connection layers, and a decoder. The SCE-UNETR encoder consists of a vision Transformer (ViT) network, where the image features are connected to the decoder by skipping connection layers. The ViT network contains a total of 12 groups of Transformer blocks, each consisting of two normalization layers, a multihead attention layer, and a multilayer perceptron. In this study, the skip connection layer and the decoder of SCE-UNETR are illuminated by a multiaxis group Hadamard product attention module instead of a convolutional operation, which changes the quadratic complexity into linear complexity and reduces the quantity of network parameters. In addition, the network incorporates the loss of the vertebral spacing constraint as a priori information, which further improves the accuracy of multivertebra semantic edge extraction.ResultThe method proposed in this study was quantitatively and qualitatively evaluated from different perspectives, including semantic edge extraction, coarse registration, pose refinement, method comparison, registration accuracy, and registration time. For the semantic edge extraction task, the SCE-UNETR was compared with SwinUNETR, TransUNet, and UNETR. SCE-UNETR has approximately half the number of network parameters of the other networks. However, in terms of the metrics of segmentation overlap, average Dice, average intersection over union, and average 95% Hausdorff distance, the SCE-UNETR is better than those of the other three networks. In addition, all networks show some improvement in semantic edge extraction accuracy after the spacing constraint loss term is combined with Dice loss. For the 2D/3D registration task, the experiments demonstrate that the proposed method outperforms the state-of-the-art methods on both simulated and real data. Following pose refinement, the proposed method achieves a translation error of less than 1 mm and a rotation error of less than 0.1°. The registration process itself takes approximately 5 s, which is well suited to the clinical environment.ConclusionThe proposed semantic edge-based 2D/3D registration method effectively reduces the search space of the subsequent pose refinement process, thus improving the registration accuracy. In terms of edge extraction, the network is illuminated, and the vertebrae spacing constraint loss is added, thereby improving the efficiency and accuracy of semantic edge extraction. Therefore, the proposed method can better meet the accuracy and real-time requirements of 2D/3D registration.关键词:2D/3D registration;spinal surgery robot;vertebra;semantic edge extraction;vision Transformer(ViT)64|88|0更新时间:2025-04-11
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0