
最新刊期
卷 30 , 期 1 , 2025
- “在计算机视觉领域,视觉基础模型的研究进展为解决传统深度学习模型依赖大量标注数据和泛化能力不足的问题提供了新方案。”
 摘要:In the field of computer vision, traditional deep learning vision models have exhibited remarkable performance on specific tasks. However, their substantial dependency on large amounts of annotated data and limited capability in generalization across new scenes significantly elevate usage costs and restrict the application scope of these models. Recently, novel model architectures centered around the Transformer, particularly in the domain of self-supervised learning, have emerged as solutions to these challenges. These models, typically pre-trained on extensive datasets, demonstrate robust generalization capabilities in complex visual scenarios and are widely recognized as vision foundation models. This paper delves into the current research status and future trends of vision foundation models, with a focus on key technological advancements in this field and their potential impact on future developments in computer vision. The paper begins by reviewing and organizing the background and developmental history of vision foundation models, followed by an introduction to the key model structures that have emerged in this developmental trajectory. The article further introduces and analyzes the design philosophies of various pre-training tasks employed in constructing vision foundation models, categorizing the existing models based on their characteristics. Additionally, the paper presents representative works in different types of vision foundation models and compiles the currently available datasets for pre-training these models. Finally, the paper summarizes the current research status of vision foundation models, reflects on existing challenges, and anticipates potential future research directions. This paper offers an expansive examination of the landscape of visual foundation models, chronicling their evolution, current achievements, and charting a course for future research. It acknowledges the Transformative impact of deep learning on computer vision, shifting the paradigm from traditional computational methods to models that excel in specialized tasks. However, it also confronts the limitations of these models, particularly their narrow applicability and reliance on extensive, meticulously annotated datasets, which have elevated deployment costs and restricted versatility. In response, the emergence of Transformer-based architectures has instigated a paradigm shift, leading to the development of vision foundation models that are redefining the capabilities and breadth of applicability of computer vision systems. This paper provides a systematic review of these models, offering historical context that underscores the transition from traditional deep learning models to the current paradigm involving Transformer-based models. It delves into the core structures of these models, such as the Transformer and vision Transformer, discussing their architectural intricacies and the principles that underpin their design, enabling them to capture the complexities of visual data with nuance and accuracy. A pivotal contribution of this paper is the thorough analysis of pre-training tasks, which is foundational to the construction of robust vision foundation models. It categorizes these tasks on the basis of their design philosophies and their effectiveness in enabling models to learn rich feature representations from large-scale datasets, thereby enhancing their generalization capabilities across a myriad of computer vision tasks. This article primarily introduces various pre-training methods such as supervised learning, image contrastive learning, image-text contrastive learning, and masked image modeling. It analyzes the characteristics of these pre-training tasks, the representative works corresponding to each, as well as their applicable scenarios and potential directions for improvement. This paper introduces existing vision foundation models based on mixture of experts according to universal visual representation backbones, aligned with language modalities, and generative multi-task models. Specifically, the article first analyzes the background of each type of foundation model, the core ideas of the models, and the pioneering work. Then, it analyzes the representative works in the development of each type of foundation model. Finally, it provides a prospect based on the strengths and weaknesses of each method. The paper also evaluates existing vision foundation models, scrutinizing their characteristics, capabilities, and the datasets utilized for their pre-training, providing an in-depth analysis of their performance on a variety of tasks, including image classification, object detection, and semantic segmentation. This paper delves into the critical component of pre-training datasets that serve as the foundational resources for the development and refinement of visual foundation models. It presents a comprehensive overview of the extensive image datasets and the burgeoning realm of image-text datasets that are instrumental in the pre-training phase of these models. The discussion commences with the seminal ImageNet dataset, which has been crucial in computer vision research and the benchmark for evaluating model performance. The paper then outlines the expansive ImageNet-21k and the colossal JFT-300M/3B datasets, highlighting their scale and the implications of such magnitude on model training and generalization capabilities. The COCO and ADE20k datasets are examined for their role in tasks such as object detection and semantic segmentation, underlining their contribution to the diversity and complexity of pre-training data. The Object365 dataset is also acknowledged for its focus on open-world target detection, offering a rich resource for model exposure to a wide array of visual categories. In addition to image datasets, the paper underscores the importance of image-text datasets such as Conceptual Captions and Flickr30k, which are becoming increasingly vital for models that integrate multimodal inputs. These datasets provide the necessary linkage between visual content and textual descriptions, enabling models to develop a deeper understanding of the semantic context. The paper anticipates research directions such as establishing comprehensive benchmark evaluation systems, enhancing cross-modal capabilities, expanding the coverage of various visual tasks, leveraging structured knowledge bases for training, and developing model compression and optimization techniques to facilitate the deployment of these models in real-world scenarios. The ultimate goal is to develop visual foundation models that are more versatile and intelligent, capable of addressing complex visual problems in the real world. Reflecting on the challenges faced by the field, the paper identifies the pressing need for more efficient training algorithms, the development of better evaluation metrics, and the integration of multimodal data. This paper also highlights several challenges, including the need for more unified model paradigms in computer vision, the development of effective performance improvement paths similar to the “scaling law” observed in NLP, and the necessity for new evaluation metrics that can assess models’ cross-modal understanding and performance across a wide range of tasks. It anticipates future research directions, such as the modularization of vision foundation models to enhance their adaptability and the exploration of weakly supervised learning techniques, which aim to diminish reliance on large annotated datasets. One of the key contributions of this paper is the in-depth discussion on the real-world applications of vision foundation models. It explores their implications for tasks such as medical image analysis, autonomous driving, and surveillance, underscoring their transformative potential and profound possible impact on these domains. In conclusion, this paper synthesizes the current state of research on vision foundation models and outlines opportunities for future advancements. It emphasizes the importance of continued interdisciplinary research to unlock the full potential of vision foundation models and address the intricate challenges in the field of computer vision. The paper’s advocacy for an interdisciplinary approach is underpinned by the belief that it will foster innovation and enable the development of models that are not only more efficient and adaptable but also capable of addressing complex and multifaceted problems in the real world.关键词:foundation model;computer vision(CV);pre-training model;self-supervised learning;multi-task learning709|467|0更新时间:2025-04-11
摘要:In the field of computer vision, traditional deep learning vision models have exhibited remarkable performance on specific tasks. However, their substantial dependency on large amounts of annotated data and limited capability in generalization across new scenes significantly elevate usage costs and restrict the application scope of these models. Recently, novel model architectures centered around the Transformer, particularly in the domain of self-supervised learning, have emerged as solutions to these challenges. These models, typically pre-trained on extensive datasets, demonstrate robust generalization capabilities in complex visual scenarios and are widely recognized as vision foundation models. This paper delves into the current research status and future trends of vision foundation models, with a focus on key technological advancements in this field and their potential impact on future developments in computer vision. The paper begins by reviewing and organizing the background and developmental history of vision foundation models, followed by an introduction to the key model structures that have emerged in this developmental trajectory. The article further introduces and analyzes the design philosophies of various pre-training tasks employed in constructing vision foundation models, categorizing the existing models based on their characteristics. Additionally, the paper presents representative works in different types of vision foundation models and compiles the currently available datasets for pre-training these models. Finally, the paper summarizes the current research status of vision foundation models, reflects on existing challenges, and anticipates potential future research directions. This paper offers an expansive examination of the landscape of visual foundation models, chronicling their evolution, current achievements, and charting a course for future research. It acknowledges the Transformative impact of deep learning on computer vision, shifting the paradigm from traditional computational methods to models that excel in specialized tasks. However, it also confronts the limitations of these models, particularly their narrow applicability and reliance on extensive, meticulously annotated datasets, which have elevated deployment costs and restricted versatility. In response, the emergence of Transformer-based architectures has instigated a paradigm shift, leading to the development of vision foundation models that are redefining the capabilities and breadth of applicability of computer vision systems. This paper provides a systematic review of these models, offering historical context that underscores the transition from traditional deep learning models to the current paradigm involving Transformer-based models. It delves into the core structures of these models, such as the Transformer and vision Transformer, discussing their architectural intricacies and the principles that underpin their design, enabling them to capture the complexities of visual data with nuance and accuracy. A pivotal contribution of this paper is the thorough analysis of pre-training tasks, which is foundational to the construction of robust vision foundation models. It categorizes these tasks on the basis of their design philosophies and their effectiveness in enabling models to learn rich feature representations from large-scale datasets, thereby enhancing their generalization capabilities across a myriad of computer vision tasks. This article primarily introduces various pre-training methods such as supervised learning, image contrastive learning, image-text contrastive learning, and masked image modeling. It analyzes the characteristics of these pre-training tasks, the representative works corresponding to each, as well as their applicable scenarios and potential directions for improvement. This paper introduces existing vision foundation models based on mixture of experts according to universal visual representation backbones, aligned with language modalities, and generative multi-task models. Specifically, the article first analyzes the background of each type of foundation model, the core ideas of the models, and the pioneering work. Then, it analyzes the representative works in the development of each type of foundation model. Finally, it provides a prospect based on the strengths and weaknesses of each method. The paper also evaluates existing vision foundation models, scrutinizing their characteristics, capabilities, and the datasets utilized for their pre-training, providing an in-depth analysis of their performance on a variety of tasks, including image classification, object detection, and semantic segmentation. This paper delves into the critical component of pre-training datasets that serve as the foundational resources for the development and refinement of visual foundation models. It presents a comprehensive overview of the extensive image datasets and the burgeoning realm of image-text datasets that are instrumental in the pre-training phase of these models. The discussion commences with the seminal ImageNet dataset, which has been crucial in computer vision research and the benchmark for evaluating model performance. The paper then outlines the expansive ImageNet-21k and the colossal JFT-300M/3B datasets, highlighting their scale and the implications of such magnitude on model training and generalization capabilities. The COCO and ADE20k datasets are examined for their role in tasks such as object detection and semantic segmentation, underlining their contribution to the diversity and complexity of pre-training data. The Object365 dataset is also acknowledged for its focus on open-world target detection, offering a rich resource for model exposure to a wide array of visual categories. In addition to image datasets, the paper underscores the importance of image-text datasets such as Conceptual Captions and Flickr30k, which are becoming increasingly vital for models that integrate multimodal inputs. These datasets provide the necessary linkage between visual content and textual descriptions, enabling models to develop a deeper understanding of the semantic context. The paper anticipates research directions such as establishing comprehensive benchmark evaluation systems, enhancing cross-modal capabilities, expanding the coverage of various visual tasks, leveraging structured knowledge bases for training, and developing model compression and optimization techniques to facilitate the deployment of these models in real-world scenarios. The ultimate goal is to develop visual foundation models that are more versatile and intelligent, capable of addressing complex visual problems in the real world. Reflecting on the challenges faced by the field, the paper identifies the pressing need for more efficient training algorithms, the development of better evaluation metrics, and the integration of multimodal data. This paper also highlights several challenges, including the need for more unified model paradigms in computer vision, the development of effective performance improvement paths similar to the “scaling law” observed in NLP, and the necessity for new evaluation metrics that can assess models’ cross-modal understanding and performance across a wide range of tasks. It anticipates future research directions, such as the modularization of vision foundation models to enhance their adaptability and the exploration of weakly supervised learning techniques, which aim to diminish reliance on large annotated datasets. One of the key contributions of this paper is the in-depth discussion on the real-world applications of vision foundation models. It explores their implications for tasks such as medical image analysis, autonomous driving, and surveillance, underscoring their transformative potential and profound possible impact on these domains. In conclusion, this paper synthesizes the current state of research on vision foundation models and outlines opportunities for future advancements. It emphasizes the importance of continued interdisciplinary research to unlock the full potential of vision foundation models and address the intricate challenges in the field of computer vision. The paper’s advocacy for an interdisciplinary approach is underpinned by the belief that it will foster innovation and enable the development of models that are not only more efficient and adaptable but also capable of addressing complex and multifaceted problems in the real world.关键词:foundation model;computer vision(CV);pre-training model;self-supervised learning;multi-task learning709|467|0更新时间:2025-04-11 - “集成电路技术发展离不开半导体晶圆,其缺陷检测对保证芯片性能至关重要。综述了晶圆缺陷检测方法的研究进展,为提高晶圆良品率和生产率提供解决方案。”
 摘要:The integrated circuit chip is developed on a semiconductor wafer substrate and serves as a fundamental electronic component in many electronic devices. The semiconductor wafer, which is the foundation for manufacturing integrated circuits, contains billions of tiny electronic components. Production is gradually moving toward high-performance and small-sized directions because of the semiconductor industry’s demand for high-quality wafers. In the manufacturing process of wafers, unexpected structures may remain due to environmental, operational, and process-related reasons, leading to a decrease in the operational performance of the wafer chip. These unforeseen structures are referred to as wafer defects. The causes of wafer defects are diverse, with common types including scratches, pits, chemical stains, and dust contamination. The occurrence of unpredictable, mixed, and complex defects can result in increased production costs, decreased product yield, and a decline in manufacturing process stability. Therefore, defect detection on semiconductor wafers is crucial to ensure their performance and improve the yield of high-quality products. Currently, methods for detecting surface defects on semiconductor wafers include manual visual inspection, optical inspection, ultrasonic testing, and machine vision detection. Manual visual inspection involves operators using microscopes or the naked eye to check for obvious defects on the wafer surface, but this method has low efficiency and accuracy for detecting small defects. Optical inspection uses light sources to illuminate the wafer surface and determines the presence of defects by detecting the intensity and shape of reflected and transmitted light. This non-contact method is suitable for large-area defect detection but is less effective for detecting small and shallow defects and cannot identify internal defects within the wafer. Ultrasonic testing utilizes the propagation speed of ultrasonic waves in the wafer, along with the reflection and scattering characteristics of defects such as cracks and voids, but it is sensitive to material density and sound speed, leading to reduced detection effectiveness in specific material. In addition to these three methods, machine vision detection uses image processing and computer vision technology to detect defects on the wafer surface. It is a non-contact, high-speed, automated, cost-effective, and scalable approach, making machine vision-based detection the primary method in the wafer defect detection field today. With the development of computer vision, machine learning, and especially deep learning, the performance of defect identification and classification algorithms for semiconductor wafers has been further enhanced. This not only improves detection efficiency but also reduces production costs and enhances product quality. Machine vision-based detection methods generally fall into three categories: traditional image processing methods, machine learning methods, and deep learning methods. The development of many emerging technology fields today requires the support of integrated circuit technology. As a key role in integrated circuit chips, semiconductor wafers are prone to various defects due to complex manufacturing processes, and their failures will greatly affect the final performance of the chip and increase costs. Therefore, defect detection of semiconductor wafers is an important means to ensure its yield and productivity. Wafer defect detection combined with machine vision algorithms has strong universality and high speed and can better meet the relevant needs of industrial inspection. To have a deeper understanding of the research status of wafer defect detection, this paper conducts a comprehensive and thorough research on the defect detection method based on machine vision. Wafer manufacturing, its surface defect detection process, and the classification of wafer defects are introduced. The detection methods based on traditional image processing, machine learning, and deep learning algorithms are fully explored. Detection methods based on traditional image processing are divided according to the spatial domain and the transform domain. Detection methods based on the spatial domain include template matching, edge gradient, optical flow method, and spatial filtering method and are divided according to the correlation between the defect pattern and the template or the dissimilarity of the background. Detection methods based on the transform domain include wavelet transform, frequency filtering, and Fourier transform. Further research is being conducted on methods based on Fourier transform in the wavelet transform domain. It focuses on the application of machine learning and deep neural network in wafer defect detection. According to the learning method, the learning techniques utilized for wafer defect identification are divided into supervised machine learning, unsupervised machine learning, hybrid learning, semi-supervised learning, and transfer learning; according to the network category, deep neural networks for wafer defect detection is divided into detection network, classification network, segmentation network, and combination network. The detection performance and advantages and disadvantages of each method are compared in depth in each section. From the collected literature, it indicates that research on wafer defect detection based on transformer is increasing year by year. The large datasets shared in this field mainly include WM-811K and MixedWM38. Most of the datasets are not open to the public and are maintained and updated by teams or companies. Representative evaluation indicators mainly include single-label indicators of supervised learning/semi-supervised learning (accuracy, precision, recall, F1 score) and multi-label indicators (micro-precision, micro-recall, exact match ratio, Hamming loss). Unsupervised learning indicators include Rand index, adjusted Rand index, normalized mutual information, adjusted mutual information, and purity. Finally, the existing problems of the current vision-based wafer defect detection are identified, namely, low data availability, serious class imbalance problem, high computational complexity, and limited research on mixed-type defects. Future development trends include multimodal and non-destructive detection techniques and more efficient feature representation learning.关键词:semiconductor wafer;defect inspection;machine vision;deep neural network(DNN);machine learning;wafer defect dataset377|156|0更新时间:2025-04-11
摘要:The integrated circuit chip is developed on a semiconductor wafer substrate and serves as a fundamental electronic component in many electronic devices. The semiconductor wafer, which is the foundation for manufacturing integrated circuits, contains billions of tiny electronic components. Production is gradually moving toward high-performance and small-sized directions because of the semiconductor industry’s demand for high-quality wafers. In the manufacturing process of wafers, unexpected structures may remain due to environmental, operational, and process-related reasons, leading to a decrease in the operational performance of the wafer chip. These unforeseen structures are referred to as wafer defects. The causes of wafer defects are diverse, with common types including scratches, pits, chemical stains, and dust contamination. The occurrence of unpredictable, mixed, and complex defects can result in increased production costs, decreased product yield, and a decline in manufacturing process stability. Therefore, defect detection on semiconductor wafers is crucial to ensure their performance and improve the yield of high-quality products. Currently, methods for detecting surface defects on semiconductor wafers include manual visual inspection, optical inspection, ultrasonic testing, and machine vision detection. Manual visual inspection involves operators using microscopes or the naked eye to check for obvious defects on the wafer surface, but this method has low efficiency and accuracy for detecting small defects. Optical inspection uses light sources to illuminate the wafer surface and determines the presence of defects by detecting the intensity and shape of reflected and transmitted light. This non-contact method is suitable for large-area defect detection but is less effective for detecting small and shallow defects and cannot identify internal defects within the wafer. Ultrasonic testing utilizes the propagation speed of ultrasonic waves in the wafer, along with the reflection and scattering characteristics of defects such as cracks and voids, but it is sensitive to material density and sound speed, leading to reduced detection effectiveness in specific material. In addition to these three methods, machine vision detection uses image processing and computer vision technology to detect defects on the wafer surface. It is a non-contact, high-speed, automated, cost-effective, and scalable approach, making machine vision-based detection the primary method in the wafer defect detection field today. With the development of computer vision, machine learning, and especially deep learning, the performance of defect identification and classification algorithms for semiconductor wafers has been further enhanced. This not only improves detection efficiency but also reduces production costs and enhances product quality. Machine vision-based detection methods generally fall into three categories: traditional image processing methods, machine learning methods, and deep learning methods. The development of many emerging technology fields today requires the support of integrated circuit technology. As a key role in integrated circuit chips, semiconductor wafers are prone to various defects due to complex manufacturing processes, and their failures will greatly affect the final performance of the chip and increase costs. Therefore, defect detection of semiconductor wafers is an important means to ensure its yield and productivity. Wafer defect detection combined with machine vision algorithms has strong universality and high speed and can better meet the relevant needs of industrial inspection. To have a deeper understanding of the research status of wafer defect detection, this paper conducts a comprehensive and thorough research on the defect detection method based on machine vision. Wafer manufacturing, its surface defect detection process, and the classification of wafer defects are introduced. The detection methods based on traditional image processing, machine learning, and deep learning algorithms are fully explored. Detection methods based on traditional image processing are divided according to the spatial domain and the transform domain. Detection methods based on the spatial domain include template matching, edge gradient, optical flow method, and spatial filtering method and are divided according to the correlation between the defect pattern and the template or the dissimilarity of the background. Detection methods based on the transform domain include wavelet transform, frequency filtering, and Fourier transform. Further research is being conducted on methods based on Fourier transform in the wavelet transform domain. It focuses on the application of machine learning and deep neural network in wafer defect detection. According to the learning method, the learning techniques utilized for wafer defect identification are divided into supervised machine learning, unsupervised machine learning, hybrid learning, semi-supervised learning, and transfer learning; according to the network category, deep neural networks for wafer defect detection is divided into detection network, classification network, segmentation network, and combination network. The detection performance and advantages and disadvantages of each method are compared in depth in each section. From the collected literature, it indicates that research on wafer defect detection based on transformer is increasing year by year. The large datasets shared in this field mainly include WM-811K and MixedWM38. Most of the datasets are not open to the public and are maintained and updated by teams or companies. Representative evaluation indicators mainly include single-label indicators of supervised learning/semi-supervised learning (accuracy, precision, recall, F1 score) and multi-label indicators (micro-precision, micro-recall, exact match ratio, Hamming loss). Unsupervised learning indicators include Rand index, adjusted Rand index, normalized mutual information, adjusted mutual information, and purity. Finally, the existing problems of the current vision-based wafer defect detection are identified, namely, low data availability, serious class imbalance problem, high computational complexity, and limited research on mixed-type defects. Future development trends include multimodal and non-destructive detection techniques and more efficient feature representation learning.关键词:semiconductor wafer;defect inspection;machine vision;deep neural network(DNN);machine learning;wafer defect dataset377|156|0更新时间:2025-04-11 - “在海洋强国战略背景下,中国专家全面梳理了水下图像清晰化方法,为解决水下机器视觉感知难题提供解决方案。”
 摘要:Since the inception of the marine power strategy, there has been an increasing focus on an investigation into the quality of underwater images in the marine environment. However, unlike images captured in favorable terrestrial conditions, light propagation underwater is influenced by the absorption and scattering of the underwater medium. Light absorption can result in color distortion, reduced contrast, and diminished brightness in underwater images, while light scattering may cause haziness, loss of details, and noise amplification. The challenge posed by low-quality underwater images hinders effective machine vision in underwater environments. Therefore, researching effective methods for enhancing underwater machine vision has become a critical issue in the current field of underwater vision. This topic holds significant theoretical and practical significance for strengthening marine technological capabilities and promoting the sustained and healthy development of the marine economy. This paper provides a comprehensive overview of existing underwater image clarification methods, highlighting the strengths and disadvantages of each approach. For instance, image restoration based on methods relies on prior assumptions, but an excess of prior knowledge can result in difficulties with multi-parameter optimization and sensitivity to robustness. Meanwhile, image enhancement based on methods only considers the pixel information of the image and does not consider the imaging model, thereby risking noise amplification and local over-enhancement. Consequently, designing simple yet effective methods for underwater image clarification is crucial for improving the quality of underwater images. This paper provides a comprehensive overview of methods to enhance the quality of underwater images through an extensive exploration of image restoration and image enhancement techniques. It concludes with a summary of the methods and their merits and demerits. With regard to image restoration, the methods are categorized into four types: underwater optical imaging, polarization characteristics, prior knowledge, and deep learning. Optical imaging methods primarily consider the optical properties of the water itself, accounting for phenomena such as light attenuation, scattering, and absorption in the underwater environment. These methods rely on physical optical models to characterize underwater light propagation. Polarization characteristic methods involve collecting polarized images from the same scene, separating background light and scattered light, estimating light intensity and transmittance, and inversely obtaining clarified images. Prior methods guide image processing through prior information, and deep learning methods utilize deep neural network models to restore underwater images. For image enhancement-based methods, the overview includes frequency-domain, spatial-domain, color constancy, fusion-based, and deep learning methods. Frequency-domain methods process underwater images through convolution or spatial transformations to achieve enhancement. Spatial-domain methods directly act on image pixels, altering their intrinsic characteristics through techniques such as grayscale mapping, effectively improving image contrast and detail. Color constancy methods enhance images by leveraging color consistency present in the image. Fusion methods apply multiple algorithms to a single input image, generating enhanced versions. Subsequently, fusion weights are calculated for these enhanced images, and the final enhanced image is generated through image fusion. Regarding deep learning-based methods, the summary covers convolutional neural network (CNN)-based and generative adversarial network (GAN)-based approaches. The former employs CNNs to enhance underwater images by learning image features, structure, and deep network processing, whereas the latter utilizes generator and discriminator components in a GAN to enhance and restore underwater images. The paper then delves into a detailed discussion of each method’s innovations, advantages, and limitations, summarizing the above methods comprehensively. Additionally, several commonly used underwater datasets are introduced, and a qualitative and quantitative analysis is conducted on representative clarity methods. This paper provides a comprehensive overview and summary of the degradation issues in underwater images, methods for underwater image clarification, underwater image datasets, and underwater image quality assessment. We selected 11 classical underwater image clarity methods and tested them on standard underwater datasets. We compared and analyzed these methods using five quantitative evaluation metrics. Through qualitative and quantitative comparative analyses, we summarized the strengths and weaknesses of these representative clarity methods and underwater image quality assessment methods, better understanding the current research status in underwater image clarification and outlining future development prospects. This study offers a comprehensive review of methods aimed at enhancing and restoring underwater images. It underscores the significance of enhancing image quality and underscores the scientific and economic potential of underwater image clarification methods in applications such as marine resource development. The study serves as a valuable guide for future research and practices in related fields.关键词:underwater image quality degradation;scattering and absorption of light;underwater image clarity;underwater image quality evaluation407|324|0更新时间:2025-04-11
摘要:Since the inception of the marine power strategy, there has been an increasing focus on an investigation into the quality of underwater images in the marine environment. However, unlike images captured in favorable terrestrial conditions, light propagation underwater is influenced by the absorption and scattering of the underwater medium. Light absorption can result in color distortion, reduced contrast, and diminished brightness in underwater images, while light scattering may cause haziness, loss of details, and noise amplification. The challenge posed by low-quality underwater images hinders effective machine vision in underwater environments. Therefore, researching effective methods for enhancing underwater machine vision has become a critical issue in the current field of underwater vision. This topic holds significant theoretical and practical significance for strengthening marine technological capabilities and promoting the sustained and healthy development of the marine economy. This paper provides a comprehensive overview of existing underwater image clarification methods, highlighting the strengths and disadvantages of each approach. For instance, image restoration based on methods relies on prior assumptions, but an excess of prior knowledge can result in difficulties with multi-parameter optimization and sensitivity to robustness. Meanwhile, image enhancement based on methods only considers the pixel information of the image and does not consider the imaging model, thereby risking noise amplification and local over-enhancement. Consequently, designing simple yet effective methods for underwater image clarification is crucial for improving the quality of underwater images. This paper provides a comprehensive overview of methods to enhance the quality of underwater images through an extensive exploration of image restoration and image enhancement techniques. It concludes with a summary of the methods and their merits and demerits. With regard to image restoration, the methods are categorized into four types: underwater optical imaging, polarization characteristics, prior knowledge, and deep learning. Optical imaging methods primarily consider the optical properties of the water itself, accounting for phenomena such as light attenuation, scattering, and absorption in the underwater environment. These methods rely on physical optical models to characterize underwater light propagation. Polarization characteristic methods involve collecting polarized images from the same scene, separating background light and scattered light, estimating light intensity and transmittance, and inversely obtaining clarified images. Prior methods guide image processing through prior information, and deep learning methods utilize deep neural network models to restore underwater images. For image enhancement-based methods, the overview includes frequency-domain, spatial-domain, color constancy, fusion-based, and deep learning methods. Frequency-domain methods process underwater images through convolution or spatial transformations to achieve enhancement. Spatial-domain methods directly act on image pixels, altering their intrinsic characteristics through techniques such as grayscale mapping, effectively improving image contrast and detail. Color constancy methods enhance images by leveraging color consistency present in the image. Fusion methods apply multiple algorithms to a single input image, generating enhanced versions. Subsequently, fusion weights are calculated for these enhanced images, and the final enhanced image is generated through image fusion. Regarding deep learning-based methods, the summary covers convolutional neural network (CNN)-based and generative adversarial network (GAN)-based approaches. The former employs CNNs to enhance underwater images by learning image features, structure, and deep network processing, whereas the latter utilizes generator and discriminator components in a GAN to enhance and restore underwater images. The paper then delves into a detailed discussion of each method’s innovations, advantages, and limitations, summarizing the above methods comprehensively. Additionally, several commonly used underwater datasets are introduced, and a qualitative and quantitative analysis is conducted on representative clarity methods. This paper provides a comprehensive overview and summary of the degradation issues in underwater images, methods for underwater image clarification, underwater image datasets, and underwater image quality assessment. We selected 11 classical underwater image clarity methods and tested them on standard underwater datasets. We compared and analyzed these methods using five quantitative evaluation metrics. Through qualitative and quantitative comparative analyses, we summarized the strengths and weaknesses of these representative clarity methods and underwater image quality assessment methods, better understanding the current research status in underwater image clarification and outlining future development prospects. This study offers a comprehensive review of methods aimed at enhancing and restoring underwater images. It underscores the significance of enhancing image quality and underscores the scientific and economic potential of underwater image clarification methods in applications such as marine resource development. The study serves as a valuable guide for future research and practices in related fields.关键词:underwater image quality degradation;scattering and absorption of light;underwater image clarity;underwater image quality evaluation407|324|0更新时间:2025-04-11
Review

- “最新研究提出了一种小波非均匀扩散模型,有效去除图像阴影,恢复颜色亮度和细节,提升图像质量。”
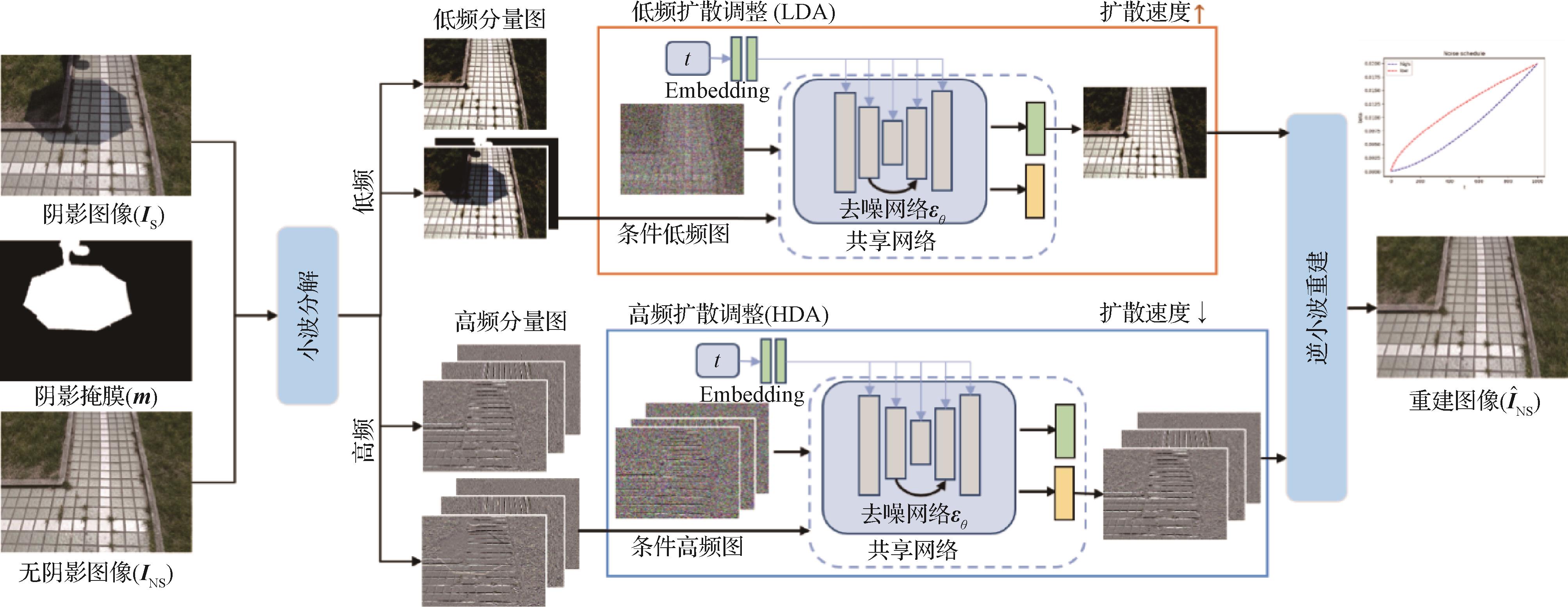 摘要:ObjectiveShadows are a common occurrence in optical images captured under partial or complete obstruction of light. In such images, shadow regions typically exhibit various forms of degradation, such as low contrast, color distortion, and loss of scene structure. Shadows not only impact the visual perception of humans but also impose constraints on the implementation of numerous sophisticated computer vision algorithms. Shadow removal can assist in many computer vision tasks. It aims to enhance the visibility of shadow regions in images and achieve consistent illumination distribution between shadow and non-shadow regions. Currently, deep learning-based shadow removal methods can be roughly divided into two categories. One typically utilizes deep learning to minimize the pixel-level differences between shadow regions and their corresponding non-shadow regions, aiming to learn deterministic mapping relationships between shadow and non-shadow images. However, the primary focus of shadow removal lies in locally restoring shadow regions, often overlooking the essential constraints required for effectively restoring boundaries between shadow and non-shadow regions. As a result, discrepancies in brightness exist between the restored shadow and non-shadow areas, along with the emergence of artifacts along the boundaries. Another approach involves using image generation models to directly model the complex distribution of shadow-free images, avoiding the direct learning of pixel-level mapping relationships, and treating shadow removal as a conditional generation task. While diffusion models have garnered significant attention due to their powerful generation capabilities, most existing diffusion generation models suffer from issues such as time-consuming image restoration and sensitivity to resolution when recovering images. Inspired by these challenges, a wavelet non-uniform diffusion model (WNDM) is proposed, which combines the advantages of wavelet decomposition and the generation ability of diffusion models to solve the above problems.MethodFirst, the image is decomposed into low-frequency and high-frequency components via wavelet decomposition. Then, diffusion generation networks are designed separately for low-frequency and high-frequency components to reconstruct the wavelet domain distribution of shadow-free images and restore various degraded information within these components, such as low-frequency (color, brightness) and high-frequency details. Wavelet transform can decompose the image into high-frequency and low-frequency images without sacrificing information, and the spatial size of the decomposed images is halved. Thus, modeling diffusion in the wavelet domain not only greatly accelerates model inference but also captures information that may be lost in the pixel domain. Furthermore, considering the complexity of the distribution of low-frequency and high-frequency components and their sensitivity to noise, for example, high-frequency components exhibit sparsity, making it easier for neural networks to learn their features. Hence, this study devises two separate adaptive diffusion noise scheduling tables tailored for low-frequency and high-frequency components. The branch for low-frequency diffusion adjustment independently fine-tunes the low-frequency information within shadow images, whereas the branch for high-frequency diffusion adjustment independently refines the high-frequency information within shadow images, resulting in the generation of more precise low-frequency and high-frequency images, respectively. Additionally, the low-frequency and high-frequency diffusion adjustment branches are consolidated to share a denoising network, thus streamlining model complexity and optimizing computational resources. The difference lies in the design of two prediction branches in the final layer of this network. These branches consist of several stacked convolution blocks, each predicting the low-frequency and high-frequency components of the shadow-free image, respectively. Finally, high-quality shadow-free images are reconstructed using inverse wavelet transform.ResultThe experiments were conducted on three shadow removal datasets for training and testing. On the shadow removal dataset (SRD) dataset, comparisons were made with nine state-of-the-art shadow removal algorithms. The proposed model achieved the best or second-best results in terms of peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and root mean square error (RMSE) in both non-shadow regions and the entire image. On the dataset with image shadow triplets dataset (ISTD), the performance was the best in non-shadow regions, with improvements of 0.36 dB in PSNR, 0.004 in SSIM, and 0.04 in RMSE compared with the second-best model. It ranked second in performance across all metrics for the entire image. On the augmented dataset with image shadow triplets (ISTD+), compared with six state-of-the-art shadow removal algorithms, the performance was the best in non-shadow regions, with improvements of 0.47 dB in PSNR and 0.1 in RMSE. Additionally, regarding the advanced shadow removal diffusion model ShadowDiffusion, the RMSE for the entire image was 3.63 on the SRD dataset when generating images of 256 × 256 pixels resolution. However, a significant performance drop occurred when generating images of the original resolution of 840 × 640 pixels, with RMSE increasing to 7.19. By contrast, our approach yielded RMSE values of 3.80 and 4.06 for images of dimensions 256 × 256 pixels and 840 × 640 pixels, respectively, showcasing consistent performance. Additionally, the time required to generate a single original image of size 840 × 640 pixels was reduced by roughly fourfold compared with ShadowDiffusion. Furthermore, our method was expanded to address image raindrop removal tasks, delivering competitive results on the RainDrop dataset.ConclusionIn this paper, the proposed method accelerates the sampling time of the diffusion model. While removing shadows, it restores missing color, brightness, and rich details in shadow regions. It treats shadow removal as an image generation task in the wavelet domain and designs two adaptive diffusion flows for the low-frequency and high-frequency components of the image wavelet domain to address the degradation of low-frequency (color, brightness) and high-frequency detail information caused by shadow images. Benefiting from the frequency decomposition of the wavelet transform, WNDM does not learn from the entangled pixel space domain but effectively separates and trains them separately, thereby generating more refined low-frequency and high-frequency information for reconstructing the final image. Extensive experiments on multiple datasets demonstrate the effectiveness of WNDM, achieving competitive results compared with state-of-the-art methods.关键词:shadow removal;diffusion model(DM);wavelet transform;dual-branch network;noise schedule189|129|0更新时间:2025-04-11
摘要:ObjectiveShadows are a common occurrence in optical images captured under partial or complete obstruction of light. In such images, shadow regions typically exhibit various forms of degradation, such as low contrast, color distortion, and loss of scene structure. Shadows not only impact the visual perception of humans but also impose constraints on the implementation of numerous sophisticated computer vision algorithms. Shadow removal can assist in many computer vision tasks. It aims to enhance the visibility of shadow regions in images and achieve consistent illumination distribution between shadow and non-shadow regions. Currently, deep learning-based shadow removal methods can be roughly divided into two categories. One typically utilizes deep learning to minimize the pixel-level differences between shadow regions and their corresponding non-shadow regions, aiming to learn deterministic mapping relationships between shadow and non-shadow images. However, the primary focus of shadow removal lies in locally restoring shadow regions, often overlooking the essential constraints required for effectively restoring boundaries between shadow and non-shadow regions. As a result, discrepancies in brightness exist between the restored shadow and non-shadow areas, along with the emergence of artifacts along the boundaries. Another approach involves using image generation models to directly model the complex distribution of shadow-free images, avoiding the direct learning of pixel-level mapping relationships, and treating shadow removal as a conditional generation task. While diffusion models have garnered significant attention due to their powerful generation capabilities, most existing diffusion generation models suffer from issues such as time-consuming image restoration and sensitivity to resolution when recovering images. Inspired by these challenges, a wavelet non-uniform diffusion model (WNDM) is proposed, which combines the advantages of wavelet decomposition and the generation ability of diffusion models to solve the above problems.MethodFirst, the image is decomposed into low-frequency and high-frequency components via wavelet decomposition. Then, diffusion generation networks are designed separately for low-frequency and high-frequency components to reconstruct the wavelet domain distribution of shadow-free images and restore various degraded information within these components, such as low-frequency (color, brightness) and high-frequency details. Wavelet transform can decompose the image into high-frequency and low-frequency images without sacrificing information, and the spatial size of the decomposed images is halved. Thus, modeling diffusion in the wavelet domain not only greatly accelerates model inference but also captures information that may be lost in the pixel domain. Furthermore, considering the complexity of the distribution of low-frequency and high-frequency components and their sensitivity to noise, for example, high-frequency components exhibit sparsity, making it easier for neural networks to learn their features. Hence, this study devises two separate adaptive diffusion noise scheduling tables tailored for low-frequency and high-frequency components. The branch for low-frequency diffusion adjustment independently fine-tunes the low-frequency information within shadow images, whereas the branch for high-frequency diffusion adjustment independently refines the high-frequency information within shadow images, resulting in the generation of more precise low-frequency and high-frequency images, respectively. Additionally, the low-frequency and high-frequency diffusion adjustment branches are consolidated to share a denoising network, thus streamlining model complexity and optimizing computational resources. The difference lies in the design of two prediction branches in the final layer of this network. These branches consist of several stacked convolution blocks, each predicting the low-frequency and high-frequency components of the shadow-free image, respectively. Finally, high-quality shadow-free images are reconstructed using inverse wavelet transform.ResultThe experiments were conducted on three shadow removal datasets for training and testing. On the shadow removal dataset (SRD) dataset, comparisons were made with nine state-of-the-art shadow removal algorithms. The proposed model achieved the best or second-best results in terms of peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and root mean square error (RMSE) in both non-shadow regions and the entire image. On the dataset with image shadow triplets dataset (ISTD), the performance was the best in non-shadow regions, with improvements of 0.36 dB in PSNR, 0.004 in SSIM, and 0.04 in RMSE compared with the second-best model. It ranked second in performance across all metrics for the entire image. On the augmented dataset with image shadow triplets (ISTD+), compared with six state-of-the-art shadow removal algorithms, the performance was the best in non-shadow regions, with improvements of 0.47 dB in PSNR and 0.1 in RMSE. Additionally, regarding the advanced shadow removal diffusion model ShadowDiffusion, the RMSE for the entire image was 3.63 on the SRD dataset when generating images of 256 × 256 pixels resolution. However, a significant performance drop occurred when generating images of the original resolution of 840 × 640 pixels, with RMSE increasing to 7.19. By contrast, our approach yielded RMSE values of 3.80 and 4.06 for images of dimensions 256 × 256 pixels and 840 × 640 pixels, respectively, showcasing consistent performance. Additionally, the time required to generate a single original image of size 840 × 640 pixels was reduced by roughly fourfold compared with ShadowDiffusion. Furthermore, our method was expanded to address image raindrop removal tasks, delivering competitive results on the RainDrop dataset.ConclusionIn this paper, the proposed method accelerates the sampling time of the diffusion model. While removing shadows, it restores missing color, brightness, and rich details in shadow regions. It treats shadow removal as an image generation task in the wavelet domain and designs two adaptive diffusion flows for the low-frequency and high-frequency components of the image wavelet domain to address the degradation of low-frequency (color, brightness) and high-frequency detail information caused by shadow images. Benefiting from the frequency decomposition of the wavelet transform, WNDM does not learn from the entangled pixel space domain but effectively separates and trains them separately, thereby generating more refined low-frequency and high-frequency information for reconstructing the final image. Extensive experiments on multiple datasets demonstrate the effectiveness of WNDM, achieving competitive results compared with state-of-the-art methods.关键词:shadow removal;diffusion model(DM);wavelet transform;dual-branch network;noise schedule189|129|0更新时间:2025-04-11 - “在图像处理领域,专家提出了一种解耦合三阶段增强网络,有效去除非均质雾霾图像中的雾霾并还原真实细节信息和颜色。”
 摘要:ObjectiveThe absorption or scattering effect of microscopic particles in the atmosphere, such as aerosols, soot, and haze, will reduce image contrast, blur image details, and cause color distortion. These problems can decrease the accuracy of subsequent advanced computer vision tasks, such as object detection and image segmentation. Therefore, image dehazing has attracted increasing attention, and various image dehazing methods have been proposed. The ultimate goal of image dehazing is to recover a haze-free image from the input hazy image. At present, existing image dehazing algorithms can be divided into two categories: traditional dehazing algorithms based on image prior and image dehazing algorithms based on deep learning. The image priori-based dehazing algorithm uses the prior information and empirical rules of the image itself to estimate the transmittance map and atmospheric light value, and it utilizes the atmospheric scattering model to realize the image dehazing process. This approach can improve the contrast of the image to a certain extent but easily leads to excessive enhancement or color distortions in the dehazed results. Driven by a large amount of image data, the image dehazing algorithm based on deep learning can flexibly learn the mapping from hazy image to haze-free images by directly constructing an efficient convolutional neural network and obtain dehazed effects with better generalization performance and human visual perception. However, because of domain differences, the image dehazing algorithm trained on the synthesized homogeneous haze dataset usually has difficulty achieving satisfactory results on heterogeneous hazy images in the real world.MethodHaze will reduce the contrast of the image and make it look blurry. Thus, we train the network (i.e., the contrast enhancement module) with the brightness map of the hazy image and the brightness map corresponding to the clear image as the training image pairs, which effectively enhances the contrast of the brightness map and obtains the brightness enhancement map with a clear image structure and details. Furthermore, we calculate the gradient differences of the brightness maps before and after the contrast enhancement process and estimate the haze density information in the hazy images to guide saturation enhancement of the hazy images. Therefore, we propose an end-to-end decoupled triple-stage enhancement network for the heterogeneous haze dehazing task, which decouples the input hazy image with color space conversion into three channels, i.e., brightness, saturation, hues. Our algorithm first enhances the contrast of the brightness map through the contrast enhancement module so that the dehazed result holds clear structure and detail information. Then, it enhances the saturation channel of the image through the saturation enhancement module so that the dehazed result takes on a more vivid color. Finally, the color correction and enhancement module is used to fine-tune the overall color of the image so that the final dehazed result will be more in line with human visual perception. In particular, we design a haze density coding matrix in the saturation enhancement module and estimate the haze density information of the hazy image by calculating the gradient differences of the brightness maps before and after the contrast enhancement process. This step will provide guidance for the saturation enhancement module to ensure the accuracy of saturation recovery. The U-Net network structure exhibits superior performance in image enhancement tasks. Thus, we choose U-Net as the backbone network of our contrast and saturation enhancement modules and obtain multi-scale information of images through the encoder and decoder structure for better dehazing results. For the color correction and enhancement module, we only need to fine-tune the previously enhanced image results, which is why we only use a simple network with convolutional layers and skip connections to prevent the loss of image information with upsampling and downsampling operations.ResultCompared with the second best-performing model in performance, the average peak signal-to-noise ratio is increased by 8.5 dB and the average structural similarity is increased by 0.12. Our perceived fog density prediction value is 0.47 and the estimated haze density is 0.21 in the real-world dataset, both of which rank first. In the SOTS dataset, our average peak signal-to-noise ratio is 16.52 dB and the average structural similarity is 0.80, which are comparable to the existing algorithms in terms of human visual perception.ConclusionThrough a series of subjective and objective experimental comparisons, the experimental results show that our algorithm has excellent processing ability for non-homogeneous hazy images and can effectively restore the real details and colors of hazy images.关键词:deep learning;non-homogeneous image dehazing;saturation enhancement;contrast enhancement;triple-stage enhancement152|171|0更新时间:2025-04-11
摘要:ObjectiveThe absorption or scattering effect of microscopic particles in the atmosphere, such as aerosols, soot, and haze, will reduce image contrast, blur image details, and cause color distortion. These problems can decrease the accuracy of subsequent advanced computer vision tasks, such as object detection and image segmentation. Therefore, image dehazing has attracted increasing attention, and various image dehazing methods have been proposed. The ultimate goal of image dehazing is to recover a haze-free image from the input hazy image. At present, existing image dehazing algorithms can be divided into two categories: traditional dehazing algorithms based on image prior and image dehazing algorithms based on deep learning. The image priori-based dehazing algorithm uses the prior information and empirical rules of the image itself to estimate the transmittance map and atmospheric light value, and it utilizes the atmospheric scattering model to realize the image dehazing process. This approach can improve the contrast of the image to a certain extent but easily leads to excessive enhancement or color distortions in the dehazed results. Driven by a large amount of image data, the image dehazing algorithm based on deep learning can flexibly learn the mapping from hazy image to haze-free images by directly constructing an efficient convolutional neural network and obtain dehazed effects with better generalization performance and human visual perception. However, because of domain differences, the image dehazing algorithm trained on the synthesized homogeneous haze dataset usually has difficulty achieving satisfactory results on heterogeneous hazy images in the real world.MethodHaze will reduce the contrast of the image and make it look blurry. Thus, we train the network (i.e., the contrast enhancement module) with the brightness map of the hazy image and the brightness map corresponding to the clear image as the training image pairs, which effectively enhances the contrast of the brightness map and obtains the brightness enhancement map with a clear image structure and details. Furthermore, we calculate the gradient differences of the brightness maps before and after the contrast enhancement process and estimate the haze density information in the hazy images to guide saturation enhancement of the hazy images. Therefore, we propose an end-to-end decoupled triple-stage enhancement network for the heterogeneous haze dehazing task, which decouples the input hazy image with color space conversion into three channels, i.e., brightness, saturation, hues. Our algorithm first enhances the contrast of the brightness map through the contrast enhancement module so that the dehazed result holds clear structure and detail information. Then, it enhances the saturation channel of the image through the saturation enhancement module so that the dehazed result takes on a more vivid color. Finally, the color correction and enhancement module is used to fine-tune the overall color of the image so that the final dehazed result will be more in line with human visual perception. In particular, we design a haze density coding matrix in the saturation enhancement module and estimate the haze density information of the hazy image by calculating the gradient differences of the brightness maps before and after the contrast enhancement process. This step will provide guidance for the saturation enhancement module to ensure the accuracy of saturation recovery. The U-Net network structure exhibits superior performance in image enhancement tasks. Thus, we choose U-Net as the backbone network of our contrast and saturation enhancement modules and obtain multi-scale information of images through the encoder and decoder structure for better dehazing results. For the color correction and enhancement module, we only need to fine-tune the previously enhanced image results, which is why we only use a simple network with convolutional layers and skip connections to prevent the loss of image information with upsampling and downsampling operations.ResultCompared with the second best-performing model in performance, the average peak signal-to-noise ratio is increased by 8.5 dB and the average structural similarity is increased by 0.12. Our perceived fog density prediction value is 0.47 and the estimated haze density is 0.21 in the real-world dataset, both of which rank first. In the SOTS dataset, our average peak signal-to-noise ratio is 16.52 dB and the average structural similarity is 0.80, which are comparable to the existing algorithms in terms of human visual perception.ConclusionThrough a series of subjective and objective experimental comparisons, the experimental results show that our algorithm has excellent processing ability for non-homogeneous hazy images and can effectively restore the real details and colors of hazy images.关键词:deep learning;non-homogeneous image dehazing;saturation enhancement;contrast enhancement;triple-stage enhancement152|171|0更新时间:2025-04-11
Image Processing and Coding
- “在图像识别领域,专家提出了BSGAN-GP模型,有效提升了少数类识别准确度,为深度学习图像识别提供新方案。”
 摘要:ObjectiveImage classification technology has realized high-precision automatic classification and screening of digital images with the improvement of algorithm performance and the development of computer hardware. This technology uses a computer to conduct a quantitative analysis of the image, classifying each area in the image or image into one of several categories to replace human visual interpretation. However, in practice, a large number of training samples and high-quality annotation information are required for high-quality training to obtain high-accuracy classification results. For large-scale image datasets, existing image annotation methods need to be performed manually by industry experts, such as polygon annotation and key point annotation. As a result of the high cost of expert annotation and the difficulty of high-quality annotation, less image data are labeled, thus seriously hindering the development of deep learning in computer vision. To this end, the semi-supervised generative adversarial network (GAN) paradigm is proposed because it can use a large amount of unlabeled data to obtain the distribution characteristics of real samples in the feature space and more accurately determine the classification boundaries. The generative semi-supervised GAN model, such as DCGAN and semi-supervised GAN, can create new samples and increase sample diversity, thus being more widely used in various fields. However, this model is often unstable in adversarial training; especially on an unbalanced dataset, the gradient can easily fall into the trap of predicting most of the data. Image datasets in real-world industrial applications are often category-unbalanced, which is why this imbalance negatively affects the accuracy of mining classifiers. Several recent studies have revealed the effectiveness of GAN, such as DAGAN, BSSGAN, BAGAN, and improve-BAGAN, in alleviating the problem of imbalance. Among them, BAGAN acts as an enhancement method to recover the balance in unbalanced datasets, which can learn useful features from most classes and use these features to generate images for minority classes. However, the experimental results show that its encoder lost many details in the image reconstruction process, making the appearance of similar categories not easy to distinguish in the reconstructed figures. Improve-BAGAN improves the BAGAN, and increasing the gradient penalty makes the model training more stable. Improve-BAGAN is the state-of-the-art achievement of existing supervised learning to solve unbalanced problems, but achieving the expected results of the model requires manual labeling of a sufficient number of samples, which greatly increases the labor and time costs.MethodIn this study, a new balanced image recognition model based on semi-supervised GAN is established, enabling the discriminator of semi-supervised GAN to fairly identify every class of unbalanced dataset. The proposed balanced image recognition model BSGAN-GP consists of two components: the category balancing random selection (CBRS) algorithm and the discriminator for adding gradient penalty. For the brand-new CBRS algorithm, we randomly selected the label data in the real data by category so that the number of labels in each class in the input model is consistent, ensuring a balance between the real sample and the generator synthesis sample. Then, we conduct confrontation training, and the generator NetG with fixed parameters generates the same number of false sample input discriminators for each class. We then update the discriminator NetD to ensure that the discriminator can fairly judge all classes to improve the identification accuracy of the minority classes. BSGAN-GP adds an additional gradient penalty item in the discriminator loss function to stabilize the model training. The optimizer selected for the experiment was the Adam algorithm, with the learning rate set to 0.000 2 and the momentum set to (0.5, 0.9). The batch size for all three datasets was 100, where the MNIST and Fashion datasets were set to 1 000, or 100 per class and 5 000 for SVHN, or 500 per class. The experiment used an RTX 4090 GPU and 24 GB of memory. Most studies in the experiment were completed within 4 500 s. For MNIST and Fashion-MNIST, we trained 25 epochs, each of which took 85 s and 108 s, respectively, on our device. For the SVHN, we trained 30 epochs, with each epoch requiring 110 s on our device.ResultThe experiment is compared with six semi-supervised methods and three fully supervised parties in the three mainstream datasets. An unbalanced version of the three datasets is developed to prove the improved identification accuracy of a few classes. The experimental indicators include overall accuracy, category recognition rate, confusion matrix, and synthesized images. In the unbalanced Fashion-MNIST, compared with the semi-supervised GAN, the overall accuracy value increased by 3.281%, and the minority class recognition rate increased by 7.14%. In the unbalanced MNIST, the recognition rate of the corresponding four minority classes increased by 2.68% to 7.40% compared with the semi-supervised GAN. In the SVHN, the overall accuracy value increased by 3.515% compared with the semi-supervised GAN. Quality comparison of synthetic images was also conducted in three datasets to verify the effectiveness of the CBRS algorithm, and the improvement of synthetic images on the quantity and quality of a few classes proved its effect. Ablation experiments evaluate the importance of the proposed module CBRS versus the introduced module in the network. The CBRS module improved the overall accuracy of the model by 2% to 3%, and the GP module improved the overall accuracy of the model by 0.8% to 1.8%.ConclusionIn this study, we propose a new algorithm called CBRS to achieve fair recognition of all classes in unbalanced datasets. We introduced a gradient penalty into the discriminator of semi-supervised GANs for more stable training. Experiment results indicate that CBRS can achieve fairer image recognition and higher-quality synthesized image results.关键词:deep learning;semi-supervised learning(SSL);generative adversarial network(GAN);unbalanced image recognition;gradient punishment141|142|0更新时间:2025-04-11
摘要:ObjectiveImage classification technology has realized high-precision automatic classification and screening of digital images with the improvement of algorithm performance and the development of computer hardware. This technology uses a computer to conduct a quantitative analysis of the image, classifying each area in the image or image into one of several categories to replace human visual interpretation. However, in practice, a large number of training samples and high-quality annotation information are required for high-quality training to obtain high-accuracy classification results. For large-scale image datasets, existing image annotation methods need to be performed manually by industry experts, such as polygon annotation and key point annotation. As a result of the high cost of expert annotation and the difficulty of high-quality annotation, less image data are labeled, thus seriously hindering the development of deep learning in computer vision. To this end, the semi-supervised generative adversarial network (GAN) paradigm is proposed because it can use a large amount of unlabeled data to obtain the distribution characteristics of real samples in the feature space and more accurately determine the classification boundaries. The generative semi-supervised GAN model, such as DCGAN and semi-supervised GAN, can create new samples and increase sample diversity, thus being more widely used in various fields. However, this model is often unstable in adversarial training; especially on an unbalanced dataset, the gradient can easily fall into the trap of predicting most of the data. Image datasets in real-world industrial applications are often category-unbalanced, which is why this imbalance negatively affects the accuracy of mining classifiers. Several recent studies have revealed the effectiveness of GAN, such as DAGAN, BSSGAN, BAGAN, and improve-BAGAN, in alleviating the problem of imbalance. Among them, BAGAN acts as an enhancement method to recover the balance in unbalanced datasets, which can learn useful features from most classes and use these features to generate images for minority classes. However, the experimental results show that its encoder lost many details in the image reconstruction process, making the appearance of similar categories not easy to distinguish in the reconstructed figures. Improve-BAGAN improves the BAGAN, and increasing the gradient penalty makes the model training more stable. Improve-BAGAN is the state-of-the-art achievement of existing supervised learning to solve unbalanced problems, but achieving the expected results of the model requires manual labeling of a sufficient number of samples, which greatly increases the labor and time costs.MethodIn this study, a new balanced image recognition model based on semi-supervised GAN is established, enabling the discriminator of semi-supervised GAN to fairly identify every class of unbalanced dataset. The proposed balanced image recognition model BSGAN-GP consists of two components: the category balancing random selection (CBRS) algorithm and the discriminator for adding gradient penalty. For the brand-new CBRS algorithm, we randomly selected the label data in the real data by category so that the number of labels in each class in the input model is consistent, ensuring a balance between the real sample and the generator synthesis sample. Then, we conduct confrontation training, and the generator NetG with fixed parameters generates the same number of false sample input discriminators for each class. We then update the discriminator NetD to ensure that the discriminator can fairly judge all classes to improve the identification accuracy of the minority classes. BSGAN-GP adds an additional gradient penalty item in the discriminator loss function to stabilize the model training. The optimizer selected for the experiment was the Adam algorithm, with the learning rate set to 0.000 2 and the momentum set to (0.5, 0.9). The batch size for all three datasets was 100, where the MNIST and Fashion datasets were set to 1 000, or 100 per class and 5 000 for SVHN, or 500 per class. The experiment used an RTX 4090 GPU and 24 GB of memory. Most studies in the experiment were completed within 4 500 s. For MNIST and Fashion-MNIST, we trained 25 epochs, each of which took 85 s and 108 s, respectively, on our device. For the SVHN, we trained 30 epochs, with each epoch requiring 110 s on our device.ResultThe experiment is compared with six semi-supervised methods and three fully supervised parties in the three mainstream datasets. An unbalanced version of the three datasets is developed to prove the improved identification accuracy of a few classes. The experimental indicators include overall accuracy, category recognition rate, confusion matrix, and synthesized images. In the unbalanced Fashion-MNIST, compared with the semi-supervised GAN, the overall accuracy value increased by 3.281%, and the minority class recognition rate increased by 7.14%. In the unbalanced MNIST, the recognition rate of the corresponding four minority classes increased by 2.68% to 7.40% compared with the semi-supervised GAN. In the SVHN, the overall accuracy value increased by 3.515% compared with the semi-supervised GAN. Quality comparison of synthetic images was also conducted in three datasets to verify the effectiveness of the CBRS algorithm, and the improvement of synthetic images on the quantity and quality of a few classes proved its effect. Ablation experiments evaluate the importance of the proposed module CBRS versus the introduced module in the network. The CBRS module improved the overall accuracy of the model by 2% to 3%, and the GP module improved the overall accuracy of the model by 0.8% to 1.8%.ConclusionIn this study, we propose a new algorithm called CBRS to achieve fair recognition of all classes in unbalanced datasets. We introduced a gradient penalty into the discriminator of semi-supervised GANs for more stable training. Experiment results indicate that CBRS can achieve fairer image recognition and higher-quality synthesized image results.关键词:deep learning;semi-supervised learning(SSL);generative adversarial network(GAN);unbalanced image recognition;gradient punishment141|142|0更新时间:2025-04-11 - “在图像分类领域,FDPRNet通过特征重排列注意力机制和双池化残差结构,显著提升了分类准确率和模型泛化能力。”
 摘要:ObjectiveA residual classification network is a deep convolutional neural network architecture that plays an important role and has a considerable influence in the field of deep learning. It has become one of the commonly used network structures in various image classification tasks in the field of computer vision. To solve the problem of network degradation in deep networks, unlike the traditional method of simply stacking convolutional layers, residual networks innovatively introduce residual connections, which directly add input features to output features through skip connections, and pass the original features directly to subsequent network layers. It forms a shortcut path, thereby preserving and utilizing feature information better. Although residual classification network effectively solves the problems of gradient explosion and vanishing during deep network training, when the output dimension of the residual block does not match the input dimension, convolution maps are needed to ensure the same dimensions, which causes a large number of pixels on the channel matrix in the residual module to be skipped, resulting in the problem of feature information loss. In addition, correlation exists between image channels, and a fixed order of channels may lead to feature bias, making it difficult to fully utilize information from other channels and limiting the model’s ability to express key features. In response to the above issues, this article proposes a double pooling residual classification network of feature reordering attention mechanism (FDPRNet).MethodFDPRNet is based on the ResNet-34 residual network. First, the kernel size of the first convolutional layer is changed from 7 × 7 to 3 × 3. This change is made because, for relatively small images, larger convolutional kernels can cause the receptive field to become larger, capturing too much useless contextual information. Time, the maximum pooling layer is removed to prevent the feature map from shrinking further, retaining more image information, avoiding information loss caused by pooling operations, and making it easier for subsequent network layers to extract features better. Then, a feature reordering attention module (FRAM) is proposed to group the feature map channels and perform inter-group and intra-group reordering so that adjacent channels are no longer connected, and the intra-group channels are grouped in a sequence of equal differences with a step size of 1. This operation can not only disrupt the order of some original channels before and after but also preserve the relationship between some channels before and after, introducing a certain degree of randomness, allowing the model to comprehensively consider the interaction between different channels, and avoiding excessive dependence on specific channels. The features of each channel combination are extracted and spliced by one-dimensional convolution, and then the sigmoid activation function is used to obtain the weights of the rearranged features, which are multiplied element by element with the input features to obtain the feature map of the feature rearranged attention mechanism. Finally, a double pooling residual (DPR) module is proposed, which uses both maximum pooling and average pooling to perform parallel operations on feature maps. This module obtains both salient and typical features of the input images, enhancing the expressive power of features and helping the network capture important information better in the images, thereby improving model performance. Element-by-element summation and convolutional mapping on the after-pooling feature maps are performed to extract key features, reduce the size of the feature maps, and ensure that the channel matrices are capable of element-level summation operations in residual concatenation.ResultIn the CIFAR-100, CIFAR-10, SVHN, Flowers-102, and NWPU-RESISC45 datasets, compared with the original model ResNet-34, the accuracy of ResNet-34 with the addition of FRAM is improved by 1.66%, 0.19%, 0.13%, 4.28%, and 2.00%, respectively. The accuracy of ResNet-34 with the addition of DPR is improved by 1.7%, 0.26%, 0.12%, 3.18%, and 1.31%, respectively. The accuracy of FDPRNet, which is the combination of the FRAM and DPR modules, is improved by 2.07%, 0.3%, 0.17%, 8.31%, and 2.47%, respectively. Compared with four attention mechanisms—squeeze and excitation, efficient channel attention, coordinate attention, and convolutional block attention module, the accuracy of FRAM is improved by an average of 0.72%, 1.28%, and 1.46% in the CIFAR-100, Flowers-102, and STL-10 datasets. In summary, whether on small or large, less categorized, or more categorized datasets, both the FRAM and DPR modules contribute to the improvement of recognition accuracy in the ResNet-34 network. The combination of the two modules—FDPR—has the best effect on improving the recognition rate of the network and achieves a significant improvement in accuracy compared with other image classification networks.ConclusionThe proposed FDPRNet can enhance the information exchange within the image channel and reduce feature loss. It not only shows high classification accuracy but also effectively enhances the network’s feature learning ability and model generalization ability. The main contributions of this article are as follows: 1) FRAM is proposed, which breaks the connections between the original channels and groups them according to certain rules. Learning the weights of channel combinations in different orders ensures that the channels between different groups interact without losing the front and back connections between all channels, achieving information exchange and channel crossing within the feature map, enhancing the interaction between features, better capturing the correlation between contextual information and features, and improving the accuracy of model classification. 2) DPR is proposed, which replaces the skip connections in the original residual block with a DPR module, solving the problem of feature information loss caused by a large number of pixel points being skipped in the channel matrix during the skip connections in the residual module. Using dual pooling to obtain salient and typical features of input images can not only enhance the expression ability of features but also help the network better capture important information in images and improve model classification performance. 3) The proposed FDPRNet inserts two modules—FRAM and DPR—into the residual network to enhance network channel interaction and feature expression capabilities, enabling the network model to capture complex relationships and strong generalization ability. It achieved high classification accuracy on some mainstream image classification datasets.关键词:image classification;feature rearrangement;attention mechanism;residual network;deep learning109|110|0更新时间:2025-04-11
摘要:ObjectiveA residual classification network is a deep convolutional neural network architecture that plays an important role and has a considerable influence in the field of deep learning. It has become one of the commonly used network structures in various image classification tasks in the field of computer vision. To solve the problem of network degradation in deep networks, unlike the traditional method of simply stacking convolutional layers, residual networks innovatively introduce residual connections, which directly add input features to output features through skip connections, and pass the original features directly to subsequent network layers. It forms a shortcut path, thereby preserving and utilizing feature information better. Although residual classification network effectively solves the problems of gradient explosion and vanishing during deep network training, when the output dimension of the residual block does not match the input dimension, convolution maps are needed to ensure the same dimensions, which causes a large number of pixels on the channel matrix in the residual module to be skipped, resulting in the problem of feature information loss. In addition, correlation exists between image channels, and a fixed order of channels may lead to feature bias, making it difficult to fully utilize information from other channels and limiting the model’s ability to express key features. In response to the above issues, this article proposes a double pooling residual classification network of feature reordering attention mechanism (FDPRNet).MethodFDPRNet is based on the ResNet-34 residual network. First, the kernel size of the first convolutional layer is changed from 7 × 7 to 3 × 3. This change is made because, for relatively small images, larger convolutional kernels can cause the receptive field to become larger, capturing too much useless contextual information. Time, the maximum pooling layer is removed to prevent the feature map from shrinking further, retaining more image information, avoiding information loss caused by pooling operations, and making it easier for subsequent network layers to extract features better. Then, a feature reordering attention module (FRAM) is proposed to group the feature map channels and perform inter-group and intra-group reordering so that adjacent channels are no longer connected, and the intra-group channels are grouped in a sequence of equal differences with a step size of 1. This operation can not only disrupt the order of some original channels before and after but also preserve the relationship between some channels before and after, introducing a certain degree of randomness, allowing the model to comprehensively consider the interaction between different channels, and avoiding excessive dependence on specific channels. The features of each channel combination are extracted and spliced by one-dimensional convolution, and then the sigmoid activation function is used to obtain the weights of the rearranged features, which are multiplied element by element with the input features to obtain the feature map of the feature rearranged attention mechanism. Finally, a double pooling residual (DPR) module is proposed, which uses both maximum pooling and average pooling to perform parallel operations on feature maps. This module obtains both salient and typical features of the input images, enhancing the expressive power of features and helping the network capture important information better in the images, thereby improving model performance. Element-by-element summation and convolutional mapping on the after-pooling feature maps are performed to extract key features, reduce the size of the feature maps, and ensure that the channel matrices are capable of element-level summation operations in residual concatenation.ResultIn the CIFAR-100, CIFAR-10, SVHN, Flowers-102, and NWPU-RESISC45 datasets, compared with the original model ResNet-34, the accuracy of ResNet-34 with the addition of FRAM is improved by 1.66%, 0.19%, 0.13%, 4.28%, and 2.00%, respectively. The accuracy of ResNet-34 with the addition of DPR is improved by 1.7%, 0.26%, 0.12%, 3.18%, and 1.31%, respectively. The accuracy of FDPRNet, which is the combination of the FRAM and DPR modules, is improved by 2.07%, 0.3%, 0.17%, 8.31%, and 2.47%, respectively. Compared with four attention mechanisms—squeeze and excitation, efficient channel attention, coordinate attention, and convolutional block attention module, the accuracy of FRAM is improved by an average of 0.72%, 1.28%, and 1.46% in the CIFAR-100, Flowers-102, and STL-10 datasets. In summary, whether on small or large, less categorized, or more categorized datasets, both the FRAM and DPR modules contribute to the improvement of recognition accuracy in the ResNet-34 network. The combination of the two modules—FDPR—has the best effect on improving the recognition rate of the network and achieves a significant improvement in accuracy compared with other image classification networks.ConclusionThe proposed FDPRNet can enhance the information exchange within the image channel and reduce feature loss. It not only shows high classification accuracy but also effectively enhances the network’s feature learning ability and model generalization ability. The main contributions of this article are as follows: 1) FRAM is proposed, which breaks the connections between the original channels and groups them according to certain rules. Learning the weights of channel combinations in different orders ensures that the channels between different groups interact without losing the front and back connections between all channels, achieving information exchange and channel crossing within the feature map, enhancing the interaction between features, better capturing the correlation between contextual information and features, and improving the accuracy of model classification. 2) DPR is proposed, which replaces the skip connections in the original residual block with a DPR module, solving the problem of feature information loss caused by a large number of pixel points being skipped in the channel matrix during the skip connections in the residual module. Using dual pooling to obtain salient and typical features of input images can not only enhance the expression ability of features but also help the network better capture important information in images and improve model classification performance. 3) The proposed FDPRNet inserts two modules—FRAM and DPR—into the residual network to enhance network channel interaction and feature expression capabilities, enabling the network model to capture complex relationships and strong generalization ability. It achieved high classification accuracy on some mainstream image classification datasets.关键词:image classification;feature rearrangement;attention mechanism;residual network;deep learning109|110|0更新时间:2025-04-11 - “在行为识别领域,研究者提出了基于判别行为信息增量学习的空—地场景多视角行为识别方法,显著提高了网络的特征学习能力,为多视角任务提供了新解决方案。”
 摘要:ObjectiveWith the increasing demand for urban security of people, ground devices are combined with air devices, such as drones, for identifying action in air-ground scenarios. Meanwhile, the extensive ground-based camera networks and a wealth of ground surveillance data can offer reliable support to these aerial surveillance devices. How to effectively utilize the mobility of these aerial devices is a topic that warrants further research. Existing multi-view action recognition methods focus only on the difference in discriminative action information when the horizontal spatial view changes, but do not consider the difference in discriminative action information when the vertical spatial view changes. The high mobility of aerial perspectives can lead to changes in the vertical spatial perspective. According to the principles of perspective, observing the same object from different heights results in a significant change in appearance. This, in turn, causes substantial differences in the appearance of the same person’s actions when observed from high-altitude and ground-level perspectives. These significant variations in action appearance are referred to as differences in discriminative action information, and they pose a challenge for traditional multi-view action recognition methods in effectively addressing the issue of vertical spatial perspective changes.MethodWhen the viewing perspective aligns with the objects being observed in the same horizontal spatial plane, the most comprehensive and rich discriminative action information can be observed. Networks can easily learn and comprehend this information. However, when the viewing perspective is in a different horizontal spatial plane from the observed objects, inclined perspective occurs, resulting in a significant change in action appearance. This transition from a ground-level perspective to an aerial perspective leads to insufficiently observed information and a reduction in the discriminative action information. When networks attempt to learn and understand this information, misclassifications are more likely to occur. Therefore, on the basis of the amount of discriminative action information, ground-level perspective information can be considered as easily learned and understood simple information, while aerial perspective information can be seen as complex information that is challenging to learn and understand. In fact, the human brain follows a progressive learning process when dealing with various types of information, prioritizing the processing of simple information and using the learned simple information to assist in learning complex information. In the vertical spatial multi-view action recognition task, differences in perspectives and environmental influences lead to varying amounts of discriminative action information observed at different heights. In this chapter, we adopt a brain-like approach. We rank samples from the aerial perspective on the basis of the amount of discriminative action information they contain. Complex samples contain less discriminative action information, and networks find them challenging to learn and understand. Simple samples contain more discriminative action information and are easier for networks to learn and comprehend. We then distill discriminative action information separately from simple and complex samples. Within the same action category, despite differences in the amount of discriminative action information between simple and complex samples, the represented action categories should have commonalities. Therefore, by using the discriminative action information incremental learning method, we incrementally inject the rich discriminative action information learned from simple samples into the feature information of complex samples. This approach addresses the issue of complex samples carrying insufficient discriminative action information, allowing complex samples to learn more discriminative action information with the assistance of simple samples. Thus, networks can learn and understand complex samples easily. This paper proposes a discriminative action information incremental learning (DAIL) for multi-view action recognition in complex air-ground scenes and to distinguish the ground view from the air view on the basis of the view height and the amount of information. This paper utilizes a neuromorphic learning knowledge referred to as “ordered incremental progression” to distill discriminative action information for different views separately. Discriminative action information is incremented from the ground-view (simple) samples into the air-view (complex) samples to assist the network in learning and understanding the air-view samples.ResultThe method is experimentally validated on two datasets, namely, Drone-Action and unmanned aerial vehicle(UAV). The accuracy of the two datasets is improved by 18.0% and 16.2%, respectively, compared with that of the current state-of-the-art method SBP. Compared with the strong baseline method, our method reduces the parameters by 2.4 M and the FLOPS by 6.9 G on the UAV dataset. To validate the effectiveness of our proposed method in scenarios involving both ground-level and aerial perspectives, we introduced two datasets: N-UCLA (comprising samples exclusively from ground-based cameras with rich discriminative behavior information) and Drone-Action (comprising a mix of ground-level and aerial samples, where aerial samples contain relatively limited discriminative behavior information). A joint analysis of discriminative behavior information ranking was conducted on these datasets. Our findings indicate that enhancing complex samples using simpler ones significantly improves the network’s feature learning capacity. Conversely, attempting the reverse can lead reduce the accuracy. This observation aligns with the way the human brain processes information, embodying the concept of progressive learning.ConclusionIn this study, we proposed DAIL for multi-view action recognition in complex air-ground scenes and to distinguish the ground view from the air view on the basis of the view height and the amount of information. Experiment results show that our model outperforms several state-of-the-art multi-view approaches and improves the performance.关键词:multi-view action recognition;incremental learning;sample classification;discriminative action information;distillation learning87|116|0更新时间:2025-04-11
摘要:ObjectiveWith the increasing demand for urban security of people, ground devices are combined with air devices, such as drones, for identifying action in air-ground scenarios. Meanwhile, the extensive ground-based camera networks and a wealth of ground surveillance data can offer reliable support to these aerial surveillance devices. How to effectively utilize the mobility of these aerial devices is a topic that warrants further research. Existing multi-view action recognition methods focus only on the difference in discriminative action information when the horizontal spatial view changes, but do not consider the difference in discriminative action information when the vertical spatial view changes. The high mobility of aerial perspectives can lead to changes in the vertical spatial perspective. According to the principles of perspective, observing the same object from different heights results in a significant change in appearance. This, in turn, causes substantial differences in the appearance of the same person’s actions when observed from high-altitude and ground-level perspectives. These significant variations in action appearance are referred to as differences in discriminative action information, and they pose a challenge for traditional multi-view action recognition methods in effectively addressing the issue of vertical spatial perspective changes.MethodWhen the viewing perspective aligns with the objects being observed in the same horizontal spatial plane, the most comprehensive and rich discriminative action information can be observed. Networks can easily learn and comprehend this information. However, when the viewing perspective is in a different horizontal spatial plane from the observed objects, inclined perspective occurs, resulting in a significant change in action appearance. This transition from a ground-level perspective to an aerial perspective leads to insufficiently observed information and a reduction in the discriminative action information. When networks attempt to learn and understand this information, misclassifications are more likely to occur. Therefore, on the basis of the amount of discriminative action information, ground-level perspective information can be considered as easily learned and understood simple information, while aerial perspective information can be seen as complex information that is challenging to learn and understand. In fact, the human brain follows a progressive learning process when dealing with various types of information, prioritizing the processing of simple information and using the learned simple information to assist in learning complex information. In the vertical spatial multi-view action recognition task, differences in perspectives and environmental influences lead to varying amounts of discriminative action information observed at different heights. In this chapter, we adopt a brain-like approach. We rank samples from the aerial perspective on the basis of the amount of discriminative action information they contain. Complex samples contain less discriminative action information, and networks find them challenging to learn and understand. Simple samples contain more discriminative action information and are easier for networks to learn and comprehend. We then distill discriminative action information separately from simple and complex samples. Within the same action category, despite differences in the amount of discriminative action information between simple and complex samples, the represented action categories should have commonalities. Therefore, by using the discriminative action information incremental learning method, we incrementally inject the rich discriminative action information learned from simple samples into the feature information of complex samples. This approach addresses the issue of complex samples carrying insufficient discriminative action information, allowing complex samples to learn more discriminative action information with the assistance of simple samples. Thus, networks can learn and understand complex samples easily. This paper proposes a discriminative action information incremental learning (DAIL) for multi-view action recognition in complex air-ground scenes and to distinguish the ground view from the air view on the basis of the view height and the amount of information. This paper utilizes a neuromorphic learning knowledge referred to as “ordered incremental progression” to distill discriminative action information for different views separately. Discriminative action information is incremented from the ground-view (simple) samples into the air-view (complex) samples to assist the network in learning and understanding the air-view samples.ResultThe method is experimentally validated on two datasets, namely, Drone-Action and unmanned aerial vehicle(UAV). The accuracy of the two datasets is improved by 18.0% and 16.2%, respectively, compared with that of the current state-of-the-art method SBP. Compared with the strong baseline method, our method reduces the parameters by 2.4 M and the FLOPS by 6.9 G on the UAV dataset. To validate the effectiveness of our proposed method in scenarios involving both ground-level and aerial perspectives, we introduced two datasets: N-UCLA (comprising samples exclusively from ground-based cameras with rich discriminative behavior information) and Drone-Action (comprising a mix of ground-level and aerial samples, where aerial samples contain relatively limited discriminative behavior information). A joint analysis of discriminative behavior information ranking was conducted on these datasets. Our findings indicate that enhancing complex samples using simpler ones significantly improves the network’s feature learning capacity. Conversely, attempting the reverse can lead reduce the accuracy. This observation aligns with the way the human brain processes information, embodying the concept of progressive learning.ConclusionIn this study, we proposed DAIL for multi-view action recognition in complex air-ground scenes and to distinguish the ground view from the air view on the basis of the view height and the amount of information. Experiment results show that our model outperforms several state-of-the-art multi-view approaches and improves the performance.关键词:multi-view action recognition;incremental learning;sample classification;discriminative action information;distillation learning87|116|0更新时间:2025-04-11 - “在羽毛球定位跟踪领域,STNet算法通过热力图轮廓检测和时域特征提取,实现了羽毛球的准确定位和稳定跟踪,性能优于现有方法。”
 摘要:ObjectiveBadminton has become one of the most popular sports in the world today. Badminton match videos contain a wealth of useful information, and extracting this information can provide data support for precise analysis of sports. Among various types of information, badminton trajectory information is particularly important, as it can extract ball speed, athlete explosiveness, and shuttlecock trajectory data from the positioning information of the shuttlecock. Compared with general video object detection and tracking tasks, real-time localization tracking in badminton videos faces two major challenges: 1) Shuttlecocks are small targets with severe motion blur and interference from similar objects. The accuracy of object detection and tracking methods based on rectangular bounding boxes is low and can cause centroid estimation errors. 2) Locating the shuttlecock target accurately in a single-frame image is difficult, but its position can be tracked using temporal features from adjacent video frames. However, existing network modules for extracting temporal features are complex and struggle to meet real-time requirements. Early research on badminton localization and tracking mainly included threshold-based methods and feature learning-based methods, which performed well in specific scenarios. However, these methods focused only on target information during model construction, making it difficult to utilize background information. As a result, their localization and tracking performance suffer in complex environments. Currently, most deep learning-based object detection and tracking methods are based on rectangular bounding box algorithms. However, shuttlecocks exhibit severe motion blur in single-frame images, making it difficult for the rectangular box algorithm to accurately locate the shuttlecock target’s pixel coordinates. Subsequently, a localization method based on heatmap contour detection emerged, which overcame the limitations of rectangular bounding box methods by directly determining the pixel position of the shuttlecock’s head center by using segmentation and morphological detection methods. However, current approaches based on heatmap contour detection have weak capabilities in extracting spatiotemporal features for video object localization and tracking, making them inadequate for real-world requirements. To enhance the network’s ability to extract temporal and spatial features from video frames, we propose a new badminton localization tracking network algorithm named shuttlecock track net (STNet) based on heatmap contour detection.MethodThe backbone of the STNet network adopts a “U”-shaped encoder-decoder structure. To tackle the issue of limited pixel information in small targets, we design an efficient feature extraction module based on squeeze and excitation (SE) channel attention and residual structure called SE channel attention and residual (SECAR). This module facilitates efficient extraction and transmission of spatial information, improving the network’s localization performance. To tackle the challenges of target loss and interference from similar objects, we design a temporal network (TPN) structure for extracting and memorizing temporal features, enhancing the network’s tracking performance. The STNet network consists of four main parts: input layer, encoder, decoder, and output layer. The input layer introduces the TPN structure, enabling the network to achieve neural network-style Kalman filtering effects. The encoder and decoder utilize SECAR feature extraction modules, which use multi-level residual bypass channels to improve the network’s spatial feature extraction capability and mitigate the problem of information loss for small targets. The output layer is responsible for restoring the output heat map to the predetermined size. After contour detection on the output heat map, pixel coordinate information of the shuttlecock can be obtained. Stable tracking of the shuttlecock is achieved by locating the pixel coordinates of the shuttlecock frame by frame.ResultExperiments conducted on the open data set TrackNetv2 and a home-brewed data set demonstrated that the STNet network achieved an accuracy of 92.0%, a precision of 96.7%, and an F1 score of 95.0%. Compared with the shuttlecock positioning trajectory method TrackNetv2, our method improved accuracy, precision, and F1 by 7.5%, 15.7%, and 7.5%, respectively, while significantly reducing the parameter count to meet real-time processing requirements (54 frames per second).ConclusionThis paper proposes a badminton localization tracking algorithm based on SECAR and a temporal encoder–decoder network. The network algorithm employs the SE channel attention mechanism and a residual bypass structure to design the SECAR feature extraction unit, which effectively improves the network’s capability to extract spatial features. To extract temporal information from video frames and achieve neural network-style Kalman filtering effects, we introduce the TPN structure. Experimental results demonstrate that even in low-frame-rate badminton match videos with severe motion blur, our proposed network can accurately locate the pixel coordinates of the shuttlecock and achieve stable tracking.关键词:shuttlecock localization and tracking;small target;heatmap;contour detection;encoder-decoder network;temporal network135|191|0更新时间:2025-04-11
摘要:ObjectiveBadminton has become one of the most popular sports in the world today. Badminton match videos contain a wealth of useful information, and extracting this information can provide data support for precise analysis of sports. Among various types of information, badminton trajectory information is particularly important, as it can extract ball speed, athlete explosiveness, and shuttlecock trajectory data from the positioning information of the shuttlecock. Compared with general video object detection and tracking tasks, real-time localization tracking in badminton videos faces two major challenges: 1) Shuttlecocks are small targets with severe motion blur and interference from similar objects. The accuracy of object detection and tracking methods based on rectangular bounding boxes is low and can cause centroid estimation errors. 2) Locating the shuttlecock target accurately in a single-frame image is difficult, but its position can be tracked using temporal features from adjacent video frames. However, existing network modules for extracting temporal features are complex and struggle to meet real-time requirements. Early research on badminton localization and tracking mainly included threshold-based methods and feature learning-based methods, which performed well in specific scenarios. However, these methods focused only on target information during model construction, making it difficult to utilize background information. As a result, their localization and tracking performance suffer in complex environments. Currently, most deep learning-based object detection and tracking methods are based on rectangular bounding box algorithms. However, shuttlecocks exhibit severe motion blur in single-frame images, making it difficult for the rectangular box algorithm to accurately locate the shuttlecock target’s pixel coordinates. Subsequently, a localization method based on heatmap contour detection emerged, which overcame the limitations of rectangular bounding box methods by directly determining the pixel position of the shuttlecock’s head center by using segmentation and morphological detection methods. However, current approaches based on heatmap contour detection have weak capabilities in extracting spatiotemporal features for video object localization and tracking, making them inadequate for real-world requirements. To enhance the network’s ability to extract temporal and spatial features from video frames, we propose a new badminton localization tracking network algorithm named shuttlecock track net (STNet) based on heatmap contour detection.MethodThe backbone of the STNet network adopts a “U”-shaped encoder-decoder structure. To tackle the issue of limited pixel information in small targets, we design an efficient feature extraction module based on squeeze and excitation (SE) channel attention and residual structure called SE channel attention and residual (SECAR). This module facilitates efficient extraction and transmission of spatial information, improving the network’s localization performance. To tackle the challenges of target loss and interference from similar objects, we design a temporal network (TPN) structure for extracting and memorizing temporal features, enhancing the network’s tracking performance. The STNet network consists of four main parts: input layer, encoder, decoder, and output layer. The input layer introduces the TPN structure, enabling the network to achieve neural network-style Kalman filtering effects. The encoder and decoder utilize SECAR feature extraction modules, which use multi-level residual bypass channels to improve the network’s spatial feature extraction capability and mitigate the problem of information loss for small targets. The output layer is responsible for restoring the output heat map to the predetermined size. After contour detection on the output heat map, pixel coordinate information of the shuttlecock can be obtained. Stable tracking of the shuttlecock is achieved by locating the pixel coordinates of the shuttlecock frame by frame.ResultExperiments conducted on the open data set TrackNetv2 and a home-brewed data set demonstrated that the STNet network achieved an accuracy of 92.0%, a precision of 96.7%, and an F1 score of 95.0%. Compared with the shuttlecock positioning trajectory method TrackNetv2, our method improved accuracy, precision, and F1 by 7.5%, 15.7%, and 7.5%, respectively, while significantly reducing the parameter count to meet real-time processing requirements (54 frames per second).ConclusionThis paper proposes a badminton localization tracking algorithm based on SECAR and a temporal encoder–decoder network. The network algorithm employs the SE channel attention mechanism and a residual bypass structure to design the SECAR feature extraction unit, which effectively improves the network’s capability to extract spatial features. To extract temporal information from video frames and achieve neural network-style Kalman filtering effects, we introduce the TPN structure. Experimental results demonstrate that even in low-frame-rate badminton match videos with severe motion blur, our proposed network can accurately locate the pixel coordinates of the shuttlecock and achieve stable tracking.关键词:shuttlecock localization and tracking;small target;heatmap;contour detection;encoder-decoder network;temporal network135|191|0更新时间:2025-04-11
Image Analysis and Recognition
- “在目标检测领域,研究者提出了一种新的知识蒸馏方法,有效提升了模型性能,并适用于多种检测器。”
 摘要:ObjectiveIn recent years, convolutional neural networks have had great potential in various fields of computer vision due to their excellent feature extraction ability. As the performance of the model increases, the size of the model becomes increasingly bloated, and the large number of parameters makes its inference speed slow. Even with the help of GPU acceleration, the real-time demand of many application scenarios cannot be met. In addition, the occupied memory and storage space increase the cost of use. As a result, these large models are difficult to deploy and run on mobile devices or embedded platforms with limited arithmetic power and storage space, restricting their promotion. Therefore, how to compress large deep neural network models is a key issue. Knowledge distillation is a simple and effective model compression method. Unlike the idea of model pruning or parameter quantization, knowledge distillation is essentially a special model training method. It does not directly make changes to the model structure or parameters; rather, it compresses the volume without changing the model structure and parameters. It is also used in model training to learn the hard labels in the training set aside from the hard labels in the training set and guide the teacher’s model by using the teacher’s model classification. In addition to learning the hard labels in the training set, we use the classification output of the teacher’s model as soft labels to guide the learning of the student model so that the hidden “dark knowledge” in the teacher’s model, which is powerful but has a bloated network structure, is transferred to the student’s model. The student’s model has a relatively simple network structure and a smaller parameter volume. This knowledge transfer enables the student’s model, which has fewer model parameters and a faster reasoning speed, to achieve comparable accuracy with the teacher’s model, thus achieving model compression. However, the target detection task requires classifying the target and outputting the specific position of the target in the picture. This step is not possible just by learning the labels output from the teacher’s model. Therefore, the traditional knowledge distillation method used for classification does not work well on the target detection task. Moreover, the network structure of the detector is more complex, so existing knowledge distillation methods based on the target detection task usually let the features of the student model directly learn the features of the teacher model for distillation instead of learning the labels of the teacher. Existing methods also have multiple limitations. Therefore, a new knowledge distillation method applicable to the target detection task is proposed, i.e., feature editing reconstruction distillation based on knowledge enhancement, to achieve effective compression of the target detection model.MethodTwo modules are constructed to address two common problems of the current knowledge distillation methods for the target detection task: 1) knowledge enhancement module and 2) feature editing and reconstruction module. To address the problem in which the existing methods distill only between the corresponding feature layers of the teacher’s model and the student’s model, which cannot fully utilize the hidden “dark knowledge” in the teacher’s model, the knowledge enhancement module is introduced to enhance the knowledge of the teacher’s model through spatial attention and channel attention, respectively. Therefore, the knowledge enhancement module is introduced to perform bottom-up and top-down multi-scale feature fusion of teacher features through spatial attention and channel attention, respectively, for knowledge enhancement. As the performance of the teacher model continues to improve, the ability gap between students and teachers becomes increasingly larger, and the trend of performance enhancement of the student model gradually reaches saturation or even decreases. The feature edit reconstruction module is used to construct a new distillation paradigm to fuse some features of the teacher’s model into the features of the student’s model as a priori knowledge to narrow the representation capability gap between the teacher’s model and the student’s model. This module then randomly deletes detailed information such as edges and contours of the student model’s features through a pixel-level mask to realize feature editing, and then forces the student model to use the remaining features in combination with the a priori knowledge through a simple convolutional block to recover the deleted detail information for feature reconstruction, and in the process of model learning to optimize the quality of the reconstructed feature maps, the student’s original feature maps are back-propagated through feature reconstruction, thus learning features with stronger representational capabilities.ResultExperiments were conducted based on three different types of detectors:retina network(RetinaNet), faster region-based convolutional neural network(Faster R-CNN), and fully convolutional one-stage object detection(FCOS),on the generalized target detection dataset visual object classes 2007(VOC2007) and the steel surface defects dataset Northeastern University surface defect database(NEU-DET) by using the teacher’s model, student’s model of ResNet101-ResNet50. First, feature map visualization found that the feature map of the distilled detector responds significantly less to the background noise information and pays more attention to the foreground critical region. A comparison of the visualization of the detection results show the distilled detector significantly improves the situation of misdetection and omission. An evaluation of the detection results using the mAP metrics shows that the mAP comparison baselines for the VOC2007 test set improved by 2.1%, 2.7%, and 3.8%, respectively, and the mAP comparison baselines for the NEU-DET test set improved by 2.7%, 2.6%, and 2.1%, respectively.ConclusionIn this study, a new knowledge distillation method for target detection task is proposed, and experimental results show that this method can significantly improve the focus of the detector feature map on the key target region and reduce the interference of noise. Thus, the false detection and leakage rate is reduced, and the accuracy improvement is better than that of several state-of-the-art algorithms. The proposed method is suitable for general target detection datasets and specialized defect detection datasets, with good generalization performance, and can be applied to many types of detectors at the same time.关键词:model compression;knowledge distillation;knowledge enhancement;feature reconstruction;target detection90|111|0更新时间:2025-04-11
摘要:ObjectiveIn recent years, convolutional neural networks have had great potential in various fields of computer vision due to their excellent feature extraction ability. As the performance of the model increases, the size of the model becomes increasingly bloated, and the large number of parameters makes its inference speed slow. Even with the help of GPU acceleration, the real-time demand of many application scenarios cannot be met. In addition, the occupied memory and storage space increase the cost of use. As a result, these large models are difficult to deploy and run on mobile devices or embedded platforms with limited arithmetic power and storage space, restricting their promotion. Therefore, how to compress large deep neural network models is a key issue. Knowledge distillation is a simple and effective model compression method. Unlike the idea of model pruning or parameter quantization, knowledge distillation is essentially a special model training method. It does not directly make changes to the model structure or parameters; rather, it compresses the volume without changing the model structure and parameters. It is also used in model training to learn the hard labels in the training set aside from the hard labels in the training set and guide the teacher’s model by using the teacher’s model classification. In addition to learning the hard labels in the training set, we use the classification output of the teacher’s model as soft labels to guide the learning of the student model so that the hidden “dark knowledge” in the teacher’s model, which is powerful but has a bloated network structure, is transferred to the student’s model. The student’s model has a relatively simple network structure and a smaller parameter volume. This knowledge transfer enables the student’s model, which has fewer model parameters and a faster reasoning speed, to achieve comparable accuracy with the teacher’s model, thus achieving model compression. However, the target detection task requires classifying the target and outputting the specific position of the target in the picture. This step is not possible just by learning the labels output from the teacher’s model. Therefore, the traditional knowledge distillation method used for classification does not work well on the target detection task. Moreover, the network structure of the detector is more complex, so existing knowledge distillation methods based on the target detection task usually let the features of the student model directly learn the features of the teacher model for distillation instead of learning the labels of the teacher. Existing methods also have multiple limitations. Therefore, a new knowledge distillation method applicable to the target detection task is proposed, i.e., feature editing reconstruction distillation based on knowledge enhancement, to achieve effective compression of the target detection model.MethodTwo modules are constructed to address two common problems of the current knowledge distillation methods for the target detection task: 1) knowledge enhancement module and 2) feature editing and reconstruction module. To address the problem in which the existing methods distill only between the corresponding feature layers of the teacher’s model and the student’s model, which cannot fully utilize the hidden “dark knowledge” in the teacher’s model, the knowledge enhancement module is introduced to enhance the knowledge of the teacher’s model through spatial attention and channel attention, respectively. Therefore, the knowledge enhancement module is introduced to perform bottom-up and top-down multi-scale feature fusion of teacher features through spatial attention and channel attention, respectively, for knowledge enhancement. As the performance of the teacher model continues to improve, the ability gap between students and teachers becomes increasingly larger, and the trend of performance enhancement of the student model gradually reaches saturation or even decreases. The feature edit reconstruction module is used to construct a new distillation paradigm to fuse some features of the teacher’s model into the features of the student’s model as a priori knowledge to narrow the representation capability gap between the teacher’s model and the student’s model. This module then randomly deletes detailed information such as edges and contours of the student model’s features through a pixel-level mask to realize feature editing, and then forces the student model to use the remaining features in combination with the a priori knowledge through a simple convolutional block to recover the deleted detail information for feature reconstruction, and in the process of model learning to optimize the quality of the reconstructed feature maps, the student’s original feature maps are back-propagated through feature reconstruction, thus learning features with stronger representational capabilities.ResultExperiments were conducted based on three different types of detectors:retina network(RetinaNet), faster region-based convolutional neural network(Faster R-CNN), and fully convolutional one-stage object detection(FCOS),on the generalized target detection dataset visual object classes 2007(VOC2007) and the steel surface defects dataset Northeastern University surface defect database(NEU-DET) by using the teacher’s model, student’s model of ResNet101-ResNet50. First, feature map visualization found that the feature map of the distilled detector responds significantly less to the background noise information and pays more attention to the foreground critical region. A comparison of the visualization of the detection results show the distilled detector significantly improves the situation of misdetection and omission. An evaluation of the detection results using the mAP metrics shows that the mAP comparison baselines for the VOC2007 test set improved by 2.1%, 2.7%, and 3.8%, respectively, and the mAP comparison baselines for the NEU-DET test set improved by 2.7%, 2.6%, and 2.1%, respectively.ConclusionIn this study, a new knowledge distillation method for target detection task is proposed, and experimental results show that this method can significantly improve the focus of the detector feature map on the key target region and reduce the interference of noise. Thus, the false detection and leakage rate is reduced, and the accuracy improvement is better than that of several state-of-the-art algorithms. The proposed method is suitable for general target detection datasets and specialized defect detection datasets, with good generalization performance, and can be applied to many types of detectors at the same time.关键词:model compression;knowledge distillation;knowledge enhancement;feature reconstruction;target detection90|111|0更新时间:2025-04-11 - “在图像拼接领域,研究人员提出了一种基于多模态数据特征融合的算法,有效提升了拼接效果和场景感知信息。”
 摘要:ObjectiveImage stitching, a cornerstone in the field of computer vision, is dedicated to assembling a comprehensive field-of-view image by merging visible data captured from multiple vantage points within a specific scene. This fusion enhances scene perception and facilitates advanced processing. The current state-of-the-art in image stitching primarily hinges on the detection of feature points within the scene, necessitating their dense and uniform distribution throughout the image. However, these approaches encounter significant challenges in outdoor environments or when applied to military equipment, where adverse weather conditions such as rain, haze, and low light can severely degrade the quality of visible images. This degradation impedes the extraction of feature points, a critical step in the stitching process. Furthermore, factors such as camouflage and occlusion can lead to data loss, disrupting the distribution of feature points and thus compromising the quality of the stitched image. These limitations often manifest as ghosting effects, undermining the effectiveness of the stitching and its robustness in practical applications. In this challenging context, infrared sensors, which detect thermal radiation to image scenes, emerge as a robust alternative. They excel in highlighting targets even under unfavorable conditions, mitigating the impact of environmental and human factors. This capability makes them highly valuable in military surveillance applications. However, a significant drawback of thermal imaging is its inability to capture the rich texture details that are abundant in visible images. These details are crucial for an accurate and comprehensive perception of the scene.MethodThis paper proposes a groundbreaking image stitching algorithm to overcome the limitations inherent in conventional visible image stitching and to extend the applicability of stitching technology across various environments. This algorithm is based on the fusion of features from multi-modality images, specifically, infrared and visible images. By exploiting the complementary characteristics of infrared and visible data, our approach integrates the precise structural features of infrared images with the rich, detailed attributes of visible images. This integration is crucial for achieving accurate homography matrix estimation for scenes viewed from multiple angles. A distinctive aspect of our method is the incorporation of a learnable feature pyramid structure. This structure is instrumental in estimating sparse offsets in a gradual, coarse-to-fine manner, thus deriving the deformation matrix through a non-parametric direct linear transformation. An innovative aspect of our approach is the fusion of stitched infrared and visible data to enrich the perceptual information of the generated scene. This fusion process entails mining deep features of the scene for contextual semantic information while also utilizing shallow features to address the deficiencies in upsampled data. This strategy aims to produce more accurate and reliable fused results.ResultWe selected a real-world dataset comprising 530 pairs of stitchable multi-modal images and a synthetic dataset containing 200 pairs of data as test datasets. It compared the qualitative and quantitative performance of 21 fusion stitching strategies, incorporating three of the latest fusion methods — namely, residual fusion network, recurrent correction network, and dual-attention transformer (DATFuse) — and seven stitching methods — namely, as projective as possible, single-perspective warps, wide parallax image stitching, seam-guided local alignment and stitching, view-free image stitching, reconstructing stitched features to images, and unsupervised deep image stitching (UDIS++). In terms of stitching performance, our method achieved accurate cross-view scene alignment, with an average corner error reduced by 53%, preventing ghosting and abnormal distortion, even outperforming existing feature-point-based stitching algorithms in challenging large-baseline scenarios. With regard to the integration of multi-modal complementary information, our method adaptively balanced the robust imaging capability of infrared images to highlight structural information and the rich texture details of visible images, resulting in an information entropy increase of 24.6% compared with the DATFuse-UDIS++ strategy, demonstrating significant advantages.ConclusionThe proposed infrared and visible-based image stitching method marks a significant advancement in the field of computer vision. It effectively addresses the limitations of traditional image stitching methods, particularly under adverse environmental conditions. Moreover, it broadens the scope of stitching technology, making it more versatile and applicable in diverse settings. The combination of infrared and visible imagery in this algorithm could revolutionize scene perception and processing, especially in military and outdoor applications where accuracy, detail, and robustness are of utmost importance. Furthermore, the algorithm’s ability to fuse different types of data opens up new avenues for research and application. It suggests potential uses in other fields such as environmental monitoring, search-and-rescue operations, and even in artistic and creative domains where novel visual representations are sought. The fusion technique employed in our algorithm not only enhances the visual quality of the stitched images but also adds a layer of information that could be vital in critical applications such as surveillance and reconnaissance. It effectively addresses the key challenges of traditional image stitching, particularly under adverse environmental conditions, and demonstrates superior performance over existing methods. This advancement not only enhances our ability to perceive and process scenes more effectively but also paves the way for future innovations in image processing and analysis.关键词:multi-modality image fusion;image stitching;convolutional neural network(CNN);infrared and visible images;multi-scale pyramid126|96|0更新时间:2025-04-11
摘要:ObjectiveImage stitching, a cornerstone in the field of computer vision, is dedicated to assembling a comprehensive field-of-view image by merging visible data captured from multiple vantage points within a specific scene. This fusion enhances scene perception and facilitates advanced processing. The current state-of-the-art in image stitching primarily hinges on the detection of feature points within the scene, necessitating their dense and uniform distribution throughout the image. However, these approaches encounter significant challenges in outdoor environments or when applied to military equipment, where adverse weather conditions such as rain, haze, and low light can severely degrade the quality of visible images. This degradation impedes the extraction of feature points, a critical step in the stitching process. Furthermore, factors such as camouflage and occlusion can lead to data loss, disrupting the distribution of feature points and thus compromising the quality of the stitched image. These limitations often manifest as ghosting effects, undermining the effectiveness of the stitching and its robustness in practical applications. In this challenging context, infrared sensors, which detect thermal radiation to image scenes, emerge as a robust alternative. They excel in highlighting targets even under unfavorable conditions, mitigating the impact of environmental and human factors. This capability makes them highly valuable in military surveillance applications. However, a significant drawback of thermal imaging is its inability to capture the rich texture details that are abundant in visible images. These details are crucial for an accurate and comprehensive perception of the scene.MethodThis paper proposes a groundbreaking image stitching algorithm to overcome the limitations inherent in conventional visible image stitching and to extend the applicability of stitching technology across various environments. This algorithm is based on the fusion of features from multi-modality images, specifically, infrared and visible images. By exploiting the complementary characteristics of infrared and visible data, our approach integrates the precise structural features of infrared images with the rich, detailed attributes of visible images. This integration is crucial for achieving accurate homography matrix estimation for scenes viewed from multiple angles. A distinctive aspect of our method is the incorporation of a learnable feature pyramid structure. This structure is instrumental in estimating sparse offsets in a gradual, coarse-to-fine manner, thus deriving the deformation matrix through a non-parametric direct linear transformation. An innovative aspect of our approach is the fusion of stitched infrared and visible data to enrich the perceptual information of the generated scene. This fusion process entails mining deep features of the scene for contextual semantic information while also utilizing shallow features to address the deficiencies in upsampled data. This strategy aims to produce more accurate and reliable fused results.ResultWe selected a real-world dataset comprising 530 pairs of stitchable multi-modal images and a synthetic dataset containing 200 pairs of data as test datasets. It compared the qualitative and quantitative performance of 21 fusion stitching strategies, incorporating three of the latest fusion methods — namely, residual fusion network, recurrent correction network, and dual-attention transformer (DATFuse) — and seven stitching methods — namely, as projective as possible, single-perspective warps, wide parallax image stitching, seam-guided local alignment and stitching, view-free image stitching, reconstructing stitched features to images, and unsupervised deep image stitching (UDIS++). In terms of stitching performance, our method achieved accurate cross-view scene alignment, with an average corner error reduced by 53%, preventing ghosting and abnormal distortion, even outperforming existing feature-point-based stitching algorithms in challenging large-baseline scenarios. With regard to the integration of multi-modal complementary information, our method adaptively balanced the robust imaging capability of infrared images to highlight structural information and the rich texture details of visible images, resulting in an information entropy increase of 24.6% compared with the DATFuse-UDIS++ strategy, demonstrating significant advantages.ConclusionThe proposed infrared and visible-based image stitching method marks a significant advancement in the field of computer vision. It effectively addresses the limitations of traditional image stitching methods, particularly under adverse environmental conditions. Moreover, it broadens the scope of stitching technology, making it more versatile and applicable in diverse settings. The combination of infrared and visible imagery in this algorithm could revolutionize scene perception and processing, especially in military and outdoor applications where accuracy, detail, and robustness are of utmost importance. Furthermore, the algorithm’s ability to fuse different types of data opens up new avenues for research and application. It suggests potential uses in other fields such as environmental monitoring, search-and-rescue operations, and even in artistic and creative domains where novel visual representations are sought. The fusion technique employed in our algorithm not only enhances the visual quality of the stitched images but also adds a layer of information that could be vital in critical applications such as surveillance and reconnaissance. It effectively addresses the key challenges of traditional image stitching, particularly under adverse environmental conditions, and demonstrates superior performance over existing methods. This advancement not only enhances our ability to perceive and process scenes more effectively but also paves the way for future innovations in image processing and analysis.关键词:multi-modality image fusion;image stitching;convolutional neural network(CNN);infrared and visible images;multi-scale pyramid126|96|0更新时间:2025-04-11 - “在行人再识别领域,提出了朝向感知特征学习,有效改善了关联效果,为解决行人再识别问题提供新方案。”
 摘要:ObjectiveIn the contemporary digital and internet-driven environment, person re-identification (ReID) technology has become an integral component of domains such as intelligent surveillance, security, and new retail. However, in real-world scenarios, the same person may exhibit significant appearance differences due to changes in view, leading to degraded association performance. Existing methods typically enhance the model’s representation ability and association capacity by first-view representation learning and designing view-based loss functions to make the model perceive view information. While these methods have achieved outstanding results, significant challenges remain, which will be elaborated upon in the following sections. The first challenge is how person representational capability can be retained in models with implicit view feature learning. In terms of view feature representation, existing methods based on the transformer architecture convert view labels into feature vectors through the view embedding layer. These methods hinder the model from perceiving complex posture information from simple labels. Consequently, these methods implicitly learn the view features; that is, they do not explicitly convey to the model the spatial structure of person posture, such as the position of keypoints and their topological relationships. This situation could result in the model not precisely perceiving person postures and views, thereby diminishing the model’s representational capability for persons. To address this issue, our method embeds keypoint coordinates and models the topological structure between keypoints. When this structured information is provided to the model, it can more intuitively understand person postures, allowing for explicit learning of person posture. The second challenge is how persons with similar appearances and the same view can be separated during indiscriminate pushing of anchor from hard negatives. With regard to the design of the view-based loss function, many existing methods generally do not differentiate specific views, learning generic view features, which might strip the model of essential person view information. Alternatively, some approaches leverage triplet loss to reduce feature map distances for persons with the same views while increasing the distances between clusters of the same identity with opposing views and bringing clusters of adjacent views closer together. However, on the basis of our analysis of error cases in real scenarios, persons with similar appearances and the same views often rank higher in retrieval results, leading to degraded performance of the ReID system. Moreover, while the aforementioned methods set a uniform margin to push anchors from hard negative examples, persons with similar appearances and the same views might still not be distinctly separated. To address this issue, we introduce a large margin for different identities with similar appearances and same views to push them apart. We then introduce view-aware feature learning (VAFL) for person ReID to address the outlined challenges.MethodFirst, we propose view feature learning based on person posture (Pos2View). Specifically, the view of a person is inherently determined by the spatial arrangement of various body parts, which provides key insights into their view. Consequently, we integrate the person’s posture information into the feature map, enhancing the model’s ability to discern the person’s view. Second, we propose triplet loss with adaptive view (AdaView), which assigns adaptive margins between examples on the basis of their views, thereby optimizing the triplet loss for person view awareness. The original triplet loss updates the model by pulling the anchor and the hard positive example closer and pushing the hard negative example away from the anchor. However, our proposed AdaView emphasizes distancing persons with the same view and similar appearances far apart in the feature space. Specifically, these similar-appearance persons are the hard negative examples in the mini-batch, which have the closest Euclidean distance. With the high visual similarity among images of the same person with same views, we aim to pull them closer in the feature space, forming sub-clusters of images with the same view. This action is reflected in the minimal margin. To make the model sensitive to changes in person appearance due to view shifts, for images of the same person with different views, we push apart their corresponding sub-clusters in the feature space. This pushing is signified by a slightly larger margin. We deliberately increase the distance between images in the feature space that have similar appearances but belong to different identities with the same view. This operation is reflected by a larger margin. Collectively, the above steps define the AdaView.ResultIn our comprehensive analysis, we assessed the performance of our proposed method against a variety of established techniques in the field of person ReID. Our evaluation encompassed multiple public datasets, including Market1501 (Market), DukeMTMC-ReID, MSMT17, and CUHK. To gauge the effectiveness of our approach, we utilized two primary metrics: Rank-1 (R1), which measures the accuracy of the first result in retrieval, and the mean average precision (mAP), assessing overall ranking accuracy. Our method involved leveraging person view annotations from select datasets and implementing a model trained on ResNet to predict views of individuals in the MSMT17 dataset. We employed various data augmentation strategies and adhered to hyperparameter settings in line with TransReID. In direct comparison with state-of-the-art methods, including classic person ReID techniques and recent advancements such as TransReID and UniHCP, our proposed method exhibited superior performance. Specifically, on the MSMT17 dataset, our approach surpassed UniHCP by 1.7% in R1 and 1.3% in mAP. This improvement can be attributed to our unique VAFL technique, which enhances cluster differentiation and retrieval accuracy. Further, we conducted tests in generalized person ReID tasks to validate our model’s adaptability and stability in diverse scenarios. Compared with representative generalization methods, our approach demonstrated a slight edge, mainly due to the VAFL technique’s capacity to refine cluster boundaries and maintain a balance between intraclass compactness and interclass dispersion. Our ablation study revealed that removing the VAFL component from our model significantly reduced its performance, highlighting the component’s critical role in the overall effectiveness of our method. This study confirms the robustness and superiority of our approach in the field of person ReID, paving the way for its practical deployment in real-world applications.ConclusionIn this paper, we introduce VAFL, which enhances the model’s sensitivity to view, aiding in distinguishing persons with similar appearances but from the same view. Experimental results demonstrate that our approach exhibits outstanding performance across various scenarios, confirming its efficiency and reliability.关键词:person re-identification;person view;adaptive view;similar appearances;view perception94|113|0更新时间:2025-04-11
摘要:ObjectiveIn the contemporary digital and internet-driven environment, person re-identification (ReID) technology has become an integral component of domains such as intelligent surveillance, security, and new retail. However, in real-world scenarios, the same person may exhibit significant appearance differences due to changes in view, leading to degraded association performance. Existing methods typically enhance the model’s representation ability and association capacity by first-view representation learning and designing view-based loss functions to make the model perceive view information. While these methods have achieved outstanding results, significant challenges remain, which will be elaborated upon in the following sections. The first challenge is how person representational capability can be retained in models with implicit view feature learning. In terms of view feature representation, existing methods based on the transformer architecture convert view labels into feature vectors through the view embedding layer. These methods hinder the model from perceiving complex posture information from simple labels. Consequently, these methods implicitly learn the view features; that is, they do not explicitly convey to the model the spatial structure of person posture, such as the position of keypoints and their topological relationships. This situation could result in the model not precisely perceiving person postures and views, thereby diminishing the model’s representational capability for persons. To address this issue, our method embeds keypoint coordinates and models the topological structure between keypoints. When this structured information is provided to the model, it can more intuitively understand person postures, allowing for explicit learning of person posture. The second challenge is how persons with similar appearances and the same view can be separated during indiscriminate pushing of anchor from hard negatives. With regard to the design of the view-based loss function, many existing methods generally do not differentiate specific views, learning generic view features, which might strip the model of essential person view information. Alternatively, some approaches leverage triplet loss to reduce feature map distances for persons with the same views while increasing the distances between clusters of the same identity with opposing views and bringing clusters of adjacent views closer together. However, on the basis of our analysis of error cases in real scenarios, persons with similar appearances and the same views often rank higher in retrieval results, leading to degraded performance of the ReID system. Moreover, while the aforementioned methods set a uniform margin to push anchors from hard negative examples, persons with similar appearances and the same views might still not be distinctly separated. To address this issue, we introduce a large margin for different identities with similar appearances and same views to push them apart. We then introduce view-aware feature learning (VAFL) for person ReID to address the outlined challenges.MethodFirst, we propose view feature learning based on person posture (Pos2View). Specifically, the view of a person is inherently determined by the spatial arrangement of various body parts, which provides key insights into their view. Consequently, we integrate the person’s posture information into the feature map, enhancing the model’s ability to discern the person’s view. Second, we propose triplet loss with adaptive view (AdaView), which assigns adaptive margins between examples on the basis of their views, thereby optimizing the triplet loss for person view awareness. The original triplet loss updates the model by pulling the anchor and the hard positive example closer and pushing the hard negative example away from the anchor. However, our proposed AdaView emphasizes distancing persons with the same view and similar appearances far apart in the feature space. Specifically, these similar-appearance persons are the hard negative examples in the mini-batch, which have the closest Euclidean distance. With the high visual similarity among images of the same person with same views, we aim to pull them closer in the feature space, forming sub-clusters of images with the same view. This action is reflected in the minimal margin. To make the model sensitive to changes in person appearance due to view shifts, for images of the same person with different views, we push apart their corresponding sub-clusters in the feature space. This pushing is signified by a slightly larger margin. We deliberately increase the distance between images in the feature space that have similar appearances but belong to different identities with the same view. This operation is reflected by a larger margin. Collectively, the above steps define the AdaView.ResultIn our comprehensive analysis, we assessed the performance of our proposed method against a variety of established techniques in the field of person ReID. Our evaluation encompassed multiple public datasets, including Market1501 (Market), DukeMTMC-ReID, MSMT17, and CUHK. To gauge the effectiveness of our approach, we utilized two primary metrics: Rank-1 (R1), which measures the accuracy of the first result in retrieval, and the mean average precision (mAP), assessing overall ranking accuracy. Our method involved leveraging person view annotations from select datasets and implementing a model trained on ResNet to predict views of individuals in the MSMT17 dataset. We employed various data augmentation strategies and adhered to hyperparameter settings in line with TransReID. In direct comparison with state-of-the-art methods, including classic person ReID techniques and recent advancements such as TransReID and UniHCP, our proposed method exhibited superior performance. Specifically, on the MSMT17 dataset, our approach surpassed UniHCP by 1.7% in R1 and 1.3% in mAP. This improvement can be attributed to our unique VAFL technique, which enhances cluster differentiation and retrieval accuracy. Further, we conducted tests in generalized person ReID tasks to validate our model’s adaptability and stability in diverse scenarios. Compared with representative generalization methods, our approach demonstrated a slight edge, mainly due to the VAFL technique’s capacity to refine cluster boundaries and maintain a balance between intraclass compactness and interclass dispersion. Our ablation study revealed that removing the VAFL component from our model significantly reduced its performance, highlighting the component’s critical role in the overall effectiveness of our method. This study confirms the robustness and superiority of our approach in the field of person ReID, paving the way for its practical deployment in real-world applications.ConclusionIn this paper, we introduce VAFL, which enhances the model’s sensitivity to view, aiding in distinguishing persons with similar appearances but from the same view. Experimental results demonstrate that our approach exhibits outstanding performance across various scenarios, confirming its efficiency and reliability.关键词:person re-identification;person view;adaptive view;similar appearances;view perception94|113|0更新时间:2025-04-11 - “在移动端应用领域,专家提出了用户定制意图理解智能体,有效应对小样本增量问题,为平面扫描图像理解提供新思路。”
 摘要:ObjectiveIn the era of mobile internet, mobile applications are developing rapidly and becoming increasingly common in society, thus becoming an indispensable part of daily life. The demands and expectations of users for mobile applications are also constantly increasing. In the development of mobile applications, user intention understanding is an important research field, which aims to provide more personalized and intelligent services for users by analyzing their behavior and needs. User intention understanding for image input in mobile applications is a common practical requirement. In image-related human-computer interaction, users often need to interact with mobile applications through touch clicks or gestures so that mobile applications can intelligently understand users’ intentions. Traditional intention understanding methods mainly use a large amount of historical user behavior data to model and predict possible user intentions for new images. However, the application scenario is faced with some challenges such as the customization problem and few interactions, thus limiting the effectiveness of traditional methods. In recent years, with the development of autonomous artificial intelligence, the emergence of agent technology has provided new perspectives for user-customized intention understanding task. Agents can imitate and learn human thinking process, accurately understand users, reduce the burden of memory and operation, and help mobile applications better understand users’ intentions and needs. Therefore, we propose to build a user-customized intention understanding agent for planar scanned images for user-customized intention understanding task.MethodThe user-customized intention understanding agent consists of task perception, task planning, task execution, and feedback correction modules. Task perception module extracts information from an input image and combines it with user-customized template information obtained from stored intention libraries to understand the intention of the input image. The task planning module utilizes the results of the perception module to plan and make decisions on input image. The task execution module follows the decision made in the planning module to execute the corresponding action and output the intention understanding result of the input image. If the user is not satisfied with the current result, then the user can provide feedback through feedback correction module, and then the agent will output a new result, use the corrected image as a new user-customized intention template image, and add it to the intention libraries. To address the technical challenges faced in building these modules such as few-shot incremental learning problem, limited computing resources, and insufficient benchmark datasets, we propose several new technological ideas. First, a “divide and conquer” domain generalization method is proposed to decouple the inferences of basic tasks and customized tasks so that they do not affect each other. Second, we achieve intention understanding through template matching to cope with new customized samples without fine-tuning, which solves the few-shot incremental learning problem. Then, we use a self-improvement strategy to reduce the noise of intention understanding results and improve the reliability of domain generalization. In addition, we construct a customized intention understanding benchmark for planar scanned images, providing a data foundation for this study and subsequent research.ResultWe conduct a series of ablation experiments on our dataset to clearly show the effectiveness of different parts of our agent. We compare our agent with seven state-of-the-art methods on our dataset, including traditional saliency detection models, model fine-tuning, and visual language models. The mean intersection over union of the agent on our dataset reaches 90.47%, which is 15.60% higher than that of the second best-performing method, and the total accuracy is improved by 22.10%. Finally, the agent is applied to a public dataset called consolidated receipt dataset to verify its generalization ability.ConclusionIn this study, we propose a user-customized intention understanding agent for planar scanned images. Experimental results demonstrate that our proposed “divide and conquer” domain generalization method, self-improvement strategy, and object detection parameters all have a certain promoting effect on intention understanding. The agent outperforms the cutting-edge detection and segmentation models on the user intention understanding task without fine-tuning, proving the effectiveness and efficiency of our method.关键词:user intention understanding;agent;few-shot incremental learning;saliency detection;interactive segmentation88|94|0更新时间:2025-04-11
摘要:ObjectiveIn the era of mobile internet, mobile applications are developing rapidly and becoming increasingly common in society, thus becoming an indispensable part of daily life. The demands and expectations of users for mobile applications are also constantly increasing. In the development of mobile applications, user intention understanding is an important research field, which aims to provide more personalized and intelligent services for users by analyzing their behavior and needs. User intention understanding for image input in mobile applications is a common practical requirement. In image-related human-computer interaction, users often need to interact with mobile applications through touch clicks or gestures so that mobile applications can intelligently understand users’ intentions. Traditional intention understanding methods mainly use a large amount of historical user behavior data to model and predict possible user intentions for new images. However, the application scenario is faced with some challenges such as the customization problem and few interactions, thus limiting the effectiveness of traditional methods. In recent years, with the development of autonomous artificial intelligence, the emergence of agent technology has provided new perspectives for user-customized intention understanding task. Agents can imitate and learn human thinking process, accurately understand users, reduce the burden of memory and operation, and help mobile applications better understand users’ intentions and needs. Therefore, we propose to build a user-customized intention understanding agent for planar scanned images for user-customized intention understanding task.MethodThe user-customized intention understanding agent consists of task perception, task planning, task execution, and feedback correction modules. Task perception module extracts information from an input image and combines it with user-customized template information obtained from stored intention libraries to understand the intention of the input image. The task planning module utilizes the results of the perception module to plan and make decisions on input image. The task execution module follows the decision made in the planning module to execute the corresponding action and output the intention understanding result of the input image. If the user is not satisfied with the current result, then the user can provide feedback through feedback correction module, and then the agent will output a new result, use the corrected image as a new user-customized intention template image, and add it to the intention libraries. To address the technical challenges faced in building these modules such as few-shot incremental learning problem, limited computing resources, and insufficient benchmark datasets, we propose several new technological ideas. First, a “divide and conquer” domain generalization method is proposed to decouple the inferences of basic tasks and customized tasks so that they do not affect each other. Second, we achieve intention understanding through template matching to cope with new customized samples without fine-tuning, which solves the few-shot incremental learning problem. Then, we use a self-improvement strategy to reduce the noise of intention understanding results and improve the reliability of domain generalization. In addition, we construct a customized intention understanding benchmark for planar scanned images, providing a data foundation for this study and subsequent research.ResultWe conduct a series of ablation experiments on our dataset to clearly show the effectiveness of different parts of our agent. We compare our agent with seven state-of-the-art methods on our dataset, including traditional saliency detection models, model fine-tuning, and visual language models. The mean intersection over union of the agent on our dataset reaches 90.47%, which is 15.60% higher than that of the second best-performing method, and the total accuracy is improved by 22.10%. Finally, the agent is applied to a public dataset called consolidated receipt dataset to verify its generalization ability.ConclusionIn this study, we propose a user-customized intention understanding agent for planar scanned images. Experimental results demonstrate that our proposed “divide and conquer” domain generalization method, self-improvement strategy, and object detection parameters all have a certain promoting effect on intention understanding. The agent outperforms the cutting-edge detection and segmentation models on the user intention understanding task without fine-tuning, proving the effectiveness and efficiency of our method.关键词:user intention understanding;agent;few-shot incremental learning;saliency detection;interactive segmentation88|94|0更新时间:2025-04-11 - “在目标跟踪领域,研究者提出了融合上下文感知注意力的Transformer跟踪方法,有效提升了跟踪性能。”
 摘要:ObjectiveVisual target tracking, as one of the key tasks in the field of computer vision, is mainly aimed at predicting the size and position of a target in a given video sequence. In recent years, target tracking has been widely used in the fields of autonomous driving, unmanned aerial vehicles (UAVs), military activities, and intelligent surveillance. Although numerous excellent methods have emerged in the field of target tracking, multifaceted challenges remain, including, but not limited to, shape variations, occlusion, motion blurring, and interference from proximate objects. Currently, target tracking methods are categorized into two main groups: correlation-based filtering and deep learning based. The former approximates the target tracking process as a search image signal domain computation. However, fully utilizing image representation information by using manual features is difficult, which greatly limits the performance of tracking methods. In recent years, deep learning has made significant progress in the field of target tracking by virtue of its powerful visual representation processing capabilities. In recent years, Transformer trackers have made breakthroughs, in which the self-attention mechanism plays an important role. Currently, the independent correlation calculation in the self-attention mechanism is prone to lead to the phenomenon of ambiguous weights, thus hampering the tracking method’s overall performance. For this reason, a Transformer target tracking method incorporating context-aware attention is proposed.MethodFirst, hierarchical vision Transformer using shifted windows (SwinTransformer) is introduced to extract visual features, and a cross-scale strategy is utilized to integrate deep and shallow feature information to improve the network’s ability to characterize targets in complex scenes. The cross-scale fusion strategy is used to obtain key information at different scales, capture templates, and search for image diversity texture features, which helps the tracking network better understand the relationship between the target and the background. Second, a context-aware attention-based codec is constructed to fully fuse template features and search features. For the problem of inaccurate correlation computation that occurs in the attention mechanism, nested computation is used for query key pairs to focus on the target information in the input sequence and incorporates a target mask for assigning weights, which can effectively suppress the noise caused by inaccurate correlation computation, seek the consistency of the feature vectors, and prompt better interaction of feature information. The encoder uses features from the output of the trunk as input and uses global contextual information to reinforce the original features, thus enabling the model to learn discriminative features for object localization. The decoder takes as input the target query and the sequence of enhanced features from the encoder, using a two-branch cross attention design. One of the branches computes the target query and the encoder’s inputs to attend to features across the full range of locations and search regions on the template. Finally, a corner prediction header is used to estimate the target bounding box, and the template image is updated by the similarity score results. Specifically, the decoded features are fed into a fully convolutional network that outputs two probability maps for the upper-left and lower-right corners of the target bounding box. The predicted box coordinates are then obtained by calculating the expectation of the probability distribution for the two corners.ResultTraining pairs are randomly selected from the common objects in context (COCO), a large-scale object tracking dataset (TrackingNet), large-scale single-object tracking (LaSOT), and generic object tracking benchmark (GOT-10k) datasets to train the tracking model in this paper. The model’s minimum training data unit is a triad consisting of two templates and a search image. It was trained using 500 epochs, using 6 × 104 triples per epoch. The backbone network and the remainder have initial learning rates are 10-5
摘要:ObjectiveVisual target tracking, as one of the key tasks in the field of computer vision, is mainly aimed at predicting the size and position of a target in a given video sequence. In recent years, target tracking has been widely used in the fields of autonomous driving, unmanned aerial vehicles (UAVs), military activities, and intelligent surveillance. Although numerous excellent methods have emerged in the field of target tracking, multifaceted challenges remain, including, but not limited to, shape variations, occlusion, motion blurring, and interference from proximate objects. Currently, target tracking methods are categorized into two main groups: correlation-based filtering and deep learning based. The former approximates the target tracking process as a search image signal domain computation. However, fully utilizing image representation information by using manual features is difficult, which greatly limits the performance of tracking methods. In recent years, deep learning has made significant progress in the field of target tracking by virtue of its powerful visual representation processing capabilities. In recent years, Transformer trackers have made breakthroughs, in which the self-attention mechanism plays an important role. Currently, the independent correlation calculation in the self-attention mechanism is prone to lead to the phenomenon of ambiguous weights, thus hampering the tracking method’s overall performance. For this reason, a Transformer target tracking method incorporating context-aware attention is proposed.MethodFirst, hierarchical vision Transformer using shifted windows (SwinTransformer) is introduced to extract visual features, and a cross-scale strategy is utilized to integrate deep and shallow feature information to improve the network’s ability to characterize targets in complex scenes. The cross-scale fusion strategy is used to obtain key information at different scales, capture templates, and search for image diversity texture features, which helps the tracking network better understand the relationship between the target and the background. Second, a context-aware attention-based codec is constructed to fully fuse template features and search features. For the problem of inaccurate correlation computation that occurs in the attention mechanism, nested computation is used for query key pairs to focus on the target information in the input sequence and incorporates a target mask for assigning weights, which can effectively suppress the noise caused by inaccurate correlation computation, seek the consistency of the feature vectors, and prompt better interaction of feature information. The encoder uses features from the output of the trunk as input and uses global contextual information to reinforce the original features, thus enabling the model to learn discriminative features for object localization. The decoder takes as input the target query and the sequence of enhanced features from the encoder, using a two-branch cross attention design. One of the branches computes the target query and the encoder’s inputs to attend to features across the full range of locations and search regions on the template. Finally, a corner prediction header is used to estimate the target bounding box, and the template image is updated by the similarity score results. Specifically, the decoded features are fed into a fully convolutional network that outputs two probability maps for the upper-left and lower-right corners of the target bounding box. The predicted box coordinates are then obtained by calculating the expectation of the probability distribution for the two corners.ResultTraining pairs are randomly selected from the common objects in context (COCO), a large-scale object tracking dataset (TrackingNet), large-scale single-object tracking (LaSOT), and generic object tracking benchmark (GOT-10k) datasets to train the tracking model in this paper. The model’s minimum training data unit is a triad consisting of two templates and a search image. It was trained using 500 epochs, using 6 × 104 triples per epoch. The backbone network and the remainder have initial learning rates are 10-5 - “在三维重建领域,研究者提出了一种结合多视图一致性约束的神经隐式表面重建方法,有效提高了复杂结构物体的重建质量。”
 摘要:ObjectiveThree-dimensional reconstruction is a critical technology in the field of computer vision, with profound implications across diverse domains such as medicine, engineering, and cultural heritage preservation. Early 3D reconstruction methods heavily relied on manual measurements and modeling, thus being complex and error prone. With the advent of digital photography, image-based 3D reconstruction became increasingly feasible. This research aims to elevate the quality of multi-view reconstruction. Traditional 3D reconstruction techniques such as stereo vision matching and laser scanning often demand precise camera poses and are highly contingent on the quality of feature matching. They exhibit limited effectiveness in scenarios involving weak textures, Lambertian surfaces, and slender objects. Meanwhile, deep learning-based 3D reconstruction methods primarily hinge on image depth information and point cloud data. However, they grapple with challenges such as limited resolution due to memory constraints and complex topological structures. To improve the quality of reconstructions in smooth object regions and enhance model completeness, particularly for intricate non-closed curved surfaces, and to address issues such as missing model data and shape deviations, this study combines traditional multi-view consistency constraints with neural implicit surface reconstruction techniques to improve surface reconstruction accuracy and completeness.MethodOur approach has three main facets. In the unsigned distance function (UDF) network training phase, we introduce multi-view geometric consistency constraints and feature consistency constraints. During the volume rendering process, we calculate color loss to guide the UDF network to learn scene information more closely aligned with reality. Neural radiance fields (NeRF), a novel object and scene representation method, implicitly model both geometry and appearance information. Employing a fully connected network (specifically, multilayer perceptron) and volume rendering techniques, NeRF enables the generation of new viewpoints and the reconstruction of 3D scenes from multi-view images. For the reconstruction of geometrically complex single objects, we introduce the definition of the UDF network, leveraging its zero-level set to represent the object’s surface and redesigning rendering weights and sampling weight functions during volume rendering to ensure unbiased rendering, facilitating neural implicit surface training. Subsequently, we introduce geometric consistency constraints to maintain the geometric relationships between images captured from different viewpoints in 3D space, especially in large smooth areas and complex geometric shapes in the model. We project a region of the object’s surface onto the image as pixel blocks, expecting these pixel blocks corresponding to the same region to maintain geometric consistency across different viewpoints. By computing photometric losses, which involve comparing grayscale color differences between pixel blocks from different viewpoints by using the normalized cross-correlation, we leverage this constraint to obtain more complex geometric and texture information. Finally, we integrate a depth map feature extraction method from multi-view geometry reconstruction. This step involves connecting the image input to a U-Net network via a convolutional network provided by Vis-MVSNet. This network effectively captures feature information at different scales, restoring details and obtaining 2D image features from various viewpoints. In stereo matching, by minimizing depth feature differences between similar pixels captured from different viewpoints, we bring spatial points closer to their actual positions, ensuring the learned neural implicit surface network closely approximates the actual surface.ResultExperimental results demonstrate that our method achieves finer surface reconstruction on both the DTU dataset and our self-captured plant dataset. We successfully reconstruct smooth regions and excel in reconstructing geometrically complex and detailed parts, with rendering results closely resembling the original images. Compared with the benchmark NeuS method on the DTU dataset, the average error represented by chamfer distance decreased by 0.16, and the average reconstruction index represented by peak signal-to-noise ratio increased by 1.04 dB. Compared with the NeuS and NeUDF methods, the average chamfer distance on the DF3D dataset was reduced by 2.76 and 0.11, respectively. To further validate our method’s effectiveness for objects with self-occlusion properties, we utilized our self-captured Physalis plant dataset, which is characterized by dense and heavily occluded leaves. We successfully reconstructed plant models with high accuracy and structural completeness, with measured lengths and widths closely matching real values.ConclusionThe proposed neural implicit surface reconstruction method, coupled with multi-view consistency constraints, effectively harnesses feature information from multi-view images. It combines implicit scene information with explicit 2D image information to enhance the quality and consistency of the reconstruction model. This advancement promises higher-quality 3D reconstruction methods for applications such as plant phenotypic trait research and other fields relying on 3D data.关键词:3d reconstruction;neural implicit surface;geometric consistency;multi-view feature consistency;mesh model89|114|0更新时间:2025-04-11
摘要:ObjectiveThree-dimensional reconstruction is a critical technology in the field of computer vision, with profound implications across diverse domains such as medicine, engineering, and cultural heritage preservation. Early 3D reconstruction methods heavily relied on manual measurements and modeling, thus being complex and error prone. With the advent of digital photography, image-based 3D reconstruction became increasingly feasible. This research aims to elevate the quality of multi-view reconstruction. Traditional 3D reconstruction techniques such as stereo vision matching and laser scanning often demand precise camera poses and are highly contingent on the quality of feature matching. They exhibit limited effectiveness in scenarios involving weak textures, Lambertian surfaces, and slender objects. Meanwhile, deep learning-based 3D reconstruction methods primarily hinge on image depth information and point cloud data. However, they grapple with challenges such as limited resolution due to memory constraints and complex topological structures. To improve the quality of reconstructions in smooth object regions and enhance model completeness, particularly for intricate non-closed curved surfaces, and to address issues such as missing model data and shape deviations, this study combines traditional multi-view consistency constraints with neural implicit surface reconstruction techniques to improve surface reconstruction accuracy and completeness.MethodOur approach has three main facets. In the unsigned distance function (UDF) network training phase, we introduce multi-view geometric consistency constraints and feature consistency constraints. During the volume rendering process, we calculate color loss to guide the UDF network to learn scene information more closely aligned with reality. Neural radiance fields (NeRF), a novel object and scene representation method, implicitly model both geometry and appearance information. Employing a fully connected network (specifically, multilayer perceptron) and volume rendering techniques, NeRF enables the generation of new viewpoints and the reconstruction of 3D scenes from multi-view images. For the reconstruction of geometrically complex single objects, we introduce the definition of the UDF network, leveraging its zero-level set to represent the object’s surface and redesigning rendering weights and sampling weight functions during volume rendering to ensure unbiased rendering, facilitating neural implicit surface training. Subsequently, we introduce geometric consistency constraints to maintain the geometric relationships between images captured from different viewpoints in 3D space, especially in large smooth areas and complex geometric shapes in the model. We project a region of the object’s surface onto the image as pixel blocks, expecting these pixel blocks corresponding to the same region to maintain geometric consistency across different viewpoints. By computing photometric losses, which involve comparing grayscale color differences between pixel blocks from different viewpoints by using the normalized cross-correlation, we leverage this constraint to obtain more complex geometric and texture information. Finally, we integrate a depth map feature extraction method from multi-view geometry reconstruction. This step involves connecting the image input to a U-Net network via a convolutional network provided by Vis-MVSNet. This network effectively captures feature information at different scales, restoring details and obtaining 2D image features from various viewpoints. In stereo matching, by minimizing depth feature differences between similar pixels captured from different viewpoints, we bring spatial points closer to their actual positions, ensuring the learned neural implicit surface network closely approximates the actual surface.ResultExperimental results demonstrate that our method achieves finer surface reconstruction on both the DTU dataset and our self-captured plant dataset. We successfully reconstruct smooth regions and excel in reconstructing geometrically complex and detailed parts, with rendering results closely resembling the original images. Compared with the benchmark NeuS method on the DTU dataset, the average error represented by chamfer distance decreased by 0.16, and the average reconstruction index represented by peak signal-to-noise ratio increased by 1.04 dB. Compared with the NeuS and NeUDF methods, the average chamfer distance on the DF3D dataset was reduced by 2.76 and 0.11, respectively. To further validate our method’s effectiveness for objects with self-occlusion properties, we utilized our self-captured Physalis plant dataset, which is characterized by dense and heavily occluded leaves. We successfully reconstructed plant models with high accuracy and structural completeness, with measured lengths and widths closely matching real values.ConclusionThe proposed neural implicit surface reconstruction method, coupled with multi-view consistency constraints, effectively harnesses feature information from multi-view images. It combines implicit scene information with explicit 2D image information to enhance the quality and consistency of the reconstruction model. This advancement promises higher-quality 3D reconstruction methods for applications such as plant phenotypic trait research and other fields relying on 3D data.关键词:3d reconstruction;neural implicit surface;geometric consistency;multi-view feature consistency;mesh model89|114|0更新时间:2025-04-11 - “在直升机桨叶检测领域,研究人员提出了一种融合多特征与自注意力的旋转目标检测器FMSA-RD,有效提升了室外复杂光照背景下桨叶的检测精度和速度。”
 摘要:ObjectiveThe motion parameters of helicopter rotor blades include flapping angle, lead-lag angle, twist angle, and coning angle, which provide an important basis for rotor structure design, upper and lower limit block design of hub, and blade load design. They are important parameters that need to be measured in ground tests before rotorcraft certification and helicopter flight tests. The traditional visual measurement method for rotor blade motion parameters has achieved good results in indoor wind tunnel environments. However, under the influence of complex outdoor backgrounds, some problems exist, such as the inability to detect the rotor blades from the image and measure the parameters accurately. Unlike indoor environments, the outdoors have complex lighting conditions such as different seasons, weather, times, and lighting directions, as well as different sky and background environments. Under these complex background interferences, the features of the rotor blades are weakened, making it difficult to accurately locate the position of the rotor blades. Deep learning is a mainstream object detection method, and how to design deep learning models to enhance the target features of rotor blades and reduce the interference of complex backgrounds is a major challenge. In this paper, on the basis of the network structure of the YOLOv5s, a prediction angle branch is added, and a rotation object detector (FMSA-RD) that fuses multiple features and self-attention is proposed to facilitate the detection of outdoor helicopter rotor blades.MethodFirst, the FMSA-RD model improves the C3 module used for feature extraction in YOLOv5s by adding multiple shortcuts. The improved feature extraction module is called convolution five (C5), which completes the feature extraction by fusing local features from different positions, thereby reducing the network structure while maintaining the feature extraction ability. Specifically, C5 replaces the BottleNeck module in C3 with two 3 × 3 convolution kernels to avoid the additional overhead caused by using multiple BottleNeck modules and increase the receptive field of the convolution layer feature map. Increasing the number of convolution layers does not necessarily lead to optimized parameters and may cause gradient divergence and network degradation. C5 adds shortcut branches to three main convolution layers to effectively avoid the accumulation of useless parameters and extract feature information from different positions. Secondly, the multi-feature fusion spatial pyramid pooling cross stage partial fast tiny module enhances the ability to fuse graphic features at different scales. This module uses a block merging method, using multiple serial 5 × 5 MaxPool layers to extract four different receptive fields, which improves detection accuracy while keeping the model lightweight. Then, to address the weak ability of convolutional neural network (CNN) structures to connect global features, the B3 module is designed to improve the extraction ability of global features by combining the multi-head self-attention mechanism of Transformer with the crossstage partial convolution(CSP) bottleneck structure, which suppresses the influence of complex outdoor rotor blade backgrounds. Finally, skew intersection over union (SKEWIOU) tilt intersection ratio loss and angle loss are introduced to improve the loss function and further enhance the accuracy of blade detection.ResultOur experiments were conducted on a self-made outdoor helicopter rotor blade dataset, a self-made outdoor simulated blade dataset, and the public dataset DOTA-v1.0 for training and validation. The self-made outdoor rotor blade dataset contains 3 878 images, which were randomly divided into training, testing, and validation sets in a 7:2:1 ratio. Our FMSA-RD was compared with mainstream horizontal and rotational models such as RetinaNet, FCOS, YOLOv5s, YOLOv6s, YOLOv7 tiny, CenterRot, FAB + DRB + CRB, H2RBox, and R3Det. Experimental results show that our method achieves an average detection accuracy of 98.5% and 110.5 frames per second. On the basis of the comparison experiments using a self-made outdoor blade dataset, the analysis indicates that the mean average precision (mAP) of FMSA-RD is 14.1%, 7.8%, 6.6%, 3.2%, 3.9%, 3.0%, 3.1%, 2.3%, and 4.2% higher than those of RetinaNet, FCOS, YOLOv5, YOLOv6s, YOLOv7 tiny, CenterRot, FAB + DRB + CRB, H2RBox, and R3Det, respectively. The public dataset DOTA contains 2 806 remote sensing images with a resolution of 800 × 800, covering various scene types such as cities, industrial areas, buildings, and roads. This comparative experiment aims to verify the generalization ability of the FMSA-RD network. We chose mainstream rotating object detection models for comparative experiments. On the self-made outdoor simulated paddle dataset, the data in the morning and noon are used as the training set, and the data at night are used as the validation set. Experiments show that FMSA-RD has low computational complexity, high detection accuracy, and good generalization ability, making it suitable for different scenarios and environments.ConclusionOur FMSA-RD can reduce complexity while integrating local feature information from different positions, suppressing complex background noise interference. The fusion of different scale features improves the accuracy of blade detection. The fusion of self-attention mechanism extracts global information and distinguishes blades without circular markers, achieving accurate detection of complex backgrounds and high aspect ratio blades while reducing model parameters and improving detection accuracy.关键词:outdoor helicopter rotor blade;rotating target detection;multi-feature;multi-head self-attention mechanism(MHSA);loss function83|64|0更新时间:2025-04-11
摘要:ObjectiveThe motion parameters of helicopter rotor blades include flapping angle, lead-lag angle, twist angle, and coning angle, which provide an important basis for rotor structure design, upper and lower limit block design of hub, and blade load design. They are important parameters that need to be measured in ground tests before rotorcraft certification and helicopter flight tests. The traditional visual measurement method for rotor blade motion parameters has achieved good results in indoor wind tunnel environments. However, under the influence of complex outdoor backgrounds, some problems exist, such as the inability to detect the rotor blades from the image and measure the parameters accurately. Unlike indoor environments, the outdoors have complex lighting conditions such as different seasons, weather, times, and lighting directions, as well as different sky and background environments. Under these complex background interferences, the features of the rotor blades are weakened, making it difficult to accurately locate the position of the rotor blades. Deep learning is a mainstream object detection method, and how to design deep learning models to enhance the target features of rotor blades and reduce the interference of complex backgrounds is a major challenge. In this paper, on the basis of the network structure of the YOLOv5s, a prediction angle branch is added, and a rotation object detector (FMSA-RD) that fuses multiple features and self-attention is proposed to facilitate the detection of outdoor helicopter rotor blades.MethodFirst, the FMSA-RD model improves the C3 module used for feature extraction in YOLOv5s by adding multiple shortcuts. The improved feature extraction module is called convolution five (C5), which completes the feature extraction by fusing local features from different positions, thereby reducing the network structure while maintaining the feature extraction ability. Specifically, C5 replaces the BottleNeck module in C3 with two 3 × 3 convolution kernels to avoid the additional overhead caused by using multiple BottleNeck modules and increase the receptive field of the convolution layer feature map. Increasing the number of convolution layers does not necessarily lead to optimized parameters and may cause gradient divergence and network degradation. C5 adds shortcut branches to three main convolution layers to effectively avoid the accumulation of useless parameters and extract feature information from different positions. Secondly, the multi-feature fusion spatial pyramid pooling cross stage partial fast tiny module enhances the ability to fuse graphic features at different scales. This module uses a block merging method, using multiple serial 5 × 5 MaxPool layers to extract four different receptive fields, which improves detection accuracy while keeping the model lightweight. Then, to address the weak ability of convolutional neural network (CNN) structures to connect global features, the B3 module is designed to improve the extraction ability of global features by combining the multi-head self-attention mechanism of Transformer with the crossstage partial convolution(CSP) bottleneck structure, which suppresses the influence of complex outdoor rotor blade backgrounds. Finally, skew intersection over union (SKEWIOU) tilt intersection ratio loss and angle loss are introduced to improve the loss function and further enhance the accuracy of blade detection.ResultOur experiments were conducted on a self-made outdoor helicopter rotor blade dataset, a self-made outdoor simulated blade dataset, and the public dataset DOTA-v1.0 for training and validation. The self-made outdoor rotor blade dataset contains 3 878 images, which were randomly divided into training, testing, and validation sets in a 7:2:1 ratio. Our FMSA-RD was compared with mainstream horizontal and rotational models such as RetinaNet, FCOS, YOLOv5s, YOLOv6s, YOLOv7 tiny, CenterRot, FAB + DRB + CRB, H2RBox, and R3Det. Experimental results show that our method achieves an average detection accuracy of 98.5% and 110.5 frames per second. On the basis of the comparison experiments using a self-made outdoor blade dataset, the analysis indicates that the mean average precision (mAP) of FMSA-RD is 14.1%, 7.8%, 6.6%, 3.2%, 3.9%, 3.0%, 3.1%, 2.3%, and 4.2% higher than those of RetinaNet, FCOS, YOLOv5, YOLOv6s, YOLOv7 tiny, CenterRot, FAB + DRB + CRB, H2RBox, and R3Det, respectively. The public dataset DOTA contains 2 806 remote sensing images with a resolution of 800 × 800, covering various scene types such as cities, industrial areas, buildings, and roads. This comparative experiment aims to verify the generalization ability of the FMSA-RD network. We chose mainstream rotating object detection models for comparative experiments. On the self-made outdoor simulated paddle dataset, the data in the morning and noon are used as the training set, and the data at night are used as the validation set. Experiments show that FMSA-RD has low computational complexity, high detection accuracy, and good generalization ability, making it suitable for different scenarios and environments.ConclusionOur FMSA-RD can reduce complexity while integrating local feature information from different positions, suppressing complex background noise interference. The fusion of different scale features improves the accuracy of blade detection. The fusion of self-attention mechanism extracts global information and distinguishes blades without circular markers, achieving accurate detection of complex backgrounds and high aspect ratio blades while reducing model parameters and improving detection accuracy.关键词:outdoor helicopter rotor blade;rotating target detection;multi-feature;multi-head self-attention mechanism(MHSA);loss function83|64|0更新时间:2025-04-11 - “在三维人体姿态估计领域,CFJCNet算法通过联合多视图融合和关节相关性,优化二维估计结果,有效提高三维姿态估计精确度。”
 摘要:Objective3D human pose estimation is fundamental to understanding human behavior and aims to estimate 3D joint points from images or videos. It is widely used in downstream tasks such as human-computer interaction, virtual fitting, autonomous driving, and pose tracking. According to the number of cameras, 3D human pose estimation can be divided into monocular 3D human pose estimation and multi-view 3D human pose estimation. The ill-posed problem caused by occlusion and depth ambiguity means that estimating the 3D human joint points by monocular 3D human pose estimation is difficult. However multi-view 3D human pose estimation can obtain the depth of each joint from multiple images, which can overcome this problem. In most recent methods, the triangulation module is used to estimate the 3D joint positions by leveraging their 2D counterparts measured in multiple images to 3D space. This module is usually used in a two-stage procedure: First, the 2D joint coordinates of the human on each view are estimated separately by using a 2D pose detector, and then the 3D pose from multi-view 2D poses by applying triangulation. On this basis, some methods work with epipolar geometry to fuse the human joint features to establish the correlation among multiple views, which can improve the accuracy of 3D estimation. However, when the system performance is constrained by the effectiveness of the 2D estimation results, improving the final 3D estimation accuracy further is difficult. Therefore, to extract human contextual information for more effective 2D features, we construct a novel 3D pose estimation network to explore the correlation of the same joint among multiple views and the correlation between neighbor joints in the single view.MethodIn this paper, we propose a 3D human pose estimation method based on multi-view controllable fusion and joint correlation (CFJCNet), which includes three parts: a controllable multi-view fusion optimization module, a 2D pose refinement module, and a structural triangulation module. First, a set of RGB images captured from multiple views are fed into the 2D detector to obtain the 2D heatmaps, and then the adaptive weights of each heatmap are learned by a weight learning network with appearance information and geometric information branches. On this basis, we construct a multi-view controlled fusion optimization module based on epipolar geometry framework, which can analyze the estimation quality of joints in each camera view to influence the fuse process. Specifically, it selectively utilizes the principles of epipolar geometry to fuse all views according to the weights, thus ensuring that the low-quality estimation can benefit from auxiliary views while avoiding the introduction of noise in high-quality heatmaps. Subsequently, a 2D pose refinement module composed of attention mechanisms and graph convolution is applied. The attention mechanism enables the model to capture the global content by weight assignment, while the graph convolutional network (GCN) can exploit local information by aggregating the features of the neighbor nodes and instruct the topological structure information of the human skeleton. The network combining the attention and GCN can not only learn human information better but also construct the interdependence between joint points in the single view to refine 2D pose estimation results. Finally, structural triangulation is introduced with structural constraints of the human body and human skeleton length in the process of 2D-to-3D inference to improve the accuracy of 3D pose estimation. This paper adopts the pre-trained 2D backbone called simple baseline as the 2D detector to extract 2D heatmaps. The threshold ε = 0.99 is used to determine the joint estimation quality, and the number of layers N = 3 is designed for 2D pose refinement.ResultWe compare the performance of CFJCNet with that of state-of-the-art models on two public datasets, namely, Human3.6M and Total Capture, and a synthetic dataset called Occlusion-Person. The mean per joint position error (MPJPE) is used as the evaluation metric, which measures the Euclidean distance between the estimated 3D joint positions and the ground truth. MPJPE can reflect the quality of the estimated 3D human poses, providing a more intuitive representation of the performance of different methods. On the Human3.6M dataset, the proposed method achieves an additional error reduction of 2.4 mm compared with the baseline Adafuse. Moreover, because our network introduces rich priori knowledge and effectively constructs the connectivity of human joints, CFJCNet achieves at least a 10% improvement compared with most methods that do not use the skinned multi-person linear (SMPL) model. Compared with learnable human mesh triangulation (LMT) incorporating the SMPL model and volumetric triangulation, our method still achieves a 0.5 mm error reduction. On the Total Capture dataset, compared with the excellent baseline Adafuse, our method exhibits a performance improvement of 2.6%. On the Occlusion-Person dataset, the CFJCNet achieves optimal estimation for the vast majority of joints, which improves performance by 19%. Furthermore, we compare the visualization results of 3D human pose estimation between our method and the baseline Adafuse on the Human3.6M dataset and the Total Capture dataset to provide a more intuitive demonstration of the estimation performance. The qualitative experimental results on both datasets demonstrate that CFJCNet can use the prior constraints of skeleton length to correct unreasonable erroneous poses.ConclusionWe propose a multi-view 3D human pose estimation method CFJCNet, which is capable of constructing human joint consistency between multiple views as well as intrinsic topological constraints on the human skeleton in the respective views. The method achieves excellent 3D human pose estimation performance. Experimental results on the public datasets show that CFJCNet has significant advantages in evaluation metrics over other advanced methods, demonstrating its superiority and generalization.关键词:multi-view;3D human pose estimation;joint point correlation;graph convolutional network(GCN);attention mechanism;triangulation79|92|0更新时间:2025-04-11
摘要:Objective3D human pose estimation is fundamental to understanding human behavior and aims to estimate 3D joint points from images or videos. It is widely used in downstream tasks such as human-computer interaction, virtual fitting, autonomous driving, and pose tracking. According to the number of cameras, 3D human pose estimation can be divided into monocular 3D human pose estimation and multi-view 3D human pose estimation. The ill-posed problem caused by occlusion and depth ambiguity means that estimating the 3D human joint points by monocular 3D human pose estimation is difficult. However multi-view 3D human pose estimation can obtain the depth of each joint from multiple images, which can overcome this problem. In most recent methods, the triangulation module is used to estimate the 3D joint positions by leveraging their 2D counterparts measured in multiple images to 3D space. This module is usually used in a two-stage procedure: First, the 2D joint coordinates of the human on each view are estimated separately by using a 2D pose detector, and then the 3D pose from multi-view 2D poses by applying triangulation. On this basis, some methods work with epipolar geometry to fuse the human joint features to establish the correlation among multiple views, which can improve the accuracy of 3D estimation. However, when the system performance is constrained by the effectiveness of the 2D estimation results, improving the final 3D estimation accuracy further is difficult. Therefore, to extract human contextual information for more effective 2D features, we construct a novel 3D pose estimation network to explore the correlation of the same joint among multiple views and the correlation between neighbor joints in the single view.MethodIn this paper, we propose a 3D human pose estimation method based on multi-view controllable fusion and joint correlation (CFJCNet), which includes three parts: a controllable multi-view fusion optimization module, a 2D pose refinement module, and a structural triangulation module. First, a set of RGB images captured from multiple views are fed into the 2D detector to obtain the 2D heatmaps, and then the adaptive weights of each heatmap are learned by a weight learning network with appearance information and geometric information branches. On this basis, we construct a multi-view controlled fusion optimization module based on epipolar geometry framework, which can analyze the estimation quality of joints in each camera view to influence the fuse process. Specifically, it selectively utilizes the principles of epipolar geometry to fuse all views according to the weights, thus ensuring that the low-quality estimation can benefit from auxiliary views while avoiding the introduction of noise in high-quality heatmaps. Subsequently, a 2D pose refinement module composed of attention mechanisms and graph convolution is applied. The attention mechanism enables the model to capture the global content by weight assignment, while the graph convolutional network (GCN) can exploit local information by aggregating the features of the neighbor nodes and instruct the topological structure information of the human skeleton. The network combining the attention and GCN can not only learn human information better but also construct the interdependence between joint points in the single view to refine 2D pose estimation results. Finally, structural triangulation is introduced with structural constraints of the human body and human skeleton length in the process of 2D-to-3D inference to improve the accuracy of 3D pose estimation. This paper adopts the pre-trained 2D backbone called simple baseline as the 2D detector to extract 2D heatmaps. The threshold ε = 0.99 is used to determine the joint estimation quality, and the number of layers N = 3 is designed for 2D pose refinement.ResultWe compare the performance of CFJCNet with that of state-of-the-art models on two public datasets, namely, Human3.6M and Total Capture, and a synthetic dataset called Occlusion-Person. The mean per joint position error (MPJPE) is used as the evaluation metric, which measures the Euclidean distance between the estimated 3D joint positions and the ground truth. MPJPE can reflect the quality of the estimated 3D human poses, providing a more intuitive representation of the performance of different methods. On the Human3.6M dataset, the proposed method achieves an additional error reduction of 2.4 mm compared with the baseline Adafuse. Moreover, because our network introduces rich priori knowledge and effectively constructs the connectivity of human joints, CFJCNet achieves at least a 10% improvement compared with most methods that do not use the skinned multi-person linear (SMPL) model. Compared with learnable human mesh triangulation (LMT) incorporating the SMPL model and volumetric triangulation, our method still achieves a 0.5 mm error reduction. On the Total Capture dataset, compared with the excellent baseline Adafuse, our method exhibits a performance improvement of 2.6%. On the Occlusion-Person dataset, the CFJCNet achieves optimal estimation for the vast majority of joints, which improves performance by 19%. Furthermore, we compare the visualization results of 3D human pose estimation between our method and the baseline Adafuse on the Human3.6M dataset and the Total Capture dataset to provide a more intuitive demonstration of the estimation performance. The qualitative experimental results on both datasets demonstrate that CFJCNet can use the prior constraints of skeleton length to correct unreasonable erroneous poses.ConclusionWe propose a multi-view 3D human pose estimation method CFJCNet, which is capable of constructing human joint consistency between multiple views as well as intrinsic topological constraints on the human skeleton in the respective views. The method achieves excellent 3D human pose estimation performance. Experimental results on the public datasets show that CFJCNet has significant advantages in evaluation metrics over other advanced methods, demonstrating its superiority and generalization.关键词:multi-view;3D human pose estimation;joint point correlation;graph convolutional network(GCN);attention mechanism;triangulation79|92|0更新时间:2025-04-11
Image Understanding and Computer Vision
-
Integrating spatiotemporal features and temporal constraints for dual-modal breast tumor diagnosis AI导读
“在乳腺肿瘤诊断领域,专家提出了融合时空特征与时间约束的双模态模型STFTCM,有效提升诊断准确性,为患者生存率提高奠定基础。” 摘要:ObjectiveBreast cancer ranks first in the incidence of cancer among women worldwide, impacting the health of the female population. Timely diagnosis of breast tumor can offer better treatment opportunities for patients. B-mode ultrasound (B-US) imaging contains rich spatial information such as lesion size and morphology. It is widely used in breast tumor diagnosis because of its advantages of low cost and high safety. On this basis, with the advancement of deep learning technology, some deep learning models have been applied to computer-aided diagnosis of breast tumor diagnosis based on B-US to assist doctors. However, diagnosis based solely on B-US imaging results in lower specificity. Moreover, the performance of models trained exclusively on B-US is limited by the singular modality of information source. Contrast-enhanced ultrasound (CEUS) can provide a second modality of information on top of B-US to improve diagnostic accuracy. CEUS contains rich spatiotemporal information, such as brightness enhancement and vascular distribution in the lesion area, by injecting contrast agents intravenously and capturing the information during the time window when the contrast agent flows into the lesion area. Considering the B-US and CEUS dual-mode information comprehensively can enhance diagnostic accuracy. A model integrating spatiotemporal features and temporal-constrained (STFTCM) for dual-modality breast tumor diagnosis is proposed to effectively utilize dual-modal data for breast tumor diagnosis.MethodSTFTCM primarily comprises a heterogeneous dual-branch network, a temporal attention constraint module, and feature fusion modules. On the basis of the characteristics of dual-mode data information dimensions, STFTCM adopts a heterogeneous dual-branch structure to extract the dual-mode feature separately. For the B-US branch, B-US consists of spatial features within the two-dimensional frames of the video, and inter-frame transformations are not prominent. Considering that training 3D convolutional networks on a small dataset tends to result in overfitting due to the larger number of parameters compared with 2D convolutional networks, a 2D network, ResNet-18, is used as the backbone network for feature extraction from a single frame extracted from the video. In contrast, CEUS video frames undergo noticeable transformations during the time window when the contrast agent flows through the lesion area, containing rich spatiotemporal information. Thus, a 3D network, R(2 + 1)D-18, is used as the backbone network for the CEUS branch. The structure is adjusted on the basis of the backbone network to ensure the feature maps extracted from corresponding layers of the dual-branch network have the same dimensions for subsequent dual-mode fusion. On the basis of the aforementioned CEUS branch, the spatiotemporal information in CEUS mainly resides within the time window when the contrast agent flows into the lesion area; thus, guiding the model to focus on this time segment facilitates better learning of CEUS features on a small dataset. To address this issue, a temporal attention loss function is proposed. An analysis of the temporal knowledge of CEUS video shows that the temporal loss function first determines the temporal attention boundary on the basis of the first-order difference of the discrete sequence of CEUS frames luminance values and then establishes a temporal mask. Subsequently, the temporal attention loss function guides the updating of the parameters of the R(2 + 1)D temporal convolutional kernels in the CEUS branch based on the temporal mask, thereby directing the model to focus on the information during the period when the contrast agent flows into the lesion area. Furthermore, a feature fusion module is introduced to fuse dual-mode information and thus improve prediction accuracy by considering information from both B-US and CEUS. Model parameter size is controlled by not setting a separate third feature fusion branch; instead, the feature fusion module facilitates feature fusion between the dual branches through lateral connections. B-US spatial information is incorporated as supplementary data into the CEUS branch. The feature fusion module comprises a spatial feature fusion module and an identity mapping branch. The spatial feature fusion module combines two-dimensional spatial feature maps of B-US and three-dimensional spatiotemporal feature maps of CEUS, while the identity mapping branch prevents loss of the original CEUS features during the fusion process.ResultComparative and structural ablation experiments are conducted to explore the performance of STFTCM and the effectiveness of the temporal attention constraint and feature fusion modules. Experimental data are obtained from the Shengjing Hospital of China Medical University, comprising 332 ultrasound contrast videos categorized into benign tumors, malignant tumors, and inflammations, with 101, 102, and 129 instances, respectively. Accuracy, sensitivity, specificity, macro-average F1, and area under the curve are used as model performance evaluation metrics. In comparative experiments, STFTCM achieves an accuracy of 0.882, with respective scores of 0.909, 0.870, 0.883, and 0.952 for the other four metrics, outperforming other advanced models. In single-branch model comparison experiments, both the B-US and CEUS branches of STFTCM perform better than other advanced models. Comparative experiments between dual-branch and single-branch models demonstrate the excellent performance of STFTCM. Structural ablation experiment results show that temporal attention loss constraint improved prediction accuracy by 5.8 percentage points, and dual-modal feature fusion enhanced prediction accuracy by at least 2.9 percentage points compared with unimodal predictions, confirming the effectiveness of the temporal attention constraint and feature fusion modules in enhancing model performance. Additionally, visualization of model attention through class activation maps validates that the temporal attention constraint improves the model’s attention in the temporal dimension, guiding better extraction of spatiotemporal information contained in CEUS.Resultsfrom experiments related to the feature fusion module demonstrate that the addition of the identity mapping branch could improve prediction accuracy by 2.9 percentage points, further confirming the rationality of the feature fusion module’s structural design.ConclusionSTFTCM, designed based on prior knowledge, has demonstrated excellent performance for breast tumor diagnosis. The heterogeneous dual-branch structure designed on the basis of the characteristics of dual-mode data effectively extracts B-US and CEUS dual-mode features while reducing model parameters for better parameter optimization on small datasets. The temporal attention loss function constrains the model’s attention in the temporal dimension, guiding the model to focus on information from the time window when the contrast agent flows into the lesion area. Furthermore, the feature fusion module effectively implements lateral connections between dual-branch networks to fuse dual-mode features.关键词:dual-modality breast tumor diagnosis;spatiotemporal feature;temporal attention constraint;contrast-enhanced ultrasound(CEUS);B-mode ultrasound(B-US)114|79|0更新时间:2025-04-11
摘要:ObjectiveBreast cancer ranks first in the incidence of cancer among women worldwide, impacting the health of the female population. Timely diagnosis of breast tumor can offer better treatment opportunities for patients. B-mode ultrasound (B-US) imaging contains rich spatial information such as lesion size and morphology. It is widely used in breast tumor diagnosis because of its advantages of low cost and high safety. On this basis, with the advancement of deep learning technology, some deep learning models have been applied to computer-aided diagnosis of breast tumor diagnosis based on B-US to assist doctors. However, diagnosis based solely on B-US imaging results in lower specificity. Moreover, the performance of models trained exclusively on B-US is limited by the singular modality of information source. Contrast-enhanced ultrasound (CEUS) can provide a second modality of information on top of B-US to improve diagnostic accuracy. CEUS contains rich spatiotemporal information, such as brightness enhancement and vascular distribution in the lesion area, by injecting contrast agents intravenously and capturing the information during the time window when the contrast agent flows into the lesion area. Considering the B-US and CEUS dual-mode information comprehensively can enhance diagnostic accuracy. A model integrating spatiotemporal features and temporal-constrained (STFTCM) for dual-modality breast tumor diagnosis is proposed to effectively utilize dual-modal data for breast tumor diagnosis.MethodSTFTCM primarily comprises a heterogeneous dual-branch network, a temporal attention constraint module, and feature fusion modules. On the basis of the characteristics of dual-mode data information dimensions, STFTCM adopts a heterogeneous dual-branch structure to extract the dual-mode feature separately. For the B-US branch, B-US consists of spatial features within the two-dimensional frames of the video, and inter-frame transformations are not prominent. Considering that training 3D convolutional networks on a small dataset tends to result in overfitting due to the larger number of parameters compared with 2D convolutional networks, a 2D network, ResNet-18, is used as the backbone network for feature extraction from a single frame extracted from the video. In contrast, CEUS video frames undergo noticeable transformations during the time window when the contrast agent flows through the lesion area, containing rich spatiotemporal information. Thus, a 3D network, R(2 + 1)D-18, is used as the backbone network for the CEUS branch. The structure is adjusted on the basis of the backbone network to ensure the feature maps extracted from corresponding layers of the dual-branch network have the same dimensions for subsequent dual-mode fusion. On the basis of the aforementioned CEUS branch, the spatiotemporal information in CEUS mainly resides within the time window when the contrast agent flows into the lesion area; thus, guiding the model to focus on this time segment facilitates better learning of CEUS features on a small dataset. To address this issue, a temporal attention loss function is proposed. An analysis of the temporal knowledge of CEUS video shows that the temporal loss function first determines the temporal attention boundary on the basis of the first-order difference of the discrete sequence of CEUS frames luminance values and then establishes a temporal mask. Subsequently, the temporal attention loss function guides the updating of the parameters of the R(2 + 1)D temporal convolutional kernels in the CEUS branch based on the temporal mask, thereby directing the model to focus on the information during the period when the contrast agent flows into the lesion area. Furthermore, a feature fusion module is introduced to fuse dual-mode information and thus improve prediction accuracy by considering information from both B-US and CEUS. Model parameter size is controlled by not setting a separate third feature fusion branch; instead, the feature fusion module facilitates feature fusion between the dual branches through lateral connections. B-US spatial information is incorporated as supplementary data into the CEUS branch. The feature fusion module comprises a spatial feature fusion module and an identity mapping branch. The spatial feature fusion module combines two-dimensional spatial feature maps of B-US and three-dimensional spatiotemporal feature maps of CEUS, while the identity mapping branch prevents loss of the original CEUS features during the fusion process.ResultComparative and structural ablation experiments are conducted to explore the performance of STFTCM and the effectiveness of the temporal attention constraint and feature fusion modules. Experimental data are obtained from the Shengjing Hospital of China Medical University, comprising 332 ultrasound contrast videos categorized into benign tumors, malignant tumors, and inflammations, with 101, 102, and 129 instances, respectively. Accuracy, sensitivity, specificity, macro-average F1, and area under the curve are used as model performance evaluation metrics. In comparative experiments, STFTCM achieves an accuracy of 0.882, with respective scores of 0.909, 0.870, 0.883, and 0.952 for the other four metrics, outperforming other advanced models. In single-branch model comparison experiments, both the B-US and CEUS branches of STFTCM perform better than other advanced models. Comparative experiments between dual-branch and single-branch models demonstrate the excellent performance of STFTCM. Structural ablation experiment results show that temporal attention loss constraint improved prediction accuracy by 5.8 percentage points, and dual-modal feature fusion enhanced prediction accuracy by at least 2.9 percentage points compared with unimodal predictions, confirming the effectiveness of the temporal attention constraint and feature fusion modules in enhancing model performance. Additionally, visualization of model attention through class activation maps validates that the temporal attention constraint improves the model’s attention in the temporal dimension, guiding better extraction of spatiotemporal information contained in CEUS.Resultsfrom experiments related to the feature fusion module demonstrate that the addition of the identity mapping branch could improve prediction accuracy by 2.9 percentage points, further confirming the rationality of the feature fusion module’s structural design.ConclusionSTFTCM, designed based on prior knowledge, has demonstrated excellent performance for breast tumor diagnosis. The heterogeneous dual-branch structure designed on the basis of the characteristics of dual-mode data effectively extracts B-US and CEUS dual-mode features while reducing model parameters for better parameter optimization on small datasets. The temporal attention loss function constrains the model’s attention in the temporal dimension, guiding the model to focus on information from the time window when the contrast agent flows into the lesion area. Furthermore, the feature fusion module effectively implements lateral connections between dual-branch networks to fuse dual-mode features.关键词:dual-modality breast tumor diagnosis;spatiotemporal feature;temporal attention constraint;contrast-enhanced ultrasound(CEUS);B-mode ultrasound(B-US)114|79|0更新时间:2025-04-11
Medical Image Processing
- “在遥感飞机细粒度识别领域,专家提出了融合边界框高斯建模与特征聚合分发的YOLOv5s算法,有效提高了小目标检测精度。实验结果显示,模型精确度分别达到了99.10%和95.36%,检测精度最佳。”
 摘要:ObjectiveAs a basic branch of computer vision, object detection plays an important role in subsequent tasks such as image segmentation and object tracking. It aims to find all the objects in the image and determine the location and category of the objects. It is used in industrial testing and has profound and extensive applications in aerospace, autonomous driving, and other fields. Aircraft detection in remote sensing images is of great significance to both military and civilian fields such as air traffic control and battlefield dynamic monitoring. As a result of the large differences in object size in remote sensing aircraft images, the acquisition process is affected by factors such as lighting and occlusion, resulting in similar characteristics of different types of aircraft, poor detection of small objects, and the inability to achieve fine-grained distinction within categories. In object detection, the loss function is used to measure the difference between the model prediction and the actual object, which directly affects the performance and convergence speed of the model. Adjusting the model parameters so that the value of the loss function reaches the minimum value can improve the accuracy of the model in the test set. The loss function of YOLOv5 consists of position loss, category loss and confidence loss. YOLOv5 uses the intersection over union (IoU) and the derivative algorithm complete IoU by default, and provides IoU, generalized IoU, and distance IoU for replacement. However, for small object detection, especially with anchor box-based algorithms such as YOLOv5, the IoU series indicators cannot meet application needs well. Different types of remote sensing aircraft have fine-grained characteristics, which are reflected in subtle differences between classes, large differences within classes, and detail accuracy within classes. For fine-grained recognition tasks, extracting local information is crucial. The feature fusion module PANet used by YOLOv5s cannot achieve global feature fusion and is not conducive to extracting fine-grained features. To solve the above problems, this article proposes a model improvement algorithm based on YOLOv5s.MethodIn view of the shortcomings of IoU in small object detection based on YOLOv5, this article introduces Gaussian Wasserstein distance into the calculation of bounding box overlap to improve the detection performance of the network. Different from the IoU series of algorithms that calculate the similarity between different prediction boxes and real boxes based on the set of pixels contained in the bounding box, the Gaussian Wasserstein distance abandons the set, models the bounding box as a two-dimensional Gaussian distribution, and proposes a new metric called normalized Gaussian Wasserstein distance to calculate the similarity between frames, which fundamentally solves the problem of IoU in small object detection based on YOLOv5. In response to PANet’s shortcomings in fine-grained detection, this article introduces the gather-and-distribute feature aggregation module in Gold-YOLO into YOLOv5s to enhance the YOLOv5s network’s ability to extract fine-grained features through convolution and self-attention mechanisms. 1) The method combining Gaussian Wasserstein distance and traditional IoU is used to improve the loss function of YOLOv5s. 2) The gather-and-distribute feature aggregation module is introduced in the neck part of YOLOv5s to enhance the network’s local feature extraction capabilities. Through the above two methods, the overall detection accuracy is improved. To test the advantages of this algorithm in fine-grained and small object recognition on military aircraft, this paper uses the remote sensing aircraft fine-grained classification dataset MAR20 and the remote sensing aircraft small object dataset CORS-ADD to conduct experiments. In the field of remote sensing military aircraft identification, different types of aircraft often have similar characteristics, resulting in different types of aircraft having similar characteristics, making it difficult to achieve intra-class identification. This article uses the open-source object detection remote sensing image dataset military aircraft recognition 20(MAR20) to achieve fine-grained recognition of remote sensing military aircraft. The dataset contains a total of 3 842 images, including 20 military aircraft models (SU-35, C-130, C-17, C-5, F-16, TU-160, E-3, B-52, P-3C, B-1B, E-8, TU-22, F-15, KC-135, F-22, FA-18, TU-95, KC-10, SU-34, SU-24). The CORS-ADD dataset is a complex optical remote sensing aircraft small object dataset that is manually annotated and constructed by the Space Optical Engineering Research Center of Harbin Institute of Technology. It contains a total of 7 337 images, including 32 285 aircraft instances, and the object size ranges from 4 × 4 pixels to 240 × 240 pixels. Different from the single data source of previous remote sensing datasets, the CORS-ADD dataset comes from satellite platforms such as Google Maps, WorldView-2, WorldView-3, Pleiades, Jilin-1, and IKONOS, covering airports, aircraft carriers, oceans, land, and other scenarios, as well as aircraft objects such as bombers, fighter jets, and early-warning aircraft at typical airports in China and the United States.ResultTo test the algorithm improvement effect of the two improved modules on remote sensing aircraft recognition based on YOLOv5s, this article compares the model performance of the original YOLOv5s with the introduction of normalized Gaussian Wasserstein distance(NWD) (r is the weight parameter used to adjust the ratio of IoU and NWD) and GD. The experimental result shows that the introduction of NWD and GD can improve the recognition accuracy to varying degrees, and the improvements are effective. When the ratio of IoU to NWD is 1:1, the recognition effect of the MAR20 dataset is the best; when the ratio of IoU to NWD is 1:9, the recognition effect of the CORS-ADD dataset is the best. Experimental results show the following: For the MAR20 dataset, compared with that of YOLOv5s, YOLOv8s, and Gold-YOLO, the mAP of improved YOLOv5s increased by 1.1%, 0.7% and 1.8% respectively; for the CORS-ADD dataset, mAP increased by 0.6%, 1.7%, and 3.9%, respectively.ConclusionAn improved YOLOv5s network is proposed to solve the problems of large object size differences and high intra-class similarity in the process of remote sensing aircraft image recognition. On the basis of YOLOv5s, the loss function of YOLOv5s is improved by combining the Gaussian Wasserstein distance with the traditional IoU metric, which improves the detection effect of objects of different sizes, thereby improving the detection accuracy of the model. At the same time, to solve the problem of the characteristics of different types of aircraft being similar and the difficulty of distinguishing between sub-categories, this article uses the gather-and-distribute feature aggregation module in Gold-YOLO to enhance the ability of the YOLOv5s network to extract fine-grained features. A comparison shows that the improved YOLOv5s has a better model detection accuracy than that of YOLOv5s, YOLOv8s, Gold-YOLO, and Faster R-CNN. To improve the image processing speed of the model without reducing the accuracy of the model and to reduce the consumption of computing resources as much as possible to achieve lightweight deployment in the future, this article will consider using the C3_DSConv network to replace the C3 network of the YOLOv5s detection part to improve the model check speed and make it lightweight.关键词:object detection;improved YOLOv5s;remote sensing aircraft imagery;fine-grained recognition;feature fusion111|103|0更新时间:2025-04-11
摘要:ObjectiveAs a basic branch of computer vision, object detection plays an important role in subsequent tasks such as image segmentation and object tracking. It aims to find all the objects in the image and determine the location and category of the objects. It is used in industrial testing and has profound and extensive applications in aerospace, autonomous driving, and other fields. Aircraft detection in remote sensing images is of great significance to both military and civilian fields such as air traffic control and battlefield dynamic monitoring. As a result of the large differences in object size in remote sensing aircraft images, the acquisition process is affected by factors such as lighting and occlusion, resulting in similar characteristics of different types of aircraft, poor detection of small objects, and the inability to achieve fine-grained distinction within categories. In object detection, the loss function is used to measure the difference between the model prediction and the actual object, which directly affects the performance and convergence speed of the model. Adjusting the model parameters so that the value of the loss function reaches the minimum value can improve the accuracy of the model in the test set. The loss function of YOLOv5 consists of position loss, category loss and confidence loss. YOLOv5 uses the intersection over union (IoU) and the derivative algorithm complete IoU by default, and provides IoU, generalized IoU, and distance IoU for replacement. However, for small object detection, especially with anchor box-based algorithms such as YOLOv5, the IoU series indicators cannot meet application needs well. Different types of remote sensing aircraft have fine-grained characteristics, which are reflected in subtle differences between classes, large differences within classes, and detail accuracy within classes. For fine-grained recognition tasks, extracting local information is crucial. The feature fusion module PANet used by YOLOv5s cannot achieve global feature fusion and is not conducive to extracting fine-grained features. To solve the above problems, this article proposes a model improvement algorithm based on YOLOv5s.MethodIn view of the shortcomings of IoU in small object detection based on YOLOv5, this article introduces Gaussian Wasserstein distance into the calculation of bounding box overlap to improve the detection performance of the network. Different from the IoU series of algorithms that calculate the similarity between different prediction boxes and real boxes based on the set of pixels contained in the bounding box, the Gaussian Wasserstein distance abandons the set, models the bounding box as a two-dimensional Gaussian distribution, and proposes a new metric called normalized Gaussian Wasserstein distance to calculate the similarity between frames, which fundamentally solves the problem of IoU in small object detection based on YOLOv5. In response to PANet’s shortcomings in fine-grained detection, this article introduces the gather-and-distribute feature aggregation module in Gold-YOLO into YOLOv5s to enhance the YOLOv5s network’s ability to extract fine-grained features through convolution and self-attention mechanisms. 1) The method combining Gaussian Wasserstein distance and traditional IoU is used to improve the loss function of YOLOv5s. 2) The gather-and-distribute feature aggregation module is introduced in the neck part of YOLOv5s to enhance the network’s local feature extraction capabilities. Through the above two methods, the overall detection accuracy is improved. To test the advantages of this algorithm in fine-grained and small object recognition on military aircraft, this paper uses the remote sensing aircraft fine-grained classification dataset MAR20 and the remote sensing aircraft small object dataset CORS-ADD to conduct experiments. In the field of remote sensing military aircraft identification, different types of aircraft often have similar characteristics, resulting in different types of aircraft having similar characteristics, making it difficult to achieve intra-class identification. This article uses the open-source object detection remote sensing image dataset military aircraft recognition 20(MAR20) to achieve fine-grained recognition of remote sensing military aircraft. The dataset contains a total of 3 842 images, including 20 military aircraft models (SU-35, C-130, C-17, C-5, F-16, TU-160, E-3, B-52, P-3C, B-1B, E-8, TU-22, F-15, KC-135, F-22, FA-18, TU-95, KC-10, SU-34, SU-24). The CORS-ADD dataset is a complex optical remote sensing aircraft small object dataset that is manually annotated and constructed by the Space Optical Engineering Research Center of Harbin Institute of Technology. It contains a total of 7 337 images, including 32 285 aircraft instances, and the object size ranges from 4 × 4 pixels to 240 × 240 pixels. Different from the single data source of previous remote sensing datasets, the CORS-ADD dataset comes from satellite platforms such as Google Maps, WorldView-2, WorldView-3, Pleiades, Jilin-1, and IKONOS, covering airports, aircraft carriers, oceans, land, and other scenarios, as well as aircraft objects such as bombers, fighter jets, and early-warning aircraft at typical airports in China and the United States.ResultTo test the algorithm improvement effect of the two improved modules on remote sensing aircraft recognition based on YOLOv5s, this article compares the model performance of the original YOLOv5s with the introduction of normalized Gaussian Wasserstein distance(NWD) (r is the weight parameter used to adjust the ratio of IoU and NWD) and GD. The experimental result shows that the introduction of NWD and GD can improve the recognition accuracy to varying degrees, and the improvements are effective. When the ratio of IoU to NWD is 1:1, the recognition effect of the MAR20 dataset is the best; when the ratio of IoU to NWD is 1:9, the recognition effect of the CORS-ADD dataset is the best. Experimental results show the following: For the MAR20 dataset, compared with that of YOLOv5s, YOLOv8s, and Gold-YOLO, the mAP of improved YOLOv5s increased by 1.1%, 0.7% and 1.8% respectively; for the CORS-ADD dataset, mAP increased by 0.6%, 1.7%, and 3.9%, respectively.ConclusionAn improved YOLOv5s network is proposed to solve the problems of large object size differences and high intra-class similarity in the process of remote sensing aircraft image recognition. On the basis of YOLOv5s, the loss function of YOLOv5s is improved by combining the Gaussian Wasserstein distance with the traditional IoU metric, which improves the detection effect of objects of different sizes, thereby improving the detection accuracy of the model. At the same time, to solve the problem of the characteristics of different types of aircraft being similar and the difficulty of distinguishing between sub-categories, this article uses the gather-and-distribute feature aggregation module in Gold-YOLO to enhance the ability of the YOLOv5s network to extract fine-grained features. A comparison shows that the improved YOLOv5s has a better model detection accuracy than that of YOLOv5s, YOLOv8s, Gold-YOLO, and Faster R-CNN. To improve the image processing speed of the model without reducing the accuracy of the model and to reduce the consumption of computing resources as much as possible to achieve lightweight deployment in the future, this article will consider using the C3_DSConv network to replace the C3 network of the YOLOv5s detection part to improve the model check speed and make it lightweight.关键词:object detection;improved YOLOv5s;remote sensing aircraft imagery;fine-grained recognition;feature fusion111|103|0更新时间:2025-04-11 - “在SAR船舶检测领域,专家提出了多粒度上下文网络,有效提高了检测准确性。”
 摘要:ObjectiveSynthetic aperture radar (SAR), as an active microwave sensor, can acquire high-resolution remote sensing images, which is crucial in marine ship detection. Nevertheless, two primary challenges confront ship detection in SAR images. First and foremost, SAR images frequently encompass complex backgrounds, incorporating turbulent sea waves, islands, and various forms of clutter. These complex backgrounds can significantly hinder the accurate identification of ship targets. The diverse spectrum of ship target sizes within SAR images presents another significant challenge. Traditional detection methods struggle to adapt to the broad range of ship sizes encountered in real-world scenarios. In recent years, with the extensive application of deep learning models and attention mechanisms, researchers have successfully improved the performance of SAR ship detection methods and effectively overcome the detection challenges of SAR ship targets of different sizes in complex backgrounds. However, these methods either have limitations in detection accuracy or require extensive computing resources. To address these challenges, this paper proposes a multi-granularity context network for SAR ship detection.MethodFirst, a multi-granularity channel attention (MCA) module is designed to weight the global and local contextual information of different granularities. The primary function of the MCA module is to focus on important characteristics of ship targets and minimize interference caused by complex backgrounds on detection results. Pointwise convolution replaces traditional convolution as an aggregator of global and local channel context information to ensure a lightweight MCA module. This substitution not only trims computational overhead but also streamlines the process. Furthermore, the MCA module is integrated into the first layer of the backbone network feature extraction of the YOLOv5s framework. The fusion of pointwise convolution and integration within the network architecture collectively strengthens our capability for accurate and efficient SAR ship detection. Then, a multi-granularity atrous adaptive spatial feature fusion (MAASFF) module is designed to reduce the loss of contextual information in feature map generation and enhance the representation capability of feature pyramids, thereby improving the detection performance of ships at different sizes. In the process of fusing features of different granularities, the MAASFF module avoids ignoring the differences between ship target features of different sizes and reduces unnecessary computational overload. It primarily employs an adaptive spatial feature fusion method to merge the feature maps extracted using three different atrous rates (1, 2, and 3) of atrous convolutions. This design effectively captures features at different spatial granularities, enhancing the feature representation capability for ships of different sizes.ResultCompared with nine other methods on two datasets, SAR-Ship-Dataset and SSDD, our method achieves the best detection results. On the SAR-Ship-Dataset, compared with the two-stage methods Faster R-CNN, DAPN, CR2A-Net, KCPNet, and BL-Net, our method can improve model detection accuracy by approximately 1.9% to 6.0%. Compared with common one-stage methods such as YOLOv4, CenterNet++, CRDet, and YOLOv5s, our method can enhance performance by 2.9%, 1.2%, 0.9%, and 1.8%, respectively. Experimental results indicate that our method achieves the best performance on the SAR-Ship-Dataset, reaching 96.1% mAP and thus outperforming all compared methods. On the SSDD dataset, our method improves the performance by approximately 8.7% (Faster R-CNN), 6.9% (DAPN), 7.2% (CR2A-Net), 4.5% (KCPNet), 1.8% (BL-Net), 0.9% (YOLOv4), 4.3% (CenterNet++), 0.6% (CRDet), and 1.6% (YOLOv5s) while maintaining a speed similar to the baseline YOLOv5s. These results show our method has good generalization ability and achieves the best performance with 97.0% mAP, further verifying its excellent effect and performance in SAR ship detection tasks.ConclusionThis paper proposes a multi-granularity context network, which aims to suppress complex background interference and enhance the ability to extract features of multi-sized ships, effectively improving the accuracy of SAR ship detection.关键词:synthetic aperture radar (SAR) image;ship detection;multi-granularity;channel attention;feature fusion116|119|0更新时间:2025-04-11
摘要:ObjectiveSynthetic aperture radar (SAR), as an active microwave sensor, can acquire high-resolution remote sensing images, which is crucial in marine ship detection. Nevertheless, two primary challenges confront ship detection in SAR images. First and foremost, SAR images frequently encompass complex backgrounds, incorporating turbulent sea waves, islands, and various forms of clutter. These complex backgrounds can significantly hinder the accurate identification of ship targets. The diverse spectrum of ship target sizes within SAR images presents another significant challenge. Traditional detection methods struggle to adapt to the broad range of ship sizes encountered in real-world scenarios. In recent years, with the extensive application of deep learning models and attention mechanisms, researchers have successfully improved the performance of SAR ship detection methods and effectively overcome the detection challenges of SAR ship targets of different sizes in complex backgrounds. However, these methods either have limitations in detection accuracy or require extensive computing resources. To address these challenges, this paper proposes a multi-granularity context network for SAR ship detection.MethodFirst, a multi-granularity channel attention (MCA) module is designed to weight the global and local contextual information of different granularities. The primary function of the MCA module is to focus on important characteristics of ship targets and minimize interference caused by complex backgrounds on detection results. Pointwise convolution replaces traditional convolution as an aggregator of global and local channel context information to ensure a lightweight MCA module. This substitution not only trims computational overhead but also streamlines the process. Furthermore, the MCA module is integrated into the first layer of the backbone network feature extraction of the YOLOv5s framework. The fusion of pointwise convolution and integration within the network architecture collectively strengthens our capability for accurate and efficient SAR ship detection. Then, a multi-granularity atrous adaptive spatial feature fusion (MAASFF) module is designed to reduce the loss of contextual information in feature map generation and enhance the representation capability of feature pyramids, thereby improving the detection performance of ships at different sizes. In the process of fusing features of different granularities, the MAASFF module avoids ignoring the differences between ship target features of different sizes and reduces unnecessary computational overload. It primarily employs an adaptive spatial feature fusion method to merge the feature maps extracted using three different atrous rates (1, 2, and 3) of atrous convolutions. This design effectively captures features at different spatial granularities, enhancing the feature representation capability for ships of different sizes.ResultCompared with nine other methods on two datasets, SAR-Ship-Dataset and SSDD, our method achieves the best detection results. On the SAR-Ship-Dataset, compared with the two-stage methods Faster R-CNN, DAPN, CR2A-Net, KCPNet, and BL-Net, our method can improve model detection accuracy by approximately 1.9% to 6.0%. Compared with common one-stage methods such as YOLOv4, CenterNet++, CRDet, and YOLOv5s, our method can enhance performance by 2.9%, 1.2%, 0.9%, and 1.8%, respectively. Experimental results indicate that our method achieves the best performance on the SAR-Ship-Dataset, reaching 96.1% mAP and thus outperforming all compared methods. On the SSDD dataset, our method improves the performance by approximately 8.7% (Faster R-CNN), 6.9% (DAPN), 7.2% (CR2A-Net), 4.5% (KCPNet), 1.8% (BL-Net), 0.9% (YOLOv4), 4.3% (CenterNet++), 0.6% (CRDet), and 1.6% (YOLOv5s) while maintaining a speed similar to the baseline YOLOv5s. These results show our method has good generalization ability and achieves the best performance with 97.0% mAP, further verifying its excellent effect and performance in SAR ship detection tasks.ConclusionThis paper proposes a multi-granularity context network, which aims to suppress complex background interference and enhance the ability to extract features of multi-sized ships, effectively improving the accuracy of SAR ship detection.关键词:synthetic aperture radar (SAR) image;ship detection;multi-granularity;channel attention;feature fusion116|119|0更新时间:2025-04-11
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0